基于人工智能的医学影像辅助诊断类软件监管与评测方法研究
2022-07-11李曼滕依杉郭佳颖赵阳光李真真
李曼 滕依杉 郭佳颖 赵阳光 李真真
(中国信息通信研究院云计算与大数据研究所智慧健康部 北京市 100191)
1 引言
医学影像由于其具有非侵入式、获取简单、信息量大等特点,已经成为了应用最广泛的疾病诊断工具。常见的医学影像数据来源包括X 射线、CT、超声、MRI、PET、内窥镜、眼底照相机、病理切片、光学相干成像等。近年来,随着医学成像技术的成熟,医学影像数据体量快速增长、数据模态更加多维,因此对其进行准确地分析解读,从中挖掘出有效信息并完成疾病诊断成为了极具挑战性的工作,单纯依靠人力对医学影像进行判读,存在着耗时长,主观性强,漏诊率和误诊率高等问题。以深度学习为代表的新一代人工智能技术能够依赖多层次的神经网络进行自主学习和特征提取,从而完成判别分类、目标检测、图像分割和定量计算等任务。因此基于深度学习的医学影像辅助诊断类软件能够辅助医生完成复杂耗时的影像诊断任务,提升疾病诊断的效率与准确率。
医学影像辅助诊断产品蓬勃发展的同时还存在着诸多问题。由于其在临床活动中会辅助医务人员进行临床决策,存在很大的临床使用风险,漏诊和误诊可能会导致疾病延误和过度医疗。因此对其进行全面系统的安全性和有效性评价非常必要。而人工智能技术的核心是基于海量数据和高算力的黑盒算法,具有数据驱动和更新迭代快等特点,传统的软件性能指标和测试方法对其适用性较低,因此目前亟需建立医学影像辅助诊断产品的评价体系,规范技术标准,为监管机构提供有力的监管依据,推动医学影像辅助诊断产品的持续健康发展。
2 国内外医学影像辅助诊断产品的监管政策研究
医学影像辅助诊断产品所属的医疗器械行业作为一个强监管行业,审批相对比较谨慎。而人工智能作为新型技术,本质上是基于海量数据驱动的黑盒算法,具有更新迭代快等特点,二者之间的不匹配给监管带来了诸多挑战。国内外的监管机构相继出台一系列政策来解决该问题。
2.1 美国
美国食品药品监督管理局(FDA:Food and Drug Administration)认为传统的医疗器械审批流程难以适用于人工智能医疗器械,并相继出台了一系列文件和指南指导监管改革与创新。
2017 年7 月,FDA 发布了《数字健康创新行动计划》,其中提出了面向中高风险硬件设备的传统审批方式已不适合快速迭代设计的数字健康医疗器械,过于复杂的上市前审批流程可能会阻碍患者使用优秀的数字健康产品。因此FDA制定该行动计划,推动数字健康产品监管的改革。行动计划主要分为两大部分:
(1)将进一步制定一系列指南与法案明确数字健康产品的监管范围与方式;
(2)提出了“软件预认证计划(precertify)”,该计划提出将尽量精简产品上市前的审核流程,重点评估企业包括文化、人员等在内的生产管理体系,来验证其是否具备持续生产高质量医疗器械独立软件(SaMD:soft as medical device,)的能力,并且强调了产品上市后真实世界数据对产品的监督作用。
2019 年6 月,FDA 发布了《基于AI/ML 的SaMD 进行修改的拟议监管框架》,其中提出了人工智能医疗器械全生命周期监管框架。该监管框架整体上可分为三大环节,包括产品生产、产品注册与产品上市。在产品生产环节中基于软件预认证项目审查企业的产品质量、用户安全、临床可靠性、网络安全责任和前瞻性文化等,确保企业具备良好的质量管理体系与规范,并有能力建立良好的算法模型。在产品注册环节中除了关注产品的安全性和有效性外还应审查算法的更新迭代协议,确定其是否明确了提交变更申请的时间。在产品上市后将基于真实世界数据持续监督算法性能,并持续优化更新算法模型。该框架提出了一种符合人工智能技术生存周期的监管方式。
2.2 中国
