基于CNN 的图像分类
2022-07-11张雪晴
张雪晴
(长江大学电子信息学院 湖北省荆州市 434023)
1 图像分类
人工分类的时间和速度有很大的不确定性和不稳定性,若图像种类和数量都很多的情况下,采取人工分类的方法耗费人力和时间,不如利用计算机的处理速度和稳定性来代替人工人类。图像分类技术是计算机视觉任务的基础。与深度学习相结合的图像分类技术,要经过图像预处理、特征提取和分类这三步骤。首先用三种方法中的一种或几种对图像做一些预处理;然后根据三类特征用相应的算法进行提取;经过一系列的特征向量的变化,最后在分类时分二分类或多分类,输出一个值。
(1)图像的预处理在有很重要的地位,因为图像的质量会影响了后面模型的需完成的任务,例如分类、识别或者分割等技术的实现。预处理主要包括是三个部分:
1.灰度化,在RGB 图像转为灰度化的图像时对应的值叫做灰度值,还可以叫强度值或亮度值,灰度值取值区间为[0,255],而在其的颜色空间之中,R、G、B 都为零时,是黑色;都为100 时。是灰色,而为255 时是白色,在这种R、G、B 的值都相等的时候,图像是在黑白灰三种颜色中过渡。灰度化方法一般会用:最大值法、平均值法、加权平均法等。
2.几何变换也叫图像的空间变换,它对图像进行平移、镜像或转置等处理,使得在样本不足的情况下,用这种方法增加样本,来增加图像分类模型训练后的正确性,减少误差。然后用图像插值方法。线性插值方法主要分为两种:线性插值:最近邻插值、双线性插值、双三次插值。和非线性插值:分为两类——基于小波系数、基于边缘信息(分为显示方法、隐式方法,其中隐式方法包括:NEDI、LMMSE、SAI、CGI)。
3.增强图像:可以增强图像的观感。通过增加一些,图像中包含的有用或重要的信息,但它同时可能在这个过程存在失真情况。比如在一张图像中,对图像中存在的一些特殊事物或特殊动物和人,进行强调或扩大这些不同物体和动物之间的特征差别;将原本有些模糊的图像变清晰等的调整,去丰富图像中的某些蕴含的信息量;也可以将图像识别的效果增强,或对图像进行一些特殊分析。图像增强主要是在频域和空间域这两种域上对图像进行处理。在频域上处理时,一般是采用低通、高通或同等滤波方式;在空间域上的处理,分为两大类:一个是点运算,对图像单个像素点邻域处理,比如灰度变换、直方图修正、伪彩色增强等技术;另一个是模板处理,对图像的像素领域处理,比如图像平滑、图像锐化等技术。
(2)从图像中提取的特征蕴含着一些信息,在通过分类器的时候,这些信息作为分类器进行分类的基础,而这些信息的种类或质量,都可能使该网络的分类任务准确性和分类任务的效率有变化。图像特征大概分为视觉特征、统计特征和变换系数特征两种。
1.视觉特征:包括图像中的各种颜色和物体或动物之类的轮廓、花朵之类的外表纹理还有各种物体的形状等特征。
2.统计特征:利用统计方法获得统计信息特征,例如图像的矩阵、峰值、方差和灰度直方图等特征。
3.变换系数特征:利用数学的一些数字变换方法获得的特征。比如用小波变换、傅里叶变换等方法获得的特征。
提取不同特征时的算法不同。例如,canny 或sobel 算子提取的轮廓边缘特征;PCA 主成分分析算法提取的主要成分信息特征。只有在更加深入地研究过关于图像特征的一些理论后,提取特征的算法将发展成将多个特征融合与多种提取方法结合的方式。
(3)二分类算法:二分类的图像分类问题是一类常见的问题,这种分类的在分类器的标签取值只有两种,而且算法中只需要一个预测的标签。即每个样本的类别可能性只有两个(0 或1)。此时的分类算法就像在画一条线,这条线将数据划分为两个类别。常见的二分类算法有:Logistic、SVM、KNN 等。
Logistics 算法:对于维度是m+1 特征是x 样本的二分类问题,有负类记作0,正类记作1.则对类别y 如式:y=f(x),y∈{0,1},找到一个h(x),使0 ≤h(x)≤1,其中θ 是待优化的参数,在对未知类别的样本x分类时,h(x)指样本是正类的概率。即:


