大数据批处理技术研究
2022-07-11章昱钟茂生童维勤严伟安
章昱 钟茂生 童维勤 严伟安
(1.江西师范大学计算机信息工程学院 江西省南昌市 330027 2.上海大学 上海市 200444)
大数据的批处理技术应用于大规模静态数据集的离线计算和处理,架构设计的初衷是为了解决大规模、非实时数据计算,以吞吐量大为显著特征。在大数据批处理技术包括两种计算模型:MapReduce 计算模型和DAG 模型。
1 MapReduce计算模型
MapReduce 的设计理念是“计算向数据靠拢”,而不是“数据向计算靠拢”。MapReduce 将复杂的、运行于大规模集群上的并行计算过程高度地抽象到了两个函数:Map()和Reduce()。使用简单的编程接口,不需要掌握分布式并行编程细节,可以很容易的将自己的程序运行在分布式系统上,完成海量数据的计算。
1.1 MapReduce编程模型
MapReduce 编程模型的示意图如图1 所示。其中,Map操作是对一部分原始数据进行对应的操作,每个Map 操作都针对不同的原始数据,因此Map 与Map 之间是相互独立的,这使得他们可以充分的并行化。Reduce 操作是对每个Map 所产生的一部分中间结果进行合并操作,每个Reduce所处理的Map 中间结果是互不交叉的,所有Reduce 产生的最终结果经过简单连接就形成了完整结果集。

图1:MapReduce 编程模型示意图
开发者只需要编写两个函数:
Map(in_key , in_value) -> {( key, value) | j = 1 , … , k };
Reduce(key , [ value1 , … , valuem ]) -> ( key , final_value);
Map 的输入参数:in_key 和in_value,它指明了Map 需要处理的原始数据,Map 的输出结果:一组< key , value >对,这是经过Map 操作后所产生的中间结果,用于后续Reduce的输入。Reduce 的输入参数:(key , [ value1 , … , valuem ]),此操作是对这些对应相同key 的value 值进行归并操作,Reduce 的输出结果:( key , final_value ),所有Reduce 的结果并在一起就是最终结果。
下面用一个简单的实例来对MapReduce 的编程模型进行讲解。
假定给出了10 万本长篇英文小说的文字,如何统计每个字母出现的次数?这个问题看似简单,但是如果使用传统的数据处理方式,在单机环境下想要快速的进行统计还是需要一些技巧的,主要原因是数据规模巨大,导致的处理速度慢和运行内存不足。MapReduce 计算模型下实现这个功能很简单直观,只要完成Map 和Reduce 操作的业务逻辑即可。这个任务对应的Map 操作和Reduce 操作如表1 所示。

表1:Map 操作和Reduce 操作
1.2 MapReduce模型工作原理
MapReduce 模型工作原理如图2 所示,其最初设计方案是将MapReduce 模型运行在由低端计算机组成的大型集群上。集群中每台计算机包含一个工作节点(Worker)、一个较快的主内存和一个辅助存储器。其中,工作节点用于数据的处理;主内存用于暂存工作节点的输出数据;辅助存储器组成了集群的全局共享存储器,用于存储全部的初始数据和工作节点的输出数据,并且计算机之间可以通过底层网络实现辅助存储器的同步远程互访。

