面向OpenVX核心图像处理函数的并行架构设计
2022-07-21潘风蕊邢立冬张好聪吴冠中
潘风蕊,李 涛,邢立冬,张好聪,吴冠中
1.西安邮电大学 电子工程学院,西安710121
2.西安邮电大学 计算机学院,西安710121
近年来,计算机视觉(computer vision,CV)在深度学习领域的应用迅速发展,图像处理作为CV中比较活跃的一个分支,广泛应用在医疗卫生、安检刑侦、图像检索与分析、增强现实等领域中。而CV领域更新变化飞快,这就要求图像处理具有很高的灵活性、实时性和精确性。传统的硬件很难满足可编程性、高性能和低功耗的要求。可编程技术的出现使得硬件变得可“编译”,能在嵌入式系统上完成多种多样的新任务。并行计算方式的出现使得硬件介质可以提供更加强大的计算能力和密度,大幅提高了芯片系统的总体性能,实现片上超级计算。业界典型的两种并行可编程模型分布式共享内存MPI(multi-point interface)和集中式共享内存OpenMP,与当前GPU 多核、众核架构相比,形式过于单一。可编程的专用指令集处理器可以兼顾功耗、性能和灵活性,一种专为图形图像处理而设计的新型多态阵列处理器应运而生,其不但处理性能在一定程度上接近于ASIC(application specific integrated circuit),而且具有灵活的可编程性,它能够将线程并行、数据并行、指令并行和操作并行融合到一个单一的阵列结构中。对于图像计算,ASIP(application specific instruction processor)是一种可行的硬件设计方法,基于ASIP 体系结构,本文提出了一种面向计算机视觉底层任务加速的可编程并行处理器。
首先,本文研究了各种拓扑特性对互联网络传输性能的影响,分析了一类基础网络的拓扑特性,选择了一种更加灵活的新型网络结构——层次交叉互联网络(hierarchically cross-connected mesh+,HCCM+),可以根据不同应用的网络流量重新配置为Mesh、HCCM 或HCCM-网络,降低整个系统的功耗。其次,以HCCM+的网络拓扑结构为基础,设计实现了一种可编程的OpenVX并行处理器,使用有限的硬件资源,以可编程的方式对OpenVX 1.3 标准中核心函数进行映射,实现通用的图像处理。
1 OpenVX的介绍
2019年Khronos发布的OpenVX 1.3标准中,核心图像处理函数包括了基本像素点处理、全局处理、局部处理、特征提取四大类。OpenVX 标准是按照新兴的图计算方式指定的,其基本加速原理是根据需求有目的性地对图像矩阵进行一定的操作。如图1 所示,OpenVX基本图像处理核函数可以看作整个处理流程中的一个节点(node)。对于图像处理流程往往是数据从源Node 流向目标Node,Node 与Node 之间形成一定的有向无环图(graph)。开发者可以根据需要将这些基本的Node连成Graph,完成对图像的操作。
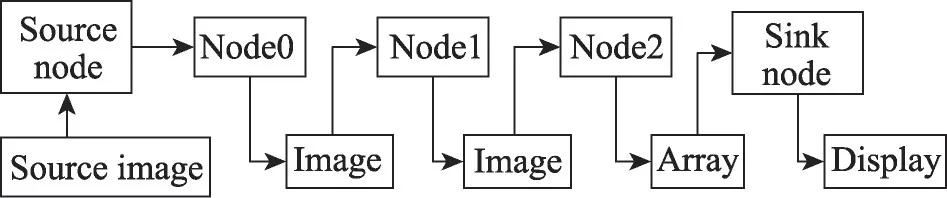
图1 OpenVX图计算模型Fig. 1 OpenVX graph calculation model
