融合时空域特征的人脸表情识别
2022-07-15陈拓邢帅杨文武金剑秋
陈拓,邢帅,杨文武,金剑秋
浙江工商大学计算机与信息工程学院,杭州 310018
0 引 言
面部表情提供了丰富的情感信息,是人们内心情感状态最直接和自然的一种传达方式(Li和 Deng,2020)。人脸表情识别在教育质量监督(Whitehill等,2014)、医疗应用(Gutierrez,2020)、人机交互(Vinciarelli等,2009)和自动驾驶等诸多领域有着广阔的应用前景,因此逐渐成为相关领域的一个研究热点。人脸表情的产生对应着一个连续的面部肌肉运动过程。多数已有的人脸表情识别方法主要针对该运动过程中的表情峰值帧,通过分析和提取该帧人脸图像中的表情空间特征信息来识别其中的面部表情。为了利用面部表情的运动信息,一些方法通过分析人脸表情的视频序列,希望从中提取出的人脸表情特征不仅包含了每帧图像中的表情“空域信息”,并且也包含了连续帧之间的表情“时域信息”,从而实现表情识别性能的有效提升(Zhao等,2018;Zhang等,2017;Hasani和Mahoor,2017;Kumawat等,2019)。但是,视频序列邻接帧中的表情空域信息具有一定的连贯性和冗余度,这种冗余性不仅造成了信息浪费,也加大了有效信息的提取和分辨难度(Zhao等,2018);此外,面部表情的运动变化可以认为是人脸关键组件(如眉毛、眼睛、鼻子和嘴巴等)的动态变化组合,而直接分析图像序列无法有效利用人脸关键组件的先验知识,因而不利于人脸表情时域信息的提取。
针对上述问题,提出了一种融合时空域特征的深度学习神经网络,以高效鲁棒地分析和理解视频序列中的面部表情空域和时域信息。该网络主要包含两个特征提取模块,分别用于学习单幅表情峰值图像中的表情静态“空域特征”和视频序列中的表情动态“时域特征”。此外,该网络还包含一种微调融合策略,该策略取得了最优的时域特征和空域特征融合效果,有效提升了人脸表情的识别性能。
对于单幅表情峰值图像,个体差异以及光照、遮挡和头部姿势等外在干扰因素都会与其中的表情特征非线性耦合在一起,使得鲁棒提取图像中的表情特征极具挑战性(Liu等,2017)。基于三元组的深度度量学习技术是一种有效的表情特征学习方法,它可以使得相同表情类别的样本在特征空间中相互靠近,而不同表情类别的样本在该空间中互相远离,最终学习得到能够有效表达表情变化的潜特征(latent features)。在实验中观察到,三元组损失函数中的阈值可以在一个范围内有效变化,并且每个阈值本质上对应着一个不同的类间差异分布,如图1所示。因此,在“空域特征”学习模块中,提出了一种基于三元组的深度度量融合技术,通过在三元组损失函数中采用不同的阈值,从单幅表情峰值图像中学习得到多个不同的表情特征表示,并将它们组合在一起,最终形成了一个鲁棒的且更具识别能力的表情特征。

