双分支特征融合网络的步态识别算法
2022-07-15徐硕郑锋唐俊鲍文霞
徐硕,郑锋,唐俊*,鲍文霞
1.安徽大学电子信息工程学院,合肥 230601;2.南方科技大学工学院,深圳 518055
0 引 言
步态识别旨在通过行人行走的模式判断其身份,具有远距离、易采集、不易模仿和伪装等优点(贲晛烨 等,2012),在视频监控、公共安全等领域有着广阔的应用前景。步态识别方法分为基于外观的方法和基于模型的方法。基于外观的方法使用轮廓图像作为输入数据并从中提取步态特征。轮廓图像的优点是易于获取和处理,且去除了背景和人体纹理信息等干扰因素,更专注于步态。基于模型的方法先通过输入数据对步态进行建模,如关节角度、运动轨迹和姿态等,再通过模型提取步态特征。
目前,步态识别尤其是基于深度学习的方法大多采用基于外观的方法。基于外观的方法一般面临两个难点,一是轮廓图像在不同视角下差异较大;二是轮廓图像在不同的行走状态下差异较大,如携带背包、衣物变化等干扰。对于视角的差异,Yu等人(2019)利用生成对抗网络将各个视角的轮廓图像都转换至相同的视角,再提取特征以提高对视角变化的鲁棒性。Wang等人(2019)利用动态视觉传感器获取数据并通过运动一致性去除噪声,再使用卷积神经网络提取步态特征。Zhang等人(2019a)结合同步态和跨步态两种网络的优势,设计了一种联合网络提取步态特征。Ben 等人(2019a,2020)针对跨视角问题提出了一系列步态识别算法,如提出一种通用张量表示框架从跨视角步态张量数据中进行耦合度量学习、提出耦合双线性判别投影算法以跨视角对齐步态图像以及提出了耦合区块对齐算法。对于行走状态的差异,大多数方法都不做针对性处理,仅靠卷积神经网络自身提取尽可能与行走状态无关的步态特征。由于输入数据为轮廓图像序列,因此时序特征的融合也是研究的关注点。Wu等人(2017)利用传统算法,先将轮廓图像序列融合为一幅特征模板图像,再将该模板送入卷积网络提取特征,并针对不同场景设计了不同的图像预处理方法和网络结构,该方法的优点是计算简单,仅需要从一幅步态模板图像中提取特征。Wolf等人(2016)利用3D卷积网络从轮廓图像序列中提取时空特征,能够更充分地融合时序上的信息,但计算量较大且3D卷积网络对序列的长度有限制。Chao等人(2019)设计新的卷积网络从轮廓图像序列的每幅图像中提取空间特征,再通过时序池化和特征融合的方法得到时空步态特征,该方法网络结构简单且融合效果良好。在此基础上,Chao等人(2021)提出新的特征融合方法并改进训练策略,进一步提高算法的识别准确率;Zhang等人(2019b)利用自动编码器将序列中的步态特征解耦为外观特征和姿态特征,再用长短时记忆网络融合时序信息生成步态特征。
