结合双注意力机制的道路裂缝检测
2022-07-15张志华温亚楠慕号伟杜小平
张志华,温亚楠,慕号伟,杜小平
1.兰州交通大学测绘与地理信息学院,兰州 730070;2.地理国情监测技术应用国家地方联合工程研究中心,兰州 730070;3.甘肃省地理国情监测工程实验室,兰州 730070;4.中国科学院空天信息创新研究院数字地球重点实验室,北京 100094
0 引 言
道路裂缝是一种普通路面和高速公路路面中常见的病害,会降低路面性能,缩短道路使用寿命,危及车辆行车安全。人工道路裂缝检测的步骤非常烦琐、费时费力,而且人工选取道路裂缝经常存在很强的主观性,直接影响道路裂缝检测的精度。常用的裂缝检测方法有Gabor滤波器、小波特征、方向梯度直方图以及局部二值模式。这些方法只编码了局部特征,未考虑全局特征,存在噪声干扰,使裂缝检测缺乏连续性(曹锦纲 等,2020)。
随着计算机视觉、图像处理以及模式识别技术的不断发展,深度学习方法广泛用于道路裂缝图像检测。最初深度学习架构下的裂缝检测方法大多是将原始图像分割为大量图像块,经筛选后通过卷积神经网络进行分类,从而实现道路裂缝检测。但检测出的道路裂缝宽于实际裂缝,检测精度需要进一步提升(Zhang等,2016)。因此,李良福等人(2019)利用滑动窗口算法将原始桥梁裂缝图像分割为更小的裂缝图像块和背景图像块,采用卷积神经网络构建分类模型,实现桥梁裂缝检测,得到了较好的裂缝检测结果。但该方法会使数据量激增,影响处理效率。Cha等人(2017)在图像分块的基础上,提出一种图像扫描块算法。首先设定滑块大小为256 × 256像素,步长为256像素,图像左上角为(0,0)坐标,分别将(0,0)和(128,128)作为起点,对每幅图像扫描两次得到图像扫描块数据集。然后通过构建深度学习网络对裂缝图像扫描块数据集进行分类,并保留分类为裂缝的图像扫描块,从而实现裂缝检测。这种深度学习方法取得了较好的裂缝检测效果,但只能检测出裂缝所在区域,无法精确定位裂缝位置。
随着深度学习网络的发展,基于深度学习的语义分割方法用于道路裂缝检测,不仅要解决道路裂缝逐像素分类问题,而且要识别每个道路裂缝像素的精确位置。相关研究通过卷积神经网络对输入图像进行逐像素分类实现裂缝检测,但这种网络结构没有设计任何有关下采样的结构,导致其网络架构与输入图像大小严格相关,直接影响着模型的泛化能力(Zhang等,2017)。为了提升深度学习网络的检测性能,一些专家学者将医学领域的U-Net网络结构应用于混凝土裂缝检测,取得了较好的裂缝图像分割效果,但该网络将输入图像分辨率固定为512 × 512 × 3的图像,未考虑输入图像的普适性(Liu等,2019)。在路况评价中,除了要检测出图像裂缝,还要求输出裂缝的长度和宽度,因此将卷积神经网络的全连接层替换为反卷积层以实现图像裂缝检测,并对裂缝的长度、宽度以及检测准确度进行定量评价,获得了较好的检测效果(沙爱民 等,2018)。另外,针对复杂背景的裂缝图像,王森等人(2018)在全卷积网络的基础上,将全连接层中的dropout层替换为卷积层以及通过加深网络深度实现裂缝检测,但该网络的最优平均交并比以及像素精确度都较低。
