基于分布式数据库的一体化档案管理研究
2022-07-11王晓东常海军王征
王晓东 常海军 王征
(河北省地质测绘院 河北省廊坊市 065000)
1 档案分类
档案分类是依据一定的标准,按照档案来源、时间、内容和形式特征的异同点,对档案进行有层次的区分,并组成一定的体系。档案种类的划分,一般采用以下几种形式:
一是按照档案形成者的性质,即档案的来源标准可分为国家机关档案、党派团体档案、企业单位档案等;二是根据档案的内容性质标准,有两种划分方法,一是分为普通档案和专门档案;另一种是直接分为文书档案、公安档案、诉讼档案等多种门类;三是根据档案的载体形式标准,可分为石刻档案、甲骨档案、胶片档案、磁带档案等,载体形式的不同,档案的整理、保管与利用的方式均有所不同;四是按照记录信息方式标准,分为文字档案、图形档案、声像档案、电子档案。
2 电子档案统一存储管理内容
本文的研究内容基于第四种分类方式,利用分布式数据库中的集群、分片、复制等技术实现数字化文字档案、图形档案、声像档案等多种类型的电子档案统一存储管理。电子档案统一存储管理涉及到的数据类型包括结构化数据(即行数据,存储在数据库里,可以用二维表结构来逻辑表达实现的数据)、半结构化数据(它是结构化的数据,但是结构变化很大)和非结构化数据(包括所有格式的办公文档、文本、图片、XML、HTML、各类报表、图像和音频/视频信息等)。研究内容主要包括关系型数据库、NOSQL 数据库及缓存数据库的选型,ORM(Object Relational Mapping)框架选择、DDD(领域驱动设计)应用等多种技术和方法。
关系数据库MySQL、Postgre 均为具有较高知名度开源软件, MySQL 同Postgre 相比具有的优点是,较好的性能;在Windows 环境中的适宜性更好;使用了线程,在不同线程间的切换和对公共的存储区域的访问具有更佳的性能。Postgre 在对视图、触发器、存储过程、约束和子过程的支持上更加完善一些。
Apache CouchDB 是一个面向文档的数据库管理系统。它提供以 JSON 作为数据格式的 REST API 来对其进行操作,并可以通过视图来操纵文档的组织和呈现。 CouchDB 是Apache 基金会的顶级开源项目。
MongoDB 同CouchDB 相比,具有如下特点:
(1)数据模型设计减少了对连接的需求,并提供了模式的简单演进。
(2)高性能:它既不包含连接,也不包含提供快速访问的事务。
(3)高可用性:是由于合并了副本集,这些副本集能够在故障期间提供冗余,而且非常健壮。
(4)可伸缩性。MongoDB 的分片特性使它能够在分布式函数中快速高效地执行。
查询语言:MongoDB 有自己的查询语言,可以替代SQL 语言。实用函数map、reduce 可以替代复杂的聚合函数。综合分析,MongoDB 更适合项目研究。
EntityFramework 对非SQL Server 数据库且无该数据库的DataProvider;在进行一些复杂查询的情况下,EF 的性能表现不太好,开发人员又无法控制SQL 语句的生成;EF需要跟踪实体的变化的和大Collection 对象的处理;EF 的Context 上下文不是线程安全的,在整个Service 上使用一个Context 上下文存在问题。
NHibernate 内存开销较大,处理数据库的方式是针对单个对象的,不适用于批量修改、删除数据,且学习成本较高。Linq2db 同EntityFramework 和NHibernate 相 比,Linq2db不需要跟踪当前实体的所有信息,是性能较快的LINQ 的ORM,能在POCO 对象和数据库之间提供简单、轻便、快速且类型安全的层。从结构上讲,它使用LINQ 表达式而不是魔术字符串,在代码和数据库之间维持一个薄的抽象层。查询由C#编译器检查,并能够轻松重构。不像Entity Framework 那样有变更跟踪,必须自己管理。从积极的一面来说,开发人员可以获得更多控制权并在访问数据时获得更好的性能。也就是说,lin12db 提供了类型安全的SQL。
上述条件是选择lin12db 主要原因。
3 系统实现研究
MongoDB 文档数据库集群搭建:
3.1 Replica-set(复制集)部署
MongoDB Replica-set(复制集),如图1,是一组维护同样数据的mongod 实例,提供冗余和高可用性。版本4.4之前版本,MongoDB 偶尔宕机切换之后,客户能感受到业务访问延迟会有抖动,一段时间后才恢复到之前的水平,抖动原因是新选举出的主库之前从未提供过读服务,并不了解业务的访问特征,没有针对性的对数据做缓存,所以在突然提供服务后,读操作会出现大量的Cache Miss,需要从磁盘重新加载数据。在大内存实例的情况下,这个问题更为明显。版本4.4 中,MongoDB 提供Mirrored Reads 功能,主库会按一定的比例把读流量复制到备库上执行,来帮助备库预热缓存。这个执行是一个Fire and Forgot 行为,不会对主库的性能产生任何实质性的影响,但是备库负载会有一定程度的上升。