国家药品监督管理局医疗器械技术审评中心(以下简称器审中心)在探究人工智能医疗器械监管方式中做出了大量积极的工作。2019 年7 月,器审中心发布了《深度学习辅助决策医疗器械软件审评要点》(以下简称“审评要点”),其中明确了通用深度学习辅助决策医疗器械软件的审评范围,并提出了基于风险的全生命周期监管方式,包含需求分析、数据收集、算法设计、验证与确认等环节。同时审评要点中提出,在满足测试的充分性、适宜性和有效性等条件下,第三方数据库可视为回顾性研究的一种特殊形式用于算法性能评估,并且明确了第三方数据库在权威性、科学性、规范性、多样性、封闭性、动态性方面的专用要求。2020 年3 月,器审中心发布了《肺炎CT 影像辅助分诊与评估软件审评要点(试行)》,指导采用深度学习技术进行肺炎影像学异常识别软件的审批上市。在此之后器审中心相继启动了肺结节CT 影像辅助决策软件、糖尿病视网膜病变辅助诊断软件等面向专门病种辅助诊断产品的审评要点的编制工作。2021年6 月,器审中心发布了《人工智能医疗器械注册审查指导原则(征求意见稿)》,进一步对人工智能医疗器械生存周期过程质控要求和注册申报资料要求进行了规范,随着监管路径的逐渐明确,截止2022 年1 月底,我国共有36 款人工智能医疗器械软件获批上市,管理类别均为第三类医疗器械,覆盖病种包括肺结节、糖尿病视网膜病变等多种疾病。
3 现有医学影像辅助诊断类软件评测研究
目前基于人工智能的医学影像辅助诊断类软件原则上均按照第三类医疗器械进行管理,因此其在国内的上市前评价分为三部分,软件质量评测、网络安全评测以及算法性能评测。其中软件质量评测部分与其他医疗器械软件相同,参考《GB/T 25000.51-2016 系统与软件工程 系统与软件质量要求和评价(SQuaRE) 第51 部分 就绪可用软件产品(RUSP)》,主要侧重考察产品质量中的功能性、性能效率、兼容性、易用性、可靠性、信息安全性、维护性、可移植性等。网络安全评价可参考器审中心发布的《医疗器械网络安全注册技术审查指导原则》,其中明确了医疗器械应具备保密性、完整性、可得性等网络安全特性。算法性能评价即通过验证算法模型的准确度、鲁棒性等性能来评估产品在临床使用时的有效性。该部分是基于人工智能的医学影像辅助诊断类软件的重要组成部分,目前已上市产品的算法性能评价均是通过临床试验的方式完成的,该方式能够较为安全、准确的验证产品的有效性。但是同时临床试验的时间周期相对较长,对于快速迭代的人工智能技术来说该方式可能会一定程度上制约产品的良性健康发展。
4 算法性能评测体系
针对上述提到的问题,参考《深度学习辅助决策医疗器械软件审评要点》,本文提出了一种基于回顾性数据集的性能评测体系,该评测体系可以在一定程度上辅助现有方式完成算法性能评价。
该评测体系以权威、隔离、可追溯为总体的指导原则,算法性能评测流程如图1 所示,首先根据产品类型与检测需求提交检测任务,测试数据库根据检测任务进行测试数据集准备,将抽取出来的测试数据分为影像数据与金标准数据标签两部分,影像数据与被测产品一同灌入封闭安全的测试环境,运行产品,产品输出预测数据标签,通过与金标准数据标签进行对比,计算各项性能指标。评测流程中的各个环节如图1 所示。
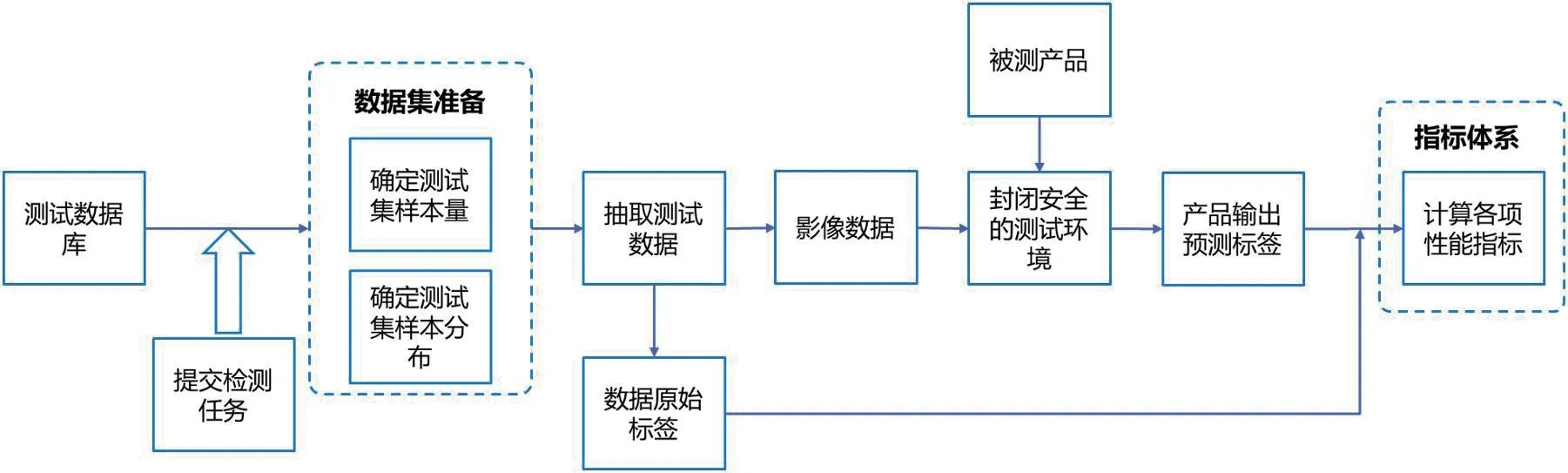
图1:医学影像辅助诊断产品的算法性能评测流程
4.1 数据集准备
数据集准备分为两部分,分别是确定测试样本量和确定样本分布。
恰当的测试样本量对于评估产品效能至关重要,传统临床试验根据研究问题的不同,有多种计算样本量的方式,包括单个诊断试验准确度的样本量估计方式、以两种诊断方法准确度差值为评价标准的样本量估计方法、评价两种诊断方法非劣性或优效性的样本量估计方法、确定合适诊断阈值的样本量估计方法、多位阅片者研究的样本量估计方法等。由于基于数据集的性能测试面向的场景一般为无人工干预的单一诊断试验,因此选择单个诊断试验准确度的样本量估计方式,并选择常用且稳定的敏感度和特异度这两种诊断相关指标进行估计。
根据敏感度指标计算样本量,计算方式见公式(1):

