网络监督数据下的细粒度图像识别综述
2022-07-15魏秀参许玉燕杨健
魏秀参,许玉燕,杨健
1.南京理工大学计算机科学与工程学院,南京 210094;2.高维信息智能感知与系统教育部重点实验室,南京 210094;3.社会安全图像与视频理解江苏省重点实验室,南京 210094
0 引 言
细粒度图像识别是计算机视觉和模式识别领域的基础研究课题,旨在对某一传统语义类别下细粒度级别的不同子类类别进行视觉识别(Wei等,2019b),如不同子类的狗、不同子类的鸟、不同车型的汽车等。细粒度图像识别是视觉感知嵌入的基础性工作(Belongie,2017),长期受到计算机视觉界的高度关注,美国的斯坦福大学、加州大学伯克利分校、哥伦比亚大学、英国牛津大学等一些计算机学科的顶尖单位都是该领域非常活跃的研究机构(Berg等,2014;Jaderberg等,2016;Khosla等,2011;Zhang等,2014)。细粒度图像识别已广泛用于智慧零售场景下的商品识别(Follmann等,2018)、公共安防场景下的车辆(Wei等,2018)及行人重识别(Yin等,2020)、车型识别(Krause等,2013)、危险品检测和识别(Miao等,2019)以及生物多样性监测(Aodha等,2019)等诸多领域,特别是在智能新经济和工业互联网的产业应用中展现出巨大实用价值。
近年来,细粒度图像识别围绕如何发掘图像中细微但具有分辨力的物体部件级别信息,以及获取具备细粒度表征能力的图像表示,发展出了一系列性能良好的识别方法,取得了深入的研究进展和广泛的现实应用。但大规模优质细粒度图像数据的获取需要耗费大量人力财力,尤其在某些特定任务中还需领域专家参与图像标注过程,这为细粒度图像识别的推广和普及带来了巨大障碍。在互联网和大数据快速发展时期,网络监督图像数据逐渐成为驱动深度学习模型训练的新型数据源,网络上免费的海量数据可缓解深度学习对大规模人工标记数据集的依赖,增加模型的易用性和推广性。
本文以细粒度图像识别,特别是网络监督下的细粒度识别为重点,介绍相关数据集、任务特点及挑战以及基于深度学习的经典方法和解决方案。此外,回顾了全球首届网络监督数据下的细粒度图像识别竞赛,希望通过对竞赛相关情况及冠军做法的分析,为该领域研究者和相关行业从业者提供一定借鉴。最后,讨论和总结了细粒度图像识别领域的未来发展趋势。
1 细粒度图像数据集
领域内已发布了一系列公开的细粒度图像识别数据集,用于统一评测相应方法的细粒度识别精度并推动相关技术的发展。本节围绕传统细粒度图像识别数据集、传统网络监督图像识别数据集和网络监督细粒度图像识别数据集进行介绍。
1.1 传统细粒度图像识别数据集
细粒度图像识别是近几年非常热门的一个领域,旨在将传统语义类别下的大量差异较小的子类别进行精确分类。近几年涌现出很多细粒度基准数据集,这些数据集包含了各个方面,如图1所示。其中包括鸟类(van Horn等,2015;Wah等,2011;Berg等,2014)、狗(Khosla等,2011;Sun等,2018)、车辆(Krause等,2013)、飞机(Maji等,2013)、花朵(Nilsback和Zisserman,2008)、蔬菜(Hou等,2017)、水果(Hou等,2017)、零售商品(Wei等,2019a)等。这些细粒度基准数据集的建立在一定程度上显示了当代社会视觉智能的现实需求。细粒度基准数据集不仅可以作为衡量模型效果的共同基础,还可将细粒度识别领域推向一个更加实用的方向。

图1 细粒度图像识别举例Fig.1 Examples of fine-grained image recognition((a) car;(b) aircraft;(c) vegetable;(d) retail goods;(e) bird;(f) flower;(g) dog;(h) fruit)
此外,越来越多更实用、更具有挑战性的细粒度数据集被逐渐提出。例如,针对智能零售场景下的细粒度商品感知的数据集(large-scale retail product checkout dataset,RPC)(Wei等,2019a),针对不同动物和植物等自然物种的iNaturalist(van Horn等,2018)。从这些新颖且贴合实际的数据集中可以发现一些具体的现实数据分布特征,例如大规模、长尾分布等。这些数据特性及分布特征可以从侧面展示现实生活中的实际问题,促进模型的学习,使产生的模型具有更强的实用性。
1.2 传统网络监督图像识别数据集
为增强数据实用性,同时减少大规模数据集标记带来的高昂成本,利用网络构建的数据集逐步走进人们的视野,经典的网络监督数据集有WebVision(Li等,2017)、OpenImages(Krasin等,2016)和NUS-WIDE(Chua等,2007)等。其中,WebVision数据集的来源主要有两个,分别是Google和Flickr两大搜索引擎。具体数据集构建时根据ImageNet中1 000个类别的文本信息从网站上进行图像数据的爬取,获得WebVision数据集中的数据,即WebVision数据集的数据类别是与ImageNet完全一致的1 000个类别。WebVision数据集的训练集由240万幅图像构成,此外,还有5万幅图像构成的验证集和5万幅图像构成的测试集(均带有人工标注)。WebVision数据集存在两个比较大的挑战:1)数据分布不平衡,有的类别样本数量高达11 000幅,而有的样本数量小于400幅,这种样本极度不平衡的现象会对训练模型产生较大的不利影响;2)数据集中含有大量噪声数据,即错误标记或有歧义标记的图像,这对深度神经网络的训练也会产生较大影响。
1.3 网络监督细粒度图像识别数据集
