基于交叉注意力机制的视频引导机器翻译方法
2022-07-14王麒鼎
王麒鼎,姜 舟*
(1.昆明理工大学 信息工程与自动化学院,云南 昆明 650500;2.昆明理工大学 云南省人工智能重点实验室,云南 昆明 650500)
0 引言
随着短视频产业的发展,来自不同国家的视频开始在网上传播。在文化、教育、金融、公益、国际环境等各个领域,视频引导机器翻译都有着很大的实用价值和市场前景。其不仅可以节省时间、提升体验,还可以帮助人们快速地找到自己感兴趣的内容,为人们提供极大的便利,对于处理好国际关系,对经济发展、政治稳定、文化交流及商务合作等方面有着重要的意义。在实际生活中,视频引导机器翻译可以帮助翻译带有社交媒体视频内容的帖子和新闻,支撑更多的自媒体App,为视障人士提供便利。
视频引导机器翻译是在给定一组视频和相关文档的情况下,根据视频和语义的对应增强文档的翻译,通过视频线索解决机器翻译的问题。与图像引导机器翻译任务相比,视频引导机器翻译更具挑战性,因为视频是由连续的帧组成的,其中视频模态包含的信息更丰富。视频信息的质量直接影响机器翻译的质量,而且在利用视频信息的过程中,人们需要选取有价值的信息来辅助机器翻译。但是在目前的视频引导机器翻译领域,机器翻译的结果还没有达到人们的要求。因此,本文对视频信息的筛选以及视频信息的特征提取开展相关研究,从不同的角度为视频引导机器翻译任务提供可行的研究方案和技术路线。
视频与句子匹配,是视频引导机器翻译的基本任务之一[1-3]。通过视频帧与句子的相关性分数选择出更贴切的视频帧是重要的步骤。这项任务在视频字幕[4-5]、视频生成[6-7]以及视觉问答[4,8-9]领域受到关注并被广泛应用[10-14]。虽然近年来取得了重大进展,但是在视频引导机器翻译领域仍然是一个具有挑战性的问题,因为它需要理解语言语义、视觉内容、交叉模态关系以及对齐的方法。
由于视觉与语言之间存在巨大的视觉语义差异[2,15],图像与句子的匹配问题仍有待解决。针对该问题,研究者们提出了各种方法,大体可分为一对一匹配[13,16-17]和多对多匹配[18-19]两类。一对一匹配方法通常提取图像和句子的全局表示,然后利用视觉语义嵌入[15]将它们关联起来。以往的方法都是将图像和句子独立地嵌入到同一个嵌入空间中,然后通过特征在空间中的距离来度量它们的相似度。在深度学习的成功推动下,主流的方法已转向针对特定形态的深度特征学习,如学习视觉特征的卷积神经网络(Convolutional Neural Networks,CNN)和学习句子特征的循环神经网络(Rerrent Neural Network,RNN)。通过对理解视觉内容任务的研究,目前已经开发了几种深层骨干模型,包括ResNet、VGG 及GoogleNet[20],并证明了其在大型视觉数据集上的有效性[21-22]。使用多对多匹配方法时,考虑到视频帧与句子单词之间的关系[25-27],现有的方法大多比较多对视频帧和句子单词,并对它们的局部相似度进行聚合[28-30],综合视频帧和句子词之间的关系,可以为图像匹配和句子匹配提供细粒度的跨模态线索。本文提出了一种用于视频帧和句子匹配的多模态交叉注意网络,通过统一的深度模型对视频帧和句子词的模态间关系和模态内关系进行建模。为了验证交叉模态匹配的鲁棒性,本文设计了两个有效的注意模块,即交叉注意模块和时间注意力模块,它们在模态内和模态间的关系建模中发挥着重要作用。
1 相关工作
针对视频引导机器翻译中的图像匹配和句子匹配的方法,在HUANG[10]的研究之后,相关方法大致分为一对一匹配和多对多匹配两类。
1.1 一对一匹配