鉴于此,针对背景较为复杂、干扰较多的道路裂缝图像数据,本文设计了一种基于双注意力机制的道路裂缝检测网络,将带有空洞卷积的101层深度残差网络作为骨干网络,提取裂缝特征;将设计的残差注意力模块(Res-A)替换101层深度残差网络(ResNet-101)中的残差模块,该模块通过不断提高特征权值以提取裂缝的低级和中级特征;然后将Non-Local计算模式的注意力机制(NL-A)连接于ResNet-101输出端,提取高级特征并输出道路裂缝检测结果。对比实验表明,与一些典型深度学习网络相比,该网络可以有效提高复杂背景条件下的道路裂缝检测精度。
1 基于双注意力机制的道路裂缝检测
基于Res-A和NL-A,设计了一种结合双注意力机制的道路裂缝语义分割神经网络模型,旨在通过不断提升道路裂缝像元的关系权重来实现道路裂缝检测。模型由3部分组成,即基于Res-A低级和中级裂缝特征循环提取模块的ResNet-101基础网络结构、空洞卷积结构和基于NL-A的高级特征提取模块。模型的设计要点如下:
1)以ResNet-101网络为基础网络,该网络由4个残差循环结构组成,4个残差循环结构分别包含3、4、23、3个残差块(共33个)。本文改进了残差块,将一种轻量型的注意力机制与残差块组成Res-A模块,并将所有残差块替换为Res-A模块。随着Res-A模块不断由残差网络循环调用,网络更加专注于提高道路裂缝特征的关系权值,有效提高了道路裂缝特征的检测性能。
2)在ResNet-101基础网络中的所有残差块替换为Res-A模块后,将残差循环结构中的普通卷积替换为空洞卷积,这样可以提高网络模型的感受野、降低计算量以及更好地捕获上下文信息。
3)将NL-A嵌入带空洞卷积的ResNet-101网络的尾部,该机制利用局部特征与全局特征上下文之间的关系,不仅可以继续增加道路裂缝的关系权值,还可以剔除冗余,最终提高检测精度。
4)通过上采样将特征图恢复到输入图像尺寸,得到最后的道路裂缝检测结果。实验部分代码已共享至GitHub(https://github.com/ HaoweiGis/ EarthLearning)。模型的网络结构如图1所示,其中128、256、512、1 024、2 048表示该层网络的输出通道数;1/2、1/4、1/8表示该层网络的输出特征图与原图的比例;×3、×4、×23、×3表示该部分Res-A模块的数量;Res-A conv1-conv4表示改进后的残差卷积模块。

图1 结合双注意力机制的网络结构Fig.1 The network structure combined with dual attention mechanism
1.1 基于空洞卷积的深度残差网络
在训练深度神经网络模型时,随着网络层数的增加,经常会伴随梯度弥散和梯度爆炸问题,从而阻止网络收敛,导致模型网络性能退化,造成精度不升反降。为此,He等人(2016)提出了深度残差网络,在卷积神经网络中引入了残差模块,通过构建恒等映射来搭建深度网络模型,确保深层网络训练误差不会大于浅层误差,从而极大地加深深度神经网络的层数。
实验采用ResNet-101作为骨干网络,由1个输入卷积模块conv1和4个残差卷积模块conv2—conv5构成,输入卷积模块采用1个7 × 7 × 64卷积。需要注意的是,conv2—conv5的位置与图1中Res-A conv1—conv4的位置相对应。4个残差卷积模块全部采用3 × 3卷积核,每经过1个残差卷积模块后通道数会增加1倍,而特征图尺寸会缩小1倍,因此通道数分别为256、512、1 024和2 048,特征图尺寸分别为输入图像的1/4、1/8、1/16和1/32。为了减少下采样造成的信息损失,将残差模块conv4—conv5替换为带空洞卷积的残差模块conv4—conv5(Yu等,2017),如图2所示,其中h和w分别代表特征图的高和宽;C代表特征图的通道数;d-1代表空洞卷积像素间的像素个数。