与传统网络监督图像识别数据集相比,网络监督下的细粒度图像识别数据除具有网络监督数据的特性外,还存在细粒度图像的鲜明特征,即类内差异大、类间差异小。在网络监督细粒度图像识别数据集的驱动下,不仅可以在一定程度上缓解细粒度图像识别对海量高质数据的依赖,而且还有望提高细粒度识别技术的可扩展性和实用性。
目前,该领域规模最大的数据集为WebFG(the webly-supervised fine-grained image recognition)2020(Wei等,2020a),是在2020年亚洲计算机视觉会议(Asian Conference on Computer Vision,ACCV)上举办的全球首届网络监督下的细粒度图像识别竞赛中提出的,其训练集和测试集数据全部来自搜索引擎Bing。为使数据集更贴合真实世界,该数据集特设定了包含动物、植物、昆虫的5 000个类别,训练集图像有557 169幅。WebFG 2020数据集存在3个主要挑战:1)类内差异大,类间差异小,类别多样,包含广泛,如图2(a)所示。2)数据集中存在较多噪声数据。因为数据的来源是网络,所以存在大量不相关数据和二义性数据。此外,数据集每一类别中可能混淆其他类别数据而造成数据集中存在噪声,如图2(b)(c)所示。3)类别样本分布不均衡,具有明显的长尾分布,即常见(但少量)的物体类别在视觉图像中出现的频次占主导地位,而罕见(却大量)的物体类别出现的频次占比微乎其微,如图3所示。
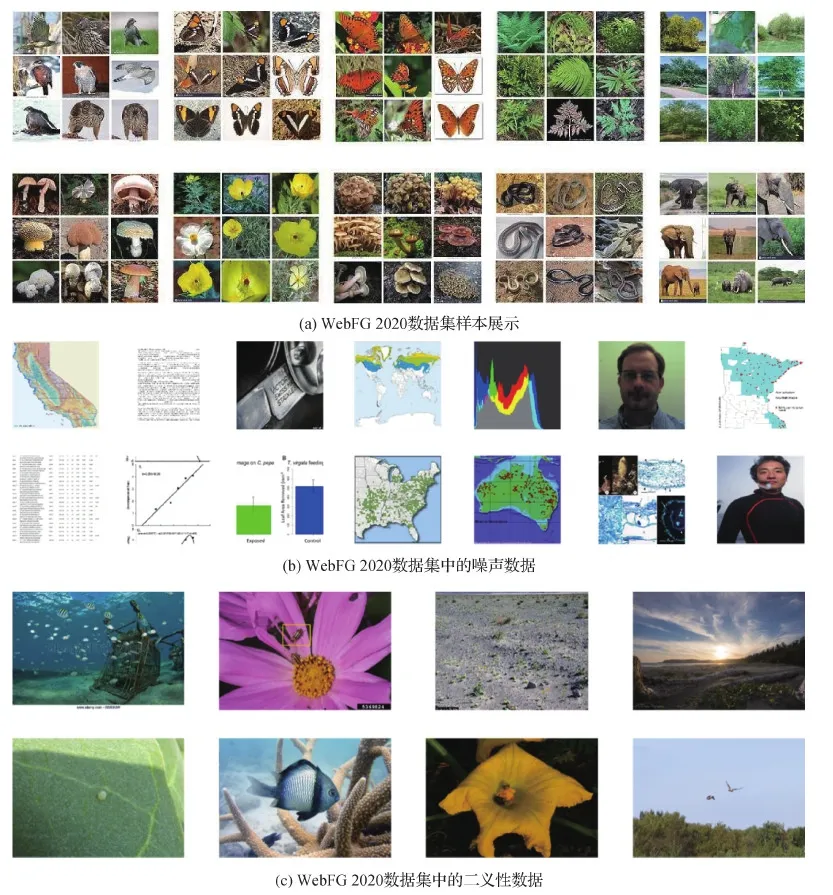
图2 WebFG 2020数据集Fig.2 The WebFG 2020 dataset ((a) sampled images of the WebFG 2020 dataset;(b) irrelevant/noisy images in the WebFG 2020 dataset;(c) ambiguous images in the WebFG 2020 dataset)
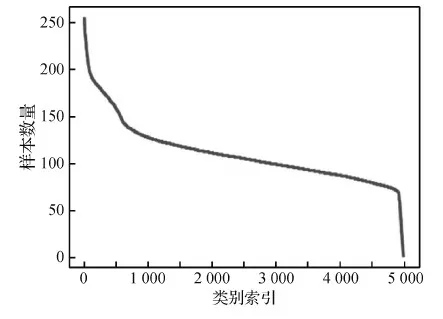
图3 WebFG 2020数据集样本分布Fig.3 Data distribution of the WebFG 2020 dataset
2 传统细粒度图像识别方法
传统细粒度图像识别在过去十几年间发展迅速,常用数据集有动物种类(van Horn等,2018)、车辆(Krause等,2013)、水果(Hou等,2017)等。不仅如此,这些细粒度识别在现实生活中皆有广泛应用,细粒度识别动物种类可以参与到生态系统保护中用于识别生物信息,细粒度识别水果等商品可以用于智能零售行业(Wei等,2019a,2020b)。但因为各个子类别之间区别较小,并且子类别之间还有较大差异,因此如何精确地进行细粒度图像识别是一个重大挑战。研究者从不同方面处理细粒度图像存在的问题。细粒度图像识别的主要方法有3种范式:1)基于“定位—分类”子网络进行细粒度图像识别;2)使用端到端特征编码进行细粒度图像识别;3)使用额外信息进行细粒度图像识别。其中第1种和第2种范式通过利用细粒度图像本身携带的图像标签、边界框和细粒度对象属性等信息监督模型训练。但由于细粒度的特点和挑战,为进一步提升识别精度,研究人员逐渐尝试利用更多的外部但廉价的信息(如网络数据、文本描述)帮助其进行细粒度识别,以进一步提高准确性,这就是第3种范式。
2.1 基于“定位—分类”子网络的细粒度识别范式
为了应对类内变化带来的挑战,研究人员将重点集中在如何捕获细粒度对象具有分辨力的语义部件(part),然后构建与最后的分类相对应的中层表示。具体来说,在基于“定位—分类”子网络范式下,定位子网是为定位细粒度对象的关键部件设计的,而分类子网则用于分类,两个子网协同工作最终完成细粒度识别任务。该范式如图4所示,现有方法可分为3种主要类型:1)基于检测或分割技术的细粒度识别;2)基于深度滤波器的细粒度识别;3)基于注意力机制的细粒度识别。
2.1.1 基于检测或分割技术的细粒度识别
基于检测或分割技术的细粒度识别是指采用检测或分割技术定位细粒度图像对应的关键区域,比如鸟类可以定位鸟的头部、尾巴和翅膀等。根据边界框或分割掩码等局部信息可以获得更具有辨识度的中层特征表示,利用这些信息进一步提高分类子网的学习能力,从而提高最终识别的准确率。
这类范式中的早期工作使用了很多额外的对象部位注释来定位细粒度对象的关键部件。Branson等人(2014)利用一组检测到对象部位的关键点来计算多个图像区域,进一步通过位姿归一化得到相应的部件级特征。Zhang等人(2014)首先提出了基于部件级别的包围框注释,然后训练一个区域卷积神经网络(region-convolutional neural network,R-CNN)(Girshick等,2014)模型作为关键区域检测器。与检测技术相比,语义分割有更准确的局部定位效果(Wei等,2018),因为分割代替了粗糙的边界框注释,是在更细粒度的像素级水平上完成的。然而,使用传统的检测器或分割模型需要密集的部件级标记进行训练,这会严重影响细粒度图像识别的可扩展性。因此,只使用图像级标签(Zhang等,2016b;He和Peng,2017;Ge等,2019;Wang等,2020;Liu等,2020)进行准确定位细粒度零件的方法相继提出,且逐渐成为热点。由于这类方法只使用图像级标签,故称为“弱监督”细粒度图像识别方法。除此之外,一些方法试图通过学习部件级特征之间的相互关系来获得更强大、更泛化的细粒度图像表示,通过执行不同的特征融合策略来联合局部特征进行学习,例如长短时记忆网络(Lam等,2017;Ge等,2019)、图(Wang等,2020)或知识蒸馏(Liu等,2020),结果表明这比以往独立的局部特征学习有更高的识别精度。
2.1.2 基于深度滤波器的细粒度识别