根据特异度指标计算样本量,计算方式见公式(2):

测试样本分布应当满足以下四点:
(1)目标病种的各类分布符合真实世界中的流行病学分布;
(2)单次测试样本的数据来源多样化,包括数据采集设备多样化、数据来源地多样化等;
(3)单次测试样本应包含部分质量不佳数据;
(4)单次测试样本中应包含部分同征不同症的数据。
4.2 计算性能指标
将准备好的数据集以及待测产品送入封闭安全的测试环境,测试完成后,对比产品预测的标签与金标准,计算产品的性能指标。医学影像辅助诊断产品的性能指标分为两部分,分别是临床性能指标与其他性能指标。
4.2.1 临床性能指标
临床性能指标分不同技术场景制定,分别是判别分类、目标检测、图像分割与定量计算。
4.2.1.1 判别分类
判别分类是指根据一定的判别准则对医学影像进行归类。判别分类是医学影像辅助诊断产品中最常见的一种技术场景,可分为二分类和多分类两种类型。二分类场景一般为根据影像特征分为患病和无病两种。多分类场景包括根据疾病的进展程度分成不同等级。例如糖尿病视网膜病变可根据病情严重程度分为0-4 级,不同程度病变的影像学表现有所不同,0 级为无病变,1-4 级病情逐级加重。或者根据疾病的种类不同进行分类,例如肺炎可根据感染的病原体不同分为细菌性肺炎、病毒性肺炎、支原体性肺炎、真菌性肺炎等。能否准确地识别疾病的不同类型或进展程度对于后续制定治疗方案至关重要。
4.2.1.1.1 二分类
在二分类场景中,通过对比产品的预测标签与金标准结果,可以得到一个二阶混淆矩阵,该混淆矩阵为计算二分类指标的基础,混淆矩阵如表1 所示。