(5)模型评估
首先,在分类过程中会出现四种分类情况,如表1 所示。

表1:分类情况
假设,A 和B 两类,任务是分出A 类,那么A 类就是正类。表1 中,TP:被模型预测为A 的A 类样本;FP:被模型预测为A 的B 类样本;FN:被模型预测为B 的A 类样本;TN:被模型预测为B 的B 类样本。


2 卷积神经网络架构
简单的卷积神经网络如图1 所示,由输入层、卷积层、池化层、全连接层和输出层五种构成的网络,下面介绍了层结构的每个部分:
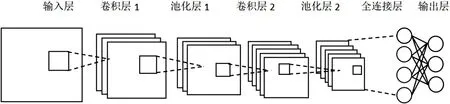
图1:简单卷积神经网络结构示意图
(1)输入层:输入原始数据。在图像分类任务中,将图像像素值作为模型的输入。
(2)卷积层:提取输入层的输出数据的特征图。如图1 所示,每个卷积层都会提取若干特征图,特征图的神经元都都与前层中的相邻神经元相互连接。前层相邻的神经元区域就是该层特征图的感受域,将经过卷积运算的特征图通过激活函数激活。在每层的卷积层进行卷积运算时,运用不同的卷积核会获得新的特征图,并且这些卷积核会进行权值共享。而这些激活函数的作用就是让卷积神经网络拥有非线性的特征。常用的激活函数有sigmoid,tanh 和ReLU。
(3)池化层:也叫做下采样层,输入是卷积层的输出,一般的池化层都在两个卷积层之间。池化有两种形式,一种是最大池化(max-pooling),选择固定的区域内的最大数来表示该固定区域;另一种是平均池化(mean-pooling),选择固定的区域内的平均数来表示该固定区域。
(4)激活层:常用的激活函数有sigmoid。
(5)全连接层:卷积神经网络在一些卷积层和池化层后,通常情况会跟着一个或多个全连接层。全连接层和前面一层的每个神经元相连,然后在全连接层中,将前面的一层的输出向量转化成一个列向量。
(6)输出层:在该网络模型中的全连接层的最后一层,一般是接着一个输出层。在分类任务上,输出层会用softmax 回归。例如多分类问题的处理用的是softmax 回归,类标签的取值是两个以上的数值就是多分类问题。
3 卷积神经网络的训练
当样本足够的时候,该网络的训练分两个阶段:前向传播和后向传播。
(1)前向传播,第一步:选择数据集,分好训练集和测试集(有时会有验证集)。第二步:随机初始化网络中的权重和偏置项还有样本误差值,手动设定初始的学习速率。该网络中学习率能够左右权值的调整过程中上浮或下降的程度。当比如学习率过大的时候,有可能错过权值调整过程中的最优值;反之,则可能使得网络只获得局部最优。手动设置初始化学习率的时候,研究人员要有很强的经验,所以一般情况是倾向于选取较小的学习率来保证系统的稳定性,但对于要完成的不同任务需要的设定会不一样,该取值范围一般在区间[0.1,0.8]。第三步:将训练集的样本的数据向量输入到网络,该向量从输入层到输出层经过每层的处理不停地变换。该网络中的么层的权值不同,当该向量经过一层时,都与当成的权值矩阵进行点乘运算,然后与偏置项相加,输出变化后的向量矩阵,通过网络的每层都重复运算操作,一直到最后的输出;
(2)后向传播,第一步:用极小化误差的方法,根据样本的实际输出值和预测输出值进行误差阈值的计算,然后将该误差值一层层的反向传播,根据误差值来调整每层的参数。第二步:将调整后总的误差值和误差域值相比较,若前者大于后者,那么网络没有达成任务目标,接下来返回到前向传播的第三步。反之,则可以接着进行下一步。第三步:训练学习任务完成,得到训练好的一个卷积神经网络并保存该网络的参数。
4 实验结果分析
CNN图像分类流程图如图2所示:首先读取已知图像(训练集)和标签信息,对已知图像和标签数据进行预处理,将图像剪裁相同尺寸;然后提取特征图,数层卷积池化层来进行对特征图的处理;接下来就是训练学习至目标模型并保存。对未知图像(测试集)也进行前两步的相同处理,然后根据目标模型内保存的参数进行对比,再通过分类器分出多个类别。
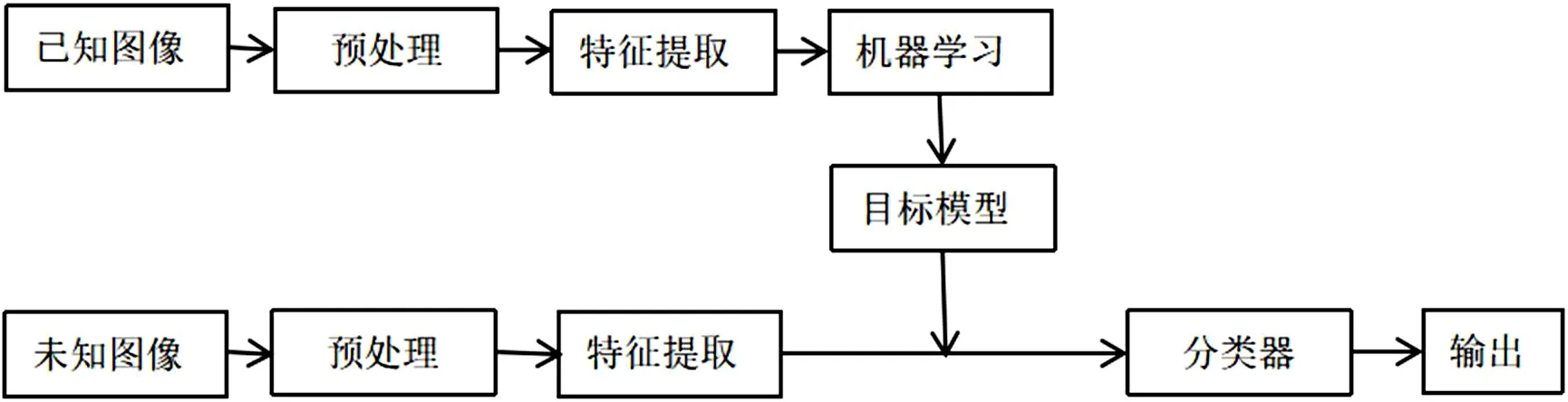
图2:图像分类流程
总的图像数据集共6600 张图,其中训练集,验证集和测试集比例是7:1:2。训练集和验证集的损失率和准确率如图3,横坐标表示epoch 迭代次数,纵坐标表示概率。绿色线loss 显示的是训练集的损失率变化,从图3-4 中可以看出训练集的损失一直下降到0.2 左右;红色的线acc 显示的是训练集的正确率变化,从图3-4 中可看到正确率逐步上升至0.9 上一点;蓝色的线val_loss 显示的是验证集的损失率变化,可看出验证集的损失率下降到0.4 后就没有再下降了,下降缓慢;橙色的线val_acc 显示的是验证集的正确率,从图中可看出验证集的正确率接近但不到0.9。