OpenVX 作为计算机视觉一个标准化的功能框架,接口统一规范,具有良好的移植性,可以直接被应用程序使用;也可以作为高级视觉的加速层、框架、引擎或平台API,被诸多芯片企业(如NVIDIA、AMD、Intel)采用,具有广泛的应用前景。但专门为OpenVX 实现的硬件芯片十分匮乏。本文的工作属于比较早涉及此标准的硬件设计之一,所提出的架构适合图计算和数据并行计算,实现可编程的加速处理,最大限度地提高硬件功能和性能的可移植性。
2 OpenVX并行处理器的整体架构
OpenVX 并行处理器是利用有限的硬件资源实现OpenVX核心函数,图像处理往往是密集且重复的操作,因此除了高速计算之外,提高硬件的通用性,尽可能地使资源共享、降低功耗也成为并行处理器设计的目的。
2.1 互联网络复杂性分析
互连网络是并行处理系统的重要组成部分,对于数据信息传递的并行计算,互连网络对系统的整体性能尤为重要,是本文所提出的OpenVX并行处理器的主干。由于简单的拓扑结构易于在超大规模集成电路(very large scale integration,VLSI)中实现和分析,互连网络宜采用简单的拓扑结构,拓扑特性包括:
(1)边数(edge number):网络链路数,影响互联网络的容量及灵活性。
(2)直径(diameter):任意两个节点之间的最短路径中的路径长度。直径与通信时间成正比,直径越长,所需通信时间越长。
(3)对分宽度(bisection bandwidth):网络被分成节点数相等的两部分,切口处最小边数为对分宽度,该参数主要反映了整个网络的最大流量。
互联网络的设计要兼顾上述3种拓扑特性,使得整体结构的性能在一定程度上有所提高。最基本的拓扑结构是Mesh型、XMesh型,本文在基本结构的基础上,选择了HCCM结构,并对HCCM进行扩展得到HCCM-、HCCM+两种拓扑结构,如图2所示。
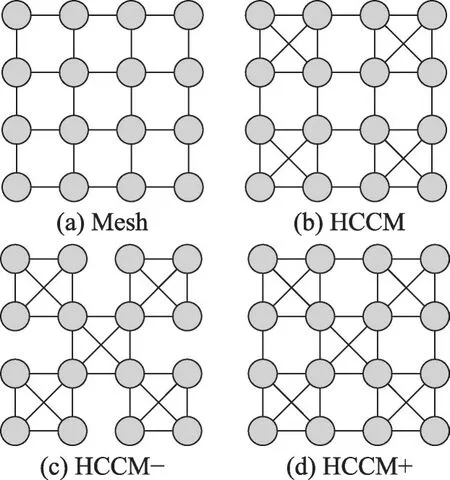
图2 互连网络拓扑结构Fig. 2 Interconnection network topology
根据递归特性、循环和边界条件,推导计算出4种结构的拓扑特性公式,如表1所示。

表1 互联网络拓扑性能比较Table 1 Comparison of network topology performance
通过对比四种结构的拓扑特性,HCCM+的直径小于Mesh 和HCCM,且比Mesh、HCCM 和HCCM-具有更宽的对分宽度。在理论上它可以比其他结构承载更大的传输量,性能优于其他结构。因此本文采用HCCM+作为并行处理器的基础网络。
2.2 并行架构设计
OpenVX 并行处理器采用了性能较为突出的HCCM+网络,包含了4×4 个处理单元(processing element,PE)、路由(RU)及全局控制(global control),整体结构如图3所示。在开始计算前,全局控制器接收微控制器(micro control unit,MCU)发送的微指令,根据指令中的PE标识号(ID),将配置及数据信息经配置开关模块(cfg&switch)下发至相应的PE 中。PE 执行任务时以微指令信息为单位,可以循环执行微指令携带的操作信息,中间结果可暂存到PE 内部缓存中,由RU控制选通PE之间的数据链路,完成数据的传输。MCU 下发的微指令可实现多个PE 的任务切换,实现整体可配置。
