递归U-Net 超分辨生成对抗网络
2022-07-11杨斌李桐解凯
杨斌 李桐 解凯
(北京印刷学院信息工程学院 北京市 102600)
1 引言
近年来深度学习的超分辨重建方法已成为主流。用神经网络进行超分辨重建主要可分为两类方法:一类是训练神经网络去拟合低分辨率图像空间与高分辨率图像空间的映射关系,可以将其概括为非线性映射法。它的特点是使用单一网络,通过不断优化减小损失函数的值,确定网络是否拟合分辨率映射空间。典型的网络结构有SRCNN、ESPCN、VDSR和EDSR等;另一类是训练一组神经网络从低分辨率空间生成合理的高分辨率像素,使用另一组神经网络判别生成图像是否和原始图像相近,通过判别网络学习带动生成网络学习,改进生成网络重建图像质量,可以将其概括为生成法。它的特点是使用两个或多个神经网络,以判别神经网络监督生成网络重建图像质量。如采用生成对抗网络(Generative Adversarial Net-work,GAN)结构的SRGAN,ESRGAN,RankSRGAN和SPSR。非线性映射法在重建过程中可以取得更高的峰值信噪比(PSNR)与结构相似性(SSIM),但重建图像的细节方面较为平滑。采用GAN 结构的生成方法通过生成网络与对抗网络博弈的方式重建的图像在细节方面更接近人类视觉感知。
SRGAN 与ESRGAN 在生成网络设计与改进中并未考虑利用合适的网络结构对图像先验信息进行学习。超分辨重建以像素作为研究对象,在生成模型中最大化利用低分辨图像的像素信息,使其以像素图像块的形式重建,既可以保证生成图像重建的真实感,也提高了重建效率。因此,使用学习图像先验信息更优的网络结构重建有重要意义。且随着生成网络先验学习能力增强,沿用SRGAN 的判别模型会过早失去对样本与生成图像的判别能力,导致模型坍塌,失去对抗性,使得判别模型结构上也需要改进。
本文在第2 部分将Deep Image Prior(DIP)的方法进一步设计,证明不同网络结构对图像先验的学习能力有差异。程德强等已经使用一种递归结构的U-Net 提升了超分辨重建质量。通过对比残差结构网络与递归结构U-Net 网络对图像先验的学习能力,递归U-Net 网络结构在学习图像先验能力更出色。在第3 部分网络设计中使用递归结构的U-Net作为GAN 的生成器进行图像重建,使用残差结构改进原VGG 结构的判别网络,增强判别网络的判别能力。第4、5部分为实验结果与总结。
2 生成模型图像先验学习能力分析
