面向大姿态人脸识别的正面化形变场学习
2022-07-15胡蓝青阚美娜山世光陈熙霖
胡蓝青,阚美娜,山世光,陈熙霖
1.中国科学院计算技术研究所,北京 100190;2.中国科学院大学计算机科学与技术学院,北京 100049
0 引 言
人脸识别技术在各领域的广泛应用,为人们的生活带来了巨大便利。随着技术的发展,人脸识别的性能得到了极大提升,非极端姿态的人脸识别已经取得了良好效果,但是大姿态下的人脸识别仍然面临很大挑战。这是由于人脸在大姿态下会发生很强的非平面内形变,影响对人脸身份的判别。主流的针对大姿态人脸识别问题的方法分为两大类:第1类方法直接在原图上提取姿态鲁棒特征,第2类方法先将人脸进行正面化之后再提取特征。第1类方法用于极端姿态人脸识别时,可以提取的特征非常有限,人脸识别性能明显降低。第2类方法先将人脸正面化再进行公共特征提取,即人脸正面化方法,可以提取出更多有效的判别特征。正面化方法分为2D生成方法和利用3D模型变换方法。2D生成方法通过一个网络直接回归出正面人脸图像,3D方法则是将人脸图像建模为3D模型,通过该模型算出原图与正面人脸的像素坐标对应关系,从而实现正面化。2D生成方法比基于3D模型的方法更加灵活,生成的人脸也更加自然。然而3D方法得到的正面化人脸图像能够保留更多的人脸身份信息。
结合2D生成和3D模型变换两种正面化方法的优点,本文提出了一种基于由粗到细形变场学习的人脸正面化方法(coarse-to-fine morphing field network,CFMF-Net),如图1所示。CFMF-Net通过学习形变场将任意人脸图像I正面化为图像Iest。该网络首先通过Fs提取人脸关键点特征S,并将S输入Fc以得到粗粒度形变场C。之后将C和Fg学到的细节特征G拼接在一起,输入Fd以得到细粒度形变场D。形变模块T将形变场D作用于输入图像I得到Iest。CFMF-Net通过拉近Iest与真实的正脸图像Igt的距离来进行优化。其中形变场的值由下方的热力图表示,红色表示该像素点上的形变场向左,蓝色表示该像素点上的形变场向右,颜色明度越高则移动距离越大。此处形变场指正面人脸与输入人脸的像素点的位置对应关系,即非正面人脸图像的像素可以根据形变场进行重组得到对应的正面人脸图像。CFMF-Net通过一个深度网络以由粗到细的优化策略学习形变场,对输入人脸进行正面化。