图1 基于不同三元组阈值学习得到的特征所进行的类间变化分布可视化Fig.1 Distributions of inter-class variations with respect to the features learned by the triplet loss with different margins
考虑到面部表情是由一些关键区域肌肉运动产生的,而这些区域的运动可由面部关键点的运动轨迹变化来表示,因此在“时域特征”提取模块中采用了简单的2维卷积神经网络(convolutional neural networks,CNN),通过分析视频序列中的面部关键点轨迹,学习得到表情的时序动态变化特征。此外,为了有效提升人脸表情的识别性能,还需要考虑如何有效融合上述两个模块中学习得到的空域特征和时域特征,使得这两个特征在表情识别任务中能够最大化地互为补充。通过大量实验,测试了各种可能的融合策略,最终提出了一种所谓的“微调融合策略”,取得了最优的时空域特征融合效果。主要贡献如下:1)提出了一种融合时空域特征的深度学习神经网络。该网络通过分析单幅表情峰值图像和视频序列中的面部关键点轨迹,有效提取了视频序列中的面部表情空域和时域特征。2)设计了一种基于三元组的深度度量融合技术。不同于传统的三元组度量学习仅使用单个阈值,该技术使用了多个阈值,不仅避免了费时的最优阈值的选取,并且有效提升了提取特征的鲁棒性和可分辨能力。3)提出了一种微调融合策略,取得了最优的时域特征和空域特征融合效果。4)该方法有效提升了人脸表情的识别性能,在3个公开的基于视频序列的人脸表情数据集CK+(the extended Cohn-Kanade dataset)(Lucey等,2010)、MMI(the MMI facial expression database)(Pantic等,2005)和Oulu-CASIA(the Oulu-CASIA NIR&VIS facial expression database)(Zhao等,2011)上均接近或超越了此前其他各类表情识别方法的性能。
1 相关工作
通常认为生气、高兴、恐惧、厌恶、悲伤和惊讶等6种基本情感在不同文化中具有共通性,因此人脸表情识别研究通常根据这些情感对表情进行分类(Ekman和Friesen,1971)。根据输入特征表示的不同,人脸表情识别方法大致可以分为基于图像的方法和基于视频序列的方法两类(Zeng等,2009)。已有的研究大多属于基于图像的表情识别方法(Liu等,2017;Acharya等,2018;Yang等,2018),主要考虑单幅表情峰值图像中的表情静态“空域特征”。基于视频序列的表情识别方法则进一步考虑了表情生成过程中的面部运动信息(Zhang等,2017;Hasani和Mahoor,2017;Kumawat等,2019),即所谓的表情动态“时域特征”,因而通常能够更加有效地完成表情识别任务。
1.1 基于手工设计特征的传统方法
为了在视频序列中提取面部表情的时序特征,研究人员将基于图像的传统手工特征扩展到连续的视频帧特征,提出了LBP-TOP(local binary patterns from three orthogonal planes)(Zhao和 Pietikainen,2007)、3D-HOG(3D-histogram of oriented gradients)(Klaser等,2008)以及3D-SIFT(3D-scale-invariant feature transform)(Scovanner等,2007)等方法。Jain等人(2011)使用条件随机场和手工创建的形状外观特征对每个面部形状进行时间建模。Taini等人(2008)则提出了一种纵向地图结构,在Oulu-CASIA数据库上实现了较好的识别性能。Wang等人(2013)通过一种间隔时序贝叶斯网络,捕获了面部肌肉之间复杂的时空关系。Ptucha 等人(2011)提出了一种基于流形的稀疏表示,通过使用基于监督的局部保形投影来映射低维流形中的特征,进而实现表情识别。Sikka等人(2016)提出了基于潜序数模型的视频表情识别,使用弱监督分类器将面部关键点的SIFT和LBP特征进行整合,并将表情作为潜变量进行学习。
虽然已有的研究工作设计了各种各样的手工特征来提取表情的时空信息并对其进行分类,但是基于深度卷积神经网络的人脸表情识别方法越来越流行,相比于基于手工设计特征的传统方法,显著提升了表情识别性能。