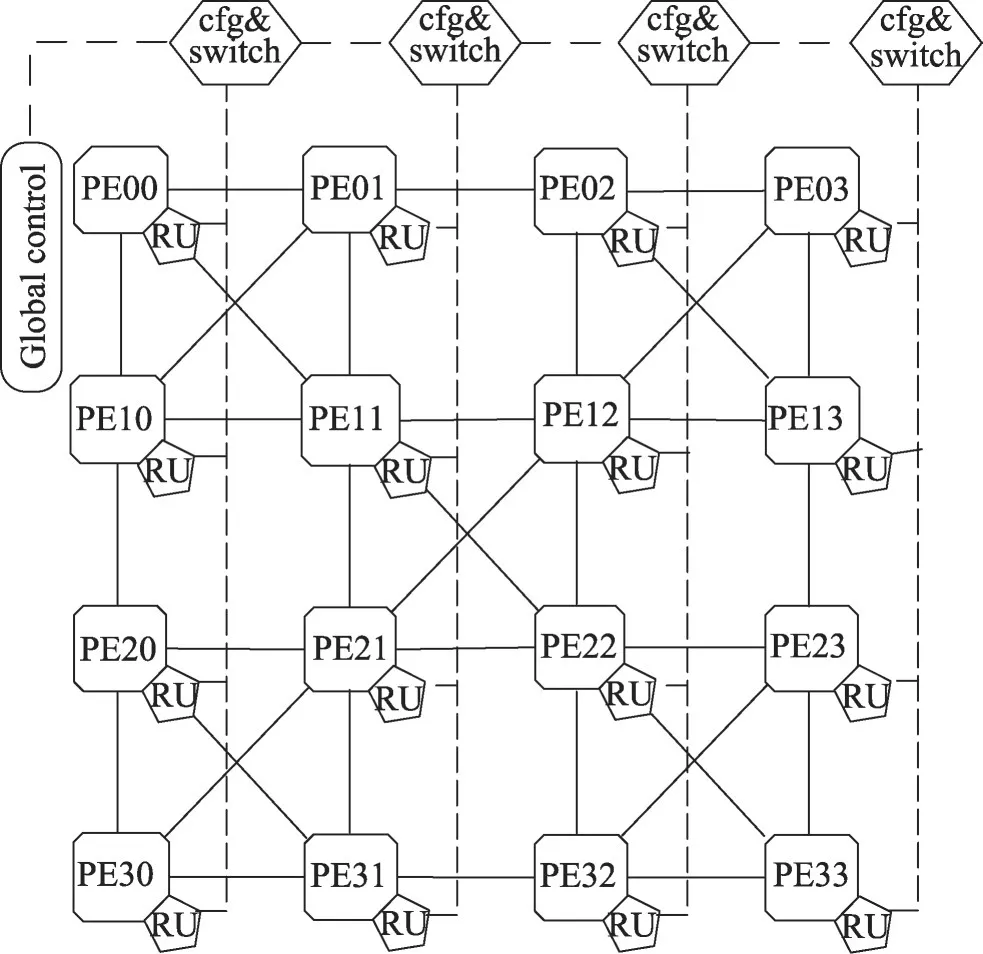
图3 OpenVX并行处理器整体架构Fig. 3 OpenVX parallel processor architecture
每个PE 中包含了8 个ALU、2 个定点乘法器(MUL)、2 个浮点乘法器(FMUL)、1 个定点除法器(DIV)、1 个浮点除法器(FDIV)、1 个内部交叉开关(Crossbar)、5 个32×16 的寄存器堆(regfile)以及寄存器堆的访存模块(RD_CTRL,LOAD_PIXEL),整体结构如图4所示。

图4 PE整体结构Fig. 4 PE architecture
(1)ALU负责执行add、sub、and、or、xor、sll、srl等指令。当ALU 执行add 指令时,a 输入端和b 输入端有三个数据源:①指定寄存器堆内的数据;②译码单元的立即数;③计算单元的输出数据。Crossbar从三个数据源中选择一个送至ALU 的输入端,输出结果由分配器派遣至下一个指定的PE,进行新的处理。其中第三个数据源的选择,是为了处理比较复杂的函数如Canny边缘检测、Harris角点检测等,中间结果写回,进行新的配置,继续计算至最终结果的输出。
(2)PE 内部的Crossbar 设计为60×32 的开关矩阵(switch matrix)、60个输入、32个输出。通过配置译码模块(configer decode)将选通信号发送给分配器和选择器,ALU输入操作数可以有选择性地连接寄存器堆或ALU 的计算结果。如图5 所示,以ALU0 为例,ALU0 的两个操作数是多路选择器的输出,ALU0 计算结果(Mid_out)通过分配器输出。输入、输出数据流向选择取决于译码模块的配置指令。将多个计算单元的输入、输出数据通路进行互联,组成开关矩阵。
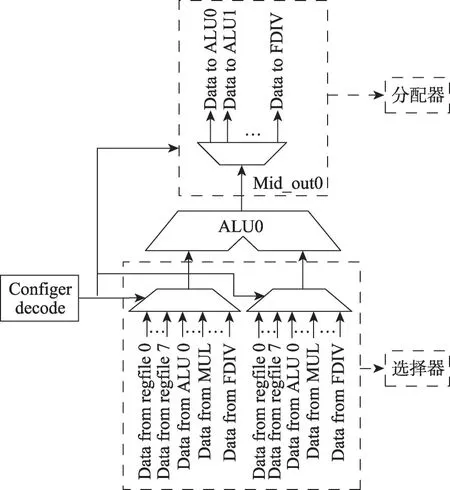
图5 ALU0 I/O数据通路Fig. 5 ALU0 I/O data path
(3)寄存器堆访存模块包括了RD_CTRL 和LOAD_PIXEL。RD_CTRL通过AXI总线访问DDR,采用突发读写的模式,将像素数据加载至寄存器堆中,减少了对DDR 访问次数。LOAD_PIXEL 访问寄存器堆,将像素数据加载至Crossbar 的数据端口,对于像素点操作和模板类操作的函数,由译码模块发送的操作类型信号(operation_type)配置不同的加载方式。当LOAD_PIXEL模块访问至寄存器堆的中间或最大地址时,会向RD_CTRL 发送Half_empty 信号,RD_CTRL 继续访问DDR,形成一个动态加载和动态取数的过程。
全局控制(global control)负责控制各个模块之间以及模块内部的数据交互、数据流向及数据选择。图6是对一个PE进行控制的电路设计。

图6 全局控制电路Fig. 6 Global control circuit
