非局部注意力双分支网络的跨模态赤足足迹检索
2022-07-15鲍文霞茅丽丽王年唐俊杨先军张艳
鲍文霞,茅丽丽,王年,唐俊,杨先军,张艳
1.安徽大学电子信息工程学院,合肥 230601;2.中国科学院合肥物质科学研究院,合肥 230031
0 引 言
足迹是指人体穿鞋、穿袜或赤足站立/行走条件下,脚掌通过体重压力作用在承痕体形成的痕迹(Gurney等,2008)。医学研究表明,足迹数据具有唯一性和独特性(Nirenberg等,2019),不仅能够反映个体的生理特征,还可以反映个体的行为特征。在侦查犯罪案件中,足迹特征相对于指纹和面部等其他人体特征来说更加不易伪装,刑侦人员可以从现场遗留足迹中挖掘到更多有效的信息和线索。因此,研究人员在足迹方面开展了形式多样的研究。Kulkarni和Kulkarni(2015)使用摄像机采集了30人的足底图像,提取足弓水平最小截距、足弓内侧最大距离、痕迹指数和痕迹几何指数等4种特征进行研究。Osisanwo等人(2014)使用捺印技术在纸板上印出足迹,比较分割后的前脚、中间和后脚3个部分的压力面积和压力值标准偏差并进行图像匹配。Khokher等人(2015)通过平板扫描仪获取了21人的足底图像,分别使用主成分分析(principal component analysis,PCA)和独立成分分析(independent components analysis,ICA)线性投影技术提取足底的纹理和形状特征来进行足迹识别,识别率分别达到95.24%和97.23%。Heydarzadeh等人(2017)使用压力传感器平面板采集了35人的足迹数据,将每帧图像叠加合成一幅融合图像,使用支持向量机(support vector machine,SVM)对融合图像进行分类识别,识别率达到97%。鲍文霞等人(2020a)使用光学足迹采集器采集134人的2 680枚足迹数据,通过度量学习方法,结合支持向量机分类器实现足迹识别,达到96.66%的准确率。朱明等人(2020)使用压力足迹采集器采集了100名受试者的1 000枚压力赤足足迹,通过多尺度自注意卷积模块自适应地提取可判别足迹特征,以实现足迹图像检索,其中mAP(mean average precision)值为81.64%,rank1值为95.63%。鲍文霞等人(2020b)使用压力足迹采集器构建了100人的2 000枚足迹图像,通过设计一种空间聚合加权模块,有效实现了足迹识别,其中算法准确率达到91.20%。
从上述足迹方面的研究可以看出,目前尚未存在公共的足迹图像数据集,并且在研究过程中的足迹图像采集规范和采集设备多样化,相同采集对象在不同采集设备下获取的足迹图像模态不同,而它们包含的信息既有共性又有各自的独特性。目前公安部门使用的足迹采集设备不统一,主要有光学和压力两种足迹图像采集仪。压力成像的足迹在图像中间或边缘都能比较准确地体现压力值的大小,压力变化层次丰富。光学成像的足迹压力值是通过算法估计得到的相对值,并且图像轮廓的边缘模糊、压力值不准确,但是光学足迹图像的这种特点更接近现场足迹。因此,通过压力和光学两种模态足迹图像的互检索,一方面可以使目前由不同设备采集构建的足迹库中的图像互查,另一方面也为下一步现场足迹比对、鉴定等应用提供了研究基础。