与普通的ResNet-101网络相比,输入特征图的通道数仍然会增加1倍,但特征图尺寸不再缩小,因此残差卷积模块conv2—conv5的通道数不变,而特征图尺寸变为输入图像尺寸的1/4、1/8、1/8和1/8,以此降低信息损失。空洞卷积的作用是扩大卷积过程的感受野以及降低卷积的计算量。另外,将输入卷积模块conv1的输出通道数由64改为128。

图2 ResNet-101网络和带空洞卷积的ResNet-101网络Fig.2 ResNet-101 network and ResNet-101 network with dilated convolution((a)traditional ResNet-101;(b)ResNet-101 with dilated convolution)
1.2 注意力机制
深度学习中的注意力机制与人类的注意力机制类似。人类视觉通过快速扫描目标或场景的全局信息获得需要的感兴趣区,然后对感兴趣区投入更多的关注度。深度学习中注意力机制的核心目标是确定图像中的全部像素对当前像素的关系权值,权值越高则代表该像素为道路裂缝的可能性越大。注意力机制已广泛应用于语义分割、目标检测以及全景分割等方面,通常由通道注意力机制、空间注意力机制以及混合注意力机制构成。
1.2.1 残差注意力模块
为了更好地提升神经网络的低级特征和中级特征提取性能,实验引入一种轻量型注意力机制(Woo等,2018)来改进ResNet-101网络中的残差模块,使之进行连续的特征融合,不断提高分割对象的权值,以达到提升分割精度的目的。
如图3所示,引入的通道注意力模块(channel attention module,CAM)和空间注意力模块(spatial attention module,SAM)可以嵌入到深度学习网络,并与深度学习网络一起进行端到端的训练。实验结果表明,加入该注意力机制有效提升了道路裂缝检测性能。

图3 通道注意力模块和空间注意力模块Fig.3 CAM and SAM((a)channel attention module;(b)spatial attention module)
CAM和SAM的设计模式如下:1)CAM模块首先分别对输入的特征图进行全局平均池化和全局最大池化,然后将两种池化结果分别输入到多层感知机,之后将这两部分结果进行矩阵加法运算,最后与输入的特征图进行矩阵点乘运算得到通道注意力特征。2)SAM模块首先对输入的特征图进行通道维度上的最大池化和平均池化,然后将两种池化结果通道合并后进行7 × 7卷积操作,最后将卷积结果与输入的特征图进行矩阵点乘运算得到空间注意力特征。
实验在该注意力机制的CAM-SAM的“串联”模式的基础上,额外增加SAM-CAM“串联”模式和CAM与SAM的“并联”模式(矩阵加法),通过道路裂缝分割实验来确定分割效果最优的组织模式。如图4所示,选择一种CAM和SAM的组织模式嵌入残差模块的尾部,组成Res-A模块,带空洞卷积的ResNet-101网络共包含33组残差模块,组成33组Res-A模块。

图4 Res-A模块Fig.4 Res-A module
1.2.2 基于Non-Local计算模式的注意力机制
