深度学习背景下视觉显著性物体检测综述
2022-07-15王自全张永生于英闵杰田浩
王自全,张永生,于英*,闵杰,田浩
1.信息工程大学地理空间信息学院,郑州 450001;2.31434部队,沈阳 110000
0 引 言
显著性物体检测(salient object detection,SOD)试图模拟人类的视觉和认知系统(Borji和Itti,2013),获取图像中感兴趣的区域。区别于人眼定位预测(eye fixation prediction),SOD需要精细划定显著性物体的像素级范围,已广泛应用于图像裁剪(Rother等,2006)、缩略图生成(Marchesotti等,2009)和目标跟踪与检测(Wu等,2014)等领域。图1展示了2015年以来SOD算法的发展历程。

图1 SOD方法发展历程Fig.1 Development of salient object detection methods
SOD一般采用平均绝对误差(mean absolute error,MAE)和F-measure(Fβ)值作为评价指标,具体公式为
(1)
(2)
式中,lMAE表示全图预测值与真值之间的一致性。S(x,y)表示预测图在(x,y)处的像素值;G(x,y)表示真值图在(x,y)处的像素值。Fβ值综合了精度P和召回率R,并可以调节二者在不同场景下的相对权重。由此可以看出,SOD本质上是一个像素级二分类问题,即以0和1来标记“当前像素是否显著”。
1 传统SOD方法的启示及缺点
1.1 传统SOD方法的启示
在传统框架中,SOD主要分为特征提取、特征融合和特征修整3个步骤,如图2所示。

图2 传统SOD技术的一般流程Fig.2 The general process of traditional salient object detection method
给定一幅待检测图像,传统SOD方法按照手工设计好的低层(low-level)、中层(mid-level)和高层(high-level)特征进行提取。其中低层特征主要为对比度特征,包括颜色、边缘、纹理、频率域(Achanta等,2009;Hou和Zhang,2007)、信息量(Bruce和Tsotsos,2005)和熵(Wang等,2010)等。它们基于数值计算,所含信息并不具备实体相关性;中层特征包含一定的实体属性信息,刻画了物体自身的形状、位置等属性,主要涵盖物体轮廓、物体形状信息和上下文/全局特征等;高层特征与物体语义信息紧密相关,可有效指导SOD模型自上而下的“寻找目标”,主要包括预置的先验图等。
为了有效提升MAE和Fβ值,大量工作采用机器学习方法对多个提取出的特征图进行融合。Liu等人(2011)采用条件随机场(conditional random field,CRF)(Lafferty等,2001)进行逐像素显著图映射的做法较有代表性。该方法将SOD问题归结为给定图像I,求解其映射为显著图A的概率的条件随机场学习问题,具体为
(3)
式中,Z为由训练样本计算的概率信息。E为能量运算符。
而后,按照最大似然规则,采用梯度下降等策略学习CRF的参数λ*,具体为
(4)
式中,n表示训练样本数量。由于CRF理论很成熟,后期大量用于特征修整步骤中。
1.2 传统SOD方法的缺点
传统SOD方法具有以下缺点:1)耗时长。大部分传统算法需要图像进行超像素分割以构建局部描述符,计算量较大。本文在Intel i7 8 GB 运行内存环境下尝试以经典SLIC(simple linear iterative clustering)(Achanta等,2012)分割算法生成一幅具有500个超像素的600×600 RGB图像,耗时超过120 s。SOD在很多任务中仅是预处理步骤,低效率限制了其应用;2)步骤烦琐,不易实现。传统方法需要手工设计特征与融合方法,且不同算法的实现环境可能不一致。除此之外,手工设计的特征往往难以表达高层信息,预置的先验图泛化性差,只能针对特定的场景和假设使用,难以拓展到通用的检测方法中;3)鲁棒性较差。传统SOD方法多是基于对比度特征进行检测,这些特征倾向于检测物体边界和内部具有对比度的噪点,但SOD任务更加关注物体本身,且不希望内部同质化区域被抑制。此外,基于空间域提取的特征易受到光照、复杂背景的影响,而频率域和数学方法提取的特征缺乏明确含义,难以有效融合其他特征。上述情况均会导致检测结果存在大量误判,且不稳定,如图3所示。

图3 基于传统方法得到的显著图缺少鲁棒性Fig.3 Salient maps achieved by traditional methods are in lack of robustness ((a) original images;(b) ground truth;(c) HF-DCF (Li and Yu,2015);(d) SF(Perazzi et al.,2012);(e) DRFI(Wang et al.,2017a);(f) HS(Yan et al.,2013);(g) RC(Cheng et al.,2011);(h) MR(Yang et al.,2013))
