基于Bert 和BiLSTM-CRF 的APT 攻击实体识别及对齐研究
2022-07-10杨秀璋彭国军李子川吕杨琦刘思德李晨光
杨秀璋,彭国军,李子川,吕杨琦,刘思德,李晨光
(1.武汉大学空天信息安全与可信计算教育部重点实验室,湖北 武汉 430072;2.武汉大学国家网络安全学院,湖北 武汉 430072)
0 引言
随着互联网技术的飞速发展,网络入侵、蠕虫感染、勒索病毒、分布式拒绝服务攻击等网络攻击事件越来越频繁,给社会和企业带来了巨大的安全威胁。在这些潜在威胁中,高级可持续威胁(APT,advanced persistent threat)攻击会造成更大的危害。APT 攻击是一种新型的网络攻击模式,以刺探、收集和监控情报为目的,具有极强的组织性、隐蔽性和威胁性[1]。360 公司在2021 年发布的全球APT报告显示我国是APT 攻击的主要受害者。此外,APT 攻击的恶意代码往往会利用攻击目标的相关信息有组织地躲避杀毒软件及防火墙检测,导致其攻击痕迹很难被溯源。面对当前复杂变化的网络安全环境,如何对抗APT 攻击已成为整个安全界亟须解决的问题。安全公司生成的海量APT 分析报告和威胁情报具有极其重要的研究价值,它们能有效地提供APT 组织的动态,从而辅助网络攻击事件的溯源分析,但其主要以非结构化文本为主。因此,如何利用多源异构的安全文本知识自动化识别APT攻击实体并构建APT 组织画像和领域知识图谱将成为新的研究热点。
近年来,深度学习技术已经被广泛应用于安全领域中,如恶意流量检测、恶意代码分析、个人隐私保护和工业控制系统安全检测等[2-3]。利用深度学习实现自动安全防护和APT 攻击检测已经成为重要的研究方向并取得一定进展。在安全日志方面,Milajerdi 等[4]提出了一种检测 APT 攻击的HOLMES 系统,旨在利用主机日志中的活动和警告信息来识别APT 攻击。在网络流量方面,Marchetti等[5]通过大量分析网络流量实现APT 活动检测,发现与数据窃取恶意行为相关的APT 攻击并识别出可疑主机。在恶意行为分析方面,Han 等[6]针对APT攻击缓慢可持续且使用0day 漏洞特点,构建一种基于溯源图的APT 攻击检测系统Unicorn,其能在没有预先设定攻击特征的情况下识别隐蔽异常行为。
然而,上述方法需要获取大量APT 样本、流量数据或日志信息,但APT 攻击隐蔽性极强,特别是利用0day 漏洞的样本很难被捕获,因此这些方法更偏向于模拟APT 攻击,在实际应用中存在一定的局限性。此外,传统方法缺乏对APT 组织画像构建,未有效利用各大安全厂商已形成的APT 分析报告,较难从碎片化、海量化的威胁情报数据中挖掘APT知识,最终导致攻击检测效果不理想。因此,亟须提出一种面向APT 攻击的知识抽取方法。