图3:准确率和损失率
测试集的各类别召回率,f1-score 和准确率如图4 所示,出错概率较大的类别3,4,6 和10,但总体的准确率维持在90%。看到图像集,结合测试集分类结果的召回率,f1-score可知类间差别较大,图像较复杂(一张图上同时有人和狗如类别3 里的图像或同时有街道,汽车图类别10 里的图像)会比图像简单(只有人脸如类别8 或者向日葵如类别5 等)的出错概率大,就像类别10 是马路的图,因为里面会有车子或房子可能会被识别到类别1 汽车。而这几个类别的召回率和f1-score 值都不高,则说明正确判断的样本数不多,但是图像集中不是所有的类别里面只有一个突出的物体或者动物,那么混起来分类只有简单图像的分类准确度是很高的,而复杂图像或图像里蕴含信息多的时候,分类的结果就不够好了。

图4:召回率,f1-score
5 图像分类总结
本文主要介绍的是基于卷积神经网络的图像分类研究。首先介绍了图像分类在当今社所研究的必要性,其次介绍图像分类之前的预处理操作,以及分类图像所涉及的算法。本文主要选取的图像分类算法为卷积神经网络算法,详细介绍其原理,并设计基于CNN 的图像分类实验,实验结果表明CNN 在图像分类中能够起到很好的识别作用,准确分类出图像的类别。但是CNN 与其他的神经网络类似,实验结果需要庞大的数据支撑,并且实验结果具有不稳定性。因此本文下一步研究内容是尝试其他的分类算法,与CNN 算法进行对比,设计出一种较为稳定的识别模型;或者进行多标签分类,能够提高复杂图像的类别分类的正确性。
