语义层次网络在文书档案开放审核中的应用
2022-07-14王楠丁原李军
王楠 丁原 李军
摘 要:贯彻新《档案法》,加大档案开放力度,是《“十四五”全国档案事业发展规划》的主要任务之一。文章采用语义工程技术,在构建语义层次网络的基础上,开发了档案智能开放审核系统。选取江苏省档案馆4个全宗的11万余件档案,分别利用关键词过滤法和基于语义层次网络的语义分析法进行检测。检测结果显示,基于语义层次网络的语义分析法较之关键词法,在精确率方面有显著提升,说明语义层次网络可以突破传统关键词技术只能匹配文书档案字面词义的局限,有效降低关键词技术带来的语义失真,从而减少开放审核中的误判、漏判和对不准的问题。
关键词:语义层次网络;档案开放审核;文书档案
《“十四五”全国档案事业发展规划》明确将“加快推进档案开放”纳入“十四五”期间档案事业发展的主要任务,并进一步提出“新一代信息技术在档案工作中的应用更为广泛,信息化与档案事业各项工作深度融合,档案管理数字化、智能化水平得到提升,档案工作基本实现数字转型”的发展方向。[1]2021年1月起正式施行的新《档案法》针对加大档案开放力度做了重要修订。[2]采用智能化辅助手段提升档案开放审核工作效率,已是大势所趋。
一、 研究背景
1. 业内对档案开放审核的相关实践
近年来,各地纷纷尝试利用信息化手段提升档案开放审核工作效率,如:青岛市档案馆编制敏感词库,通过软件对档案目录中的敏感词进行扫描;福建省档案馆利用类别特征词进行开放审核;上海市浦东新区档案馆借助人工智能技术对关键词进行审核;宁波市档案馆开发的馆藏资源管理系统可进行敏感词辅助鉴定提示。[3]利用关键词方式辅助档案开放审核具有投入成本低、门槛低的优势,已成为当前业内主流。
2. 关键词技术存在的问题及解决之道
利用关键词方式辅助档案开放审核,其有效程度严重依赖档案题名或全文中是否存在可供判断的关键词。此方法的局限性在于关键词的词义必须和鉴定条件的语义完全对应。而在以下情境中,很难仅凭关键词判断该档案是否应予继续控制。
情境一:关键词与主语义不匹配。如因涉及商业或技术秘密,“工艺”作为关键词有可能成为控制条件。若某档案题名是“关于印发《加强某中药制剂工艺流程管理》的通知”,虽然题名含有“工藝”,主语义却是“通知”,与关键词不匹配。
情境二:档案不含命中控制条件的关键词,只有对应的语义。例如,行政案件的原告或被告是行政机关,假设某控制条件为“行政案件相关档案应予以继续控制”,但在相关档案的题名和全文里,作为关键词的“原告”“被告”“行政机关”字样可能都没有出现,行文中只有对具体机构名称和案件的描述。
情境三:语义的层次性造成关键词范围难以界定。如涉及我国“重要资源”的材料需要控制,该控制条件的内涵层次则极丰富,本地土地、气候、水、生物、矿产等方面的重要资源都在范围中,单靠整理收录关键词难以穷举。
上述情境都可以看作语义层次的问题。情境一是文书档案中的词义与档案分析人员期望的语义脱节。情境二是文书档案中只有一些语义,而没有对应的词及其词义。情境三是词义和语义的层次太深,在不知晓语义层次关系的情况下,很难确认文书档案中的词义与哪些深层语义存在对应关系,或文书档案中的一些基层词义与哪个抽象的高层语义对应。因此,构建语义层次网络并用以支撑档案开放审核中的条件匹配,是解决上述关键词技术缺陷的可行之道。