2 传统特征与深度学习特征的融合
传统特征与深度学习特征的融合指2015年前后出现的按照人为设定的规则对两种特征进行融合处理的方法。2012年,AlexNet(Krizhevsky等,2012)的出现使得卷积神经网络(convolutional neural network,CNN)开始广泛应用于各种计算机视觉任务。Krizhevsky等人(2012)探究了其网络结构和特征提取方式,并指出该网络全连接层输出的4 096维特征向量具有良好的表征能力。VGG(Visual Geometry Group)(Simonyan和Zisserman,2015)进一步发展了卷积神经网络的结构,采用堆叠小卷积核的方法,在降低参数量的同时提升了网络性能。基于这两个网络模型,相关学者开始利用神经网络提取高层特征,弥补传统方法对高层语义特征表达能力不足的问题。Li和Yu(2015)在传统方法的基础上,将过分割后的超像素按照3个尺度(自身、邻域和全图)投入AlexNet中提取包含局部和全局信息的高层特征,经过降维后与手工设计特征(包括颜色直方图、纹理直方图和归一化系数等)进行拼接,得到每个超像素最终表示向量,使用随机森林回归器进行回归,同时附加条件随机场模型进行特征修整。本文将其称为HF-DCF方法(其中,HF(hand-crafted fea-ture)表示手工特征,DCF(deep contrast feature)表示深度学习模型产生的对比度特征),如图4所示。
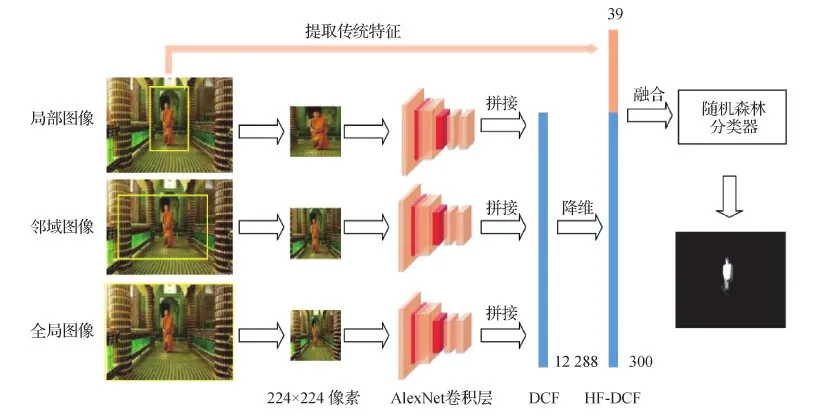
图4 HF-DCF方法示意(Li和Yu,2015)Fig.4 Illustration of HF-DCF(Li and Yu,2015)
ELD-HF(encoded low level distance map and high level features)(Lee等,2016)将深度神经网络进一步融入SOD框架,为之后的深度学习方法提供了参考。ELD-HF采用过分割(over-segmentation)方法获取超像素,通过设计颜色、纹理等特征计算各个超像素之间的距离,构建低层编码距离图(encoded low level distance map,ELD-map),而后,设计一个浅层网络编码ELD-map,与VGG提取的特征图共同转为列向量,拼接后输入全连接层,利用softmax计算得到分类的得分,取代了传统方法中的机器学习分类器。
在早期的融合方法中,人为设定的特征融合规则(如简单的向量拼接)缺少理论支撑;CNN仅起到提取高层特征的作用,每个超像素均需遍历输入进神经网络,时间成本高;由于当时缺少自适应全局池化层,导致模型只能接收固定长宽(224 × 224像素)的输入,因此每个超像素必须放大到标准尺寸,不仅增大了计算量,而且导致超像素内部信息变形,降低了特征准确性。此外,采用的AlexNet和VGG模型大多在ImageNet数据集上预训练得到,尽管其包含的图像内容很广泛,但面向分类任务的全连接层输出向量倾向于识别全局信息,输入局部超像素生成的描述子是否具有可靠性能,还有待分析。
3 基于卷积神经网络的SOD方法
SOD本质上是一种像素级二分类问题,适合使用卷积神经网络或带有卷积结构的神经网络模型来解决。出于提升性能与检测速度的考虑,学界整体倾向于使用统一的网络模型完成所有流程。大量工作将传统检测框架中的特征提取、特征融合以及特征修整等步骤全部或大部分内化到网络模型中,只有少部分算法仍然在最后使用机器学习等方法进行辅助精修。根据模型对于输入样本的要求不同,基于卷积神经网络的SOD方法可分为基于像素级标注样本(或称强监督)方法以及基于非像素级标注样本(或称弱监督)方法两大类。图5展示了这些方法的分类体系和发展方向。前一类方法的主体一般为单个典型网络结构,例如循环卷积神经网络、全卷积神经网络和基于卷积结构的生成对抗网络;后一类方法则一般包含多个额外设计的专用网络模块用于处理弱监督标签,主要分为基于单类非像素级标签的SOD方法和基于多类非像素级标签的SOD方法。
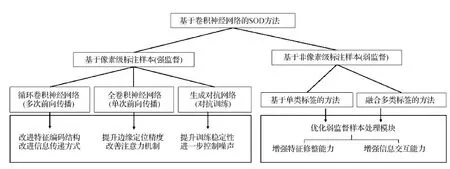
图5 基于卷积神经网络的SOD方法分类体系和发展过程Fig.5 Classification and development process of SOD method based on convolutional neural network
如前文所述,一个典型的SOD过程应当完成特征提取、特征融合和特征修整3个步骤,其中特征提取步骤由卷积神经网络自动完成。在强监督SOD方法中,最初采用卷积层的降采样处理与跳层连接完成多尺度特征的融合,并采用条件随机场进行特征修整;注意力机制模块(Hu等,2020)广泛应用于特征融合步骤中,特征修整过程也逐渐由更有针对性的边缘混合损失函数引导,可以完全实现端到端SOD;弱监督SOD方法往往由语义引导,利用类别信息对物体进行粗略聚焦与定位,而后采用空间一致性等先验知识,训练条件随机场模块以及另行设计的辅助网络模块进行特征融合。
