基于动态对抗泛化网络的跨领域脑电情绪识别
2022-07-14梁圣金
梁圣金
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
0 引言
在日常交流中,人们通过观察面部表情和聆听声音等方式判断对方的情绪状态,并据此作出相应的反馈,以完成连贯的交流互动。为了使得人机交互过程更加友好,研究者尝试赋予机器能够检测和处理人类情绪的能力,并借助脑机接口技术从大脑信号中识别人类情绪[1-2]。相比于测量大脑活动的其他方法,具有简单易用、价格便宜等优点的脑电(electroencephalography,EEG)得到了广泛的使用。脑电是利用电极在头皮表层记录的电位,与人类的许多心理活动和认知行为密切相关,为识别不同情绪提供了可靠的信号来源[3]。
然而,应用广泛的脑电信号却具有非平稳性[4]。这使得脑电数据的概率分布容易发生变化,导致情绪识别模型在应用于新个体(跨被试场景)或者同一个体的新时段(跨会话场景)时,模型性能会出现较大的下降。为了改善跨领域脑电情绪识别的效果,研究者引入了迁移学习技术,包括领域自适应[5]和领域泛化[6]。领域自适应方法旨在减小源域和目标域之间的分布差异来提高源域模型应用于目标域的性能,这在过去得到了广泛的研究。例如,LI 等人[7]利用领域对抗神经网络(Domain-Adversarial Neural Network,DANN)[8]来减小源域被试和目标域被试之间的个体差异。此外,无需使用目标域数据训练模型的领域泛化方法也得到了初步的关注。MA等人[9]提出了一个领域残差网络(Domain Residual Network,DResNet),学习特征提取器的领域特有参数和领域共享参数,以促进对领域共享特征的提取。领域泛化方法虽然更有利于模型的实际应用,但是它比领域自适应方法更难,所以其研究工作相对较少。
本文提出了一个新颖的领域泛化方法,即动态对抗泛化网络(Dynamic Adversarial Generalization Network,DAGN)。DAGN 利用全局领域对抗和局部领域对抗的动态融合来从多个源域中学习提取领域不变特征的模型,以改善对目标域数据的预测效果。跨被试与跨会话两种场景下的跨领域迁移实验验证了DAGN 的有效性。
1 方 法
1.1 领域泛化问题
领域泛化旨在利用现有的一个或者多个不同但相关的源域的数据,训练可以应用于未知领域的较为通用的模型[6]。在领域泛化问题中,目标域在训练模型时不可访问,从而减少了对目标域数据的依赖。因此,领域泛化方法只能通过已有的源域数据来学习应用于未知领域的模型。
本文考虑跨被试和跨会话这两个跨领域场景。跨被试场景假设存在多个可用的源域被试,而跨会话场景假设存在多个可用的源域会话,不同被试或者会话被视为不同的领域。具体而言,假设给定K个分布不同但相关的源域,其中第k个源域为为样本数据,∈{1,…,C}和为对应的情绪标签和领域标签,nk为样本数量,并且n1+…+nK=N。本文的目的是,仅利用这K个源域的数据来学习对未知目标域具有较好泛化能力的脑电情绪识别模型。
1.2 动态对抗泛化网络
1.2.1 网络架构
本文提出的动态对抗泛化网络(Dynamic Adversarial Generalization Network,DAGN)主要由特征提取器、标签预测器以及领域分类器3 部分组成,如图1 所示。

图1 所提出的动态对抗泛化网络(DAGN)架构(i ≠j 且i,j ∈{1,…,K})
1.2.2 特征提取
在DAGN 中,输入数据将会通过几个神经网络层,以提取有利于进行情绪分类的特征。MA 等人[9]的研究表明,显式地学习各个源域特有的参数和所有领域共享的参数,有助于提高模型的泛化能力。据此思想,DAGN 将每个源域的特征提取器划分为特有部分(网络参数为,k∈{1,…,K})和公共部分Gf(网络参数为θf),其中特有部分独立于其他领域(如图1 中源域i特征提取器和源域j特征提取器),而公共部分由所有领域共享(如图1 中公共特征提取器)。因此,对于来自源域k的训练样本,由其特有的和公共的特征提取器所得到的特征可以表示为:

1.2.3 情绪分类
情绪分类是实现情绪识别的主要任务。情绪分类由标签预测器Gy实现,其对应的网络参数为θy,如图1 中标签预测器所示。标签预测器Gy是一个多类别分类器,它接收特征提取器所提取的特征作为输入,并由此判断输入数据的情绪类别。
在训练网络模型时,根据标签预测器对输入数据的预测和对应的真实标签,可以利用交叉熵损失函数L(·,·)计算标签预测损失:在训练阶段不断优化标签预测损失Ly,可以提高模型对源域数据的预测精度。
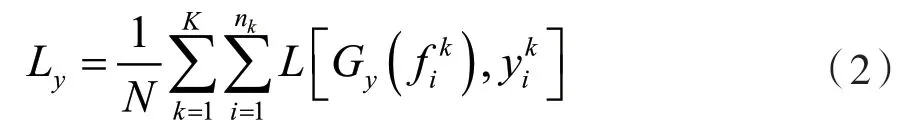
1.2.4 领域对抗
为了减小所提取特征受到领域之间的差异的影响,DAGN 采用领域对抗的方式来提高特征的领域不变性。领域对抗通常需要两个组件来实现,第一个组件尽可能产生无法区分原始领域的数据,第二个组件尽可能判断输入数据的原始领域,两个组件在相互竞争中形成对抗训练模式。基于GANIN等人[8]的工作,DAGN 将特征提取器作为领域对抗的第一个组件,而领域分类器作为第二个组件,二者由梯度反转层[8]连接起来。
在DAGN 的领域对抗中,梯度反转层起着重要的作用。它在前向传播时对数据作恒等变换,而在反向传播时将梯度取相反数。如果梯度反转层用伪函数R(x)表示,那么它在前向传播时的表现为R(x)=x,在反向传播时的表现为dR/dx=-I,其中I为单位矩阵。
DAGN 利用全局领域分类器来与特征提取器形成对抗训练模式,它在本质上是一个K类分类器。全局领域分类器用Gd表示,对应的网络参数为θd,其对应的损失可以表示为:
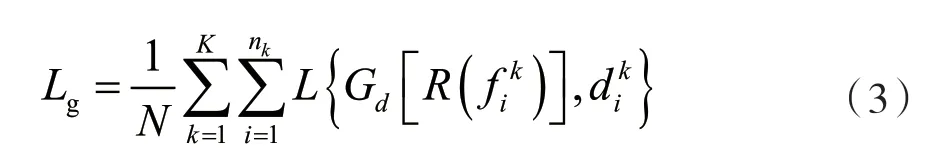
YU 等人[10]的研究表明,一个全局领域分类器可以对齐不同领域之间的全局(边缘)分布;而当领域之间的全局分布比较接近时,局部(条件)分布需要给予更多关注,以对齐不同分布之间的多模式结构,实现更细粒度的领域匹配。据此思想,DAGN为C个情绪类别分别构建了对应的局部领域分类器(网络参数为,c∈{1,…,C})。对于来自源域k的训练样本,标签预测器Gy的输出反映了被预测为C个情绪类别的概率(如反映了将样本预测为情绪类别c的概率),那么此概率可以用来衡量同一特征以多少的比例输入到各个局部领域分类器。所有局部领域分类器的损失为:

DAGN 使用一个动态系数w来权衡全局和局部的领域分类器的损失。在训练模型的过程中,动态系数w将在每一次迭代后进行更新,并由式(5)计算:

利用动态系数w对所有的领域分类器进行加权,得到领域对抗损失为:

1.2.5 模型训练与测试
根据前面对DAGN 各个组成部分的介绍,可以得到用于训练模型的总的损失函数为:

在Ltotal中,λ为权衡参数,用于调节标签预测损失和领域对抗损失的比例。在模型训练过程中,最小化总的损失函数,标签预测器的分类精度将会得到提高,从而促进特征提取器提取具有情绪判别性的特征。此外,由于梯度反转层前后的梯度的符号相反,所以特征提取器和领域分类器在对抗训练中不断提高自身能力,从而促进特征提取器提取对领域差异不敏感的特征。模型经过优化后,将会学习到网络各个组成部分的参数,即
在测试阶段,目标域的样本数据通过特征提取器Gf和标签预测器Gy进行预测。对于目标域样本(i∈{1,…,nT}),其对应的情绪标签可由式(8)进行预测:

2 实验设置
2.1 实验数据
本文采用基于脑电的情绪识别研究常用的基准数据集SEED[2]作为实验数据,以评估所提出方法的性能。该数据集包含15 名被试在不同的日期所参与的3 次脑电采集实验的数据,每次实验称为一个会话。在每个会话中,被试需要观看15 个时长约为4 min 的情感电影片段,以激发被试产生积极、中性及消极3 种情绪,并通过所佩戴的62 通道脑电帽同步采集对应的脑电数据。所采集的原始脑电数据在经过下采样和带通滤波等处理后,将每个通道的数据划分为5 个不重合的频段,并从中以1 s的时间长度计算微分熵作为数据样本,每个样本为310 维的向量。最终,SEED 数据集的每个被试在每个会话中得到3 394 个脑电数据样本。
2.2 跨领域实施方式
本文分别执行跨被试和跨会话两种迁移实验来实施跨领域的脑电情绪识别。
对于跨被试迁移实验,每个被试只选择一个会话的脑电数据参与实验。由于共有15 名被试,所以每个方法进行了15 次跨被试迁移实验,使得每名被试依次作为目标域,而对应的剩余14 名被试则作为源域。最后对15 次实验的分类准确率求平均值和标准差。
对于跨会话迁移实验,分别在每个被试内部进行实验。具体而言,每名被试均有3 个会话的脑电数据,将会话3 作为目标域,而剩余的会话1 和会话2 作为源域。最后对所有被试的跨会话迁移实验的分类准确率求平均值和标准差。
2.3 各个方法的实现细节
与本文所提出方法进行比较的方法有领域对抗神经网络(Domain-Adversarial Neural Network,DANN)[8]、领域残差网络(Domain Residual Network,DResNet)[9]、多对抗领域泛化(Multi-Adversarial Domain Generalization,MADG)以 及DAGN_W。DANN 属于领域自适应方法,它将所有源域合并为一个源域,需要目标域数据参与模型的训练;其余方法均为领域泛化方法。DResNet 只有一个全局领域分类器,相当于将本文提出的DAGN 的动态系数w固定为1。MADG 在DResNet 的基础上将全局领域分类器改为局部领域分类器,相当于将本文提出的DAGN 的动态系数w固定为0。DAGN_W 是本文所提出方法的变体,它直接将本文提出的DAGN的动态系数w固定为0.5。
各个方法的特有或者公共的特征提取器均有3层,每层的节点数量分别为512,256 和128。标签预测器都有3层,各层的节点数量分别为64,32和3。全局或者局部的领域分类器均有3 层,其中DANN各层的节点数量分别为256,256 和2,其余方法的各层节点数量分别为256,256 和K(源域数量)。
所有方法的权衡参数λ的设置与GANIN 等人[8]的设置一致。用p表示模型训练的进度(从0 变化到1),那么权衡参数λ设置为:
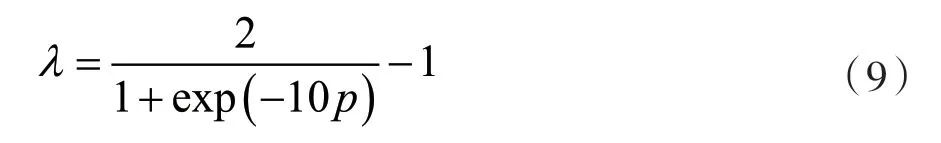
3 实验结果
3.1 跨被试迁移实验
在跨被试的脑电情绪识别实验中,每个被试分别作为目标域时的实验结果如图2 所示,各个方法的平均准确率和标准差在表1 中给出。对比不同方法的实验结果,可以得到一些重要的发现。

