来华留学预科汉语考试作文评分研究
——基于概化理论和多面Rasch模型
2022-07-14孔傅钰
孔傅钰
一、引言
中国政府奖学金本科来华留学生预科教育结业汉语综合统一考试(以下简称汉语预科考试),旨在评价来华留学生在接受了一学年预科教育后,其汉语水平是否达到了进入我国本科专业学习的要求。不同于一般的语言水平考试,预科考试既要测量学生的日常语言交际能力,又要考查其学习本科专业知识时的汉语运用能力[1]。其中,作文是重要的组成部分,其目的是考查学生书面叙述一件事情或简单说明一个问题的能力,而对考生写作能力的判断则以评分员评判的分数为基础,因此,作文评分质量问题一直备受关注。一般来说,在整体评分中,评分员数量越多,越有可能减少因个体认知差异而产生的评分偏差。然而,受人力和经济等条件的限制,实际操作时需要在评分员数量和评分信度之间寻找平衡。早期的研究多在经典测量理论(Classical Test Theory,CTT)的框架下进行,主要聚焦评分的一致性,然而CTT依赖具体测试样本且无法解释评分者数量、试题形式等因素带来的误差。概化理论(Generalizability Theory,GT)和多面Rasch 模型(Many-Facet Rasch Model,MFRM)则在一定程度上能够对这些误差来源进行有效评估,因而成为目前探讨作文评分问题的主要理论方法。本研究将使用这两种方法,以5名评分员对120 份汉语预科考试作文实测卷的评分结果为样本展开信度研究。
二、研究现状
概化理论(GT)整合了经典测量理论与方差分析技术,将随机误差分解为不同的来源成分纳入到影响测试结果的模型中。GT 通常包含两个研究阶段:G 研究(概化研究)和D 研究(决策研究)。前者主要估计不同的测量侧面及其交互作用对考试分数的影响,后者则是对G 研究阶段所得分数的转换与解释。当涉及作文评分时,GT 可以从总体、宏观的角度审视数据,提供测量目标与不同侧面各自的主效应以及交互效应[2]。此外,相较于CTT,GT 的优势在于能够识别得分方差和误差的来源,同时估计这些方差成分对评分一致性和准确性的影响[3]。
Rasch 模型是项目反应理论(IRT)的模型之一,其中考生能力和试题参数完全独立。其不足之处在于只考虑了项目难度参数,对多种误差来源的解释效果欠佳。基于此,多面Rasch 模型(MFRM)将多个层面纳入评估框架中。根据不同的考试以及研究需要,可以对MFRM 进行拓展。拓展之后的MFRM 可将考生能力、题目难度、评分员严厉度、评分量表中相邻等级的阶梯难度等多个层面纳入同一个数学模型,共同决定考生取得某一分值的概率大小[4]。假设考试中的写作部分由某个特定的项目(如一篇作文)组成,同时考虑不同的评分员具有不同的评分严厉度,则MFRM方程表示为:

在上述方程式中,Pnijk表示考生n 在项目i 上被评分者j评为k的概率,Pnij(k-1)表示考生n在项目i上被评分者j评为k-1的概率。Bn代表考生n的能力参数,Di代表项目i 的难度参数,Cj是评分者的严厉程度,Fk是评分等级k相对于k-1的难度。MFRM 可以使各层面相互分离,即考生的能力值不受其他层面的影响。同时,它不仅能够判断层面内部的因素(如考生能力)是否具有显著差异,还能够检验各层面是否具有交互作用,如评分员是否对某一群体的考生特别严格或宽松。此外,通过拟合度统计参数,可以发现异常的原始分数,也可以发现其他各个面上的异质点[5]。总之,MFRM 在研究写作评分方面具有极大的优势。
