融合标签和组推荐技术的评分预测算法
2022-07-12吴晓鸰
詹 彬 吴晓鸰 凌 捷
(广东工业大学计算机学院 广东 广州 510000)
0 引 言
推荐系统是继信息分类、搜索引擎之后解决信息过载的一项重要技术。推荐系统根据用户的历史数据来帮助用户从海量信息中筛选信息,减少所要处理的数据。用户的历史数据一般情况下有两种:一种是显式反馈的信息,比如用户的评分数据、评价等级等;另一种是隐式反馈,如用户的一些行为数据。目前推荐系统模型有很多,例如经典的协同过滤推荐模型[1]、基于知识或内容的推荐模型[2]、基于统计学的推荐模型、混合推荐模型、社会化推荐模型[3]和组推荐模型[4]等。
一些推荐算法[5-6]结合了用户的评分信息和用户之间的社交化信息来更为有效地为用户解决推荐和缓解用户信息过于稀疏的问题。现实中大多数情况下都是只拥有用户的购买或评分信息,而实验环境下才拥有用户的社交网络数据。通常大量的用户社交网络数据无法获取到。在没有用户社交数据的情况下如何提高推荐系统的有效性以及准确率是推荐系统中的一个重要问题。
在推荐系统中已经有很多人提出解决此类问题的方法,比如图论、降维等。在评分预测中,最为成功的还是奇异值分解,也就是矩阵分解技术。但是没有结合用户社交网络信息的矩阵分解技术不能有效解决数据稀疏的问题。由于数据稀疏,预测结果的误差到了一定程度就无法进一步缩小。本文提出融合标签和组推荐的概率矩阵分解方法(CTPMF),在概率矩阵分解的基础之上增加用户对物品打的标签数据再结合组推荐算法来进一步降低预测结果的误差,从而提高算法的有效性。
1 相关工作
1.1 概率矩阵分解
矩阵分解作为推荐系统中特别常用的一种技术,在现代推荐系统领域比较有影响力,常用于评分预测(rating prediction)和Top-N推荐中,常见的场景如用户的电影评分预测。
在矩阵分解的基础上,研究者提出各种改进方法,有BiasSVD、SVD++、timeSVD、NMF[6]等。还有人提出在原来的基础上增加用户的社交关系数据来提高预测准确率和可解释性,比如SoRec。本文提出的融合标签和组推荐的概率矩阵分解方法(CTPMF)是在概率矩阵分解算法的基础上[7]来改进的。PMF(Probabilistic Matrix Factorization)模型是假设用户隐特征矩阵、项目隐特征矩阵、评分矩阵均服从正态分布,如式(1)-式(3)所示。将待求解的子矩阵作为参数(如式(4)所示),并用最大似然估计求出子矩阵,即最小化式(5)。概率矩阵分解模型如图1所示。
