一种基于多模态信息融合的火车司机疲劳驾驶检测方法
2022-07-12李小平
李小平,白 超
(兰州交通大学 机电工程学院,甘肃 兰州 730070)
火车司机是铁路行业非常重要的技术岗位,其值乘过程中的精神状态对于铁路运输安全至关重要,一旦疲劳驾驶造成事故,将会造成巨大的生命财产损失,因此对火车司机疲劳驾驶状态进行检测,对于保障铁路运输安全至关重要。
火车司机疲劳驾驶检测主要包括基于生理特征、视觉特征和语音特征的方法[1]。基于生理特征的疲劳检测由于需要使用昂贵的可穿戴设备,并且传感器的侵入可能引起司机不适,不便于普及推广[2];基于视觉特征的疲劳检测由于具有非接触性及可直接根据司机面部特征(如眼睛睁闭、点头低头、打哈欠等)反映其疲劳状态的优点,成为司机疲劳驾驶检测领域的一个重要研究方向[3],如类Haar特征和极限学习的疲劳检测[4]、基于MSP模型的多任务分层CNN疲劳检测[5]、深层级联LSTM疲劳检测[6]、基于TPOT的多特征融合疲劳检测[7]、基于深度学习的司机疲劳驾驶检测[8]等;基于语音特征的疲劳检测同样具有非接触式及成本低廉等优点,如基于语音迁移的疲劳检测[1]、基于支持向量机的运动疲劳检测[9]等。
上述研究主要针对单一语音模态或视频模态的疲劳状态检测,在实际应用中,基于视频的疲劳检测存在采集角度、光线变化及脸部遮挡等因素的影响[10],基于语音的疲劳检测存在噪声干扰[11]、数据维数高[1]、语音样本数据分布偏移导致的非平稳泛化误差[12]等问题,导致单一模态的检测手段往往误判率较高。由于我国铁路机车上安装的视频监控装置可以采集司机在值乘过程中的视频信号,司机在值乘过程中按司乘作业标准进行的呼叫应答语音信号也会被铁路机车呼叫应答装置[1]记录保存,因此在火车司机值乘过程中能够同时采集视频和语音两种模态的数据。为此本文提出一种基于多模态信息融合的火车司机疲劳驾驶检测方法,通过机车视频监控装置与呼叫应答装置采集司机视频信号与语音信号,采用多模态深度学习技术[13]实现视频与语音模态的疲劳检测,利用随机子空间算法(Random Subspace Method,RSM)[14]降低语音特征参数的维度,剔除模态间的冗余,减少系统耗时,采用串行结构的stacking集成学习模型[15]实现视频与语音模态之间的互补与融合,以长短期记忆网络(Long Short-Term Memory,LSTM)作为初级学习器,采用多折交叉验证(Cross-Validation, CV)提高非线性表达能力,降低泛化误差[16],以梯度提升决策树(Gradient Boosting Decision Tree,GBDT)作为次级学习器,最终实现司机疲劳状态的精准检测。
1 基于多模态信息融合的火车司机疲劳驾驶检测模型
基于多模态信息融合的火车司机疲劳驾驶检测模型见图1,采用stacking集成学习模型,由初级学习器和次级学习器组成,视频信号初级学习器采用LSTM1,语音信号初级学习器采用LSTM2,次级学习器采用GBDT。stacking集成学习模型可以堆叠任何分类器,具有很好的适应性,并且集成后的模型边界更加稳定,过拟合风险更低,提高了模型的非线性表达能力,降低了泛化误差。

图1 基于多模态信息融合的火车司机疲劳驾驶检测模型