为有效从APT 分析报告中自动抽取实体,形成APT 组织结构化知识,本文提出一种融合实体识别和实体对齐的APT 攻击知识自动抽取方法。其贡献主要包括以下3 个方面。
1) 设计一种混合模型来实现APT 攻击领域的实体识别和知识融合。该模型能从APT 报告中自动提取结构化知识,利用实体对齐和知识融合构建黑客组织画像,从而为安全研究人员网络攻击事件分析和关键特征识别提供决策支持,也为APT 领域知识图谱构建和溯源分析提供支撑。
2) 融合主流的ATT&CK(adversarial tactics,techniques,and common knowledge)知识框架设计12种命名实体类别,提出一种融合Bert(bidirectional encoder representations from transformers)模型、双向长短期记忆(BiLSTM,bidirectional long and short-term memory)网络和条件随机场(CRF,conditional random field)的APT 攻击实体识别方法。通过Bert 预训练词向量,增强了模型的泛化能力,接着构建BiLSTM-CRF 模型学习上下文语义信息并完成实体识别。该方法能有效弥补传统实体识别无法较好地抽取特定领域实体,需要大量标注信息,且对存在语义歧义、命名规则复杂的实体抽取精确率较低的不足。
3) 提出一种实体对齐方法并应用于APT 领域的知识融合,有效地将APT 分析报告和黑客组织指纹画像构建结合,通过实体对齐能有效提升所抽取APT 攻击实体的质量,并形成常见APT 组织的知识消息盒。此外,本文实验基于真实的APT 分析报告完成,并与类似研究进行系统比较,证明了所提方法具有良好的性能和实用价值。
1 相关工作
1.1 APT 攻击研究现状
APT 是近年来形成的新型网络攻击模式,具有针对性强、组织严密、持续时间长、隐蔽性高和威胁程度大的特点,给全球政府部门、金融机构和企业带来极大的安全隐患[7]。APT 攻击给全球网络空间安全带来了严重的威胁,如何快速精准地检测APT 攻击已成为重要的研究热点。
面对日益增多的攻击事件,工业界对APT 攻击的防御和溯源研究越来越多。Muckin 等[8]提出网络空间安全杀伤链框架,将网络空间安全划分为7 个阶段,并基于攻击者视角对APT 攻击行动进行整体分析。Mitre 公司提出ATT&CK 知识框架,整个框架以战术、技术和过程为核心,能有效辅助自动化威胁分析。同时,FireEye、卡巴斯基、360、奇安信、安天等公司对APT 攻击的溯源及检测都做了大量的研究。
在学术界,研究者提出了恶意代码分析[9]、主机应用保护[10]、网络入侵检测[11]、大数据分析[12]等APT 攻击检测方法。文献[13]通过博弈论实现主动防御,在分析博弈模型的纳什均衡基础上计算使APT 攻防双方收益最大的攻击路径和防御策略。张小松等[14]提出一种基于树形结构的APT 攻击检测方法。Milajerdi 等[15]基于审计日志构建溯源图,结合网络威胁情报和图模式匹配设计POIROT 系统来检测APT 攻击。近年来,随着人工智能的火热发展,研究者将机器学习和溯源图应用到APT 攻击检测并取得一定成果。