目前,考试写作评分的信度及误差评估方法主要有三种。第一,基于概化理论的评分研究。Gebril 将新型综合写作和传统独立式写作进行了对比,对测量结构组合的搭建提出建议[6]。朱宇等人估计了试题、评分员、评卷速度效应及其交互效应的方差分量,考察了HSK5 级书写成绩的可靠性[7]。第二,利用多面Rasch 模型进行评分研究。李清华等对TEM-4 写作新分项式评分标准质量进行了检验[8];张文星等则从严厉度、集中趋势、随机效应等角度探究了TEM-4 作文评分员的评分效应[9]。第三,考虑到概化理论和多面Rasch 模型各自的特点以及它们的互补性,越来越多的写作评分研究将这两种方法结合起来。李航对CET-6 实考作文的结果进行了分析,GT 发现评分员层面以及包含评分员与考生之间交互作用的残差占有一定的比重,MFRM 则发现评分员在严厉度上存在较大差异[10]。关丹丹研究了硕士入学考试能力测试的写作评分,GT 表明评分者和题目对评分准确性影响不大,MFRM 显示评分者之间在宽严度上不存在显著差异,但在特定考生特定题目上表现出特殊偏向[11]。徐鹰对CET-4 模拟作文的分数进行了分析,GT 表明考生能力是测试总变异的主要来源,MFRM 表明评分人严厉度差异性显著,但自我一致性较好[12]。林椿等探究了汉语母语与英语母语评分员在写作评分信度和评分行为上的差异,GT 和MFRM 分别证明了在趋中度方面,两类评分员的评分质量无差别,而在信度系数、评分员一致性、对评分量表的把握等方面,前者的评分质量更高一些[13]。
总的来说,上述研究已经对影响写作评分信度的各个方面及其交互作用进行了一定的探索,同时意识到概化理论和多面Rasch 模型可以分别从测量组别和个体层面对信度检验的过程进行说明和互补,后者还能够对概化理论的研究结果进行验证,这在一定程度上提高了研究结果的科学性。然而,国内的相关研究多集中于英语测试,对汉语测试的关注度不足。汉语预科考试对留学生而言是一项高利害测试,考试成绩对他们是否有资格进入中国大学进行本科学习具有较大影响,而作文分数①预科试卷构成:听力理解45题、综合阅读65题、书面表达11题(写汉字10题、看图作文1题),共计121题。听力和阅读为客观题,每题计1 分;写汉字每题满分1.5 分;看图作文满分为15 分。试卷总分为140 分。作文分数约占总分的11%,占书面表达的50%。也直接影响着总体得分,因此作文评分的质量显得十分重要。目前尚未有人综合运用上述两种方法来探讨预科考试作文评分情况,对其评分信度的研究显得尤为必要。
三、研究设计
本研究对汉语预科考试作文的评分信度进行实证研究。该部分共计1 题,题型为运用关键词,根据图片写作文。考生需在15 分钟内完成一篇不少于60 字的作文,满分为15 分。根据字数、理解度和准确度,每3 分形成一个档次,共有5 个档次。具体的评分标准见表1。
在正式评分阶段,每篇作文由两位评分员进行独立评分,当他们的分差不大于3 分时,取其平均分;当其分差大于3 分时,则请第三位专家评分员独立给出最终分数。
(一)研究问题
本研究基于概化理论和多面Rasch模型展开,研究问题分为两部分。在概化理论阶段,主要分析以下两个问题:
(1)考生面、评分员面以及两者交互作用的残差对测量总变异有什么影响?
(2)增加评分人数将会在多大程度上改变评分信度?
多面Rasch模型将回答另外两个问题:
(1)评分员严厉度、内在一致性以及和考生的偏差情况如何?
(2)评分量表的表现如何?
(二)研究样本
本研究的作文均来自2019 年6 月在17 个考点施测的汉语预科考试试卷。为确保研究效果,从实测卷中分层随机抽取了120 份试卷用作实验样本。为了让作文分数覆盖所有的评分档位,根据实测各分数段的比例,9分以下抽取了36份,9-12分抽取了48 份,13-15 分抽取了36 份。对上述样本的描述性统计分析显示,1-15 分均有涉及,平均分为9.93,标准差为3.776。
(三)评分员
