专业领域智能问答系统设计及应用
2022-07-11庄莉苏江文卢伟龙张晓东陈江海
庄莉 苏江文 卢伟龙 张晓东 陈江海
(福建亿榕信息技术有限公司 福建省福州市 350003)
1 智能问答系统的设计需求
智能问答系统可对知识信息追本溯源,并借助智能助手为用户提供多种语言交互功能,降低此类实训的操作门槛,使实训过程的信息服务更加精准全面,提高智能实训系统易用性。根据功能的不同,可将其分为以下模块,彼此之间紧密联系,均以服务用户为目标。
(1)知识库梳理模块。该模块的应用对象为数据标注人员,采用本体类标注,并根据本体类向用户显示标注结果,要求显示知识维度和知识拓扑。本系统需要人工设置领域内的关键词,并以此为依据显示出对应的答案,该模块还支持标注者手动添加关键词,满足知识库编辑需求。
(2)系统维护模块。该模块可满足工作人员日常维护工作,易于添加标准问题、答案和分机问题,操作员也可以根据权限对相应内容进行修改。在执行删除操作时,应区分删除的内容。在执行删除标准问题时,如果与之相对应的答案没有展开,则在删除标准问题后,将标准答案与扩展问题将被一起剔除。
(3)用户查询模块。该功能要求针对用户所提问题给出想要获取的正确答案。在执行用户查询操作中,用户可根据获得的答案向系统提交满意度。如果不满意,系统可以允许用户将通过其他方式对答案进行补充。通过智能助手的应用,可在交互期间感知和采集用户操作行为,依靠精细化日志分析人工智能实训平台的应用状态,并提出相应的优化意见,促进实训平台产品不断优化升级。在用户日志基础上,通过优化推荐系统、搜索引擎等方式,将用户日志的价值充分突显出来,使问答历史得到准确高效的记录。
2 智能问答系统设计内容与方法
2.1 设计内容
该项目在知识图谱基础上开展,包括智能助手应用、基础服务、平台集成研发等内容,创建知识网络可为实训全过程提供服务,使用户能够按照自然语言智能交互,为实训全过程提供准确信息,提高实训系统应用便捷性。面向智能助手研发基础智能服务,将搜索、信息推荐、智能问答等基础类服务统一提炼与封装,为智能问答与相关应用提供支撑服务,具体内容如下。
(1)信息推荐服务。该服务可在内容、浏览历史与协同过滤基础上进行个性化推荐,并挖掘用户的兴趣爱好等,适用于文档资料推荐、课程推荐以及问答检索推荐等相关场景内;
(2)综合搜索服务。该服务包括非结构化内容全文检索,可在知识图谱基础上进行检索。智能助手可提供两种基础性服务,综合服务可将课程资料、人工智能知识搜索、知识图谱等整合起来,可为人工实训平台提供公共搜索服务;
(3)智能问答服务。在语义网、自然语言处理以及机器学习等技术方面,可结合电子专业知识、实训课程、人工智能知识等创建结构化问答知识库,从问题检索、理解与答案生成等方面开展问答服务,研究出一对一应答、交互应答的问答服务。
2.2 设计方法
根据需求分析与基本服务可知,该系统主要包括知识库梳理、系统维护与用户查询三项内容。其中,知识库梳理包括知识拓扑与维度展示、本体类管理、问答历史管理等功能;系统维护包括标准问题、答案与拓展问题增删功能;用户查询包括反馈结果、数据库查询等功能。
(1)知识库梳理。该模块为抽象类,包括知识维度、拓扑展示等内容,并在内部执行具体操作。其中,抽象类可提供与数据库相关的操作,并在木块内以特定数据的形式展示出来。子模块包括库中多类问题与答案增删功能,本体管理可将知识拓扑和维度展现给用户,管理和查询问答历史数据,日志内容支持查询与增减,但不能手动添加日志;Word 类管理负责系统中的所有关键字,如培训要点、考试要求等;根据培训机构的特点,发布常见问题,用户可以手动添加问题和答案到系统中。同时,利用机器学习技术可结合人工智能知识,创建结构化问答知识库,从问题检索、理解与答案生成等方面开展问答服务,获得交互应答的问答服务;
(2)系统维护。该模块可面向智能助手研发基础智能服务,将搜索、信息推荐、智能问答等基础类服务统一提炼与封装,为智能问答与相关应用提供支撑服务,主要为系统维护人员提供服务,系统培训师在系统中是维护人员,为用户问答进行回复,并支持用户自行编辑答案、系统维护。