图1 基于由粗到细形变场学习的方法CFMF-Net流程图Fig.1 Overview of our CFMF-Net
本文采用的以形变场进行正面化的方式与利用3D人脸模型进行人脸正面化的方法类似,都能够通过像素点的移动来变换图像,保证正面化人脸图像中的像素点全部来源于原始图像。并且本文方法与2D回归方法类似,都是通过网络自动学习,而不是人为设计的规则。因此该方法兼具了2D正面化方法的灵活性与3D正面化方法的保真性。
目标形变场来自高维空间,这给网络的优化带来了不小的难度。因此本文借鉴分步渐进的优化思路,提出了由粗到细的形变场学习框架,以获得更加准确鲁棒的形变场。然而在学习粗粒度形变信息时,模型只留意了人脸的主要形变,会导致细节信息的丢失,因而增加了一个细节补充分支网络,以进一步保证预测出的形变场的准确性。
本文的主要贡献在于:1)采用2D回归的方式以类3D的行为对人脸进行正面化,结合了2D正面化方法的灵活性与3D正面化方法的保真性;2)由粗到细的学习方式提升了模型的易学习性。
1 相关工作
大姿态人脸识别方法分为直接在原图上提取姿态鲁棒特征和先将人脸正面化再提取特征两类。
直接提取姿态鲁棒特征的方法主要是将不同姿态的人脸图像都映射到一个公共的特征空间中。典型相关分析(Li等,2009)是直接提取姿态鲁棒特征早期的经典方法,通过最大化两组不同姿态的图像的特征相关性,将不同姿态的特征映射到统一的空间中。然而该方法只保证了提取到的是不同姿态图像的公共特征,忽略了特征的判别能力。Sharma和Jacobs(2011)改进了典型相关分析,通过偏最小二乘法最小化同一个人所有姿态的图像的特征距离,得到的特征不仅是姿态鲁棒的,且具有较好的判别能力。Zhang等人(2013)给训练集中同一人所有姿态的图像设定同一张随机的人脸作为映射目标,以得到姿态鲁棒的具有良好判别能力的特征。多视角判别网络(Kan等,2016)针对不同姿态的图像采用不同的特征映射,将多姿态的图像映射到公共特征空间中,得到了更准确的公共判别特征。深度网络的提出与发展进一步赋予了模型更强大的特征学习能力。基于深度学习的特征解耦方法(Peng等,2017)首先利用深度网络提取出更准确的人脸表示,之后通过特征解耦与交叉重组得到姿态鲁棒特征。
这些直接提取姿态鲁棒特征的方法对非极端姿态的人脸识别已经有了不错的效果,但对极端姿态的人脸识别却效果有限。因为对这些姿态差异巨大的人脸图像直接提取公共特征会丢失很多对识别有用的信息。因此研究者提出了先将人脸转正,再进行人脸识别的人脸正面化方法,这些方法又分为2D正面化方法和3D模型正面化方法。图2展示了几种经典方法在MultiPIE数据集上的正面化结果。
2D人脸正面化方法直接通过一个编码器网络将不同姿态的人脸图像映射为正面姿态的图像。经典的方法(Zhu等,2013;Kan等,2014)是用渐进式学习的方式对侧面人脸进行逐步的姿态调整,以映射到正面人脸。随着生成对抗网络(generative adversarial network,GAN)(Goodfellow等,2014)的提出,很多方法借助GAN强大的分布拟合能力生成各种姿态的人脸,包括正脸。相比于通过回归生成人脸的方法,基于GAN的方法生成的人脸图像更加逼真。在Luan等人(2017)方法中,由特征提取器得到的身份特征和指定的姿态信息一起输入GAN中,以生成多姿态的人脸图像。Yin等人(2017)提出了另一个更精细的基于GAN的方法,给予GAN更多的信息,即3D可变形模型的系数,得到保留了更多原始信息的正面人脸图像。Huang等人(2017)同时兼顾整张人脸和人脸局部图像块的逼真程度,使生成的人脸图像保留了更多的细节。Zhang等人(2019)认为更大姿态的人脸更难以识别与正面化,因此在通过GAN正面化人脸的训练过程中对难样本采用更大的训练权重。Rong 等人(2020)通过特征级和图像级两种GAN判别器,加强GAN正面化人脸的效果。Luan等人(2020)在GAN判别器中加入自注意力机制保持人脸图像的几何结构,令人脸正面化更加真实。
3D人脸正面化方法通过建立人脸图像的3D模型将人脸映射到正面姿态。相比于2D方法,3D人脸正面化方法能保留更多的人脸结构信息。早期的经典方法,3D通用弹性模型(Prabhu等,2011)和基于视角的主动外观模型(Asthana等,2011)等直接利用3D模型进行人脸姿态变换。这些方法通过将2D图像映射到3D坐标上,再投影到任意的角度,以生成相应姿态的人脸。更直接的方法是计算侧面人脸图像到其正面人脸图像的像素点的位置对应关系,即形变场,再用该形变场进行图像变换。Li等人(2012)用从训练集得到的正面化形变场的线性组合来正面化测试集人脸图像。而这些3D方法都不能处理姿态变化引起的自遮挡,如图2(b)所示。Ding等人(2015)在3D模型变换的基础上,利用人脸的对称性填补遮挡部分,但生成的人脸依然存在严重的失真,如图2(c)所示。Hu等人(2017)提出了一种利用全连接网络自动回归正面化形变场的方法,生成了更逼真并保留更多原始信息的正面人脸。Cao等人(2018)提出一种结合了3D模型和GAN的方法,首先通过形变场得到一个初始的正脸图像,再通过GAN进行图像调整,最终得到足够逼真且身份保持的正面人脸。