3.1 基于像素级标注样本的SOD方法
3.1.1 循环卷积神经网络
循环卷积神经网络(Liang和Hu,2015)通过不断更新调整识别结果,对输入数据进行循环前向传播,在降低参数量的同时,不同层级的特征也自然融合,可以达到比单次前馈网络更好的效果。在DHSNet(deep hierarchical saliency network)(Liu和Han,2016)中,对某个循环卷积层中第k个特征图上(i,j)的状态,输出单元zijk(t)可以表示为
(5)
对循环卷积神经网络的改进有两种思路,一是改善特征编码结构,二是改善消息传递结构。Deng等人(2018)设计残差优化模块(residual refinement block,RRB),直接拟合显著图真值和当前预测之间的残差,该方法更易收敛,通过堆叠使用RRB替代了其他神经网络中的特征编码器,在5个数据集的测试指标上超越了同期16个最佳SOTA(state-of-the-art)算法。Zhang等人(2018)提出双向消息传递检测模型BMPM(bi-directional message passing model)(如图6所示),采用门状双向消息传递模块融合多尺度卷积特征,使得模型具备对多尺度上下文的敏感性,考虑传统的堆叠卷积和池化层提取的特征不能包含丰富的上下文信息,设计了多尺度上下文敏感的特征提取模块(multi-scale context-aware feature extraction module,MCFEM),每个MCFEM均采用多重空洞卷积学习物体信息和图像背景,并采用跨通道方式进行特征图拼接。图6中,每个彩色框代表1个特征模块,蓝色部分利用VGG16网络提取多尺度特征,而后投入MCEFM中,融合过程采用灰色部分的门状双向信息传递模块计算,门函数的作用是控制信息传递速率。融合过程中的特征记为{hij},i=1,2,3;j=1,2,…,5,完成高级特征向低级特征的融合之后网络才会生成最终的预测图。
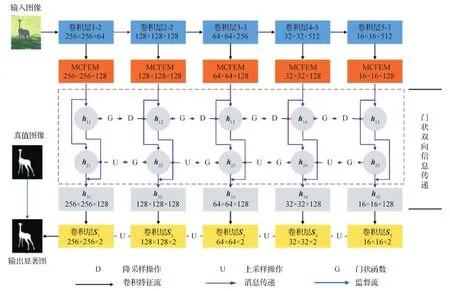
图6 双向消息传递显著性检测模型(Zhang等,2018)Fig.6 Bi-directional message passing model for salient object detection(Zhang et al.,2018)
3.1.2 全卷积神经网络
全卷积神经网络(fully convolutional network,FCN)(Shelhamer等,2017)将VGG网络中的全连接层修改为全卷积层,如图7所示,在降低参数量的同时使输入图像尺寸不再受到限制。基于FCN进行改进是众多SOD方法中最直接的思路,改进策略主要聚焦于提升边界信息定位(对应特征修整部分)的准确性,相关方法从后期辅助修整、引入额外边缘检测器,发展为设计与边缘相关的损失函数、保边平滑算法,再到保边注意力机制等方法的引入,使网络的适应能力和检测能力不断增强。图7中,conv{i},i=1,2,…,7表示不同降采样率的卷积层。pool{i},i=1,2,…,5表示池化层。{b×},b=2,4,8,16,32表示不同倍率的上采样操作。由此,得到预测结果FCN-{x}s,x=8,16,32。FCN-32s不经过中间步骤,直接由1/32分辨率的特征图上采样32倍得到,检测性能最差;计算FCN-16s时,先将1/32分辨率特征图上采样2倍,而后与第4池化层得到的1/16分辨率特征图相加,再经过16倍上采样得到预测图,检测性能较FCN-32s有所提升;FCN-8s由3层特征图仿照FCN-16s的方式,经上采样与融合后生成,检测效果最好。FCN较早基于跳层连接进行特征融合,这种方法使得网络从单向拓扑图变为有向无环图(directed acyclic graph,DAG),在完成高低层特征融合的同时增强了网络的鲁棒性,基本实现了卷积神经网络模型对传统SOD计算框架的全面替代。
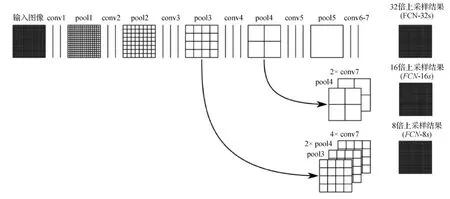
图7 FCN结构示意图(Shelhamer等,2017)Fig.7 Illustration of FCN(Shelhamer et al.,2017)
分析FCN网络结构,不难发现以下问题:1)反卷积易产生棋盘状伪影(checkerboard artifact)(Odena等,2016),这是因为反卷积无法恢复卷积操作造成的信息丢失,只能根据已有像素进行拓展填充,造成了局部棋盘伪影(马赛克)现象;2) FCN输出特征图在边界部分存在较大误差。
针对反卷积造成的棋盘状伪影,Zhang等人(2017b)采用1×1卷积对输入像素进行基于线性插值法的上采样,而后与传统的反卷积结果相加得到最终的上采样结果。这种模式分离了上采样和卷积,并且与传统反卷积相容,线性插值的加入起到了平滑马赛克的作用。此外,利用2个FCN网络分别构建编码器和解码器,同时针对全卷积网络模型的过拟合现象,吸取dropout(Krizhevsky等,2012)思想对卷积层设计了随机失活单元R-dropout,提取并融合不确定(由随机失活造成的)卷积特征(uncertain convolutional feature,UCF),增强了模型的泛化能力。