基于图像的跨模态检索方法主要包括子空间方法、主题模型方法、哈希变换方法和深度学习方法。子空间方法的原理是利用跨模态样本对的信息构建共享子空间,通过度量相似性实现跨模态检索(Liang等,2016),但存在不能有效建模不同模态的高阶相关性的问题。主题模型法是通过对各模态都学习一个潜在主题模型,再建模不同模态间的关系(Zheng等,2014),但在建立不同模态语义关联的同时未能综合考虑不同模态的结构。哈希变换法是将高维特征转换为便于存储和计算的二进制码,其中相似的数据会得到相似的二进制码,并将不同模态特征映射到一个汉明(Hamming)二值空间再进行学习(Cao等,2016),可能会造成图像信息上的损失。深度学习方法是利用能够学习到高层语义特征的神经网络为多个模态构造一个公共语义空间,减小跨模态的异构性,然后在公共空间进行模态之间的相似性度量(Wang等,2015),具有更好的检索效果,因此成为目前跨模态检索的研究热点。例如,在深度学习领域,Wu等人(2017)提出一个深度零填充网络来自适应地学习模态共享特性,实现了可见光行人图像与红外光行人图像之间的跨模态检索;Ye等人(2018a)引入了双流网络(two stream network)来建模特定的和可共享的信息,进行模态内和模态间的特征学习,实现了可见光行人图像与红外光行人图像的模态内和模态间的特征学习;Zhu等人(2019)提出了一个新的异质中心损失(hetero-center loss),以减少类内交叉模态的变化,再结合交叉熵损失和双分支结构,扩大类间差异和尽可能提高类内跨模态相似性,在红外光和可见光的跨模态行人重识别领域取得了较优的检索效果。
在行人重识别、草图识别以及图像、文本、声音及视频的多模态领域中,跨模态检索取得了一定进展,但关于足迹图像的跨模态检索方面的研究还很少。因此,本文根据赤足足迹图像的特点,结合深度学习方法研究足迹的跨模态检索问题。首先设计了人在自然行走状态下的足迹图像采集规范和流程,利用光学足迹和压力足迹图像采集仪器,采集并建立了一个包含138人的5 520枚赤足足迹的跨模态检索数据集。针对细粒度赤足足迹图像存在的类内差异大类间差异细微的特点,设计了一种基于非局部(non-local)注意力机制的双分支网络用于赤足足迹的跨模态检索,该网络在特征提取模块采用了双分支结构,各分支均采用ResNet50网络作为基础网络,提取不同模态的有效特征,过滤干扰特征;在特征嵌入模块通过参数共享构建一个多模态的共享空间,并在网络的layer2层和layer3层的每个残差块处引入非局部注意力机制模块,增强每个模态的有用特征,以得到更具辨别性的足迹特征,同时获取跨模态的共享特征空间;为了实现每个模态以及跨模态类间距离的最大化和类内距离的最小化,本文损失函数采用了交叉熵损失和三元组损失,以学习到更有效的跨模态共享特征。
1 足迹图像获取和预处理
本文使用光学足迹图像采集仪器和压力足迹图像采集仪器获取足迹图像。
光学足迹图像采集仪器由正面为脚踏面的等腰三棱镜、均匀直流光源和拍摄装置组成,采集时不需要在足底涂抹油墨,而是利用棱镜全反射原理形成足迹图像并由拍摄装置获取。光学足迹采集图像的分辨率为1 362 × 2 871 dpi(dots per inch)。光学足迹图像采集器及软件界面如图1所示。