1.2 基于深度学习的表情识别方法
近年来,深度卷积神经网络逐渐主导了各种计算机视觉任务。例如图像分类(Simonyan和 Zisserman,2015)、目标识别(Ren等,2017)和物体分割(Shelhamer等,2017)等。对于视频序列中的人脸表情识别任务,基于深度学习的网络模型也取得了诸多最新研究成果。Jung等人(2015)提出一种使用DTAN(deep temporal appearance network)和DTGN(deep temporal geometry network)两个深度神经网络的方法。DTAN网络是一个简单的3D卷积神经网络,用于从视频序列中捕获表情的时空信息;DTGN网络是一个由全连接层构成的浅层网络,用来捕获面部关键点的时序运动变化。通过对这两个网络进行同时微调,该方法获得了当时最先进的表情识别性能。Zhang等人(2017)进一步改进了Jung等人(2015)的方法,提出了一个空间网络MSCNN(multi-signal convolutional neural network)和一个时间网络PHRNN(part-based hierarchical recurrent neural network),其中MSCNN对应着一个基于单幅表情峰值图像的简单卷积神经网络,用于学习表情的空间信息,而PHRNN则由几层循环神经子网络(recurrent neural network,RNN)构成,用于学习视频序列中的表情时间信息。此外,Zhang等人(2017)还提出了一种排序融合策略,以有效融合这两个网络学习得到的表情时空特征。为了更好地学习视频序列中的表情时空特征,Hasani和Mahoor(2017)将面部关键点和残差单元的输入张量相乘替换原始3D Inception-ResNet中的残差结构。Kumawat等人(2019)提出了一种称为局部二值体的3D卷积层对图像序列上的面部表情进行识别。Deng等人(2019)提出可以同时捕获微观和宏观运动的双流循环网络,以此改善基于视频的情感识别性能。
本文方法的基本思想与Zhang等人(2017)方法相似,提出的融合时空域特征的深度学习神经网络主要包含两个特征提取模块,分别用于学习单幅表情峰值图像中的表情静态“空域特征”和视频序列中的表情动态“时域特征”,但与Zhang等人(2017)及其他方法相比,有以下3方面的区别:1)一般的表情识别网络均使用softmax损失作为训练监督函数,虽然从中提取的CNN特征具有一定语义,但是它们与表情含义并没有直接关联,这是因为softmax损失函数并没有显式地考虑类内的紧凑和类间的分离。提出的基于三元组的深度度量融合技术不仅能够学习得到有效表达表情变化的语义特征,并且相比于传统的三元组度量学习,这些特征更加鲁棒且更具识别能力。2)循环神经网络一般具有更高的学习和训练难度,因此使用了简单的2维卷积神经网络,通过分析视频序列中的面部关键点轨迹,学习得到表情的时序变化信息。3)一般情况会使用特征级别或者决策级别的融合方式来组合多个网络的学习结果,但是不同的网络模型具有不同的学习能力且学习到的特征也不尽相同,简单的融合方式有时不仅无法实现时域特征和空域特征的互补融合,还可能会削弱它们彼此的识别性能。因此,提出了一种微调融合策略,取得了最优的时域特征和空域特征的融合效果。
2 本文算法
如图2所示,本文提出的融合时空域特征的深度学习神经网络主要包含空域特征提取模块DMF(deep metric fusion)和时域特征提取模块LTCNN(landmark trajectory CNN)两个子网络模块。其中,DMF子网络使用了本文提出的深度度量融合技术,以视频序列中的单幅表情峰值帧图像为输入,从中提取出表情的静态空间特征。在LTCNN子网络中,采用了一个简单的2维卷积神经网络结构,利用人脸关键组件中的先验知识,以视频序列中人脸关键点轨迹构成的类特征图作为输入,进而从中提取出连续帧中隐含的表情时序运动特征。在实现中,为了达到网络的最佳训练效率并取得最优性能,首先分别对DMF子网络和 LTCNN子网络进行单独训练,然后将时域和空域两个不同维度上的特征子模块有效融合在一起,以最终提升人脸表情的识别性能。
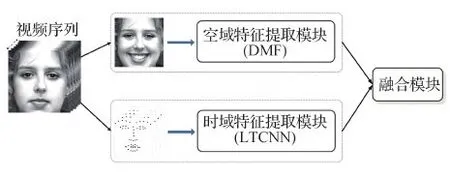
图2 整体网络结构Fig.2 The proposed network structure
2.1 基于深度度量融合的空域特征提取