早期的大量研究提取图像和句子的全局表示,然后将它们与基于铰链的三联体排序损失相关联,其中匹配的图像-句子对距离较小。在近期研究中,FAGHRI 等人[2]尝试在三重损失函数中使用硬负挖掘,并得到显著的改善。在GU[25]和PENG[26]等人的研究中,生成目标与交叉视图特征嵌入学习相结合,学习可视和文本数据的更有区别的表示。同时,YAN 等人[17]利用深度典型相关分析对图像和句子的特征进行关联,真实匹配的图像-句子对具有较高的相关性。KLEIN 等人[24]也有类似的目标,利用Fisher 向量来获得判别句表示。此外,LEV 等人[19]利用RNN 对FV 进行编码,从而获得更好的性能。在计算机视觉中,视觉注意的目标是聚焦于特定的图像或子区域[4,17-18]。同样,自然语言处理的注意方法自适应地选择和聚合信息片段来推断结果[12,21,29]。近年来,人们提出了基于注意力的图像-文本匹配模型。HUANG 等人[10]开发了一种语境调制的注意方案,选择性地注意出现在图像和句子中的一对实例。同样,NAM 等人[1]提出了双注意网络(Dual Attentional Network),通过多个步骤捕捉视觉与语言之间的细粒度相互作用。然而,尽管语义匹配的数量会因图像和句子描述的不同而变化,这些模型还是采用了带有预定义步骤数的多步推理来一次观察一个语义匹配,然而,他们忽略了一个事实,即全局相似性是由潜在的视觉-语言对应在视频帧和句子单词层面的复杂聚合而产生的。
1.2 多对多匹配
在视觉和语言领域,越来越多的人开始考虑视频帧与句子单词之间的细粒度对齐。在ANDREJ和LI 等人[27]的研究中,第一个工作是对视频帧和句子词之间进行有结构目标的局部相似度学习。HUANG 等人[10]的实验提出了一种用于实例感知图像与句子匹配的选择性多模态长短时记忆网络。同样,NAM 等人[1]的研究提出了一个双重注意网络,通过多个步骤捕捉视觉与语言之间的细粒度相互作用。自底向上注意是ANDERSON 等人[4]在图像字幕和视觉问答研究中提出的一个术语,指的是与人类视觉系统自发地自底向上注意相似的纯视觉前馈注意机制[14,21-23]。ANDREJ 和LI 等人[27]提出利用R-CNN 在物体水平上对图像区域进行检测和编码,然后将所有可能的区域-词对的相似度分数相加推断出图像-文本的相似度。NIU 等人[31]提出了一种模型,将句子中的名词短语和图像中的物体映射到一个共享的嵌入空间中,该空间位于完整的句子和完整的图像嵌入之上。HUANG 等人[10]将用于模型学习的图像-文本匹配和句子生成与改进的图像表示相结合。与本文的模型相比,这些研究没有使用传统的注意机制来学习在给定的语义背景下聚焦图像区域。然而,通过采用多步骤的方法来实现整个图像与句子之间的特征对齐,其可解释性较差。所以研究者利用堆叠交叉注意机制提出了SCAN,以发现所有显著对象与单词之间的对齐。但它没有考虑到视频帧与句子词之间的关系。随后,SAEM[13]利用自我注意机制来探究每个模态内的关系,而忽略了不同模态间的关系。然而,很少有人提出方法来调查跨模式和在一个统一的图像和句子匹配框架内的模内关系。总地来说,解决视频引导机器翻译任务中视频带来的噪声干扰,可以根据文本和视频帧匹配的方式,通过交叉注意力选取视频特征。
2 基于交叉注意力机制的视频引导机器翻译方法
本节主要描述基于交叉注意力的视频引导机器翻译网络(Cross-Temporal Attention,CTA)。基于交叉注意力机制的视频引导机器翻译方法模型如图1 所示。本文的目标是将单词和视频帧映射到一个共同的嵌入空间,从而推断出整个视频与完整句子之间的相似性。从自底向上的注意开始,检测视频帧并将其编码为特征。此外,将句子中的单词与句子上下文映射到特征上。然后,通过对齐视频帧和单词特征,应用交叉注意来推断视频句子的相似性,提取重要视频帧,降低视频模态的噪声。