针对边界信息检测精度不足的问题,陆续发展出以下解决思路:
1)引入边缘特征图。Hou等人(2019a)吸取了FCN跳层连接的优势,引入整体嵌套边缘检测器(holistically nested edge detector,HED)(Xie和Tu,2017)进行弥补。然而,HED只能在前、背景区分较为明显的图像上提升检测精度。为增强边缘检测的鲁棒性,Amulet(Zhang等,2017a)将多个分辨率的特征分别进行压缩—拓展操作(shrink and extend),对一个目标大小为W×H×C的特征,将网络中输出的分辨率高于该特征的特征图进行压缩(shrink),对网络中输出分辨率低于该特征的特征图进行拓展(extend),得到尺寸为W×H×C/(n+m+1)的n+m+1个特征图(n和m分别表示分辨率缩放因子),经过通道维度的连接(concatenate),得到基于分辨率的特征融合图,而后将其投入显著图预测(salient map prediction,SMP)模块,融合网络浅层部分的输出进行保边优化(boundary preserved refinement,BPR)。循环进行SMP和BPR操作以提升预测精度。
2)设计与边缘相关的损失函数。为简化网络结构,同时将特征修整过程融入网络训练过程,Luo等人(2017)设计了4 × 5网格状的网络,通过特征图的前馈和反馈提取局部和全局信息,同时借鉴Mumford-Shah 模型(Mumford和Shah,1989),针对边界信息设计了基于交并比(intersection-over-union,IoU)的损失函数FMSE,训练过程中即完成边缘精化,基本取代了人工设计的边缘检测器和基于CRF等传统机器学习的方法的特征修整过程。其中,损失函数FMSE具体为
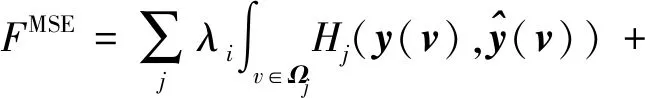
(6)
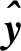
(7)
式中,A表示面积函数。除了基于交并比的损失函数,对边界敏感的像素级损失函数也得到了发展。式(7)中的IoU损失具有视觉直观含义,但是对于不规则分割边缘而言,直接计算预测面积与真值面积交并比较为困难,存在一定误差。Qin等人(2019)提出的BASNet(boundary-aware salient network)将IoU的含义泛化,计算真值图和预测图在数值空间上的交并比,最终形成融合二分类交叉熵、IoU和结构相似度(structural similarity,SSIM)的混合损失函数lbce、liou和lssim,同时在网络中分别设计预测模块和残差精化模块进行特征修整,在保持显著性物体自身结构的同时得到了较好的边缘探测效果。损失函数lbce、liou和lssim计算为
(8)

(9)
(10)
式中,S(r,c)表示预测为显著的概率值,G(r,c)为真值,取值均为0或1。式(10)降低了IoU计算的难度。x和y是原图和真值图上某块相关区域,μx和μy为均值,σx和σy为方差,σxy为协方差,设置C1=0.012,C2=0.032,防止分母为0。Wu等人(2020)进一步提出了包含边界强化损失函数(boundary-enhanced loss,BEL)的AFNet,并且将模型检测速度提升到26 帧/s,达到实时要求。
3)设计自适应的边界调整方案。SE2Net(siamese edge-enhancement network)(Zhou等,2019)包含了边界引导交互算法(edge-guided inference algorithm),该方法产生若干大小为5 × 5像素且中心位于显著物体边缘上的矩形框,每个矩形框都会被边缘分为显著和非显著两部分,而后计算每个矩形框内部的显著像素所占比例,若显著像素比例更高,则将该矩形框全部设置为显著,实现了检测过程中对边缘进行自适应调整。
除了设计保持边缘的损失函数,引入注意力机制也是一种改进思路。按照权重分布的位置,适配CNN的注意力机制模块主要分为空间注意力机制和通道注意力机制。空间注意力机制生成的权重与输入特征图的尺寸相关,权重施加在特征图的像素上;通道注意力机制生成的权重与输入特征图的通道数相关,权重施加在特征通道上。对于SOD任务而言,由于其核心解决方案是多层次特征的提取与互补融合,因此注意力机制模块应起到加强特征表达或抑制噪音的作用。基本思路有:
1)使像素“注意到”局部区域和全局区域。Liu等人(2018)针对以往算法在单个注意力计算阶段中只提取1幅权重图的问题,提出了像素级上下文注意力机制PiCANet(pixel-wise contextual attention network)。在提取全局特征图时,对每个像素位置,采用双向长短时记忆机制(bi-directional long short-term memor,Bi-LSTM)(Hochreiter和Schmidhuber,1997)对全图进行扫描,在该位置生成(W×H)×1×1的“全局信息向量”(即为“使该像素‘看到’全局信息”),而后对其进行softmax操作得到该像素的全局注意力分数。提取局部特征时,仿照该方式,对每个像素生成(W2×H2)×1×1(W2和H2为以该像素为中心区域的局部宽度和高度)的注意力分布张量,进行softmax操作得到该像素的局部注意力分数。PiCANet可以生成有效的上下文信息,但逐像素计算的注意力分数图数据量很大,只能使用在较小尺寸的特征图中,或需要设计显存优化策略。Hu等人(2021)指出了这一问题,LSTM实现复杂,因此选择性地利用局部上下文和全局上下文信息,设计空间衰减上下文模块(spatial attenuation context module,SACModule),嵌入特征金字塔(feature pyramid network,FPN)(Lin等,2017)解码器的每一层中。该注意力模块通过逐像素传递信息(过程中受反距离衰减因子控制)获取全局特征信息,并在6个标准数据集上性能超过了29种SOTA算法。
2)使模型“注意到”边缘信息。Chen等人(2020)针对卷积网络算法降采样过大导致的信息损失问题,提出使用侧方输出(side-output)的残差学习方式修正FCN输出的特征图,同时设计了逆注意力机制(权重计算方法为1-Sigmoid(A),A为卷积网络输出的特征图张量)嵌入VGG网络中以抑制物体内部信息,引导网络关注显著性物体的边缘,并采用更大的卷积核提高感受野,使骨干网络更加适合于像素级分类任务。该方法在达到SOTA的同时,获得了45帧/s的检测速度,同时将模型大小缩减为81 M。但是,在应用空间注意力机制以保持边缘时,部分文献并没有给出令人信服的理论解释。
3)不同注意力机制的联合使用。Zhao和Wu(2019)设计了金字塔特征注意力网络(pyramid feature attention network,PFA),该网络针对高层特征设计了上下文感知金字塔特征提取器(context PFA,CPFA)和通道注意力模块以获取丰富的上下文信息,针对低层特征设计了空间注意力模块用于保持边缘。PFA沿用了空洞卷积以提升感受野,并且根据拉普拉斯梯度设计了保边损失函数。同期,Liu等人(2019)针对经典U型网络中信息传递效率不足的问题,设计了金字塔池化模块(pyramid pooling module,PPM)和特征聚合模块(fusion feature module,FAM),并嵌入FPN。其中PPM将特征图自适应平均池化后融合,起到增大感受野的作用,而后分别上采样投入对应尺度的FAM中。FAM先对输入特征图进行下采样,经卷积后融合输出。PPM和FAM的级联使用缓解了高层特征的稀释问题。Li等人(2020)同样修改了FPN网络,在编码部分将5层特征图输入跨层特征聚合器(cross-layer feature aggregation,CFA),将FPN输出的5层特征图进行全局平局池化得到通道级的全局特征,而后得到进行拼接经过两层SENet(squeeze-and-excitaion networks)(Hu等,2020)的全连接层。得到5维的特征图权重后,再将5层特征图进行拼接得到“聚合特征”,输入跨层特征分布器(cross-layer feature distribution,CFD)进行逐层降采样拼接,分布到解码器的5个尺度上,生成最终显著图,较好保持了每个层次的语义和细节信息。
4)简化注意力机制的结构和运算。使用注意力机制会带来日趋复杂的网络结构,如何对模型进行剪枝成为一大问题。Fu等人(2019)提出的DANet(dual attention network)设计了双注意力机制网络结构,图像经ResNet(residual neural network)网络提取特征后,只投入一次注意力模块(attention module,AM)中,AM的两个分支分别对特征图进行矩阵转置与运算操作,获取到相应位置和通道的权重,如图8所示。图中,C×H×W表示输入特征图具有C
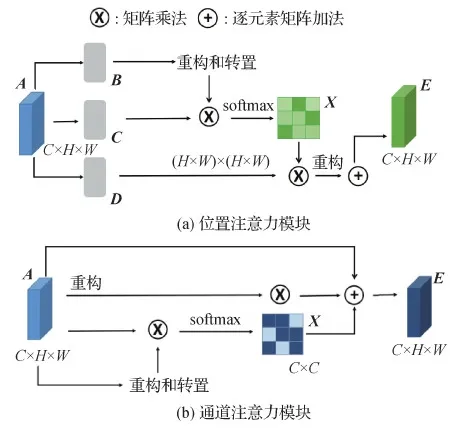
图8 双注意力网络示意图(Fu等,2019)Fig.8 An overview of the dual attention(Fu et al.,2019)((a) position attention module;(b) channel attention module)
通道、宽为W、高为H的张量,A、B、C、D、E、X均为中间变量。DANet方法显著减少了注意力模块参数量,陆续被后续算法借鉴。
3.1.3 基于卷积结构的生成对抗网络