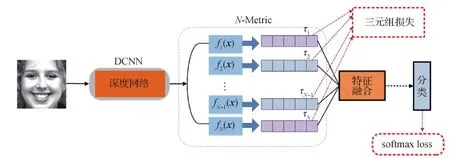
图3 DMF子网络:深度度量融合网络结构Fig.3 DMF sub-network:the structure of deep metric fusion

(1)
因此,三元组损失函数lossi定义为

(2)
式中,M为集合中的三元组个数。注意,上述三元组损失函数不仅保证了正样本与锚点之间的特征距离比负样本与锚点之间的特征距离小于给定的阈值τi,同时也保证了锚点与正样本之间的特征距离比负样本与正样本之间的特征距离小于该给定的阈值。
2.2 基于人脸关键点轨迹的时域特征提取
考虑到卷积神经网络(CNN)出色的特征表示学习能力,同时为了避免3D CNN的高计算量,可以使用2D CNN学习视频序列上的时域表情运动特征。因此,提出了基于人脸关键点轨迹的卷积神经网络(LTCNN),通过分析视频序列中人脸关键点的运动变化来提取其中蕴含的表情时域特征。如图4所示,LTCNN子网络对应一个简单的2D卷积神经网络,由4个卷积层和2个全连接层组成。LTCNN子网络输入的是由视频中人脸关键点轨迹构建而成的类特征图。给定一个人脸表情视频序列,首先从视频中均匀采样到一个固定帧数的图像序列。在实现中,均匀采样了11帧。然后,针对每个采样帧,可以在人脸的双眼、眉毛、鼻子和嘴巴等4个关键部位上检测出51个关键点,如图4所示。所有采样帧中关键点的位置变化即对应着视频中人脸关键点的运动轨迹。最后,将所有采样帧中关键点的坐标组合在一起,即得到输入到LTCNN子网络的类特征图。此外,受图像RGB三通道表示的启发,基于关键点的序列数据,在实现中采用两种方式构造LTCNN子网络的输入特征图。
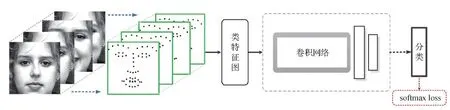
图4 LTCNN子网络:基于人脸关键点轨迹的卷积神经网络结构Fig.4 LTCNN sub-network:the structure of landmark trajectory convolutional neural network
1)将每帧中51个关键点的x、y坐标依次组合在一起,形成一个102维的特征向量(x1,y1,x2,y2,…,x51,y51)。然后将所有采样帧对应的特征向量组合在一起,即得到一个11×102×1大小的向量,该向量可以看做是带1个通道而大小为11×102的特征图,并称以该特征图作为输入的LTCNN子网络为LTCNN-1CL。
2)将每帧中51个关键点的x、y坐标分别组合在一起,形成两个51维的特征向量(x1,x2,…,x51)和 (y1,y2,…,y51)。然后分别将所有采样帧对应的x或y特征向量组合在一起,即得到一个11×51×2大小的向量,该向量可以看做是带2个通道而大小为11×51的特征图,并称以该特征图作为输入的LTCNN子网络为LTCNN-2CL。
2.3 DMF与LTCNN子网络的最优融合
提出的融合时空域特征的深度学习神经网络通过将提取空域信息的DMF子网络和提取时域信息的LTCNN子网络融合在一起,实现了人脸识别性能的有效提升。一般地,通常可以采用特征融合策略或者决策融合策略。
2.3.1 基于决策融合的后期融合策略
多数人脸表情识别方法通过决策融合来提高算法性能。如图5所示,该融合策略首先单独训练DMF和LTCNN子网络,每个子网络得到一个分类结果,然后将所有子网络的分类结果通过某种数学方式进行汇总,汇总结果即为最终的分类结果。一般可以使用简单的加权平均来汇总分类结果,也可以采用稍微复杂的汇总方式,例如决策排序融合(Zhang 等,2017)。在决策融合策略中,因为两个子网络是单独训练,因而无法考虑它们之间的互补性。

图5 基于决策融合的后期融合策略Fig.5 Late-fusion strategy based on decision fusion
2.3.2 基于特征融合的前期融合策略
在该融合策略中,DMF子网络的特征输出(即最后一个全连接层的输出)与LTCNN子网络的特征输出(即最后一个全连接层的输出)通过后续的全连接层融合在一起,以得到一个更具分辨能力的表情特征,如图6所示。在实现过程中,使用了一个256大小的全连接层来融合DMF和LTCNN子网络的输出特征,并结合softmax表情分类层对整个网络通过一种端到端的方式进行训练。但是,由于DMF和LTCNN子网络在学习过程中的收敛速度可能不同,因而以统一的学习率对它们进行端到端的训练无法充分照顾它们不同的收敛特性。

图6 基于特征融合的前期融合策略Fig.6 Early-fusion strategy based on feature fusion
2.3.3 基于微调的特征融合策略
针对前期特征融合策略下DMF和LTCNN子网络可能存在不同训练下收敛速度不一致以及后期决策融合策略下两个子网络因单独训练而没有考虑结果互补性的问题,提出了第3种融合策略,即基于微调的特征融合策略。其思想简单,先对DMF和LTCNN子网络分别进行训练,然后通过特征融合的方式将这两个子网络结合在一起,并以端到端的方式进行统一微调。在实现中,采用DMF子网络优化时所用的超参数进行微调训练,并考虑了4种微调方案。1)局部微调。固定两个子网络参数,只微调后面新加的全连接融合层和softmax分类层。2)固定DMF的微调。固定DMF子网络参数,联合微调LTCNN子网络以及后面新加的全连接融合层和softmax分类层。3)固定LTCNN的微调。固定LTCNN子网络参数,联合微调DMF子网络以及后面新加的全连接融合层和softmax分类层。4)整体微调。对网络中所有模块进行联合微调。
实验发现,后3种微调方案均能够有效实现DMF和LTCNN子网络的同步训练以及互补融合。其中,整体微调取得了最高的表情分类精度。
3 实验结果
3.1 3个表情数据集
为了评估提出的融合时空域特征的深度学习神经网络的性能,选取3个公开且广泛使用的基于视频序列的表情数据集CK+(Lucey等,2010)、MMI(Pantic等,2005)和Oulu-CASIA(Zhao等,2011)进行实验。