然而,目前主流的APT 攻击分析框架和防御方法仍然依靠大量的专家知识,没有将安全厂商发布的APT 分析报告有效利用,并且仍未提出一种有效的方法来自动提取并生成APT 组织画像。此外,面对语义丰富的非结构化文本数据,传统方法抽取知识的效果较差,缺乏有效的安全知识表达,从而无法形成APT 结构化知识。为解决上述问题,本文提出一种混合型的APT 攻击实体识别及对齐方法。
1.2 实体识别研究现状
实体识别又称为命名实体识别(NER,named entity recognition),它在自然语言处理和知识图谱领域扮演了一个重要的角色。命名实体是指一个词或短语,用于标识一组具有相似属性的事物,命名实体识别是定位命名实体边界并提取预定义实体集合的过程[16]。目前,实体识别的方法主要有三类:基于规则的实体识别、基于统计的实体识别和基于深度学习的实体识别。
基于规则的实体识别利用词典或专家知识构造规则,为每条规则赋予权重,通过规则匹配识别命名实体。比较著名的包括 LaSIE-II[16]系统、Facile[17]系统和DL-CoTrain[18]实体识别方法。然而,该类方法过度依赖专家知识,需要手工构造大量的规则,受领域限制严重且可移植性较差。
基于统计的实体识别是将该任务转换为多分类或序列标注问题,通过统计样本数据集的相关特征来建立识别模型。常见方法主要包括隐马尔可夫模型(HMM,hidden Markov model)[19]、最大熵(ME,maximum entropy)[20]、支持向量机(SVM,support vector machine)[21]和条件随机场[22]等。基于统计的命名实体识别方法在一定程度上对语言的依赖性更小。但是,这些方法仍然需要大量的人工参与,特征工程比较消耗时间,且严重依赖语料库和设定的特征模板,扩展性较差,缺乏对语义知识的学习。
近年来,深度神经网络被广泛应用于自然语言处理领域。基于深度学习的实体识别能够解决命名实体识别的上下文语义难以理解和数据稀疏问题,并且具有对专家知识依赖小且移植性好的优势。在实体识别任务中,常用的深度学习模型包括卷积神经网络、循环神经网络、长短期记忆(LSTM,long short-term memory)网络以及与CRF相结合的模型。Hammerton[23]首先将LSTM 模型应用于实体识别。随后,ID-CNN[24]、Lattice-LSTM[25]等方法被提出。然而,这些方法缺乏预训练词向量来学习语义特征,在小样本标注场景的效果不佳,并且未融合实体对齐,从而导致其对特定领域的实体识别和知识抽取的效果不理想,如APT 领域。