研究者通常认为神经网络生成真实图像能力来自于学习了大量示例图像的真实图像先验。DIP 中,首先对神经网络随机初始化,通过均匀分布生成的噪声经过网络传播后模拟图像的退化过程,并将退化后噪声与真实退化图像用反向传播的方式进行学习。噪声在迭代中逐渐变成未退化的图像(如图1)。整个过程并没有使用大量示例图像,只用真实的退化图像即得到未退化图像证明了神经网络自身可以学习到大量低层次的图像先验信息。神经网络经过长时间发展已设计出多种结构。由于不同神经网络的结构差异以及参与图像处理的任务不同,作为生成网络在学习图像先验的能力上必然会存在差异。
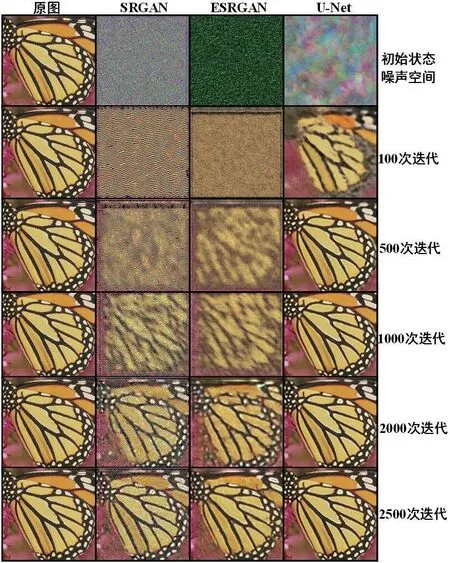
图1:三种网络对butterfly 学习结果


在模拟退化过程中,噪声n 会经历两步变化。第一步生成网络会生成未退化的图像,即超分辨任务中的高分辨率图像G(n)。第二步为学习图像的退化过程,即下采样G(n)成为品质接近于x的低分辨率图像。在整个过程中,使用不同结构的G(n)即可对比不同生成网络学习图像先验信息的能力。当噪声通过不同结构的网络学习高分辨率退化图像时,受限于不同结构对图像先验信息的学习能力,亦或者说网络捕捉真实图像的概率分布能力与捕捉低分辨率图像细节能力存在差异,不同网络在一定的迭代次数下生成高清图像的速度与质量也存在不同。
由公式(1),分别对SRGAN、ESRGAN 的生成网络与递归结构的U-Net 做比对实验。低分辨图像LR 用插值法的对原始图像进行4 倍下采样得到。为了更好的观察噪声在网络传播,将SRGAN 与ESRGAN 生成模型中用于对低分辨率图像上采样到高分辨率图像的模块移除,并对ESRGAN 生成网络增加BN 层,使三种结构的对比条件一致。网络迭代次数为2500 次。
网络在学习过程中,噪声PSNR与SSIM变化情况如图2。
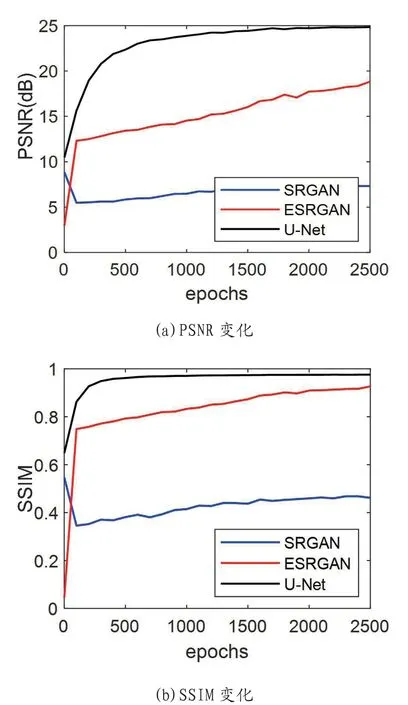
图2:三种网络学习图像先验PSNR 与SSIM 变化
经过2500 次迭代后,最终生成图像的指标结果:
从过程图1 与表1 来看,在重建图像时,使用递归结构的U-Net 迭代收敛速度最快,生成图像质量最高。ESRGAN次之,SRGAN 的生成模型最差。ESRGAN 与SRGAN 均是残差结构的网络,区别是ESRGAN 加入了密集连接结构。递归U-Net 模型的表现最好,证明了该结构的网络提取图像先验信息的能力优于残差结构。
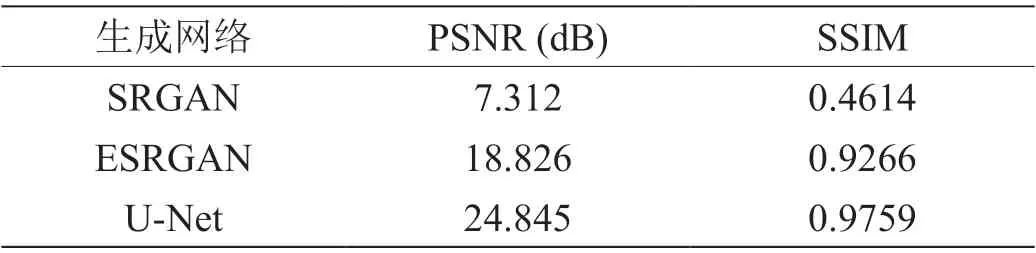
表1:三种网络学习先验最终指标
3 递归U-Net生成对抗网络
3.1 损失函数设计
网络损失函数参考了彭晏飞、张中兴等人的设计方法,对SRGAN 的损失函数进行改进。除了SRGAN 的内容损失与对抗损失外,还加入全变差损失(TV Loss)。全变差损失可以抑制生成器中噪声的污染,但代价是增加图像的空间平滑性,所以在损失函数里权重不宜过大。此时生成网络损失函数可表示为公式(2):