图1 光学足迹图像采集仪器及软件界面Fig.1 Optical footprint image collector and its software interface((a)optical footprint image collector;(b)software interface)
从生物力学角度来看,压力足迹图像采集仪器可以获取采集者自然行走过程中的压力变化以及足迹特征等信息。该采集器的性能稳定,能够较好地保证采集图像的质量。压力足迹图像采集器及软件界面如图2所示。表1给出了采集仪器的主要技术参数,其中采集频率为100 Hz,可以满足人体行走时图像采集的要求;传感器密度为25个/cm2;幅面为50 cm×30 cm的有效区域,便于清晰地观察采集的压力图像。压力足迹采集图像的分辨率为250×150 dpi。

图2 压力足迹图像采集仪器及软件界面Fig.2 Pressure footprint image collector and its software interface((a)pressure footprint image collector;(b)software interface)

表1 压力图像采集仪器主要参数Table 1 Parameters of pressure footprint image collector
1.1 足迹数据采集流程
本次实验总共采集了138人的光学赤足图像和压力赤足图像,其中男性90人,女性48人。数据采集前,首先在系统中录入被采集人员的身高、体重等个人基本信息。表2给出了被采集人员的基本信息分布。

表2 被采集人员的信息分布Table 2 Information distribution of the person to be collected
在图像采集过程中,可能会受到灰尘、仪器噪声以及被采集人员脚部的施力状态和行走姿势等因素的影响。为了提高采集的规范性,采集过程要求采集仪器表面保持一定的清洁。足迹是体现人体心理的重要载体,心理活动与足迹之间有着必然的联系(薛亚龙和岳佳,2012),被采集人员的心理活动也会影响采集数据的质量。因此,采集人员会提前向被采集者介绍采集内容和方式,然后向被采集者示范正确的采集规范。具体的采集流程如下:
1)将采集仪器水平嵌入地板槽内,保持仪器与地面持平。随后打开电源连接设备进行测试,确认设备无误后,根据被采集者信息和采集方式建立文件夹,例如“学号_行走趟数_左脚”。为了达到采集标准,在光学足迹和压力足迹正式采集前预留足够时间,要求被采集人员行走多趟适应地面环境以达到自然行走状态。然后点击“采集”按钮,并示意被采集人员按示范的标准开始行走。
2)在被采集人员平稳自然行走经过采集仪器时,查看生成的图像是否存在缺损严重、偏离采集页面中心以及行走速度过快等问题,若有则重新采集,以提高采集图像的质量;如果被采集者和采集的图像满足采集规范,则将图像数据保存到事先建立好的个人文件夹中。
3)为了维持采集设备的性能稳定性,每天在早中晚3个时间段只采集两个人的赤足足迹图像,并在每次采集后进行仪器表面的清理,减少采集图像的背景噪声。
正式采集时,被采集人员在赤足条件下自然地来回走过采集仪器10趟,得到20幅赤足足迹图像,其中左右脚图像各10幅,最终共采集5 520幅赤足足迹图像,其中光学赤足图像和压力足迹图像各有2 760幅。图3展示了3个不同被采集人员在每种模态下的6幅赤足足迹图像,其中左右脚图像各3幅。由于被采集人员的身高、体态以及行走习惯等因素,被采集人员的光学和压力足迹在形态以及图像中的具体分布位置等方面存在很大差异;同时,在单模态内同一个被采集人员的图像存在较大差异,而不同被采集人员之间的图像差异细微,导致跨模态赤足足迹检索难度显著提升。

图3 采集的光学赤足图像和压力赤足图像Fig.3 Collected optical barefoot images and pressure barefoot images ((a) the collected person A;(b) the collected person B;(c) the collected person C)
1.2 足迹数据预处理
采集的光学赤足图像中含有标尺部分,并且在采集的过程中受灰尘等因素的影响,从而产生少量噪声,因此首先对采集的赤足足迹图像进行去标尺和滤波等预处理。在去噪方法中最常用的是中值滤波(赵博文 等,2020),因为中值滤波可以保留图像轮廓信息,更能起到保护图像细节信息的作用,因此本文采用中值滤波方法分别对光学赤足图像和压力赤足图像进行去噪处理,并在足迹图像送入网络训练之前将分辨率统一调成了224 × 224 dpi。光学赤足图像和压力赤足图像的预处理分别如图4和图5所示。为了提升网络模型的泛化能力和鲁棒性,对采集图像进行了垂直翻转、水平翻转、逆时针旋转10°和顺时针旋转10°的数据增广,光学赤足图像和压力赤足图像的增广操作分别如图6和图7所示。经扩充后,光学赤足图像和压力赤足图像分别从2 760幅扩展为13 800幅。

图4 光学赤足图像的预处理效果图Fig.4 Preprocessing of optical barefoot images ((a) optimal original image;(b) after removing the scale;(c) after filtering)

图5 压力赤足图像的预处理效果图Fig.5 Preprocessing of pressure barefoot image ((a) pressure original image;(b) after filtering)

图6 光学赤足图像的数据增广效果图Fig.6 Data augmentation of optical barefoot images ((a) filtering;(b) vertical flipping;(c) horizontal flipping;(d) rotating 10 degrees counterclockwise;(e) rotating 10 degrees clockwise)

