一种融合Transformer 和CNN 的印刷体数学表达式图像识别方法
2022-07-11尹锋朱跃生周昭坤
尹锋 朱跃生 周昭坤
(北京大学深圳研究生院 广东省深圳市 518055)
1 介绍
数学表达式是人类知识和智慧的结晶,通过数字和字符就能够揭示自然界不同事物之间的关系。印刷体数学表达式图像识别(Printed Mathematical Expression Recognition,PMER)是光学字符识别(Optional Character Recognition,OCR)技术的一个重要分支。由于PMER 不仅需要从图像中识别所有的符号,而且还需要捕获符号之间复杂的二维结构信息,包括常量表达式、变量表达式、求积分、开根号、复杂分数、矩阵、求和、平方、立方等,而目前的OCR 技术无法处理含有二维结构信息的数学表达式图像。
传统数学表达式图像识别研究主要是基于字符分割的识别方法。1968 年,Anderson在其博士论文中首次提出了关于数学表达式图像识别的研究。在Okamoto等人的系统中,将数学表达式识别分为依据字符投影的轮廓信息进行数学表达式分割、使用模版匹配法进行符号识别以及自顶向下和自底向上的结构分析法。
目前基于深度学习的数学表达式图像识别方法通常是基于卷积神经网络(Convolutional Neural Network, CNN)进行图像编码,基于循环神经网络(Recurrent Neural NSetwork, RNN)并结合注意力机制生成字符级别的LaTeX 字符序列。中国科技大学语音和信息处理国家工程实验室张建树和杜辉等人提出了基于GRU(Gated Recurrent Unit,GRU)的编码器-解码器框架的端到端的数学表达式识别方法,该方法能够识别在线手写体数学表达式,它基于门控递归单元的循环神经网络对输入的二维手写体轨迹进行编码,解码器同样是门控递归单元的循环神经网络在注意力机制作用下完成对数学表达式字符识别和结构分析,最终输出LaTeX 格式的字符序列。2017 年,哈佛大学团队提出的从粗到细的注意力机制来降低计算成本的IM2Markup 模型。2019,密歇根州立大学和学而思教育集团AI 实验室的团队提出了R-Transformer模型,具有RNN和Transformer的优点,同时避免了它们各自的缺点,该模型可以有效捕获序列中局部结构和全局依赖关系,而不需要任何位置嵌入。2019 年,北京大学深圳研究生院的张伟在原有注意力机制的基础上,提出了一种多重注意力机制模型,从而提升了数学表达式识别模型对于数学字符定位的精度。2020 年,华东师范大学的Fu提出了一种EDSL 方法,即编码器-解码器与符号级特征,以识别打印的数学表达式。2021 年10 月,微软亚洲研究院团队等设计和开发了一个高效识别打印和手写文本识别的模型,这是一种端到端的基于Transformer 的OCR 识别模型,它利用Transformer 进行图像的编码和word-level 文本生成,该模型简单有效。虽然该模型是针对OCR 识别,但其思想和方法对于数学表达式图像的识别有一定的参考价值。
尽管以上方法有效并取得了一定的成果,但我们认为,这些方法在解决PMER 问题上可能不是最优的,这些方法存在以下不足:
(1)传统识别方法需要依赖大量的先验知识,需要手动执行符号分割,不是端到端的识别方法。这种方法对于空间结构复杂的数学表达式图像,传统识别方法存在很大的挑战,往往受到字符分割算法和结构分析方法的限制。
(2)基于深度学习CNN 和RNN 的识别方法在处理图像的复杂的二维结构信息上不是最优的。在同一个数学表达式中,相同的符号可以具有不同的语义,对于如下公式(1)所示的数学表达式:

有7 个数字“2”,“2”在不同的位置其表示的意义也就不同。