为了进一步提取道路裂缝的高级特征,实验引入了另一种基于Non-Local计算模式(Wang等,2018)的注意力机制(Fu等,2019)。如图5所示,该注意力机制由通道注意力模块和空间注意力模块构成。通道注意力模块计算每一个通道与所有通道的依赖关系,并通过加权求和的方式确定每一个通道的关系权值,加权方式由当前通道与任一通道的特征相似性所决定;空间注意力模块计算空间中每个位置与所有位置的依赖关系,同样通过加权求和的方式确定空间中每一个位置的关系权值,加权方式由当前位置与所有位置的特征相似性决定。这两种模块结合(矩阵加法)后,可以在局部特征与全局特征上建立丰富的上下文关系,这有利于剔除冗余、准确定位与恢复道路裂缝细节信息。网络在进入NL-A模块时,特征图的通道数为2 048,特征图的高和宽分别为输入图像高和宽的1/8,假定输入图像的高和宽分别为H和W,那么此时的输入矩阵为[2 048,H/8,W/8]。具体而言,通道注意力模块和空间注意力模块的矩阵变化如下:

图5 NL-A模块Fig.5 NL-A module
1)通道注意力模块。首先,将输入特征图分为3个支路,每个支路的初始矩阵为[2 048,H/8,W/8]。将第1支路的矩阵维度变换为[2 048,H/8×W/8],将第2和第3支路的矩阵维度变换为[2 048,H/8×W/8]并转置为[H/8×W/8,2 048]。其次,将第1支路与第2支路进行矩阵乘法运算,得到[2 048,2 048]。再将上一步输出与第3支路进行矩阵乘法运算,得到[2 048,H/8×W/8]。然后,经过矩阵维度变换后得到[2 048,H/8,W/8]。
2)空间注意力模块。首先,将输入特征图分为3个支路,每个支路初始矩阵为[2 048,H/8,W/8]。将第1支路的矩阵维度变换为[2 048,H/8×W/8],并转置为[H/8×W/8,2 048],将第2和第3支路的矩阵维度变换为[2 048,H/8×W/8]。其次,将第1与第2支路得到的结果进行矩阵乘法运算,得到[H/8×W/8,H/8×W/8],再将第3支路与上一步输出结果的转置进行矩阵乘法运算,得到[2 048,H/8×W/8]。然后,对上一步结果进行矩阵维度变换后得到最终输出维度[2 048,H/8,W/8]。
最后,将通道注意力机制和空间注意力机制进行矩阵加法运算得到输出结果[2 048,H/8,W/8]。
2 实验结果与分析
实验环境为Intel(R) Core(TM) i9-9900k CPU,32 GB内存,Geforce RTX 2080Ti GPU,11 GB显存,操作系统为Ubuntu,在pytorch深度学习框架下实现。
为了验证结合双注意力机制网络模型的有效性,选择公共道路裂缝数据集Crack500(Yang等,2020)进行实验。该数据集图像中裂缝粗细相差较大且背景较为复杂、干扰较多。实验时,从中获取了2 817幅原始图像及其对应的真实分割图(ground truth,GT),图像分辨率为640 × 360 × 3。将所有图像随机划分为训练集、验证集和测试集,分别包含1 992幅、500幅和325幅图像。为了提高模型的训练性能,训练时在原裂缝图像的基础上进行颜色变换,之后将每幅图像由分辨率640 × 360 × 3随机裁剪为若干幅分辨率360 × 360 × 3,360由图像长和高的最小值所得。所有模型采用统一的参数进行训练,初始学习率为0.000 1,优化器为随机梯度下降法(stochastic gradient descent,SGD),采用softmax_cross_entropy为损失函数,训练迭代次数设置为24 900,训练过程中每次迭代所取的图像数batchsize = 4,所有数据训练的总轮数epochs为50。模型会在整个训练过程中不断迭代保存最优的模型参数。