MCU 负责发送Node 类型,开始进行图像处理。RD_INST 向INST_MEM 发送请求,读取微指令。派遣模块(dispatch)负责将微指令派遣至相应PE 的译码单元(decode)进行解析。译码单元将地址信息(address)发送至寄存器堆(regfile)的地址端,将配置信息(cfg_inst)顺序写入到开关矩阵(switch matrix)的配置寄存器(Cfg_inst)中,进行数据通路的选择,像素数据流向对应的ALU进行计算。ALU的输出可作为中间结果(Mid_results)返回,也可经RU 直接输出至下一个PE对应的缓存中。
PE 之间数据路由受全局控制模块控制,本文路由以XY 路由为基础,并对其进行了一定的改进,增加了新的判断状态,在数据从当前节点流向目标节点的过程中增加一条对角边。路由结构如图7 所示,上一级各个方向PE 的输出Edout、Sdout、Wdout、Ndout、ESdout、WNdout 输入至相应的缓存E_buf、S_buf、W_buf、N_buf、ES_buf、WN_buf。Arbiter 模块采用先来先到的仲裁机制决定数据的传输顺序。RU模块根据规定的传输方向优先级决定数据流向,数据经全互联交叉开关输入至目的PE。
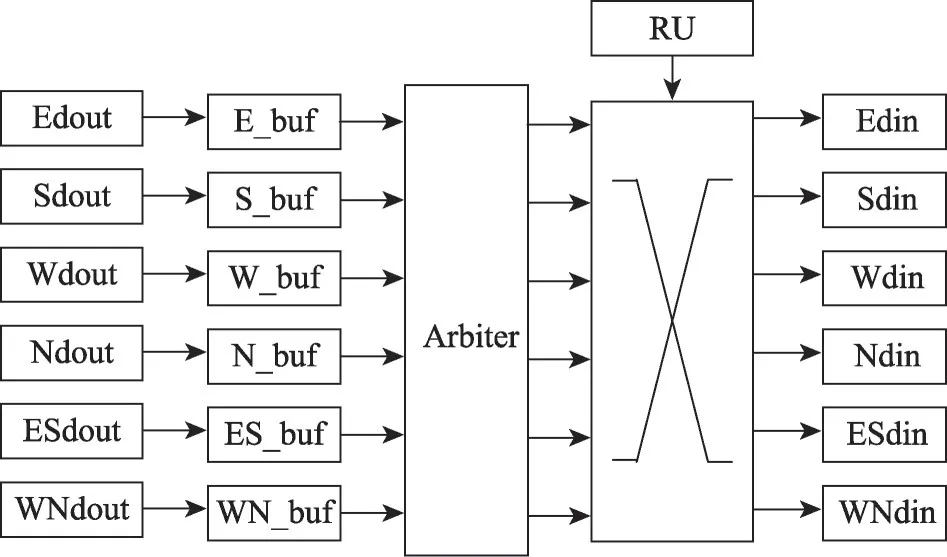
图7 路由结构Fig. 7 Route structure
RU 模块支持一对一单目标传输,其中对角快速通道优先级最高,其次为水平方向的数据通路,最后为竖直方向;RU 也支持一对多目标的数据扇出,此时目标与目标之间优先级相同,对于某一目标通道优先级与一对一单目标传输时优先级相同。译码模块将路由配置信息写入PE 内部路由选择寄存器中,选通本地PE到目标PE的通信路径,将计算结果发送至目标PE,执行新任务。
PE之间主要数据通路如图8所示,假设当前节点为PE00,目标节点为PE32,则数据流向为:PE00→ES_dout→PE11→ES_dout→PE22→S_dout→PE32。

图8 PE之间数据路由Fig. 8 Data routing between PEs
2.3 整体架构的优化
高性能OpenVX并行处理器共有五种指令类型:定点运算、浮点运算、逻辑运算、加载/存储、特殊指令(控制、存取及停止)。以定点运算为例,常规的指令格式为:
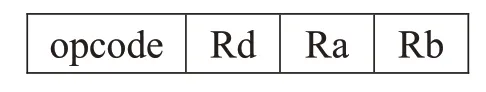
本文指令格式为:

其中,Rd为目的寄存器,提供计算结果地址;Ra为源寄存器,提供源操作数A 地址;Rb 为源寄存器,提供源操作数B地址。opcode为操作类型,相比于传统的指令,本文每条指令中有4 个opcode,一次可控制多个操作,使得更多运算单元能够同时工作,增大了操作的并行度,提高了像素的吞吐率。
为了减少数据通路,ALU中将加法和移位合并,同时包含了与、或、非以及异或等布尔运算。例如局部图像处理,模板总是固定的常系数,目标中心像素由常系数与窗口内的像素进行乘加得到。而OpenVX并行处理器中只需要配置ALU执行ADD操作即可,耗费一个时钟周期就可完成4组像素的乘加操作。
同时在用汇编指令实现核心函数时,可以合理地、自由地调整配置指令的顺序,尽量避免相邻指令间数据传递依赖性,减小整个程序的执行时间。
传统运算单元中只有一个ALU,合理地增加PE中ALU数目,可以减少流水停滞时间,增大像素吞吐率,计算速度快。