与基于外观的方法相比,基于模型的方法较少。由于早期方法没有建立合适的模型,导致识别准确率与基于外观的方法相比有很大差距。另一方面早期方法构建的模型仅适用于严格条件限制下的场景,因此泛化性能较差。随着姿态估计算法的进步,可以利用已有的姿态估计器获取较为准确的姿态信息,这为基于模型的方法提供了新的思路。Liao等人(2017)利用姿态估计方法提取2D姿态关键点,并使用卷积网络提取步态特征;之后进一步使用3D姿态关键点(Liao等,2020),提高了算法对视角场景下的准确率,同时结合人体姿态先验如上下肢的运动关系、运动轨迹等提取步态特征。此外,也有部分工作利用深度相机、雷达等获取3D姿态骨架并从中提取步态特征(Kastaniotis等,2015;Sadeghzadehyazdi等,2019)。相比之下,虽然这些方法获取的姿态信息更加准确,但需要额外的硬件设备,不便于实际应用。
综上所述,基于外观的方法和基于模型的方法各有优缺点。基于外观的方法效果较好且步骤简单,但易受外界因素干扰,如人体外观变化、视角变化等,这些因素导致轮廓图像改变,进而影响识别准确率;基于模型的方法对外观变化更加鲁棒,但在建模过程中丢弃了外观信息,导致可用信息减少,而且姿态准确性受姿态估计算法的限制,识别准确率与基于外观的方法仍有一定差距。基于此,融合外观与模型两种方法有助于进一步提高步态识别的准确率。目前,与此相似的研究是多模态特征融合(Vaezi Joze等,2020),由于外观和模型两种方法的网络结构和特征维度有较大差异,常见的特征融合方法如特征相加、张量积等并不能直接用于步态识别算法。针对以上问题,本文设计了一种基于特征融合的步态识别算法,使用双分支网络,两条分支分别用于提取外观特征和姿态特征,最后利用特征融合模块,将两种特征自适应地融合以发挥两种特征间的互补性。本文算法的创新之处在于:1)设计了一种双分支卷积神经网络,利用外观和姿态两种数据分别提取外观特征和姿态特征,并进一步融合以得到更准确更鲁棒的步态特征,从而达到更高的准确率;2)设计了一种新的特征融合模块,能够有效利用外观特征和姿态特征间的互补性,且适用于两种特征维度差距较大的情形;3)在CASIA-B(Institute of Automation,Chinese Academy of Sciences,Gait Dataset B)数据集上与主流方法进行实验对比,验证了算法的有效性。
1 本文网络模型
本文算法的总体结构如图1所示,输入数据为原始RGB视频序列,通过背景分割算法得到轮廓图像序列,通过姿态估计算法获得姿态关键点序列。轮廓图像数据通过外观分支网络得到外观特征,姿态关键点数据通过姿态分支网络得到姿态特征。之后两种特征通过特征融合模块得到最后的步态特征。在测试时将步态识别看做检索问题,根据样本间步态特征的距离判断其相似性。

图1 本文网络框架图Fig.1 The pipeline of the our network