在深度卷积神经网络(deep convolutional neural network,DCNN)中,深度滤波器指的是在卷积层学习的权重。研究人员发现,中间的CNN输出能够连接公共对象的语义部分(Zeiler和Fergus,2014),因此人们尝试使用滤波器输出作为部件探测器(Zhang等,2016a;Wang等,2018;Ding等,2019;Huang和Li,2020)。依靠它们进行细粒度识别的一个主要优点就是不需要任何部件级别的标记。Xiao等人(2015)利用谱聚类将深度滤波器聚成多组,然后利用滤波器组作为部件检测器。此外,为了便于检测和分类学习,还开发了统一的端到端训练的细粒度模型(Wang等,2018;Ding等,2019;Huang和Li,2020)。结果表明,该模型可显著提升识别精度。
2.1.3 基于注意力机制的细粒度识别
虽然之前细粒度的局部化分类方法已经表现出很强的分类性能,但其主要缺点在于对象的部件需要有监督信息。而在许多现实应用任务中可能很难定义某一对象的某些部件,例如非结构化对象食物(Bossard等,2014)或花朵(Nilsback和Zisserman,2008)。相比前面的方法,更自然的寻找局部位置的解决方案就是利用注意力机制(Itti等,1998)作为子模块。这使得CNN关注细粒度对象的定义区域,因此注意力机制成为一个有前途的方向。
众所周知,注意力在人类的感知中起着非常重要的作用(Itti等,1998)。根据这一特点,Fu等人(2017)和Zheng等人(2017)率先采用注意力机制提高细粒度物体识别的准确率。Peng等人(2018)和Zheng等人(2020)提出了多层级的注意力模型,从而获得分层的注意信息(即对象级和部件级)。Yan等人(2017)利用属性引导的注意力机制提取图像特征,从而提高细粒度图像识别的准确率。Sun等人(2018)合并通道注意力并进行度量学习,从而加强不同参与区域之间的相关性。Zheng等人(2019)开发了一种多线性注意力采样网络,主要作用是在数百个关键区域中学习细粒度特征并有效地提取到一个CNN中。Ji等人(2020)提出了一种基于卷积二叉神经树的注意力机制,将注意力机制和树结构相结合,以方便模型由粗到细分层次进行细粒度特征的学习。此外,Cui等人(2020)利用注意力机制获取局部和全局的特征,并利用哈希进行分类,对提升图像检索识别效率起到了促进作用。需要指出的是,虽然注意力机制在细粒度识别中取得了很高的精度,但是它往往会过拟合,尤其对小规模数据过拟合的风险更高。
2.2 基于端到端特征编码的细粒度识别范式
另一种细粒度识别范式是端到端特征编码,与其他视觉任务一样,特征学习在细粒度识别中也起着十分重要的作用。因为子类别之间的差异通常较小,用全连接层捕获全局语义信息限制了细粒度模型的表达能力,从而影响了最终的细粒度图像识别。基于端到端特征编码的细粒度识别范式如图5所示。目前提出的方法主要有以下3种:1)基于高阶特征编码的细粒度识别;2)设计新的损失函数的细粒度识别;3)其他细粒度识别方法。

图5 基于端到端特征编码的细粒度识别范式Fig.5 Illustration of fine-grained recognition based on end-to-end feature encoding
2.2.1 基于高阶特征编码的细粒度识别
特征学习几乎在所有视觉任务中都扮演着至关重要的角色。深度卷积网络的成功主要是因为学习图像中的深度特征。在深度学习的初始阶段,全连接层的特征通常用做图像表示,之后发现顶部卷积层的特征映射包含更加丰富的信息(如对象的整体和局部信息),使得卷积特征(Liu等,2015;Xu等,2015)广泛使用。与全连接输出相比,卷积神经网络上的编码技术显著改善了细粒度图像识别的结果(Cimpoi等,2015;Xu等,2015)。在某种程度上,这些改进的编码技术来自于最终特征的高阶统计编码。
基于协方差矩阵的表示(Wang等,2015)是一种具有代表性的高阶特征交互技术,目前已在计算机视觉和机器学习中得到应用。在过去的几年里,通过将基于协方差矩阵的表示与深度特征表示相结合,在细粒度识别中表现出良好的准确性。其中最具代表性的方法就是双线性卷积神经网络,它将图像表示为两个深度卷积神经网络,然后解码二阶统计编码,该方法使细粒度识别有明显改善。但是这个方法会导致过拟合,在大规模数据集上表现尤为突出。为了解决这个问题,Gao等人(2016)应用Tensor Sketch来减少特征维度。Kong和Fowlkes(2017)提出了对协方差矩阵的低秩逼近和低秩双线性分类器,由此产生的分类器无需显式计算双线性特征矩阵的参数便可进行评估。Li等人(2017)利用低秩约束和二次变化模拟成对特征的相互作用。Yu等人(2018)在双线性映射前采用降维投影来缓解维数爆炸问题。除了这些方法,有些方法还试图捕获更高阶数的特征以产生更强的表示。Cui等人(2017)提出了一种通过特征映射捕获任意有序和非线性特征的核池化方法。
2.2.2 基于新型损失函数的细粒度识别
损失函数在深度网络的构建中起着重要的作用,它可以直接影响分类结果和模型功能,因此,设计细粒度专有的损失函数也是细粒度识别的一个重要方向。
不同于一般的图像识别,在细粒度分类中,类间样本在视觉上可能会非常相似,遵循这一原理,Dubey等人(2018)使用两两混淆优化程序,以解决过度拟合和样本特定的细粒度识别,随后降低其预测过度的置信度,从而提高泛化能力。人类可以通过比较图像来有效地进行识别,而这种对比学习在细粒度识别中也很常见。Sun等人(2018)首先学习了多个部件对应的注意力区域,然后利用度量学习将相同注意的同类特征拉近,同时将不同注意或者不同的类特征推远,此外,在训练过程中,Sun等人(2018)方法还可以增强不同对象之间的相关性。注意力成对交互网络(attentive pairwise interaction net,API-Net)(Zhuang等,2020)也是建立在度量学习框架之上的一种方法,它可以自适应地从一对图像中发现对比线索,并通过两两注意力的交互来区分它们。除此之外,设计一个单一的损失函数定位局部区域并进一步强化图像级别的表示也逐渐成为研究热点。Sun等人(2020)提出了一个基于梯度的损失函数和一个迫使网络快速区分类别的模块,可较好地分辨模糊和混淆的细粒度类别。
