片上路由器中存储设备容量与路由器性能的分析与优化
2022-07-11蒋海雁
蒋海雁
(沈阳工业大学信息科学与工程学院 辽宁省沈阳市 110870)
1 绪论
自20 世纪90 年代末引入多核处理器以来,片上网络逐渐进入人们的视野,成为备受关注的片上多核通信互联架构。随着半导体工艺的迅速发展,芯片上集成的晶体管数量可高达上亿、几十亿,数目如此庞大的晶体管数量如何被高效地应用于芯片上对研究人员来说是个难题。传统的总线型架构带宽低,扩展性差,无法满足未来多核处理器的高性能需求。而片上网络的出现无疑是给多核处理器提供了一种有效的方案,片上网络能够便捷的提供可扩展的带宽及较高的通信效率,使用全局异步局部同步时钟策略解决了全局同步的难题。综合来看,片上网络与总线型架构相比在性能上具有明显的优势,正逐渐成为多核处理器首选的互连架构。此外,片上网络独特的通讯协议和拓扑结构有也利于研究人员在此基础上进行创新设计从而提升片上网络的相关技术。作为多核处理器时代的一个重要研究方向,片上网络对于解决处理器之间的通信瓶颈,及提高处理器的内存性能有着极大的意义。图1 展示的是片上网络的微结构视图。

图1: 片上网络体系结构
由图1 可见路由器在片上网络的硬件结构中扮演极为重要的位置,承担了主要的通信功能,直接决定了网络的传输延迟,同时路由器也是片上网络能耗和面积的主要消耗者。传统路由器的流水线是基于数据微片(Flit)层次的,将数据包进一步划分为流控制数字,再对其进行流控制,数据微片也是分配链路资源、缓冲区资源的基本单位。图2 展示的是路由器的结构设计,传统路由的内部组成包括输入缓冲区、路由计算单元、交换机分配器、虚拟信道分配器和交换机。

图2: 路由器微结构
在传统路由器的数据传输流程中,会执行以下操作:缓冲区写入(BW)、路由计算(RC)、虚拟信道分配(VA)、交换机分配(SA)、交换机遍历(ST)、链路遍历(LT)。路由器内部可以根据这些操作大致划分为数据路径和控制路径两部分,数据路径是由交换机和存储设备组成,负责路由内数据包的存储和移动;控制路径则是由路由内其他组件组成,负责控制协调数据包在数据路径中的移动。