本研究聘请了5 位评分员参与实验,他们均具有至少一次的预科作文正式评分的经验,其中一位为预科作文评分组长。评分之前,所有评分员都接受了与正式评分阶段无异的培训,进一步熟悉并理解评分标准。培训之后进行了试评,效果良好。所有评分员均在3小时内完成了评分工作。
(四)测量设计
汉语预科考试的作文试题只有1 题,鉴于此,本研究采用概化理论最基础的p*r随机单面交叉模式。p 为考生的写作能力,r 为评分员,共有5 个水平。在G 研究阶段,主要探索考生、评分员侧面、以及这两者之间交互作用和随机误差的残差的方差分量对测量总变异的影响。在D 研究阶段,主要讨论评分员数量与G 系数之间的关系。多面Rasch 模型研究则包含考生和评分员两个层面,同时还将对考生和评分员层面的偏差及评分量表的表现进行分析。
(五)统计软件
本研究采用EduG(瑞士教育研究学会教育测量研究小组设计,可通过https://www.irdp.ch/institut/english-program - 1968. html 免费下载使用)和MINIFAC 软件进行数据处理。Facets 软件是进行多面Rasch 模型分析的主流软件,由John Michael Linacre 于20 世纪90 年代研发。MINIFAC 是Facets的缩减版本,它拥有Facets 的全部功能,但处理的数据量上限为2000,可通过官方网站免费下载使用(https://www.winsteps.com/minifac.htm)。
四、研究结果
(一)概化理论的分析结果
概化理论的G 研究估算了考生、评分员和他们的交互作用的残差方差分量以及占总方差的百分比,详见表2。

表2 方差分析
考生面的方差分量所占的比例最大,为83.1%,这属于全域分数的方差分量,说明得分变异的最大部分来自考生本身的汉语写作能力,目标测量的准确性较高。评分员面的方差分量仅占5.2%,代表评分员因素给分数变异带来的误差不大,但也有可能在评分的宽严方面存在一定的差别。考生与评分员交互效应的方差成分虽远远不及考生层面,但仍占11.8%,意味着评分者可能在自身一致性方面存在一定的问题,如评分时对某些考生趋于严格,对某些考生又趋于宽松。
概化理论的D 研究阶段,通过对评分人数量的操控来观察相对概化系数和绝对概化系数的变化,详见表3。

表3 评分员数量与概化系数之间的变化
相对概化系数涉及相对误差(测量对象与其他侧面之间交互产生的误差),用于常模参照的测验,绝对概化系数则涉及绝对误差(除了测量对象之外的所有误差),用于标准性参照测验。两者的取值范围都在0~1 之间,由于涉及误差的不同,绝对概化系数一般小于相对概化系数。汉语预科考试属于标准性参照测验,因此本研究参考绝对概化系数。从研究结果来看,只有1 名评分员的情况下,绝对概化系数就已经达到了0.8306,如果两位评分员进行评分,则能够达到0.90746。将评分员个数分别增加到3、4、5 个的时候,系数均不断增大,但不及由1 名评分员增至2 名时明显。上述结果表明,在一评条件下,评分信度已经达到比较理想的状态,双评的结果更好。在正式的预科作文阅卷过程中,采用的就是双评的规则,在实际可行的条件下保证了最大化的评分信度。
(二)多面Rasch模型的分析结果
1. 总体分析
有关考生、评分员和评分维度这三者的综合信息详见图1。图中共有4 列,左起分别为:逻辑量尺(logit,模型所使用的测试单位,平均值设为0,下文的能力数值单位均为logit)、考生的写作能力、评分员信息、评分维度的表现。考生写作能力值的范围为-5.06 至6.42,基本呈正态分布。对考生而言,度量值越大,能力越强。与考生相反的是,评分员方面的数值是负向的,即度量值越大,评分员越严厉。5位评分员的取值范围为-0.73至1.08,除4号评分员,其他评分员都集中在量尺0 的附近,说明评分员们掌握评分标准的尺度基本较一致。最右列中的横线代表相邻两个分值的临界能力值,能力值大于该临界值的容易被评为更高的分数,反之则可能被得到更低的分数。