图2:MapReduce 计算架构工作原理图
由图2 可知,一个MapReduce 作业是由Map 和Reduce两个阶段组成,每一个阶段包括数据输入、计算处理和数据输出三个步骤。其中每一个阶段的输出数据被当作下一阶段的输入数据,而且只有当每一个计算机都将它的输出数据写入共享存储器并完成数据同步后,计算机才可以读取它前一个阶段写入共享存储器的数据进行数据互相访问。除此方式以外,各个计算机之间不存在其他的数据交互方式(主节点Master 除外)。
1.3 MapReduce模型的优缺点
1.3.1 优点
(1)硬件要求低,MapReduce 模型的设计是面向由数千台中低端计算机组成的大规模集群,并能够保证在现有的异构集群中运行;
(2)接口化,MapReduce 模型通过简单的接口实现了大规模分布式计算的自动并行化,屏蔽了需要大量并行代码去实现的容错、负载均衡和数据分布等复杂细节,程序员只需关注实际操作数据的Map 函数和Reduce 函数;
(3)编程语言多样化,MapReduce 模型支持Java、C、C++、Python、Shell、PHP、Ruby 等多种开发语言;
(4)扩展性强,MapReduce 模型采用的Shared-Nothing结构保证了其良好的伸缩性,同时,使其具有了各个节点间的松耦合性和较强的容错能力,节点可以被任意地从集群中移除,几乎不影响现有任务的执行;
(5)数据分析低延迟,基于MapReduce模型的数据分析,无需复杂的数据预处理和写入数据库的过程,而是直接基于平面文件进行分析,这种移动计算而非移动数据的计算模式可以将分析延迟最小化。
1.3.2 缺点
(1)无法达到数据实时处理,MapReduce 模型设计初衷是为解决大规模、而非实时数据问题,因此在大数据时代,MapReduce 并不能满足大数据实时处理的需求;
(2)程序员负担增加,MapReduce 模型将文件存储格式的设计、模式信息的记录以及数据处理算法的实现等工作全部交由程序员完成,从而导致程序员的负担过重;
(3)I/O(Input or Output,输入输出)代价较高,MapReduce 的输入数据并不能“贯穿”整个MapReduce 流程,在Map 阶段结束后数据由内存写入本地存储,Reduce 阶段的输入数据需要从本地存储重新读取,这种基于扫描的处理模式和对中间结果步步处理的执行策略,导致了较高的I/O代价。
2 DAG模型
MapReduce 虽然解决了批处理领域中的部分需求,可是它也存在或多或少的局限性,比如I/O 代价较高。为了弥补这些不足,行业中衍生出了另一类基于DAG(Directed Acyclic Graph,有向无环图)计算模型的大数据计算架构。DAG 是数据结构领域的概念。在大数据领域,DAG 计算模型往往指将计算任务在内部分解为若干个子任务,这些子任务之间由逻辑关系或运行先后顺序等因素被构建成有向无环图结构。
本节将以Spark 计算架构为例,介绍在批处理领域中DAG 模型的工作原理。DAG 是在分布式计算中非常常见的一种结构,因为其通用性强,所以表达能力自然也强。比如前面介绍的MapReduce 计算模型,在本质上是DAG 模型的一种特例。
2.1 Spark运行架构
Spark 运行架构如图3 所示,其中包括集群资源管理器(Cluster Manager)、运行作业任务的工作节点(Worker Node)、每个应用的任务控制节点(Driver)和每个工作节点上负责具体任务的执行进程(Executor),资源管理器可以用自带的、Mesos 或YARN。
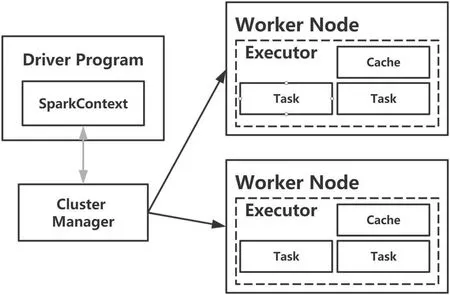
图3:Spark 运行架构图
(1)Application:用户编写的Spark 应用程序;
(2)Driver:Spark 中的Driver 即运行上述Application的main 函数并创建SparkContext;
(3)Cluter Manager:指的是对集群进行资源管理的外部服务。
(4)Executor:是运行在工作节点(Worker Node)的一个进程,负责运行Task;
(5)Task: 运行在Executor 上的工作单元;
(6)RDD(Resillient Distributed Dataset,弹性分布式数据集):分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型;
(7)Job:一个Job 包含多个RDD 及作用于相应RDD上的各种操作;
一个Application 由一个Driver 和若干个Job 构成,一个Job 由多个Stage 构成,一个Stage 由多个没有Shuffle 关系的Task 组成,包含关系如图4 所示。
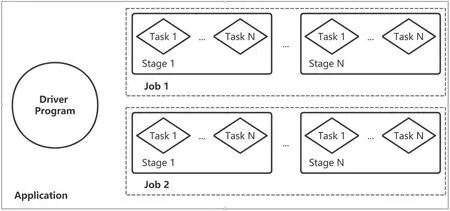
图4:Application 结构图
当执行一个Application 时,Driver 会向集群管理器申请资源,启动Executor,并向Executor 发送应用程序代码和文件,然后在Executor 上执行Task,运行结束后,执行结果会返回给Driver,或者写到HDFS 或者其它数据库中。
与MapReduce 计算架构相比,Spark 所采用的Executor有两个优点:
(1)利用多线程来执行具体的任务减少任务的启动开销;
(2)Executor 中有一个BlockManager 存储模块,会将内存和磁盘共同作为存储设备,有效减少IO 开销。
2.2 Spark运行流程
Spark 的运行基本流程图如图5 所示。分为以下4 步进行解释:
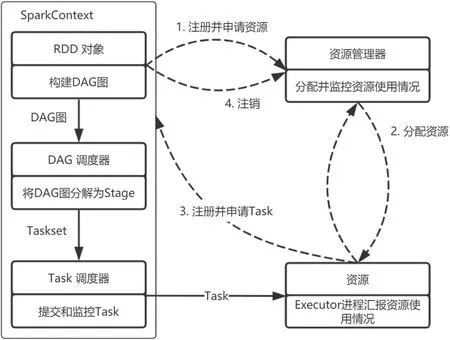
图5:Spark 运行的基本流程图
(1)首先为应用构建起基本的运行环境,即有Driver创建一个SparkContext,进行资源申请、任务分配和状态监控;
(2)资源管理器为Executor 分配资源,并启动Executor 进程;
(3)SparkContext 根据RDD 的依赖关系构建DAG 图,DAG 图提交给DAG Scheduler 解析成Stage,然后把一个个TaskSet 提交给底层调度器Task Scheduler 处理;Excutor向SparkContext 申请Task,Task Scheduler 将Task 发放给Executor 运行,并提供程序代码;
(4)Task 在Excutor 上运行,把执行结果反馈给Task Scheduler,然后反馈给DAG Scheduler,运行完毕后写入数据并释放所有资源。
总体而言,Spark 运行架构具有以下特点:
(1)每个Application 都有自己专属的Executor 进程,并且该进程在Application 运行期间一直驻留,Executor 进程以多线程的方式运行Task;
(2)Spark 运行过程与资源管理器无关,只要能够获取Executor 进程并保持通信即可;
(3)BlockManager 将中间数据存储于内存或磁盘,实现缓存机制;
(4)Task 采用了数据本地性和推测执行等优化机制。
2.3 RDD之间的依赖关系及Stage的划分
RDD 依赖关系,也就是有依赖的RDD 之间的关系,比如RDD1——>RDD2(RDD1 生成RDD2),RDD2 依赖于RDD1。这里的生成也就是RDD 的Transformation 操作。
RDD 之间的依赖关系分为窄(narrow)依赖(如图6 (a)所示)和宽(shuffle/wide)依赖(如图6(b)所示)。窄依赖表现为一个父RDD 的分区对应于一个子RDD 的分区,或多个父RDD 的分区对应于一个子RDD 的分区。宽依赖则表现为存在一个父RDD 的一个分区对应一个子RDD 的多个分区。