2.1 评价指标
实验采用平均交并比(mean intersection over union,mIoU)、像素精确度(pixel accuracy,PA)和训练迭代时间对道路裂缝检测结果进行定量评价(翟鹏博 等,2020)。需要注意一点,在定量比较不同模型的性能时,3个评价指标的优先级为mIoU>PA>训练迭代时间。
平均交并比mIoU是语义分割中衡量分割精度的重要度量,即一个类别真实值和预测值的交集与并集之比。在计算一幅图像的mIoU时,需要分别计算每个类别的mIoU,然后再计算所有类别的mIoU。mIoU越大表示分割效果越好。具体计算为
(1)
式中,k代表类别数,pii为像素实际类别为i且预测为i的数量,pij为像素实际类别为j且预测为i的数量,pji为像素实际类别为i且预测为j的数量。
PA为像素精确度,即预测正确的像素数量与像素总量的比值。具体计算为
(2)
式中,p为分类正确的像素数量,s为像素总数。PA越大,模型精度越高,分割效果越好。
训练迭代时间,即训练过程中每次迭代所需时间,所用时间越少,模型训练效率越高。
2.2 Res-A模块不同结构性能比较与分析
为比较Res-A模块中通道注意力机制和空间注意力机制在道路裂缝检测中的性能,基于提出的双注意力机制道路裂缝检测网络,设计了3种模型进行实验。模型1为Res-A(C→S)+NL-A,模型2为Res-A(S→C)+NL-A,模型3为Res-A(S⊕C)+NL-A。其中,“→”表示按照前后顺序进行串联连接,“⊕”表示两者并联连接执行矩阵加法运算,“C”和“S”分别表示Res-A模块中的CAM和SAM,“+”表示在其后连接NL-A注意力机制。选用测试集中不同类型的道路裂缝图像对3种模型进行对比实验,部分道路裂缝图像的检测结果如图6所示,3种模型的检测结果相差较大。图像中裂缝较细或背景干扰较小时,如图6第1行所示,模型1存在漏检导致检测出的裂缝不连续,模型2未能检测出裂缝,而模型3检测出的裂缝较为完整,检测效果最好。图像中裂缝粗细适中且结构较为简单时,如图6第2、3行所示,模型2出现了大量漏检,检测出的裂缝表现出了不连续性,模型1和模型3虽然都出现了轻微漏检,但都可以较准确地检测出裂缝,并且模型3比模型1检测出的裂缝更加完整。图像中裂缝较粗且结构较为复杂时,如图6第4—6行所示,模型2漏检较严重且检测出的裂缝不连续,尤其在第4、5行漏检了大量裂缝像素,而模型1除了漏检还出现了一定程度的误检,模型3整体检测效果较好,虽然存在轻微的漏检和误检,但细节信息更加丰富,能够更加准确完整地检测出裂缝。综上分析,模型3的道路裂缝检测效果最好,整体上存在更少的漏检和误检,检测出的裂缝具有更好的连续性,因此Res-A模块中的通道注意力机制和空间注意力机制采用“并联”模式可以表现出最好的道路裂缝检测效果。

图6 CAM和SAM的不同组织模式检测示例Fig.6 Examples of detection of different organization patterns of CAM and SAM((a)original images;(b)ground truth;(c)model 1;(d)model 2;(e)model 3)