3. 业内对语义层次网络的相关研究
近几十年,阐述概念及概念之间关系的理论——本体论(Ontology)被应用到计算机界。[4]1968年,奎林提出语义网络(Semantic Network)概念。1998年,蒂姆·伯纳斯提出语义网(Semantic Web)概念。两者共同的基础是本体论。国内,夏天、钱毅把本体论、语义网络以及元数据的思想运用到了档案数据建设中。[5]相关研究虽然都提出了语义网络的概念,但都未将语义层次作为研究重点,语义层次仅包含在网络概念中。根据奎林的语义网络[6]、菲尔墨的格语法[7]、山克的概念从属逻辑理论[8]及汉语“字义基元化,词义组合化”现象,中科院声学研究所黄增阳教授创立了语义层次网络(Hierarchical Network of Concepts,HNC)理论。[9]HNC理论认为,所有的自然语言空间对应着同一个语言概念空间。[10]HNC理论的创新点是专门针对层次的论述,缺陷在于把静态的概念和动态的事件混杂在一起,使得层次关系冗杂紊乱。
基于此,本研究采用人工智能领域前沿的语义工程技术,打造突出层次关系的语义层次网络。与此同时,对本体论中的概念定义进行了细化,重点区分了静态实体概念和动态事物或事件(即在特定环境中发生的事物)概念。在此基础上,开发了档案智能开放审核系统,以期改善以往主要借助关键词技术的档案开放审核系统的不足。
二、 技术方案
1. 开放审核的机理
利用计算机辅助档案馆进行开放审核可以有两个设计方向:一是让计算机自动找出应予以控制的档案;二是让计算机自动找出应予以开放的档案。即使前者将一部分应予以开放档案误识别为应予以控制档案,只要误判率足够小就可以接受,因为被误判的档案尚处于档案馆管控中,未来还有开放机会,而并未造成泄密。但对于后者,哪怕只有一份应予以控制档案被误开放,也是严重的泄密事故。
保证计算机识别的有效性主要靠条件匹配法。一方面,把国家规定的抽象划控鉴定条件与档案馆自身的具体情况相结合,细化出适合本档案馆的鉴定条件集;另一方面,让计算机从档案中自动提取适合鉴定条件的线索,与细化后的鉴定条件匹配,匹配成功就会触发对档案的划控识别。
2. 基于语义分析的解决方案
准确匹配文字内容的技术是语义匹配,只要档案中所表达的意思与鉴定条件的意思相同,则触发划控识别的准确率是100%。故此,开放审核的问题转化为如何解析鉴定条件到一系列具体语义,如何在档案中准确识别语义,以及如何匹配二者的问题。
实际上,关键词匹配也是一种语义匹配。如果一个关键词不足以表达目标语义,可以用一组关键词来映射档案原文中蕴含的语义。如果一组关键词不够,可以把词出现的顺序(即词序)和出现的次数(即词频)也用上。如果加入词序和词频还不够,可以把词性、语法和句法等关系都用上。以上所有方法有一个共同的特点,即完全依赖档案原文中的词及词与词之间的关系。因此,这类语义分析方法称为字面语义分析或浅层语义分析。
档案中还有很多语义不是直接通过字面语义表达出来的,需要结合语境、语义模型等进行推断才能获得。以“聚众赌博”为例,不是含有这个词的档案都需要控制使用,如《某单位职工行为规范》;但如果“聚众赌博”一词出现在与评鉴某人相关的文件里,则该档案应予以控制使用。这类语义分析称为隐含语义分析或深层语义分析。本研究开发的利用语义层次网络的语义分析技术就是一种深层语义分析技术。