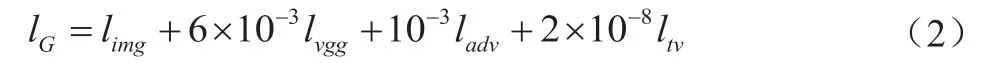
式中,l是图像的像素的MSE Loss,l是经典SRGAN 网络中提出的一个为防止MSE Loss 生成纹理过于平滑的更符合感知效果的损失函数。本文用VGG19 网络作为l。l与l合起来即为重建过程的内容损失,l是SRGAN 网络中提出为更好欺骗判别网络其改进生成图像细节的对抗损失,l为全变差损失。
各损失函数的具体公式如下:

上述各式,l中s 为上采样因子;l中H,W为所采用的所述判别网络相应特征图的高度与宽度, 为在经过第i 次池化前,通过第j 次卷积后的特征图运算;l中β 为TV Loss 的可调参数,当β<1 时容易生成图像伪影,β>1 时,图像会更加平滑。
3.2 U-Net—残差生成对抗网络模型
3.2.1 生成网络模型
U-Net于2015 年提出,是一种快速精确进行图像语义分割的网络。由第2 部分的分析表明,递归形式的U-Net可以将不同深度的图像特征进行融合,学习更多的图像先验信息。ESRGAN 中使用残差-残差密集块结构(RRDB),表明通过密集连接结构能将更多低分辨率图像特征在传播过程中补偿,重建图像的细节质量会更好。本文的U-Net 网络在设计上使用递归的方式,同时加入了跳跃连接结构,补偿每一层深度下丢失的特征信息。
在网络上采样方法的选择中,通常可以采用插值、反卷积、亚像素卷积等多种方法。经典U-Net 结构选择插值法对低分辨率图像进行像素填充。使用插值方法会导致上采样后图像过于平滑,不利于图像重建。亚像素卷积以像素块形式填充,避免上采样后图像平滑。由于用图像块填充,使其上采样后的图像存在明显的棋盘效应。在设计上,本文通过增加网络第一层卷积输入通道数来进行抑制。如图3,当输入通道数为16 时,重建图像有明显的棋盘效应,而随着输入通道的增加,在输入通道数为128 时,网格更加细化,棋盘效应会显著减弱。除此之外,相较于插值法,亚像素卷积的计算量更小。为提升重建图像的细节质量与重建效率,本文U-Net 中所有上采样方法均采用亚像素卷积。

图3:不同输入通道重建结果
将上采样模块放置在前端时,使整个过程中学习到更多的原图先验信息,扩充的特征图通过网络学习到原图像素排列的映射关系,保证生成图像结构与原图一致,并在细节上越来越接近于真实图像。在网络结构中最后输出卷积层的卷积核尺寸选择上,不同尺寸也会对重建图像细节产生影响。为更有效抑制亚像素卷积带来的棋盘效应,为了让图像更自然,本文将最后的输出卷积核尺寸设为3。U-Net 生成网络结构如图4。其中k 表示卷积核尺寸,n 为特征图数量,s 为卷积步长。
