Multi-head attention-based long short-term memory model for speech emotion recognition
2022-07-13ZhaoYanZhaoLiLuChengLiSunanTangChuangaoLianHailun
Zhao Yan Zhao Li Lu Cheng Li Sunan Tang Chuangao Lian Hailun
(1School of Information Science and Engineering, Southeast University, Nanjing 210096, China)(2School of Biological Science and Medical Engineering, Southeast University, Nanjing 210096, China)
Abstract:To fully make use of information from different representation subspaces, a multi-head attention-based long short-term memory(LSTM)model is proposed in this study for speech emotion recognition(SER).The proposed model uses frame-level features and takes the temporal information of emotion speech as the input of the LSTM layer.Here, a multi-head time-dimension attention(MHTA)layer was employed to linearly project the output of the LSTM layer into different subspaces for the reduced-dimension context vectors.To provide relative vital information from other dimensions, the output of MHTA, the output of feature-dimension attention, and the last time-step output of LSTM were utilized to form multiple context vectors as the input of the fully connected layer.To improve the performance of multiple vectors, feature-dimension attention was employed for the all-time output of the first LSTM layer.The proposed model was evaluated on the eNTERFACE and GEMEP corpora, respectively.The results indicate that the proposed model outperforms LSTM by 14.6% and 10.5% for eNTERFACE and GEMEP, respectively, proving the effectiveness of the proposed model in SER tasks.
Key words:speech emotion recognition; long short-term memory(LSTM); multi-head attention mechanism; frame-level features; self-attention
Speech emotion recognition(SER)plays a significant role in many real-life applications, such as human-machine interaction[1]and computer-aided human communication.However, it is challenging to make machines fully interpret emotions embedded in speech signals owing to the subtlety and vagueness in spontaneous emotional expressions[2-3].Despite the wide use of SER in applications, its performance remains far less competitive in comparison with those of human beings, and the recognition process still suffers from the local optima trap.Therefore, it is essential to further enhance the performance of automatic SER systems.
Deep learning networks have shown great efficiency in dealing with SER tasks, such as convolutional neural networks(CNN)and recurrent neural networks(RNN), which brings a great improvement in the recognition accuracy[4].The attention mechanism is also utilized in neural networks to dynamically focus on certain parts of the input.Mirsamadi et al.[5]introduced the local attention mechanism to an RNN to focus on the emotionally salient regions of speech signals.Statistical features were used for the study.Tarantino et al.[6]proposed a new windowing system with the self-attention mechanism to improve the SER performance.These studies[5-6]follow the traditional method of using low-level descriptors as the input.Recently, spectrograms have gained considerable attention as the input feature.For instance, Li et al.[7]adopted the self-attention mechanism for the salient periods of speech spectrogram.Although researchers paid considerable attention to deep networks, the input features are mainly extracted from the time dimension.
Many studies focus on exploring multiple dimensions’ feature vectors.Xie et al.[8]proposed a weighting algorithm based on time and feature-dimension attention for the long short-term memory(LSTM)output, which could significantly improve the SER performance.Li et al.[9]combined a dilated residual network and multi-head self-attention to model inner dependencies.For the above algorithms[8-9], the last time-step output of models is used as the input of the next layer.The studies indicate that parallel multiple feature vectors help improve the SER performance.Moreover, the attention mechanism has demonstrated great performance for SER tasks[5-9]and has been used in combination with deep neural networks.