相比于CK+,MMI数据集(Pantic等,2005)中的个体表情差异更大,并且部分存在遮挡(例如眼镜和胡须等),因此更具挑战性。数据集由来自31个主体的236个图像序列组成,每个序列对应6个基本表情(没有蔑视) 之一,实验中选择了正面视图拍摄的208个序列。每个序列以中性表情开始,在序列中间达到表情峰值,并以中性表情结束。与CK+类似,通过均匀采样获得具有固定帧数的样本,并使用严格主体独立的方式进行10折交叉验证。
3个表情数据集的部分示例如图7所示。其中,MMI和Oulu-CASIA数据集中没有“蔑视”的面部表情。

图7 3个表情数据集中的部分示例Fig.7 Some examples of three expression datasets
3.2 实现细节
3.2.1 DMF子网络实现细节
1)数据预处理与数据增强。DMF子网络以视频序列中的单幅表情峰值帧图像作为输入。首先使用该帧图像中的人脸关键点裁剪出人脸图像并缩放到236 × 236像素。对没有提供人脸关键点的峰值帧图像,使用MTCNN算法(Zhang等,2016)检测其中的人脸关键点。此外,所有的人脸图像均进行了相应的直方图均衡化和全局对比度归一化处理。进一步,为了防止过拟合,在训练阶段,同时采用了在线和离线的数据增强方法来扩充数据训练集中的数据样本。在离线增强阶段,分别使用-10°、-5°、0°、5°、10°等5个角度对每幅图像进行旋转。在训练过程中,进一步通过在线增强扩充数据。一方面,从图像的5个位置(4个角和中心)随机裁剪出224 × 224像素的图像块作为训练数据样本;另一方面,以0.5的置信度对图像进行随机水平翻转。最终,通过离线和在线数据增强处理,可以将原始数据集的大小扩充50倍。在测试阶段,仅将从图像中心裁剪出的224 × 224像素的一个图像块作为DMF子网络的输入。
2)三元组构造。对于N-Metric模块中计算三元组损失函数所需的三元组样本,通过批次难例挖掘策略(batch hard)构建(Hermans等,2017),即对训练批次中的每个样本a,可以找到最难的(与a特征距离最大)正样本以及最难的(与a特征距离最小)负样本,分别称为锚点、正样本和负样本,并以此来形成一个三元组。
3)DMF子网络的优化训练。为了对DMF子网络进行单独训练,在DMF子网络的最后加了一个softmax表情分类层。因此,DMF子网络可以以一种端到端的方式进行单独训练,其整体损失函数定义为
(3)
式中,loss0对应用于表情分类的softmax损失函数,λ用于控制不同种类损失函数之间的贡献权重。在实现中,λ=0.5/N。为了训练得到具有较高泛化能力的DMF子网络,首先通过在人脸表情数据库FER-2013(facial expression recognition-2013)(Goodfellow等,2013)上微调VGG16-Face网络模型来预训练子网络中的DCNN模块。然后,针对每个实验数据集,对整个DMF子网络进行整体微调。训练采用Adam优化器,学习率设为5E-6,批处理大小为96,全连接层使用了0.5权重的dropout策略,整个子网络以一种端到端的方式训练70个epoch。

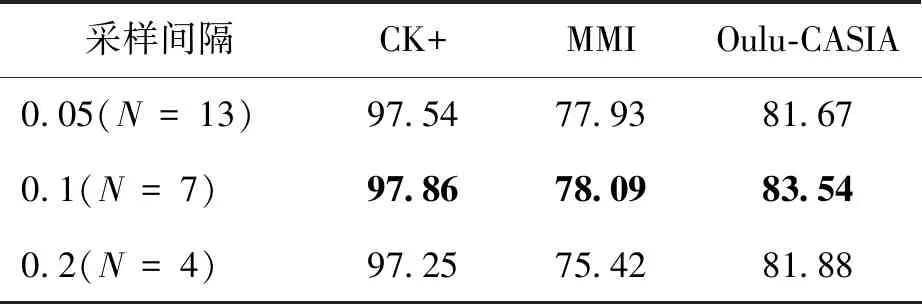
表1 3个数据库上不同采样间隔的识别精度Table 1 Recognition accuracy of different sampling intervals on three databases /%
3.2.2 LTCNN子网络实现细节
1)数据预处理。在实现中,使用DAN(deep alignment network)算法(Kowalski等,2017)检测采样图像中的51个人脸关键点。为了消除头部姿势及其大小对人脸关键点轨迹分析的影响,对人脸关键点的坐标进行归一化处理。具体方式为:对于每一个视频序列,可以以鼻子中心作为坐标原点,首先将每个关键点的位置坐标减去鼻子中心点的位置坐标,然后将该坐标除以所有采样帧中关键点位置坐标的标准方差。即
(4)