图1中,视频监控装置和呼叫应答装置首先采集司机值乘过程中的视频和语音信号,预处理后分别生成视频和语音疲劳特征参数数据集,并分别将数据集划分为训练集和测试集;然后将训练集分别输入stacking初级学习器LSTM1和LSTM2进行训练,采用k折交叉验证(轮流将其中k-1份作为训练数据集,另1份作为验证数据集),训练好LSTM1和LSTM2后,再用测试集进行测试,视频疲劳检测的训练集、测试集输出结果softmax1和语音疲劳检测的训练集、测试集输出结果softmax2融合构成次级学习数据集;最后将次级学习数据集输入stacking次级学习器GBDT进行训练,最终得到司机疲劳驾驶状态的预测结果。对于高维语音数据采用RSM降维后生成m个随机子空间,分别导入m个LSTM2初级学习器进行训练,可以减少冗余并提高处理效率。
1.1 数据预处理
(1)视频数据预处理
根据脸部视频图像特征与疲劳相关性的最新研究成果[8],司机脸部的疲劳特征可通过fp、Kmouth、hdown及头部偏航角θyaw、俯仰角θpitch、滚转角θroll等6个参数来描述。其中fp为根据PERCLOS原则判断眼睛睁闭状态计算出的眼睛闭合时间占总时间的百分比;Kmouth为司机因打哈欠而嘴巴张开程度最大时的嘴部横纵比;hdown为司机因疲劳而低头(打盹)时低头时间占总时间的百分比;θyaw为司机摇头的角度;θpitch为司机点头的角度;θroll为司机头部旋转的角度。
首先,车载视频监控装置实时获取司机的视频关键帧图像,通过MTCNN[17]网络确定司机脸部区域,然后将检测出的人脸区域采用PFLD模型[18]进行人脸关键点检测,最后计算生成脸部视觉疲劳特征参数fp、Kmouth、hdown、θyaw、θpitch、θroll,按照时间帧序列t[t∈(t1,t2,…,tn)]生成司机脸部视频疲劳状态参数矩阵Xvideo,司机脸部视频数据预处理过程见图2。
图2中,fptn为tn时刻的fp,其他参数以此类推。
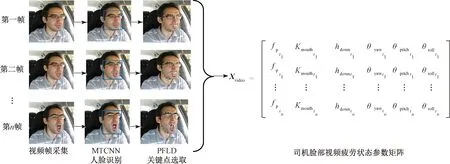
图2 司机脸部视频数据预处理过程
(2)语音数据预处理
首先将司机呼叫应答语音文件转换为没有文件头和文件结束标志的二进制pcm文件,便于运用python进行处理;然后采用Wiener滤波适用范围广的特点[19]滤除环境噪声;最后根据语音特征与疲劳相关性的最新研究成果提取语音疲劳特征参数[1],选取韵律、音质、语谱和非线性动力学4类特征来描述语音信号中所包含的疲劳信息,包括语速、短时能量、短时平均过零率、基音频率、基频微扰、振幅微扰、共振峰、梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient,MFCC)、最大Lyapunov指数、分形维数、近似熵等参数,构成司机语音疲劳特征参数Xvoice,如表1所示。

表1 司机语音疲劳特征参数Xvoice
(3)语音数据RSM降维
为了提高基分类器之间的差异性,从而提高组合分类器的性能,每个分类器构造的随机子空间特征子集合尽可能不同。将输入的80维特征参数构建出m个随机子空间,每个子空间都包含r(0 ζt=f[Xvoice,kζ(t)] ( 1 ) 将特征子集在训练集Xvoice上进行投影得到不同子空间上的训练数据集 Dt=MapζtXvoicet=1,2,…,m ( 2 ) 式中:Dt为不同子空间上的训练数据集;Map为将ζt在训练集Xvoice上进行投影;m为基分类器数。通过随机子空间的方法,将原本80维的语音数据降到r维,样本数量为r×m,样本维数小于原空间维数。 由于司机驾驶视频和语音信号是时间序列信号,因此stacking集成学习的初级学习器选用LSTM,通过基于时间序列的LSTM进行预测,视频信号初级学习器为LSTM1,语音信号初级学习器为LSTM2。由于初级学习器之间的差异性是影响融合分类器性能的重要因素,LSTM1的数据集为Xvideo,LSTM2的数据集为D1,D2,…,Dm,不同的数据集有效保证了LSTM1和LSTM2的差异性。