图1:MongoDB 复制集示意图
MongoDB 复制集的意义在MongoDB 于实现服务高可用,它依赖于两个方面,数据写入时将数据迅速复制到另一个独立节点上,在接受写入的节点发生故障时自动选举出一个新的替代节点。在实现高可用的同时,复制集实现了其他几个附加作用。数据分发,将数据从一个区域复制到另一个区域,减少另一个区域的读延迟;读写分离,不同类型的压力分别在不同的节点上执行;异地容灾,在数据中心故障时候快速切换到异地。
Mongodb 复制集架构,一个典型的复制集由3 个以上具有投票权的节点组成,包括:
一个主节点(primary) ,接受写入操作和选举时投票;从节点(secondary),用于复制主节点上的新数据和选举时投票。 Arbiter (投票节点),将某一个从库,设置为专用的投票节点,从节占不存储数据,不负责数据复制。不推荐使用Arbiter(投票节点)在测试环境中,配置了三台服务用于部署Replica-set(复制集):
server-1 member0.tech.com:192.168.1.211
server-2 member1.tech.com:192.168.1.212
server-3 member2.tech.com:192.168.1.213
3.2 Mongodb分片集群部署
mongodb分片集群,如图2,由mongos、configServer集群、mongodb 复制集组成,mongos 提供路由功能。configServer作为集群的核心,集中存放集群和路由分片的元数据,包括集群中有哪些分片、分片的是哪些集合及数据的分布。mongodb 复制集维护多个mongod 实例,在多个实例间复制数据,提高系统的可用性。
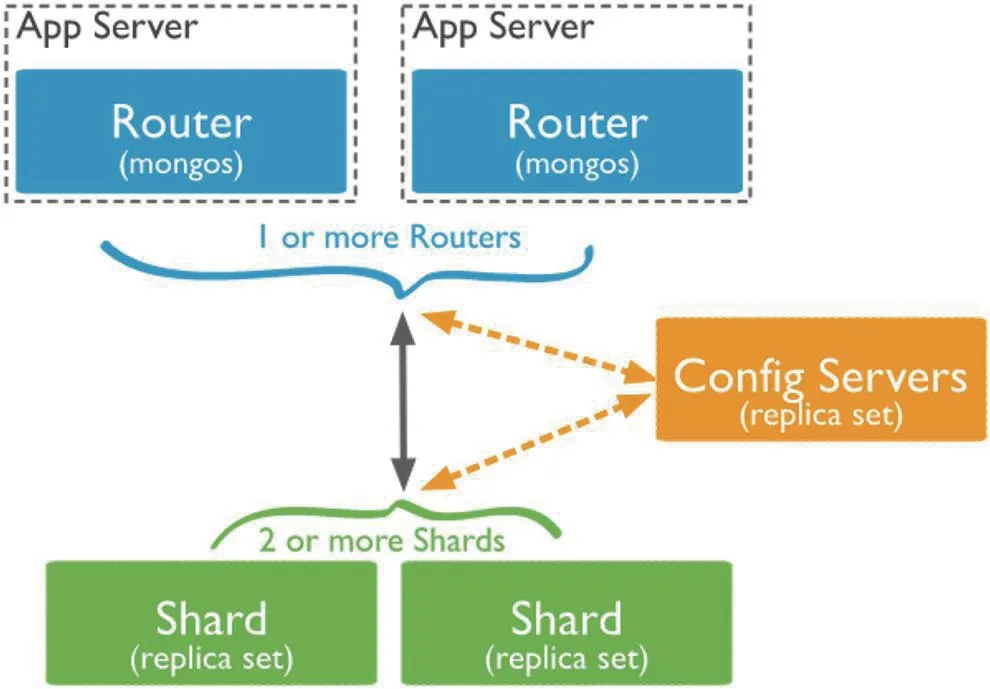
图2:Mongodb 分片集群示意图
4 一体化档案管理验证系统
一体化档案管理验证系统在架构设计中,采用了分层架构模式。Martin Fowler 在“企业应用架构模式”一书中总结了分层架构的优点,开发人员可以只关注整个结构中的其中一层;很容易用新的实现来替换原有层次的实现;能够降低层与层之间的依赖;有利于标准化;有利于各层逻辑复用。分层结构也有其不足之处,降低了系统的性能;有时也会导致级联的修改。
4.1 关系数据库提供模块
一体化档案管理验证系统在数据访问层采用了“面向接口编程”,抽象出接口ILibDataProvider,定义了数据库访问所需要的操作,摆脱了对具体数据库的依赖,有利于整个数据访问层在不同实际数据间的切换。
对mysql、postgre 均定义了相应的模MySqlNopData Provider、PostgreSqlDataProvider,实现了ILibDataProvider和继承了BaseDataProvider,验证系统可根据需求使用mysql、postgre,无需对代码做出修改。
NoSql 数据库提供者模块
NoSql 数据库部分,以MongoFramework 为基础设计了IMongoDataProvider 为验证系统与数据库交互的接口。
4.2 数据库设计
验证系统访问数据库,首先要解决的是如何处理好数据实体和数据库中--表(对于关系数据库来说)或集合及文档(mongodb)的对应关系,以ORM 为基础进行数据库设计时,生成数据库的方式主要有三种Database First、DB First及Code First。由于系统实现采用了领域驱动设计(Domain Driven Design),因此在处理Model 和数据库的对应关系时采用Code First 模式, CodeFirst 开发模式中直接创建领域类,linq2db 根据创建的领域类自动生成数据库。