2)数据增强。为了防止LTCNN子网络在训练过程中发生过拟合,对人脸关键点进行随机水平翻转,并在关键点位置坐标中添加随机高斯噪声。即
(5)

3)LTCNN子网络的优化训练。与DMF子网络类似,为了对LTCNN子网络进行单独训练,在LTCNN子网络的最后加了一个softmax表情分类层。在实现中,LTCNN子网络前4个卷积层的大小分别为3×15×64、3×11×96、3×7×128和3×3×128。其中,3×15×64表示使用了64个3×15大小的2D卷积核,其他卷积层大小的含义一样。对于LTCNN子网络中的后两个全连接层,分别使用了512和128个神经元。训练时,使用Xavier初始化整个子网络,再采用Adam优化器进行优化,设置权重衰减率为0.000 1,初始学习率、批处理大小以及训练周期分别为1.0E-4、96和70。
3.3 表情识别性能的分析与评估
3.3.1 DMF子网络中多分支的特征可视化
在DMF子网络的N-Metric模块中,使用了7条分支通过基于三元组的深度度量学习来学习得到不同的人脸表情特征。图8给出了不同分支上学习特征的可视化结果。其中,第2—8列为各分支上的特征,最后1列为所有分支融合而成的特征。每个特征通过与其关联的全连接层中的神经元进行可视化,其中1个小方格对应着1个神经元,且颜色越亮代表值越大。特别说明,对于融合特征,显示了它对应的所有256个神经元,而对于各分支的特征,为了清晰显示,仅从其中的512个神经元中均匀采样了64个神经元进行显示。从图8可以看出,1)对于同一幅人脸图像,各个分支上的特征具有各不相同的可分辨特性;2)对于具有相同表情的不同个体图像,每一分支上的表情特征极其相似,而对于同一个体下的不同表情图像,每一分支上的表情特征则相差较大。