图2 3种经典方法在MultiPIE数据集上的正面化结果Fig.2 Visualization results of three methods ((a) Kan et al.(2014);(b) Li et al.(2012);(c) Ding et al.(2015))
综上所述,人脸正面化方法相比于直接提取姿态鲁棒特征的方法能够提取出更有效的公共判别特征。正面化方法中,2D方法比3D方法更加灵活,生成的人脸也更加自然。3D方法得到的正面化人脸图像能够保留更多的人脸身份信息。
2 本文方法
如图1所示,本文提出的CFMF-Net主要由可学习形变场网络F和用形变场进行正面化的模块T两部分组成。网络F的输入为原始人脸图像I,其输出为正面化I的形变场D。T的输入为原始图像I和形变场D,其输出为正面化后的图像Iest。
可学习形变场网络F通过渐进式的方式学习形变场,即先学习粗粒度形变场以捕捉人脸结构的主要形变,在此基础上再学习细粒度形变场来精修细节上的形变。因此,网络F主要包含粗粒度形变场网络Fc和细粒度形变场网络Fd两部分。具体来讲,Fc首先学习人脸关键点,再解码出粗粒度形变场。Fd进一步完善粗粒度形变场,得到与原图同分辨率的细粒度形变场,其输入包含Fc的输出与一个分支网络Fg从原图学到的补充细节两部分。
CFMF-Net通过学习到的形变场对图像进行变换,因而其输出图像的像素值都是来自于原图,保留了更多的身份信息,减少了额外噪声的引入。相比于2D方法通过回归像素值生成正脸图像,本文方法通过学习形变场进行正面化,从而限制了正面化图像中的像素均来自于原图,更好地保持了原始信息。相比于3D方法基于3D模型规则计算形变场,本文方法得到的形变场是基于学习得到的,从而能够得到更逼真的正面化结果。
2.1 形式化
(1)
式中,W为整个模型的可学习参数。
(2)
2.1.1 形变场学习网络
(3)

粗粒度形变场网络Fc和细粒度形变场Fd是CFMF-Net的两个重要组成部分。

Sk=Fs(Ik)
(4)
Ck=Fc(Sk)
(5)
式中,Fs和Fc是两个连接在一起的卷积网络,其参数分别为Ws和Wc。Sk∈R68×2为68个稀疏人脸关键点的位置表示,作为人脸结构鲁棒特征表示用来指导粗粒度形变场的学习,而学得的形变场Ck将作为学习大小为h×w的细粒度形变场的中间表示,为细粒度形变场学习打下良好基础。
Ck建模了输入到输出人脸图像的主要形变,但Ck忽略了细节的变化,因此还需要进一步细化。在CFMF-Net中,分支网络Fg用来提取原始图像Ik的细节特征Gk=Fg(Ik),其中Fg的参数为Wg。之后,将Ck与Gk拼接在一起,输入到细粒度形变场网络Fd中,得到与原图分辨率大小相同的细粒度形变场Dk∈Rh×w。即
Dk=Fd([Ck,Gk])
(6)
式中,Fd为反卷积网络,可以对粗粒度形变场进行上采样,其参数为Wd。
2.1.2 形变模块

(7)

(8)
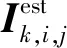
(9)
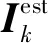
2.1.3 整体训练目标

(10)
2.2 优化过程
为了加快CFMF-Net的收敛,首先预训练CFMF-Net每个模块,得到一个较好的初始化参数,再以式(10)为目标进行端到端的训练。
2.2.1 预训练
如前所述,粗粒度形变场学习中的Fs用来学习人脸关键点位置Sk。此处用人脸关键点对Fs进行优化(若无标定的关键点可省略该步)。即
(11)


