融合自注意力机制的长文本生成对抗网络模型
2022-07-21夏鸿斌肖奕飞
夏鸿斌,肖奕飞,刘 渊
1.江南大学 人工智能与计算机学院,江苏 无锡214122
2.江苏省媒体设计与软件技术重点实验室,江苏 无锡214122
在机器翻译、文本摘要、问答系统等自然语言处理中,生成语句通顺、连贯的文本是非常重要的。而这些都是基于有监督的文本生成,无监督的文本生成最近引起了重大关注。
一种最早由Cho 等人提出的经典方法是训练一个递归神经网络(recurrent neural network,RNN),后来用作最大化给定观察到的每个正确的标注数据的对数似然性。但是由于它采用的是线性序列结构,当用于反向传播时存在传播路径太长、梯度消失或者梯度爆炸等优化困难的问题。为了解决这个问题,有学者引入了长短期记忆网络(long short-term memory,LSTM)和门控循环单元(gated recurrent unit,GRU)模型。通过增加中间状态信息直接向后传播,解决了梯度消失问题,使得LSTM 和GRU 成为RNN的标准模型。后来,自然语言处理(natural language processing,NLP)又从图像领域借鉴并引入了注意力机制,叠加网络把深度做深,以及引入编码器-解码器框架,这些技术进展极大拓展了RNN的能力。2015年,LeCun 等人将卷积神经网络(convolutional neural networks,CNN)引入NLP 领域,使用时间卷积网络(ConvNets)将深度学习应用于从字符级输入一直到抽象文本概念的文本理解。CNN强有力的并行计算能力使得其已经完全取代了RNN 在NLP 领域中的地位。但是CNN不同于RNN的线性结构,不会自然地将位置信息进行编码,因此存在位置编码的问题,当在设计模型中加入池化层时,CNN 会丢失相对位置信息。就目前CNN 的发展趋势来看,大多数已经放弃池化层,选择加深卷积层的深度。2017年,谷歌首次提出了Transformer并用于机器翻译任务,并以Transformer为基础提出了bert模型,该模型编码器部分由Multi-Head Attention和一个全连接组成,用于将输入语料转化成特征向量。Transformer不像RNN或CNN,必须明确地在输入端用位置函数来进行位置编码。在长距离捕获特征和并行计算能力等方面,Transformer表现出比RNN和CNN更明显的优势。
生成对抗网络(generative adversarial networks,GAN)最早是在2014 年由Goodfellow 提出,用于连续的数据例如图像、图片和视频生成等。并逐步应用于离散数据,例如文本生成。生成对抗网络包含生成器网络和判别器网络,这些网络可以是神经网络,例如卷积神经网络、递归神经网络等。这两个网络之间相互博弈,生成器网络目标是生成完美能欺骗判别器的虚假图像,而判别器的目标则是分辨出图像的真实性。经过反复多次的博弈,最终使得生成器网络生成的图像能被判别器网络认同。标准的GAN在处理离散数据时会遇到生成器难处理传递梯度和判别器不能评估残缺的序列等困难,AAAI 2017的文献[10]提出的序列对抗网络(sequence generative adversarial networks,SeqGAN)解决了这些问题。核心思路是将GAN 作为一个强化学习系统,用策略梯度算法更新生成器的参数,同时采用蒙特卡洛搜索算法,实现对任意时刻的残缺序列都可以进行评估。尽管如此,SeqGAN 仍存在缺陷,即当要生成较长的文本时,判别器的指导信号的稀疏性使得生成过程中缺少与文本结构相关的中间信息,从而导致效果不够良好。随后AAAI 2018的文献[11]提出了一种叫作LeakGAN(leak generative adversarial networks)的新算法框架,通过泄露由判别器提取的特征作为逐步引导信号,以指导生成器更好地生成长文本,同时借鉴分层强化学习从判别器向生成器提供更丰富的信息。在GAN中,鉴别器使用CNN提取输入信息的特征向量,来指导生成器中MANAGER 模块的训练,使指导信号更有信息性,同时使用分层生成器结构,将整个生成任务分解为各种子任务,进而缓解指导信号的稀疏性问题。但是,对于使用这种分层强化学习,会导致生成对抗网络在训练上遇到许多困难,以及生成长文本缺乏多样性。2019年,文献[15]提出了一种叫作RelGAN(relational generative adversarial networks)的网络模型。该模型不仅解决了上述两个问题,并且对初始化参数和超参数也加以优化。其主要思想是利用relational memory,使生成器具有更强表达能力和在长文本上更好的模型能力。利用gumbel-softmax relaxation模型训练生成对抗网络,代替强化学习启发式算法。在判别器上利用多层词向量表示,使得生成器往更具多样性方向更新。
浅层CNN不具备捕获长距离依赖关系和区分位置信息的能力,Transformer虽然可以弥补其缺点,但是计算量大,并行速度慢。本文在文献[11]的基础上对LeakGAN 模型引入多头自注意力机制,并命名为SALGAN(self-attention leak generative adversarial networks)模型,将多头自注意力机制融入CNN 模型获取原始文本的全局语义信息,从而提高CNN 模型的长距离捕获能力。在生成器中使用GRU模型编码训练,使得参数减少,加快训练速度。
本文工作的主要贡献:
(1)引入多头自注意力机制与CNN模型相结合,增强CNN 模型的长距离特征提取能力,multi-head的数量越多,长距离特征捕获能力越强,相比传统CNN更快达到拟合。
(2)在生成器部分引入GRU替换掉LSTM,利用其参数少、训练速度快的优点,降低了计算量,提高了生成文本的质量。
1 生成对抗网络SALGAN模型
1.1 生成对抗网络模型
生成对抗网络其实就是一个极大极小的博弈,主要由判别器和生成器构成,如图1所示。在博弈的过程中,生成器生成的数据尽可能地欺骗判别器,判别器无法分辨生成的数据就是真实数据,判别器的作用就是区分哪些是真实数据,通过反复多次这样的交替训练,判别器和生成器两个模型不断增强,直到判别器判断生成的数据就是真实数据并且生成器生成的数据与真实数据十分相似,也就能得到完美的生成效果。换句话说,就是极大化判别器的判断能力,极小化生成器的被识破的概率,因此有以下公式:
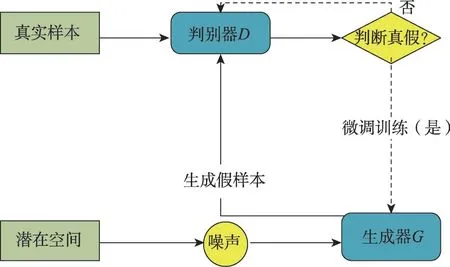
图1 生成对抗网络Fig. 1 Generative adversarial networks

