铁路货车铸件DR图像的疏松缺陷快速检测
2022-07-12李小利曾理
李小利,曾理
(1.重庆大学 数学与统计学院,重庆 401331;2.重庆大学 工业CT无损检测教育部工程研究中心,重庆 400044)
作为铁路货车转向架中重要的组成部分,摇枕和侧架的质量影响着货车行驶时的安全[1]。在制造摇枕和侧架等铸件的过程中,铸件中可能产生多种类型的缺陷,如疏松、裂纹和气孔等,这些缺陷可能影响铸件内部质量。因此,缺陷检测和识别是必要的工作。在铸件出厂前,常采用无损检测法检测铸件内部缺陷,如超声、电磁和射线等检测方法。数字化X射线照相(Digital Radiography,DR)是一种射线检测方法,其主要特点是可以直接获取含有缺陷的图像,成像速度快,扫描铁路货车的一个铸件只需要2~3 min,适用于铸件的整体检测。目前,工业上对DR图像的缺陷检测和识别方法主要依赖于人工目测图像检测法。但由于铁路货车铸件DR图像像素较多(如摇枕或侧架的一幅DR图像像素达到五千多乘两千多),这种方法不仅耗时费力容易疲劳,而且依赖于检测人员的经验,不同的检测人员可能对同一缺陷有着不同的检测结果。人工检测法不利于实时检测数据庞大的DR缺陷图像集。因此,采用自动化检测方法实现DR图像缺陷的实时检测具有重要意义。当前铸件DR图像缺陷检测和识别的主要任务是确定缺陷存在的位置、缺陷的大小以及缺陷的类别。针对DR图像缺陷检测问题,大部分方法是基于图像处理的技术。赵亚丁等[2]通过改进Local Binary Pattern(LBP)算法,并结合参考缺陷数据库进行缺陷检测,相比原LBP算法,提高了DR图像缺陷检测率。刘玲慧等[3]在DR图像的缺陷检测中采用几何主动轮廓模型的方法,能够较好地检测出原DR图像中的缺陷。周鹏飞等[4]设计了一种基于中值滤波和灰度连通性的方法,实现了图像中可疑缺陷的自动检测。曾理等[5]通过计算图像的分形系数来确定缺陷的大致位置,再用Facet模型对定位区域进行边缘检测,从而能够确定缺陷的准确形状和位置。张静等[6]针对金属铸件外观缺陷检测存在的问题,研究了一种基于局部二元模式和局部图像方差强度的金属纹理表面缺陷检测方法,克服了金属材料光照不均匀的问题,对缺陷类型具有较高的鲁棒性。VALAVANIS等[7]提出了一种基于几何和纹理特征的射线图像缺陷检测和分类方法,通过考虑全局图像特征,能够捕获不同的感知区域。对于图像中缺陷的分类识别问题,吕瑞宏等[8]提出了一种基于主成分分析的SVM缺陷分类方法,能够提高准确率。周鹏等[9]使用SIFT算子来获取具有尺度旋转不变性的特征向量,并结合欧式距离相似性判定度量进行图像匹配,从而识别表面缺陷。曾理等[10]研究了一种基于DR图像多重快速分割的铸件提取方法。