(1)
(2)
(3)
(4)
(5)
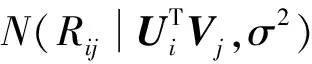
1.2 组推荐模型
在推荐系统领域,有越来越多的推荐服务涉及群体而不是个人。与个性化推荐系统不同,组推荐系统关注的是对某个群体的推荐。例如,电视节目的推荐FIT、TV4M,以及PolyLens和MusicFX音乐推荐等。组推荐技术关注整个用户群体的综合效果,本文方法(CTPMF)采用组推荐技术提取组成员的偏好来构造组偏好矩阵。计算用户群体偏好常见的方法有如下几种。
(1) 评分求和(Additive Utilitarian Strategy)。这个方法是将每一个用户对当前项目的评分都累加,求出最后的和(如式(6)所示),从而产生一组对所有项目的评分列表。
(6)
式中:Hc表示c产品的综合评分;Ruc表示成员u对c的评分。
(2) 评分相乘(Multiplicative Utilitarian Strategy):
(7)
1.3 基于标签的推荐
目前的推荐系统主要是通过三种方式去联系用户的兴趣和相对应的物品[8](如图2所示),一种是给用户推荐与用户喜欢过的物品相似的物品,也就是基于物品的协同过滤算法;第二种是基于用户的特征来对用户推荐符合用户特征的项目。最后一种是找到与用户兴趣最相似的用户,并将其喜欢的物品推荐给当前用户,也就是基于用户的协同过滤算法。

图2 推荐系统中联系项目与用户的几种途径
很多推荐系统算法也使用到了标签[9],如基于social tag、social bookmarking等。这些都可以反映物品或者用户之间的关系,还可以用于解决推荐系统当中的冷启动问题[10]。根据给项目打标签的人群,可大致将标签分为两种:一种是让作者或者专家打标签;另一种是让用户来打标签,即UCG(User Generated Content)。很多网站都有UCG标签系统,代表性的有Delicious、CiteULike、豆瓣等。
在推荐系统中,标签的作用很大。30%的用户认为标签系统表达了用户对物品的看法,23%的用户认为可以帮助推荐系统找到用户偏好,27%的用户认为可以增加对当前项目的了解,14%的用户认为可以辅助用户更快地找到自己喜欢的项目。
2 融合标签和用户聚类的评分预测
2.1 方法介绍及变量声明