图7 压力赤足图像的数据增广效果图Fig.7 Data augmentation of pressure barefoot images ((a) filtering;(b) vertical flipping;(c) horizontal flipping;(d) rotating 10 degrees counterclockwise;(e) rotating 10 degrees clockwise)
2 基于非局部注意力的双分支网络
2.1 网络总体结构
采集的光学赤足图像纹理信息较为完好,但是边缘模糊,压力值不准确;采集的压力赤足图像的轮廓较为清晰,压力变化对比鲜明,重压面区域较清晰。由于不同模态足迹图像的特征之间既有共性又有各自的独特性,且赤足足迹图像属于细粒度图像,不同个体赤足足迹图像差异细微,而同一个体由于受环境、心理以及走路姿态等影响使得足迹图像差异较大,即存在较大的类内差异和较小的类间差异。针对足迹图像的这些特点,本文设计了一个双分支卷积神经网络用于跨模态赤足足迹图像的检索。整个网络包含特征提取(feature extractor)、特征嵌入(feature embedding)和双约束损失(dual-constrained loss)3个模块,如图8所示。其中特征提取模块采用两个分支分别用于提取不同模态赤足图像的特征;在特征嵌入模块中,将特征提取模块输出的各模态特征进行拼接(concat)实现参数共享,以构建一个多模态的共享空间,同时引入非局部注意力机制(Wang等,2018),快速捕获长范围依赖,获得更大感受野,专注赤足图像整体压力分布,从而学习到更优的压力分布多模态共享特征;为了增大赤足图像特征的类间差异和减小类内差异(Wang等,2019),减小光学模态与压力模态图像的语义鸿沟,在双约束损失模块引入交叉熵损失(cross-entropy loss,CE loss)和三元组损失(triplet loss,TRI loss)进行网络优化。

图8 跨模态足迹检索网络结构Fig.8 The network architecture of cross-modal retrieval for footprint images
2.2 特征提取模块
在深度学习领域,随着网络深度的增加,可能会伴随梯度消失或梯度爆炸等问题,不利于网络的收敛优化。常用的ResNet50网络(He等,2016)通过短接操作构建了恒等映射,使原始粗略的特征与训练后得到的精细化特征相互补充融合,可以突出有用特征,过滤掉一些无用特征。同时ResNet50网络的学习过程是去拟合残差,不是直接拟合输入和输出,优化更加简单,不仅能够学习有效的足迹特征,还使得梯度反向传播时,更加不容易出现梯度消失等问题。因此本文采用经过预训练的ResNet50网络作为双分支结构中的每个单分支的基础网络。
ResNet50的网络结构图如图9所示,特征提取模块由ResNet50网络的layer1层之前的卷积层(convolution layer,Conv)、批量正则化(batch-normalization,BN)、ReLU(rectified linear unit)激活函数以及最大池化(max pooling,MaxPool)构成,分别提取光学赤足图像的特征和压力赤足图像的特征。