表1:混淆矩阵示意表
其中的几个概念如下:
(1)真阳性(TP:True Positive):样本的真实类别是阳性,且模型预测的结果也是阳性;
(2)真阴性(TN:True Negative):样本的真实类别是阴性,且模型将其预测成为阴性;
(3)假阳性(FP:False Positive):样本的真实类别是阴性,但是模型将其预测成为阳性;
(4)假阴性(FN:False Negative):样本的真实类别是阳性,但是模型将其预测成为阴性。
基于该混淆矩阵可以计算得到二分类产品的准确度、敏感度、特异度、精确度,计算公式如表2 所示。

表2:二分类指标列表


其中,(x,y)为ROC 曲线上按序连接的点。
4.2.1.1.2 多分类
在多分类场景中,可从分级性能与综合性能两方面来评价产品。
(1)分级指标。
为了更好地观测多分类产品在各级分类中的性能表现,在对多分类产品进行性能指标评估时需要将多分类问题转化成多个二分类问题,以眼底糖尿病视网膜病变国际通用DR0-DR4 五级分期的分类方式为例,转化方式如图2 所示。

图2:多分类问题转化成多个二分类问题示意图
针对每一级的性能指标包括准确度、敏感度、特异度、精确度、ROC 曲线和AUC 值,计算公式和绘制方式与上文一致。
(2)综合指标。
为了综合评估多分类产品的性能,对各级计算得到的准确度、敏感度、特异度、精确度、AUC值分别进行加权平均(权重为各级样本数量),得到整个多分类产品的综合指标。
同时,Kappa 系数作为衡量分类精度的指标可以比较好地反映多分类产品的综合性能,指标说明和计算公式如下:
(a)说明:Kappa 系数是基于混淆矩阵进行计算得到的,Kappa 系数的范围为[-1,1],可以认为Kappa 系数越接近1,分类精度越高;Kappa 系数越接近-1,分类精度越低。
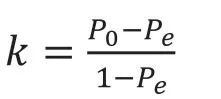
其中P是每一类正确分类的样本数量之和除以总样本数。
假设每一类的真实样本个数分别为a,a,……,a,而预测出来的每一类的样本个数分别为b,b,……,b,总样本个数为n,则有:

4.2.1.1.3 目标检测
目标检测是指对获取的医学影像中病灶的位置进行检测,并以预测框的形式将病灶位置框出。计算产品目标检测场景下的性能指标可分为三个步骤:
(1)产品输出预测框;
(2)根据预测框与金标准框之间的关系确定预测框所在位置是否为正确检出病灶;
(3)计算产品的性能指标,流程如图3 所示。

图3:目标检测流程图
其中,判定预测框位置是否检出应有相应指标,例如交并比大小、中心点距离等,具体检出指标可由产品自行选择,但是产品应对选择的指标、计算公式与阈值要求进行说明。若金标准框与预测框满足检出指标阈值要求,则认为该处为正确检出的病灶,若金标准框与预测框不满足检出指标阈值要求,则认为该处为非病灶位置误定位。若金标准框与预测框不是唯一对应,则认为检出指标值最优的为正确检出病灶,其余为非病灶位置误定位。
目标检测场景下产品的性能指标包括真阳率、平均假阳性个数和FROC 曲线,计算方式见公式(4)、(5):
(1)真阳率

(2)平均假阳性个数

(3)FROC 曲线
FROC 曲线的纵轴为真阳率,横轴为平均假阳性个数,根据每一个预测结节的预测概率,绘制FROC 曲线,计算真阳率在平均假阳性个数分别为1/8,1/4,1/2,1,2,4 和8 这7 种不同情况下的平均值,作为评价指标之一。
4.2.1.1.4 图像分割
图像分割是指在影像中将病灶的轮廓勾勒出来,评估产品图像分割场景中的性能指标分别为交并比和Dice 系数,计算方式见公式(6)、(7):
(1)交并比

其中A 为预测范围像素的集合,B 为金标准范围像素的集合。
(2)Dice 系数

其中A 为预测范围像素的集合,B 为金标准范围像素的集合。
4.2.1.1.5 定量计算
定量计算是指基于影像信息,计算病灶的部分灰度特征和形态学特征,从而更加客观的反应病灶的性质。例如,在肺结节辅助诊断中,计算肺结节最大横截面的长径与短径、肺结节空间最大直径、肺结节体积对于评估结节的良恶性有重要意义,在肺炎辅助诊断中,计算炎症区域面积能够更好地评估病情进展。定量计算场景下的性能指标分别为绝对误差和相对误差,可以反应产品测量值与金标准值之间的差距,计算方式见公式(8)、(9):
(1)绝对误差