3. 语义层次网络的构建
语义层次网络是一种专门为解决对不准问题而设计的语义模型。一般的语义网络中,节点之间的关系可以是任意关系,包括同级节点之间的关系、相邻节点之间的关系、跨节点的关系、相邻层级之间的关系以及跨层级的关系等。语义层次网络只包括相邻层级之间的关系,不包括同层级的任何关系,即:同层级节点之间相互独立,也不包括任何跨节点关系和跨层级关系(二者的区别见图1)。
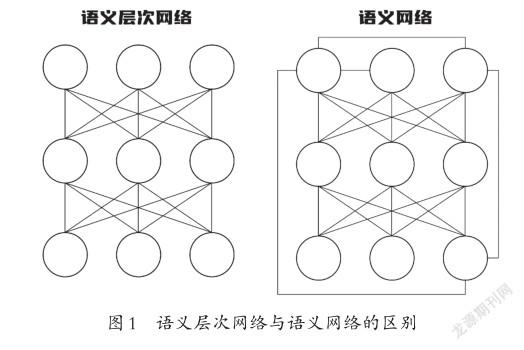
语义层次网络是解析抽象档案鉴定条件的基础。语义层次网络建设越完备,抽象鉴定条件就可以被解析得越具体,越容易被计算机匹配成功。同样,语义层次网络也是在档案中从抽象字面语义挖掘具体语义的基础。语义层次网络可以使档案原文和鉴定条件中逻辑距离看似很远的词组之间在任意语义层次中实现对齐,完成匹配,以此有效解决档案开放审核工作中对不准的问题,同时减少误判和漏判。
(1)概念的表示
语义层次网络与泛化的语义网络都是以概念为节点,语义层次网络的节点不仅包括静态的实体概念,还包括动态的事物,采用定义更宽泛的参数作为特征描述量。本研究定义的概念将实体和事物作了明确区分,有利于规范它们各自的关系和相互之间的关系。
针对文书檔案,概念节点指一类文字语义,由概念名(n)、概念语义定义(d)和概念值(v)组成的三元组[n、d、{v}]表示。{v}代表所有符合d的v值的集合。例如,“人名”是一个概念,其名称就是“人名”,其语义定义为“人的称呼”,其值为原文中所有符合该语义定义的具体人名。
(2)概念的层次
概念层次(Hierarchy,简称:h)的分层方法由各种层次分明的关系决定,包括但不限于如下类型。
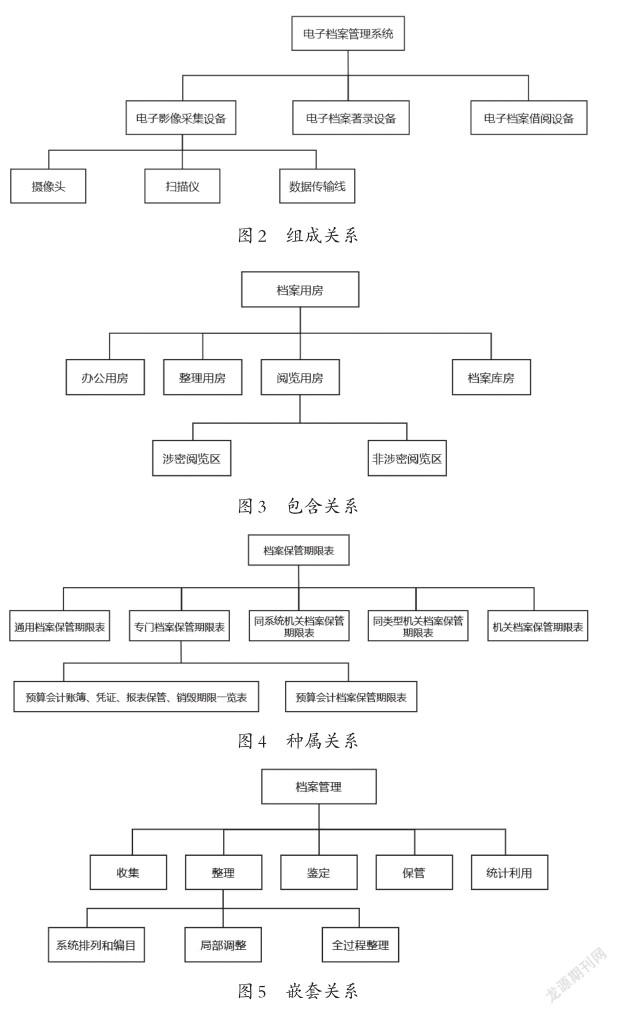
① 组成关系,即:字段之间具有“局部”功能组成“整体”功能的关系(见图2)。
② 包含关系,即:客观存在的空间形式逻辑关系定义下的局部与整体关系,“局部”包含在“整体”之内(见图3)。
③ 种属关系,即:相同分类特征定义下的一事物类与其子类的关系(见图4)。
④ 嵌套关系,即:事物过程与步骤的关系(见图5)。
鉴于语义层次网络的完整性,设计该网络的节点时可设计一定数量在档案原文中无对应内容的节点,称为“虚节点”,而在原文中有对应内容的节点称为“实节点”。如果将语义层次网络视为“树”,在设计和表示语义层次网络时,末端节点都是实节点,但可以“剪枝”。“剪枝”后的末端节点,无论是实节点还是虚节点,应继承其下所有未展开节点的特性。
事物或事件为节点时,以它们之间的组成关系、包含关系、属种关系或嵌套关系为分层依据,可以组成更高层次的抽象概念,包括但不限于:一系列简单事物类概念组成的多层次复杂事物概念是“复杂事物”类概念,如出访、交易等;由一系列相关的典型性事物概念组成的高级抽象概念是社会事务类概念,如外交、经济等;由一系列相关的、集中发生的事件概念组成的高级抽象概念是社会运动类概念,如战争、改革等;由一系列相关的、经常发生的事件概念形成的高级抽象概念是社会现象类概念,如科技创新、精神文明建设等。业内所指的“关键词”,在本研究中也是一种特殊的概念,概念名就是对象关键词本身,其语义定义可能是其自身的词义,也可能是语义层次网络定义人员认为重要的任意语义,关键词概念的值是原文中对象关键词的所有同义词。