以上方法基本属于传统方法的改进,基于计算机技术的发展,许多研究者已经将深度学习神经网络方法应用于缺陷检测与识别的自动化。罗隆福等[11]提出了一种改进的SSD网络来对顶紧螺栓进行缺陷检测。蔡彪等[12]将Mask R-CNN神经网络应用于DR图像的缺陷检测与识别,得到了较好的检测识别效果。谷静等[13]采用基于深度学习的密集连接卷积网络算法,较好地提高了缺陷识别率。王宪保等[14]通过建立深度置信网络和利用BP算法微调网络参数的方法,能够比较准确且快速地进行缺陷检测。缺陷检测与识别属于深度学习中的实例分割任务,主流的2个实例分割方法是单阶段法与两阶段法。两阶段法主要代表为R-CNN系列,主要关注检测精度而非速度,不能达到实时的效果,如Faster R-CNN[15],Mask R-CNN[16](其第1阶段为提取候选的感兴趣区域)。单阶段法包括了YOLO系列,SSD[17],YOLACT[18],这些方法通过删除两阶段方法中的第1个阶段来达到提高速度的目的,并用其他方式来弥补损失的性能。DR图像中疏松缺陷形状复杂,可以分为树枝状、羽毛状和海绵状等,一个铸件的局部疏松缺陷可能是多种不同形状疏松缺陷的组合,这增加了检测识别的难度。针对铸件DR图像疏松缺陷的特点,本文发展了一种基于YOLACT网络的DR图像疏松缺陷检测与识别方法。基于原始DR图像的特点,首先对原始DR图像进行反相操作和窗宽/窗位调节,由于图像过大,采取了分割图像操作;再利用引导图像滤波以及分数阶微分对图像进行增强;最后采用标注软件Labelme[19]对图像进行标注,得到训练数据集。将训练数据集输入到YOLACT网络中,实现疏松缺陷的检测与识别,避免了人工检测的不一致性问题,实验结果验证了本文方法的有效性。
1 方法论述
1.1 图像预处理
由于铸件本身具有厚薄不均匀的特性,通过X射线扫描后,得到的原始DR图像灰度不均并含有噪声,而且缺陷和周边区域灰度值差异小,缺陷边缘部分模糊,缺陷细节不明显。因此,必须对图像进行预处理,使其显示缺陷区域。原始DR图像如图1所示。

图1 原始铸件DR图像Fig.1 Original DR image of casting
铸件原始DR图像的缺陷部分难以分辨,因此通过软件对原始DR图像进行反相操作,突出铸件本身,再对图像进行窗宽/窗位调节,使得缺陷区域能够暴露。为了让DR图像的边缘以及缺陷部分清晰明显,需要对图像进行增强。增强后的图像更容易进行标记,获取的训练数据更可靠。本文采用引导滤波结合分数阶微分的图像增强方法,引导图像滤波具有保边平滑作用[20]。此算法需要输入图像p,引导图像I,对p进行基于I的滤波操作,滤波后输出图像q中某像素点的值(像素值的范围为0~255),表示如下:
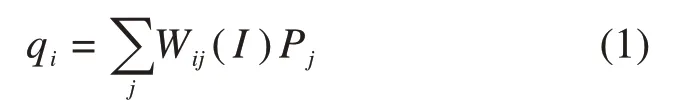
其中:Pj代表的是第j个像素索引的图像像素值;滤波核Wij(I)为引导图像I的权重函数,Wij(I)=Ii和Ij为引导图像中第i个和第j个像素索引的图像像素值;ωk为方形窗口;ω为窗口中所有像素的个数;μk和σk为窗口中所有像素的均值和标准差;ε为大于0的数。因此,将输入图像p与滤波后的输出图像q进行相减,得到图像的大致结构与细节,再结合输出图像q,得到利用引导图像滤波处理后的图像IG。其增强过程如图2所示。
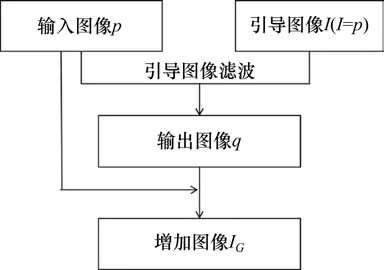
图2 引导图像滤波增强流程Fig.2 Flowchart of enhanced image of Guided Image Filtering
滤波过程中设置的引导图像与输入图像一致,滤波后的图像在低频区域会有纹理和细节丢失。因此,采用分数阶微分进行细节增强,由分数阶微分的Grumwald-Letnikov(G-L)定义出发,选取8个方向对图像进行微分运算,并构造一个5×5的分数阶微分算子[21]:

1.2 YOLACT网络
本文采用的深度学习网络是近年发展起来的YOLACT(You Only Look At CoefficienTs)网 络[18],该网络可用于实例分割。常用的实例分割网络几乎都是基于区域建议目标检测网络来产生感兴趣区域,从而进行分割与分类,但这一类网络计算开销大。同Mask R-CNN的构造相似,YOLACT网络在一个单阶段目标检测模型上增添一个掩码分支而形成,其依旧是一个单阶段法,且速度快。YOLACT网络结构中主要包括2个部分:1)利用全卷积网络(Fully Convolutional Networks,FCN)生成一系列原型掩码;2)在目标检测上添加预测掩码系数的头部。YOLACT网络将复杂的实例分割任务分解成2个并行的子任务,通过线性组合2个子任务的输出结果,以得到最终的结果。YOLACT网络结构如图3所示。
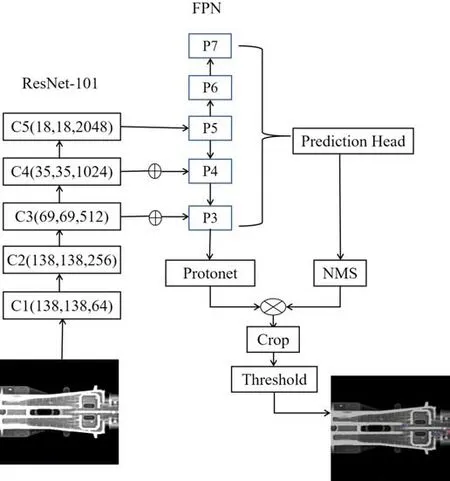
图3 YOLACT网络结构Fig.3 YOLACT network architecture
1.2.1 主干网络
YOLACT网络的主干网络由深度残差网络ResNet-101和特征金字塔网络(Feature Pyramid Networks,FPN)构成。将图像输入到ResNet-101,采取下采样的方式,得到5种不同尺寸的特征图,选取尺寸最小的3个特征图输入到特征金字塔网络中。特征金字塔网络可以检测图像中不同尺寸的目标,并利用浅层特征和深层特征提取出目标[22]。其不仅采用了图像金字塔的横向连接方式和深度卷积网络(Deep Convolutional Networks,DCN)自下而上的连接方式,且添加了自上而下的连接方式,因此可将低层特征与深层特征进行融合,得到不同尺寸的特征。FPN提取特征过程如图4所示。