图3 人脸关键点示例Fig.3 Exemplars of facial landmarks


(12)

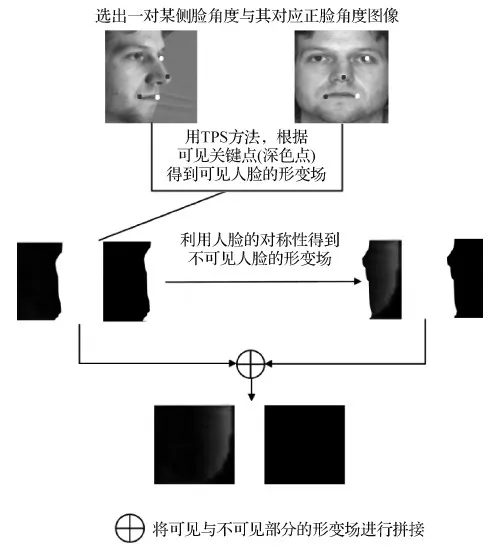
图4 CFMF-Net预训练时粗略估计过程Fig.4 The estimating process of during pretraining
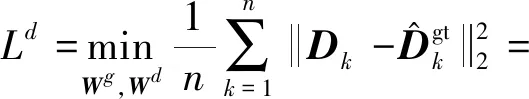
(13)
2.2.2 端到端调优
在预训练的基础上,CFMF-Net以式(10)为目标对网络进行端到端的优化。
(14)


(15)
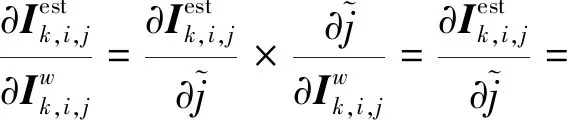
(16)
整个CFMF-Net网络参数{Wd,Wg,Wc,Ws}通过梯度下降进行优化,对应每个模块的梯度为
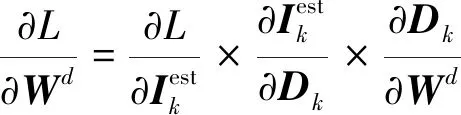
(17)
3 实 验
为验证本文方法对大姿态人脸识别问题的有效性,在4个代表性大姿态人脸识别数据集上进行实验,包括通用人脸识别数据集LFW(labeled faces in the wild)、包含更多更极端姿态变化的数据集MultiPIE(multi pose,illumination,expressions)、CFP(celebrities in frontal-profile in the wild)和IJB-A(intelligence advanced research projects activity janus benchmark-A)。
3.1 数据集与实验设置
在MultiPIE数据集(Sim等,2003)上进行可控场景下的大姿态人脸识别实验,在300 W-LP(Zhu等,2015)、Webface(Yi等,2014)、LFW(Huang和Learned-Miller,2014)、CFP(Sengupta等,2016)和IJB-A(Klare等,2015)上进行非可控场景下的大姿态人脸识别实验。在所有实验中,首先通过CFMF-Net进行人脸正面化,之后通过一个人脸识别网络进行人脸识别。其中,300 W-LP为CFMF-Net网络的训练集,Webface为人脸识别训练集,LFW、CFP和IJB-A为人脸识别测试集。训练集和测试集的设置情况如表1所示。实验时,通过裁剪缩放,所有的人脸图像调整至128×128像素,像素值归一化至[-1,1],图像坐标值归一化到[0,1],形变场归一到[-1,1]。图5展示了不同实验的CFMF-Net网络结果。接下来具体介绍实验中的数据集。
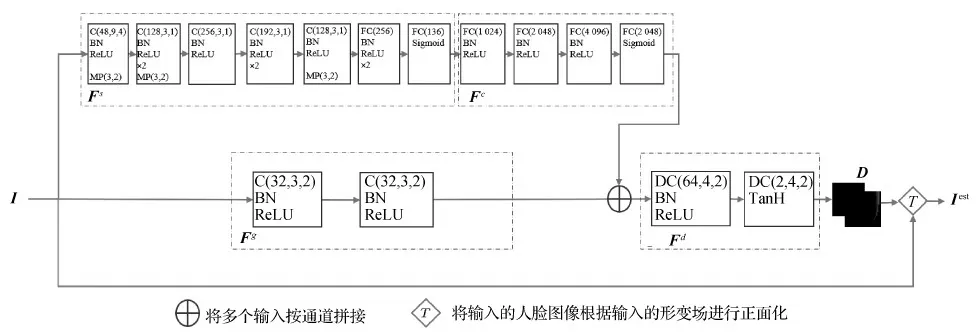
图5 CFMF-Net网络结构Fig.5 Architecture of CFMF-Net