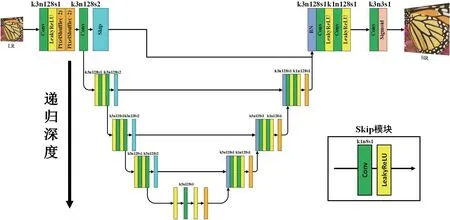
图4:递归结构U-Net 生成网络模型
3.2.2 判别网络模型
在生成模型训练效率超过判别模型效率时,判别模型会更早的达到判别极限,起不到博弈的作用,导致模型崩塌。SRGAN 判别网络采用VGG 网络结构实现。通过VGG 将图像层层降采样,得到图像高级细节特征。最终通过对这些特征的分类,得到真实图像与重建图像的分类概率。递归结构的U-Net 生成网络通过学习图像先验使其在训练效率上高于SRGAN 的生成结构。仅在少次数迭代学习中,判别网络就无法对生成图像与真实图像进行分辨。因此需要对原始模型进行改进。
为提升判别网络的效率,需要得到深层的高级特征或者更多细节特征对生成图像进行判别。本文在VGG 结构的降采样模块前增加残差结构,通过加深网络层数使判别网络提取到更深层的高级图像特征。相较于前者的7 层网络结构,改进判别结构的网络深度增加到了14 层。同时,残差网络的结构特点在于使用残差进行特征补偿,使经过残差块的退化信息的通过补偿流入到下一个残差块。既提高了信息流通,也并且避免了由与网络过深所引起的消失梯度问题和退化问题。通过加入残差结构的改进,图像在重建过程中学习到更高质量的细节。改进判别网络结构如图5。

图5:改进的残差结构判别网络模型

表4:五种数据集不同方法重建SSIM 指标
4 实验与结果分析
本文的实验环境,硬件环境:Intel(R) Core(TM) i7-7700 3.6GHz 处理器,16G 运行内存,NVIDA GeForce GTX 1080(8G)显卡。软件环境:Windows10 操作系统,搭载Python 3.8 版本的Anaconda 4.8.5。深度学习框架为Pytorch 1.6。
4.1 实验过程
数据集方面,本文选用了PASCAL-VOC2012 作为训练集,将超分辨重建常用的Set5 作为验证集。网络参数采用Adam 方法进行优化,初始学习速率(Learning Rate)为10,指数衰减率(遗忘因子 )为0.9。所有Leaky ReLU 函数的超参值设为0.2。训练的迭代次数为500 次。为方便称呼,将本文设计的网络称为USRGAN。
在开始训练前,也需将数据集做预处理。先将数据集中的图片随机裁剪成88×88 的小块作为真实图像标签保存,再通过双三次插值的方法将标签图像缩小4 倍,作为网络输入。在同样迭代训练500 次的条件下,将SRGAN 的训练过程和USRGAN 过程比较,最佳数据如表2 所示。