判别网络进行次更新,生成网络才会完成一次更新,当判别网络进行更新时,()越大越好,噪声函数()越小越好,因此需要最大化判别模型,而在生成网络更新时则相反,需要最小化生成模型。
1.2 多头自注意力机制
首先介绍自注意力机制(self-attention),自注意力机制计算三个新向量、、,分别由嵌入向量与一个随机初始化的矩阵相乘得到。然后,乘以的转置表示编码一个词,表示对输入的其他部分的关注度。接下来这个关注程度除以一个常数后做softmax 操作,表示其他部分对这个词的相关性程度。最后使用和softmax 得到的值相乘,结果即为self-attention在这个词的值,如下所示:
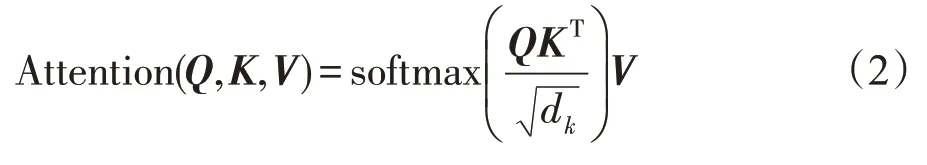
多头自注意力(multi-head self-attention)就是由多个self-attention 组成的,初始化多组、、,然后把这些矩阵降为一个矩阵,再与一个随机初始化的矩阵相乘即可。如下所示:

文献[7]提出一种向量位置编码解决词顺序问题的方法。位置编码的维度和嵌入的维度相同,将位置编码与嵌入的值相加,代替原本嵌入的值传递给下一层。位置向量能表示当前词所在位置。其常用的计算方法有以下三种:
第一种采用正弦位置进行编码,位置编码必须要和词向量的维度相同,位置为偶数时用正弦函数,位置为奇数时用余弦函数:

第二种是相对位置表达,当相对位置超出规定的某个阈值的绝对值时,都用该阈值进行代替,如图2所示。

图2 相对位置表达Fig. 2 Relative position expression
第三种采用学习位置编码。对应每个位置学得独立的向量,方法与生成词向量大致相同。
经过比较,本文采用第三种方法。前馈神经网络提供非线性变换。注意力机制输出的维度由输入的batch_size与句子长度的乘积和判别器中的卷积核层数与卷积核数量的乘积决定。
1.3 SALGAN模型
在文献[11]提出的LeakGAN 模型基础上,构建一种改进SALGAN模型。将多头自注意力机制融入到CNN 模型中,引入位置信息编码,使得CNN 模型对于长距离特征提取能力显著提高,将WORKER模块使用GRU 代替LSTM 进行编码,提高运算速度并改善文本生成质量,SALGAN模型如图3所示。

图3 SALGAN模型Fig. 3 SALGAN model
与传统的GAN 训练框架不同,判别器新增内部状态特征f,其作用是向生成器提供当前生成句子的特征,分层生成器包含一个高层次的MANAGER模块和一个低层次的WORKER 模块,生成器通过MANAGER模块将判别器泄露的信息进行非线性变换,并且利用生成词的提取特征输出一个潜在向量来指导WORKER 模块进行下一个词的生成。给定MANAGER生成的目标嵌入,WORKER首先用GRU编码当前生成的词,然后结合MANAGER 的输出和目标嵌入,并在当前状态下采取最终动作。 s表示当前生成的所有词,作为当前状态,表示随机策略参数化生成网络,(·|s)表示将s映射到整个词汇表的一个分布,x表示下一个词,D表示参数化判别器,f表示判别器在当前状态为生成器提供的特征向量。考虑到当句子变长时,标量引导信号的信息量相对较少,因此允许判别器向生成器提供当前状态下的特征向量f,生成器的分层结构能更好地利用其泄露的信息进行生成。
其对抗文本生成使用D作为学习奖励函数:
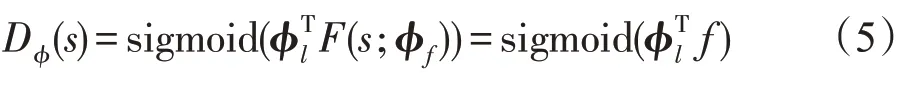
MANAGER 模块是一个LSTM 模块,在每一时间步,输入提取的特征向量f,并输出一个目标向量g,然后将该目标向量g作为WORKER 模块的输入,以指导下一个词的生成。
MANAGER 和WORKER 模块都从全零隐藏状态开始,在每一步中,MANAGER从判别器中接收泄漏的特征向量f,该特征向量进一步与MANAGER的当前隐藏状态相结合产生目标向量g:
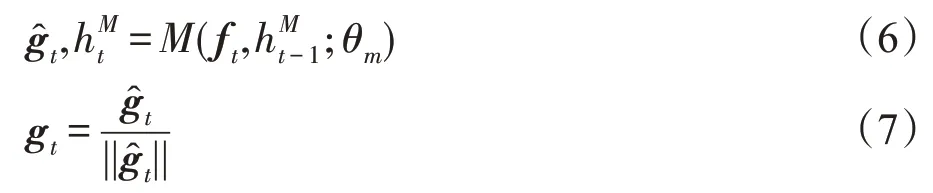
为了整合MANAGER 产生的目标,对最近个目标求和后,结合权重矩阵进行线性变换,以产生维目标嵌入向量w:
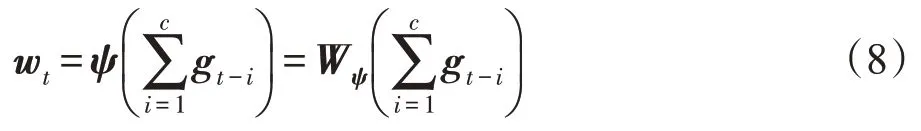
给定目标嵌入向量g,WORKER模块以当前词x作为输入,输出一个矩阵o,再与w通过矩阵乘积相结合,通过一个softmax可以得到:

然后使用策略梯度算法以端到端的方式训练生成器。分别对MANAGER 和WORKER 模块训练,可以使用蒙特卡洛搜索算法进行估算,MANAGER模块的梯度定义为:

同理,WOEKER模块的梯度定义为:

WORKER模块的内在奖励被定义为:

在实践中,需要在对抗训练前对生成器进行预训练。其中MANAGER的预训练梯度为:
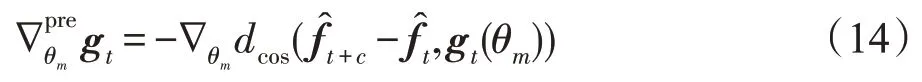
MANAGER被训练成模拟特征空间中真实文本样本的转换,而WORKER 则是通过最大似然估计来训练的。
在训练过程中,生成器和判别器交替训练。在生成器中,MANAGER和WORKER也为交替训练。
2 实验及分析
采用Pytorch深度学习作为框架,在Linux 64位操作系统,Pycharm 2019,CPU为IntelCorei7-7700k@4.20 GHz,内存32 GB,GPU 为11 GB 1080Ti,python 3.7(Anaconda)的环境下进行对比实验分析。
2.1 数据集
为了数据集的统一性和让最终生成结果更具有可对比性,本文使用Image_COCO(1 MB)数据集和EMNLP2017 WMT News(48 MB)数据集,其中数据均已完成分词预处理,并按照文献[15]的标准进行划分:在Image_COCO 数据集中,训练集和测试集分别由10 000 个句子组成,设置样本数量为10 000,单个句子最大长度为37,词汇表大小为4 658。EMNLP-2017 WMT News 数据集包含270 000 个句子的训练集和10 000个句子的测试集,设置样本数量为10 000,单个句子最大长度为51,词汇表大小为5 256。
2.2 实验评价指标
对于合成数据,本文使用两种负对数似然值和对应的,前者用于测试样本多样性,后者用于测试样本质量,负对数似然常用于解决分类问题,也可用于测量两种概率分布之间的相似性,取负是为了让最大似然值和最小损失相对应。定义如下:

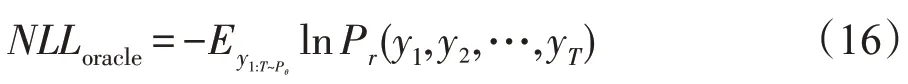
对于真实数据集,为了评估本文模型的精确性和相似度,选择一种广泛使用于文本生成领域且适用于分析生成文本和参考文本中元组出现的程度的评价方法BLEU作为评价指标,定义为:
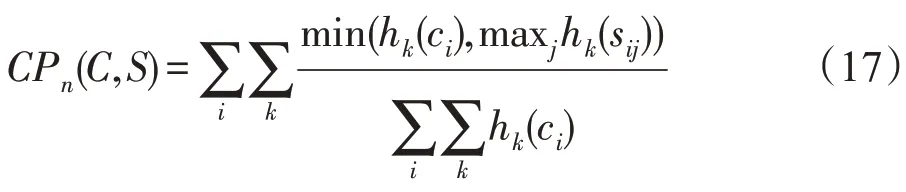
其中,候选译文可以表示为c,而对应的一组参考译文可以表示为s={s,s,…},-gram 表示个单词长度的词组集合,令w表示第组可能的-gram,h(c)表示w在候选译文c中出现的次数,h(s)表示w在参考译文s中出现的次数。
因为普通的CP值计算并不能评价翻译的完整性,但是这个属性对于评价翻译的质量不可或缺,所以研究者们在最后的_值之前加入BP 惩罚因子:

本质上,BLEU 是一个-gram 精度的加权几何平均,按照下式计算:

在本文中,取2,3,4,5,而w一般对所有取常值,即1/。
2.3 对比模型和实验设置
为了验证提出的SALGAN 模型的性能,本文对比了修改前后的传统的泄露生成对抗网络模型LeakGAN和另外两个生成对抗网络模型SeqGAN和RelGAN以及基线模型MLE。
(1)MLE:MLE在生成对抗网络中取得较好结果,是一种采用LSTM训练的简单的生成对抗网络模型。
(2)SeqGAN:Yu等人通过强化学习作为框架,使用策略梯度算法和蒙特卡洛搜索分别对单个词进行考量。
(3)LeakGAN:Guo 等人通过判别器泄露特征信息指导生成器中的两个LSTM对单个词进行生成,从而解决了长文本信息稀疏性的问题。
(4)RelGAN:Narodytska 等人在生成器上使用relational-memory 代替传统的LSTM,同时为了简化模型,使用gumbel-softmax relaxation 进行训练,在多样性和质量上有很大提升。
(5)SALGAN:本文模型,融入多头自注意力机制,改善传统CNN 仅能解决局部文本语义的特征提取能力,随后采用GRU代替LSTM进行编码,减少运算时间。
在COCO IMAGE CAPTIONS 和EMNLP2017 WMT NEWS两个真实数据集上进行实验,这里考虑到SALGAN 模型GPU 占用率和使用设备配置以及运行时间等因素。由于EMNLP2017 WMT NEWS数据集较大,将batch_size 设置为32,COCO IMAGE CAPTIONS 数据集对应的batch_size 设置为64,其他模型batch_size 均设置为64。对于SeqGAN 模型,生成器学习率为0.01,判别器学习率为0.000 1,dropout设置为0.2,MLE 训练epoch 设置为120,对抗训练epoch 设置为200;对于LeakGAN 和SALGAN 模型,生成器学习率设置为0.001 5,判别器学习率为0.000 1,dropout 设置为0.2,MLE训练epoch设置为8,对抗训练epoch设置为200,温度设置为1.0;对于RelGAN模型,生成器学习率设置为0.01,判别器学习率为0.000 1,dropout 设置为0.2,MLE 训练epoch 设置为150,对抗训练epoch设置为3 000,温度设置为100.0。
2.4 实验结果及分析
(1)合成数据
分别对长度为20 和40 的合成数据进行对比实验,作为表1 中SALGAN 模型与其他模型的对比实验结果,其中基线模型是MLE。

表1 合成数据实验结果Table 1 Experimental results of synthetic data
从表1中可以得出,SALGAN模型在该实验中表现出的性能优于其他对比模型。随着文本长度的增加,SALGAN 模型的性能也是最好的。由于GRU 参数量少,WORKER模块采用GRU解决了在保留长期序列信息下减少梯度消失问题,运行速度加快。GRU只使用两个门控开关,减少了过拟合的风险,效果与LSTM 接近,当引入GRU 后效果提升显著。结果证明该方法的有效性是基于GRU 的改进,该方法可适用于生成短文本以及中长度文本。
(2)COCO IMAGE CAPTIONS数据集
为了验证SALGAN 模型在中长度文本中的性能,在COCO IMAGE CAPTIONS数据集上进行对比实验,实验结果如表2 所示。根据结果可以得出:本文的SALGAN 模型相比LeakGAN 模型性能有较大提升,RelGAN模型在该数据集上生成的文本效果要优于LeakGAN 模型,SALGAN 模型在相同环境上对比RelGAN 模型的评价指标(BLEU-2,3,4,5)分别提升了1.6%、4.9%、4.4%、6.9%。
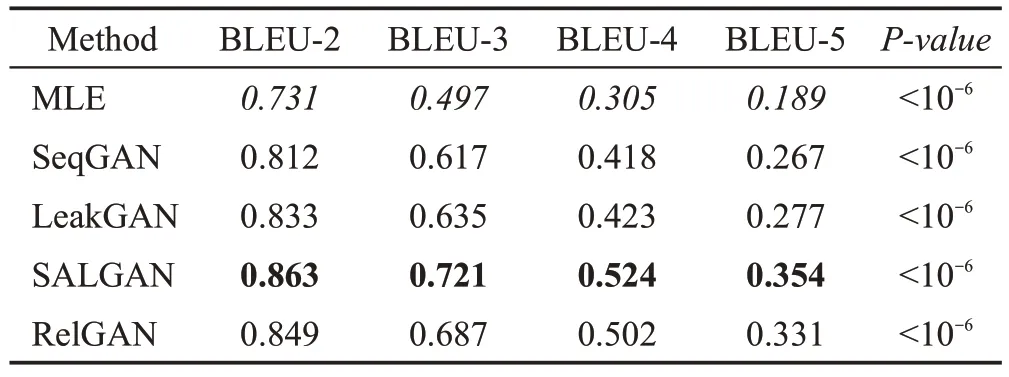
表2 COCO IMAGE CAPTIONS数据集实验结果Table 2 Experimental results of COCO IMAGE CAPTIONS dataset
因为在小型英文数据集中,LeakGAN 模型使用LSTM 对单个词进行编码参数量较大,花费时间过长,采用参数量减少的GRU代替LSTM,在一定程度上减少了过拟合的风险。由于传统CNN是通过堆积深度捕获长距离特征,当卷积核的大小和深度增加,可以获得更大的长度覆盖,而对于本文的SALGAN模型,引入多头自注意力机制提高CNN 模型的长距离捕获能力,影响其主要因素是multi-head 的数量。在资源有限的环境下,经调整超参数后,SALGAN模型的特征提取能力增强。因此证明,SALGAN 模型中的CNN与自注意力机制相结合的方式能极大提高长距离特征提取能力,传递更完整的特征信息指导文本生成,提高文本生成质量。又由于生成对抗网络训练速度比较缓慢,GRU相比LSTM参数量小,可以在一定程度上加快训练速度。
(3)EMNLP2017 WMT NEWS数据集
为了验证SALGAN 模型生成长文本的性能,在EMNLP2017 WMT NEWS 数据集上进行对比实验,实验结果如表3所示。实验结果表明:相比LeakGAN模型,SALGAN模型的评价指标在BLEU-2和BLEU-3 上提升了6.1%和1.4%。RelGAN 模型性能优于LeakGAN 模型,而本文的SALGAN 模型在BLEU-2上对比RelGAN模型提升了1.0%。