图1 基于交叉注意力的视频引导机器翻译模型图
2.1 交叉注意力机制
交叉注意力机制需要两个输入:其一是一组视频特征V={v1,v2,…,vk},Vi∈RD,使每个视频特征对视频帧进行编码;其二是一组单词特征E={e1,e2,…,en},ei∈RD,其中每个单词特征都对句子中的一个单词进行编码。交叉注意力机制的输出是一个相似度分数,用来衡量视频帧-句子的相似度。本文在推断相似性时,交叉注意力机制对视频帧和将视频帧和单词作为上下文采用不同的注意力机制。视频帧-文本交叉注意力机制方法如图2 所示。

图2 视频-文本交叉注意力机制方法图
视频帧-文本交叉注意力机制包括两个注意力阶段。阶段1:根据每个视频帧来处理句子中的单词。阶段2:根据每个视频帧与相应的句子向量进行比较,以确定视频帧相对于句子的重要性。通过给定视频I,包含k个视频帧,句子T包含n个单词,计算所有可能对的余弦相似度,即:

式中:i∈[1,k]表示视频帧,j∈[1,n]表示单词。
在阶段1 中,首先关注句子中关于每一帧视频特征vi的单词,为第i帧视频生成一个被关注的句子向量。在阶段2 中,比较和vi,确定每个视频帧的重要性,然后计算相似度得分。在计算过程中sij表示第i个视频帧与第j个单词之间的相似度。
对视频信息加入一个时间注意力机制,将视频中的每一帧赋予不同的权重,通过计算不同帧的影响力,选出一簇时间上关联的关键帧作为最终的视频特征,最后通过长短时记忆网络(Long Short-Term Memory,LSTM)解码出目标语言。通过视频具有的时间特征,结合视频中的动作特征、时序特征,将源语言和目标语言进行一个空间上对齐的效果,从而提升模型翻译质量。根据KARPATHY 经验[27]得知,将相似度阈值设为零对实验的效果最佳,然后将相似矩阵归一化为:
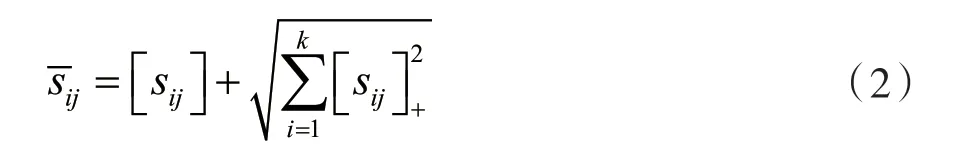
式中:[x]+=max(x,0)。为了关注相对于每个视频帧区域的单词,本文定义了一个加权的单词表示组合(即关注的句子向量):

式中:λ1是softmax 函数的逆向表达,注意力的权重是点击注意力的一种变形式。
在确定给句子上下文的每个视频帧的重要性方面,本文将第i个视频帧与句子之间的相关性定义为所关注的句子向量与每个视频特征vi之间的余弦相似度,即:

受语音识别中最小分类误差公式的启发,视频帧I与句子T的相似度通过Log Sum Exp pooling(LSE)来计算,即:


同样,本文先关注每个单词对应的视频帧,然后将每个单词与相应的被关注的视频帧向量进行比较,从而确定每个单词的重要性。总地来说,将第i个视频帧和第j个单词之间求取预先相似度sij,在第i帧和第j个单词之间:

在关注视频帧相对于每个单词的重要性上,本文定义了视频帧特征的加权组合(对第j个单词的视频帧向量):
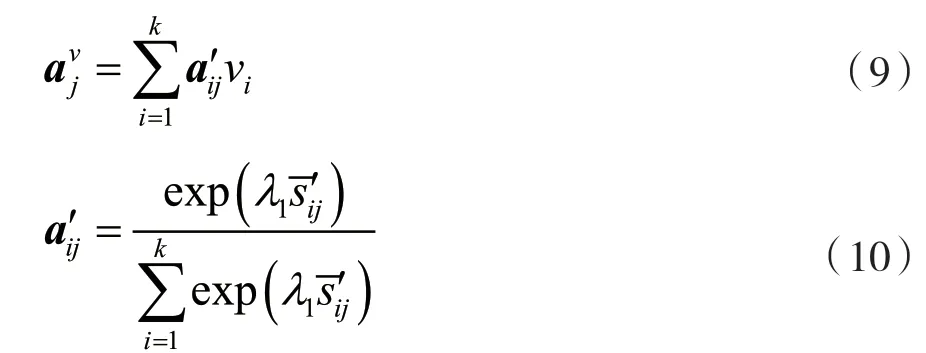
利用参与视频帧向量与单词特征ej之间的余弦相似度,将第j个单词与图像之间的相关性度量为:

视频帧I与句子T最终相似度得分由最大池化层(LSE)进行计算,即:

通过平均池化层计算公式为:

在之前的工作中,将图片与词的相似度定义为vj与ej之间的点积,即:

并且通过聚合所有可能而不使用注意力机制的图像-文本相识度计算:

2.2 目标校准
Triplet loss 是视频帧与文本匹配中常见的排序处理方式。过去的方法采用基于hinge-based 的Triplet loss,即:
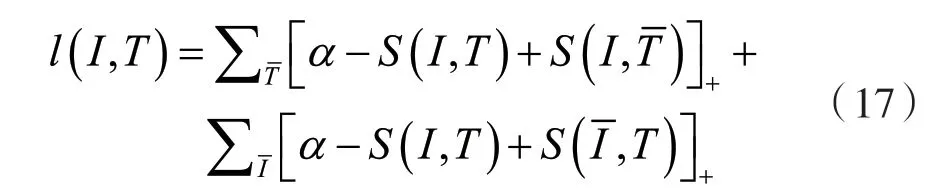
式中:[x]+=max(x,0),S是相似度分数函数。第一个求和是所有非准确词汇给定的图像I,第二个求和考虑所有非准确图像匹配的句子T。如果在这里嵌入空间中,I和T比任何负采样对都要接近,为了提高效率,通常只考虑小批量随机梯度下降中的负采样,而不是对所有负采样求和,即:
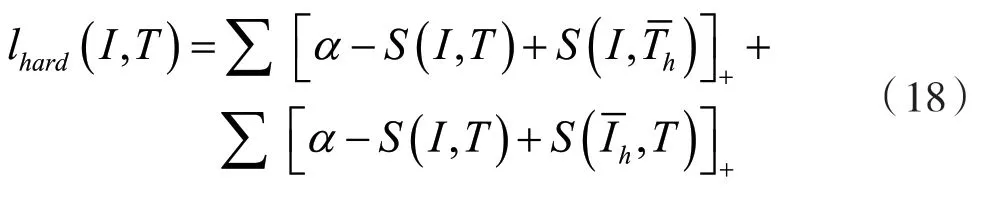
2.3 时间注意力机制
本文采用Soft attention 机制,解码器针对每个时间特征向量F={f1,f2,…,fn}。过去利用这种方法来挖掘图像的底层空间结构,这里对其进行调整,来处理视频的时间结构。不采用简单的平均策略,而是对时间特征向量进行动态加权求和,使得:


上述即是将注意力机制计算为归一化相关分数并归一化得到注意力权重的整个过程。该注意机制允许解码器通过增加相应时间特征的注意权值来选择性地聚焦于帧的一个子集。然而,本文并没有明确地强行使这种选择性注意发生。相反,这种注意力机制的包含使解码器能够利用时间结构。
2.4 LSTM 解码器
本文选择LSTM 作为解码器。与RNN 相比,除了使用通常的隐状态hd外,本文还设定一个内部内存状态cd:

式中:⊙是基于元素的乘法。输出门od的计算式为:
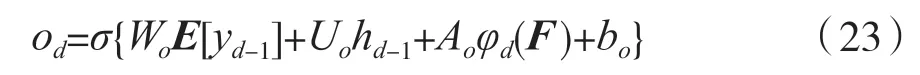
式中:σ是sigmoid 函数,φd是对编码器特征的时变函数;Wo,Uo,Ao和bo依次为输入权重矩阵,前一个隐状态,编码器的上下文和偏差。E为嵌入矩阵,用E[yd-1]表示yd-1词向量。