(3)PMER 需要提供对数学表达式全面的、细粒度的描述。并且现有方法的模型难以并行化,训练时间较长,并且当输入字符序列很长时,由于梯度消失难以捕捉长距离依赖关系。
随着Transformer 在图像处理、目标检测、自然语言处理等领域的成功,Transformer 可以很好的对模型进行并行化训练,并且有捕获数学表达式字符长距离依赖关系的优势,但是考虑到Transformer 缺乏CNN 所固有的一些归纳偏置,比如平移不变性和局部特性,因此,我们提出了一种融合Transformer 和CNN 的印刷体数学表达式图像识别方法,简称TrCPMER,它解决了当输入字符序列很长时,难以捕获长距离依赖关系的问题,同时通过融合CNN增加了模型的平移不变性和更好的提取图像的多尺度的局部特征。TrCPMER 模型由编码器和解码器两个组件组成,编码器组件由CNN 和 transformer 编码器两个模块组成,TrCPMER 编码器组件以细粒度的方式识别符号特征和符号之间复杂的二维空间信息。TrCPMER 解码器组件采用的是标准的Transformer 解码器,将编码后的图像解码为顺序输出的LaTeX 字符序列。
本文的主要贡献如下:
(1)我们提出了一个融合Transformer 和CNN 的端到端的编码器-解码器模型,用于解决PMER 问题。Transformer 可以捕获输入图像的全局特征,CNN 可以提取输入图像的局部特征。
(2)我们在公共数据集上进行了大量实验。实验结果表明,识别性能在多项指标上表现良好,并且提升了模型的训练效率。
2 模型构建
本文遵循标准Transformer 模型的架构,对模型的设计具体描述如下。
2.1 问题定义
对于一个印刷体数学表达式图像x,假设y= <y, y, y,…, y>为LaTeX 文本字符序列,其中y为LaTeX 序列y 中的第i 个文本字符,n 为序列的长度。TrCPMER 的任务是将印刷体数学表达式图像转录为LaTeX 文本序列。因此,TrCPMER 问题可以定义如下:
定义1(TrCPMER 问题):给出一个印刷体数学表达式图像x, TrCPMER 的目标是学习一个映射函数f,该映射函数f 能实现把x 映射为LaTeX 文本字符序列y= <y, y, y, …,y>,使用LaTeX 编译器可以把y 渲染为图像x 中的数学表达式。
2.2 TrCPMER模型
图1 是TrCPMER 模型的总体结构图,它由两个主要组件组成:
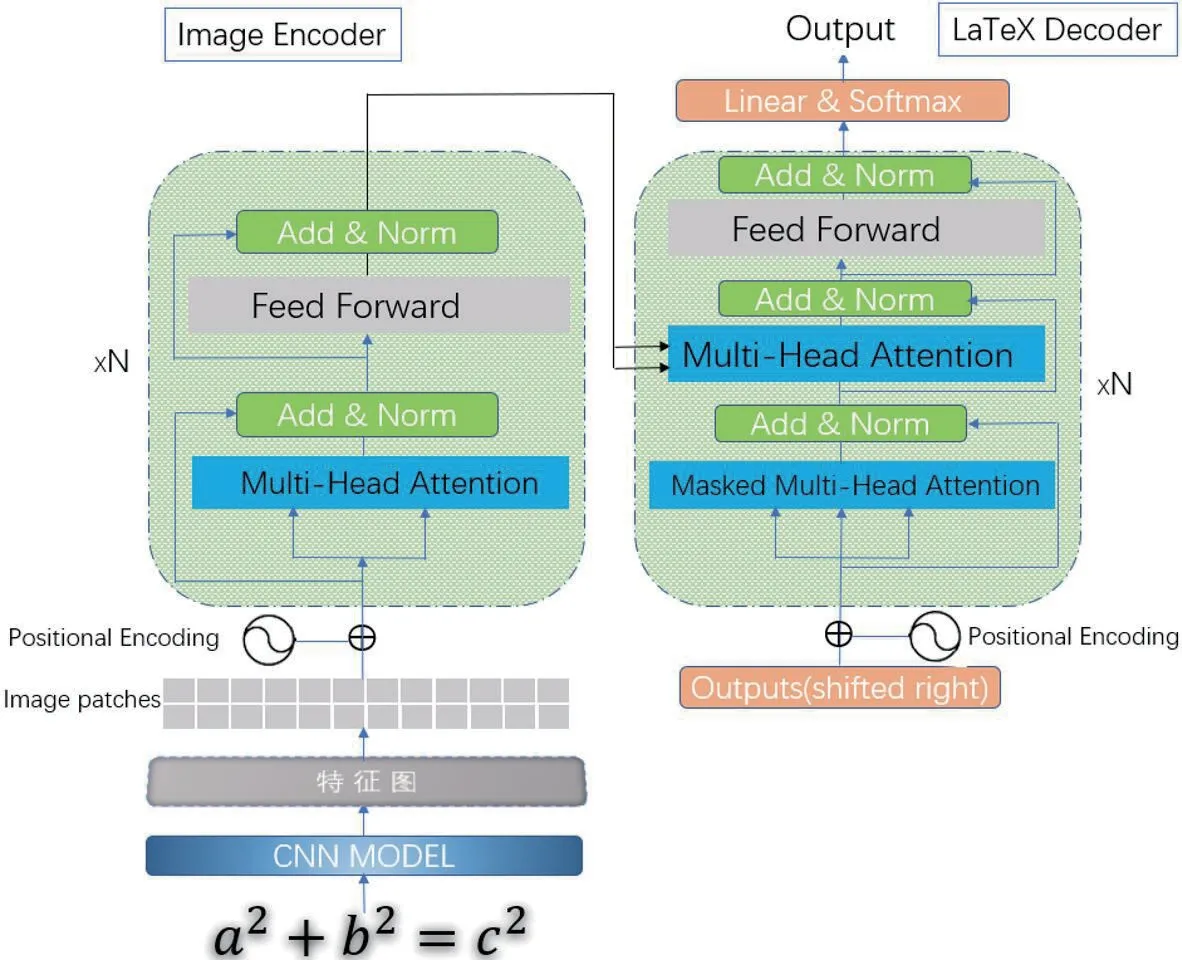
图1:TrCPMER 模型总体结构图
(1)融合CNN 的Transformer 图像编码器;
(2)LaTeX 字符序列Transformer 解码器。
图像编码器组件由CNN 编码器和Transformer 编码器两个模块组成,用于提取数学表达式图像的局部特征和全局特征信息,以及复杂的二维结构空间信息。解码器组件采用标准的Transformer 解码器,用于将编码数学表达式图像转录为LaTeX 字符序列。
2.2.1 CNN 编码器
我们首先将输入的数学表达式图像进行了预处理,图像的大小调整为56×168。由于数学表达式具有复杂的二维空间结构,空间相邻像素通常是高度相关的。然后,我们使用CNN 提取输入图像中数学表达式的视觉特征,CNN 编码器通过使用局部感受野、共享权值来捕获图像的局部特征,从而实现了一定程度的平移、尺度和旋转不变性。此外,考虑到不同复杂程度的局部特征,卷积核的层次结构学习是从简单的低级边缘和纹理到高级语义的学习模式。CNN 编码器由6 个卷积神经网络和3 个最大池化层。每个卷积层的卷积核大小为(3,3),步长为1;而所有的最大池化层窗口都采用核大小为(2,2),stride 为2,padding 为0。图像经过卷积和池化,将输入的数学表达式图像编码生成特征图。