创建数据库对象
调用相应数据库提供者类中的InitializeDatabase()函数创建与Model 相对应的数据库对象。
数据访问
仓储(Respository)模式就像一个内存集合,将Model 与数据库对象完全隔离起来,它采用POCO(plain old common language runtime object)和PI(persistence ignorant)对象。是工作单元和数据库之间单独分离出来的一层,是对数据访问的封装。优点是业务层不需要知道它的具体实现,达到了分离关注点。提高了对数据库访问的维护,对于仓储的改变并不会改变业务的逻辑。
验证系统中的实现,首先定义了一个通用的泛型接口,实现了数据的获取、插入、更新和删除通用操作功能;


泛型的使用可以简化验证系统中每个Model 对应Respository 实现,结合.net framework 提供的依赖注入机制,能够非常简洁的实现Respository 对象的创建。

数据缓存
缓存技术已被广泛使用各种软件技术中,用高速存储介质替代低速存储介质,用键值对方式替代较为复杂的数据库查询,在B/S 架构的系统中作用更为明显,显著提高用户使用体验。缓存技术常用于有数据库端、应用服务器和客户端。
验证系统用到缓存技术在三个均有涉及,本文着重于应用服务器。在实现和使用上有两种形式,基于应用服务器本机内存和基于内存的分布式数据库。
验证系统定义缓存管理接口,用于缓存数据对象的统一管理

基于应用服务器本机内存方式的实现原理,当用户请求数据对象时,优先查询本地缓存,如果发现请求的数据对象,则返加给用户,否则将请求转发到数据库,从数据库进行查询,并将查询结果加载到本地缓存,从缓存把数据对象返回给用户。等到下次处理相同请求时直接从存在中取出缓存的数据对象,缩短了应用服务器的请求计算时间、与数据库系统的交互时间,提高系统的并发量,能够明显降低网络负载。本机缓存优点是性能高,管理方便;缺点是本机缓存无法被多个应用服务器共享,一旦宕机缓存数据对象将全部丢失。
本机缓存管理器实现了ICacheManager 接口

基于内存的分布式数据库在数据对象的处理上与基于应用服务器本机内存的操作方式相近,不同点在于缓存的数据对象存放于Redis 是一个分布式内存数据库(非关系型数据库),它可以存储键值对与5 种不同类型的值之间的映射。基于分分布式内存数据库的缓存管理的优点是缓存数据对象只要分布式内存数据库不发生宕机的情况,数据对象就不丢失;缺点是在性能和维护有一定开销。

5 结束语
基于分布式数据库的一体化档案管理系统构建并初步部署后,改变了以往的数据管理模4 式,在各个方面都取得了较好的应用效果。
(1)有效提高了数据的录入效率。集中式数据库的管理模式,不同部门的项目档案数据都在同一个数据库管理系统中存储和应用,导致数据库管理系统的负载过重,在使用过程中经常会出现无法响应等情况,而本系统基于分布数数据库的拆分策略实现了数据的智能化动态分配,较好地解决了上述问题。
(2)实现了数据资源的共享。传统模式下,部门档案数据资源与院内其他管理系统的数据资源在存储方式上相互独立,没有建立起共享机制,而本系统建立了不同应用数据库之间的共享和同步机制,有利于数据的综合利用。
(3)解决了数据一致性的问题。传统模式下对于档案数据的管理,往往在使用时为了方便,出现多个数据的副本,而当数据更新时,副本数据无法得到及时更新,出现脏数据问题,分布式档案管理系统采用基于SQL Server 的同步处理方式,使不同节点的数据保持一致,提高了职工档案数据信息的准确性。
(4)提高了档案数据的查询效率。基于传统集中式数据管理模式,当出现多个用户并发查询的情况时,系统往往无法做出快速的反应,而且所获取的数据信息内容不全,系统基于2-+*分布数存储优化了数据查询的性能,并且可以为用户提供要素齐全的数据。
基于分布式数据库系统构建的一体化档案管理系统,系统功能基本完善。在项目管理上,项目从需求分析到架构设计到功能实现及系统测试环节,都遵循软件开发标准流程。在技术上,基于C#.NET Framework 进行系统功能开发,基于私有云平台搭建分布式数据库环境,对分布式数据库技术的优势发挥进行了充分探索和证明。系统还有很大的优化空间,未来无论从技术创新角度还是业务需求角度都有更多价值可以挖掘。