本文方法(CTPMF)在基于传统PMF的基础之上,增加物品的标签数据和通过组推荐技术得到的偏好信息来对原有的PMF模型进行约束。“用户-标签”矩阵-F为每个项目被打上各种标签的次数。“用户-标签”矩阵一定程度上可反映用户对物品的划分。而“用户-类别”矩阵则可以反映出用户之间的关联关系。
“用户-类别”矩阵通过相似度计算获得。首先通过用户偏好计算用户之间的相似度,然后使用用户相似度对所有用户进行聚类并计算出每个类簇的用户的综合评分,再计算用户与每个类别的相似度得出“用户-类别”相似度矩阵。
本文方法的计算过程如下:
(1) 根据用户的评分来计算不同用户之间的相似度,从而得到相似度矩阵。
(2) 根据用户的相似度对用户进行聚类(一个类别的用户之间的相似度尽可能高,不同类别的用户的相似度尽可能低)。
(3) 计算每个类别的用户的偏好,得到“类别-项目”偏好矩阵。
(4) 计算出用户与每个类别的相似度,得到“用户-类别”相似度矩阵。
(5) 将“用户-类别”相似度矩阵与“项目-标签”矩阵添加到概率矩阵分解当中。
(6) 使用梯度下降寻找最优的预测参数。
变量说明如表1所示。
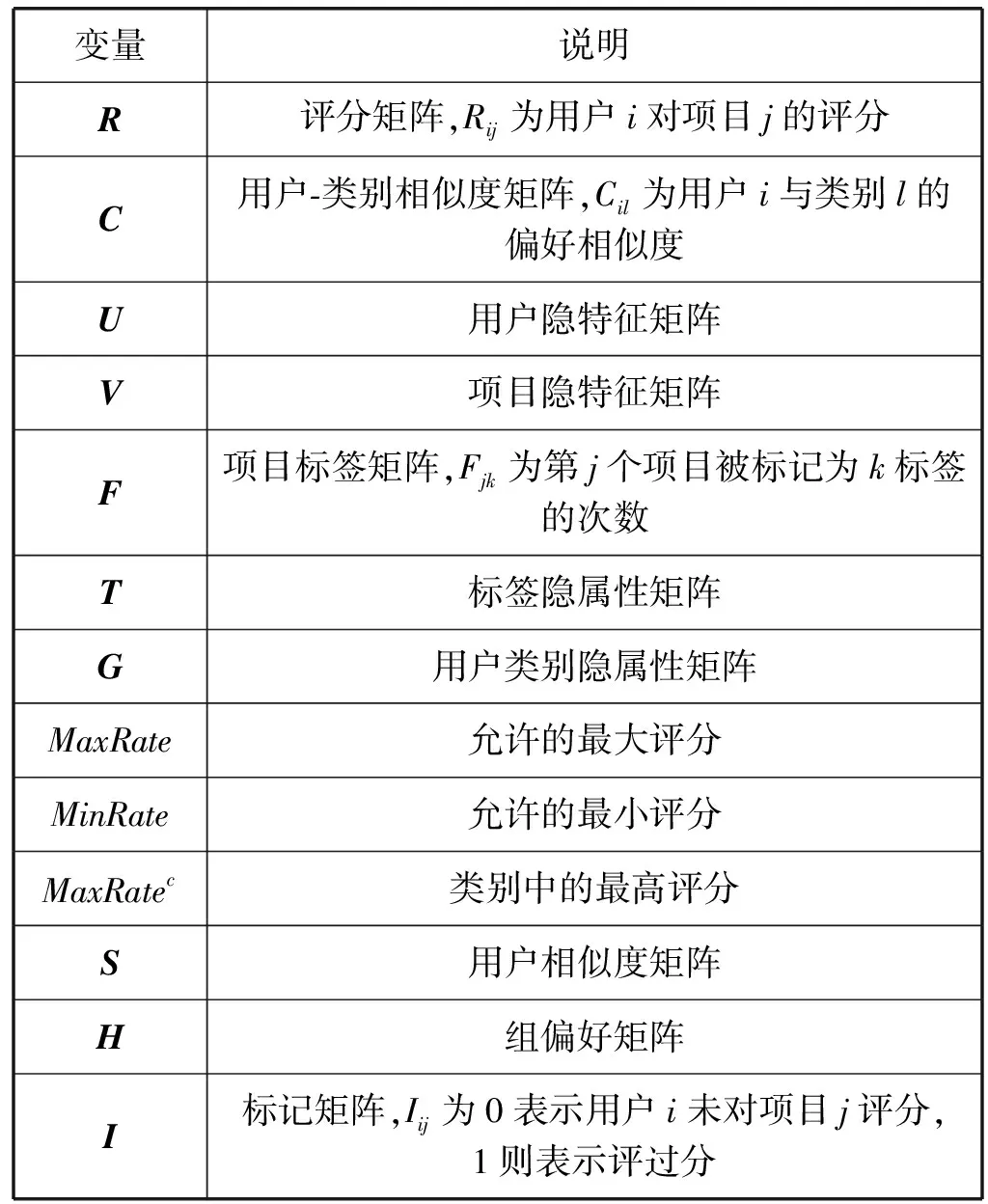
表1 变量说明
2.2 用户类别矩阵
(1) 用户相似度矩阵。在用户的聚类过程中需要用到用户之间的距离,可以使用用户的相似度来度量。由于每一个用户的评分习惯会不同,有的用户习惯给高分,有的用户则习惯给低分,比如用户A习惯给的评分范围是[3,5],而用户B的习惯评分范围是[1,3]。对于B用户来说,3分已经算比较好的评价了,而从用户A的角度来看,打3分基本算是很差的评价了。为了缓解这个问题带来的影响,本文方法(CTPMF)使用余弦相似度来计算用户之间的相似度(如式(8)所示)。
(8)
(2) 用户聚类。计算出用户之间的相似度之后,使用谱聚类算法对用户进行聚类。谱聚类算法可以基于用户的相似度来对所有的用户进行聚类,使得相似度较高的用户都被分到同一个类簇里面,相似度较低的用户分配到不同的类簇。谱聚类算法在处理一些大小不一和形状不一的数据时有较好的效果[11-13]。
定义G(V,E)表示用户之间构成的无向图(如图3所示)。V表示点的集合,图中的点表示每一个用户。E表示边的集合,边则表示用户之间有关联,用户之间的相似度作为边的权值Wij,即WijSij。谱聚类是要将用户之间组成的无向图划分为若干个无交集的子图。同一个子图里面的用户相似度尽可能高,而不同子图之间的用户相似度尽可能低。一般情况下谱聚类划分子图时使用到的损失函数为被子图截断的边(如连接U1、U5的边和连接U3、U4的边)的权重和(如式(9)所示),将这些边的权重和最小化即可。