1.1 数据预处理

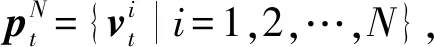
(1)
对于轮廓图像,首先按照边界去除无用的背景,只保留包含轮廓图像的区域;再将轮廓图像保持宽高比例不变的同时将高度缩放到64像素,并将图像的宽度左右平均填充到44像素,最后对所有轮廓图像进行标准化处理。
1.2 外观分支网络
本文算法采用GaitSet(Chao等,2019)作为外观分支网络,结构如图2所示。网络主干由6层卷积层组成,输入轮廓图像序列后得到特征图序列。该网络的分支用于融合网络浅层与深层的特征,图2中的池化操作表示在时序上对序列进行池化,⊕表示对应元素相加,因此分支网络的另一作用是融合时序信息。经过主干与分支两条路径后得到两种特征图,为了便于后期的特征融合,添加了拼接操作将两种特征图在通道维度上拼接,经过池化层下采样和全连接层上采样后得到外观特征。
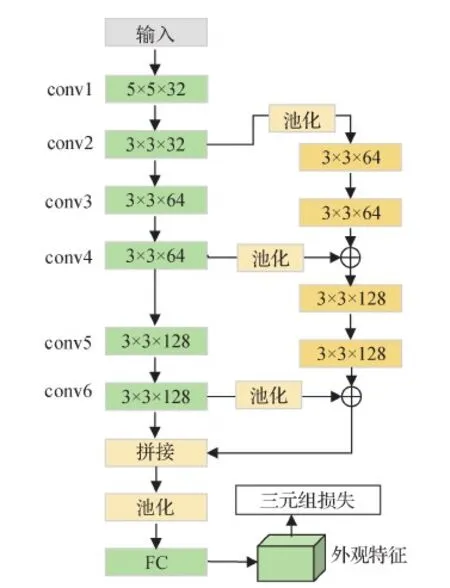
图2 外观分支网络结构Fig.2 Architecture of the appearance branch network
1.3 姿态分支网络

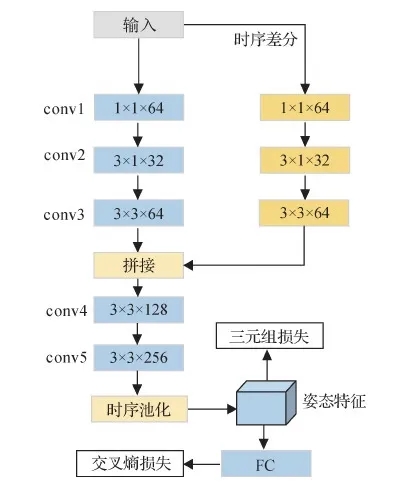
图3 姿态分支网络结构Fig.3 Architecture of the pose branch network
1.4 特征融合模块
输入数据经过外观分支网络和姿态分支网络后,分别得到外观特征图fA和姿态特征图fP。其中,fA∈Rh1×w1×c1,fP∈Rh2×w2×c2。h1、w1、c1和h2、w2、c2分别表示外观特征图和姿态特征图的高度、宽度和通道数。外观特征图fA和姿态特征图fP经过池化融合后得到最终的外观特征fa和姿态特征fp。特征融合常见的方法有相加、加权平均、张量积和拼接等,在本文算法的双分支网络中,由于外观分支网络与姿态分支网络结构不同,特征维度有很大差距。在实施中,外观特征fa∈R15 872×1,而姿态特征fp∈R1 024×1,因此相加、加权平均并不适用于该算法的网络,同时外观特征维度较高导致张量积的计算量很大。相比之下,特征拼接的融合方法简单且适用于该算法的双分支网络,但仅使用特征拼接不能充分利用两种特征的互补性。
受MMTM(multi-modal transfer module)(Vaezi Joze 等,2020)利用SE(squeeze excitation)模块处理多模态模型中不同尺寸特征图的启发,本文算法设计了一种基于SE模块(Hu 等,2018)的特征融合模块(squeeze-and-excitation feature fusion module,SEFM),结构图如图4(a)所示。SEFM模块使用SE模块的结构以融合外观和姿态两种特征。具体融合方法为:
1)对外观特征图fA和姿态特征图fP分别池化下采样,得到全局外观特征f′a∈R1×1×c1和全局姿态特征f′p∈R1×1×c2,将两种特征拼接后得到拼接特征f′c∈R1×1×(c1+c2),这里采用了全局最大池化将特征图的空间信息压缩到通道维度中,以便于融合不同尺寸的特征图。
2)将拼接特征f′c映射到低维空间,得到融合特征f′m,该过程可表示为
f′m=Wf′c+b
(2)
式中,W表示权重,b表示偏差;f′m=R1×1×ce,ce表示映射后的特征通道数,该过程称为压缩(squeeze),算法实施中ce=(c1+c2)/2。
3)将融合特征分别映射到全局外观特征空间和全局姿态特征空间,该过程称为激励(excitation),得到外观特征图和姿态特征图的激励值ea和ep,可表示为
ea=σ(Wf′m+b),ep=σ(Wf′m+b)
(3)
式中,σ(·)表示sigmoid函数;ea∈R1×1×c1,ep∈R1×1×c2;两次映射的权重和偏差值不共享,训练网络时各自独立训练。
4)将激励值ea和ep分别看做外观特征图fA和姿态特征图fP通道上的权重,将其扩展到与对应特征图相同的尺寸后再通过哈达玛积计算加权后的特征图。该过程与SE模块相似,可看做是通道维度上的注意力机制,不同之处在于SEFM有两种激励输出。最后将加权后的特征图与原始特征图相加,得到新的外观特征图f′A和姿态特征图f′P。
5)分别对外观特征图f′A和姿态特征图f′P做池化下采样,将所得特征展开为1维向量后,拼接得到最终的步态特征f。
从整体结构上看,SEFM以特征拼接为基础融合两种特征的信息,并通过压缩—激励过程学习外观特征和姿态特征的权重,以达到自适应融合的目的。SE模块在通道维度上进行加权,这种注意力机制使模型更多关注有效特征并抑制不重要特征。而SEFM特征融合模块可看做在姿态和外观两种特征上加权,首先将两种特征在空间上压缩并拼接得到融合特征,压缩单元接收融合特征并进一步生成一个全局的联合表示,激励单元则根据这个联合表示强调姿态和外观两种特征中更重要的特征。
为了研究外观特征和姿态特征对融合结果的影响,在原始模块的基础上对激励过程进行改动,得到另外两种融合模块,分别如图4(b)和图4(c)所示,称为SEFM-A和SEFM-P。与原始模块不同的是,SEFM-A模块在激励阶段只计算外观特征图的激励值,即将姿态特征融入外观特征,姿态特征保持不变;而SEFM-P模块在激励阶段只计算姿态特征图的激励值,即将外观特征融入姿态特征,外观特征保持不变。
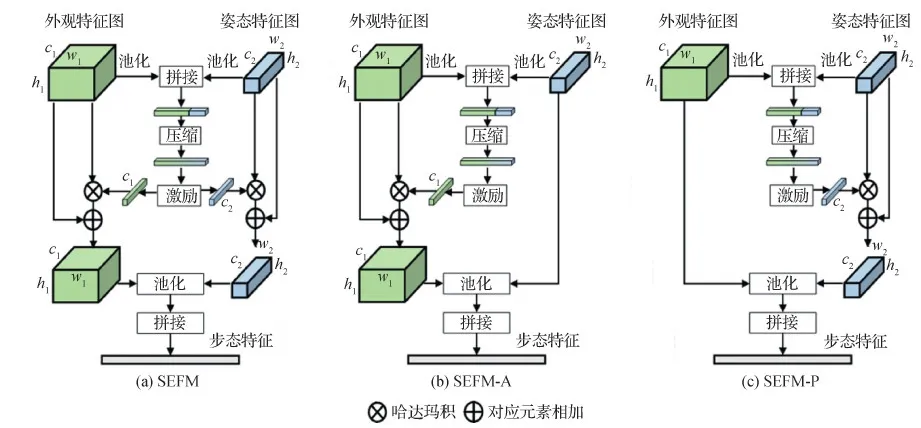
图4 3种不同的特征融合模块结构Fig.4 Architecture of three different feature fusion modules((a)SEFM;(b)SEFM-A;(c)SEFM-P)