2.2.3 其他细粒度识别方法
除上述方法,还有其他一些提高细粒度识别准确率的方法。Zhou和Lin(2016)提出将二分图标签放入卷积神经网络模型中用以训练细粒度类别之间的重要关系。Xiong等人(2020)提出一种更直接的细粒度特征学习方法,即制定细粒度图像的对抗性学习方式,从而直接获得一个统一的粗粒度图像表示。这种直接的特征学习方式不仅保留了生成图像的特性也显著提高了视觉识别性能。
2.3 基于额外信息的细粒度识别范式
除了传统的识别范式,另一种范式是利用外部信息,例如网络数据、多模态数据或人机交互等,以进一步帮助细粒度识别。图6展示了基于额外信息的细粒度识别范式,主要包括基于网络数据的细粒度识别、基于多模态数据的细粒度识别和基于“人在回路”的细粒度识别。
图6 基于额外信息的细粒度识别范式Fig.6 Illustration of fine-grained recognition based on external information
2.3.1 基于网络数据的细粒度识别
为了提高细粒度图像识别的准确率,通常需要海量且标注良好的图像作为数据集。然而,海量高质数据的标注需要耗费大量的成本。与此同时,网络数据在细粒度识别上展现出的卓越成果(Krause等,2016)让学者们将研究目光放在了如何使用网络数据上。基于网络数据进行细粒度图像识别大致分为两个方向。第一个方向是利用网络上免费却含有噪声的数据,通过收集整理生成数据集进行训练来提高细粒度图像识别的正确率。该方法称为网络监督学习(webly-supervised learning)。网络监督学习方法主要集中在消除网络数据和标注良好的标准数据集之间的差距,从而减轻网络数据集中噪声数据带来的负面影响。为了解决因网络数据集特性产生的问题,学者们频繁使用对抗学习的深度学习技术(Goodfellow等,2014)和注意力机制(Zhuang等,2017)作为解决方法。第二个方向是利用标记良好的辅助类作为训练集转移知识,其通常应用于零样本学习(Niu等,2018)或元学习(Zhang等,2018a)。
2.3.2 基于多模态数据的细粒度识别
随着多媒体数据的快速增长,如何利用多媒体数据进行细粒度识别也引起了广泛关注。与网络监督学习不同,基于多模态数据的细粒度识别是利用文本信息或知识图谱等多媒体数据来帮助模型进行细粒度识别,从而提高细粒度的识别精度。经常使用的多模态数据包括文本描述(例如自然语言的句子和短语)和图结构的知识库。与基于部分注释的强监督细粒度图像识别相比,多模态数据属于弱监督类型。除此之外,多模态数据中的内容(如文本描述)可以不需要领域专家进行标注,普通人也可以利用自己掌握的知识进行相对准确地反馈。图结构的知识库中,高阶知识图谱(high-level knowledge graphs)是一种常用的资源,其包含丰富专业知识可以为细粒度识别提供较好的辅助指导,如DBpedia(Lehmann等,2015)。Reed等人(2016)收集文本描述,并引入了一种结构化的联合嵌入,通过组合文本和图像来实现零样本细粒度图像识别。He和Peng(2017)以端到端的联合训练方式将视觉和语音流结合起来,从而生成互补的细粒度表示。
2.3.3 基于“人在回路”的细粒度识别
“人在回路”的细粒度识别通常是一个由机器和人类用户组成的迭代系统,结合了人的智慧引导和机器的智能,要求系统尽可能以人类劳动的方式工作。一般来说,对于这些类型的识别方法,每轮中的系统都在寻求理解人类如何执行识别。例如,通过要求未训练的人类标记图像类别并挑选样例(Cui等,2016),或者通过识别关键部位定位并选择辨别特征(Jia等,2016)来进行细粒度识别。
3 网络监督细粒度图像识别
为缓解细粒度图像识别对高质海量数据的依赖,基于免费网络图像的网络监督细粒度图像识别逐渐引起学界和业界研究者的关注。而目前网络监督下的细粒度图像识别尚处于起步阶段,本节将首先介绍网络监督细粒度图像识别的主要特点及挑战,之后分别针对这些挑战介绍相应解决方案。
3.1 网络监督细粒度图像识别的主要挑战
与传统细粒度图像识别一样,因不同类别之间存在的差异较小,如何准确高效地识别不同的类别依旧是一项非常重要的挑战。除此以外,网络监督细粒度图像识别还有其独特的挑战。
网络监督细粒度图像识别数据集中的图像来源于网络,由于网络中数据查找的问题,搜寻到的数据存在严重的噪声数据,而深度神经网络输出结果的精确性与具有高质量标注的大规模数据集有着十分密切的关系,利用含有噪声数据的训练集进行训练会严重影响在无噪声数据的测试集上的准确率。
数据集中的噪声数据一般分为不相关数据和二义性数据两种。不相关数据是指该图像与所属类别的图像没有任何关系,即标签错误的数据。例如在ACCV WebFG 2020竞赛(Wei等,2020a)中的不相关图像(图2(b))有地图、表格、指示符和论文截图等。这种情况就需要对含有噪声的数据集进行“清洗”,保留有用数据。二义性数据是指数据中含有多个类别物体的图像,标签无法确定类属于哪一个物体。例如在ACCV WebFG 2020竞赛中训练集的二义性图像(图2(c))中包含两种鱼类,但是图像却仅存在一种类别中,标注的类别究竟指向哪一类并没有明确说明。还有的图包含一只昆虫和一朵花,图像也同样只存在于一个类别中,标注没有具体说明指向的是花还是昆虫。这样的二义性问题会影响模型的训练。