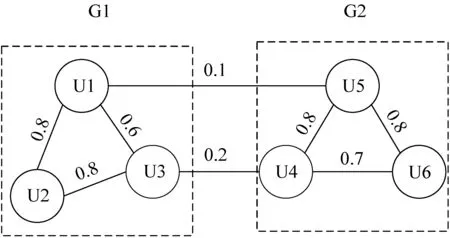
图3 谱聚类

(9)
p=[p1,p2,…,pn]
(10)
(11)
式中:p用来表示划分方案;根据pi的值来表示用户i被划分到哪一个类别。则损失函数可以写成如式(12)所示。图的划分问题就转化成pTLp的最小值问题。
(12)
计算过程如图4所示。其中需要使用到无向图的度矩阵D(度矩阵为对角矩阵,每个对角元素都表示所代表每个点(用户)在无向图中的度)、权值矩阵W(也就是用户相似度矩阵)、拉普拉斯矩阵L。
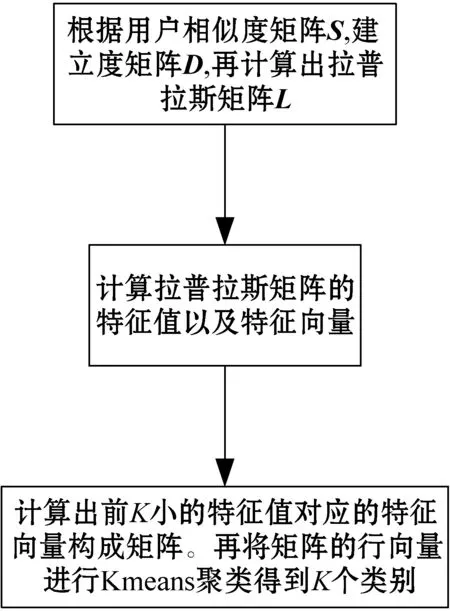
图4 谱聚类流程
(3) 计算每个类别的用户偏好。本文方法(CTPMF)用到用户的群体偏好来对概率矩阵分解模型增加约束,所以首先需要获取每个类别的用户群体的偏好,用到的方法是评分求和法(Additive Utilitarian Strategy),即:
(13)
通过每个类别的用户评分数据计算出类别的项目评分列表(如式(13)所示),由于得出的组偏好是当前类所有用户的评分之和,所以在此之前需要将矩阵中用户未评分的项目进行填充(如式(14)所示,Sil为上面所求的用户相似度)。
(14)
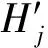
(15)
组偏好的计算过程如图5所示,其中U1、U2、U3为一个组的成员,首先根据用户与类别中其他用户的相似度填充每个用户的评分,然后通过评分求和计算组偏好,得出最终的组偏好矩阵。
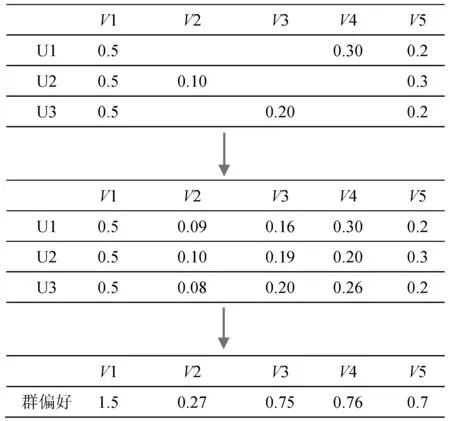
图5 群偏好计算过程示例
(4) 生成用户-类别矩阵。本文方法(CTPMF)将用户-类别矩阵作为概率矩阵分解模型的一个约束添加到模型中。让评分较少的用户的评分偏向于用户所在类簇的用户偏好。这里需要通过用户的偏好和每个类别的用户的群体偏好来计算出用户与每个用户群体之间的相似度(计算相似度依然是使用式(8))。矩阵每一个值是对应类别和用户的相似度。
2.3 加入用户类别矩阵与物品标签矩阵