为减少PE通过AXI总线访问DDR的次数,在PE内部设置了5个深度为16,宽度为32 bit寄存器堆,用于快速存取原像素数据及中间计算结果。PE之间传递数据直接通过访问邻接共享存储,实现数据的传递复用,只有最后一个PE 的计算结果才写回DDR,用于最终的显示。
本文所采用的HCCM+中,嵌入了Mesh、HCCM和HCCM-,可以根据不同应用的网络流量重新配置为Mesh 型、HCCM 型或HCCM-型结构。对于流量较大的应用,可以使用HCCM+所有边缘。对于中等级别的流量,可以关闭一些边缘以形成HCCM网络,这有助于节省功耗。对于大多数短距离轻型通信,可以关闭更多的边缘来形成HCCM-网络,进一步降低功耗且更加灵活。
为了适应系统网络结构,本文路由在XY路由算法的基础上,增加了对角传输路径。这种改进不仅为数据到达目标节点提供了最佳传输路径,而且增大了单节点的数据扇出,可以适应复杂度更高的Graph,使更多的PE 可以交互,延长PE 数据传输链路,提高PE单元的复用率。同时路由中采用结构简单的全互联交叉开关,传输延迟低,速度快,可实现数据并行传输。
3 Graph映射
并行处理器的流处理类似于FPGA(field programmable gate array)或ASIC 的流水线,每个运算单元处理的颗粒粗细程度由MCU进行配置调整,宏观上实现流水处理。
3.1 数据并行计算模式
数据并行计算模式是对图像分块处理,将图像分配至不同的处理单元,配置相同的指令,对不同的图像数据进行相同的操作,实现数据级并行操作。针对该模式,选取基本的核心函数在并行处理器上进行映射,多个处理单元同时执行同一种操作。如图9 所示,将Sobel 函数在并行处理器上以数据并行处理的模式进行映射。图10为数据并行处理模式下图像分块方式,PE 调度的个数与图像分块的个数相关。在每个PE内部,针对核心函数的算法,对基本算数逻辑操作流水细分,按需分配,微观上实现细粒度并行运算。
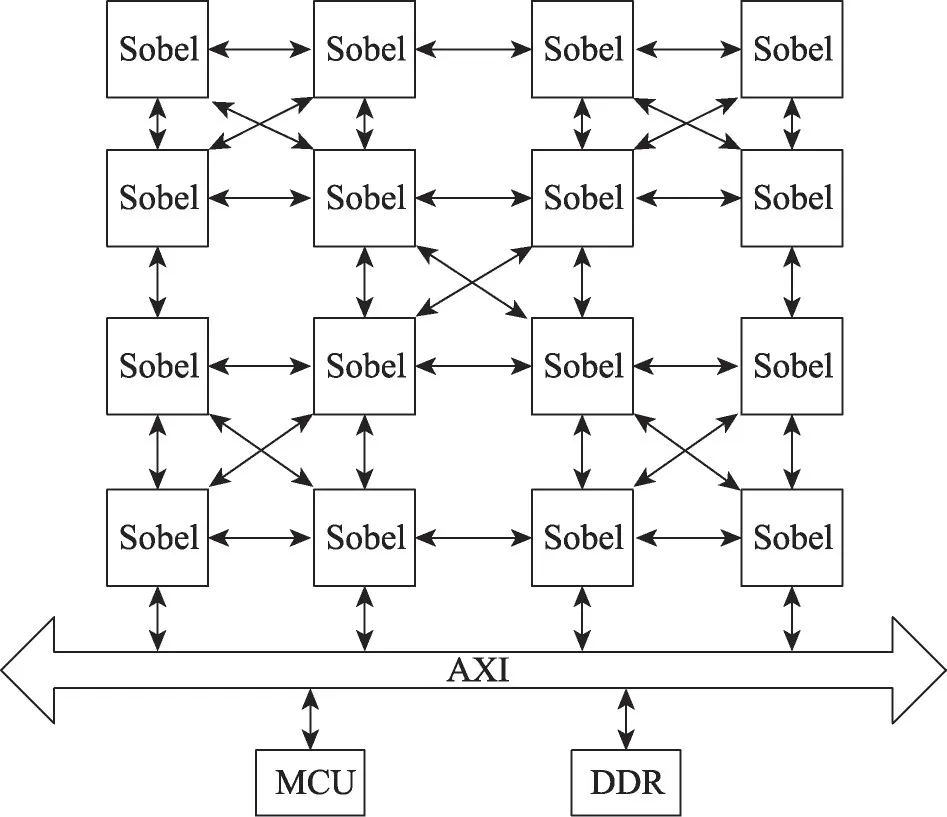
图9 数据并行计算模式映射Fig. 9 Data parallel computing pattern mapping
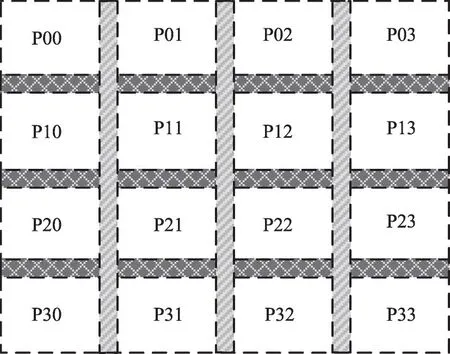
图10 数据并行计算模式下图像分块Fig. 10 Image segmentation in data parallel computing mode
3.2 流水线处理
流水线处理是将复杂的程序分解为数个简单的操作,分配到不同的处理单元上,处理单元之间可通过相邻的数据通路进行数据传递,整体实现流水处理。相邻处理单元之间指令独立,使本结构非常适合流水线处理的运行方式。针对该模式,选取均值滤波(box filter)、通道合并(channel combine)、色系转换(color convert)、图像膨胀(image dilate)和图像腐蚀(image erode),构造形态学滤波的Graph计算模型,执行流程如图11 所示。每个基本函数为一个Node,将该执行流程映射到并行处理器上,由于通道合并和通道提取比较简单,将其与均值滤波合并到一起,在结构映射中并未体现,映射结果如图12所示。