网络是人类创造的最大的公共数据集,在这个庞大的数据集中,提取到的数据必然会存在质量上的问题,即数据偏差。在网络环境中,数据是由人们以自己的意识生成的,在生成过程中必然会受到各方面因素(如文化、政治和环境等)的影响。在细粒度数据集中的表现尤为突出,由于细粒度数据集中各个类别区别不大,网络中数据的发布者因为自身因素将数据错认从而产生数据偏差这一问题更是常见。此外,网络数据集中数据发布者根据自身喜好,在同一环境同一角度发布同一数据的情况也经常发生,这必将对模型训练产生影响。
长尾分布是指少数类的样本数量庞大而多数类的样本量较小的数据分布现象,这一现象非常契合真实世界的情况。在真实世界中随处可见的动植物只占很少的一部分,还有很大一部分的动植物是在正常生活中见不到的,这种情况反推到网络监督细粒度数据集中也是一样的道理。网络中的图像也需要人为拍摄采集,尾部数据在日常生活中稀有,拍摄的图像少。当利用网络构建一个类别的细粒度数据集时,网络中存在比较多的是日常中常见的细粒度类别,从而构造时会产生存在长尾分布的网络监督细粒度数据集。直接利用呈现长尾分布的网络数据来训练模型往往会对头部数据过拟合,从而在预测时忽略尾部的类别,影响模型的准确率。
由以上分析可知,网络监督下的细粒度图像识别主要挑战有以下几个方面:1)细粒度图像普遍存在类间差异小、类内差异大的特点,如何准确地对细粒度类别进行精准的判定,在当前仍是一个极大挑战。2)网络监督细粒度数据集中存在较多的噪声数据,过多的噪声数据会影响模型的训练,从而影响结果的判定。如何去除噪声数据的影响,使模型较好地完成识别任务是目前存在的另一大挑战。3)网络中的数据会因人的主观因素产生数据偏差,存在偏差的数据加上细粒度类别之间相似程度高的特性,在很大程度上影响细粒度图像的识别。4)自然界存在的长尾分布特点会映射到网络中,使网络中的数据存在长尾分布,从而导致数据存在过拟合问题,影响模型的识别精度。
3.2 针对噪声数据的解决方案
解决数据集中存在的噪声数据问题主要有两种方式,分别是聚类和交叉验证。
3.2.1 聚类
聚类就是按照某个特定标准(如距离准则)将一个数据集分割成不同的类或簇,使得同一个簇内数据对象的相似性尽可能大,同时,不在同一个簇中的数据对象的差异性也尽可能大。根据这一特性可以将数据集中的噪声数据与真实数据分开,从而达到清洗数据集的效果。聚类方法分为传统聚类方法和现代聚类方法。传统聚类方法主要有基于划分的聚类、基于层次的聚类、基于密度的聚类、基于网格的聚类、基于分形理论的聚类和基于模型的聚类。现代聚类方法主要有核聚类算法和大规模数据的聚类等。
基于划分的聚类算法(MacQueen,1967)的基本思想是将数据点的中心作为对应聚类的中心。但是该算法对离群值相对敏感,容易陷入局部最优,且聚类数需要预设,聚类结果对聚类数敏感,不适合网络监督细粒度数据的“清洗”工作。
基于层次的聚类算法(Guha等,1998;Jafarzadegan等,2019)的基本思想是构造数据之间的层次关系,以便进行聚类。假设每个数据点一开始代表一个单独的簇,然后,最相邻的两个簇合并成一个新的簇,直到只剩下一个簇,或者构造其反向过程。该算法适用于任意形状和任意类型属性的数据集,聚类之间的层次关系容易检测,一般可扩展性较高,但是时间复杂度相对较高,集群数量一般需要预设。
基于密度的聚类算法(Kriegel等,2011)的基本思想是认为位于数据空间高密度区域的数据属于同一个聚类。Corizzo等人(2019)利用密度聚类实现了一种分布式算法,从而利用已识别的聚类解决单目标和多目标的回归任务。Li等人(2020a)提出了一种利用最近邻图的固有性质识别局部高密度样本的方法。该类算法高效,适用于任何形状的数据,对数据集发现噪声数据并进行数据集“清洗工作”有明显效果,但数据量大时需要更大的内存。
基于网格聚类算法(Wang等,1997)的基本思想是将原始数据空间转化为一定大小的网格结构进行聚类。
基于分形理论的聚类算法(Mandelbrot,1983;Barbar和Chen,2000)认为对象的部分和整体是有一些共同特征的。整体可以分成几个部分的几何图形。这种聚类算法的核心思想是任何内部数据的变化对分形维度上的内在质量都没有任何影响。
基于模型的聚类算法(Fisher,1987)的基本思想是为每个簇选择一个最合适的模型。基于模型的聚类算法主要有两种,一种基于统计学习方法,另一种基于神经网络学习方法,该方法计算复杂度高。
核聚类算法(Schölkopf等,1998)的基本思想是通过非线性映射将输入空间中的数据转换到高维特征空间中进行聚类分析。该算法在一定程度上分担了计算的局限性,与此同时可以推广到多标签聚类问题。Ren和Sun(2021)提出的结构保持多核聚类方法采用一种新的核仿射权重策略,该策略可以自动为每个基本核分配合适的权重。
大数据有4个主要特点,即容量大、种类多、速度快和准确性存疑。大数据聚类按基本思想可以归纳为4类:1)样本聚类(MacQueen,1967);2)数据合并聚类(Steinbach等,2000);3)降维聚类(Kriegel等,2009);4)并行聚类(Tasoulis和Vrahatis,2004)。
从上述介绍可以看出,划分聚类和层次聚类的类别数量需要预设,不适合大规模数据集的清洗;网格聚类和分形聚类因其特性不利于网络监督数据集中噪声数据的去除;模型聚类可以进行清除但是需要的计算成本太高。根据数据的无序和数据量大的特性,密度聚类、核聚类和大数据聚类在一定程度上可以对网络监督数据集进行噪声数据的清除。
3.2.2 交叉验证
交叉验证本是用来验证分类器性能的一种统计分析方法,在这里可以进行细粒度数据集中噪声数据的筛选工作。常见的交叉验证形式大致分为4种,即保持法(holdout验证)、2折交叉验证、K折交叉验证和留一法。