此外,针对安全领域的实体识别主要偏向于漏洞和威胁情报的实体识别[26],其实体类别较少,场景单一,且尚无针对APT 攻击领域的实体识别,也缺乏利用ATT&CK 框架与结合APT 攻击真实流程来自动提取知识的研究,从而无法为APT 组织结构化指纹生成、攻击溯源和图谱构建提供支撑。
为了解决上述问题,本文有效地将实体识别和实体对齐任务应用于APT 攻击领域,结合ATT&CK框架设计12 种命名实体。在模型方面,本文采用Bert 模型来预训练词向量,从而增强模型的泛化能力及适应不同的语义环境,同时构建BiLSTM-CRF和注意力机制模型来提取APT 攻击领域的命令实体,并融合实体对齐提升所抽取知识的质量,最终形成常见APT 组织知识消息盒。本文融合实体识别和实体对齐来开展APT 攻击知识自动抽取的研究,取得了良好效果。
2 问题描述
2.1 任务定义
APT 攻击实体识别旨在提取具有特定意义的攻击实体;实体对齐旨在精确识别不同来源的攻击组织,并将其知识融合。常见的APT 攻击实体包括APT 组织名称、攻击装备、攻击手法、攻击漏洞等。该问题在本文中的定义如式(1)给出的函数f所示。
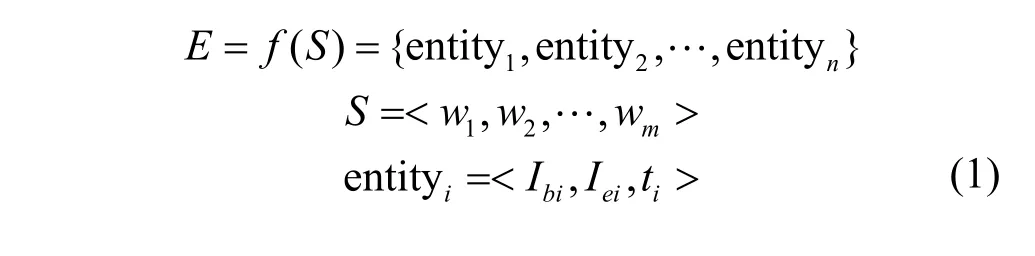
其中,E表示识别出来的APT 攻击命名实体集,包含n个实体三元组;S表示输入的APT 攻击报告或网页单词序列,wj表示第j个位置的单词,共m个单词;entityi表示S中的第i个命名实体,Ibi∈[1,m]且Iei∈[1,m],分别表示该命名实体在S中的开始和结束位置,ti表示该实体的类型。例如,对于输入文本序列“Lazarus usually uses phishing attacks”,模型会识别出<1,1,Lazarus>和<4,5,phishing attacks>2 个实体三元组。
图1详细展示了APT攻击实体识别及对齐任务的过程,共7 个步骤。数据预处理和数据标注后的文本经过实体识别和实体对齐处理后,能有效提取包括组织名称、地理位置、攻击装备、攻击漏洞等结构化实体知识。实体识别其实是序列标注问题,通常采用BIO 方法进行数据标注。其中B 和I 分别对应实体起始位置和实体中间位置(含结束位置),不属于任何实体的词语采用O 表示,该方法能有效标记出实体的类型和位置。
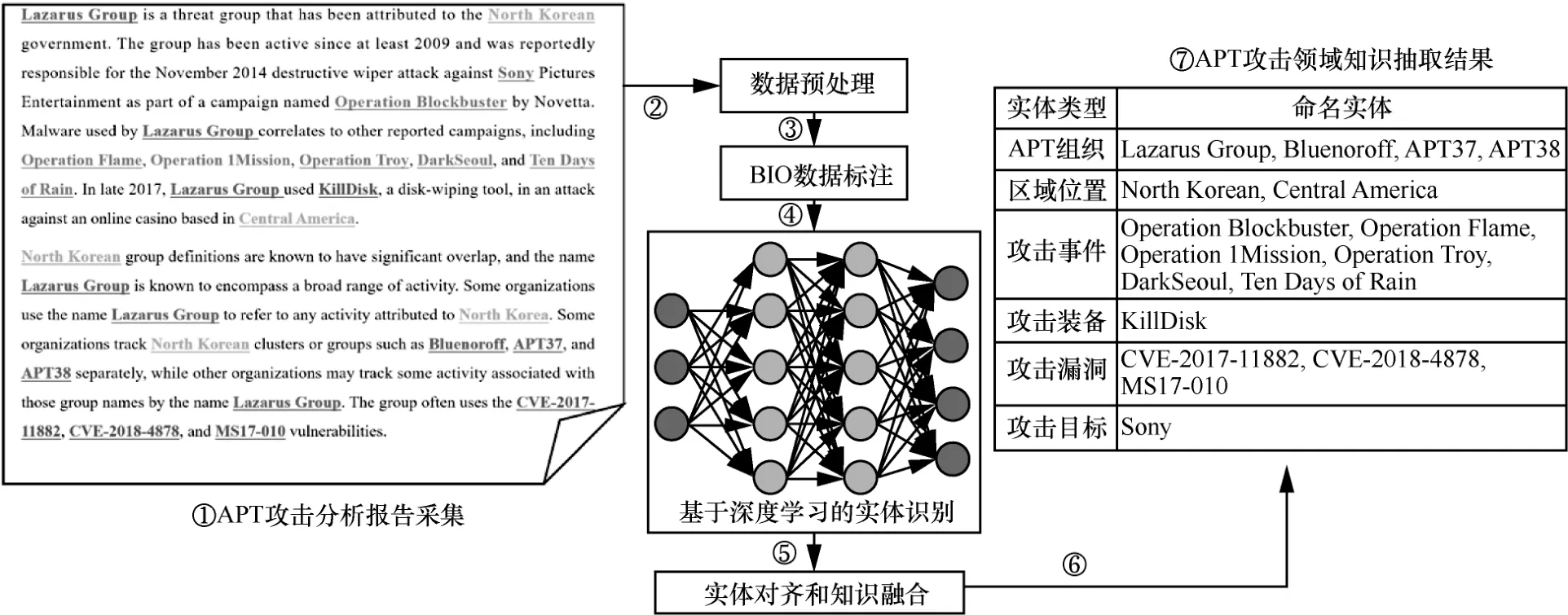
图1 APT 攻击实体识别及对齐任务过程