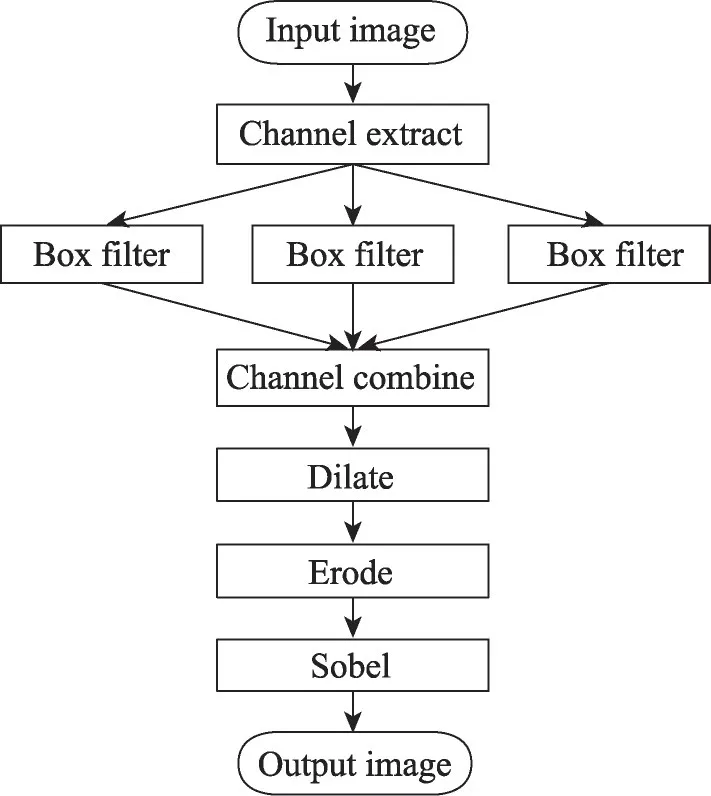
图11 形态学滤波执行流程Fig. 11 Morphological filtering execution flow

图12 流水线处理模式映射Fig. 12 Pipeline processing pattern mapping
如图13 所示是形态学滤波数据分块分配方式,将图像数据分成四块,其中阴影部分为图像分块后的边界。常见的边界处理方法是边界复制和边界填零。MCU 控制加载图像像素数据时,发送两次边缘像素的读取指令,实现对边界像素进行复制。第一块图像数据经过P00、P01、P02、P03 所构成的运算单元链(流水线)分任务进行处理。实际上,形态学滤波是由多流水线并行处理实现的,执行不同任务的PE实现流水线处理,执行同一任务的PE实现数据并行处理,宏观上实现粗粒度并行运算。

图13 形态学滤波数据分块Fig. 13 Morphological filtering data segmentation
4 测试验证及结果分析
4.1 验证平台
对图像处理硬件系统设计一个完整稳定的验证系统也是至关重要的,本设计基于VS2015的MFC仿真测试平台,如图14 所示。VS 平台和FPGA 平台共享输入源图像数据,经过相同的算法,将最终图像处理的结果打印至文本中。可以直接打开文本查看结果,也可以对软件算法处理结果与FPGA的处理结果进行逐像素对比验证,并输出两者的比对结果。
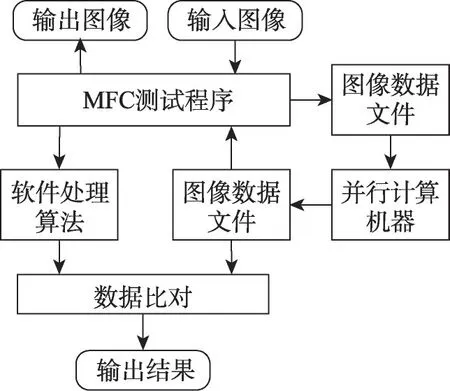
图14 仿真测试平台Fig. 14 Simulation test platform
4.2 实验结果分析
除了要关注图像处理的正确性外,还要考虑并行处理器的性能,性能可以通过阿姆达尔定律模型展开分析,用加速比来衡量并行处理的效果,式(1)在高度理想情况下等号成立,因此加速比往往是小于处理器的个数。
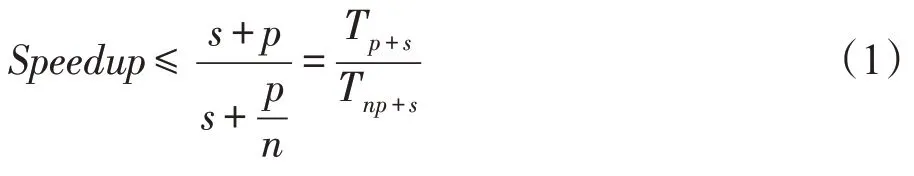
式中,为串行处理部分,为可并行处理部分。在数据并行计算模式下,为正在处理的像素数据个数,即图像分块的个数。在流水线处理模式下,为执行不同指令的处理器个数,同时也是Graph计算模型流水线的阶段个数。
在数据并行计算模式下,从OpenVX视觉函数库中四类函数(Ⅰ基本像素点处理函数、Ⅱ全局处理函数、Ⅲ局部处理函数、Ⅳ特征提取函数)中选取部分典型函数进行映射。用Modelsim 仿真工具进行仿真,调用不同数目PE 对分辨率为640×480 像素的图像进行处理,对每个函数的处理时间进行了统计。如表2 所示,对图像处理时间为,结合阿达姆定律计算了相应的加速比。经统计分析后,对同一函数,调用更多数目PE 的情况下,图像处理时间骤减,所对应的加速比成线性增长。但对于不同类别的函数加速效果存在一定的差异,Ⅱ、Ⅳ类函数的加速比略低于Ⅰ、Ⅲ类函数。

表2 基本核心函数加速比对比Table 2 Comparison of speedups of basic kernel functions