与带有复杂跳层连接与注意力机制的卷积神经网络相比,在结构上相对简单的生成对抗网络(generative adversarial network,GAN)(Goodfellow等,2014)受到相关学者的关注。使用GAN进行显著性检测始于SalGAN(Pan等,2018),其在生成器结构中使用VGG16组成编码部分,采用4个上采样层和10个卷积层组成解码部分;判别器由6个卷积层和3个全连接层组成,二者联合对抗训练以判断显著图是否有效。严格来说,SalGAN并不是针对SOD任务,而是针对显著性检测的另一个分支——人眼定位预测设计的。因此SalGAN在SOD任务中的表现并不精确,但其思想启发了后续的网络。Mukherjee等人(2019)针对传统算法对噪声处理能力弱的问题,对SalGAN进行了继承和发展,提出了DsalGAN,该网络由3组生成对抗网络组成。第1组中,生成器G1对图像进行去噪操作,判别器D1判断图像是否已经去除噪声;第2组中,生成器G2基于对抗性损失的数据驱动对去噪图像进行显著性预测,判别器D2判断图像是否预测成功,完成了特征融合;第3组中,生成器G3和判别器D3则用循环一致性损失进行特征修整。尽管DsalGAN在指标上超过了当时的SOTA算法,但由于GAN训练终止于不易收敛的鞍点,因此训练难度远高于其他网络,且易发生模式坍塌(Mao等,2019),相对较为成熟的FCN系列算法,研究成果较少。
3.2 基于非像素级标注样本的SOD方法
构建具备精细标注的像素级数据集成本高昂,并且在有限样本数据集上训练的模型易缺乏泛化能力。事实上,相比于像素级标注样本,现实中有很多非像素级标注的弱样本可供使用,例如ImageNet中上百万幅带有图像分类标签的样本、目标检测数据集中用矩形框标识的样本,甚至是涂鸦方式标识的显著性物体。这些样本制作容易,数据量更大,泛化性更强,若能使用弱监督方法加以利用可产生较高的效益。弱监督SOD方法往往以卷积神经网络的语义引导为初始状态进行特征修整。
3.2.1 语义引导与可行性
随着CNN的发展,相关学者开始借鉴构造“权重分布”的方法,可视化地证明CNN的性能。类激活图(class activation map,CAM)(Zhou等,2016)的尝试和之后的Grad-CAM(Selvaraju等,2017)以及Grad-CAM++(Chattopadhyay等,2018)证实了CNN存在空间“注意力”。3种方法分别采用全局平均池化结果、特征映射梯度和梯度的ReLU值对网络输出的特征图赋予权重,而后得到关注点热力图。如图9所示,其中,图9(b)是一个网络输出的热力图,可以看出CAM结果与图9(d)一致,因此,神经网络将图像识别为dog类别,若输出结果为cat,热力峰值区域则集中在图中的cat身上。

图9 CAM与卷积神经网络模型的注意力(Zhou等,2016)Fig.9 CAM and attention of CNN(Zhou et al.,2016)((a) original image;(b) CAM;(c) cat;(d) dog)
不难发现,卷积神经网络提取出的高层次特征具备很强的目标定位与概略范围确定能力,为基于非像素级标签的SOD方法的实现提供了可能。同时,由于弱监督样本在训练模型得到初始显著图后不足以再支持精细化训练,因此还需要设计样本更新策略,这个任务通常由先验信息指导下的条件随机场和辅助网络模块完成。
3.2.2 基于单类非像素级标签的SOD方法
Wang等人(2017b)提出基于图像分类标签的弱监督网络,本文称为WSS1(weakly supervision for saliency detection 1),如图10(a)所示。该方法将CAM计算各特征图权重的全局平均池化(global average pooling,GAP)改为自主设计的全局平滑池化(global smooth pooling,GSP),GSP更加适合于计算特征响应,从而将特征图线性组合,而后设计前景推理网络(foreground inference network,FIN)用于生成初始显著图,采用迭代条件随机场算法执行细化操作。需要指出的是,条件随机场并未利用像素级标签,而是依据一定准则(如空间一致性)逐步修正FIN预测的显著图,作为近似真值反馈给FIN。在网络训练完成之后,直接使用FIN进行显著图推理,不需要任何后处理。该方法在MAE指标上全面超越同时期所有无监督传统方法,检测速度达到62.5帧/s,超越同时期所有监督学习方法,在弱监督条件下接近同时期最佳像素级学习算法水平(相差小于0.3)。
Li等人(2018)提出利用图像标签的弱监督算法,本文称为WSS2(weakly supervision for saliency detection 2)。该方法以CAM输出的热力图作为粗糙的显著图预测,使用传统无监督方法制作的像素级显著图作为附带噪声的“标签”。根据第1节的描述,传统对比度方法侧重描绘显著性物体的“边界”,CAM输出的热力图则聚焦于显著性物体内部,二者是互补的。Li等人(2018)交替训练图形模型(graphical model)和基于ResNet101(He等,2016)的全卷积网络。前者本质上是全连接条件随机场(Krähenbühl和Koltun,2012),采用空间一致性和结构不变性来修正标签模糊性;后者则有助于跨图像修正语义模糊性。训练过程以MAE指标为判别条件,比较经CRF处理的显著图和现有标签的优劣以实现标签的更新。该方法超过了同期所有像素级监督学习算法,从侧面证明了大样本量带来的泛化性能优势。

