基于改进SSD 的人脸口罩佩戴检测算法
2022-07-20任健杨帆张奕凡王智捷廖磊
任健,杨帆,张奕凡,王智捷,廖磊
(四川师范大学物理与电子工程学院,四川成都,610101)
0 引言
深度学习技术的出现革新了目标检测的模式,并提升目标检测的精度和鲁棒性。深度神经网络提取多层尺度的特征,基于深度学习的目标检测模型,相比于传统方法,学习的特征更丰富,特征表达能力更强[1,2]。现代的目标检测器可以大致的分为单阶段[3,4,5,6]和两阶段[7,8,9,10]。两阶段检测方法首先生成一系列区域提案,随后对区域提案进行分类和回归[11]。另一方面,单阶段方法通过图像上的常规采样网格将默认锚框直接回归和分类到框中,单阶段主要在单尺度特征上进行不同尺寸目标的分类与定位,在精度以及速度等方面均有优势[12]。
深度学习方法已应用于计算机视觉各个领域,如车牌识别,人脸检测,遥感图像目标检测,自然场景文本检测,医学图像检测等等。目前没有专门应用于人脸口罩检测算法,深度学习的快速发展为解决计算机视觉等相关的问题提供全新的方案。
本文的主要贡献如下:(1)构建了一个人脸口罩检测的数据集,可用于人脸口罩佩戴的识别检测等研究工作;(2)将目标检测应用于口罩佩戴检测,提出一种基于SSD 方法的口罩佩戴检测方法,在SSD[4]目标检测算法基础上,将基准网络替换为表征能力更强的残差网络ResNet,解决随着网络层数加深出现的性能退化问题[13],同时引入低层与高层的多尺度特征融合策略实现对自然场景中人脸口罩的实时检测。
1 SSD 目标检测算法
SSD 模型主要由一个基础网络块和多尺度的特征块级联而成。位于前端的基础网络块一般选用深度卷积神经网络提取原始图片特征在多尺度下提取位于后端的级联多尺度特征检测网络前端网络产生的特征[15],使特征图中每个单元输入图像的感受野更广阔,更适合检测尺寸较小的目标[4]。SSD 检测目标时,生成多个不同尺度的预测框,并通过预测框的类别和偏移量实现目标检测,如图1 所示:各个尺度相互独立,不考虑不同尺度特中层间映射关系,层与层之间关联性较弱,导致特征细节信息利用不充分。
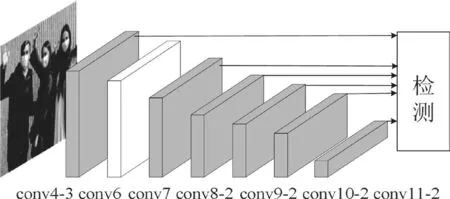
图1 SSD 框架
2 相关工作
2.1 特征层默认框映射
SSD 采用多尺度的方法获得多个不同尺寸特征图[35],大小分别为(38,38),(19,19),(10,10),(5,5),(3,3),(1,1)。考虑模型检测采用m 层特征图,第k 个特征图的默认框比例计算公式如下:


2.2 损失函数
在SSD 算法中,目标损失函数的设计思想与MultiBox类似[14],并将其扩展为可处理多个类别的目标函数。网络训练的损失函数包括置信度损失和定位损失,即