为进一步分析每类函数加速比存在差异的影响因素,在每一类中选取一个具有代表性的函数,分别对处理过程串并比例进行统计。如图15 所示,分别为通道提取、直方图、Sobel、高斯金字塔中串行并行比重统计,表示串行处理部分,表示并行处理部分。对于Ⅰ类函数,串行处理时间主要为预加载像素的时间;Ⅲ类函数相较于Ⅰ类,串行处理额外地增加了读取窗口内多个像素及多像素之间相关性操作时间。Ⅱ类函数串行处理时间主要来自遍历整幅图像、统计或累加预处理的时间,串行预处理完后才开始进行并行处理。Ⅳ类函数,复杂度明显高于其他三类,存在中间结果写回,导致流水细分程度略低于其他三类函数。

图15 不同函数串并比处理权重对比Fig. 15 Weight comparison of different functions serial parallelism ratio
在调用不同数目PE 下,四个代表函数处理时间对比如图16 所示,由于每类函数的可并行处理部分所占的比重不同,处理时间存在较大的差异,可并行处理度越高的函数,实现所用时间越短。
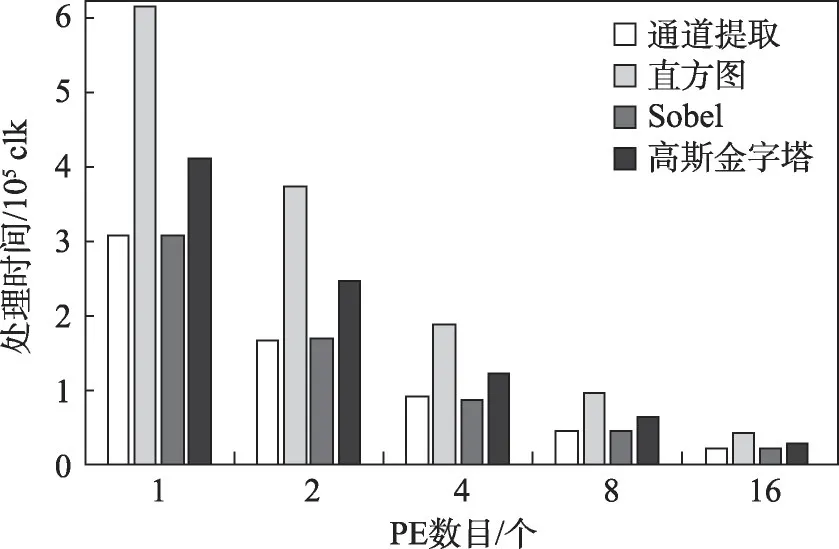
图16 不同函数处理时间对比Fig. 16 Comparison of processing time of different functions
在流水线处理模式下,将形态学滤波Graph执行模型映射到本结构上,启用多个流水线进行同一Graph 的运算。本文将PE 阵列分为4 个流水线进行加速比的计算。如果需要增加线程数,则需要将Graph 计算模型中的操作重新划分,增加每个PE 的任务负载,在总任务不变的情况下,对空闲的PE重新分配任务。或是将本并行处理器作为基本簇,以此扩展,实现多簇并行执行任务,进一步提高整体的并行性。如图17所示是原图与本文硬件处理后结果图的对比,其中(a)是源图像,(b)是膨胀腐蚀后的开操作结果,(c)是Sobel边缘检测结果图,(d)是软硬件处理结果比对图,验证了硬件电路功能的正确性。
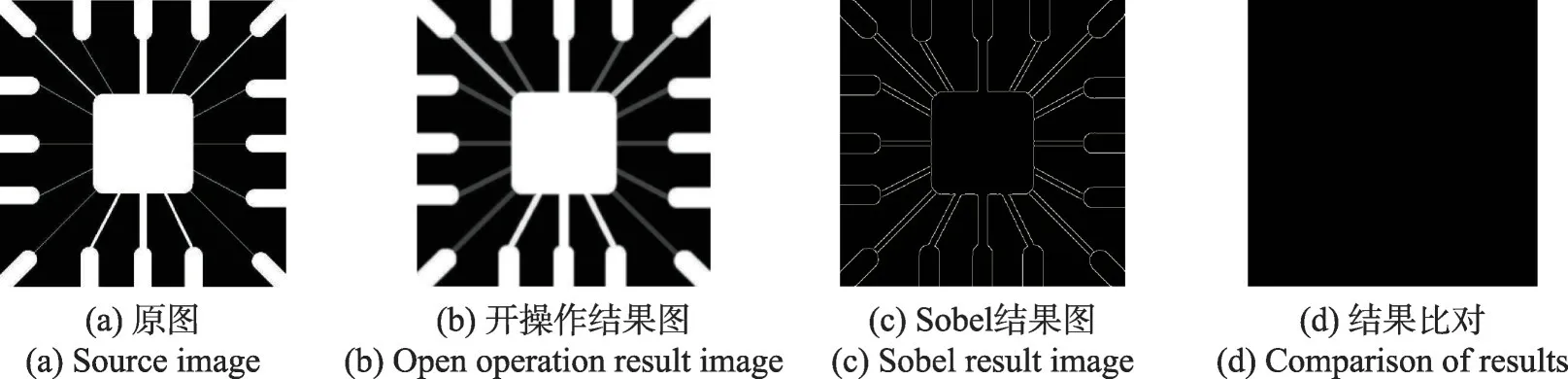
图17 图像处理前后对比Fig. 17 Contrast before and after image processing
图18 为Graph 单流水线处理图,是加载PE内部寄存器堆时间(预处理),为加载PE间缓存时间,图像数据从Graph中的第一个节点流向最后一个节点并输出,整体流水实现耗时为313 045 clk,相比逐函数串行处理(=1 843 860 clk)速度提升了4.89倍。

图18 Graph单流水线处理Fig. 18 Graph pipeline processing
启用不同数目的流水线对同一Graph进行处理,测试结果如表3所示,根据阿达姆定律计算了相应的加速比,如图19 所示。当执行流水线数增加时,Graph的处理加速比成线性增长。

表3 不同数目流水线处理时间Table 3 Processing time of different number of pipelines
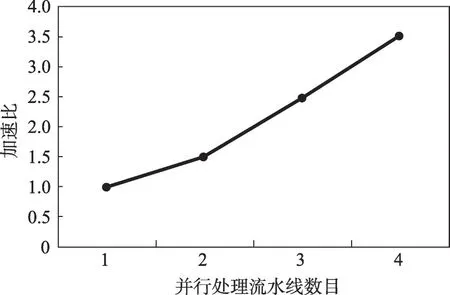
图19 Graph计算模型加速比Fig. 19 Graph execution model acceleration ratio
4.3 性能分析