(3)用户查询。该功能包括三个子类,均可以完成系统算法模型的相关应用。其中,LuceneRank 类作为基本模块,可利用Lucene 全文检索系统将答案在列表中展现出来;VectorModel 类作为混合向量模块,可利用预先训练好的问题,创建向量模型,然后根据该模型内的反馈答案传递到相应的列表内;LearningToRankModel 类针对现有答案列表进行排序,然后根据查询模型运行程序,将最佳的答案反馈给用户。
2.3 总体设计
2.3.1 主体结构
结合智能问答系统的现实需求,创建该系统的主体架构,如表1 所示。主要包括问题解析、服务检测与上下文管理、知识梳理等模块。该系统应用中,用户自然语言查询后,利用语音输入法将语音变成文字,再利用声韵母语音识别文本,对错误字音进行纠正,得出与领域相关的正确语句。在词典纠错期间,针对文本进行分词,因部分词语有多重含义,需要利用同义词典将其转换,再利用条件随机场模型做好问句标注,获得相应的<领域词,词语含义>二元组串。

表1:智能问答系统主要内容
因上下文本间有所关联,对用户查询结果产生较大影响,在对问句的二元组串查询后,应对上下文的关联情况进行判断。如若判断结果是“有关联”,则应将组串加入本次查询的二元组串内,根据该元素的语义创造查询请求服务,再将该服务与语义特征构造查询请求服务相结合,使请求服务与查询服务相对应,便可得到符合实例条件的查询服务,将其当作查询服务。同时,还应利用owl-s 对查询结果进行检验,再将结果纳入到查询上下文的表内以备后用。如若判断结果为“无关联”,则为用户反馈“无结果”,由此完善全部查询流程。
2.3.2 服务描述规则
在智能问答系统中,服务属于关键环节之一,系统按照用户的提问为其提供相应的搜索结果,将搜索参数实例化后调用服务,并将最终结果展示给用户。因服务与搜索结果息息相关,根据服务特点与用户需求,应对相应服务规则与基本概念进行描述,如下。
Service 代表的是存储相关服务的顶层概念,将与服务描述相关的概念知识放于下层;
Domain 代表的是顶层概念,下层存储与本领域有联系的概念,例如时间概念、地点概念等;
OtherCondition 代表的是存在服务描述剩余条件的顶层概念,能够顺利确定与之相对应的服务,如用户询问动机如何,是想要搜索还是比较等等;
hasOwlInputSeq 代表的是概念属性,其作用在于将用户搜索的服务变成实例,与真实的Web 服务参数相对应,可理解为服务参数与实例之间具有映射反应;
hasOtherCondition 同样是概念属性,其作用是对描述服务的其他因素进行展示,能够与OtherConditon 相对应。
2.3.3 命名实体识别策略
(1)文本纠错策略。语音识别准确性与命名实体的服务匹配度具有紧密联系,进而影响到实例化水平。在利用声韵母语音识别后,还可利用文本纠错法,使组合歧义类、未登陆词处理、混合歧义、交际歧义等字段得到良好处理。在专业领域中创建领域词典,单一元素为领域相关词中的概念二元组,因部分词汇具有多重含义,存在的概念较多。汉字是识别单元为音节,音节包括声母和韵母两项内容。因此,可先用语音识别声韵母后,再采用文本纠错策略,依靠语音输入法将用户输入的文本变成声韵母串,再根据相似度对比进行纠正,标准问题纠错表如表2 所示。

表2:标准问题纠错表
(2)实体标注策略。在分词后很容易出现一词多义情况,可利用条件随机场进行词性标注。每条语料都包括编号与一段句子,且语料针对编号、句子内的词语进行词性标注,因训练期间无需记录编号,需要先对语料实施预处理,获得符合训练要求的样本。选取特征窗口长度为7,由7 个单词和6 个二元组合而成。在模板内,“#”表示的是注释;U 表示的是采用Unigram 模板,00 表示的是编号;x[s,o]表示的是CRFs 内的点(state);在t 时段内标签用s 表示,上下文用o 表示,如表3 所示。

表3:用户查询记录表