路由的存储设备在路由内的耗电占比极高,根据国外学者的研究可知,在低负载时,存储设备所消耗的静态功率在总静态功率中的占比超过了75%。在高负载时,存储设备约消耗了总动态功率的55%,而静态功率则是消耗了53%以上。由此可见,存储设备是路由的主要电能消耗元器件,也是数据传输的关键路径,故本文针对路由器内部存储设备容量的变化进行了研究分析,以厘清存储设备容量与路由性能之间更深层次的关联,并对不同存储设备容量的路由的网络适用范围进行了探索。基于这些探索,本文详细论述了如何针对网络数据流的特点优化能效比并改进路由器的设计与结构。
2 实验方案设计
2.1 路由器存储设备容量设置
传统路由器的存储设备使用的是单读写端口的内存,每块内存作为输入单元与输入端口绑定。本文研究了三种存储设备容量下的传统路由,分别是1VC 路由、2VC 路由、4VC 路由。图3 展示了三种路由的存储单元容量设置,三种路由的其他部件一致,故缓冲区数量也侧面展示了三种路由的面积差异。
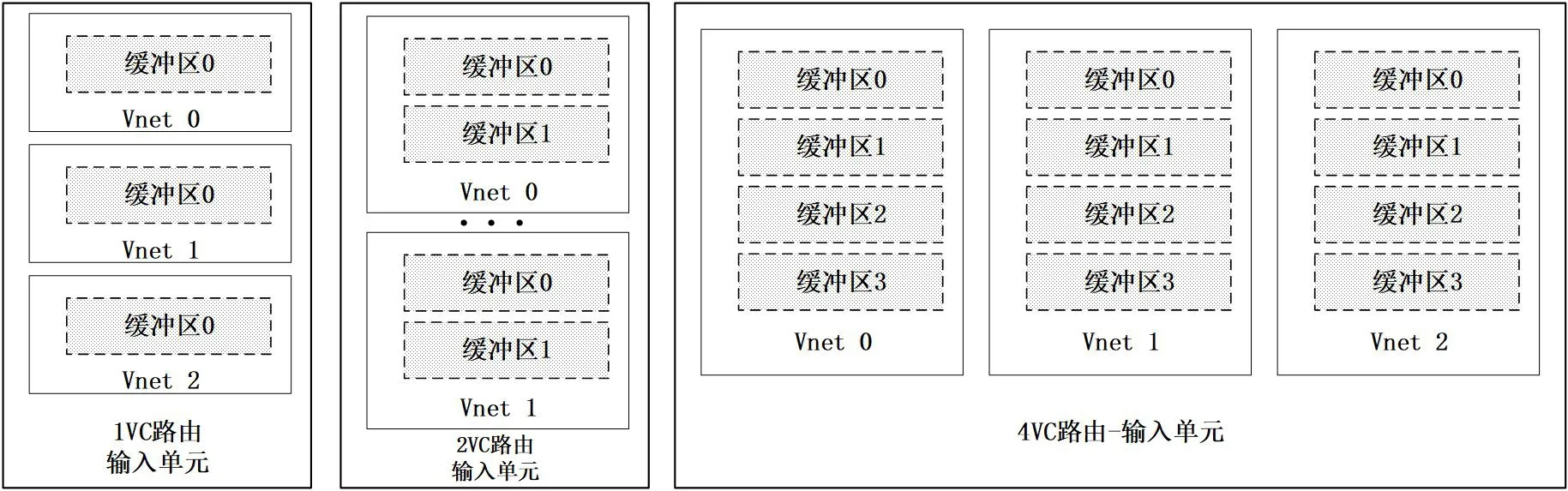
图3: 路由的存储单元设置
2.2 仿真平台及实验参数
本文使用的仿真平台GEM5是一个模块化离散事件驱动的计算机系统模拟器平台,该系统将时间的流逝模拟为一系列离散事件。GEM5 功能强大,可以模拟一个或多个计算机系统,并能使用预制组件来组建模拟系统,有利于研究人员扩展计算机体系结构的相关设计。在GEM5 仿真平台上,本文使用的网络模型是Garnet,片上网络设置的是4 乘4 的Mesh 拓扑结构,共有16 个处理单元,路由算法采用的是X-Y维度有序路由算法。片上网络的每个处理单元由IP 核、缓存、路由、目录组成,其中路由是实现处理单元之间通信的关键部件。网络外部的数据流是从网络接口注入路由,经过传输路径上的路由后到达目的节点,至此数据传输结束。最后表1 展示的是本文相关实验使用的仿真系统实验参数。
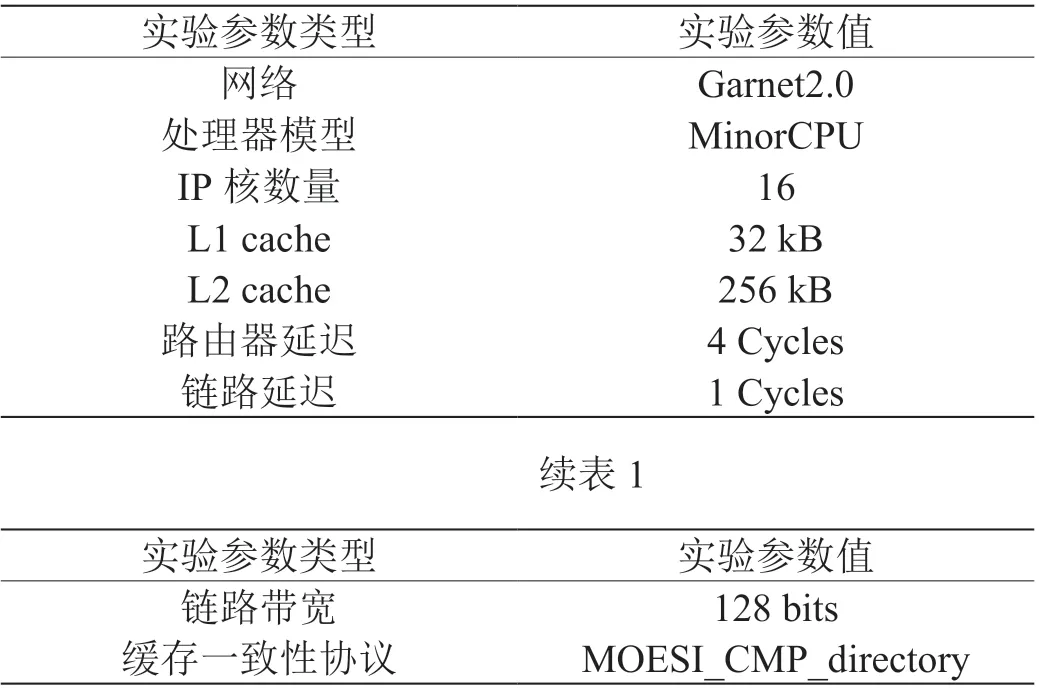
表1: 系统实验参数
2.3 性能评估指标