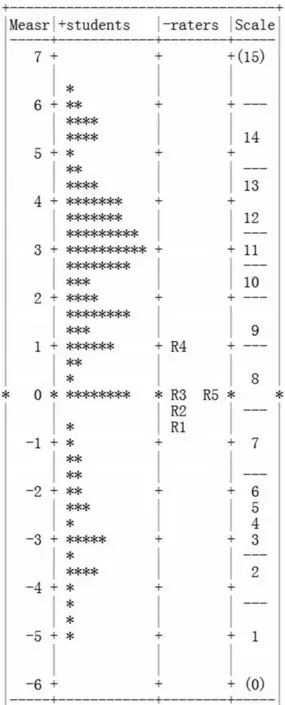
图1 评分总体信息
2. 考生层面
在多面Rasch模型中,测试的信度可参考个人分隔信度(person separation reliability)和个人分隔指数(person separation index),两者的数值越大,信度则越高。一般来说,分隔指数大于2 时被认为具有显著差异[14]。本研究考生层面的分隔指数为6.58,分隔信度为0.98,卡方检验值为6053.2(df=119,p=0.00),表明考生之间的成绩存在统计上的显著差异性,此次作文考试的区分度很好。考生能力分布的卡方值为116.5(df=118,p=0.52),说明考生的能力呈正态分布。
在所有考生中,能力最强的是85 号(6.42),能力最弱的是82 号(-5.07),两者相差了11.84。平均能力值为1.64,标准差为2.8,标准误平均值为0.41,标准差为0.08。考生的加权均方拟合度(Infit MnSq)平均值为0.97,标准差为0.8。Infit 值通常可以作为判断个体是否拟合模型的依据,一般来说,对其取值范围没有严格的规定。这里采用Myford & Wolfe 提出的判断标准,当Infit 值>3.0 时,为非拟合,即评分之间的差异显著大于模型预测值,Infit 值<0.5 时,为过度拟合(overfitting),即评分之间的差异显著小于模型预测值[15]。据此,共有13 号(4.51)、120 号(3.91)、37 号(3.25)这3 位考生存在非拟合问题。值得注意的是,这3 名考生都属于评分员与考生交互存在显著偏差的例子,说明这些考生的分数受到了评分员评分偏差的影响。过度拟合的考生人数则高达37名。此外,|Z|>2也被认为是超出可接受的范围[16]。3名非拟合考生的Z 值均大于2,为显著非拟合;在过度拟合的37 名考生中,有4 名的Z 值小于-2,为显著过度拟合。上述结果表明,考生分数只存在轻微的非拟合问题,而过度拟合的现象相较稍多,这意味着评分员可能一定程度上有评分趋中的倾向。
3. 评分员层面
评分员层面的数据详见表4。从整体上看,5 位评分员的分隔指数为8.26。分隔信度为0.99,卡方检验值为262.9(df=4,p=0.00),平均严厉度为0.00,标准差为0.67,这说明评分员在严厉度方面有显著差异。在所有的评分员中,最严厉的是4 号(1.09),最宽松的为1号(-0.74),二者的严厉度相差了1.83。
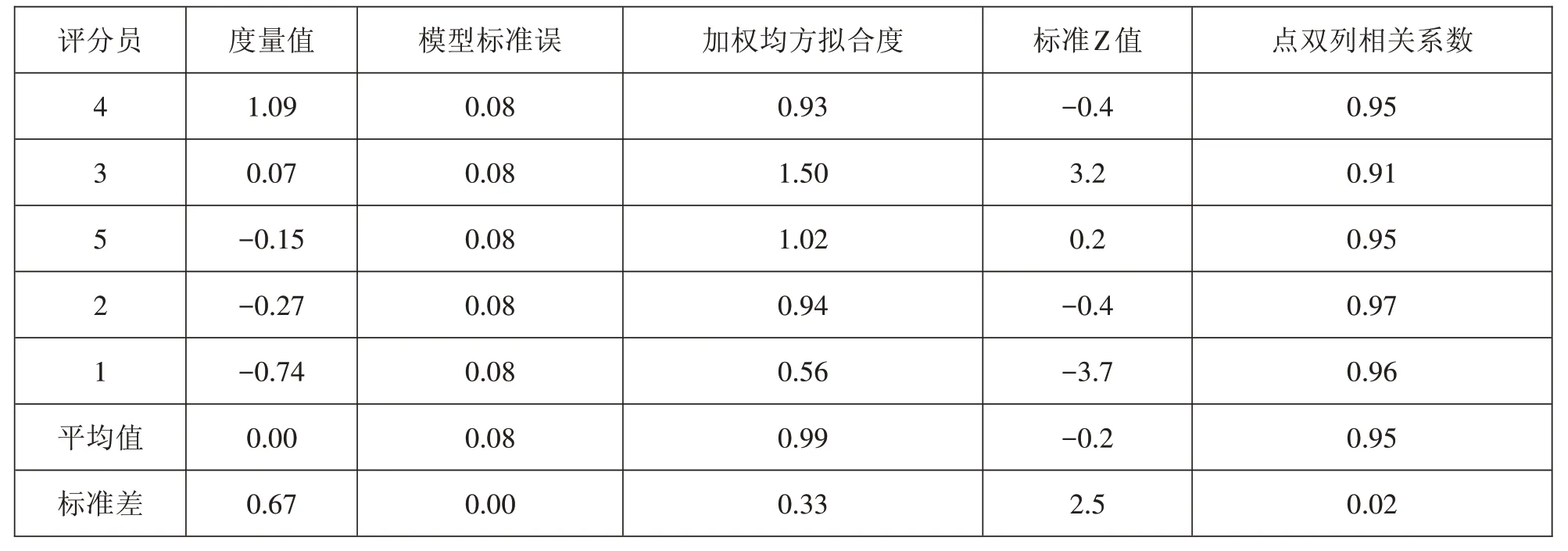
表4 评分员层面的结果
通过观察加权均方拟合度,可以得出评分员自身一致性的信息。Bonk & Ockey 提出,Infit 的取值范围在0.7~1.3 之间可以认为评分员具有较好的自身一致性[17];Lincare 和Weigle 则认为该范围也可以适当扩大至0.6~1.4 或者0.5~1.5[18-19]。考虑到汉语预科考试是一项重要的标准化考试,故采取0.7~1.3这一更严格的标准。据此,3 号评分员(Infit=1.5,Z=3.2)和1 号评分员(Infit=0.56,Z=-3.7)未达标,前者自身一致性较差,后者评分差异性过小,评分具有一定的趋于中性。此外,还需要关注评分员的点二列相关系数,若在平均值±2SD 内则视为可接受[20]。本研究的可接受范围是(0.91,0.99),3号评分员刚好处于最低值的临界点(0.91),这意味着与其他评分员相比,该评分员评分时具有轻微的随机性,使用某些分数段时有不一致的情况。