(3)概念的参数
定义概念和概念的层次在很大程度上有助于进行语义识别,但对于利用概念做语义分析、为文书档案开放审核设计鉴定规则还远远不够。为增强语义分析能力,不仅须定义出概念名表达的语义和层次关系,还须定义或识别出围绕概念的参数(Parameter,简称p),并挂接在其修饰的概念下。概念拥有属性、性质、方面、数量、能力等基本参数,事物或事件节点还拥有方式、目的、指向、能愿等参数。
属性(Attribute),所有可测量或可感知的量,其特性是可排序、可比较。它的名称是该属性维度的名称,值是该属性维度中的一个特定项。
性质(Nature),只可做定性比较的量,一般只有三个值:左极端值、右极端值、中间值。性质的名称一般是性质两个极端值的组合,例如好坏、强弱、优劣等;其值是该性质的三个值之一,例如名称是“优劣”,值是“中”。性质的名称也可以由形容词加“性”字后缀表示,如“重要性”,其正值就是形容词本身,如“重要”;负值就是形容词前加“不”字,如“不重要”;中间值就是“既+形容词+又不+形容词”,如“既重要又不重要”。
方面(Aspect),修饰宿主概念的其他概念,例如形式、趋势等。除专门解释这类概念的句型,这类概念在句中一般不单独使用,须与宿主概念搭配表达才有意义,例如合作形式、发展趋势等。方面类参数的名称是文书档案中表示方面的概念词,其值类似性质值的表述,即:用几个简单的等级做定性描述,例如名称是“形势”,值是“好”。
数量(Quantity),即宿主概念的可数特征,如概念的“数量”,行为的“频次”,对于事物或事件而言,则既可是数量,也可是频次。数量类参数的名称是文书档案中该数量的宿主实体或事物的数量表示,例如总人数、销售额、比赛成绩等,其值就是它们的具体数值(+度量单位),如80人、1000万元、129分等。
能力(Ability),表示其修饰的实体概念能够干什么。能力类型的参数名多以表示能力的事物或事件的“行为+客体”形式命名,如踢球、学习英语等,或用“主体+行为”的形式命名,如自我安慰、火山爆发等。能力的值常用“会+事物”“能+事物”“干过+事物”等类似短语表示,例如会武功、能爬山、当过兵等。
事物或事件概念还存在以下参数:方式(Method),即如何实施,包括参考依据、所使用的工具等;目的(Purpose),即实体概念实施行为的目的;指向(Point),指实体概念行为作用的对象;能愿(Desire),代表实体概念实施某类行为的可能性、倾向性。
值得注意的是,本研究定义的“参数”与一些学者在自然语义处理技术中定义的“元数据”类似,都是描述或限定概念的量。不同之处是,参数更强调原文中宿主概念自身拥有的、代表语义的特征量,可以用于语义分析,而元数据更强调文字工作者为使用文本内容定义给宿主概念的名称,适用于内容管理。
(4)概念的状态