保持法(Kohavi,1995)将原始数据随机分为训练集和验证集两组,利用训练集训练模型,然后利用验证集验证。严格来说,保持法并不能算是交叉验证,因为这种方法没有达到交叉的思想,并且保持法有一定的缺点,由于原始数据是随机分成两组,最后验证集分类准确率的高低与原始数据的分组有很大关系,所以该方法得到的结果不稳定,没有较强的说服力。
2折交叉验证(Cudeck和Browne,1983)是将数据集划分为两个大小相同的子集进行两次模型训练。第1次训练时,一个子集做训练集,另一个子集做测试集;第2次训练时,做训练集和做测试集的子集调换,再对模型进行训练。该方法中因为划分子集的随机性,导致数据子集变异度大,实验过程不可复制,所以得到的结果不稳定。
K折交叉验证(Stone,1974)本是防止模型过于复杂而引起过拟合所产生的一种评价训练数据泛化能力的统计方法。该方法可以有效避免过拟合以及欠拟合状态的发生,最后得到的结果也比较具有说服性。具体操作是将数据集等比例划分成K份,以其中的一份作为测试集,其他的K-1份数据作为训练集。如此操作进行K次结束,也即实验重复了K次,每一次都从这K份中选取没有当做测试集的数据作为测试集,余下的K-1份数据集作为训练集,K次进行完毕后,所有的数据都有一次当做测试集。该方法对数据清洗还有着十分显著的效果,具体过程是将数据划分为K部分,每一部分都轮流做“清洗对象”即测试集,将当前没有被正确识别的数据称为负样本,负样本中含有大量的噪声数据,根据多次筛选,在测试集中没有被正确识别的数据(即负样本)会被当做噪声数据最后从数据集中删除。由于通过K折交叉验证可能会删去过多的真实数据,根据ACCV WebFG 2020参赛选手的做法,此处的K折交叉验证还可以设置一个“回捞”步骤,即将K次测试过程中测试集中较高正确率的数据进行收集,这些数据称为正样本。收集完毕后,将正样本投入到模型中对模型进行再次训练。训练完成的模型对所有的负样本进行测试,将预测正确的数据再放回数据集中,该步骤可以重复多次进行,直到没有正样本产生,从而结束“回捞”。
留一法就是将每个样本单独作为验证集,其余的N-1个样本作为训练集,所以留一法会得到N个模型。相比于K折交叉验证,留一法有两个明显优点。一是每次训练几乎都是所有的样本都用于模型训练,因此最接近原始样本的分布,这样评估的结果比较可靠;二是实验过程中没有随机因素影响实验数据,确保实验过程是可以复制的。但留一法计算成本高,当原始数据样本数量相当多时,留一法几乎不可能使用,由于网络监督数据集中数据非常多,进行噪声数据的清除工作时间成本太大,使用留一法不太现实。
3.3 针对数据偏差的解决方案
网络中的数据是发布者以自己的意识生成/上传的,过程中会受到文化、政治和环境等各方面因素的影响,于是便会产生数据偏差。由于细粒度类别之间的相似性,数据偏差问题在细粒度数据集中的表现尤为突出。解决数据集中存在的数据偏差问题的主要方式有知识蒸馏、标签平滑和数据增强。
3.3.1 知识蒸馏
网络监督数据集中存在的数据偏差会对模型的训练产生影响,知识蒸馏中产生的暗知识可以在一定程度上缓解数据偏差带来的消极作用。
知识蒸馏(Hinton等,2015)即将大模型中的暗知识提取出来供小模型进行学习。知识蒸馏中的暗知识有3种。1)基于结果反馈的知识(Hinton等,2015),通常是指教师模型最后一个输出层的神经反馈,即直接模仿教师模型的最终预测;2)基于特征的知识(Romero等,2015),即利用中间层的特征和最后输出层的结果共同对学生模型进行训练;3)基于关系的知识(Yim等,2017),前两种方法是使用教师模型中特定层的输出,基于关系的知识是进一步探索不同层或数据样本之间的关系,并作为知识对学生模型进行训练。
知识蒸馏的学习方案大致也分为3种,即离线蒸馏、在线蒸馏和自蒸馏。
早期的知识蒸馏方法大多是离线蒸馏。Hinton等人(2015)提出的方法中知识是从预先训练的教师模型转移到学生模型。整个训练过程分为两个阶段,一是先在一组训练样本上训练教师模型,然后进行蒸馏;二是教师模型以逻辑或中间特征的形式提取知识,然后将提取的知识用于指导学生模型的训练。在离线蒸馏过程中,研究人员主要对知识转移进行了不同角度的研究。Romero等人(2015)和Hinton等人(2015)对产生的知识进行了设计。除此之外,还有用于改善匹配特征或分布匹配的损失函数(Passalis和Tefas,2018;Li等,2020b)。离线蒸馏简单且易于实现,但是教师模型训练时间消耗巨大,学生模型在一定程度上高度依赖教师模型。
针对离线蒸馏的不足之处,Zhang等人(2018b)提出在线蒸馏,在没有大容量高性能教师模型的情况下提高学生模型的性能。在线蒸馏过程中,教师模型和学生模型可以同步更新。Lan等人(2018)提出了一种多分支架构,其中每个分支表示一个学生模型,不同的分支共享同一个主干网络。
在自蒸馏中,相同的网络用于教师和学生模型。这可以看做是在线蒸馏的特例。Zhang等人(2019)提出了一种新的自蒸馏方法,来自网络较深部分的知识被蒸馏到其较浅部分。Snapshot 蒸馏(Yang等,2019)是自蒸馏的一种特殊变体,网络早期(教师)的知识被转移到网络后期(学生)以支持同一网络内的监督训练过程。
3.3.2 标签平滑
标签平滑(label smoothing)是分类问题中用来缓解数据集含有错误标签的一种解决方法。对于分类问题来说,常常会将分类的预测结果向量转换成one-hot向量,对于损失函数来说需要用预测的结果来拟合真实概率,而拟合one-hot的真实概率函数会产生两个问题:1)模型的泛化能力无法保证,大概率会出现过拟合现象;2)one-hot向量会使模型过于相信预测的类别,那么如果数据集内的数据错误,对训练的模型将会有较大影响。尤其是网络监督细粒度数据集中存在较为突出的数据偏差问题,数据集中数据标签并非完全正确。为了减少数据偏差带来的影响,使训练模型不要过度拟合数据集标签,产生了标签平滑机制。即