图8 DMF子网络中不同分支上的特征可视化结果Fig.8 Visualization results of features on different branches in DMF sub-net((a) original images;(b)τ1=0.15;(c)τ2=0.25;(d)τ3=0.35;(e)τ4=0.45;(f)τ5=0.55;(g)τ6=0.65;(h)τ7=0.75;(i) fusion features)
综上分析,每条分支显然学习到了不同的特征表示并且对表情具有极强的分辨性。最终,将这7条分支上的特征组合在一起,可以得到一个更加鲁棒且更具识别能力的表情“空域特征”。
3.3.2 DMF子网络中单分支与多分支模型的对比
为了进一步验证DMF子网络中多分支模型的有效性,仅保留了DMF子网络中的一条分支,并分别使用不同的阈值来训练该单分支的DMF网络模型。表2给出了不同阈值下该单分支DMF网络的性能结果。可以看出,模型的识别性能随着阈值的改变发生了相应变化,并且对于不同的数据库,其最佳阈值有所不同,这也验证了前述的观察结果,即通过改变损失函数中的阈值可以学习到不同的表情特征。此外,结果还表明,在CK+、MMI和Oulu-CASIA数据库上,即使采用最佳阈值,单阈值方法的性能也比多阈值融合的方法要低,分别低约1.31%、4.42%和2.33%,这充分证明了深度度量融合技术的优势。
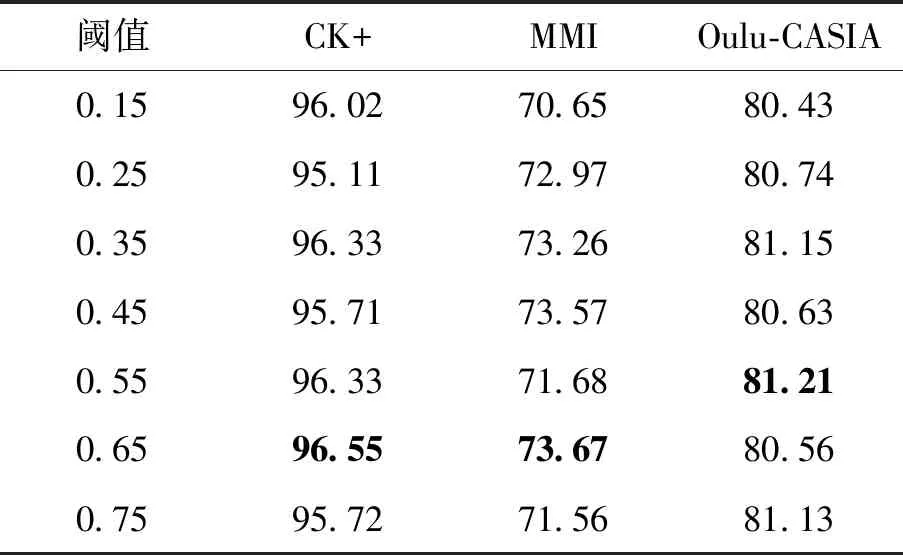
表2 单分支DMF网络在不同阈值的识别精度Table 2 Recognition accuracy of single-branch DMF network at different thresholds /%
3.3.3 两种不同的关键点轨迹特征图
在基于关键点轨迹构造LTCNN子网络的输入特征图时,可以采用单通道或双通道的特征图方式,它们分别对应LTCNN-1CL和LTCNN-2CL。表3给出了对应的表情识别性能结果。可以发现,在3个数据库上,LTCNN-2CL均取得了比LTCNN-1CL更高的准确率。即LTCNN-2CL对应的特征图能够更加准确地提取出关键点轨迹中的运动信息。因此,本文其他所有的相关实验均采用双通道的关键点轨迹特征图作为LTCNN子网络的输入。

表3 LTCNN-1CL和LTCNN-2CL的识别精度Table 3 Recognition accuracy of LTCNN-1CL and LTCNN-2CL /%
3.3.4 不同融合策略的性能对比
针对DMF和LTCNN子网络的融合,表4给出了不同策略融合下的表情识别性能。可见,基于整体微调的特征融合方法有效实现了DMF和LTCNN子网络的互补融合,取得了最高的表情分类精度。
此外,表4给出了单独DMF子网络和单独LTCNN子网络的人脸表情识别精度。显然,通过充分结合表情的时域和空域特征信息,融合时空域特征的人脸表情识别方法取得了表情识别性能的显著提升。需要注意的是,在表4中,一般特征融合策略取得的识别精度甚至低于单独使用DMF或LTCNN子网络的识别精度。这是因为DMF和LTCNN子网络在学习过程中的收敛速度不同,而以统一的学习率对它们进行端到端的训练无法充分照顾它们的不同收敛特性。

表4 不同融合策略的识别精度Table 4 Recognition accuracy of different fusion strategies /%
3.3.5 与之前方法的性能比较
表5给出了本文方法与其他已有方法的性能对比。在这些已有方法中,DTAGN(deep temporal appearance-geometry network)通过局部微调的融合方式集成两个子网络学习到的时序外观特征和时序几何特征(Jung 等,2015)。PHRNN-MSCNN通过决策排序融合的方式集成不同网络学习到的表情时空信息(Zhang 等,2017)。从表5可以看出,通过整体微调,本文提出的融合时空域特征的人脸表情识方法取得了较好的性能提升。表5进一步给出了PHRNN-MSCNN中时域和空域特征子网络各自的表情识别性能。可以看出,1)相比于MSCNN子网络,提出的DMF空域特征子网络在3个数据库上均取得了明显的性能提升;2)提出的LTCNN时域特征子网络取得了与PHRNN子网络较接近的识别性能,但是提出的基于CNN的网络结构避免了RNN网络结构可能带来的网络训练难度。最近,LBVCNN(local binary volume convolutional neural network)通过局部二值体卷积神经网络可以从视频序列的3个正交面同时学习其中的时空局部纹理信息(Kumawat等,2019),与之相比,本文提出的时空融合网络用专门的子网络分别专注于学习时域信息和空域信息,然后再进行互补融合,取得了更高的表情识别性能。