图2 每名被试所对应的跨被试迁移准确率
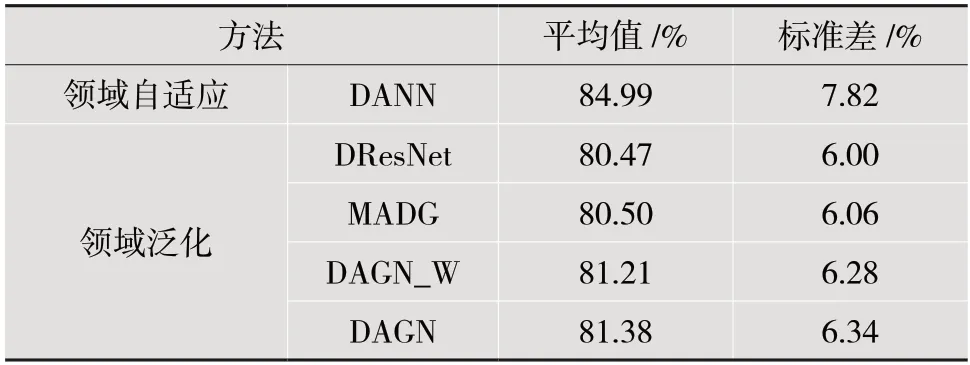
表1 跨被试迁移实验的平均准确率和标准差
(1)DANN 在所有方法中取得了最高的平均准确率。所比较的领域泛化方法都是在领域自适应方法DANN 的基础上进行改进的。DANN 在训练模型时需要使用无标签的目标域数据,所以它能够直接减小源域和待测试的目标域之间的数据分布差异,从而取得最好的实验结果。而领域泛化方法只能使用源域数据来训练模型,无法提前获知待测试的目标域的数据分布情况,所以实验结果不如DANN。但是在实际应用场景中,待测试领域的数据可能无法提前获取甚至难于收集,所以领域泛化方法仍然具有较大的实际应用价值。
(2)本文所提出的DAGN 方法在所有领域泛化方法中取得了最高的平均准确率,同时也是实验结果最接近DANN的方法。这有几个方面的原因。首先,DResNet 只使用了一个领域分类器来促进对领域不变特征的提取,而没有考虑对局部分布的对齐,可能带来负迁移。其次,MADG 只使用了多个局部领域分类器,而没有对齐全局分布。最后,DAGN 的变体DAGN_W 将动态系数w固定为0.5,而在模型训练过程中的不同阶段,全局和局部两部分的对抗损失可能会有不同的重要性。而所提出的DAGN方法同时考虑了全局和局部的动态融合对齐,从而在领域泛化方法中取得了最好的效果。
(3)从图2 中各个被试的比较中可以发现,不同被试的实验准确率变化较大,意味着待测试领域的数据分布是多样化的,甚至与训练模型的数据有着较大的领域差异。DAGN 及其变体DAGN_W 在大部分被试中都取得了比其他领域泛化方法更好的结果,表明同时考虑局部分布对齐和全局分布对齐能够更好地应对变化多样的测试数据。
3.2 跨会话迁移实验
在每个被试内部独立地进行了跨会话的脑电情绪识别实验,所得到的实验结果如图3 所示,各个方法在所有被试中的跨会话平均准确率和标准差如表2 所示。观察实验结果,可以得到以下发现。

图3 每名被试所对应的跨会话迁移准确率

表2 跨会话迁移实验的平均准确率和标准差
(1)在跨会话场景下,同时利用源域和目标域数据训练模型的领域自适应方法DANN 仍然获得了最高的平均准确率。
(2)DAGN 及其变体DAGN_W 较其他领域泛化方法表现得更好,并且DAGN_W 在领域泛化方法中取得了最好的结果。这表明,在跨会话场景下同时考虑局部对抗和全局对抗方式可以更好地提取具有领域不变性的特征。
(3)将各个方法的跨会话实验结果与前面的跨被试实验结果相比较,容易发现跨会话的实验结果都有了明显的提升。在跨领域问题中,领域之间的数据分布不一致是导致模型在跨领域应用时性能下降的重要原因。当源域和待测试的目标域的差异变小,模型性能将会得到提升。实验结果表明,跨会话场景下的源域和目标域的差异相对较小,因为同一被试在不同时段下的脑电数据的变化相对较小。
(4)由前面的分析可知,跨被试迁移场景比跨会话迁移场景更难应对。但是从两种跨领域迁移场景下的实验结果可见,所提出的DAGN 在跨被试场景下比其他领域泛化方法拥有更明显的性能提升。这说明与其他领域泛化方法相比,DAGN 在源域和目标域的差异较大时能够提取更加通用的特征,从而实现更好的跨领域情绪识别效果。
4 结语
为了减少对目标域数据的依赖和提高模型的跨领域应用能力,本文提出了一个新颖的领域泛化方法——动态对抗泛化网络。通过全局对抗和局部对抗的动态融合方式,该方法能够有效地从多个源域中学习能够提取领域不变特征的模型。所提出方法的性能在情绪脑电数据集SEED 上得到了验证,而且取得了与领域自适应方法较为接近的结果,有利于促进脑电情绪识别模型在实际场景中的应用。