(1)
式中,Pi表示第i类的概率,ε是一个较小的超参数,K表示多分类的类别总数,i表示预测向量中的类别,y表示样本标签。利用式(1)可以使模型不会过于相信标签,保证在数据中真的出现错误数据时,也能缓解错误数据对模型训练产生的影响。
3.3.3 数据增强
由于数据偏差导致数据数量和质量得不到保障,缓解数据集中数据偏差的一个有效方法就是增加数据集中样本的数量,但是由于细粒度类别之间差别不大,人工引入数据的正确率得不到保障,如何能在现有数据集数据上进行数据扩充就显得十分重要,于是数据增强便成为解决网络监督细粒度数据集中数据问题的有效方法。
Krizhevsky等人(2012)在实验中使用了数据扩充,是通过在原始图像中随机裁剪,并使用主成分分析颜色增强改变RGB通道的强度实现的。数据增强的基础方法是通过各种几何变换和色彩抖动在数据集中的样本上进行数据扩充。除此之外,数据增强还有一些新颖的方法。Kang等人(2017)用一种独特的核滤波器进行实验,该滤波器在n×n滑动窗口中随机交换像素值。Inoue(2018)提出了将样本配对发展成有效的扩增方法。在实验中,两幅图像随机裁剪并随机水平翻转,然后通过平均每个RGB通道的像素值来混合这些图像。Liang等人(2018)使用生成式对抗网络(generative adversarial network,GAN)产生混合图像。他们发现在训练数据中包含混合图像减少了训练时间,并增加了GAN样本的多样性。GAN可以精细化地进行数据扩充,Zhu等人(2017)提出的CycleGAN引入了一个额外的损失函数,以帮助稳定GAN训练。Wang和Perez(2017)提出了一种元学习的神经扩增方式,从同一个类中随机选取两幅图像。通过卷积神经网络将它们映射成一幅新图像。Zhang等人(2018c)提出一种简单且数据无关的数据增强方式mixup,构建了虚拟的训练样本,构建方法为
(2)
(3)

3.4 针对长尾分布的解决方案
对于细粒度来说,只有一小部分的类别是日常生活中普遍见到的,而且数量众多,还有很多细粒度类别在日常生活中见不到,网络可以真实反映自然生活的状态,所以网络上的数据分布亦是如此。网络监督数据集存在明显的长尾分布,主要解决方法有重采样、重加权和新型网络结构。
3.4.1 重采样
重采样(re-sampling)是指对不同类别的图像根据样本数量进行反向加权,这样就产生了欠采样和过采样两种方法。重采样中最常见的策略称为类别均衡采样(Kang等,2020),采样公式为
(4)
式中,K为数据集的类别数量,ni为类别i的样本总数,pj为从j类别中采样一幅图像的概率。在传统的均衡采样策略中q=1,这时可以看出在采样过程中,选取头部样本的概率要大于选取尾部样本的概率。在这种情况下没有办法产生数据的完全均衡分布,于是在类别均衡采样中q=0,这样会使所有的类别都会采集到相同数量的样本。
过采样是对少数类中的样本进行随机复制以增加尾部类别的样本数,研究表明过采样对图像识别有明显效果(Jaccard等,2017),但是简单的过采样会导致过拟合。SMOTE(synthetic minority over-sampling technique)(Chawla等,2002)是一种克服长尾分布问题的采样方法,通过插值相邻创建数据点从而增加人工示例。Jo和Japkowicz(2004)提出了基于聚类的过采样,首先对数据集进行聚类,然后分别对每个聚类进行过采样,这样可以减少类间和类内的不平衡。Shen等人(2016)提出了一种类感知采样,是一种针对随机梯度优化神经网络的过采样,主要是保证每一批的类分布均匀,控制每个类中选择实例的数量。
与过采样相反,欠采样是从多数类中随机移除样本,直到所有类都具有相同数量的数据样本。欠采样一个显著的缺点就是丢弃了一部分可用数据,为了保证丢弃的数据不对模型产生较大的影响,Kubat和Matwin(1997)提出选择识别类之间边界冗余的样本数据。
3.4.2 重加权
重加权(re-weighting)主要体现在损失函数上,但也有其他的改进方法。
Cui等人(2019)提出了一种在模型和损失不可知的情况下计算样本的有效数量,并利用有效样本数量来设置惩罚权重的方法,该方法在长尾分布数据集上取得了较好效果。具体计算为
(5)
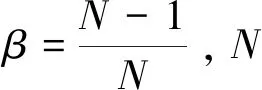
Cao等人(2019)提出一种基于margin的重权重方法,表明不同样本数量的类别应对应不同的margin,希望提高样本数量较少类别的泛化能力,使更少样本数量的类别有更大的margin。
3.4.3 新型网络结构
深度学习的图像分类任务通常将分类器部分和特征提取部分耦合在一起进行模型训练,但是常见的处理长尾分布的方法(例如重采样和重加权)是通过提高分类器的学习能力来缓解长尾分布带来的影响。修改类别的样本数量的重采样和扭曲数据分布的重加权都会在一定程度上影响模型的特征提取。于是,研究人员将网络解耦,然后分别进行训练。Kang等人(2020)将学习过程分解为表征学习和分类,并系统地探索不同的平衡策略如何影响长尾识别。实验表明,该方法有可能优于设计的重采样和重加权策略。双分支神经网络(Zhou等,2020)构建了两条分支,分别训练分类能力和特征提取能力,双分支神经网络将这两个重要模块进行解耦,保证这两个方面相互不影响,从而达到各自的最优效果,该模型的双分支共享参数,然后对这两个分支进行动态加权,二者协同促进深度学习在长尾分布上的泛化能力。实验结果表明,双分支神经网络在iNaturalist 2017/2018、CIFAR-10-LT和CIFAR-100-LT等多个长尾分布的标准数据集上均达到了目前最佳的表现效果。
4 网络监督细粒度图像识别竞赛