(2)相对误差

4.2.2 其他性能指标
除了临床性能以外,基于人工智能技术的医学影像辅助诊断产品的算法鲁棒性、泛化性和可再现性也是其重要的性能评价指标。
4.2.2.1 鲁棒性
鲁棒性指系统在一定程度的干扰下仍能保持某些性能的特性。在测试中,对测试影像人为地增加部分定量的干扰因素,观测产品对这些干扰的对抗能力。具体的测试方式为:抽取部分测试数据进行随机的基本变换,来进行产品鲁棒性的测试。其中基本变换包括原图边长5%的裁剪、左右翻转、上下翻转、增加对比度(5%)、减少对比度(5%)、增加亮度(5%)、减少亮度(5%)、增加一定信号幅度的高斯白噪声(5%)。实际测试过程中应至少包括其中3 种变换,具体采取何种变换由产品声称选择。其中进行基本变换的数据应占所有测试样本量的10%。用变换后的测试数据及剩余未变换的数据灌入封闭沙箱,计算得到临床性能指标结果,分析是否有统计学差异。
4.2.2.2 泛化性
泛化性指算法对训练集之外的样本类别的预测能力。具体的测试方式为:基于临床性能测试,根据不同维度的数据属性来统计测试结果,从而分别计算不同属性下的临床性能指标,分析是否有统计学差异。例如统计维度为不同地区,则每一类数据属性为中部地区、北部地区、南部地区等。具体统计维度可包括不同地区、不同采集设备厂商等。
4.2.2.3 可再现性
可再现性指在算法测试环境和初始条件相同的情况下,算法对于相同或相似的数据集的不同测试结果之间的一致性。具体的测试方式为:基于上次临床性能测试使用的相同数据集进行第二次测试,所得到的临床性能指标应不劣于上次测试结果。
4.3 测试后封样
为保证测试环境的封闭性、测试产品与测试数据的安全性以及测试的可复现性,在全部指标计算结束后,需要进行一步测试后封样,测试后封样示意图如图4 所示。

图4:测试后封样流程图
测试结束后,输出测试结果,同时对本次测试进行留档封样,留档数据包括:本次测试数据集全部的元数据(包括数据ID、数据属性、数据来源库等)保证测试的可追溯性与可复现性;本次测试的元属性(包括本次测试的应用场景、测试策略等);本次测试的测试结果(包括本次测试计算得到的性能指标),留档封样后,将本次测试的产品与数据一同销毁,保证测试安全性。
5 总结与讨论
本文深入剖析了基于人工智能的医学影像辅助诊断类软件的发展现状、监管政策以及现有的评测方式,并针对此类软件缺少快捷、权威、安全的算法性能测试方法,提出了一套基于数据集的算法性能评测体系,其中包括可落地可实施的评测方法,以及全面的指标体系和指标计算方式。该算法性能测试方式能够在一定程度上证明辅助诊断类软件的安全有效性,并可以成为辅助诊断类软件临床试验的有力辅助工具。
在评测方法的研究过程中笔者认为基于数据库的算法性能测试存在一定的不可替代性。本文提出的评测方式是使用基于回顾性数据建立的第三方测试数据库来完成的,即通过广泛收集已有的数据建立形成数据库,该方式与传统临床试验相比有以下几点优势:
(1)第三方数据库具有样本量丰富、信息量大、多维度等特点,能够更好的评估算法的泛化性,同时对于一些声称能够对罕见病、合并病进行辅助诊断的产品来说,在临床试验中采用前瞻性研究的方式收集数据难度很大,基于一个包含大量信息的第三方测试数据库重复对不同产品进行测试,能够大幅节约经济成本和时间成本。
(2)人工智能技术具有数据驱动、更新迭代快的特点,在产品发生数据驱动型更新后,可以基于第三方测试数据库验证其算法性能是否发生显著性变化,若不明显劣于产品首次注册时的结果则无需提交产品重大更新说明,加快产品更新审批的速度,并使企业能够保持持续优化产品的动力。
同时本文提出的评测方法尚且存在一定的局限性。首先,在测试过程中为保证测试的权威性,待测产品与待测数据被送入封闭的测试沙箱中完成测试,产品运行过程无人工干预,因此对于一些在使用过程中涉及较多人机交互环节的辅助诊断产品则可能不适用于该评测方式。