2.2.2 Transformer 编码器
我们首先将CNN 编码器生成的特征图像(H,W)分割为固定大小的patch 序列,作为Transformer 编码器的输入,因为标准Transformer 是不能处理原始图像。Patch 的大小为4×4,因此特征图像被分割成patch 序列数N=HW/P。然后,将patch 序列平铺成特征向量转换为多头注意力机制输入所需要的维度。然后嵌入位置信息,输入到具有相同的编码器层传递。每个Transformer 层都由一个多头注意力Multi-Head Attention、一个全连接前馈网络Feed Forward 和Add& Norm 三个组件组成。对CNN MODEL 输出的特征矩阵进行编码,输出具有上下文信息的特征结果向量。
多头注意力Multi-Head Attention 由8 个Self-Attention组成。Self-Attention 的输入是CNN MODEL 输出的数学表达式图像特征,经过如下三个公式(2)(3)(4)的三个线性变换,得到查询矩阵Q、键矩阵K、值矩阵V。

其中h=8,把8 个head, …, head拼接在一起(Concat),然后传入一个线性层Linear 层,得到多头注意力Multi-Head Attention 的输出矩阵Z。
编码器的下一个模块Feed Forward Neural Network,是一个两层的全连接,第一层的激活函数是ReLU,第二层是一个线性激活函数,可以表示为公式(7):

为了帮助深度神经网络训练更快,加快收敛,在编码器部分引入了残差连接Add 和归一化Norm。残差连接Add 可以让网络只关注当前差异部分,归一化Norm 会将每一层神经元的输入都转成均值和方差都一样。
编码器对图像特征进行编码,输出具有上下文信息的特征结果向量。
2.2.3 LaTex 解码器
本文的TrCPMER 模型使用标准Transformer 解码器。解码器的结构与编码器的结构相似。第一个不同的地方是第一个Multi-Head Attention 层采用了Mask 操作,第二个不同的地方是第二个Multi-Head Attention 层键矩阵K 和值矩阵V 使用了编码器的输出矩阵,而查询矩阵Q 使用了上一个解码层的输出。解码器最后的归一化指数函数Softmax 层用来计算输出字符的概率向量,找出概率向量中最大概率值索引对应的字符作为生成的字符。通过循环解码,从而获得输入数学表达式图像x 对应的LaTeX 字符序列y。
3 对比实验及结果分析
为了验证和评估TrCPMER 的性能,我们在公共数据集上进行了对比实验。
3.1 数据集
为了对我们的模型进行实验,我们使用了公共数据集IM2latex-100k,它收集了一个用LaTeX 编写的真实世界的数学表达式的大语料库。
IM2latex 数据集由103556 张分辨率为1654×2339 的图像、以及相应的LaTeX 公式组成,其中83883 幅图像作为训练数据集,9319 幅图像作为验证数据集,10354 幅图像作为测试数据集。数据标签由LaTeX 文本字符序列组成,符号长度在38 到997 之间,平均118 个字符,中位数98 个字符。
3.2 评价参数
我们的模型的核心评价指标是BLEU评分,用来检测识别出的数学表达式与源图像x 中的真实数学表达式的准确性。Bleu 是双语翻译质量评价辅助工具,是一个评估机器翻译质量的工具。机器翻译结果与专业人工翻译结果越接近,机器翻译的质量就越好。计算生成的数学表达式的思想与计算机器翻译的思想是一致的。BLEU 算法决定两个句子之间的相似度。目前,数学表达式识别通常将原始表达式序列与模型生成的表达式序列进行比较。这与机器翻译的情况非常相似,所以我们借用了机器翻译中的BLEU 评价指标作为参考。一个生成的数学表达式序列与其相对应的原始序列比较,算出一个综合分数。这个分数越高说明模型生成的数学表达式效果越好。该指标不仅能反映数学表达式字符识别的准确度,还能体现数学字符之间的前后关系,因此我们重点使用4-单位片段BLEU 值进行评估。