本文针对APT 攻击特点,结合ATT&CK 知识框架,归纳出12 种命名实体,包括APT 组织(AG,APT group)、攻击装备(AEQ,attack equipment)、攻击手法(AM,attack method)、攻击漏洞(AV,attack vulnerability)、攻击事件(AE,attack event)、攻击目标(AT,attack target)、攻击行业(AI,attack industry)、恶意文件(MF,malicious files)、恶意软件家族(MFA,malware family)、区域位置(RL,regional location)、操作系统(OS,operating system)和利用软件(SI,software information),详细描述如表1 所示。后续实验会将标记符和BIO 方法结合,如“B-AG”表示组织的起始位置,“I-AM”表示攻击手法的中间位置。
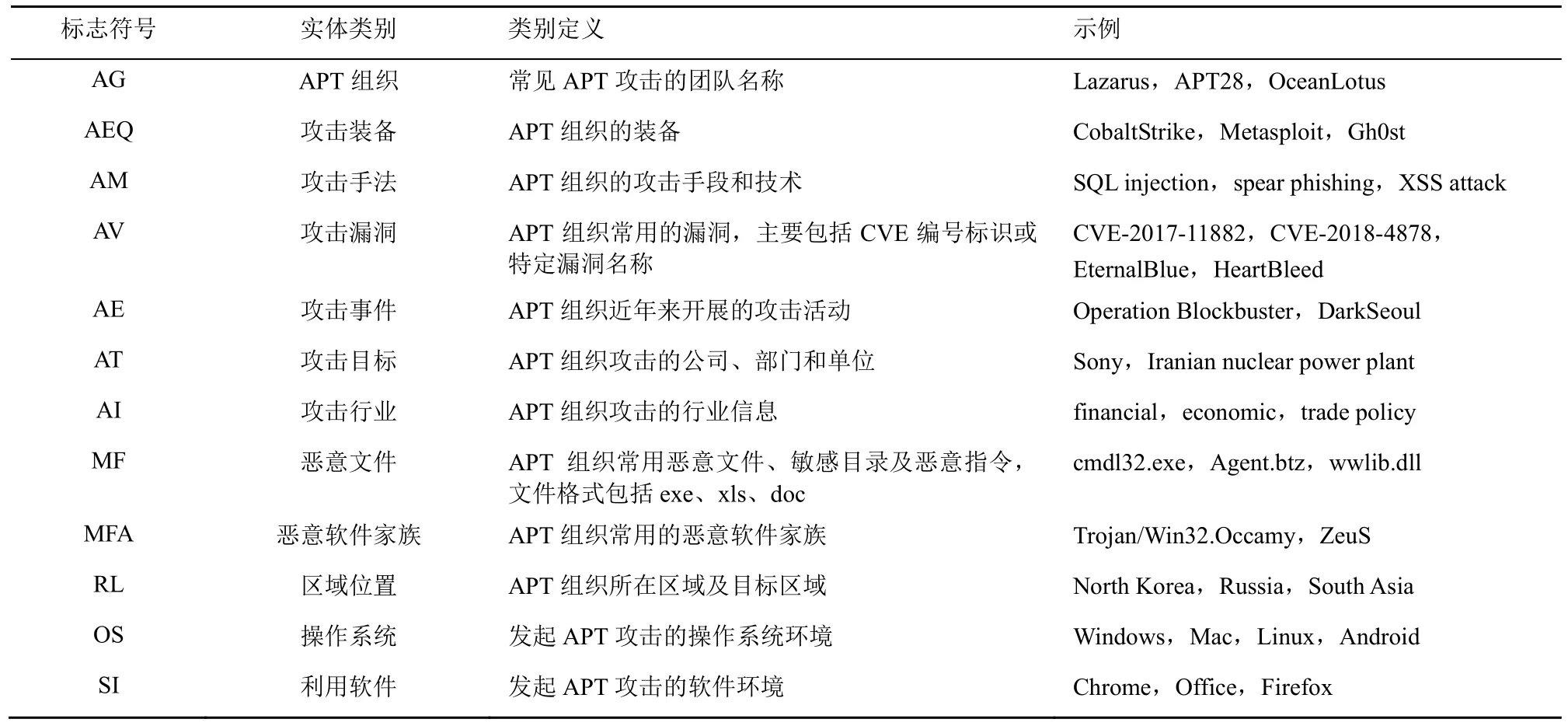
表1 APT 攻击领域的命名实体类别
2.2 研究动机及挑战
当前,APT 攻击非结构化文本处理存在诸多挑战,这些安全信息呈碎片化分散于互联网中,没有被有效地整合和利用。本文旨在从公开的APT 分析报告中抽取APT 攻击实体,构建模型自动生成APT结构化知识,这将为APT 组织的恶意行为分析和攻击溯源提供线索,具体研究动机如下。
1) APT 攻击知识图谱构建。面对大规模的安全数据,传统方法主要利用系统内部产生的日志信息和入侵检测数据进行态势感知,缺乏对外部网络安全知识的有效利用和语义理解。如何描述APT 攻击行为,自动生成攻击指纹和构建APT 知识图谱是一个关键问题。此外,APT 分析报告存在大量嵌套、别名、缩略词及组合词,如何准确抽取知识存在挑战。基于此,本文开展APT 领域的知识自动抽取研究。
2) 少规模数据标注和融合语义实体识别。实体识别需要丰富的训练语料来构建词语表示。然而,APT 攻击领域尚无已标注的专业语料库,传统方法需要花费大量时间去完成数据标注工作。借助专家知识,本文旨在深入分析APT 攻击流程,实现少规模数据标注的知识抽取,设计一种融合实体识别和实体对齐的方法,有效生成黑客组织的结构化知识。
3) APT 攻击溯源。APT 组织为抵抗恶意代码检测和防御技术,通常会使用代码混淆,从而导致APT 恶意代码溯源困难,仅通过异常流量和样本分析判断恶意行为的方法过于局限。如何有效利用公开的APT 分析报告辅助恶意软件溯源并识别其所属组织具有重要意义。目前,APT 攻击的知识自动抽取研究仍处于起步阶段,安全人员的手工分析方法耗时耗力。本文对此开展研究,为后续APT 组织画像构建和攻击溯源提供一定的帮助。
知识图谱通常包括知识抽取(实体识别、关系抽取、属性抽取)、知识表示、知识融合和知识推理等阶段。其中,APT 攻击知识图谱的关系抽取、知识表示和知识推理将在未来开展深入研究。本文将实体识别和实体对齐作为整个研究的起点,为APT 知识图谱构建及黑客组织指纹的自动化抽取提供思路。综上,本文在这些动机的驱动下,将对APT 攻击知识的自动抽取开展全面的研究。
3 模型设计与实现