图9 ResNet50网络结构图Fig.9 The network structure of ResNet50
2.3 特征嵌入模块
将特征提取模块输出的各模态特征拼接(concat)后送入特征嵌入模块,用于构建多模态的共享空间。为了获取更加充分全面的共享特征信息,特征嵌入模块由ResNet50中的layer1—layer4层构成,同时在layer2层和layer3层的每个残差块处都引入了非局部注意力模块(Wang等,2018)。
在常规的卷积操作输出特征图中,每个空间位置的输出值由输入特征图和卷积核在局部范围内进行对应元素相乘再相加获得,而non-local注意力机制在计算每个空间位置输出时,不是仅考虑局部元素,而是与图像中所有空间位置计算相关性,并将相关性作为权重以表征当前空间位置与其他空间位置的相似度。通过关注所有空间位置并取其加权平均值作为当前空间位置的响应值,从而增强赤足足迹图像中的有效特征。同时,非局部注意力机制的输入尺度多样化,易与其他基础网络模型相结合。如图8所示,本文在ResNet50基础网络的layer2和layer3中每个残差块处都引入了non-local注意力机制,该注意力机制的完整表达式为
zi=Wzyi+xi
(1)
式中,i是输出特征图的空间位置索引,xi表示空间位置i处的输入特征向量,yi是对所有空间位置进行加权学习全局信息的特征向量,形状与xi相同,Wz表示训练过程中输出特征向量z的学习参数。其中yi的表达式为
(2)
式中,j表示所有空间位置的索引,g(xj)表示进行信息变换的一元输入函数,C(x)为保证变换前后整体信息不变的归一化函数,f(xi,xj)表示特征图中空间位置i与空间位置j之间的相似度权重关系函数,f(xi,xj)的表达式为
f(xi,xj)=θ(xi)Tφ(xj)
(3)
式中,θ(xi)表示用1 × 1卷积学习当前位置的信息,φ(xj)表示用1 × 1卷积学习全局信息。通过将θ(xi)的转置与φ(xj)进行矩阵相乘操作,计算位置i与位置j的相似度大小。
该注意力机制的实现细节如图10所示。其中,x表示形状为[b,c,h,w]的特征向量,b表示每个模态的批量处理数目,c表示特征图的通道数,h和w分别表示特征图的高度和宽度。对x经过1×c×1×1卷积(输入通道为c,输出通道为1的1×1卷积)操作,得到形状为[b,1,h,w]的特征向量fea1。fea1经过变维操作1后得到形状为[b,h×w,1]的特征向量,记为g(x);fea1经过变维操作2后得到两个形状均为[b,1,h×w]的特征向量,分别记为θ(x)和φ(x),将θ(x)的转置与φ(x)进行对应元素相乘,得到f(xi,xj);经过1/N(N=h×w)得到归一化的特征向量,与g(x)进行对应元素相乘的加权操作,并经过变维操作3得到形状为[b,1,h,w]的特征向量fea2;然后通过c×1×1×1卷积(输入通道为1,输出通道为c的1×1卷积)操作和BN正则化操作,输出与x形状相同的特征向量。最后将y与原始输入特征向量x进行对应元素相加,从而学习到更有关联的共享特征z,减小了模态间的特征差异。
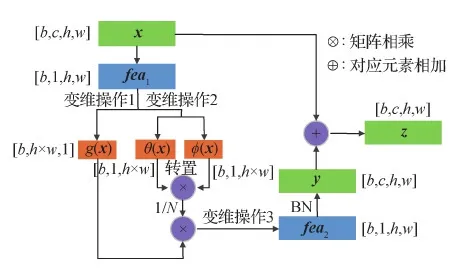
图10 Non-local 注意力模块原理图Fig.10 The schematic diagram of non-local attention module
2.4 双约束损失模块
为了能够同时考虑到模态内和模态间的特征差异,使网络学习到更好的跨模态共享特征,本文损失函数采用交叉熵损失和三元组损失双约束方式进行网络优化。损失函数具体结构如图11所示,其中光学足迹特征和压力足迹特征为图8中特征提取模块输出的光学模态特征向量和压力模态特征向量,通过在第1维度上concat后得到fea1特征向量,再依次经过ResNet50的layer1、layer2、layer3、layer4,以实现特征嵌入模块中的参数共享。为获得更有辨别性的模态特征,学习到一个更好的模态共享空间,本文在layer2和layer3中的每个残差块处引入non-local注意力机制进行训练,将最后输出的特征向量经过两种不同处理分别得到交叉熵损失(CE loss)和三元组损失(TRI loss)。本文总的损失函数为
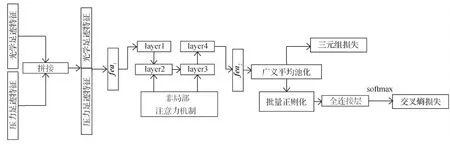
图11 损失函数结构图Fig.11 Structure diagram of loss function
Ltotal=LCE+LTRI
(4)
式中,LCE为交叉熵损失,LTRI为三元组损失。
交叉熵损失是利用特定模态信息学习类别特征,并对各模态的类内特征进行约束,使类间差异增大,同时也有助于增加跨模态样本的相关性(Ye等,2018b)。如图11所示,将由广义平均池化(generalized mean pooling,GmPool)操作产生的特征向量,经过正则化(BN)、全连接层(FC1)和softmax函数,结合标签计算得到交叉熵损失,其中正则化可以在一定程度上提升网络训练速度,加快收敛过程。
交叉熵损失(CE loss)计算为
(5)
式中,i表示样本索引,K表示2 × batch_size,其中batch_size为网络训练的超参数,本文设置batch_size为16;j表示类别索引,n表示总的类别数,本文设置n为82;xi为第i个样本的特征向量,yi表示样本i的真实类别,wj表示权重的第j列,wyi表示权重的第yi列,byi表示偏置的第yi列。该损失值越小,表示预测概率分布与真实概率分布之间的差异越小。
三元组损失(Liu等,2020)通过在跨模态共享空间中促使每幅足迹图像与相同类别图像之间的距离小于其与不同类别图像之间的距离,以进一步解决图像检索中类内距离大于类间距离的问题。如图11所示,将经过池化层GmPool的特征向量,结合每个模态的标签计算可得到三元组损失。
三元组损失(TRI loss)计算为
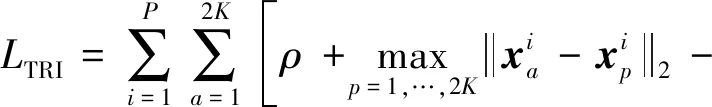
(6)