表5 不同方法的识别精度Table 5 Recognition accuracy of different methods /%
表6—表8分别显示了基于整体微调融合的时空网络在3个表情数据集上的混淆矩阵。可以看出,在CK+数据集上,本文方法对于每个类别均具有较好的识别性能。对于更具挑战性的MMI数据集,由于恐惧与惊讶两种表情较为相似,它们对应的面部关键点的轨迹运动差别较为细微,使得较多数量的恐惧表情错误地识别为惊讶,最终造成恐惧类别的识别率较低。对于Oulu-CASIA数据集,本文方法在所有类别上取得了较为均衡的识别性能,并且在生气和惊讶两种表情上取得了最高的识别率。

表6 本文方法在CK+数据集上的混淆矩阵Table 6 Confusion matrix of this method on CK+ dataset /%
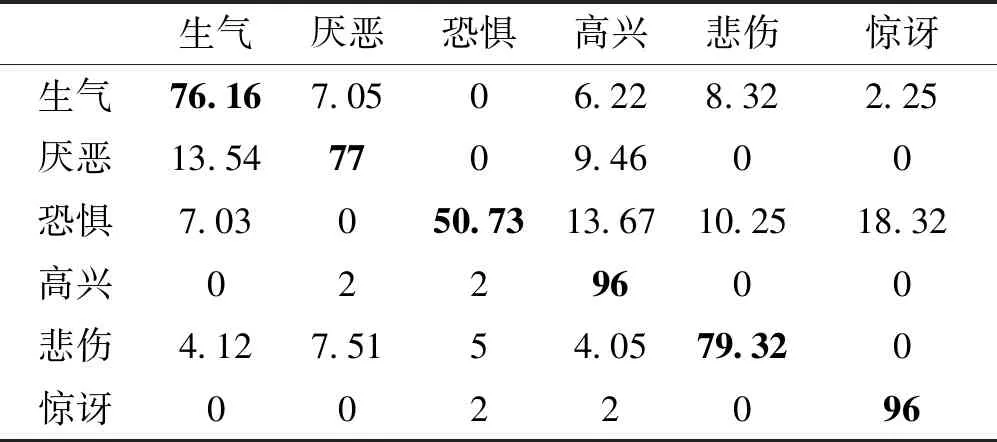
表7 本文方法在MMI数据集上的混淆矩阵Table 7 Confusion matrix of this method on MMI dataset /%

表8 本文方法在Oulu-CASIA数据集上的混淆矩阵Table 8 Confusion matrix of this method on Oulu-CASIA dataset /%
4 结 论
针对基于视频序列的人脸表情识别,本文提出了一种融合时空域特征的深度学习神经网络。首先,提出了一种基于三元组的深度度量融合技术,通过采用不同的三元组阈值,从单幅表情峰值图像中学习得到多个不同的表情特征表示,并将它们组合在一起最终形成了一个鲁棒的且更具识别能力的表情“空域特征”。然后,基于视频序列中的人脸关键点轨迹特征图,使用简单的2维卷积神经网络,学习得到描述表情运动信息的表情“时域特征”。最后,提出一种基于整体微调的网络融合策略,取得了最优的时域特征和空域特征的融合效果。
在3个公开且广泛使用的表情数据集CK+、MMI和Oulu-CASIA上验证了本文算法的有效性。实验结果表明,本文方法取得了显著的性能提升,在3个数据集上均接近或超越了当前最高的人脸表情识别性能。但本文方法仍有一些不足之处,未来可以通过以下几方面进一步研究:1)提出的方法仅考虑了视频和图像两种模态下的人脸表情识别,未来可以融合更多模态的特征,例如主体的身份信息、场景描述信息和语音信息等,以进一步增强表情识别算法的鲁棒性。此外,未来还计划将三元组深度度量融合技术推广到其他相关应用,例如图像分类、图像搜索以及可视对象识别等。2)本文方法只探究了几种模型融合策略来结合时序和空间特征。未来可以尝试其他融合方法,更好地利用各个子网络中的互补信息。也可以对最新提出的3D卷积进行改进,在利用3D卷积联合学习时空特征优势的同时,降低3D卷积网络的复杂性。3)许多研究通常在特定的数据库上评估算法性能,但是一些跨数据库实验表明,由于数据的采集方式和环境不同,数据库之间普遍存在数据偏差和注释不一致的问题,这将大幅降低在未知数据上的泛化性能。深度域适应和知识蒸馏是解决数据偏差的可行解决方案。未来可以将研究扩展到跨数据库的人脸表情识别问题上。