在训练过程中,双分支网络使用了两种损失函数,分别为三元组损失Ltriple和交叉熵损失LCE。其中三元组损失作用于融合后的步态特征,而交叉熵损失作用于融合前的姿态特征,总的损失为
L=Ltriple+λLCE
(4)
式中,λ为权重参数,算法实施中取λ=2。
2 实 验
为了评估双分支特征融合网络的步态识别算法的有效性,在CASIA-B数据集上进行实验,实验中的模型均使用Pytorch框架实现。
2.1 数据集

2.2 实验细节
训练时,每次迭代从训练样本里随机挑选16位行人,再从每个行人的数据中随机挑选8个序列,因此批尺寸为128;之后从每个序列中随机选取连续的30帧作为输入数据,不足30帧的序列重复至30帧。所有网络均采用Adam优化器,姿态分支网络的初始学习率为0.000 2,外观分支网络和特征融合模块的初始学习率为0.000 1;在跨视角设置中,共迭代60 000次,并在第45 000次时将学习率衰减至各自的0.1倍;在不同行走状态设置中,共迭代20 000次;三元组损失的阈值距离设为0.2。
2.3 实验结果
表1是双分支网络与不同的特征融合方式的测试结果。前3行是双分支网络中单个分支网络的准确率,后4行是双分支网络结合不同的特征融合模块的结果。
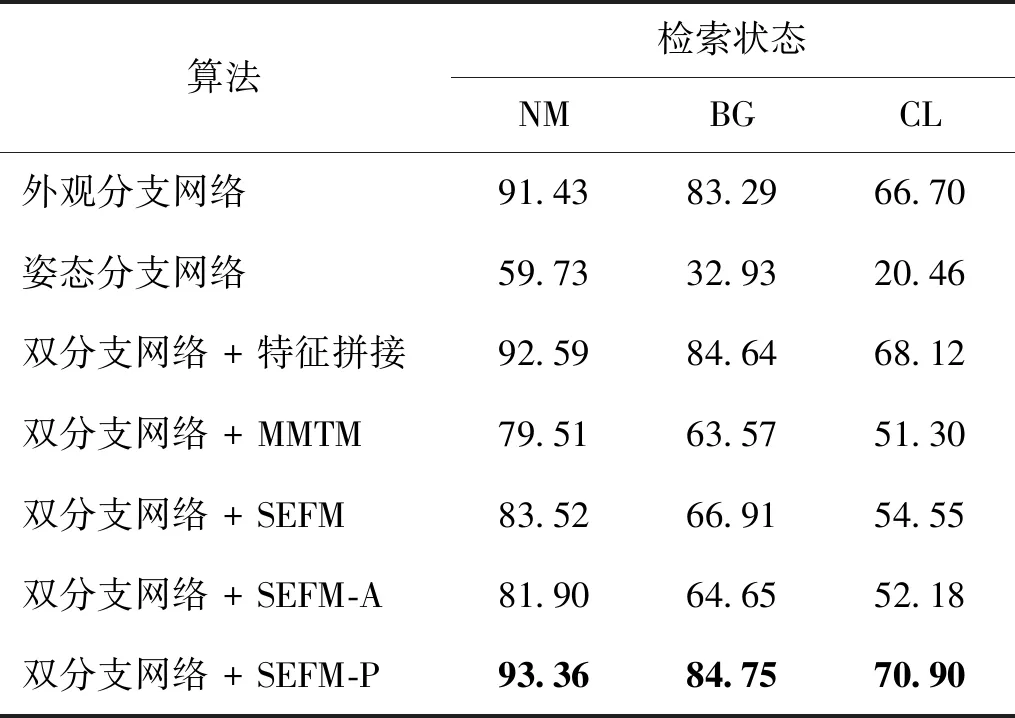
表1 不同特征融合方法的Rank-1准确率Table 1 Rank-1 accuracies of different feature fusion methods /%
从表1可以看出,1)基于外观的方法在准确率上远高于基于模型的方法,因为一方面姿态数据本身包含的信息少于轮廓图像,另一方面受姿态提取算法的限制,获得的姿态关键点并不完全准确。但经过特征拼接后,得到的准确率优于外观分支网络,证明了外观特征和姿态特征存在互补性,二者融合后得到的步态特征更加准确。2)添加MMTM、SEFM和SEFM-A共3种特征融合模块后最终的准确率急剧降低,甚至低于外观分支网络;而添加SEFM-P特征融合模块后准确率提升。导致该结果的原因仍在于姿态数据,由于相机角度限制,行人在行走过程中存在自遮挡现象,此外原始RGB视频的分辨率较低,以及姿态估计算法的性能限制,这些因素共同导致了姿态数据中存在部分噪声。因此在特征融合的过程中,如果将姿态特征融入外观特征,反而会因引入噪声,导致外观特征也不准确。在几种特征融合方法中,MMTM和SEFM将姿态特征和外观特征相互融合;SEFM-A将姿态特征融入外观特征中,所以这3种融合模块都导致准确率降低。而SEFM-P将外观特征融入姿态特征,同时保持外观特征不变,避免了外观特征受噪声污染;特征拼接也同样保持了外观特征不变,因此这两种特征融合方法都提高了准确率。根据准确率对比,可以看出本文算法设计的几种SEFM模块都优于MMTM模块,而且SEFM-P达到了最高的准确率,证明了本文算法中特征融合模块的有效性。