3.2.3 基于多类非像素级标签的SOD方法
随着图像理解技术的发展,可获取的样本中增加了图像说明(caption)标签。Zeng等人(2019)针对之前弱监督检测方法只利用单一类型弱样本的缺点,提出了综合利用图像分类标签、图像说明标签(图10(c))和无标签数据的弱监督显著性检测方法MSWSS(multi-source weak supervision for saliency detection),并且该网络具备良好的可拓展性,即提供了面向更多数据处理模块的接口。MSWSS由分类网络CNet(classification network)(输出标签与粗糙的显著图)、带有LSTM机制的说明文本聚合网络PNet(caption generation network)(生成与说明文本相关的区域)以及显著图预测网络SNet(saliency prediction network)组成,并采用注意力转移损失函数(attention transfer loss)在网络之间传递信号。进行分类任务和文本标签解译任务时,交替计算CNet的类别定位损失和PNet的注意力转移损失,PNet和CNet训练完毕后即可生成伪像素级显著图,供SNet训练。

图10 不同弱监督SOD训练样本Fig.10 Different training examples of weakly-supervised salient object detection((a)caption of category;(b)scribble annotations;(c)caption of image understanding)
除了弱样本,传统的无监督检测方法(例如边缘检测等方法)以及语义分割等相关问题的解决方案均存在一定程度的重合,可设计多任务方法,使其互相促进与优化。这种思路促进了多任务模型的发展。该方法试图通过强制模型共享参数的方式促进不同任务间特征的交互,而不考虑底层的细节。
Lee等人(2016)提出刻画显著性物体固有语义属性的多任务全卷积神经网络DeepSaliency,卷积层由显著性检测和语义分割任务共享,以减少网络结构冗余。对于图像分割任务,使用反卷积层和1×1卷积计算C张分割分数图(C为类别数)。对于显著性检测任务,使用1个卷积层和2个反卷积层生成[0,1]之间的显著图,并设计正则Laplacian非线性回归层进行细粒度超像素显著性细化,采用MAE和交叉熵作为损失函数交替对网络进行训练。
Hou等人(2019b)提出了融合SOD、边缘探测和骨架提取3种任务的统一框架TBOS(three birds on stone),该方法利用级联编码器增强特征表示,通过密集连接提升特征融合效果。图11 展示了具备不同连接结构的网络简化图(Hou等,2019b)。图11(a)为不具备特征融合的简单结构,图11(b)(c)使用了金字塔结构自上而下融合特征,图11(d)(f)引入了侧监督机制。Hou等人(2019b)对不同跳层连接之间的结构进行分析,认为图11(a)—(e)的解码器接收的特征较弱,不能同时完成边缘检测和骨架提取任务,因此在解码器之前增加了一个编码器,如图11(g)所示,并在此基础上设计了堆叠使用编码器的通用TBOS(图11(h))。每个编码器均由残差结构组成,互相密集连接,接受3个尺度上采样后的加和,经卷积后与原始尺度相加,以融合多级特征。该算法结构较为复杂,每一层的特征都会复制到其他层中,需要设计一定的显存优化策略。Wu等人(2020)使用互学习方法(mutual learning method,MLM)引导前景轮廓和边缘检测任务同时进行,每个MLM模块都包含了多个网络分支,使得协同网络性能取得了较大提升。
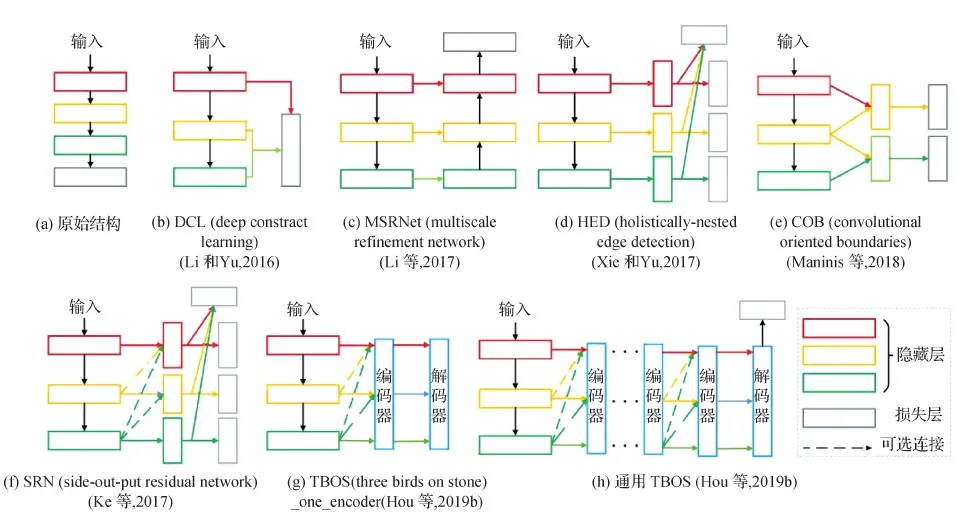
图11 具备不同连接结构的网络简化图(Hou等,2019b)Fig.11 Simplified diagram of network structures with different connection manners(Hou et al.,2019b)((a)original structure;(b)DCL(Li and Yu,2016);(c)MSRNet(Li et al.,2017);(d)HED(Xie and Tu,2017);(e) COB(Maninis et al.,2018);(f)SRN(Ke et al.,2017);(g)TBOS_one_encoder(Hou et al.,2019b);(h)general TBOS(Hou et al.,2019b))
4 发展方向分析
对现有SOD方法的改进主要聚焦于特征融合方法、协同显著性检测、弱监督与多任务策略和针对多类别图像的显著性检测等方面。