“状态”是概念的一个动态参数,指概念任意变化在某个时点或时段的值。状态类参数的名称与其宿主概念有关。如果宿主概念与状态参数的关系明确,状态名可直接使用变化量的名称,否则按“宿主名+‘.’+变化量名”命名。例如,“案卷.质量”“馆藏档案.保存情况”等。状态值可能有三种形式:一是变化量,如“全宗增加了三个”;二是在某个时段的值,如“立档单位合并撤销”;三是发展趋势,如“脱贫攻坚档案整理扎实推进”。
在语义层次网络中,一个节点的基本概念可由[n,d,{v}]表示,该节点可能拥有的参数可由{p}表示,该节点对相邻节点的所有层次关系可由{h}表示(注意同层级节点之间是相互独立的),则语义层次网络节点的完整表述可以是一个五元组[n,d,{v},{p},{h}]。参数集合{p}中包括动态参数“状态”,因此这个五元组既表示语义层次网络节点的静态关系,也表示其动态关系。
4. 基于语义层次网络的文书档案开放审核系统

在上述概念的基础上,本研究绘出了基于语义层次网络的文书档案开放审核系统总体框架图(见图6)。其中,解决方案包括五个组成部分:①档案预处理;②档案文本解析;③档案语义分析;④档案开放审核;⑤档案人工审核。
档案预处理模块把非文本档案转化为纯文本档案。这是后续所有语义分析模块的基础。
档案文本解析模块把纯文本档案转化为一个可以进行语义分析的文件。有两个子任务:一是恢复纯文本档案的版面格式,例如正确划分段落、句子,正确区分标题、正文等;二是对文本的每个自然句进行自然语言解析,包括切词、词性标注、词语聚合、短语识别等。
档案语义分析是核心模块,分为格式语义分析、浅层语义分析和深层语义分析。
格式语义分析模块能够将档案版面位置所隐含的语义“翻译”出来,如识别密件的密章或“内部材料”“机密”等标密格式,使之成为开放审核线索之一。它可以在档案预处理的结果上运行。在格式语义库的支持下,其分析结果直接输出至基于语义分析的开放审核模块。
浅层语义分析主要依靠字符串匹配技术实现。浅层语义分析又分为全文检索和字面语义分析。语义主要由词义体现,没有层次。如果一次只匹配一个词,则为全文检索。全文检索采用业内成熟模块,在纯文本档案的基础上,由一个关键词库支持。如果一次匹配多个字符串,并集齐字符串的上下文信息用以分析句子乃至整个档案的语义,则为字面语义分析。字面语义分析较之全文检索,语义失真程度明显更低。
深层语义分析是本研究的重点创新。文书档案中的字符串只是语义层次网络节点概念的名称,其语义由语义层次网络各层相应节点的语义决定。因此,深层语义分析不再是简单的字符串匹配技术,而是在语义层次网络的不同语义层中的语义匹配,由此可以挖掘字符串名下隐含的深层语义。
深層语义分析和鉴定条件解析都由基于语义层次网络的语义知识库支撑。进行开放审核时,输入的鉴定条件往往非常抽象,不能为计算机直接使用。条件解析模块将简单抽象的鉴定条件在语义层次网络中解析,不断细化、具体化,直到计算机从档案原文中提取的语义线索为容易匹配的层次,由此形成鉴定条件库。
格式语义分析、浅层语义分析和深层语义分析的结果都会输入“基于语义分析的档案开放审核”模块,在鉴定条件库的支撑下,实现文书档案语义与鉴定条件语义的相互匹配,完成对档案的开放审核,输出不可开放的档案(集)。在输出不可开放档案的同时,系统会将候选开放的档案移交人工审核。经人工确认无误,系统输出可以开放的档案(集)。
三、 实验验证