上述对评分员的分析显示,评分员在严厉度方面有显著差异,有个别评分员在自身一致性方面存在问题,有一定的随机性,还有个别评分员存在评分趋中的问题。需要关注的是,上文在概化理论的G研究阶段发现评分员的方差分量占有少量比例(5.2%),但Rasch 模型的研究结果表明,不存在非拟合和过度拟合状态的评分员(Infit 均在0.5 至3.0 之间),换言之,评分员层面的严厉度差异不会对测试分数产生整体影响[21]。
4. 评分量表的使用情况
多面Rasch模型能对评分量表进行有效的分析,如检验各评分员是否使用了评分标准的所有分值,各分值是否能体现相应的能力以及是否具有足够的区分度[17]。汉语预科作文评分量表0-15分的使用情况详见表5。

表5 评分量表的使用结果
第一,计数和百分比显示了各分数的使用频率,每个分值均有涉及,7-14各分数的使用频率相当,在10%左右,总体不存在对某一分数过度使用的情况。第二,实际得分平均度量值(Avge Meas)从低到高依次递增(-4.55至5.44),与Linacre 提出的评分标准质量的基本要求相符[22],这也表明了评分员整体上能够较准确地使用各分数来区分不同能力的考生。第三,未加权均方拟合度(Outfit MnSq)也是分值使用情况的检验指标。若该值>2.0,则表明得到该分值的考生其预测分数和实际分数之间有较大差距,即该分数不能准确地反映考生的水平[23]。表5 中所有分数的未加权均方拟合度都小于2,基本处于1 附近,从这个角度来看,各分值可以区分不同能力的考生。第四,分阶校准值显示了各分数的起始值。除3、4、5、6、11、12分之外,其余分数都呈现由低到高递增的趋势。3、4、5分使用的频率较少,模型估计的误差相应地也会增加,起始值的无序性可能就是由此导致的。同时,相邻分数的间隔数值也应作为参考,如表6所示。

表6 相邻分数的间隔数值
Linacre认为各分数的间隔应该在1.4~5之间[23],除了2-1、5-4、7-6、8-7、11-10分之间的起始值间隔达到了该标准,其他分数未满足,即这些分数之间的区别并不十分明显。汉语预科作文考试的评分标准共有5档,每档包含3个分值(详见表1)。评分时先定档,然后在相应的档位里选择合适的分数。此时取每个档位的中位数,对各档位之间起始值的间隔进行计算,结果见表6。2档与1档、4档与3档的间隔值落在了1.4~5 内,说明这些档位的差别很明确。3 档与2档、5档与4档的结果则相反,它们之间的差别不太明显。综合上述分析,评分档次之间以及总体相邻分数差别的准确性有待提高,这也在一定程度上解释了个别评分员具有评分随意性的问题。
此外,还应关注各分值概率曲线,如图2所示。

图2 评分量表各分数段概率曲线图
图中的每个波形对应一个分值,各波形的交点即相邻分值的临界点。若概率曲线有独立的且有一定间隔的波峰,说明每个分数值各自对应一个明显的能力区域,在此区域内的考生最容易获得该分值[24]。图2 显示,除了两端有较明显的独立波峰,其余能力段考生的概率曲线处于重叠状态,尤其是中间偏左侧(3 分到5 分)和中间偏右侧(11 分到12分),这说明该评分标准需要改进,如合并某些分值。
5. 偏差分析
偏差分析可以用来判断各个面之间的交互作用。通过比较观测值和模型期望值之间的差异来对评分员与考生之间的偏差进行分析。评分员与考生之间的实验偏差项目(empirically bias terms)共有600 个。若Z 值>2,则该评分员对该考生更为严厉;若Z 值<-2,则该评分员对该考生更为宽松。本研究共存在16 个显著偏差,10 个偏严格,6 个偏宽松,共占所有偏差项目(600)的2.67%,符合偏差比率在5%之内的要求[20]。表7 显示了评分员与考生之间的显著偏差信息。