在每个LSTM中, 输入门:it=σ(Wi×[ht-1,xt]+bi) ( 3 ) 遗忘门:ft=σ(Wf×[ht-1,xt]+bf) ( 4 ) ( 5 ) ( 6 ) 输出门:ot=σ(Wo×[ht-1,xt]+bo) ( 7 ) ht=ottanh(Ct) ( 8 ) LSTM关于火车司机疲劳状态的预测属于二分类问题(疲劳,非疲劳),其损失函数采用交叉熵损失函数L1,2,即 (9) (1)初级学习器LSTM1 将司机视频疲劳状态参数矩阵Xvideo分成k份,轮流将其中k-1份作为训练数据,另1份作为验证数据,按行输入LSTM1网络中,构成k折交叉验证LSTM1网络,见图3(其中Da1表示由视频训练集得到的疲劳参数矩阵k折交叉中的第1份,以此类推),再将验证数据的预测结果进行平均输出即可得到司机值乘状态下的视觉疲劳状态判断概率x11,x21,…,xz1(z为验证数据个数)。由于引入了k折交叉验证,使得模型的鲁棒性更强,在使用测试集时不进行k折交叉验证,选择在k折验证集上表现最佳的模型进行预测,从而提高预测效率和精度。 图3 k折交叉验证LSTM1网络 (2)初级学习器LSTM2 k折交叉验证LSTM2网络结构见图4,其中Db1表示语音训练集降维后得到的疲劳参数矩阵k折交叉中的第1份,其余以此类推。将RSM降维后的语音数据通过k折交叉验证的方式(方法同上)训练各个初级学习器LSTM2,k折交叉验证后的预测结果作为各个初级学习器的预测值,该预测结果取平均值即可得到司机值乘状态下的语音疲劳状态判断概率x12,x22,…,xz2。 图4 k折交叉验证LSTM2网络 LSTM1输出视频疲劳状态判断概率,LSTM2输出语音疲劳状态判断概率后,为了将LSTM1和LSTM2的模态数据进行融合从而使拟合能力更强,将初级学习器输出结果输入次级学习器GBDT中,实现对视频模态与语音模态的融合。LSTM1与LSTM2输出结果构成次级学习器GBDT的数据集Xz,即 (10) 式中:x11和x12分别为LSTM1和LSTM2的第一个输出值,构成第一个融合数据x1=[x11x12],其标签值为y1,其余参数以此类推。 GBDT是一种采用加法模型(以决策树为基函数的线性组合),通过不断减小训练过程产生的残差来达到将数据分类或者回归的算法。GBDT模型包含多轮迭代,每一轮迭代生成的基分类器在上一轮分类器残差(残差=真实值-预测值)基础上进行训练,然后不断去拟合上轮残差,并使残差朝梯度方向减小,最后通过多棵树联合决策(将所有迭代产生的模型相加)从而获得最终的预测模型,见图5。本文中以x11,x21,…,xz1作为第一特征,x12,x22,…,xz2作为第二特征,因此GBDT处理的是由z个样本x1,x2,…,xz构成的二分类问题(疲劳,非疲劳),其样本对应的标签(即真实值)yi(i=1,2,…,z)取值分别为1,0(1代表非疲劳,0代表疲劳),选择指数损失函数L(yi,c),GBDT的算法如下: 图5 GBDT模型 先对学习器f0(x)初始化 (11) 式中:c为使损失函数达到最小的常数;argmin为使后式达到最小值时变量的取值。 对于s=1,2,…,S,i=1,2,…,z,计算损失函数负梯度值作为残差的估计值 (12) 式中:f(xi)为运算到第i个数据时GBDT模型的预测值。 根据所有数据的残差rsi得到了一棵由J个叶节点组成的决策树,则其叶子节点区域为Rsj,j=1,2,…,J。对于每个节点的最优解为 (13) 式中:csj为最佳残差拟合值。 更新学习器fs(x) (14) 式中:I为指示函数,若x∈Rsj则I=1,否则I=0。 