我们还使用了文本编辑距离准确率Edit Distance 评价指标,文本编辑距离是一个标准的衡量两个字符串之间相似度的指标。此外,我们还使用了检查渲染的预测图像与真实图像的匹配精度Match,我们还使用Match-ws 检查消除空白列后的精确匹配精度。
3.3 模型的实现方法
在我们的TrCPMER 模型中,我们采用了8 头注意力机制的4 层Transformer 编码器和解码器。TCPMER 的嵌入尺寸是256。我们在NVIDIA Titan X GPU 上训练了我们的模型。数据集的批量大小为16,优化器是Adam 算法,初始学习率设置为0.0003。如果在验证时损失函数在连续三个阶段没有减少,学习率就会减半。如果在验证时损失函数在连续50 个阶段没有减少,我们就停止训练。
4 实验结果和分析
通过大量的实验,实验结果如表1 所示,实验结果与deng提出的IM2Markup 模型进行了比较。我们提出的TrCPMER 模型的各项指标都优于IM2Markup 模型,在公共数据集IM2latex-100k 上的实验结果如表1 所示。

表1:在公共数据集IM2latex-100k 的实验结果
实验结果显示,在BLEU 评价指标上达到了90.40%,在符号编辑距离Edit Distance 评价指标上达到了96.18%,在图像匹配精度Match 上达到了86.56%,在消除空白列后的图像精确匹配精度Match-ws 上达到了79.99%。通过实验结果和分析,说明了图像中数学表达式的二维空间结构对识别结果有很大影响。
我们的模型超参数很多,对模型性能影响较大的主要有初始学习率learningRate、训练样本的次数epoch 等,本文拟采用控制变量的方法,在保证其他参数不变的情况下,研究了初始学习率learningRate 对模型的识别效果。通过Bleu和Edit Distance 评价指标随着各个参数的变化,动态地反映了该模型的性能。
如图2所示,当初始学习率0.00006≤learningRate≤0.0003时,对模型的识别精度影响相对较小,但是当初始学习率learningRate<0.00006 时,或learningRate>0.0003 时,该模型的重要指标Bleu 和Edit Distance 产生了很大的变化,当learningRate=0.0015 时,Bleu 仅为17.2%,Edit Distance 仅为37.35%。
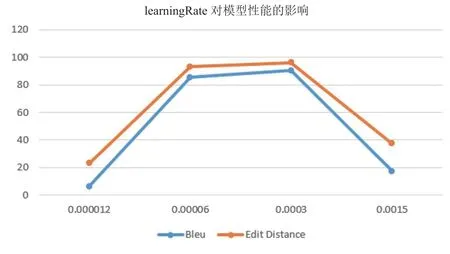
图2:初始学习率learningRate 与Bleu 和Edit Distance 指标
因此,印刷体数学表达式图像识别准确率与初始学习率learningRate 并不是正相关的。当初始学习率learningRate=0.0003 时,模型可以达到更好的性能。
5 结论
本文提出了一种基于融合Transformer 和CNN 的端到端PMER 方法TrCPMER,该TrCPMER 方法简单且有效,不仅可以捕获图像的局部特征和全局特征,而且提升了模型的训练效率和识别准确率。与现有的方法的对比实验结果表明,我们的方法在识别性能的评价指标BLEU、Edit Distance和Match 上分别达到了90.40%、96.18%和86.56%,相应提升了3.04%、9.79%和11.75%。未来的可能研究方向包括:构建更优的CNN 编码器、更优的位置编码算法、优化Transformer 编码器、手写数学表达式识别等。