为验证语义层次网络在文书档案开放审核中的作用,本研究做了一个对比实验,从江苏省档案馆选取了4个全宗的11万余件档案,分别利用传统的关键词过滤法和基于语义层次网络的语义分析法各检测一遍,并将两次结果进行比较。
需要说明的是,基于语义层次网络的语义分析法也包括关键词技术。当语义层次只有一层时,字符串匹配就很重要,如果每次只匹配一个字符串,就是关键词匹配。理论上讲,基于语义层次网络的语义分析法在关键词技术的基础上增加了更多、更强大的功能,较之单独使用关键词匹配技术的方法应用效果应该更好。
1. 评价方法
本次实验采用的评价方法为业内标准的评价方法,为便于理解实验结果,仅对相关术语做了调整。本实验主要采纳三个评价指标:
① 检出率(Acc),在整个件数样本N中,被检出的需要划控的档案件数M,即:Acc=M/N;
② 精确率(Pre),在被检出的需要划控的档案件数M中,确实需要划控的件数m,即:Pre=m/M;
③ 召回率(Rec),假设真实需要划控的档案件数为Z,上述机器识别出的正确的划控件数m与Z的比为召回率,即:Rec=m/Z。
由于在具体的实验中,真正需要划控的档案件数Z是一个未知数,我们用人工鉴定的结果来代替,即:把与人工鉴定结果完全一致的档案件数称为“确实需要划控的档案件数m”,把人工鉴定需要划控的档案总件数称为“真实需要划控的档案件数Z”。因此,本实验的精确率和召回率实际上只是个近似值,取决于人工鉴定结果的质量。
为保证实验结果的可比性,本研究严格遵守“其他条件完全相同”的原则,即人工鉴定结果造成的系统误差对关键词法和语义分析法的影响相同,以此保证两种方法实验结果的相对可比性。
2. 实验数据
实验结果数据如表1所示。对比各组检测结果和平均值,基于语义层次网络的语义分析法较之关键词法,在精确率方面有较大提升。由此可知,语义分析法更接近人工开放审核的真人判断。该结果为本研究的理论假设提供了证据,即:语义层次网络的设计可以有效减少关键词技术缺陷导致的语义失真,减少误判、漏判和对不准的问题。
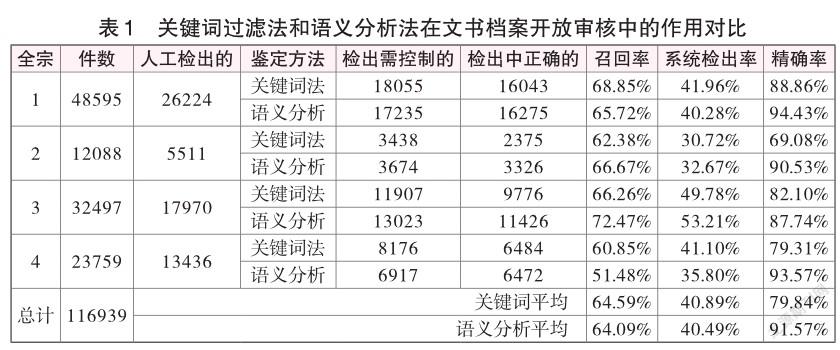
实验结果显示,在检出率方面,基于语义层次网络的语义分析技术较之关键词技术,改进并不明显。其原因主要在于:一个全宗内能检出的应划控档案的数量,取决于实际应划控档案在该全宗内的数量。有的全宗内大部分都是需要开放的档案,因此就算把应划控档案全部识别出来,也不会产生高检出率;而对于一个大部分档案都需要划控的全宗而言,检出率相应就会很高。因此,对于计算机自动开放审核而言,主要目标是把应划控档案尽量都检测出来,检出率只是节约人力程度的参考指标。
与检出率相比,召回率更能体现机器算法与人类意见的一致性。如果召回率高一些,说明计算机判定划控的标准制定得宽松了一些;反之,召回率低一些,说明相应标准严苛了一些。这正是本实验语义分析的精确率徘徊在90%左右的原因。理论上,只要鉴定条件设计合理,计算机检出的应划控档案一定押中了某条鉴定规则,精确率应接近100%,但是,本实验对比的标杆是人工检测结果,人机认识上的偏差必然导致精确率的下降。换言之,改进、完善语义层次网络,使计算机的鉴定规则更加贴近人的认识,是提高档案开放审核精确率和召回率的关键。
四、 结论