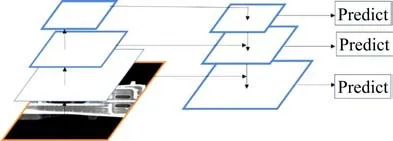
图4 FPN提取特征过程Fig.4 FPN feature extraction process
1.2.2 原型
在计算机视觉领域内,学习原型(又称词汇或码本)已经被广泛探究。在YOLACT网络中,原型生成分支可以预测整幅图像中的原型。原型生成结构如图5所示,其网络结构为FCN,其输入是特征金字塔网络中P3层的特征图,经过卷积层的作用,输出k个138*138的原型掩码。P3是经过ResNet-101中C3与特征金字塔网络处理后,得到尺寸最大的一层特征图,其保留了更多的浅层信息,更适用于逐像素的分割,并且从深层特征信息中可以产生更加鲁棒的掩码。在小目标中,高分辨率的原型能产生高质量的掩码。

图5 原型生成结构Fig.5 Prototype generation structure
1.2.3 检测模块
在预测阶段,基于锚的目标检测器一般包括分类层和回归层。在YOLACT网络中,预测分支不仅包括分类层和回归层,还包括掩码系数层。分类层输出缺陷的类别;回归层输出预测框结果(预测缺陷的位置);掩码系数层主要预测生成的K个掩码系数,每一个系数对应于每一个生成的原型。预测分支的结构如图6所示。特征金字塔网络中特征层Pi(i=3,4,5,6,7)的结果作为预测分支的输入,通过共享卷积层的方式得到3组数据:对每个锚点预测其所属缺陷类别、其预测(或称回归)框的坐标和掩码系数的预测。图6中C为训练数据集中缺陷的类别,a为特征图中锚点的数量,K为生成的原型个数。
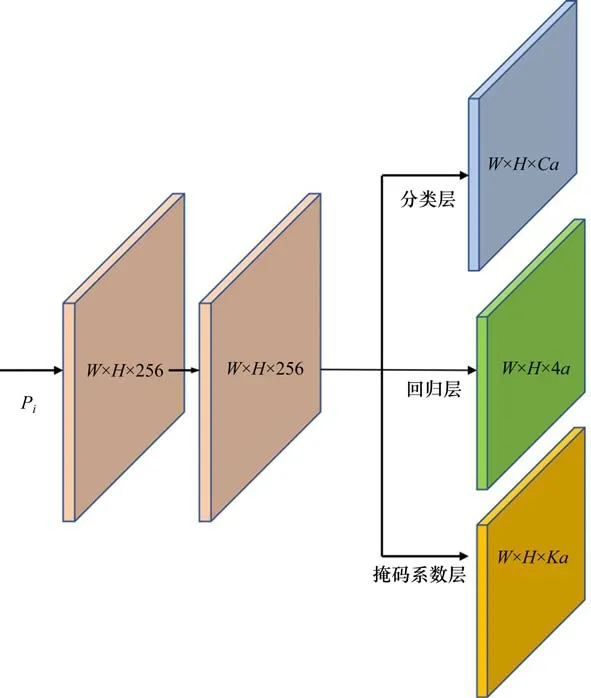
图6 预测分支Fig.6 Predicting branch
1.2.4 损失函数
在YOLACT网络框架中,为了生成最后实例掩码(掩码表示分割结果),结合原型分支和掩码系数分支,通过对以上2个分支的结果进行基本的矩阵乘法和Sigmoid函数作用,得到掩码:

其中:P表示原型模板的h×w×k矩阵;C表示经过非极大值抑制(Non-Maximum Suppression,NMS)处理和得分阈值化后保留的n个实例掩码系数的n×k矩阵。框架中,损失函数主要由3部分组成:

其中:Losscls,Lossbox和Lossmask分别表示分类损失函数、预测框损失函数和掩码损失函数;α和β为权重系数,分别取1.5和6.125。分类损失函数定义为交叉熵损失,预测框损失函数采用L1-smooth损失,掩码损失函数定义为预测掩码和ground truth(gt)掩码之间的逐像素二进制交叉熵:
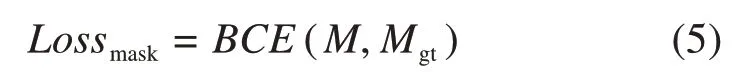
2 方法流程
在YOLACT网络的基础上,增加了引导图像滤波结合分数阶微分图像增强等图像预处理过程,方法流程如图7所示。对原始DR图像进行反相、窗宽/窗位调节和裁剪等预处理后,采用引导图像滤波结合分数阶微分的方法对图像的细节进行增强,采用标注软件Labelme进行标注得到训练数据集,输入到YOLACT网络中。训练数据集输入到残差网络ResNet-101,FPN的输入为ResNet-101的输出结果,FPN中P3层的特征图输入到FCN中,通过FCN向后卷积进行上采样,采用3×3大小的卷积核完成特征预测,并采用1×1大小的卷积核生成K个原型。另外,FPN的特征层的结果经过共享FCN得到分类、预测框和掩码系数。经过NMS和阈值化处理后,将保留的掩码系数与原型线性组合,并对组合结果使用Sigmoid函数,得到掩码,根据预测框结果裁剪掩码以保留原型中的小目标,形成最终的分类、预测框和掩码结果,从而达到缺陷检测与识别的目的。
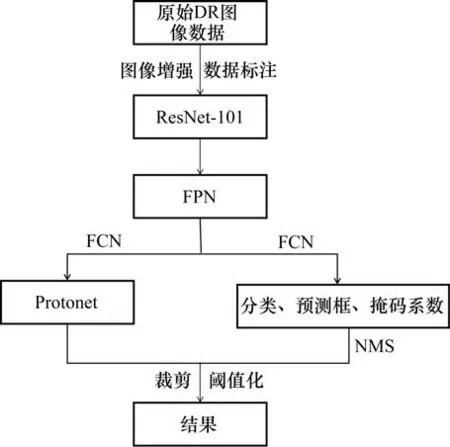
图7 方法流程Fig.7 Method flowchart
3 实验结果与分析
实验中,图像的大小统一为2 240*2 048像素,训练集为900张包含不同等级的疏松缺陷图像及其对应的标注数据集,测试集为100张包含不同等级的疏松缺陷图像。实验使用Pytorch深度学习框架,采用GTX1660显卡。
3.1 图像预处理结果
分别对未增强图像使用引导图像滤波和引导图像滤波结合分数阶微分进行增强,增强结果如图8所示。图8的局部放大图如图9所示。图9(a)中缺陷不明显,缺陷和背景的灰度差异小,难以辨别其缺陷的类别和等级。图9(b)可以看出缺陷虽然有所增强,但图像仍旧模糊,缺陷细节不够清楚。相比于图9(b),图9(c)中缺陷和背景的对比度得到提高。

图8 图像增强对比Fig.8 Image enhancement contrast
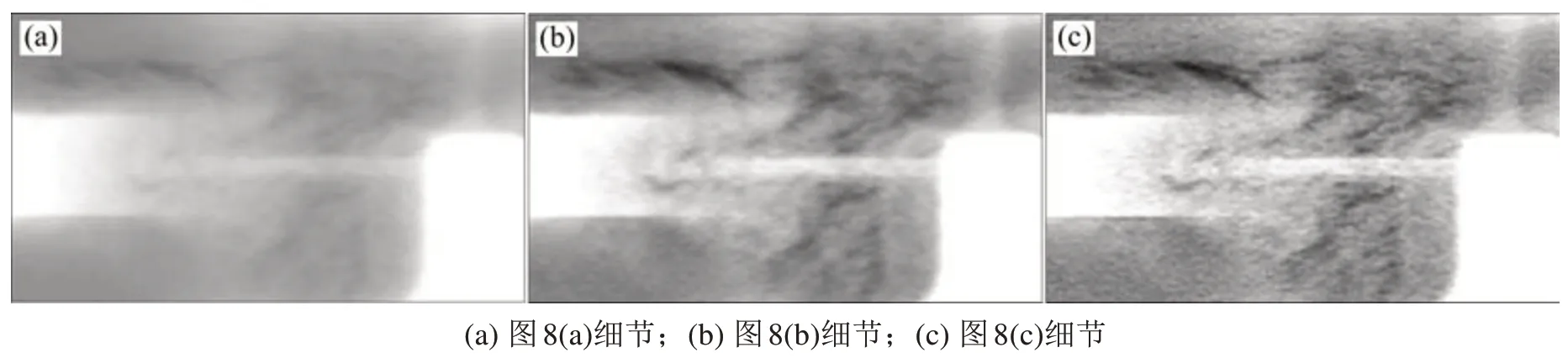
图9 细节放大对比Fig.9 Details zoom in and contrast
3.2 图像标注
基于以上实验,选取引导图像滤波结合分数阶微分的图像增强方法对铸件DR图像进行增强。增强图像后,利用标注软件Labelme对其标记疏松缺陷,标注的形式参考目标检测中COCO数据集的制作,得到训练数据集。本实验中,疏松缺陷分为5个等级,数字1~5表示缺陷等级,数字越大则缺陷等级越高,字母c表示疏松。缺陷的不同等级采用不同的颜色进行填充标注,对属于同一等级的多个缺陷在标记时添加尾缀-1,-2,…,以进行区分;若图中同一等级的缺陷只有一个,如c1,则可以不添加尾缀,Labelme标注过程如图10所示。标注完数据之后,在文件夹中生成对应的json文件,将每个json文件转换为COCO数据集格式,输入到YOLACT网络中进行训练。