文献[4,8]针对OpenVX 1.0 标准中的核心库函数,提出了基于Mesh 型结构的阵列处理器。通过改变源节点的数据注入率,对本文系统与文献[4,8]系统的平均延时和吞吐量进行了统计分析。测试中每个节点作为源节点注入数据的概率是相同的,通过一定约束,对目标节点的选择符合随机均匀分布。如图20 所示,平均延时均随着数据注入率的增大而增大,由于HCCM+相比于Mesh 型网络多了对角快速传输通道,本文平均延时整体小于Mesh型系统。

图20 平均延时对比Fig. 20 Average delay comparison
如图21所示,随着数据注入率的增大,网络负载增大,吞吐量也随之增大。当数据注入量增大到一定程度时,网络负载达到饱和,吞吐量处于稳定状态。由于本文系统中网络的对分宽度大于文献[4,8],本文系统的吞吐量整体上更大,可以承载更大的数据流量。
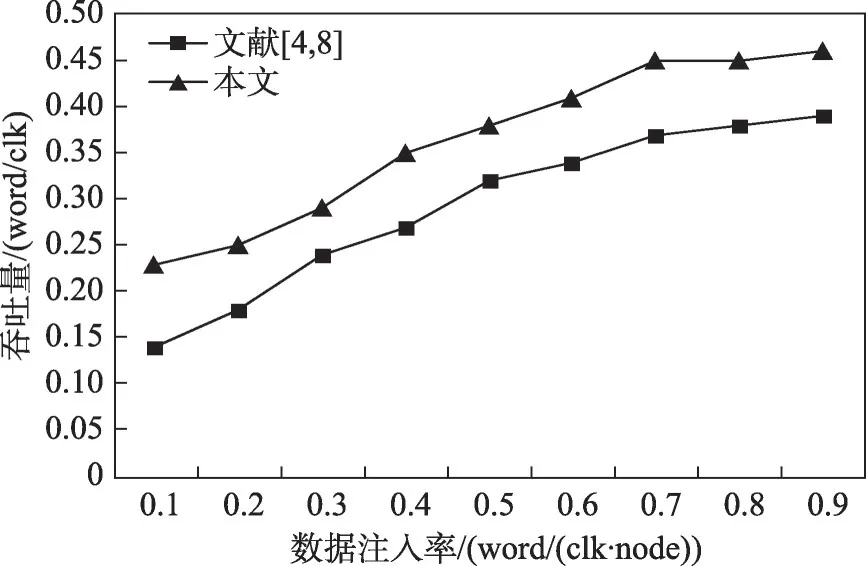
图21 吞吐量对比Fig. 21 Throughput comparison
针对相同Kernel 函数,本文与文献[8]的加速比对比如图22所示,(a)、(b)和(c)分别是中值滤波、颜色转换及图像腐蚀的加速比对比。结果表明,在处理性能上,本文相比同类的图像阵列处理器,具有更大的加速比,更有优势。

图22 核心函数加速比对比Fig. 22 Speedup comparison of kernel functions
文献[18-20]是基于FPGA对Sobel算法的并行化设计,实现了专用的图像处理。如表4 所示,当本文调用的PE 数目比较少时,处理速度小于专用硬件电路,但是随着调用PE 数目的增加,处理速度明显提高,当采用16 个PE 进行映射时,处理速度大于专用硬件电路。本文与文献[18-20]资源占用对比如表5所示,本文资源占用高于其他三个设计,但系统工作频率更高,可支持更多的图像处理类型,更加通用。
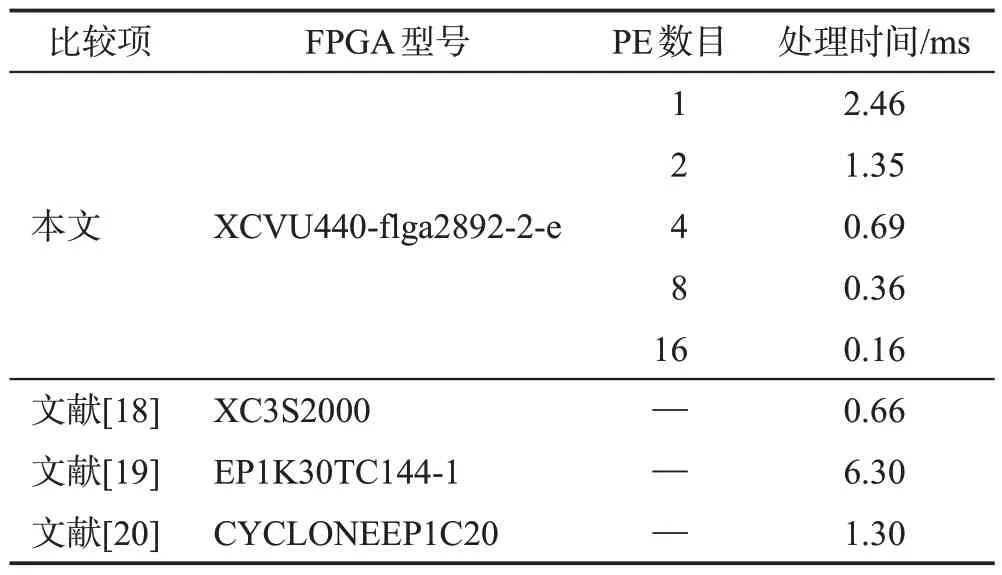
表4 处理时间对比Table 4 Comparison of processing time
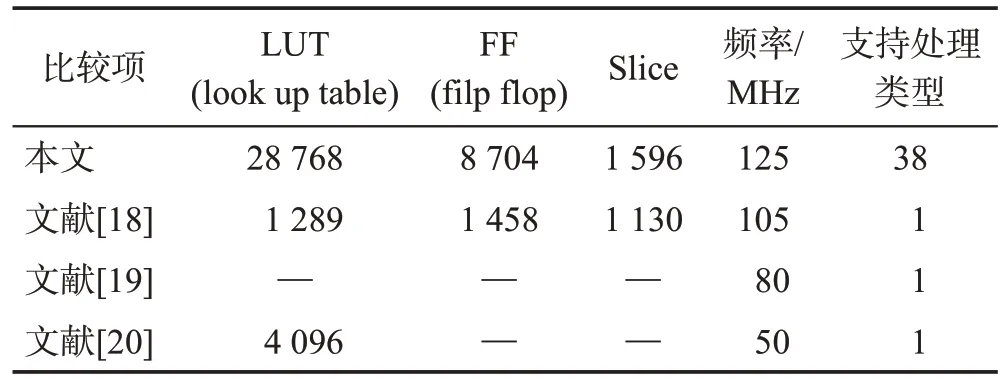
表5 性能对比Table 5 Performance comparison
5 结束语
针对传统的处理器灵活性与处理速度不能兼顾的问题,本文设计实现了一种OpenVX 并行处理器,不但在性能上接近于ASIC,而且具有灵活的可编程性,结构简单易扩展。并行处理器支持数据并行和管线处理两种计算方式,使用有限的硬件资源完成对OpenVX 核心函数和复杂Graph 执行模型的映射并且线性加速。对Ⅰ类函数的最大平均加速比为15.170,对Ⅱ类函数的最大平均加速比为14.825,对Ⅲ类函数的最大平均加速比为15.215,对Ⅳ类函数的最大平均加速比为14.810,能够有效地提高图像的处理速度,实现数据级并行和任务级并行。与同类阵列处理器相比,加速效果更加明显。今后研究工作重点是继续分析各个函数的处理瓶颈,找到更优的映射方式,优化最长路径。其次以本并行处理器为基本簇,结合更加有效的通信管理机制,对其进一步扩展,实现多并行处理器簇,进一步提高整个系统的性能。