为了进一步对比3种模型的有效性,对3种模型的mIoU、PA和迭代时间进行定量分析,实验结果如表1所示,模型3的mIoU和PA均为最优,分别为79.28%和93.88%。其中,mIoU比模型1和模型2分别高出2.11%和11.29%,PA比模型1和模型2分别高出2.08%和0.23%。因此,模型3的裂缝检测效果最好,与定性分析结果相一致。此外,模型3训练时每次迭代的时间消耗最长,为0.490 4 s,表明“并联”组织模式的计算量要高于“串联”组织模式。
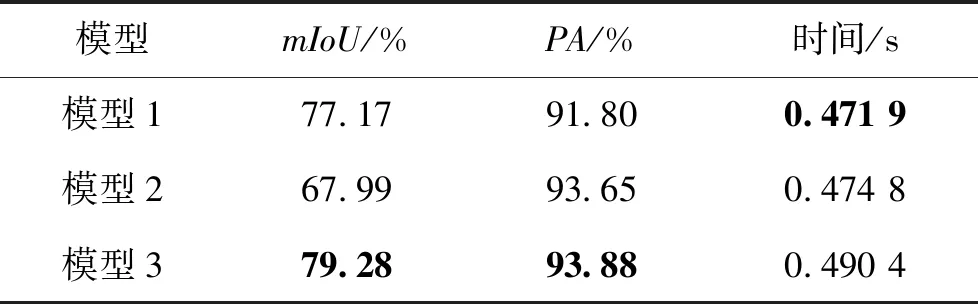
表1 CAM和SAM不同组织模式实验结果Table 1 Different organization model experimental results of CAM and SAM
为了证明Res-A模块的有效性,在Crack500数据集上进行了Res-A模块的消融实验,添加Res-A模块的模型选用效果最好的模型3,而NL-A注意力机制是本文网络内置的模块,因此不用对其进行消融实验。Res-A模块消融实验的定量对比结果如表2所示。可知,当添加Res-A模块时,mIoU和PA分别比未添加Res-A模块高出2.34%和3.01%,表明了Res-A模块对于整个网络的有效性。同时可以发现,未添加Res-A模块时,每次迭代耗费时间为1.294 9 s,是添加Res-A模块时耗费时间的2.64倍,表明Res-A模块除了可以循环提取特征外,还有缩小计算量的作用。

表2 Res-A模块消融实验对比结果Table 2 Comparison results of Res-A module ablation experiment
在Res-A模块不同组织模式的对比实验以及Res-A模块的消融实验之后,对其中的空洞卷积进行消融实验,定量对比结果如表3所示。使用普通卷积的mIoU和PA为72.63%和89.70%,比空洞卷积分别低6.65%和4.18%,表明空洞卷积可以较好地提升道路裂缝检测的性能。另外,使用普通卷积时的迭代时间为1.805 3 s,是使用空洞卷积的3.68倍,印证了空洞卷积可以降低网络模型计算量的特点。

表3 空洞卷积消融实验对比结果Table 3 Comparison results of dilated convolution ablation experiment
2.3 与其他深度学习神经网络对比实验
为进一步验证模型3的有效性,在公开道路裂缝数据集Crack500上,从定性和定量角度与FCN(fully convolutional network)(Long等,2015)、PSPNet(pyramid scene parsing network)(Zhao等,2017)、ICNet(image cascade network)(Zhao等,2018a)、PSANet(point-wise spatial attention network)(Zhao等,2018b)和DenseASPP(dense atrous spatial pyramid pooling)(Yang等,2018)等网络进行对比实验,测试设备均保持一致,实验结果如图7和表4所示。
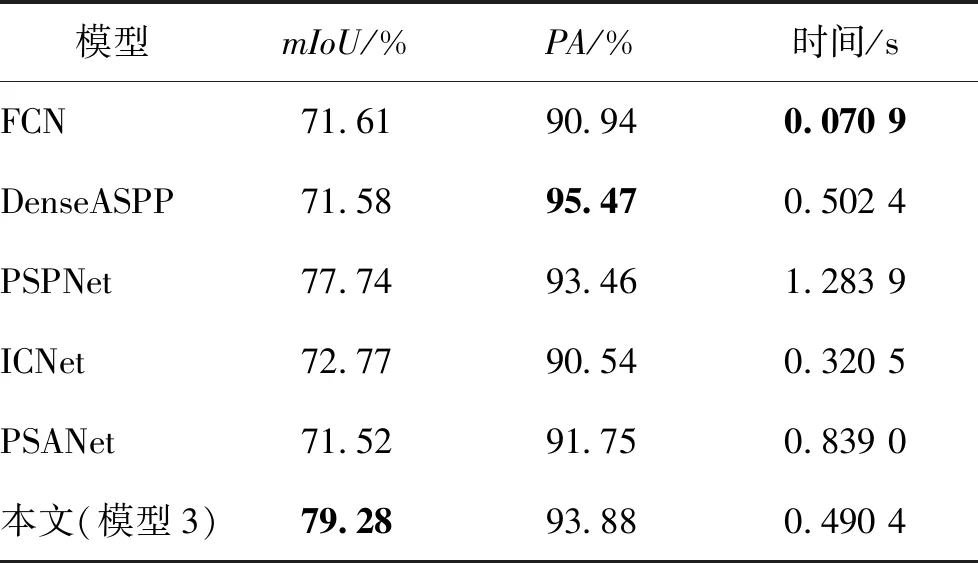
表4 不同深度神经网络评价指标对比Table 4 Comparison of evaluation indicators of different depth neural networks