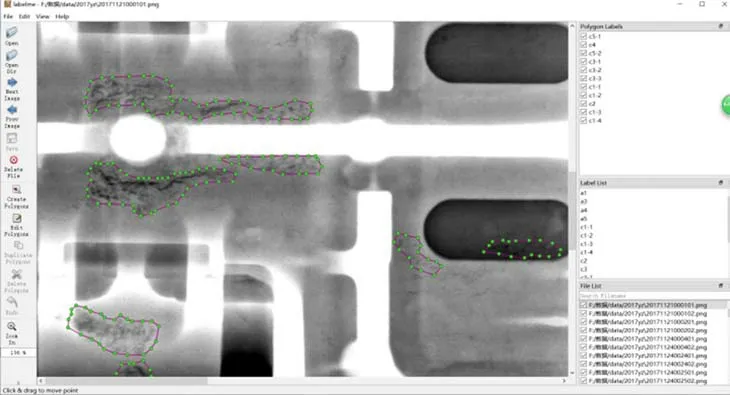
图10 Labelme操作界面Fig.10 Labelme operation interface
3.3 缺陷检测结果
3.3.1 网络训练结果
YOLACT网络在COCO数据集上训练得到预训练模型。在此模型上,本文训练了输入样本为900张包含疏松缺陷图像的YOLACT网络。网络参数设置:学习率为0.000 1,批量大小为3,最大训练步数为360 000步。在训练网络过程中,每隔10 000步将当前训练结果写入可视化工具Tensorboard的日志summary中。YOLACT在训练集上表现最好的检测结果见表1,Box表示所有类型疏松缺陷的预测框平均精度(Average Precision,AP),Mask表示所有类型疏松缺陷所生成的掩码的平均精度。由表1可知,基于YOLACT网络对DR图像中所有类型疏松缺陷的预测框和掩码的AP50达到82.63%和61.47%,其中APi(i=50,55,60,70)为检测结果与ground truth的交并比(Intersection over Union,IoU),其值大于等于i/100的平均精度,i越大,平均精度越低。
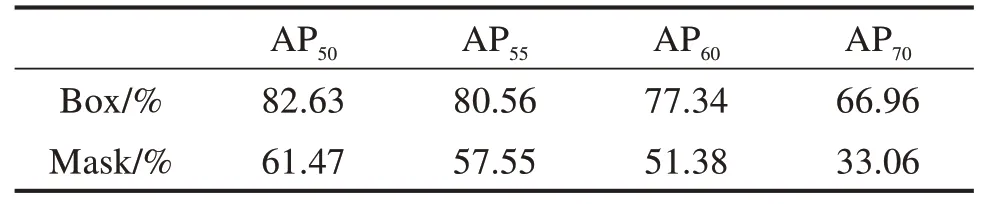
表1 训练检测结果Table 1 Training detection result
3.3.2 网络测试结果
YOLACT网络训练结束后,选取网络中训练最好的权重模型,在测试集上验证该模型的优劣。输入未标注的疏松缺陷图像进行测试,测试结果示例如图11所示。图11中不同等级的疏松缺陷能够被较好地识别,并且预测边界框可以较好地包围图像中存在的缺陷。图11的局部放大图如图12和图13所示,图中类别后的数字代表着置信度,置信度的范围为0~1,数字越接近1则代表越大可能为此类别。通过对比网络缺陷测试结果和依赖人工判定缺陷结果,可以发现二者的缺陷等级基本一致。测试结果表明该模型能够较好地识别缺陷等级,定位、分割缺陷。

图12 测试结果I局部放大Fig.12 Partially enlarged view of the detection result I