(3)服务概念匹配策略。服务匹配的宗旨是将用户提问关联到与之相对的服务中,将<领域相关词,语义概念>二元组串应用到相应的基本服务内。在概念层级基础上寻找匹配方式,将传输服务参数与相应领域概念相配合,并将其分成不同类型。当服务请求概念服务对象概念相同时,则说明二者相吻合;如若服务请求参数与服务对象内超类相符合,则与搜索需求相符合,能够进行匹配;如若服务请求参数与服务对象内的子类相对应,因二者无法匹配,在实例化过程中参数类型可能发生改变,说明无法成功匹配;如若服务请求期间,同类参数数量较多,而在匹配服务中该参数数据集相同时,二者能够成功匹配。例如,在搜索“河北省2018 年GDP”时,在服务请求中的输入参数为GDP,属于indicator,与服务对象输入参数内的indicatorSet 相对应,二者便可成功匹配;如若服务请求内的参数与服务概念中子类没有关联,在实例化过程中参数类型也会出现误差,影响匹配成功度;
3 智能问答系统的实现
针对智能问答系统内的部分功能,通过流程图形式展现主要算法模块的实际应用,具体实现方式如下。
3.1 知识库梳理
该系统中的知识库包括两种不同种类的知识源,一种是组织完毕的常见问题(FAQ)集合,可直接利用;另一种是需要人工梳理型知识源,依照技术手册、网页信息等进行梳理。本系统重点对梳理第一类知识元素,将第二类知识元素手动应用到第一类要处理的知识元素上。知识库的梳理是系统预处理环节的关键组成部分,梳理效果对算法模型准确率具有直接影响,具体如下。
(1)知识库管理。在问答系统中知识库作为中枢所在,包括分类、标准问题与答案、实例等方面。其中,实例代表的是相同答案的不同问法集合;分类是指用户事先对不同问答对标准的信息;属性代表的是不同类型的信息,例如办事项、查询项等等;标准问答是指用户给出的FAQ 问答对;标注人员对相同答案提供的多种问法即扩展问题。
(2)本体类与词类管理。本体类管理主要对概念之间关系进行表达,可分为实体与方法两种类型。例如,在人工智能实训中,教学属于方法类,教材属于实体类。通过对本体类的科学管理,可完成知识继承与总结的目标;词类管理重点对敏感词、近义词、前后缀等词汇进行管理,尤其是特定范围内的专业术语,可采用手动添加的方式,使词类信息更加全面。
(3)问答历史。该模块可记录用户操作痕迹,并突出重点问题以及未能及时解决的问题,由此提高智能助手的智能化水平。在用户日志基础上,通过优化推荐系统、搜索引擎等方式,将用户日志的价值充分突显出来,使问答历史得到准确高效的记录,用户信息表如表4 所示。

表4:用户信息表
3.2 问题检索
该模式是当用户输入处理完毕后,系统可依照用户所提问题进行查询,并将结果反馈给用户,包括重新排序与Lucene 检索两个方面。Lucene 检索将标注的问题与答案配对,并以正则表达式展现出来。经过知识库梳理后,将标准问题扩展到不同的模板中,然后将问题和答案分别编入索引,在该模块中引入查询语句,并使用Lucene 判断是否有匹配的答案。在此期间,Lucene 可以传递给用户50 个最佳的答案,为后期程序排序提供参考。重排序模块主要对Lucene 反馈结果的算法进行优化,借助事先训练好的模型来实现。在实际应用中,可先调整开发集参数,并在词向量技术基础上,利用神经网络将其变为句向量,由此得到最佳检索效果。
3.3 问题理解
在自然语言技术的支持下,对用户输入语句进行转化,由原本的查询语句变为通俗易懂的、系统可准确识别的语义,该系统利用三个模块完成这一任务,具体如下。
(1)预处理。该阶段是用户输入查询语句时,系统对用户查询语句进行处理,可将用户查询语句分为智能分词和命名实体。在此之前,用户输入内容没有经过分词处理,需要利用开源汉语分词包进行准确分词,将特殊词、词组加入词典中,使词典内容更加完善;后一阶段为实体识别,该模块的主要功能是识别语句中预先标注的实体名称和地名,并进行不同的记录;