从图7可知,各模型之间表现出较大差异。当图像中裂缝较细或背景干扰较小时(图7第1行),FCN和PSA检测出极少量裂缝(白色矩形框标出),PSPNet和ICNet检测出少量裂缝。仅DenseASPP和模型3可以较准确地检测出裂缝,但DenseASPP漏检较多,而模型3可以较好地检测出裂缝。当裂缝粗细适中且结构较为简单时(图7第2、3行),仅PSPNet和模型3可以较完整地检测出裂缝,其他各模型均出现了不同程度的漏检。相较于PSPNet,模型3漏检更少,检测结果更连续、更完整。当裂缝较粗且结构较为复杂时(图7第4—6行),如第4行所示,ICNet、PSPNet和DenseASPP出现了较为严重的漏检,PSPNet存在错检;如第5行所示,FCN、PSPNet、ICNet和PSANet错检较为严重,造成检测出的裂缝较粗且变形;如第6行所示,FCN、ICNet、PSANet和DenseASPP存在漏检,细节信息不足,造成检测出的裂缝不连续;而模型3在第4—6行只有较少的漏检和错检,检测效果较准确,细节信息更丰富,可以较好地保持裂缝的完整性。定性分析表明了模型3对道路裂缝检测的有效性。
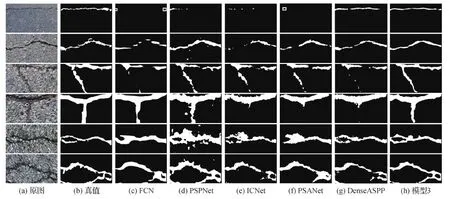
图7 不同深度神经网络裂缝检测示例Fig.7 Examples of crack detection with different depth neural networks((a)original images;(b)ground truth;(c)FCN;(d)PSPNet;(e)ICNet;(f)PSANet;(g)DenseASPP;(h)model 3)
从表4可知,模型3的mIoU最高,分别比FCN、PSPNet、ICNet、PSANet、DenseASPP高出7.67%、1.54%、6.51%、7.76%、7.70%,模型3的PA仅比DenseASPP低1.59%,分别比FCN、PSP-Net、ICNet、PSANet高出2.94%、0.42%、3.34%、2.13%。这充分表明了模型3在道路裂缝检测上具有较好的有效性。训练迭代时间表明模型排在第3位,虽然Res-A模块可以有效缩短训练时间,但双注意力机制网络整体上还是较为复杂。当外部软硬件设备配置较高时,在一定程度上可以忽略此评价指标。
3 结 论
针对背景复杂、干扰较多的道路裂缝图像检测性能较低问题,本文提出了一种结合双注意力机制的道路裂缝检测网络。主要结论如下:
1)首先采用基于带空洞卷积的骨干网络ResNet-101,改变下采样次数,获得较大感受野并且保持较高的特征图分辨率,在避免网络退化的同时可以保留更多的特征细节信息;然后通过残差模块与轻量型注意力机制构造Res-A模块以及引入NL-A模块,结合空间和通道之间的依赖关系,不断提高检测对象的关系权值,自适应学习更加有效的道路裂缝特征的信息表达,抑制其他特征的信息表达。
2)将本文网络在背景复杂、干扰较多的Crack500道路裂缝数据集上进行实验,采用mIoU和PA评估网络性能,证明Res-A模块中通道注意力机制和空间注意力机制并联相加时,道路裂缝检测效果最优。
3)与现有的一些典型网络进行对比实验,结果表明本文网络训练时间较短,模型性能更好,细节信息更丰富。
虽然本文网络取得了较好的道路裂缝检测效果,但还是存在一定程度的错检和漏检,主要是由于未考虑损失函数对模型性能的影响。因此,在未来,除了继续改进网络模型以外,还将使用合适的损失函数来进一步增强模型性能,如focal loss等,提升道路裂缝的mIoU和PA。