表1 训练集和测试集的设置说明Table 1 Overview of training and testing datasets
MultiPIE数据集(Sim等,2003)是最常用的可控场景下的大姿态人脸识别数据集,包含337个人在不同姿态、光照和表情下的照片。实验采用与大姿态人脸识别的代表性工作(Cao等,2018)相同的实验设置,即取前200个人的所有图像进行人脸正面化和识别的训练,剩下137个人的所有图像进行测试。在测试阶段,采用这137个人的正面姿态、光照和中性表情的照片作为注册集(gallery),剩下72 000张照片作为查询集(probe)。与大多数对比方法相同,在MultiPIE的实验中,本方法采用LightCNN-29(Wu等,2018)作为识别网络。
LFW(Huang和Learned-Miller,2014)和CFP(Sengupta等,2016)是两个经典的非可控场景下的人脸识别数据集,通常用来测试人脸识别方法的性能。LFW包含13 233幅采集自网络的人脸图像,其中通常用于人脸识别测试的部分为3 000对来自于同一人的图像与3 000对来自于不同人的图像。CFP包含来自500人的7 000幅图像,其中每个人都有10幅准正面(小于10°)图像和4幅大姿态(大于10°)的图像。本文实验中,LFW和CFP用来进行人脸验证实验。在LFW上的测试指标为人脸验证准确率ACC(accuracy)与ROC(receiver operating characteristic curve)曲线下的面积AUC(area under the curve)。在CFP上的测试包含正脸—正脸图像对(frontal-frontal,FF)和正脸—侧脸图像对(frontal-profile,FP)两部分,其测试指标为人脸验证准确率ACC。同样,在LFW和CFP实验中,本文方法用LightCNN-29(Wu等,2018)作为识别网络。
IJB-A(Klare等,2015)是更大的不可控场景下的人脸识别数据集,主要用来测试大姿态人脸识别方法的性能。IJB-A包含很多极端姿态和光照条件下的人脸图像,相比于前面介绍的测试数据集,更具有挑战性。IJB-A包含来自500人的5 396幅网络图像和20 412幅截取自网络视频的图像。其测试协议为10折交叉验证,每次划分出333人的图像作为训练集,剩余167人的图像作为测试集,最终的准确率为10次实验的平均准确率。在多数方法中,首先在一个更大数据集(如Webface)上训练一个识别模型,再用IJB-A的小训练集进行微调(Klare等,2015)。相比于之前介绍的数据集,IJB-A上的测试不再是单一图像的对比,而是图像集合之间的对比。测试包含人脸验证和人脸识别两部分。人脸验证的指标为在某个指定错误接受率(false accept rate,FAR)下的正确接受率(true accept rate,TAR)。人脸识别通常为闭集测试,指标为第1名准确率和前5名准确率。在之前的方法中,IJB-A上的测试没有统一的训练集和训练网络结构,为了与之前的方法公平比较,本文方法采用了两个不同的人脸识别网络,分别为Fast AlexNet和LightCNN-29(Wu等,2018)。其中,Fast AlexNet是对AlexNet进行优化后得到的模型,与大多数已有方法的模型能力相当,但收敛速度更快,具体结构如表2所示。