延迟和带宽作为重要的片上网络性能评估指标,能反映出不同方案下的网络性能优劣。延迟表示的是数据微片从源节到目的节点期间所经历的总周期,是数据微片在网络里所消耗的时间,延迟越低则说明通信效率越快。带宽表示的是单位时间内网络能传输的数据量,带宽越高就代表数据传输能力越强。此外,能耗也是片上网络性能提升的首要限制因素,根据这3 个指标可以对片上网络进行细致的评估。
3 基于Parsec应用程序的实验结果
本文使用的流量负载是PARSEC应用程序集,PARSEC 是适用于多核处理器未来功能改进的测试集,且支持并行模型,用于实验可有效评估多核处理器的性能。PARSEC 程序集包括了不同领域的工作负载,每个类型的应用程序都具有一定的代表性。PARSEC 应用程序提供了仪器、操作和执行所包含的程序详细模拟的基础设施。
文中实验选择的PARSEC 应用程序是blackscholes、canneal、ferret、freqmine、x264。每个PARSEC 应用程序有5 种输入大小设定,分别是:Test、Simdev、Simsmall、Simmedium、Simlarge。其中Test 和Simdev 输入小只能用作简单的测试,不适用于仿真实验。本文使用的输入类型是Simsmall 和Simmedium,这两种输入都适用于仿真实验,并能取得有效的实验结果。
基于这8 个PARSEC 应用程序得到了不同存储设备容量路由方案下的片上网络平均延迟,如图4 左上所示。将基于三种存储设备容量路由的网络延迟进行对比可知,1VC 路由的延迟明显高于2VC 路由、4VC 路由,2VC 路由次之,4VC 路由则是整体上延迟低于2VC 路由。1VC 路由由于缓冲区容量有限,限制了网络的带宽,所以延迟相对来说最高。综合延迟数据来看,4VC 路由的延迟最低,通信效率最好。
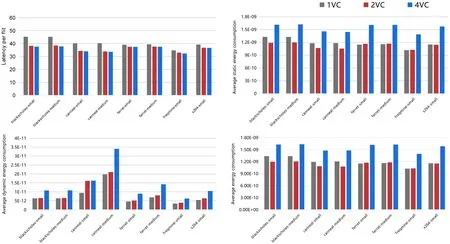
图4: 不同方案下的片上网络延迟与能耗