In this research, an improved multi-head attention LSTM model is proposed to overcome the above-mentioned barriers and improve the SER performance.Multi-head time-dimension attention(MHTA)has the ability to jointly attend to information from different representation subspaces at different positions[10].Deep network outputs are performed in parallel through the attention function and then concatenated for the final values.Compared with a single-head attention output, concatenated values contain various context vectors, which are weighted by different attention functions.The transformer based on the multi-head attention mechanism is introduced to the pre-training model, named bidirectional encoder representations from transformers(BERT)[11], becoming one of the most successful models for natural language processing.The success of pre-training by BERT makes multi-head attention widely being used for various fields of speech, such as speech recognition.Lian et al.[12]employed the multi-head attention layer to predict the unsupervised pre-training for the Mel spectrum.Tian et al.[13]introduced multi-head attention into the RNN-transducer structure and achieved excellent results.However, the above-mentioned models did not use the mechanism for mining the temporal relations from the LSTM output.Previous studies mainly focused on directly utilizing multi-head attention layers for pre-training and improving the SER performance.From this point of view, the values contain more information of the salient speech region.The all-time output and last time-step output are utilized for the MHTA calculation.Moreover, SER is not just decided by the output of the MHTA but also by different representations from other aspects.Therefore, the output of feature-dimension attention and the last time-step output of LSTM are introduced to the final context vector.The information loss always exists during the backpropagation of the traditional deep learning network.The residual neural network[14-15]helps solve this problem by connecting the previous layer output with the subsequent layer output directly.Inspired by the idea, feature-dimension attention for the all-time output of the first LSTM layer is employed to select useful information.Finally, the context vector is fed to the fully connected layer.Experiments conducted on the eNTERFACE and GEMEP corpora demonstrate the effective performance of the proposed model.
1 Proposed Method
1.1 Frame-level feature extraction
The openSMILE[16]features proposed by Schuller et al.[17]are the most widely used speech features for SER.In this research, to keep the uniformity and coherence of the previous work[8], the same frame-level features are used.
1.2 MHTA mechanism
In this structure, the LSTM layer for processing the time series samples with the variable length is used.The LSTM network, which is proposed by Hochreiter and Schmidhuber[18], models time series sequences and generates a high-level representation.It has the ability to extract features automatically and hierarchically.To maintain continuity and consistency of the previous work[8], which demonstrates the effectiveness of the attention gate, the double-layer LSTM with the attention gate was used in the structure.The LSTM’s output can be described as a matrix composed of time steps and feature data.Therefore, neural components are required to learn hidden information between the time steps and features of the output representations.In this paper, improved attention is introduced as the core mechanism for computing the representations’ time and feature relationship.
Vaswani et al.[10]introduced an attention function as mapping a query and a set of key-value pairs to an output.The output was computed by weighted values, where the weight was calculated by the query with the corresponding key.Instead of applying a single attention function, Vaswani found it useful to apply multi-head attention functions for queries, keys, and values.The neural network utilizes the multi-head attention algorithm to consume hidden information from different subspaces, which can significantly improve the performance compared with single-head attention.
Multi-head(Q,K,V)=Concat(h1,h2,…,hn)WO
(1)
hi=Attention(QWi,Q,KWi,K,VWi,V)i∈[1,n]
(2)
whereQ,K, andVare the query, key, and value vectors;Wiis the parameter matrix for mapping into subspaces;WOis the mapped-back parameter matrix; n is the number of attention heads.
The frame-level features were selected for SER.Because the frame-level features contain the time and feature relationship of the LSTM output, the attention function applied to the time and feature dimensions helps the model to improve performance.A previous work[8]used the attention mechanism on the time and feature dimensions to achieve state-of-the-art performance for emotion recognition.The attention weighting for the time-dimension calculation is
St=softmax(Om(OaWt)T)
(3)
Ot=StOa
(4)
whereOm∈RB×1×Zis the last time output andOa∈RB×F×Zis the all-time output;Bis the batch size;Fis the number of time steps;Zis the feature’s dimension;St∈RB×1×Fis the attention score of the time dimension;Otis the output of the time-dimension attention layer, which is subsequently fed into the fully connected layer.
Theoretically, the multi-head attention algorithm, intended to project the LSTM output into different subspaces for hidden information with different dimensions, could achieve a good performance.Moreover, for each head, the decreased dimensions help to keep the calculation amount similar to that of the single-head attention.The last time-step output of LSTM accumulates the greatest amount of information because of the memory ability of the LSTM network.By using the all-time output of LSTM and last time-step output, the keys, values, and queries are computed as
Ki=Wi,KOa+bi,K
(5)
Vi=Wi,VOa+bi,V
(6)
Qi=Wi,QOm+bi,Q
(7)
Next, the calculated keys, values, and queries are utilized to compute the corresponding attention scores and attention output.The calculations are as follows:
(8)
omti=siVi
(9)
Omt=Concat(omt1,omt2,….,omtn)
(10)
wheresiis the multi-head attention score on the time dimension andomtiis its output for each subspace;Omtis the final output of the MHTA layer.After the output from all the subspaces is obtained, outputs from their corresponding subspaces are concentrated, which will be fed into the fully connected layer.