3 实 验
3.1 实验环境
实验所用计算机带有两块NVIDIA 2070ti,系统环境为Linux操作系统,网络模型均在PyTorch中搭建。本文应用sampler方式选取训练图像,各模态赤足图像在每次迭代时的批处理大小均设置为16,其中随机选择4个不同类别,每个类别对应4幅不同的图像。同时各模态赤足图像在每次迭代时选取的类别须对应。图像尺寸设置为224 × 224像素,并采用翻转、旋转等预处理操作。损失函数使用交叉熵损失(CE loss)和三元组损失(TRI loss)进行双约束。优化器采用随机梯度下降法(stochastic gradient descent,SGD)对网络进行训练,初始学习率设置为0.01,训练轮数在[0,9]范围内时学习率按0.01进行增加,训练轮数在[10,20)范围内时学习率为0.1,训练轮数在[20,50)范围内学习率为0.01,训练轮数在[50,80]范围内时学习率为0.001。本算法共训练81个epoch。
3.2 评价指标
本文选用Dai等人(2019)和Zhao等人(2019)采用的评价指标评估赤足图像跨模态检索的性能,包括mAP和CMC(cumulative match characteristic curve)中的rank1(R1)、rank5(R5)和rank10(R10)。rank1表示首位检索到的概率,相较于其他rank值使用更为广泛。为进一步验证本文算法对赤足足迹图像跨模态互检索的有效性,实验过程中将两种检索模式下的mAP均值(mAP_Avg)和rank1均值(R1_Avg)也同时作为评价指标。其中mAP_g2y和R1_g2y分别表示光学到压力检索模式下的mAP值和rank1值,mAP_y2g和R1_y2g分别表示压力到光学检索模式下的mAP值和rank1值。
3.3 数据集的划分
实验数据集划分为训练集、验证集和测试集。其中,训练集包含82人,验证集包含28人,测试集包含28人,人数比例为6 ∶2 ∶2。为了保证实验的公平性和有效性,须保证训练集、验证集和测试集的类别和图像各不交叉重叠。训练集包括82人的8 200幅光学赤足图像和8 200幅压力赤足图像。验证集包括两种检索模式,一种是根据光学图像检索压力图像,另一种是根据压力图像检索光学图像。同时将查询集和检索集的数据量比例设置为1 ∶2,即查询集中每人50幅图像,检索集中每人100幅图像。测试集的图像数目分布与验证集相同。在每轮训练结束后都对验证集进行性能评测,得到mAP和rank值,并且按照rank1最高值保存最优模型。为证明模型的有效性,最终运用保存的最优模型对测试集进行性能评测,记录和保存最后的实验结果数据。
3.4 实验结果及分析
本文设计了基于非局部(non-local)注意力双分支网络架构的跨模态赤足足迹检索算法。对比实验包括以下4个方面:1)non-local注意力机制对检索性能的影响;2)采用不同损失函数的对比;3)特征嵌入模块后采用不同池化方法的对比;4)将本文算法与跨模态检索领域的FGC(fine-grained cross-media)方法以及跨模态行人重识别领域的HC(hetero center)方法进行比较。
3.4.1 非局部注意力机制对检索性能的影响
为验证本文算法中non-local注意力机制对足迹图像跨模态检索性能的影响,对网络是否使用non-local注意力机制以及将该注意力机制应用在ResNet50网络的不同位置进行对比分析,实验结果如表3所示。其中Non0、Non23、Non146和Non46分别表示不使用non-local注意力机制和将non-local注意力机制应用在ResNet50网络的不同残差块上的4种实验方法,Non46为本文方法。ResNet50网络在layer1、layer2、layer3和layer4上的残差块数目分别是3、4、6和3。Non23表示注意力机制应用在layer2层中的后2个残差块和layer3层中的前3个残差块;Non46表示注意力机制应用在layer2层中的4个残差块和layer3层中的6个残差块;Non146表示注意力机制应用在layer1层中的最后一个残差块、layer2层中的4个残差块和layer3层中的6个残差块。实验结果表明,Non46方法的效果最优,其中mAP_Avg和R1_Avg分别达到83.95%和96.5%,相较于Non0,分别高出0.63%和0.78%;相较于Non23,分别高出0.72%和0.07%;相较于Non146,分别高出1.66%和0.21%。
表3中Non0方法的mAP_Avg和R1_Avg分别为83.32%和95.72%,Non23、Non46和Non146方法的R1_Avg均高于Non0,但Non23和Non146方法的mAP_Avg比Non0低0.09%和1.03%,仅本文采用的Non46方法的mAP_Avg比Non0高出0.63%。上述结果说明,该non-local注意力机制通常可以在一定程度上帮助网络更好地进行跨模态检索的特征学习,进一步提高检索精度。同时,non-local注意力机制应用在ResNet50网络的具体位置会影响最终的检索结果。
Non23和Non46方法皆是将注意力机制应用在ResNet50的layer2层和layer3层,区别仅在于具体应用的残差块上。表3中的实验结果比较直观地体现了相同层不同残差块上的检索效果差异。其中,Non46方法的mAP_Avg和R1_Avg分别比Non23高0.72%和0.07%,说明将注意力机制应用在layer2层和layer3层的所有残差块可以进行远距离深层次的信息交互(Wang等,2018),更有利于本文针对跨模态检索的研究。
表3中Non146方法的mAP_Avg和R1_Avg分别为82.29%和96.29%,相较于最优实验效果的Non46方法降低了1.66%和0.21%。该实验结果表明在layer1层引入non-local注意力机制不利于跨模态特征的学习,与layer1层学习到的浅层足迹信息相比,layer2层和layer3含有更为丰富的细节信息,使得non-local注意力机制能够捕获更具辨别性的特征。