McPAT是一个集成功耗,面积和时序建模的框架,能精确建模多核和众核处理器,并同时建模和评估功率、面积和时间,精确地将电路模型扩展到深亚微米技术。McPAT支持90nm~22nm 的多核处理器配置,功能强大,可以用于多核处理器以及其组件相关设计的探索。在微体系结构方面,McPAT 支持的组件包括:有序(In-Order)和无序(Out-of-Order)处理器、片上网络、共享缓存、内存控制器以及多个域的时钟。McPAT 使用XML 作为和其它性能模拟器的接口,在XML 文件中能够配置系统的微架构参数,同时传递仿真模拟器生成的动态程序运行数据。最后,McPAT 还可以通过基于XML 的接口将运行时功耗返回仿真模拟器,以便模拟器可以对功率等数据进行收集。McPAT 非常灵活,并且可以轻易地移植到其他性能模拟器上。
在仿真系统GEM5 上运行PARSEC 应用程序得到运行数据后,综合使用McPAT 来对网络的能耗数据进行分析,图4 分别展示了不同路由方案下的数据微片平均静态能耗、平均动态能耗以及总平均能耗。由右上图可知,4VC 路由的静态能耗最高,其次则是1VC 路由,整体来看静态能耗最低的是2VC 路由。在其他组件相同的情况下,路由的存储设备容量与晶体管的面积呈正相关,而晶体管的面积也是决定静态能耗的关键因素,所以4VC 路由静态能耗最高。虽然1VC 面积最小,但由于其延迟最高,静态能耗也与延迟密切相关,所以实验结果表明:静态能耗最优的是2VC 路由。
下面将对数据微片的平均动态能耗进行分析,由图4 可知,4VC 的动态能耗最高,其次则是2VC 路由,1VC 路由总体来看动态能耗最低。在路由的动态能耗中,缓冲区读写的能耗占据了绝大部分,远大于交换机遍历和仲裁器仲裁的动态能耗占比。4VC 路由的存储设备容量最大,存储设备的容量也与单次读写能耗的大小成正比,故4VC 的动态能耗最高。1VC 路由的存储设备容量最小,单次读写能耗相对来说最小。综上,在动态能耗中表现最佳的是1VC 路由。
最后综合动静态能耗数据来对网络的平均能耗进行分析。由图4 可知,2VC 路由平均能耗最低,1VC 路由次之,4VC 路由平均能耗最高。综合延迟和能耗数据可知,4VC路由延迟最低,数据传输最快,可适用于与通信性能要求高的片上网络;2VC 路由在能耗方面表现突出,是三种存储设备容量路由中最节能的路由,可适用于需要严格控制电力开销的片上网络。除了存储设备外,分配器和交换机在总能耗中的占比也不低,如若可以充分发挥路由器内存储设备的功能,以存储及转发的形式来处理数据微片,则仲裁及纵横开关的遍历的流水线阶段可以移除,从而极大地降低片上路由器的能耗和面积,并有效地提升片上网络的能效比。