1.3 Multiple-context-vector generation
For SER, the features exhibit different influences.To classify the feature difference, the feature-dimension attention mechanism is applied in this work.The feature-dimension attention used in the model helps to relieve the overfitting problem caused by the time-dimension multi-head attention algorithm.The feature weighting is calculated as follows:
sf=softmax(tanh(Omwf)uf)
(11)
Of=∑sfOa
(12)
wherewfandufare the training parameters.The feature-dimension attention scoresf, which is different from each other, could indicate the effect of different features.Next, the summation over the time frames is calculated.The outputOfrepresents the statistical value of the time-dimension features.
Finally, the last time-step output(Ols)is chosen, which accumulates the greatest amount of information as parts of the final output.The final output consists of three different parallel characterizations.After the context vector is calculated, they are put through the unsqueeze function.
Otfl=Concat(Omt,Of,Ols)
(13)
Oap=Averagepooling(Otfl)
(14)
However, because a double-layer LSTM structure is used in this study, the LSTM layer may discard vital information during the process.Therefore, the all-time output of the first LSTM layer(Oaf)is taken into consideration.The modified output calculation is
Omo=Concat(Omt,Of,Ols,Oaf)
(15)
Another problem arises becauseOlsandOafcould contain the same information, which leads to information redundancy.This situation is not expected to happen because it may have a bad influence on the effectiveness and performance of the model.To avoid such a situation, the feature-dimension attention mechanism is applied for the first LSTM layer’s all-time output to screen for useful information.
sa=softmax(tanh(Oafwf)uf)
(16)
Oal=∑saOaf
(17)
Finally, the multiple context vectors are calculated and used as the input of the fully connected layer.
Oc=Concat(Omt,Of,Ols,Oal)
(18)
The new context vector(Oc)not only provides inherent information from time and feature dimensions but also utilizes the last time-step output as auxiliary information for SER.It can strengthen the key information and ignore irrelevant information to generate a highly effective feature representation.Fig.1 shows the proposed multi-head attention-based LSTM structure.

Fig.1 Proposed improved multi-head attention structure
2 Experiment and Analysis
2.1 Database
The proposed model is evaluated on eNTERFACE[19]and GEMEP[20]corpus.The eNTERFACE dataset contains 42 subjects(34 male and 8 female).The audio sample rate was 48 MHz, in an uncompressed stereo 16-bit format, with an average duration of 3.5 s.In this research, 1 260 valid speech samples are used for the evaluation, where 260 samples are used as the test set.
GEMEP is a French-content corpus with 18 speech emotional categories, including 1 260 utterance samples.Twelve labeled classes are selected:relief, amusement, despair, pleasure, anger, panic, interest, joy, irritation, pride, anxiety, and sadness.Therefore, 1 080 samples are used from the chosen categories, where 200 samples are selected as the test set randomly.
2.2 Experimental setup
In this section, the proposed model is compared with several baselines:1)LSTM; 2)LSTM with time-dimension attention; 3)LSTM with MHTA.For experiments performed on the same database, the parameters are kept the same for the LSTM layer.
The input dimension is[128,t,93], where 128 is the number of batch sizes,tis the frame number, and 93 is the number of extracted features.The output dimension is[128,c], wherecrepresents the number of emotion categories in databases.For the double-layer LSTM, the first layer has 512 hidden units, while the second layer has 256 hidden units.To ensure the dependability and reliability of the experiments, other parameters are kept the same.
As SER is a classification task, the unweighted average recall(UAR)is used as the evaluation metric.
2.3 Results and discussion
Experiments are conducted to verify the effectiveness of the proposed multi-head attention mechanism.Tab.1 presents the results of the LSTM model and time-dimension attention-based LSTM models.Compared with the LSTM model, the time-dimension attention LSTM obtains a recognition accuracy of 83.8% and has an 8.0% improvement on the eNTERFACE corpus.For the GEMEP corpus, LSTM with the attention mechanism also obtains an increase of 4.5%.Tab.2 exhibits the results of the models with three context vectors.The results prove that the LT8 model outperforms other models.The results show a tendency of increasing first and then decreasing, which indicates that the model achieves its boundary when it has eight heads.