图6:RDD 依赖关系图
Stage 是Job 的基本调度单位,一个Job 会分为多组Task,每组Task 被称为Stage,或者也被称为TaskSet,代表一组关联的,是相互之间没有Shuffle 依赖关系的任务组成的任务集。
Stage 的划分主要有三大原则:
(1)将窄依赖的RDD 归并到同一个Stage 中;
(2)将宽依赖的RDD 前后拆分为两个Stage,前一个Stage 写完文件后,下一个Stage 才能开始;
(3)进行Action 操作时,相关RDD 会归并在同一个Stage 中,这个Stage 称为ResultStage,没有输出,而是直接产生结果或进行存储。除ResultStage 外,称为SuffleStage。
如图7 所示是一个Stage 划分的示意图。其中的RDD被划分为3 个Stage,在Stage2 中,从map 到union 都是窄依赖,这两步操作可以形成一个流水线操作:分区7 通过map 操作生成分区9,可以不用等待分区8 到分区10 这步map 操作的计算结束,而是继续进行union 操作,得到分区13。这样流水线执行大大提高了程序的计算效率。

图7:Stage 划分样例示意图
至此,Spark 的运行原理由整体到局部已解释完毕,从中不难看出,Spark 使用的DAG 计算模式较之MapReduce有着诸多优势:
(1)不局限于Map 和Reduce 两个算子,编程模型更灵活,表达能力更强;
(2)Spark 提供了内存计算,可以将SuffleStage 产生的中间结果保存在内存中,较之磁盘而言,迭代的效率更高;
(3)DAG 计算模型将Tasks 分为不同Stage,同一个Stage 中的任务可以并行计算,极大的提高了程序的计算效率。
3 大数据处理技术的发展
随着处理静态的大数据的MapReduce 计算模型、DAG模型的成熟,在各个行业都有着应用上的发展,如交通数据分析、商业零售数据分析、电影影评数据分析、互联网微博数据、用户上网行为分析等。静态分析模型用于教育领域对行业数据复盘,历史数据刻画有着重要的作用。
随产业界对大数据处理技术的进一步需求,若数据吞吐量需求增大,实时性要求更高,各种特定业务需求越来越复杂,那么对大数据计算技术的需求就越丰富。
就拿物联网来举例,其传感器所产生的数据,都是不断增加的,产生的速度也是极快的,而且这些数据需要被实时的进行处理,比如全国各地所有大桥的传感器监测数据,需要被实时处理,得到各种健康指标来判断桥梁是否健康,批处理技术已经无法满足这种需求,因此需要流处理技术,如Spark Streaming,其思想是将实时流入的数据按一定时间片(通常在0.5~2 秒之间)组合成一小批一小批的数据,再使用批处理进行计算处理,由于其是构建在Spark 基础之上的,所以其与Spark 系的系统进行整合,风险和成本消耗都不会很大,如果实时需求不是特别高的话,是个不错的选择;普通的流处理(数据流进,计算,数据流出),每次计算不会考虑历史数据的计算结果,即是无状态的计算。
因此,从软件上讲,大数据处理技术为应对产业界的需求,在算法上结合机器学习和人工智能,研究适用于不同数据处理类型的软件框架,以及对以上架构进行整合是大数据分析和处理行业的发展趋势。