4 基于合成流量测试程序的实验结果
GEM5 仿真器提供了合成流量框架,该框架可模拟流量输入可被控制的Garnet 网络,研究人员可以根据注入率的数值设置来外部向网络注入的流量大小,在合成流量实验中,注入率表示的是每个处理器核在每个周期生成数据包的概率,也可以表示外部向网络注入流量的速度。随着注入率的升高,片上网络里的流量负载逐渐变重,延迟也会上升。
合成流量是根据合成流量模式来选择数据包的目的地,本文选择的合成流量模式是uniform_random 和neighbor。图5 展示的是随着注入率的提升,两种模式下不同存储设备流量方案的片上网络延迟变化曲线。
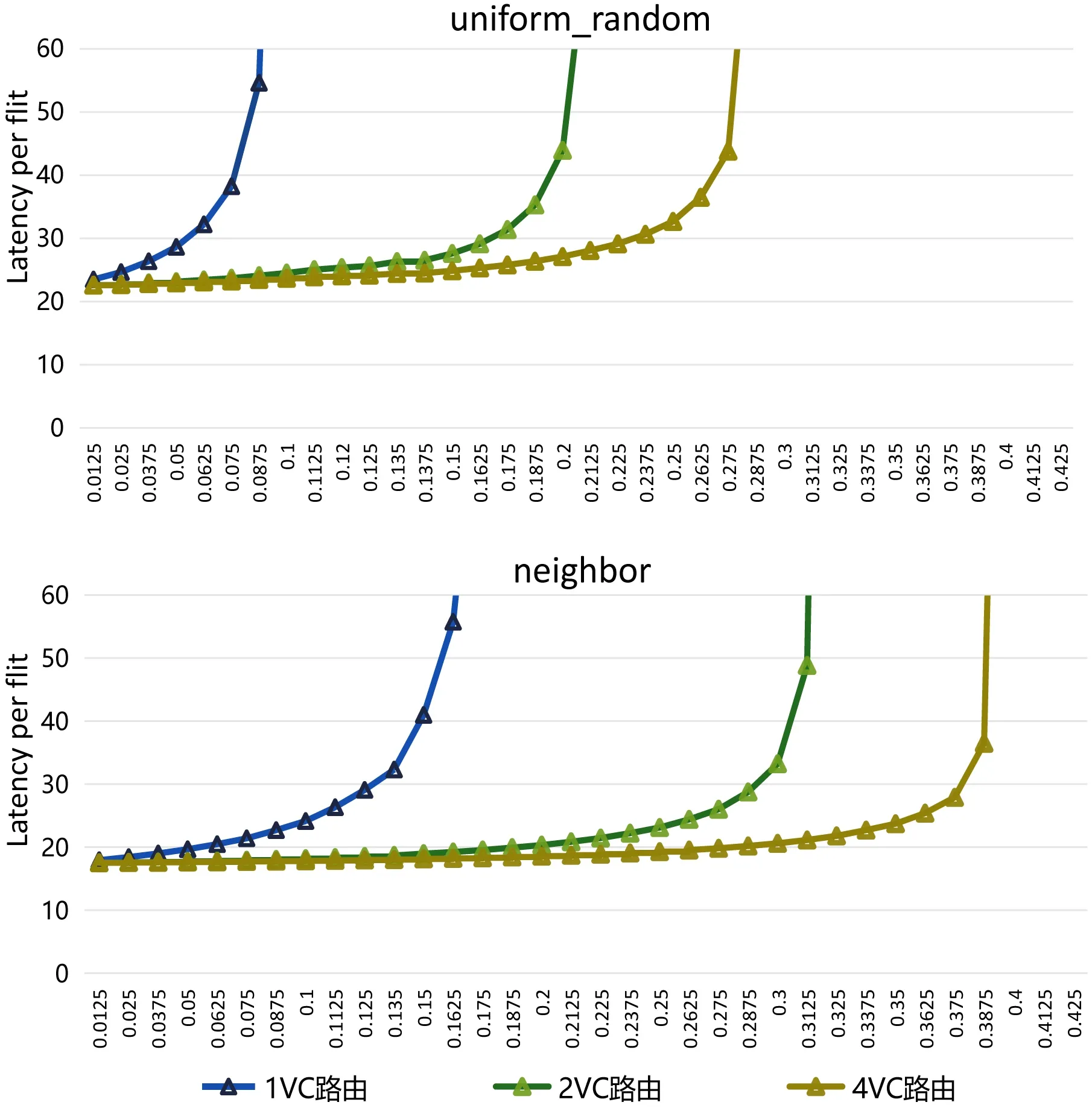
图5: 合成流量实验数据
uniform_random 模式是片上网络路由研究中使用的标准基准程序,也可看作是一种均衡共享内存计算的流量模型。neighbor 模式下目标节点的选择是以80%的概率随机选择源节点的最近邻节点,以20%的概率随机选择其他节点。分析图5 可知,4VC 路由最晚突破延迟上限值,极限注入率最高,其次则是2VC 路由,极限注入率最低的是1VC 路由。极限注入率越高表明网络更晚趋向于拥堵,网络带宽更高。其中可以发现,存储设备容量与带宽也是在部分程度上呈现正相关。综上,4VC 路由的带宽最高,网络对流量的接收程度最高,可适用于网络较为拥堵的情况。
5 总结
本文对不同存储设备容量下的片上网络路由器进行了深度的考察,利用仿真实验揭示了路由器在并行应用程序及合成流量下的延迟与能耗等表现。基于并行应用的仿真揭示了存储设备容量及路由器延迟与能耗之间的关联,合成流量实验则是体现了存储设备容量对网络带宽的影响。通过以上分析,本文提出了针对片上网络路由器中存储设备容量的优化选择方案及片上网络路由器结构的改进方案。同传统的存储设备容量及路由器结构相比,本文的方案可有效降低片上网络的能耗并显著改善片上网络的能效比。