3 改进措施
3.1 基础网络ResNet
基础网络对输入的图片数据进行特征提取,并将特征送入后续网络进行训练。SSD 算法采用VGG-16 作为基础网络,具有加深神经网络层数提升模型效果,且对其它数据集泛化能力较强,由于随着网络层数加深,精度出现不升反降现象,并引入跳跃连接机制降低提取特征的冗余度,解决层数增加出现的性能退化问题[13],ResNet 允许网络更深,全连接密集层代替全局平均池操作,模型的尺寸更小,表征能力更强。选取conv2_x,con3_x,conv4_x,conv5_x,conv_7_x,conv8_x,conv9_x 特征提取层。图2 为经过网络替换后的网络结构图:
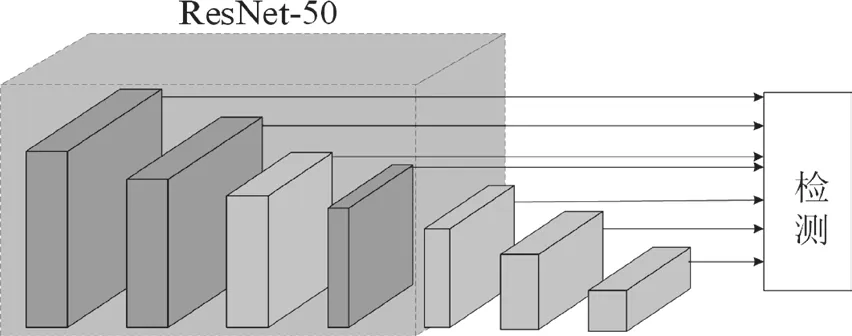
图2 SSD(with ResNet)框架
3.2 多尺度特征融合
3.2.1 反卷积操作
通过卷积操作提取图片中的特征,低层的卷积层提取图片边缘、线条、角等特征,高层的卷积从低层的卷积层中学到更复杂的特征[12]。反卷积对特征图上采样,将低维局部特征映射为高维向量,学习更多上文信息。SSD 网络结构中低层的特征图中具有丰富的边缘信息,高层的特征图具有较多的语义特征。设步长s,输入特征大小i,滤波器大小k,扩充值p,有:
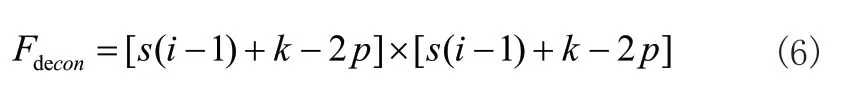
本次实验中设计i=3,s=1,k=3,p=0。将conv4_3 映射至conv7 层,设该映射层为conv7f,同理,将conv7 映射至con8_2 层,设该映射层为conv8_2f。融合反卷积操作提取层如图3 所示:
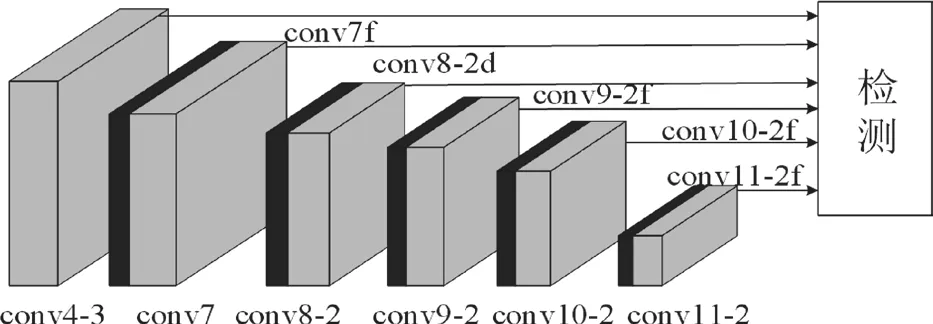
图3 融合反卷积操作提取层
3.2.2 空洞卷积操作
在图像分割领域中,池化操作减少图像尺寸增大感受野,上采样操作实现扩大尺寸,在池化和上采样图像尺寸变化过程中损失部分信息,设计空洞卷积在不丢失信息的情况下增大卷积层感受野,改善对小目标的表达。本文中设计卷积核3×3,扩张dilation 为2 的空洞卷积,感受野计算公式为:

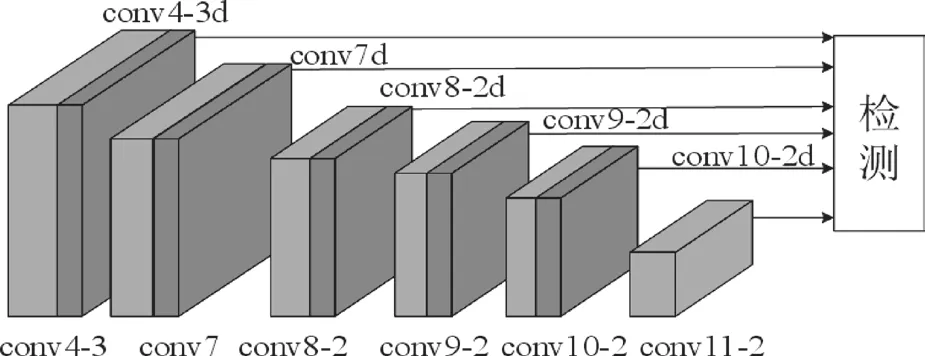
图4 融合反卷积操作提取层
3.2.3 网络结构
SSD 检测目标时,生成多个不同尺度的预测框,不考虑不同尺度特征层间映射关系,层与层之间关联性较弱。本文优化SSD 目标检测算法的网络结构,选择表征能力更强的基础网络ResNet-50。特征层融合机制将多个特征层的信息融合,空洞卷积操作将低层与高层的特征图融合,明显提高分类网络的感受野范围,促使模型学习更多的全局信息;反卷积操作将高层的特征图和低层的特征图融合,提高低层特征层检测小目标的能力,增强模型的语义表征能力。该连接方式使改进后的网络可在同一特征层上将目标的不同尺度考虑在内,增强模型的泛化能力。
以conv7 为例,conv7 从SSD 中继承而来,通过conv4_3反卷积操作映射生成conv7f,通过conv8_2 空洞卷积操作映射生成conv7d,改进SSD 的网络结构如图5 所示。
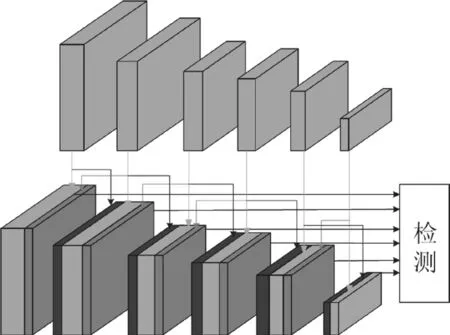
图5 改进SSD 网络结构
4 实验
4.1 数据集
本实验的数据集基于香港中文大学Yang Shuo 等制作的人脸数据WIDER FACE[16],并从网络爬取,实地采集和算法合成7106 张关于佩戴口罩与未佩戴口罩的自然场景人脸口罩数据集。数据通过准确的人工标注,标注类别分为佩戴与未佩戴,所有图片均为彩色。数据集样例图6。