本节介绍和回顾全球首届网络监督细粒度图像识别竞赛情况和冠军做法,以期对该领域研究者和从业人员提供一定实践方面的借鉴。
在2020年亚洲计算机视觉会议(ACCV 2020)上,进行了首届网络监督细粒度图像识别国际性挑战赛WebFG 2020,主要解决网络监督下的细粒度图像识别问题。这项挑战期望参赛者能够开发网络监督细粒度识别模型并利用网络图像进行模型训练,以缓解深度学习方法大规模人工标记数据集的极端依赖,增强模型的实用性和可扩展性。
WebFG 2020竞赛吸引了来自全球的54支参赛队伍(Wei等,2020a),前10名成绩如表1所示,其中测试数据集按均匀分布划分为A榜和B榜,A榜占总测试集40%,B榜占总测试集60%。NetEase Games AI Lab团队获得冠军,其解决方法主要包括两方面。首先是清理噪声数据。比赛的训练集数据中包含样本标签错误的噪声数据,该队使用聚类和知识蒸馏对数据进行清理,因为数据存在长尾分布,清理时注意保持类间样本平衡。其次是模型的选择。主干网络对模型的表现至关重要,带注意力机制的主干网络能够聚焦于关键细节,带来更好的表现。该队使用EfficientNet(Tan和Le,2019)、ResNet(He等,2016)和双分支网络(bilateral-branch network,BBN)(Zhou等,2020)作为主干网络。

表1 WebFG 2020前10名队伍成绩展示Table 1 Display of the WebFG 2020 top-10 team performance
除此之外,参赛队伍中有很多优秀方法值得借鉴(Wei等,2020a)。例如,利用数据扩充方法缓解数据集中的数据偏差和长尾分布问题;利用尺寸调节解决数据集中物体较小的问题;利用标签平滑增强模型的泛化能力等。这些方法在一定程度上解决了网络数据集中存在的问题,但是有些方法在比赛中没有展现出效果。例如,利用边缘排序下的区域(area under the margin ranking,AUM)统计识别错误标记的数据(Pleiss等,2020),根据AUM的输出删除部分图像时会造成显著的精度下降。还有一些训练后的模型在单独进行测试时精度很高,但是进行多个模型融合后精度并没有提高。
5 展望与挑战
网络监督细粒度图像识别主要依赖网络细粒度图像数据进行模型训练,再对测试图像进行识别。根据上述网络监督细粒度数据的特点,总体来说有如下几方面的展望及挑战:
1)针对数据集中类别之间差异较小的特性,如何高效准确地进行图像识别是所有细粒度类数据集最基础且重要的问题。基于自监督、弱监督和无监督等学习范式在图像识别领域均取得了不错的进展,在保证细粒度图像识别准确率的基础上,逐渐使网络监督与自监督相结合、网络监督与弱监督相结合或者网络监督与无监督相结合,是下一阶段可能的发展方向。但网络监督数据集一般规模庞大且含有较多噪声,如何结合自监督等方式在不受噪声数据影响的情况下提高识别精度是一个新颖且充满挑战的任务。
2)网络数据没有具有专业知识的专家进行标注,其数据“纯度”不能保证,数据集中存在一定的噪声数据。如何在确保数据集纯度较高的同时高效清除数据集中的噪声数据,在现有方法上进行创新和总结,或设计专门应用于数据集去噪的模型是下一阶段可能的发展趋势。对于伴有噪声数据的网络监督识别问题,能否通过纯度较高的少样本甚至零样本从根源上解决这一问题尚待进一步考证。
3)网络中的数据在各种因素下会存在数据偏差问题,这个问题是必然存在的。除了通过上述标签修改手段和数据增强措施缓解数据偏差外,在数据集构建中,如何建立一个稳健的采集系统进行数据的合理收集也是构建网络监督数据集下一步需要研究的问题。
4)网络数据是对真实世界的映射,其数据分布和真实世界中细粒度类别的数据分布非常相似,即存在长尾分布现象。解决长尾分布目前主要有3类方法,其中对模型网络结构进行调整,即将特征学习和分类器学习进行解耦分治,是较为新颖有效的解决方案。若能将目前长尾分布中发现的规律应用于网络监督细粒度,也会对未来这一方向有着深远的影响。
5)目前网络监督细粒度图像识别方法是对数据不同方面的问题逐一处理后再进行模型训练。未来能否设计出一个统一框架的网络监督细粒度图像识别范式也是值得深入探索的问题。此外,基于Transformer(Dosovitskiy等,2021)的模型在细粒度图像识别中展现出不俗的实力(He等,2021),Transformer与网络监督下的细粒度识别相结合也是极具研究价值的方向。
6 结 语
细粒度图像识别是计算机视觉和模式识别的长期热门领域,随着深度学习的发展,细粒度图像识别取得了长足进步。但由于深度学习需要拥有高质量标签的大规模数据进行训练,实用性和扩展性受到了一定约束。为了解决这一问题,利用网络上的免费数据训练细粒度识别模型成为可行的研究方向,希望借此缓解深度学习对大规模人工标记数据集的依赖,在降低成本的同时以期提高细粒度识别技术的实用性。
本文通过介绍细粒度图像识别引出网络监督细粒度图像识别,对传统细粒度图像识别数据集、传统网络监督图像识别数据集和目前网络监督细粒度图像识别的数据集进行介绍,对比得出当前网络监督细粒度图像识别的特点和使用网络监督数据进行细粒度图像识别的意义。此外,介绍了传统细粒度图像识别的概念及多种范式,详细阐述了网络监督下细粒度图像数据的主要特点和问题,并总结了目前相应的解决方案。最后介绍了全球首届网络监督细粒度图像识别竞赛WebFG 2020的相关情况。
可以预见的是,随着深度学习在细粒度识别领域的深入发展,网络监督细粒度图像识别的研究与应用必将越来越多,涉及的范围也将越来越广,发挥的作用亦将越来越大。本文对目前网络监督数据细粒度图像识别进行了简要介绍,总结其大体框架。对未来而言,从理论研究走向落地应用定会遇到很多现实问题与挑战,如何克服这些困难并且探索更加实用的解决方法将是下一阶段需要着重展开的研究工作。
