基于地球空间网格的基础地理信息数据库空间索引方法
2022-07-12王乃生庞晓峰勾会杰
王乃生 吴 鑫 庞晓峰 勾会杰
(1.自然资源部陕西基础地理信息中心 陕西西安 710054;2.西安市水利规划勘测设计院 陕西西安 710054)
基础地理信息是国家空间数据基础设施的重要组成部分,是国家信息化的权威、统一的定位基准和空间载体,是国家经济建设、社会发展和生态保护中不可或缺的基础性和战略性信息资源[1],具有通用性强、共享需求大、行业应用广泛等特点。随着社会经济的加速发展,一方面基础地理信息数据的动态更新和全面更新已逐步覆盖了各级比例尺,另一方面基础地理信息数据的数据量呈爆发式增长。
传统的基础地理信息数据库以关系型数据库为主,数据的空间检索主要借助空间关系运算和数据库索引来实现,对海量异构数据的检索效率低。如何科学、高效地管理基础地理信息数据库,提高海量异构数据的空间检索效率,进而提升地理信息数据库的管理能力,是业内学者一直关注的研究方向。
徐道柱等[2]提出了一种适应分布式环境下的分层+分块的矢量数据存储组织模型,实现了高并发条件下的数据高效访问;于亮和宋明明等[3-4]对基于R-树的空间索引技术进行了探讨,提出了一种改进型的R-树索引结构,在一定程度上提升了空间数据的检索效率;余冬梅[5]对空间索引及其发展分类、空间数据查询及其与传统关系数据库的区别进行了研究。这些研究从不同视角研究了空间数据索引,但并未提出针对基础地理信息数据库有效管理的完整解决方案。
地球空间网格[6]编码规则的提出为基础地理信息数据库的空间索引提供了一种新的思路。本文在研究地球空间网格编码规则等关键技术的基础上,设计了基础地理信息数据库的空间索引算法及对应的数据空间检索算法,以解决基础地理信息数据库的空间检索问题。
1 数据空间索引关键技术
1.1 地球空间网格编码规则
地球空间网格是为了满足地球空间区域位置结构化表达和统一标识,将地球空间剖分成不同尺度单元的空间参考系统。地球空间网格按照四叉树递归剖分方案,以地球参考椭球面、本初子午面与赤道面3个面的交点为起始位置,在经度(L)、纬度(B)和大地高(H)3个方向逐级递归二分,在地球参考椭球面形成地球表面剖分,加大地高方向形成立体剖分。
地球空间网格编码是为地球空间上的任意网格赋予唯一可识别的编码。地球空间网格编码采用四进制1位变长编码,编码顺序采用Z序进行,即每一级网格编码在上一级网格编码基础上采用Z序继续编码,将地球表面空间区域划分为32级的网格。
1.2 基础地理数据存储管理
基础地理信息数据库中的数据主要包括矢量数据、栅格数据、文档数据及元数据。矢量数据以空间数据集进行存储管理,地理要素都有相应的空间信息和属性信息;栅格数据以镶嵌数据集或文件形式进行存储,空间信息和属性信息管理主要通过对应的元数据来实现;文档数据以文件形式进行存储,空间信息和属性信息管理也是通过对应的元数据来关联实现。
1.3 空间关系
根据空间对象间的拓扑关系,多边形与网格的空间关系可归纳为以下3种:
1)相离关系,网格完全不在多边形内部;
2)相交关系,网格部分在多边形内部或多边形完全在网格内部;
3)包含关系,网格完全在多边形内部。
1.4 完全容纳数据的最小网格
空间索引是一种依据基础地理信息数据的位置、形状或空间实体之间的某种空间关系,按一定顺序排列的数据结构。基于地球空间网格实现基础地理信息数据的空间索引,就是以地球空间网格的方式重新组织基础地理信息数据的位置,建立数据和网格的关系,为数据库的高效检索提供支撑。
能够完全容纳数据的最小网格,是建立数据和网格关系的一种直观有效的方式。对于矢量数据,其数据内容由一个个地理要素构成,当地理要素的最小外接矩形与第m级网格的相交个数为1、与第m+1级网格的相交个数大于1时,则认为第m级网格是能够完全容纳当前要素数据的最小网格。对于通过元数据进行管理的栅格数据和文档数据,可将元数据的范围看作是一个面要素,按矢量数据中的面要素计算最小网格。
2 数据空间索引算法
基于地球空间网格实现基础地理信息数据的空间索引,实际上就是计算数据对应的最小网格并进行编码的过程。计算完全容纳数据的最小网格算法流程为:
第1步:根据要素实体的左、右、上、下经纬度坐标和所在空间区域,计算上下纬度和左右经度坐标差dL、dW,若dL大于dW,则将dL作为长边、dW作为短边,得到要素实体的最小外接矩形。
第2步:若dL的边长小于某一级网格边长Dm且大于下一级网格边长Dm+1,则可确定描述该要素实体对应的网格层级为m。