式中遗忘门和输入门为:

当计算出新的隐状态hd,就可以使用单个隐藏层神经网络得到可能单词集合上的概率分布:

式中:Up,Wp,bp,d为网络参数,softmax 函数分布在p(yd|y<d,F)之间。
之后从LSTM 解码器生成一个句子。例如,可以从返回的p(yd|…)递归地求φ和样本值,直到采样的yd为序列结束符号。也可以通过使用简单的波束搜索来近似地找到概率最高的句子。
3 实 验
3.1 数据集
本实验数据集使用公共数据集Vatex 和笔者收集的汉-越视频翻译数据集进行实验。Vatex 公共数据集包含41 269 个短视频,每条视频都配有由20 位人工注释者标注的5 个中文-英文的平行句对,涵盖了600 项人类活动和多种视频内容,其中每段视频长约10 s,Vatex 数据集有在线测试的方式,将在本地训练的包上传到Vatex 官网在线测试,得到最终双语互译质量评估(Bilingual Evaluation Understudy,BLEU)值。同时,基于视频引导机器翻译任务,本文从汉越新闻网和Youtube、Tiktok、微博等平台共收集了10 500 个视频片段,视频片段约为10 s 同时配有5 个视频描述的汉越平行句对,其中测试集有2 000 条。
3.2 实验设置
本文选用Python 语言以及Pytorch 作为框架实现模型,模型损失采用交叉熵损失函数并选用Adam 优化器。使用单层LSTM,其中隐藏层大小设置为1 024,词嵌入大小设置为512,学习率设置为10-4。Dropout 设置为0.1。
3.3 实验结果与分析
为了验证模型的有效性,本文考虑以下三个基线进行比较。
(1)Base NMT 模型,在只考虑文本信息的情况下,通过LSTM 模型,输入源语言,输出目标语言。
(2)Cross-attention+解码器模型,带有交叉注意力机制,无时间注意机制的模型结构,分别使用门控循环单元(Gated Recurrent Unit,GRU)模型和LSTM 模型进行解码。
(3)Averager 模型,Average 为每10 帧提取一帧的平均策略。
VMT 模型则是Vatex 视频引导机器翻译提供的基线翻译结果,使用了时间注意力机制。本文模型(Cross-attention+Tempeoal attention)则使用交叉注意力方法的模型结构并带有时间注意力机制。采用Vatex 公共数据集的验证集进行对比实验,实验结果(BLEU 值)如表1 所示。
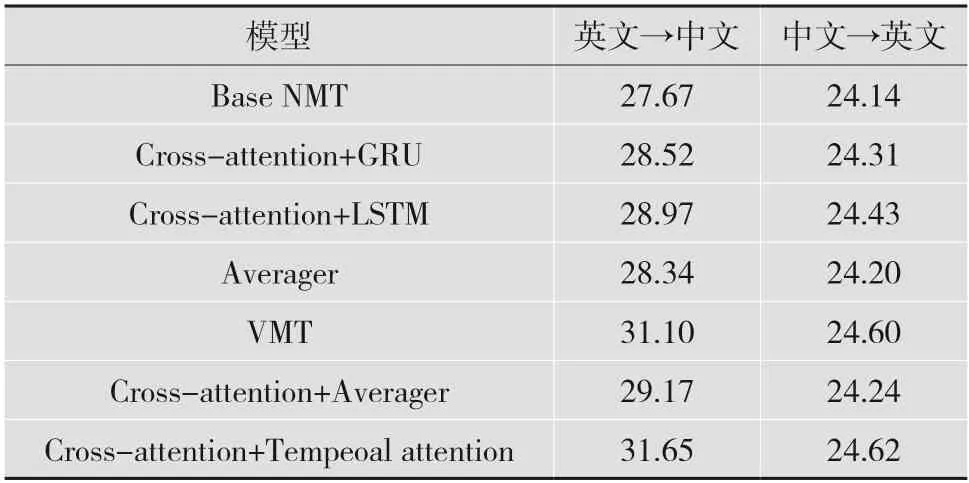
表1 交叉注意力网络模型对比实验BLEU 值
从表1 可以看出,在英文到中文的实验中,Cross-attention+Tempeoal attention 模型获得了最高的BLEU 值,与Base NMT 实验相比获得了显著的提高。比较几个基线模型在英文到中文实验的效果,Cross-attention+LSTM 模型和Cross-attention+GRU模型相比于Base NMT 模型分别提高了0.85 和1.3 个BLEU 值,说明对视频帧使用交叉注意力机制,能够选择出信息更重要的视频帧。Crossattention+LSTM 模型与Cross-attention+GRU 模型相比有0.45 个BLEU 值提高,证明了使用LSTM 在视频引导机器翻译任务中的效果要更好。
VMT 是Vatex 视频引导机器翻译提供的基线翻译结果,它的模型使用了时间注意力机制。与Averager 模型相比,时间注意力机制在Vatex 公共数据集上相比于平均提取视频帧方式的BLEU 值提高了2.76 个,说明在视频引导机器翻译的任务中对视频进行时间注意力机制是有必要的,经过时间注意力机制能够使模型翻译得更好。通过比较本文提出的交叉注意力机制与时间注意力机制结合的方法与VMT 的方法,实验结果的BLEU 值提高了0.55,证明了使用交叉注意力机制能够筛选出与源句子更贴切的视频帧作为辅助进行机器翻译。在中文到英文的对照实验中,本文方法同样未损失BLUE 值甚至有一定的提升。
表2 是本文翻译模型在Vatex 公共测试集上获得的分数,为30.35 个BLUE 值。Vatex 公共测试集无法下载,只能通过网络上传模型得到实验结果。在英文到中文的实验上,相比于VMT 模型,本文模型同样获得了1.23 的BLUE 值提升。进一步说明了本文模型的可靠性。