表2:SRGAN 与USRGAN 训练最佳指标
得益于递归结构U-Net 对图像先验的学习能力,递归结构U-Net 作为生成网络可以达到更低的网络损失。整个训练过程的验证集指标表明,相比于SRGAN,同条件训练过程下的USRGAN 在验证集的PSNR 与SSIM 指标明显好于前者。
4.2 实验结果分析
本文在5 个公开的数据集Set5、Set14、BSDS100、Uraban100 以及Manga109 中测试模型重建效果。以4 倍的放大因子作为基准进行图片重建,并与经典的SRCNN、EDSR 网络结构,流行的超分辨生成对抗网络SRGAN、ESRGAN、RankSRGAN 的重建结果的PSNR 指标、SSIM指标进行对比。对比结果在表3 与4。

表3:五种数据集不同方法重建PSNR(单位:dB)指标
在PSNR 方面,以递归结构U-Net 为生成模型设计的GAN 在重建性能上有显著提升,在所有网络中表现最佳;在SSIM 指标中,递归U-Net 生成网络也在多个数据集中展现了更优秀的表现。这种结果得益于U-Net 网络在图像先验提取中的出色表现。USRGAN 在重建细节质量仍然存在部分棋盘效应现象,较ESRGAN 与RankSRGAN 有差距,但与经典的SRCNN、EDSR 这些非线性映射网络相比,通过GAN 方法重建,图像细节质量有明显优势。
从Set5、Set14、BSDS100 以及Urban100 中选取图片,使用USRGAN 与其他网络在4 倍采样因子下重建结果如图6。重建图片上可看出USRGAN 在细节上与原图细节近乎一致,这也使USRGAN 在PSNR 与SSIM 指标上相较于其他网络表现出更稳定更优秀的性能。
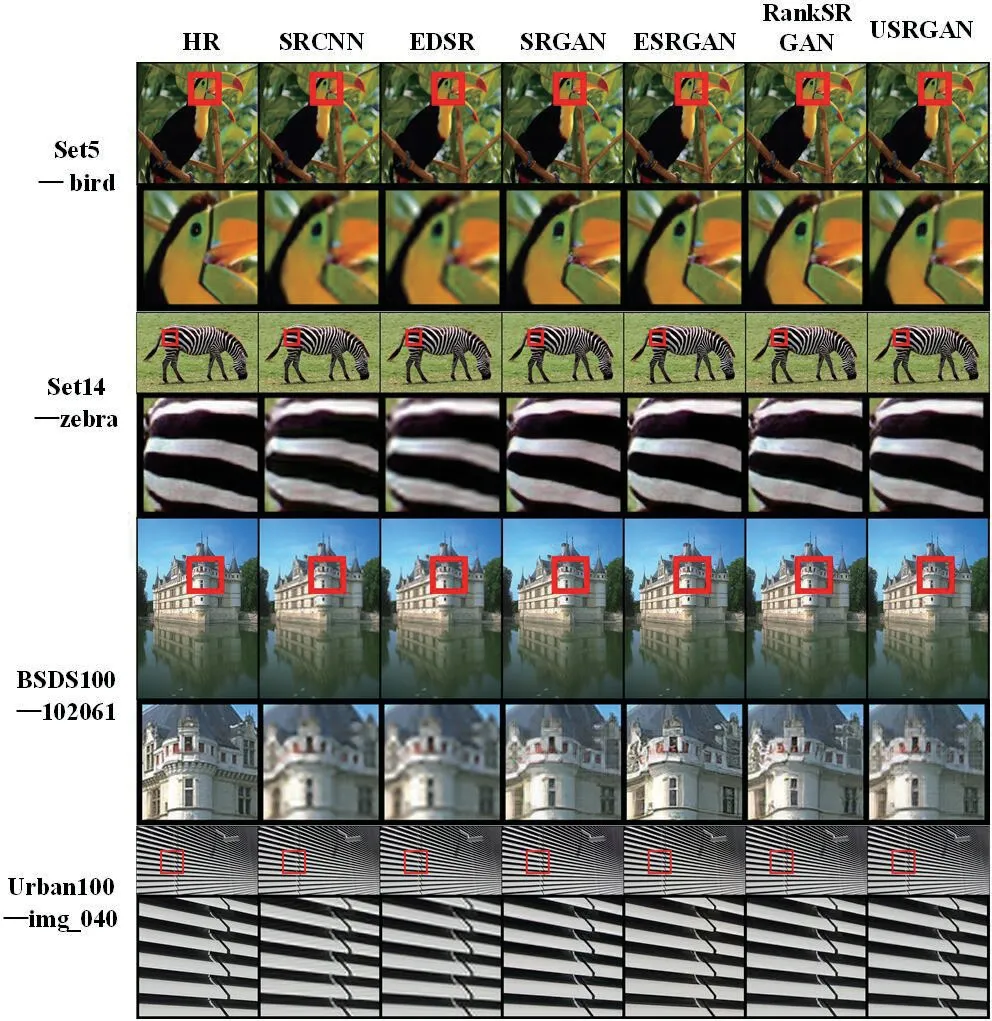
图6:不同重建方法重建图片(×4)
5 结语
本文对比了超分辨中残差结构网络与递归结构U-Net 网络对图像先验的学习能力,提出使用学习图像先验能力更强的递归结构U-Net 网络作为超分辨生成对抗网络生成器;为强化判别器对生成图像与真实图像的细节判别,引入残差结构改进SRGAN 的判别器。实验表明将递归结构U-Net 作为生成对抗网络的生成模型可以有效提高图像重建的PSNR 与SSIM 指标,并获得更加真实自然的细节。以Set5,Set14,BSDS 等五种标准数据集作为基准,在PSNR 指标上平均提升0.656dB,在SSIM 指标上平均提升0.02。在保证重建细节真实自然的前提下,得到质量更好的图像细节是本设计结构后续改进的重点。此外,本文对比不同网络结构学习图像先验的能力的实验,也为后续选择有更强的学习图像先验能力的超分辨生成模型提供了思路。