表3 本文算法中non-local注意力机制对检索性能的影响Table 3 The effect of non-local attention mechanism in the algorithm on retrieval performance /%
3.4.2 不同损失函数的对比实验
实验对网络采用的损失函数进行对比,结果如图12所示。CE表示仅使用交叉熵损失,TRI表示仅使用三元组损失,CE_TRI表示交叉熵损失和三元组损失的双约束损失。实验结果表明,使用交叉熵损失(CE loss)和三元组损失(TRI loss)的双约束损失下检索效果最优,mAP_Avg值为83.95%,R1_Avg值为96.5%,相较于仅使用CE损失分别提高了7.93%和3.46%;相较于仅使用TRI损失分别提高了30.84%和17.96%。

图12 采用不同损失函数的结果柱状图Fig.12 Histogram of results using different loss functions
交叉熵损失衡量的是实际输出与期望输出之间的差异大小。差异越大,参数调整得越快,收敛速度也越快。虽然三元组损失可以针对细粒度赤足足迹图像的特点实现增大类间距离且减小类内距离,但仅使用三元组损失而省略交叉熵损失,在一定程度上加大了训练难度。从图12中对比数据可知,只采用TRI时,mAP_Avg值为53.11%,R1_Avg值为78.54%,相较于CE损失,分别降低了22.91%和14.5%。因此,在本文研究任务上,交叉熵损失的实验效果更优于三元组损失。而本文采用双约束损失CE_TRI,融合了CE损失和TRI损失的优点,均优于仅使用CE损失或仅使用TRI损失的实验效果。
3.4.3 特征嵌入模块后采用不同池化方法的对比
为验证不同池化方法对检索性能的影响,本文分别在特征嵌入模块后采用3种池化方法进行对比分析,即最大池化(MaxPool)、平均池化(AvgPool)和广义平均池化(GmPool)。该对比实验结果如图13所示,其中横坐标为3种不同池化方法的检索精度。从对比数据可以看出,采用广义平均池化效果最好,mAP_Avg和R1_Avg分别为83.95%和96.5%,相较于最大池化分别提高了4.79%和2.18%;相较于平均池化分别提高了3.07%和1.46%。
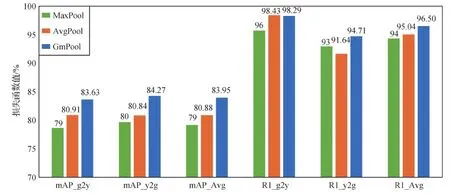
图13 特征嵌入模块后采用不同池化方法的结果柱状图Fig.13 Histogram of results adopting different pooling methods after the feature embedding module
3.4.4 与其他跨模态检索方法的比较
为了验证本文算法的有效性,在本文采用的赤足足迹数据集上,分别与跨模态检索领域提出的具有代表性的FGC方法(He等,2019)和HC方法(Zhu等,2019)进行对比分析。FGC的研究对象是细粒度图像及其对应的文本、声音和视频的多模态数据,取得了一定的跨模态检索效果;HC的研究对象分别是三通道彩色图的可见光行人图像和单通道灰度图的红外光行人图像,也取得了不错的效果。实验结果如表4所示。结果表明,本文算法效果最优,mAP_Avg、R1_Avg、R5_Avg和R10_Avg值分别为83.95%、96.50%、98.13%和98.74%,相较于FGC分别高出40.01%、36.50%、20.42%和16.1%;相较于HC分别高出26.07%、19.32%、20.95%和6.81%。