表2 Vatex 公共测试集实验BLEU 值
表3 是基于笔者收集的汉-越低资源数据集进行的实验结果。实验在52 500 个汉越平行句对的训练下得出实验结果,其中视频有10 500 个。实验结果表明,在数据集为低资源的汉越视频引导机器翻译的情况下,BLEU 值依然有所提高;在低资源数据集中,依然对最后的翻译结果有所改善,证明本文模型在公共数据集和低资源数据集上对机器翻译的结果都有所改善。
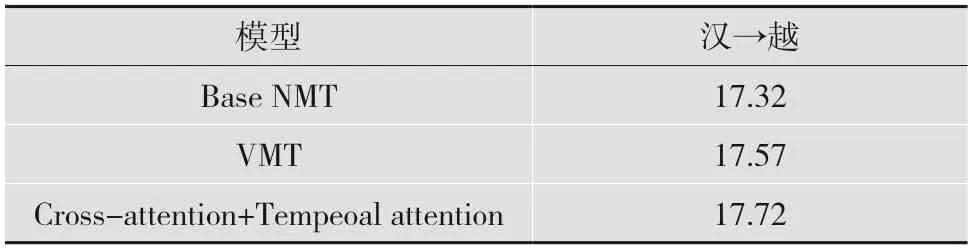
表3 汉越语料对比实验BLEU 值
4 结语
本文从视频帧与文本匹配的角度对视频引导机器翻译进行了深入的研究。视频引导机器翻译是以视频模态作为额外模态,帮助文本从源语言翻译成目标语言的任务。在多模态机器翻译中,不同模态的重要程度是不同的,本文从视频引导机器翻译任务中文本模态的重要程度高于视频模态的角度出发,通过交叉注意力机制,用文本选择出更重要的视频帧,降低相对不重要的视频帧对任务的干扰,从而可以帮助视频引导机器翻译任务达到去除噪声的效果。实验结果表明,交叉注意力机制在视频引导机器翻译中是有效的。
在未来的工作中,将探索文本特征和视觉特征更好的交互,通过词与视觉实体的文本相似度,对视觉特征的权重进行调整。在文本表述模糊的时候,抑制文本模态信号,使模型更关注视觉模态,从而达到两种模态互补的效果,进一步增强视频引导机器翻译性能。