第3步:若数据所在空间范围的最小外接矩形与第m级网格的相交个数为1,与第m+1级网格的相交个数大于1时,则认为第m级网格是能够完全容纳当前数据的最小网格。
第4步:若最小外接矩形与第m级网格的相交个数大于1,则m=m- 1,继续第3步。
第5步:若最小外接矩形与第m级网格的相交个数等于1,则m=m+ 1,继续第3步。
在计算最小网格时会存在一些同时跨越多个网格的数据,如果跨网格数据采用最小网格作为其所在的空间网格,则这些数据最小网格的层级过高,不利于后续数据检索。因此,需要对这些跨网格数据进行特殊处理,选择与跨网格数据相交的指定层级的网格作为这些数据所在的空间网格。为了判断数据是否为跨网格数据并确定其所在空间网格的层级,设计算法流程为:
1)获取数据外接矩形的左下角点PLB和右上角点PRT。
2)获取PLB和PRT坐标(X,Y)的整数值(XLB,YLB)和(XRT,YRT)。
3)若XRT-XLB>0或者YRT-YLB>0,则认定该数据是跨网格数据;反之,则进行下一步判断。
4)根据外接矩形的长边计算跨网格数据所在的层级m。
5)根据最小网格算法计算跨网格数据最小网格所在的层级n。
6)若m-n≥4,则认定该数据是跨网格数据;反之,则不是跨网格数据。
7)m为该数据所在空间网格的指定层级。
计算数据所在地球空间网格后,按照地球空间网格编码规则计算空间网格的编码,如果数据所在的空间网格有多个,则以“,”作为分隔符,以“编码1,编码2,…,编码n”的格式进行编码。
3 数据空间检索算法实现
基于地球空间网格建立的空间索引进行数据空间检索时,需要自顶向下逐级判断多边形检索范围以及与不同级别网格的空间关系,最后计算多边形范围内相应的地球空间网格,算法实现如图1所示。
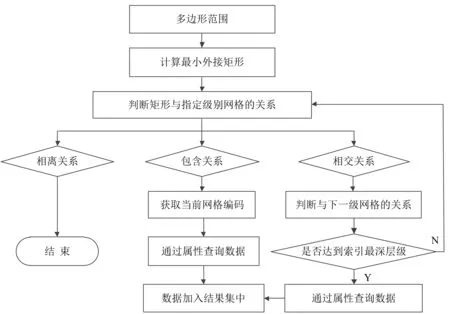
图1 空间检索流程
由图1可知,当多边形与网格为相离关系时,该网格及其子网格均被过滤掉。当多边形与网格为相交关系时,该网格则需要递归判断其子级网格与多边形的关系,直至其子级网格被多边形包含或网格级别达到空间索引时计算的网格最深层级。当多边形与网格为包含关系时,多边形与该网格及其下级网格中的数据均为包含关系。
计算多边形检索范围对应的地球空间网格后,需要根据不同的空间关系进行相应的属性查询。
首先,当多边形与网格为包含关系时,由于网格编码之间存在上下级关系,即网格第n+1级网格编码的前n位是上一级网格的编码,因此在定位具体数据时,通过属性查询只需查找到前n位编码相同,即可查找到该网格及其所有下级网格中的数据。
其次,当多边形与网格为相交关系时,只需要定位网格对应的每个数据。如查找交叠的m级,其网格编码为s的网格a中的数据,将查询条件设为“位置编码=s”,通过属性查询查出的数据即为m级网格a中的数据。为验证上述算法,选取陕西省某区域的1∶10 000 基础地理信息要素和地理国情要素数据进行了数据试验,同时,基于地球空间网格的空间索引编码,对比测试了基于地球空间网格空间索引后的空间检索与传统空间检索的效率,试验数据统计信息见表1。

表1 空间检索统计信息Tab.1 Statistics Data in Spatial Retrieval图层名称要素/个检索结果/个传统空间检索时间/s基于网格的检索时间/s 效率比/%CPTP2 2659700.130.121.04HFCL35 34812 6460.490.421.17LFCL385 945124 4984.972.641.88RESP397 22876 2103.142.051.53LRDL705 18514 5400.780.810.96VEGA831 041358 23637.148.644.30LRDA7 5872 2210.340.331.04UV_SFCP22 7422 4810.260.261.00UV_HYDL122 4415 2950.690.421.64UV_HYDA32 8183 5250.640.401.61UV_LCRA7 190 715387 57340.6314.922.72
从表 1可知,基于地球空间网格空间索引的空间检索时间与传统空间检索时间相比,在所有图层其效率均高于传统空间检索,检索效率平均提升1.5倍,部分图层可提升4倍以上。
4 结 语
本文提出的基于地球空间网格的基础地理信息数据库空间索引方法,可以在不改变已有数据模型和存储模式的基础上,快速为已有的基础地理信息数据库构建扩展索引,大幅提升了空间数据的检索效率。
本文的研究成果已在陕西省基础地理信息数据库中得到应用,与传统的空间检索方法相比,检索效率平均提升1.5倍,部分图层可提升4倍以上。