3.1 整体框架
本文提出了一种融合实体识别和实体对齐的APT 攻击知识自动抽取方法,其框架如图2 所示,主要包括5 个部分:1) 通过预处理层对语料进行数据清洗和数据标注,将预处理后的APT 文本序列表征成向量;2) 通过Bert 预训练,对每个词语编码并生成对应的字向量;3) 构建BiLSTM 和Attention模型,利用BiLSTM 捕获长距离和上下文语义特征,再结合注意力机制突出关键特征,将向量序列转换为标注概率矩阵;4) 通过CRF 算法对输出预测标签间的关系进行解码,输出最优的标签序列;5) 构建语义相似度和Birch 的实体对齐方法,通过知识匹配提升所抽取APT 攻击知识的质量,最终融合形成各APT 组织的知识消息盒。

图2 本文模型总体框架
整个方法的实现过程如算法1 所示,输入为APT 分析报告的文本词序列S,输出为APT 组织的命名实体及攻击知识集合E。该算法首先经过预处理和数据标注;然后构建相关的Bert 和BiLSTM 模型,并经过初始化后分别对向量进行训练;最后利用CRF 算法预测实体标签序列,再进行实体对齐。
算法1APT 攻击命名实体识别及对齐算法


3.2 Bert 模型
Bert[27]是谷歌2018 年提出的预训练语言模型,通过双向Transformer 更好地捕捉语句中的双向关系。Bert 模型充分考虑词嵌入、句嵌入和位置嵌入的关系特征,增强了字向量的语义表示,从而获取高质量的词向量。本文通过该模型预训练APT 领域知识,使用多个Transformer 双向编码器对字符进行编码,其会将输入句子中的每个词都和句中所有词做注意力计算,从而获取词间的相互关系,捕获句子内部结构。这能在一定程度上反映不同词语之间存在的关系和重要程度,有效解决NLP 中的长依赖问题,计算式为
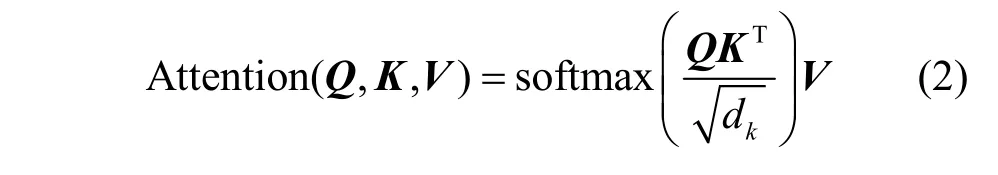
其中,Q、K、V分别表示Query、Key 和Value 向量,它们是编码器的输入字向量矩阵;dk表示输入向量的维度。由于Bert 模型能够将学习到的语义知识通过迁移学习应用到数据标注较少的命名实体任务上,因此本文选用该模型进行APT 攻击命名实体识别的上游预处理任务,在一定程度上减少数据标记工作,从而更好地挖掘APT 文本中的特征信息。
3.3 BiLSTM 模型
LSTM 是一种典型的循环神经网络,能解决训练时产生的梯度爆炸或梯度消失问题。LSTM 核心结构包括遗忘门、输入门、输出门和记忆单元。整个记忆单元由细胞状态Ct来调节,输入门和遗忘门共同保留重要信息,遗忘无用信息。LSTM 结构的计算式为
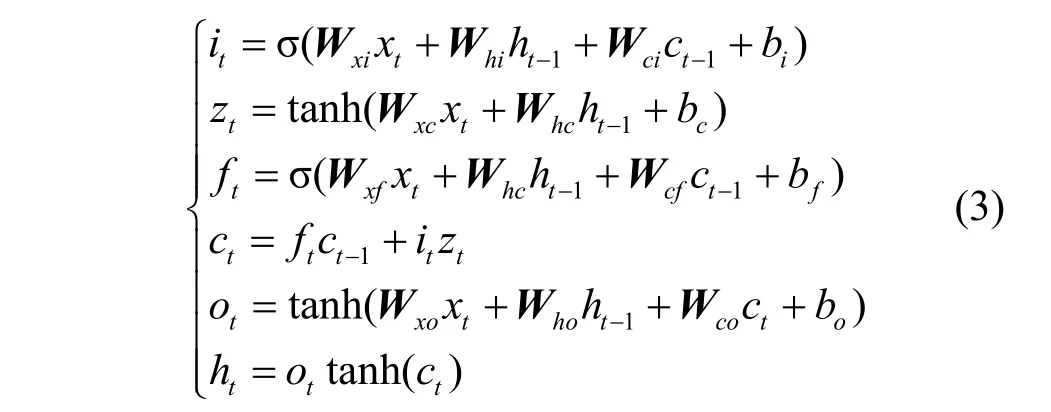