表2和表3分别列举了跨视角设置下基于特征融合的算法和近年主流的步态识别算法在CASIA-B数据集上采用MT和LT两种划分方式的准确率。其中PoseGait(Liao 等,2020)和JointsGait(Li 等,2020)是基于姿态模型的方法;GaitSet(Chao等,2019)、CNN-LB(CNN-matching local features at the bottom layer)(Wu等,2017)和GaitNet-pre(Zhang 等,2019b)是基于外观的方法,使用轮廓图像作为输入;EV-Gait(event-based gait recognition)(Wang 等,2019)也是基于外观的方法,但其输入数据为事件图像(event image)。结合表1,本文算法的外观分支网络采用与GaitSet算法相同的网络结构。在MT实验设置下,3种步行状态的平均准确率分别为91.4%、83.3%和66.7%,而GaitSet(MT)的平均准确率分别为92.0%、84.3%和62.5%。这是因为本文算法在实验实施中调整了序列数据的采样方式,在略微降低NM、BG状态准确率的条件下,大幅提高了CL状态的准确率。与另一种基于姿态的方法PoseGait相比,本文算法的姿态分支网络的准确率较低。这是因为考虑到提取姿态的计算复杂度,本文算法采用了2D姿态数据,而PoseGait采用的3D姿态数据在跨视角时更有优势,因此具有更高的准确率。在结合姿态分支网络、外观分支网络和特征融合模块SEFM-P后,本文算法的双分支网络准确率进一步提升,分别为93.4%、84.8%和70.9%。相比于GaitSet(MT),在3种行走状态下的准确率分别提升了1.4%、0.5%和8.4%。在LT实验设置中,本文算法同样优于CNN-LB、GaitSet(LT)、GaitNet-pre和EV-Gait等方法,达到了最高的准确率。需要说明的是,与外观分支网络GaitSet相比,本文算法在CL行走状态下提升较大,说明本文算法对衣物变化等外观干扰因素具有更好的鲁棒性;但在NM和BG行走状态下提升较小,这是因为姿态分支网络的准确率远低于外观分支网络,限制了特征融合的效果。根据表2的结果,基于姿态的算法如PoseGait、JointsGait等,其准确率远低于其他几种基于外观的算法,这也是目前基于姿态的算法面临的主要问题。

表2 跨视角设置下不同算法在CASIA-B数据集上采用MT方式时的平均Rank-1准确率Table 2 Rank-1 accuracies of different methods on the CASIA-B dataset with MT under different views /%