与人工判定结果对比,图11(a)和图11(b)漏检了疏松缺陷c3;图13(a)中将c3缺陷误检为c2缺陷,且预测框没有完全包围疏松缺陷;图13(c)中将不是疏松缺陷的部分误判为疏松缺陷c4。出现以上结果的原因有以下几种可能:1)人工标注疏松缺陷时,标注框没有完全贴合缺陷边缘;2)图像增强过程中,缺陷细节没有充分增强。
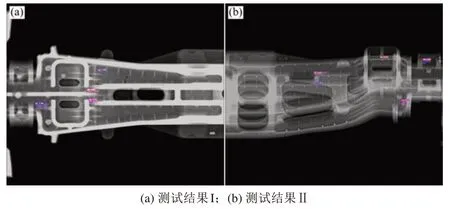
图11 YOLACT测试结果示例Fig.11 Example of YOLACT detection result

图13 测试结果II局部放大Fig.13 Partially enlarged view of the detection result II
在测试中,可以发现该方法检测速度快,单幅DR缺陷图像的平均检测时间为1.48 s,满足工业实时检测的要求。缺陷测试结果统计见表2,疏松缺陷的平均检测率为60.56%,疏松Ⅱ级及以上缺陷的检测率较高,疏松Ⅰ级缺陷的检测率有待提高。检测精度不高的原因包括缺陷的等级相近、灰度值差异小、形状复杂,需要进一步改进算法,提高缺陷的检测精度。总体上,引导图像滤波结合分数阶微分增强方法,再结合YOLACT网络,能对铸件疏松缺陷检测有较好的结果。
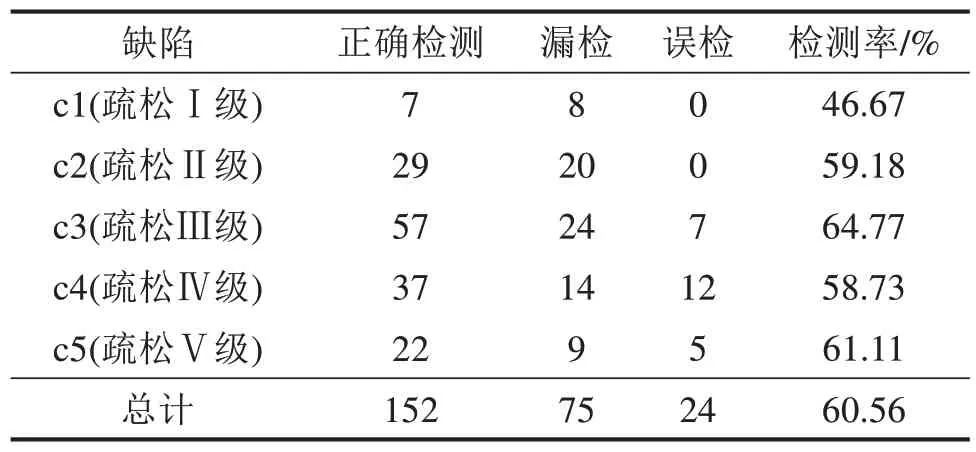
表2 缺陷测试结果统计Table 2 Statistics of defect test result
3.3.3 YOLACT结合引导图像滤波测试结果
作为和本文方法的一种对比,将使用引导图像滤波(未用分数阶微分)增强后的图像及其标注得到的数据集输入YOLACT网络中进行训练,得到的模型在相同的测试图上的检测结果如图14所示。图14(a)正确检测了c5和c4缺陷,漏检了c2和c3缺陷,误检c4缺陷;图14(b)仅检测出一个c4缺陷。表明输入图像的质量影响着训练结果和测试结果,分数阶微分方法可有效地提高输入图像的质量。
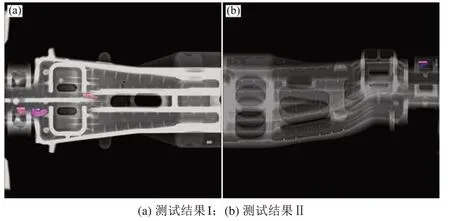
图14 YOLACT结合引导图像滤波检测结果Fig.14 YOLACT combined with guided image filtering detection result
4 结论
1)采用引导图像滤波与分数阶微分相结合的方法进行图像增强,能有效地暴露出疏松缺陷细节;采用标定样本训练网络,能较好地识别缺陷。
2)本方法实现了对DR图像的疏松缺陷的自动分类、分级及定位,能够达到实时检测的要求,并且检测速度快。但检测正确率仅有60%左右,还不能完全代替人工检测,可以作为一种辅助人工检测的手段,提醒检测人员铸件中可能存在缺陷的区域和可能的缺陷类型。由于铸件疏松缺陷形状复杂等因素,检测难度较大,因此可增加标记训练样本的数量,或者结合部分无监督网络,可以提高检测的正确率。