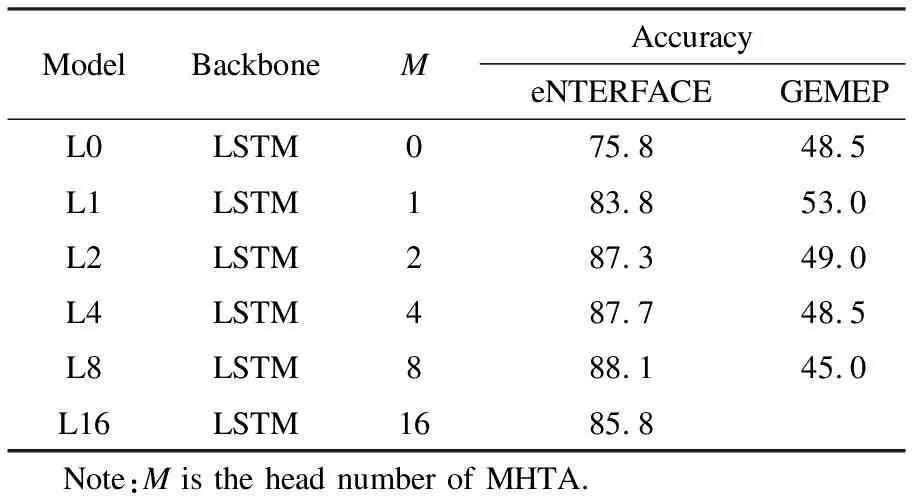
Tab.1 Results of the time-dimension attention LSTM models %
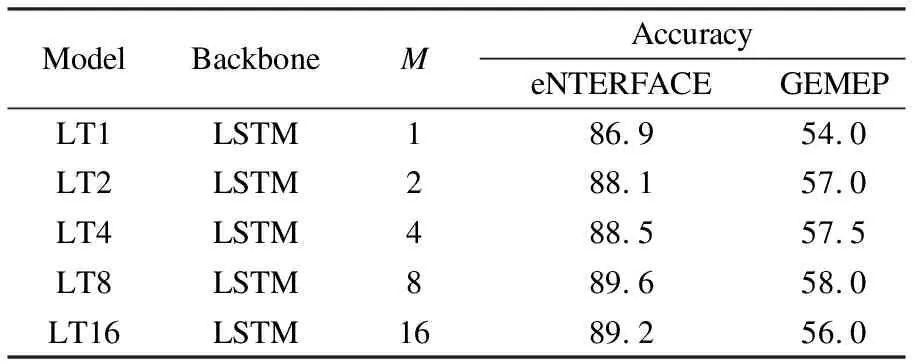
Tab.2 Results of the models with three context vectors %
Furthermore, the recognition accuracy increases along with the increase in the time-dimension attention head number(less than eight)and then decreases.The reason is that projecting into subspaces has its boundary.Good results cannot always increase by simply increasing the head numbers.This tendency indicates that the multi-head attention is effective for the eNTERFACE corpus.The accuracy of the proposed model is better than that of LSTM, and the curves seem to increase together with the increase in the head number.When the head number is equal to eight, the proposed model achieves the best recognition accuracy of 89.6% and 58.0% in the eNTERFACE and GEMEP corpora, respectively.
Multitask learning[7]has proven its effectiveness for speech recognition.Compared with multitask learning, multiple context vectors are used to determine SER results.Although time-dimension attention would complicate the model, the classification is dependent not only on the context vector of the multi-head attention layer but also on other context vectors.Finally, the output of the feature-dimension attention layer and last time-step output together are composed with the context vector of MHTA to form the final context vector.