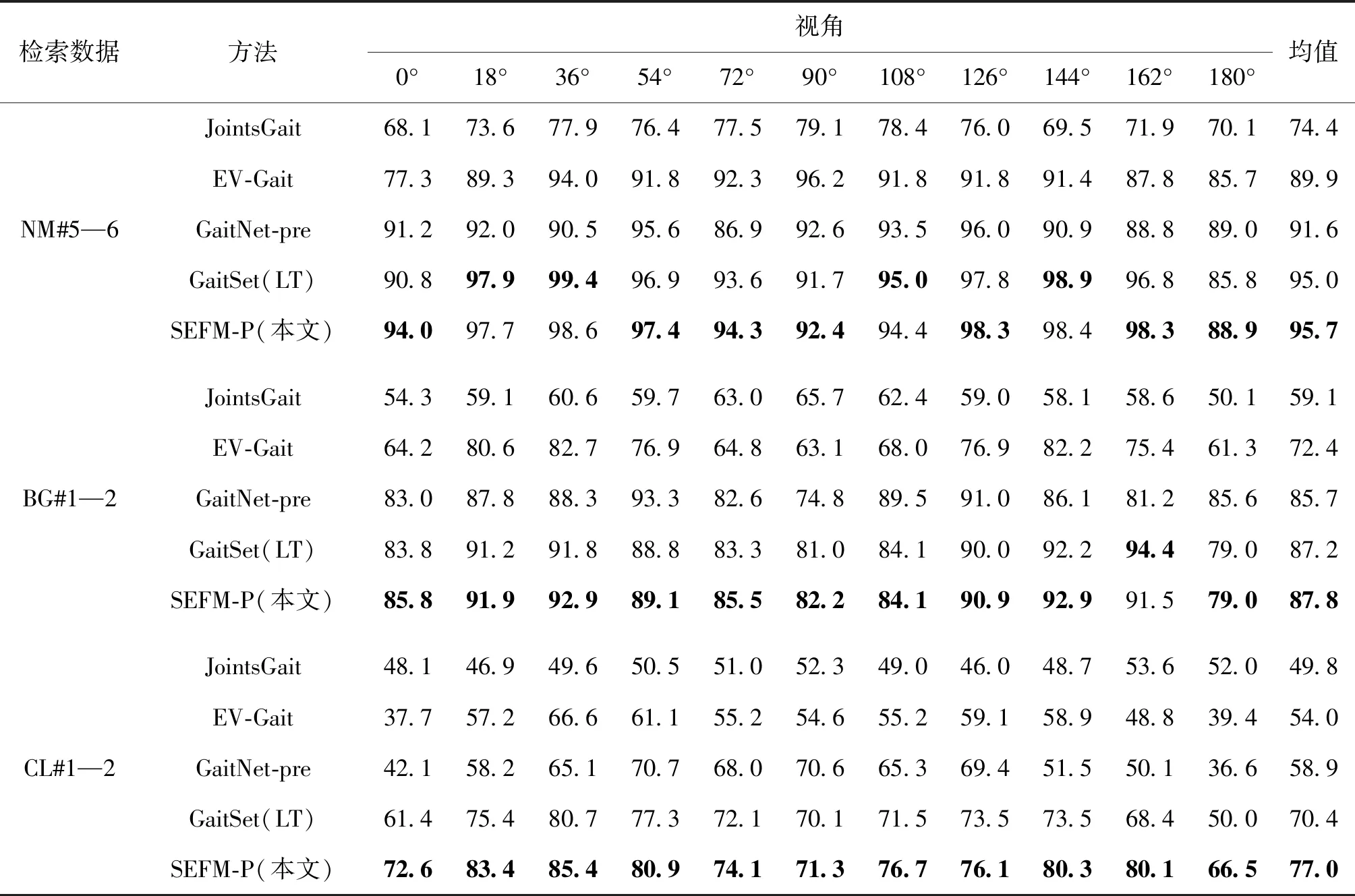
表3 跨视角设置下不同算法在CASIA-B数据集上采用LT方式时的平均Rank-1准确率Table 3 Rank-1 accuracies of different methods on the CASIA-B dataset with LT under different views /%
表4为不同行走状态设置下的实验结果。可以看出,与JUCNet(joint unique-gait and cross-gait network)(Zhang等,2019a)和CNN-LB相比,本文算法在CL行走状态下的平均准确率为90.0%,远高于CNN-LB算法的62.5%。在BG行走状态下的平均准确率为94.9%,优于JUCNet算法的93.2%。GaitNet-pre算法通过特征解耦提取与行走状态无关的步态特征,在CL行走状态下达到了89.8%的平均准确率,与本文算法的90.0%相差不大,但在BG行走条件下的准确率低于本文算法。与外观分支网络GaitSet算法相比,本文算法在BG和CL行走状态下的准确率分别提高了1.6%和6.7%,说明SEFM-P特征融合模块能够有效融合外观和姿态两种特征,且融合姿态特征后能够提升算法对背包、衣物等外观变化的鲁棒性。

表4 不同行走状态设置下不同算法在CASIA-B数据集上的平均Rank-1准确率Table 4 Rank-1 accuracies of different methods on the CASIA-B dataset under different walk conditions /%
3 结 论
步态识别算法包括基于外观的方法和基于模型的方法两类,结合两类方法的优点,设计了一种双分支特征融合网络的步态识别算法。该算法通过两条分支网络分别提取外观特征和姿态特征,再利用特征融合模块融合两种特征以得到更准确的步态表示,适用于能够同时获得轮廓图像和人体姿态的场景。CASIA-B数据集上的实验结果表明,该算法与目前主流的算法相比具有优势,达到了更高的准确率。与其他步态识别算法相比,该算法能够利用更丰富的步态信息,对于衣物外观变化这类干扰因素具有更好的鲁棒性;与其他特征融合方法相比,该算法在融合两种特征的同时,能够避免外观特征受姿态特征中的噪声影响,得到更准确的特征。尽管该算法在准确率上有所提升,但对姿态数据的处理上还存在不足。首先,该算法没有对姿态数据中的噪声进行处理,导致姿态特征的准确性较低;其次,该算法使用两条分支网络分别提取特征,效率有所降低。在未来的工作中,将围绕以上问题进一步改进。一方面提高网络对姿态数据中噪声的鲁棒性,以得到更准确的步态表示;另一方面优化网络结构,提高算法效率使其满足实际应用的需求。