PMF模型假设用户、项目、用户评分矩阵服从正态分布且相互独立(如图1和式(1)所示)。本文方法(CTPMF)在PMF基础上加入项目标签矩阵与“用户-类别”相似度矩阵之后的模型如图6所示。通过已有的评分矩阵R、C、F估算出所需要的U、V。最后只需最大化后验概率来求得最优解,也就是最小化式(18)。使用梯度下降来最小化能量公式,需要先对各个方向求偏导,如式(19)-式(22)所示,再将对应值按负梯度改变。(这里使用了Logistic函数将数据映射到(0,1)的区间来计算梯度,如式(23)、式(24)所示)。

图6 基于用户聚类与物品标签的概率矩阵分解模型

(16)
(17)
(18)
(19)
(20)
Fij)Vj+λTTk
(21)
Cli)Ui+λGGl
(22)
(23)
(24)
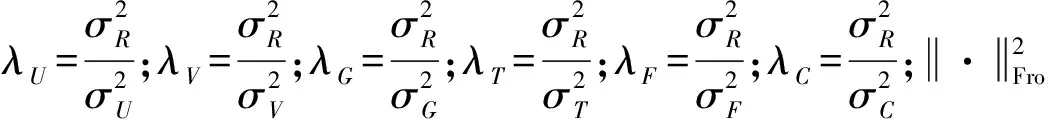
3 仿真实验
3.1 仿真实验数据
仿真实验采用的数据是由明尼苏达大学GroupLens实验小组提供的MoiveLens数据集[14]。数据集由两部分组成,分别包含100 835条用户评分数据和3 662条用户对电影打标签的数据。其中用户评分数据由评分用户id、被评分电影id、评分、时间戳组成,打标签数据由打标签用户id、电影id、标签、时间戳组成。数据集中包含610个用户、9 724部电影和1 589种标签。数据集中的用户评分为1分至5分,分数越高表示用户的对电影的评级越高。
3.2 评价指标
本文选取了平均绝对误差MAE(Mean Absolute Error)与均方根误差RMSE(Root Mean Square Error)作为预测结果的评价指标。RMSE可以用来衡量观测值同真值之间的偏差。MAE能更好地反映预测值误差的实际情况。下面给出MAE与RMSE的公式定义:
(25)
(26)
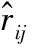
3.3 实验结果及分析
(1) 参数分析。这里将λu、λv、λg、λf、λc、λt设置为相同的值,测试参数对于预测误差的影响。该实验将参数分别设置为λ∈{0.1,0.3,0.8,2.0},比较使用这些参数分别在训练集比例ratio∈{20%,50%,80%}的情况下的效果。具体如图7-图9所示。
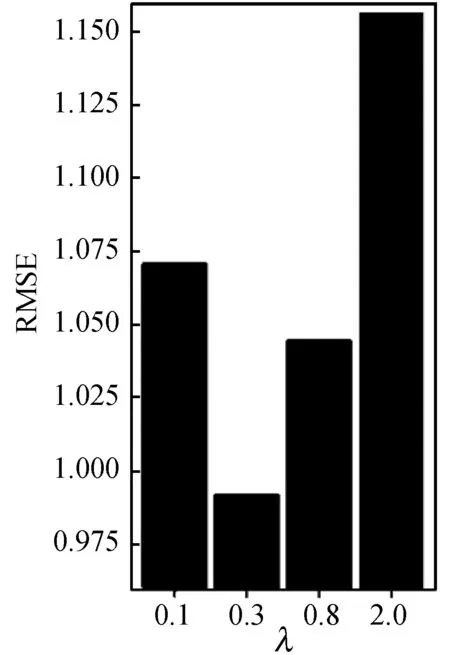
图7 训练集比例为20%下的参数比较结果

图8 训练集比例为50%下的参数比较结果

图9 训练集比例为80%下的参数比较结果
图7-图9展示了在不同比例的训练集下,本文方法(CTPMF)对于不同λ值的结果对比。可以看出,在λ值为0.3时在20%、50%、80%的数据作为训练集的情况下λ=0.3的结果优于λ=0.8与λ=0.1的结果,λ=0.8的结果优于λ=2.0的结果。