表7 评分员与考生之间的偏差分析
5 位评分员均表现出了一定的偏差性,其中3 号评分员的偏差情况最为严重,与5 个不同能力值范围(每1logit 间隔算一个能力范围)的考生发生了7次偏差。能力值在0之上的5个考生,评分全部偏严格,能力值在0 之下的2 个考生,评分全部偏宽松。实际得分为8 的5 号、46 号这两位考生之间的能力值、期望得分都相差甚远,7 号、13 号考生也是相同的情况,这也印证了4.2.1小节中的结果,即3号评分员自身一致性偏差,评分存在随机性,使用分数时存在前后标准不一的问题。
总体来看,评分偏严格的情况多于偏宽松的情况。在8 个不同的考生能力区间中,分数显著偏严覆盖了6 个区间,其中有5 个区间相互联结,即1 至6。分数显著宽松覆盖了4 个区间(-3 至-2、-1 至0、1 至2、3 至4),彼此之间没有联结。由此,共有11 个显著偏差(68.75%)发生在1至6之间,可能是因为所有考生中共有67.5%的人属于这个能力区间,二者比例接近。这一结果也表明了显著偏差出现在能力较高考生中的比例高于能力一般和较差的考生,评分员在对前者进行评分时,出现偏差的概率更大。同时,评分员总体呈现出对较高能力考生评分严格而对较低能力考生评分宽松的趋势。上述研究结果表明,一方面要提醒所有的评分员注意对高、低能力考生进行评分时的严厉度差异,另一方面要加强对类似3 号的评分员群体的培训,关注评分结果并纠正其随意性。
五、结论
基于概化理论和多面Rasch 模型研究了5 名评分员对120 份汉语预科实测作文考卷的评分结果,对其信度进行了检验。综合上述分析,可以得到以下结论。
第一,概化理论的G 研究阶段提供了考生、评分员以及二者交互作用所占的方差分量。考生能力差异是总变异的主要来源(83.1%),评分员层面占比5.2%,总体表现较为稳定。评分员与考生之间的交互作用占比11.8%,评分员在评分严厉度上存在差异,对某些考生的评分存在前后不一致的情况。
第二,在概化理论的D 研究阶段发现,一位评分员评分时就能达到可接受的概化系数(0.83),具有较高的信度,而采用双评则可以将系数提高到0.91,随着评分员的继续增多,系数也在逐步提高,但幅度不大,所以在正式评分时应保持目前的两位评分员评分的状态。
第三,多面Rasch模型对考生、评分员、考生及评分员的交互作用、评分量表这四个方面进行了详细的解释,主要有以下发现:(1)汉语预科作文考试能有效地区分不同能力的考生;(2)评分员在严厉度方面存在显著差异,总体一致性较好,有两位评分员未达标,3 号评分员评分时具有一定的随机性,1 号评分员存在评分趋中的问题;(3)考生与评分员的交互作用表明,评分偏严格的情况比偏宽松的情况要多,较高能力考生出现显著评分偏差的概率更大,评分员总体对该群体更严格,对能力一般及较差的考生更宽松,对3 号评分员的探讨也进一步证明了其存在的评分问题,需要重点关注;(4)评分量表大致可以区分不同能力的考生,评分员整体上也能够较准确地使用各分数来达到此目的,然而有两组评分档位之间以及各相邻分数的差别不太明显,其准确性有待提高。
总的来说,概化理论和多面Rasch模型从不同的角度对评分信度进行了考察,具有较好的互补性。需要明确的是,作文评分属于一项复杂的心理活动,评分员表现出来的严厉度倾向、一致性差异都是正常的现象,偏差显著的交互作用同样无法避免。基于此基本认知和研究结果,可以通过加强对评分员的培训、检测并纠正评分员的评分活动、改进评分量表等行为来减小偏差,同时采用质性手段来印证并补充数据分析的结果,从而最大化地保证评分信度。