4.1 特征融合方法改进
现有的特征融合方式大致分为连接方式、残差方式和注意力机制3种。
1)连接方式。主要有跳层连接、密集连接等方式,这些方法致力于充分融合高层特征的定位能力和低层特征的保持细节能力,然而存在两方面的问题。首先,由于高层特征图信息较少,上采样操作恢复到原始图像尺寸造成的棋盘伪影问题容易导致高层特征“稀释”(dilute),需要设计更有效的上采样方式,例如设计带有内插策略的上采样卷积核以平滑结构突变;其次,跳层连接、密集连接的设计较为主观,不同连接方式的应用场景不够明确,造成模型结构日趋复杂。未来可采用分组卷积等轻量化网络的设计策略对网络进行剪枝,突出重要的特征。
2)残差方式。残差方式直接学习卷积网络输出的粗糙显著图与真值之间的残差,基本避免了设计复杂网络结构,针对特征融合的不足,可采用循环前向传播的方式逐步进行修正。此外,面向图像级分类任务的神经网络感受野较小,在处理像素级分类任务时,单像素承载的信息量不足,可采用增大卷积核或采用空洞卷积的方式防止因多层池化造成信息量过大损失。
3)注意力机制,或称为自适应聚合(adaptive aggregation)。对于SOD任务,普遍存在高层次特征不足、低层次特征有噪音的问题。注意力机制可以有效过滤信息,使模型更加关注需要的部分,但存在两个问题。首先,注意力模块设计应具备明确设计含义,例如“保持边缘”和“逆向抑制”。然而许多方法采用的空间注意力机制都没有清晰说明其意义,只是笼统地表述“可以凸显前景信息”,而且由于神经网络大量的通道自身含义不明确,因此通道注意力机制难以解释其背后的机理;其次,设计复杂的注意力模块嵌入网络中,易使网络计算量激增,特别是具有分支计算结构的空间注意力模块,往往只能在高层小尺寸特征图上使用,否则会出现显存溢出问题。
4.2 协同显著性检测
随着视频处理任务和海量网络数据识别需求的不断增加,挖掘图像中的关联信息成为研究热点。传统方法大多基于手工设计的描述符进行匹配,缺少语义信息,当成像角度差距较大时,难以分辨出语义相近的物体。协同显著性检测则可以有效解决该问题,由于图像间关联信息不再服从欧氏空间分布,亦难以用规则方式描述图的节点和边,故采用图神经网络等算法研究协同显著性检测或成为未来的研究方向。如Zhang等人(2020b)设计的自适应图卷积网络AGCN(adaptive graph convolutional network)可以同时获取图像内部和图像外部的信息联系,即直接计算任意两个图像位置之间的相互作用。提取到这些特征后,采用图注意力聚类模块区分共同的目标和显著前景。AGCN可采用无监督方式进行优化,生成协同显著图,最后使用具有编解码器CNN结构的端到端计算框架进行协同显著性目标生成,可获得较好的效果。
4.3 弱监督与多任务策略
进行像素级标注成本高昂,有限的训练数据集规模必然导致模型泛化性能不足。弱监督方法极大拓展了样本来源,并且可以预防监督方法中的过拟合。使用弱监督方法往往需要设计双向更新策略,即显著图更新策略和标签更新策略,如何更好地保证标签向更准确的方向更新,值得进一步研究。除此之外,随着实例分割技术的发展,SOD可同时利用人眼定位预测与实例分割的结果,计算图像中每个对象的显著性分数,从而筛选人眼关注的显著性物体。这种方法思路简单,基于现有的成熟网络也容易实现。
4.4 针对多类别图像的显著性检测
现有的SOD算法大多针对近景自然图像,拍摄画面清晰、物体显著性强,实际应用场景中可能出现两种问题。1)图像质量很可能达不到训练集的数据,主要表现在降质图像的显著性检测上。一方面,由于训练集上的显著性物体摆放规整,鲜见形变,因此在待检测对象出现大角度偏差时,可能无法检测;另一方面,图像分辨率降低时,由于网络的感受野不足,易导致丢失细小目标。这一问题可采用迁移学习、引导学习等方法,利用现有的研究成果对模型参数进行调整。例如,Zhou等人(2020)提出多类别自注意力机制引导网络MSANet(multi-type self-attention network),在每一组样本对(原图像和降质图像)上使用ImageNet预训练模型,“指导”面向降质图像的“学生网络”进行训练,并使用多个基于卷积的门状循环单元,按照一定规则进行状态更新。2)图像种类纷繁复杂,例如成像距离较远的可见光遥感图像、多光谱图像和雷达图像,以及各种没有明确空间含义的图像(例如数据可视化图)等。这些图像信息量增多,显著性降低,如何设计更好的算法快速关注到其局部和全局的显著性,以减轻图像处理人员的负担,这一问题可结合专用的目标检测网络与超分辨率重建技术进行目标的定位并缩小处理范围,而后进行精细划分。但具体应用时,需要结合使用场景确定算法的精度。
5 结 语
本文从原理、基本思想和算法特点角度对SOD进行了归纳。不难看出,显著性检测的核心思路(多层次特征提取、融合与修整)没有发生根本性变化,深度学习方法是对传统方法的整合和提升,在精度和效率方面取得了长足进步。未来,SOD将会越来越多地部署落地,促进各类计算机视觉技术的进步。