表4 本文算法与FGC和HC方法的结果对比Table 4 Comparison of results among FGC,HC and ours /%
FGC是将每个模态原始输入样本在第1维度上进行拼接后再经过一个单分支ResNet50网络进行多模态的学习,损失函数采用交叉熵损失和中心损失,以实现各模态类别的分类以及增加各模态中同类别特征的紧致性,但是该中心损失仅有益于拉近同模态的类内特征距离,忽略了跨模态的类内之间的距离。
HC方法采用的也是双分支网络架构,损失函数包括交叉熵损失和异质中心(hetero-center)损失。其中,异质中心损失通过拉近跨模态同类别样本的中心距离减少跨模态类内差异,但是由于双分支网络结构的复杂性以及嵌入模块位于网络的后端,难以有效地学习跨模态赤足足迹特征。
本文设计的跨模态赤足足迹检索算法采用双分支网络,结构简单,有助于网络学习到不同模态的足迹特征。同时,运用non-local注意力机制获取更有辨别性的特征,采用交叉熵损失和三元组损失的双约束方式,考虑到了模态内和模态间的特征差异问题,对整个网络进行有效优化,在赤足足迹图像的跨模态检索任务上,相较于FGC方法和HC方法,具有更高效的跨模态检索性能。
4 结 论
足迹检索在犯罪案件侦查、身份识别等领域发挥着重要作用。针对目前足迹检索中采集设备种类多样化的问题,本文以光学和压力赤足足迹为研究对象,构建了138人的光学和压力赤足足迹图像数据库,提出一种基于细粒度足迹图像的非局部注意力双分支网络模型,对赤足足迹图像的跨模态互检索问题进行了研究。该模型由特征提取、特征嵌入和双约束损失3个模块组成。在特征提取模块的各个分支上均采用ResNet50作为基础网络进行足迹有效特征的学习。为了减小跨模态的异构性,在特征嵌入模块通过参数共享以学习到一个多模态的共享空间。同时,为了获得更有辨别性的多模态足迹特征,该模型在网络的layer2层和layer3层的所有残差块上采用了non-local注意力机制,用于学习特征图中每个空间位置与所有空间位置之间的相似度权重关系,从而增强足迹有用特征,同时突出跨模态的共享特征。为了增大不同类别之间差异和减小相同类别之间的差异,本文算法还采用了交叉熵损失和三元组损失的双约束损失进行网络优化。
在跨模态赤足足迹数据集上的实验结果验证了本文采用的non-local注意力机制、不同损失函数和在特征嵌入模块后采用不同池化方法对跨模态赤足足迹检索效果较好。同时,与细粒度图像的跨模态检索方法FGC和跨模态行人重识别方法HC在足迹数据集上的实验效果进行对比分析,结果表明,本文方法的mAP和rank1指标均取得最优效果。
由于本文主要采用注意力机制构造一个跨模态共享空间,且针对的研究对象是基于光学和压力两个模态的赤足足迹图像,所以未来考虑使用对抗网络学习更有效的足迹特征。下一步将考虑在穿鞋、穿袜和捺印等其他模态足迹图像中,利用对抗网络中的生成器和判别器,更好地解决模态内和模态间的特征差异问题,进一步提升跨模态检索精度。