图6 数据集
4.2 实验环境
本文的实验环境如表1 所示,并设置训练阶段的重要参数,如表2 所示。

表1 实验平台
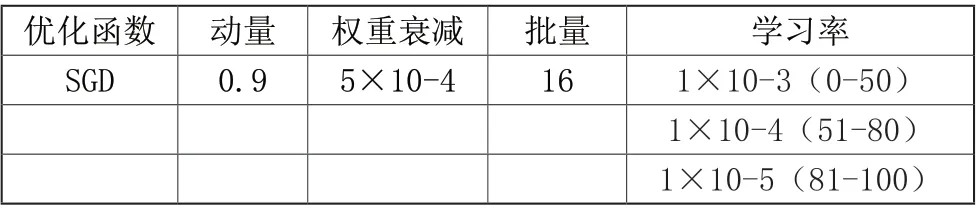
表2 训练参数
在训练过程中,模型的损失和精度变化是重要的两个变量,模型经过35000 次迭代,loss 最终下降至0.2 附近,模型的精度上升至97.7%附近。此外,在测试数据集对模型性能进行评估,如图7 所示,最终right 标签的单类AP 为92.89%,no 标签的单类AP 为88.41%
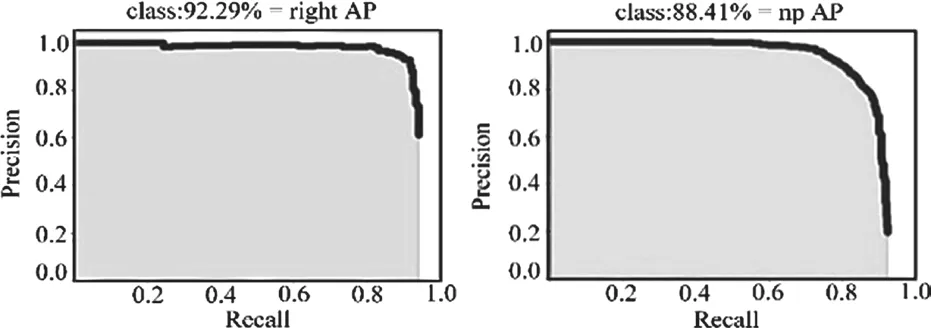
图7 right P-R 和no P-R
算法改进前后的实验结果如表3 和图8 所示,本文算法通过改进在人脸检测和口罩佩戴检测方面相比SSD 均有提高,综合测试由原SSD 的82.37%提升至90.65%。本文算法取得较好的检测效果,对于优化后训练包含小尺寸目标时本文算法的检测效果相比SSD 提升较大,对于部分受到遮挡的目标,本文算法相比优于SSD 检测能力。

表3 方法改进前后对比
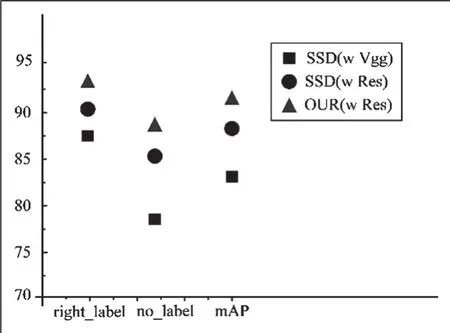
图8 精度对比图
5 总结
本文通过对基础网络的替换,以及多尺度特征融合方法实现对SSD 算法的改进,实验通过在本文建立的7106 张图片数据集训练以及评估,结果显示该方法可以有效检测自然场景人脸口罩,平均精度达90.65%,证实了本文算法框架的合理性。