表3 EMNLP2017 WMT NEWS数据集实验结果Table 3 Experimental results of EMNLP2017 WMT NEWS dataset
可以得出结论,在长文本英文数据集中,随着序列变长,数据复杂度变大,由于GRU 参数较少,导致其编码效果不如LSTM,又由于CNN 捕获长距离特征的能力与卷积核的大小和深度有关,本文模型中的CNN 与自注意力相结合增强特征信息的提取能力,使其包含文本的全局语义信息。当数据量非常大时,达到拟合的速度比传统CNN 快且生成的文本有较好的相关性,因此本文模型融入自注意力机制后的长距离特征捕获能力和语义特征提取能力比传统CNN模型提升更为明显。而通过对比本文模型和RelGAN 模型可以得知,当处理较长文本时,采用LSTM编码效果比GRU更优。
(4)生成样本示例
考虑仅通过BLEU 作为评价指标评估模型生成文本质量的好坏具有一定的片面性,因此也可以观察每个模型生成的样本,较主观地评价生成样本的流畅程度以及语法逻辑问题。
为了更好地验证并评估生成文本的质量,在线下邀请20个人完成问卷调查填写。为了实验的公平性,每个问卷包含由SeqGAN、LeakGAN、RelGAN 和本文的SALGAN模型分别随机生成的10个句子,要求参与人员判断生成句子的真实性,即主观判断该句子是否由机器生成。如果认为该句子是真实的则得分加一,反之不得分。最终计算每个模型的平均得分,得分越高表示生成效果越真实,质量越好。最终的问卷调查结果如图4所示。根据图中数据显示:本文的SALGAN模型生成的句子相比于其他模型来说具有更好的可读性和全局一致性。每个模型分别在COCO IMAGE CAPTIONS 与EMNLP2017 WMT NEWS 两个真实数据集上生成的部分样本如表4所示。

表4 真实数据集生成样本示例Table 4 Examples of samples generated from real datasets

图4 图灵测试结果Fig. 4 Results of Turing test
3 结束语
针对传统生成对抗网络存在生成长文本时判别器指导信号稀疏的问题和学习文本局部语义信息的限制,本文提出一种融入自注意力机制的长文本生成对抗网络模型。考虑到分层生成器效果十分缓慢,MANAGER 模块仍采用LSTM 编码特征向量效果更好,WORKER 模块使用结构简单的GRU 编码,可以适当减少计算量,提高运算效率的同时还能提高文本生成质量。此外,对比了另外三种深度学习模型SeqGAN 和RelGAN 以及原模型LeakGAN,实验结果显示,SALGAN 模型在上述两个真实数据集上均表现出较好的结果,证明采用本文模型提取文本信息的上下文语义关系和关键信息能一定程度上提高文本生成的质量,并且GRU 的代替在小数据集上不仅没有因为缺少运算导致评价指标降低,还减少了运行时间,并且在合成数据中提高了生成样本的质量。
尽管SALGAN模型的评测指标有一定的提高,但由于生成器部分采用的WORKER模块和MANAGER模块均对单个词进行处理,导致实验效率低下,并且占用GPU资源量大,而且GRU在大数据集中表现不佳。因此接下来的工作可尝试将本文思想应用于中文数据集,从中文分词等角度改善运算效率。考虑到生成器难以控制的问题,还可以尝试在生成模型和判别模型上为数据添加标签,减少关键信息的缺失,进一步地提高提取特征向量的能力。