(2)会话管理。主要是智能反问句,如果无法搜索到用户的答案,系统会以用户提出问题为中心,对相关问题进行拓展,判断用户是否存在表达不清楚情况,并向用户反问,如“您是否想咨询XX 问题?”。
(3)后处理。该模块以智能纠错为主,包括拼音纠错、拼写纠错两个方面。其中,前者通过注音程序训练语料,建立相应的训练模型,然后将置信度小的词汇转换为大词,由此实现纠错目标;后者适用于字形错误纠正,在拼音准确的情况下,通过拼写纠错可使问答系统反馈准确率得到显著提升。
3.4 上下文管理
在服务对象成功匹配后,应对Wen服务参数实例化处理,使整个问答流程得以完善。在本系统中用wsdl 对Web 进行描述,再经过OwlsEdit 工具对Wen 服务进行生成,获得服务描述的owl 文件。经过查询匹配获得与之相应的服务描述本体,再利用“hasOwlUri”属性对文件描述的服务进行定位,使本体内的服务输入能够与Uri 相应服务输入进行映射,包括本体描述服务、经过wsdl 文件生成的服务描述。因服务语义特点不够清晰,可通过“hasOwlUni”“hasOutput”等映射到“Uri”“para1”“para2”中,且输入“data”概念与“para2”映射,服务中拥有参数类型信息,可将服务输入参数实例更好的映射到与之相对的参数中,使各项服务均可自动化调用。
4 系统测试与分析
4.1 性能评价指标
智能问答系统测试关键在于该系统能否为用户提供正确答案。本系统采用准确率、命中率两项指标进行性能测评,具体如下。
(1)准确率。该项指标是最为简便直接的测试手段,是指系统认为可信度最高的答案,计算公式可表示为:
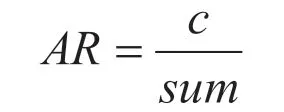
式中,AR 代表准确率;c 代表系统反馈的最佳答案数量;sum 代表的是系统检测出的全部答案数量。
(2)命中率。该指标是在固定前几名的答案,在去掉第一个最佳答案后,还要分析后续几个备选答案。将涵盖n个问题的测试集用qi 表示,其中i 取值范围为1 到n,假设ri 代表系统反馈列表中的最佳答案,如若无最佳答案,则取值为0,在有最佳答案的情况下,计算公式可表示为:
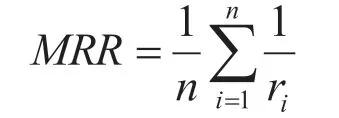
式中,MRR 代表的是命中率;r代表的是反馈答案排名。通常只分析前五名或者前十名的候选答案,排名靠后的答案基本不会对该指标产生影响。
4.2 用户评价指标
该系统在问答测试中设置了用户反馈功能,系统在为用户展示答案的同时,用户可根据系统反馈的准确度进行评价,由此得出使用满意率,在满意情况下可用公式表示如下,不满意则为0。
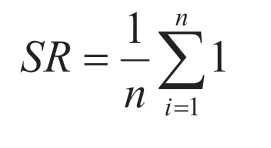
式中,SR 表示用户满意度;n 表示用户的咨询数量。该系统将自动记录用户询问后的评价结果,也就是用户获得反馈后的满意度,再对用户反馈进行统计,得出总体满意度。
4.3 测试结果分析
采用爬虫框架对用户搜索的500W 条数据进行采集和清洗,提出重复和异常状态数据后,最终得到4352162 条数据投入实验,将此类数据归为数据集D,按照上文所述的设计架构创建智能问答系统。因数据量众多,系统无法逐一检验,因此在集合D 中随机抽出500 条问答进行实验。将系统给予的前5 名反馈答案排序后,由人工对比答案质量,测试系统性能。根据测试结果可知,问答系统检索的最佳答案准确率较为稳定,命中率较高,达到98.35%。在系统性能测试后,本实验还面向10 名用户开展用户测评,每位用户都登录系统,针对特定领域进行提问,并针对系统应用体验进行打分。根据满意度测评结果可知,由75%的用户表示满意,达到预期设计要求。
5 结论
综上所述,智能问答系统带有知识库梳理、问题检索与理解三个模块,可依靠机器学习技术优化系统性能,正确纠正拼写与输入错误,使查询准确度得到极大提升,获得广大用户的好评。在未来的发展中,针对当前问答系统在技术方面存在的不足,还应结合新的使用需求不断完善系统框架,使其更加适用于专业领域,降低耦合性,提高扩展能力,从而为用户提供更多服务。