本研究提出的语义层次网络能够在文书档案字面语义与开放审核条件所蕴含的深层语义之间搭起一座桥梁,打破了传统关键词技术只能匹配文书档案字面词义的局限性,有效降低关键词技术带来的语义失真,从而减少开放审核中的误判、漏判和对不准问题。
提高文书档案开放审核质量的关键在于完善用于支撑开放审核的语义层次网络以及基于该网络的语义知识库,继而完善基于该语义知识库的文书档案语义识别、分析、判断和审核系统。此外,考虑到基于语义层次网络的文书档案开放审核系统需要对待鉴定档案进行全文解析,因此系统在设计功能时应具备全文OCR提取能力。与此同时,鉴于当下国内档案馆多采用国产信创环境,系统设置也应做到充分兼容,可无障碍对接档案馆现有管理系统,从而实现审核结果高效率回填。
*本文系国家档案局科技项目“基于语义分析的档案馆划控开放智能鉴定的研究”(项目编号:2021-X-71)阶段性研究成果。
注释与参考文献
[1]中华人民共和国国家档案局.中办国办印发《“十四五”全国档案事业发展规划》[EB/OL] .[2021-06-09].https:// www.saac.gov.cn/daj/toutiao/202106/ecca2de5bce44a0eb5 5c890762868683.shtml.
[2]中华人民共和国国家档案局.中华人民共和国档案法[EB/OL] .[2020-06-20].https://www.saac.gov.cn/daj/falv/202006/ 79ca4f151fde470c996bec0d50601505.shtml.
[3]参考自江苏省档案馆馆长陈向阳在2021年12月15日召开的“江苏省馆藏档案开放工作视频会”上作的报告:《聚焦主责主业、勇于担当作为,全力提升馆藏档案开放工作水平》。
[4]Stanford Encyclopedia of Philosophy.Logic and Ontology[EB/OL].[2022-06-28].https://plato.stanford.edu/entries/ logic-ontology/.
[5]夏天,錢毅.面向知识服务的档案数据语义化重组[J].档案学研究,2021(2):36-44.
[6]语义网络[EB/OL].[2022-06-28].https://baike.baidu. com/item/%E8%AF%AD%E4%B9%89%E7%BD%91%E7%BB%9C/ 2841346 fr=Aladdin.
[7]Fillmore C J. The case for case[J].Universals in Linguistic Theory,1967(4):16-24.
[8]Schank R C. Conceptual Dependency: A Theory of Natural Language Understanding[J].Cognitive Psychology, 1972,3:552-631.
[9]温有奎.文本知识分析中的语义层次网络方法[J].情报科学,2002(3):260-261.
[10]中国科学院声学研究所.HNC(语义层次网络)理论[C]//中国中文信息学会第六次全国会员代表大会暨成立二十五周年学术会议中文信息处理重大成果汇报展资料汇编,2006:139-143.