经过S轮迭代得到最终模型 (15) 式中:f(x)即为基于视频与语音的司机综合疲劳概率。 实验平台采用Intel(R)Core(TM)i5-4210,主频1.70 GHz,8 GB内存。在Windows10环境下使用Tensorflow深度学习框架,采用Adam优化器,stacking在python中使用mlxtend库来完成。 实验数据集使用某机务段在司机值乘过程中采集的司机监控视频数据集和呼叫应答语音数据集。数据集共有1 200个不同司机的驾驶数据,其中划分为1 000个训练数据,200个测试数据,训练数据集采用5折交叉验证(轮流将其中800个作为训练数据,另200个作为验证数据),专业技术分析人员对视频和语音数据中的司机状态进行了标记(疲劳、非疲劳)。 视频数据提取时,关键帧帧间距选择20 ms,帧长为320;语音特征提取时,选择语音采样频率为16 kHz,当帧间距选择20 ms时,则帧长为320,帧移取160,预加重系数α取0.98。 首先将每个脸部视频进行分帧,将关键帧的人脸照片输入MTCNN模型进行人脸定位,再将人脸区域输入到PFLD模型进行关键点标记即可得到所有关键帧照片的人脸关键点坐标,其中视频32(非疲劳).mp4中的第10关键帧图像的人脸关键点坐标及姿态角见图6。 图6 32(非疲劳).mp4第10关键帧图像人脸关键点坐标及姿态角 将视频数据集中同一视频图像关键点坐标按照参考文献[8]中的计算方法可计算出相应的疲劳特征参数,计算结果如表2所示(前10帧)。 表2 视频32(非疲劳).mp4疲劳参数计算表(前10帧) 2.2.2 司机呼叫应答语音数据疲劳参数采集 (1)语音读取及转换 读取mp3、wav等格式文件,其中将mp3利用ffmpeg工具包转换为pcm格式,wav利用wave工具包跳过包头直接将裸流的bytes数据按照二进制生成pcm文件。 (2)语音信号预处理 首先将每段语音分割成若干个短时帧,即对语音信号采用海明窗进行处理,再进行Wiener滤波去除环境噪声,海明窗尺度因子a为1、2、4、8、16,窗宽为32、64、128、256、512,手指口呼_呼叫应答1.mp3的疲劳特征参数预处理结果见图7。 图7 手指口呼_呼叫应答1.mp3语音信号预处理 (3)语音特征提取 将经过预处理的语音信号提取语音疲劳特征参数。首先对语音信号进行预加重,即将语音信号通过一个高通滤波器,预加重系数α取0.98,再将语音信号进行分帧处理,帧长为320,帧移取帧长一半为160,手指口呼_呼叫应答1.mp3的疲劳特征参数图像见图8,表3为手指口呼_呼叫应答1.mp3疲劳参数(前10帧)。 图8 手指口呼_呼叫应答1.mp3的疲劳特征参数图像 2.2.3 基于LSTM的stacking初级学习器 (1)LSTM1的视频数据集学习 将视频数据集中每个视频文件分解出100张关键帧照片,将检测出的疲劳参数输入LSTM1网络,其中将1 000个视频作为训练集,采用5折交叉验证,200个视频作为测试集,其中测试集不使用k折交叉验证,学习率为0.001,最后通过softmax1输出。 (2)LSTM2的语音数据集学习 ①RSM算法降低特征参数维度 选取初级学习器LSTM2的个数为5,r取40,每个子空间随机生成一个索引向量kζ(1),kζ(2),…,kζ(5),根据索引向量在Xvoice中产生5个40维向量子集ζ1,ζ2,…,ζ5,将ζ1,ζ2,…,ζ5在Xvoice上进行投影得到各个初级学习器LSTM2的数据集Dt=Mapζt(Xvoice)(t=1,2,…,5)。 ②LSTM2语音数据集学习 将每个呼叫应答语音文件提取的特征经过RSM降维后生成的数据集输入到LSTM2网络中,其中1 000个语音文件作为训练集,采用5折交叉验证,200个语音文件作为测试集,其中测试集不使用k折交叉验证,学习率为0.001,最后通过softmax2输出。 softmax1和softmax2输出结果汇总形成新的数据集,做为GBDT次级学习器的数据集,如表4所示。 表4 softmax1和softmax2输出结果 2.2.4 基于GBDT的次级学习器 GBDT数据集为softmax1和softmax2的输出,则训练集XT与测试集CP为 GBDT为黑箱模型,其参数设置为:基础树1 000棵,最大深度为5,决策树划分时的最小样本设置为2,学习率为0.001,GBDT预测结果如表5所示。 表5 GBDT预测结果 经过测试集200个数据测试,共计有6个数据分类有误,测试集准确率达到了97%。 2.2.5 实验过程伪代码 实验过程部分伪代码如下: (1)LSTM伪代码(以语音数据为例) Load data #RSM降维 Fori=1,2,…,z Fort=1,2,…,m randomkζ(t)∈Zr ζt=f(Xvoice,kζ(t)) Dt=Mapζt(Xvoice) End for End for #LSTM2 Fori=1,2,…,k#k折交叉验证 trainset=[1,2,…,z]-[i,i+1,…,z/k] Inputtrainsettotrain Inputi,i+1,…,z/kto validatei Outputi=average validatei End for [x12,x22,…,xz2]=Output1+Output2+…+Outputk (2)GBDT伪代码 Fors=1,2,…,Sdo: Fori=1,2,…,zdo: End for Forj=1,2,…,Jdo: End for End for 表3 手指口呼_呼叫应答1.mp3疲劳参数表 为了验证本文方法的先进性,将本文和文献[1,4-6,10]的方法进行对比实验,结果如表6所示。从文献[1,10]可以看出,目前单独对语音特征进行分析来判断疲劳状态的方法正确率不到90%,低于采用图像进行判断的方法[4-6],而采用图像和语音多模态融合后形成了语音和图像特征的互补,检测正确率达到了97.0%,比文献[10]的语音方法提高了7.4%,比文献[6]的视频图像方法提高了1.17%,有效提高了疲劳检测的正确率。本文所采用的方法为视频与语音的多模态融合,导致检测速度相比于文献[4-6]的方法慢了0.1~0.2 s,该时间以高速列车350 km/h的运行速度来计算行进9.7~19.4 m,占高速列车6 500 m紧急制动距离的0.15%~0.3%,对司机的应急反应和实施紧急制动影响不大。 表6 不同疲劳检测方法检测结果对比表 本文针对火车司机的驾驶疲劳检测问题,采用基于视频监控的图像特征以及司机呼叫应答的语音特征融合的方法,构建了基于多模态信息融合的火车司机疲劳驾驶检测模型,初级学习器采用LSTM,k折交叉验证,视频信号和语音信号分别进行处理,次级学习器采用GBDT,经过两级学习器后输出预测结果,疲劳检测正确率达到了97.00%。1.2 LSTM初级学习器




1.3 GBDT次级学习器

2 实验
2.1 实验环境及实验数据集
2.2 实验过程2.2.1 司机脸部视频数据疲劳参数采集
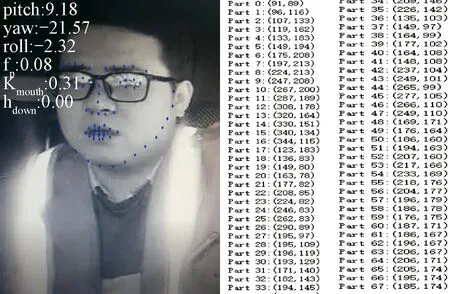
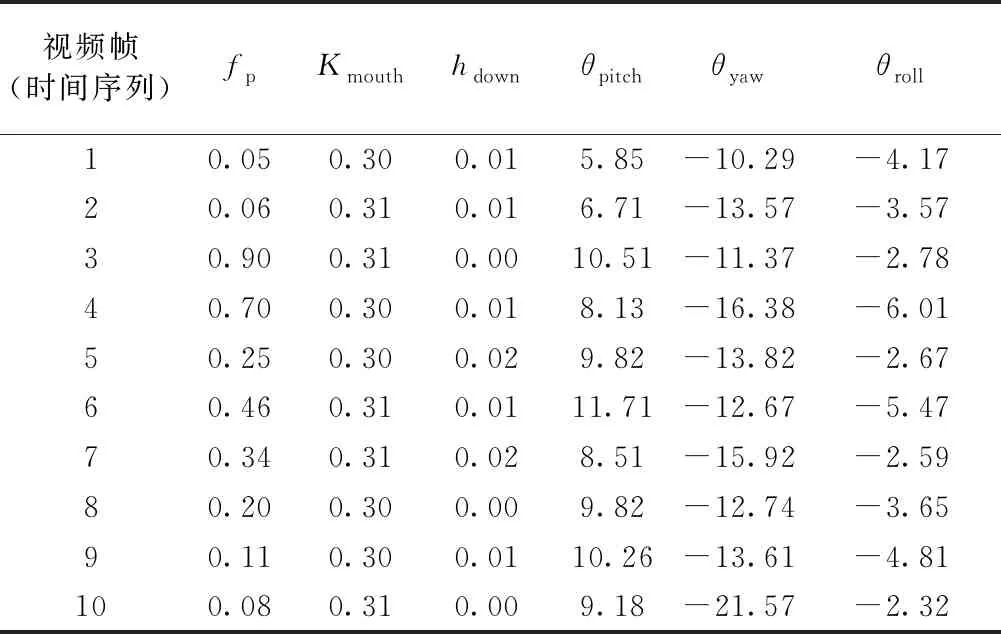





2.3 对比分析

3 结论