表2 Fast AlexNet网络结构Table 2 Architecture of Fast AlexNet
Webface(Yi等,2014)是一个通用人脸识别训练集,包含来自10 575个人的494 414幅图像。实验中,使用Webface训练非可控条件下的人脸识别模型。
3.2 实验结果
在MultiPIE、LFW和CFP数据集上,本文提出的CFMF-Net与多种方法进行实验对比,包括多任务学习方法(Yin和Liu,2018)以及与本文方法同为图像生成类的基于GAN的方法(Luan等,2017;Yin等,2017;Zhao等,2018a,b;Cao等,2018)。其中Luan等人(2017)的方法是一种直接基于GAN的2D人脸正面化方法。Yin等人(2017)在DR-GAN的基础上进一步抽取了3DMM(3D morphable model)的系数作为特征,更好地保持了人脸结构信息。Cao等人(2018)首先将形变场作用于原图得到正面化人脸,再以此为中间结果做进一步调整。
在IJB-A数据集上,本文方法与不同类型的方法进行了对比,包括特征解耦方法(Crosswhite等,2017;Yang等,2017;Zhao等,2017)、人脸增广方法(Zhu等,2016;Masi等,2017;Chang等,2017)和人脸正面化方法(Luan等,2017;Yin等,2017;Zhao等,2018a;Cao等,2018)。
值得一提的是,2019年以后出现的方法多为通用人脸识别方法,极少针对大姿态人脸识别这一特定问题专门研究,本文与ArcFace(Deng 等,2019)采用ResNetSE50网络结构(网络能力与本文网络差不多)的版本(https://github.com/TreB1eN/ InsightFace_Pytorch)进行比较。


表3 不同方法在MultiPIE数据集上的识别率Table 3 Face recognition accuracy of different methods on MultiPIE dataset /%
在LFW和CFP上的实验结果如表4和表5所示。可以看出,本文方法在正面人脸居多的测试中与当前最好方法的性能相当,包括采用更大训练集的Deng 等人(2019)方法。从表4可以看到,在LFW数据集上,本文方法得到了保持原始信息的正面化人脸。从如表5可以看到,本文方法在正脸—侧脸的识别上取得了更好性能,表明本文方法的正面化对侧面人脸识别起到了重要作用。

表5 不同方法在CFP数据集上的人脸验证准确率ACCTable 5 Face verification accuracy of different methods on CFP dataset /%
在IJB-A数据集上的实验结果如表6所示。在人脸正面化类方法中,本文方法与当前最好的方法效果相当。表6中,本文方法CFMF-Net1是以最大化真实正面人脸与生成正面人脸的相似度为目标,学习原图与正面化图像的形变场,通过重组原图像素点得到正面化的图像,保证生成图像的所有像素都来自原图。Masi等人(2017)、Luan等人(2017)和Yin等人(2017)的方法与CFMF-Net1具有相似的训练集和识别网络,将它们单独对比。可以看到,CFMF-Net1取得了更好的识别效果。因为Masi等人(2017)提出的是基于3D模型规则进行正面化的方法,生成的正面人脸不够逼真,Luan等人(2017)和Yin等人(2017)提出的2D回归生成方法没有充分保留原图中的有效信息。而CFMF-Net1结合了3D和2D方法的优势,既保持了原始身份信息,又保证了生成图像足够逼真。CFMF-Net1在LFW和IJB-A数据集上的正面化结果示例分别如图6和图7所示。本文方法CFMF-Net2是仅通过简单的形变场回归来正面化人脸,与结合了GAN与密集形变场的方法(Zhao等,2018a;Cao 等,2018)相比,得到了与这些复杂方法持平的效果。

图6 CFMF-Net1在LFW上的正面化结果示例Fig.6 Exemplars of frontalization results on LFW of CFMF-Net1((a)original input images;(b)x-axis morphing field;(c)frontalized results)