In this paper, multiple context vectors are proposed to analyze speech emotions.To evaluate the effectiveness of the proposed method, several experiments are conducted.As several studies have proven the effectiveness of the time-feature attention mechanism[8]and skip connection structure[21]for SER tasks, the performance of the proposed model is compared with the attention LSTM network.As the results of multi-head LSTM models hint that the models achieve the best performance when the head number is equal to eight, it is applied for the attention-based models with different context vectors.Model performance comparisons against other techniques are presented in Tab.3.The experimental results indicate that the proposed model outperforms LSTM by 14.6% and 10.5% for eNTERFACE and GEMEP, respectively.The UARs decrease in the eNTERFACE and GEMEP databases when the all-time output of the first LSTM layer is employed as an additional context vector for the fully connected layer.This situation may be a result of the all-time output of the first LSTM layer that provides too much redundant information for the model.It makes the fully connected layer input less effective.To solve this problem, the assumption is to employ the feature-dimension attention mechanism for the all-time output of the first LSTM layer to select useful inherent information.

Tab.3 Results of the LSTM models with various context vectors %
The proposed model is compared with other methods.The local attention mechanism[5]is re-implemented for SER.As CNN networks have been widely used for SER tasks, CNN networks[7, 22]are re-implemented as comparisons.Tab.4 shows the comparison of the experiment results on the literature and the proposed model.The model parameters are shown in Tab.5.With a slight improvement in the model parameters, the proposed model shows much better performance than the traditional LSTM model.Figs.2 and 3 present the confusion matrix of the proposed model(LC8).For CNN-based experiments, the audio samples are changed into spectrograms.The spectrograms are used as the input features for the networks.

Tab.4 Comparison of the experiment results on the literature and the proposed model %

Tab.5 Comparison of the model parameters in the traditional models and proposed models

AngerDisgustFearHappySadSurprise92.680.004.880.000.002.442.5689.745.130.000.002.560.006.9890.700.002.330.000.000.000.00100.000.000.002.220.000.000.0097.780.005.267.027.023.510.0077.19AngerDisgustFearHappySadSurprise

AmusementAnxietyIrritationDespairJoyPanicAngerInterestPleasurePrideReliefSadness81.820.000.009.090.009.090.000.000.000.000.000.0013.3326.6713.3313.336.6713.330.0013.330.000.000.000.000.004.1762.500.004.074.170.004.174.174.174.178.330.000.000.6733.3326.670.000.0020.006.670.000.006.675.000.0015.005.0045.005.005.005.0010.005.000.000.0011.760.0011.765.885.8864.710.000.000.000.000.000.000.000.000.0015.005.0010.0070.000.000.000.000.000.000.000.0010.000.0010.000.000.0050.0020.000.000.0010.000.000.000.000.000.000.000.006.6793.330.000.000.000.0014.290.000.004.760.004.764.769.5261.900.000.000.000.000.000.000.000.000.000.009.090.0081.829.090.0014.299.520.004.760.000.004.764.760.0014.2947.62Amusement AnxietyIrritationDespairJoyPanicAngerInterestPleasurePrideReliefSadness
Based on the results, the LSTM models show better performance than CNN networks on GEMEP and eNTERFACE corpus.The UARs of the models[7,22]are at least 10% lower than those of the LSTM models.Among all the models, the best UARs(90.4% and 59.0%)are achieved by the proposed model.Therefore, combining the multi-head attention mechanism along with multiple context vectors results in improvement, providing an effective method for SER tasks.
3 Conclusions
1)In this research, an MHTA weighting method is proposed to distinguish the salience regions of emotional speech samples.
2)To form the parts of the input of the full connection layer, the output of the feature-dimension attention layer and last time-step output are utilized.Moreover, feature-dimension attention is employed for the all-time output of the first LSTM layer to screen information for the fully connected layer input.
3)Evaluations are performed on the eNTERFACE and GEMEP corpora.The proposed model achieves the best performance for SER compared with the other models.The results demonstrate the effectiveness of the proposed attention-based LSTM model.
杂志排行

Journal of Southeast University(English Edition)的其它文章
- Graph-enhanced neural interactive collaborative filtering
- Path prediction of flexible needles based on Fokker-Planck equation and disjunctive Kriging model
- Mapping relationship analysis of welding assembly properties for thin-walled parts with finite element and machine learning algorithm
- Dependency-based importance measures of components in mechatronic systems with complex network theory
- Feasibility analysis of using biomass gas or hydrogen in the tobacco curing system
- Simulation analysis of significance and interaction of influencing factors on mixing uniformity of double-drum recycling mixing plant