在基于矩阵分解的推荐算法中,潜在特征维度的大小对结果有一定的影响。潜在特征维度太小会导致潜在特征无法充分表示,而潜在特征维度过大则计算复杂度增大。本文分别在20%、50%、80%的数据作为训练集时比较潜在特征维度分别取Dimension=5,10,15,20的情况下的结果,如图10-图12所示。

图10 训练集比例为20%下的特征维度比较结果

图11 训练集比例为50%下的特征维度比较结果
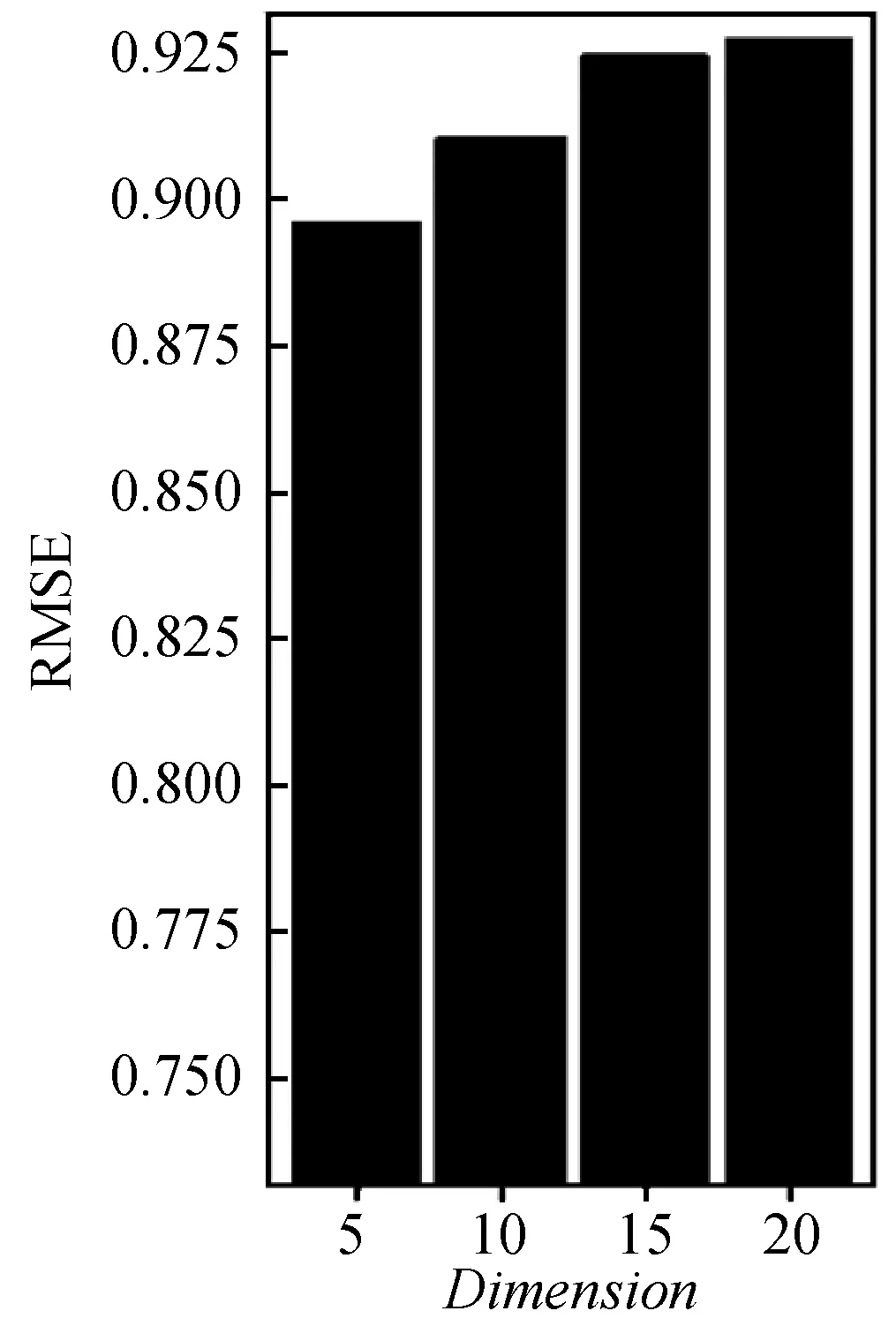
图12 训练集比例为80%下的特征维度比较结果
可以看出,在数据集的20%作为训练集的时候潜在特征维度为15和20的情况下结果较好。在数据集的50%作为训练集的时候潜在特征维度为5的情况下效果最好,其次是20,最后是10和15。在数据集的80%作为训练集的时候,潜在特征维度为5的情况下效果最佳,然后依次是10、15、20。可以看出在这三种比例的训练集中在潜在特征维度为5的情况下的效果较好。
本实验共选取了4种方法与本文方法(CTPMF)进行对比,包括PMF、CPMF、NMF(Non-negative matrix factorization)、SVD[15]。实验分别在潜在特征维度为5和10及训练数据集比例为50%和80%的情况下对比CTPMF与其他算法的RMSE和MAE。
如表2和表3所示,CTPMF在原来的概率矩阵分解的基础上增加了用户聚类以及用户的标签数据。实验结果表明,在50%和80%的数据作为训练集的情况下CTPMF预测结果的RMSE、MAE优于其他推荐算法,而RMSE和MAE均随训练集比例的增加而减小,潜在特征维度为5时的实验结果总体上优于潜在特征维度为10的实验结果。

表2 特征维度为5的结果

表3 特征维度为10的结果
4 结 语
本文提出的融合标签与组推荐技术的概率矩阵分解方法(CTPMF)通过用户之间的评分相似度来对用户进行聚类进而计算出用户与每个组的相似度并增加物品的标签数据进行概率矩阵分解,通过梯度下降逐渐降低误差对个人评分进行预测。CTPMF改善了因数据稀疏导致的预测结果误差无法进一步减小的问题,在不同比例的训练数据集下的多个指标均优于实验部分所提出的其他方法,进一步验证了CTPMF的有效性。而在未来的研究工作当中仍需进行更深层次的探索,研究更优的推荐模型。