图7 CFMF-Net1在IJB-A上的正面化结果示例Fig.7 Exemplars of frontalization results on IJB-A of CFMF-Net1((a)original input images;(b)x-axis morphing field;(c)frontalized results)
值得一提的是,当前数据集的人脸图像主要的变化在yaw方向,即本文中的x方向。一种自然的想法是能否通过加强x方向形变场的训练权重来提升性能。然而实际上这种做法对性能几乎没有影响,因为CFMF-Net可以自动学习到形变场的主要变化在x方向。此外,给x方向形变场更多训练权重可能对可扩展性有影响,因为现实中的人脸图像还会存在其他方向上的姿态变化。
3.3 消融实验
为了分析CFMF-Net每个模块对人脸正面化和识别的影响,进行了一系列消融实验。在300 W-LP数据集上消融实验的可视化结果如图8所示。可以看到,通过TPS可以得到一个基本的人脸正面化结果(图8(b))。直接利用粗粒度形变场得到的人脸正面化图像,由于自遮挡问题,依然存在一定程度的失真(图8(c))。而借助细粒度形变场,可以得到逼真的正面化人脸图像(图8(d))。这验证了CFMF-Net各部分对正面化的作用。

图8 CFMF-Net在300 W-LP上消融实验的结果Fig.8 Ablation study of frontalization on 300 W-LP((a) original input images;(b) results of TPS;(c) results of CFMF-Net w/o Fg,Fd;(d) results of CFMF-Net)
从识别结果的角度来看,CFMF-Net的每一部分对人脸识别的准确率都具有重要作用。CFMF-Net在IJB-A数据集上的消融实验结果如表7所示。可以看出,相比于不进行人脸正面化直接用Fast Alex-Net进行人脸识别,使用粗粒度形变场进行正面化,能在一定程度上提升人脸识别的准确率。而使用细粒度形变场进行人脸正面化,能进一步提升识别的准确率。

表7 CFMF-Net在IJB-A上的消融实验Table 7 Ablation study of CFMF-Net on IJB-A /%
为了进一步验证CFMF-Net对大姿态人脸的效果,将IJB-A测试集按姿态大小分为3组,即[0°,±30°)、[±30°,±60°)和[±60°,±90°)(详见https://github.com/whobefore/MF-Net/tree/master/Data/IJBA)。测试协议与IJB-A人脸识别测试相同,但每组再细分为3组不同姿态的实验,即[0°,±30°)的子集作为gallery,[0°,±30°)、[±30°,±60°)、[±60°,±90°)作为probe分别进行人脸识别测试。在每组数据上,首先用CFMF-Net进行人脸正面化,再用Fast AlexNet进行人脸识别,以测试识别准确率,并将其与直接使用Fast AlexNet进行识别的准确率相比较,结果如表8所示。可以看出,本文方法相比通用人脸识别方法(Deng等,2019),在能力相当的网络结构下取得了更好结果,说明现在仍存在对姿态特殊处理的必要。另外,在大姿态[±60°,±90°)的测试集上,正面化后图像的识别率得到显著提升,进一步验证了本文方法对大姿态人脸识别的有效性。

表8 IJB-A上不同姿态子集的TOP-1识别率Table 8 Top-1 recognition accuracy in our self-defined pose-subdivision test protocol on IJB-A
4 结 论
针对大姿态人脸识别问题,本文提出了一种基于由粗到细形变场回归的人脸正面化的方法CFMF-Net。在实验结果中,尤其是大姿态的人脸识别实验中,本文方法表现出了比相关方法更好或持平的效果,表明该方法可以有效结合2D和3D人脸正面化方法的优点,既充分保留了原始图像中的信息,又保证了生成的正面图像足够逼真。与通用人脸识别方法的对比结果表明,尽管可以通过数据集的丰富和损失函数的设计显著提升直接进行人脸识别方法的性能,但目前对人脸姿态的处理仍然存在其必要性。然而在本文方法中,虽然通过由粗到细的学习方式提升了密集形变场回归的鲁棒性,但这样的算法仍然有很高的自由度,压缩形变场的冗余信息是一种更好的解决方式。在未来的工作中,一方面希望对密集形变场进行结构可保持的稀疏化,另一方面希望能够进一步设计出识别性能驱动的自动人脸或人脸特征对齐方法,发掘出最佳人脸对齐角度,并应用到更复杂场景的人脸识别中。