其中,it、ft和ot分别表示t时刻输入门、遗忘门和输出门的结果,ct表示t时刻细胞状态,σ和tanh表示2 种不同的神经元激活函数,W表示连接两层神经元的权重矩阵(如Wxi表示输入层到隐藏层的输入门权重),b表示偏置项,xt、ht和zt分别表示t时刻的输入变量、隐藏层变量和增量。
本文使用BiLSTM 模型更好地捕获APT 数据集的语义特征和长距离依赖信息。该模型由前向LSTM 和后向LSTM 组成,从前后2 个方向对APT攻击文本的实体进行识别,从而提高具有前后关联实体识别的性能,如“SQL Injection”“OceanLotus Group”“XSS Attack”等。
3.4 CRF 算法
CRF 是一种判别式概率无向图模型,在给定输入随机变量的情况下,能计算输出随机变量的条件概率分布。在命名实体识别中,BiLSTM 模型能够捕获长距离的文本信息,但无法感知实体及相邻标签间的依赖关系,并且APT 攻击领域的实体依赖关系更加复杂。CRF 算法能有效解决该问题,它考虑标签之间的转移关系并计算整体标签序列的概率,从而获取全局最优的标记序列。因此,本文在BiLSTM 模型后连接一个CRF 模型,用以提升APT攻击命名实体的识别效果。
本文使用线性链条件随机场,对于任一输入序列X=(x1,x2,...,xn),其中xi为第i个单词的输入向量,假定s是BiLSTM 模型的输出得分矩阵,s由n个单词和k个标签组成,sij表示第i个单词的第j个标签的分数。对于预测标签序列Y=(y1,y2,...,yn),其得分函数计算规则为分数越大则标签的可能性越高。
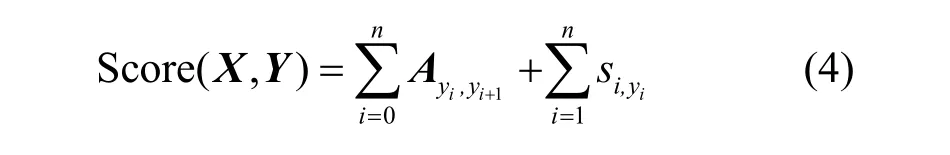
其中,A表示转移矩阵,旨在完成标签之间的分数转移,Aij表示标签i转移为标签j的概率,即转移分数。同时,在k个标签的基础上增加“开始”和“结束”2 个标签,它们对应的s分数为0。CRF 模型会采用对数最大似然估计计算损失函数使正确的序列的概率最大,再解码得到最大分数的输出序列,作为最终APT 攻击实体识别的标注结果。
3.5 实体对齐算法
实体对齐旨在确定2 个待消解的实体是否指向同一个目标实体,又称为实体消解。本文通过上述步骤抽取不同来源的APT 攻击知识,包含APT 组织、攻击装备等在内的12 种命名实体,接着构建基于语义相似度和Birch 聚类的实体对齐算法,将每篇APT 分析报告的实体映射成融合上下文语义的词向量,再对APT 组织名称执行实体对齐与知识融合,从而自动化生成APT 组织的知识消息盒(InfoBox)。
实体对齐算法流程如图3 所示。通过融合Bert和BiLSTM-CRF 模型完成命名实体识别,抽取APT文本的结构化知识,再利用Word2Vec 转换成融合语义的词向量,构建实体相似度计算模型,通过语义相似度距离来实现基于Birch 算法的聚类,从而将相似的命名实体进行对齐,最后将不同APT 组织共现的实体进行知识融合,形成最终的APT 组织指纹特征库以及知识消息盒。
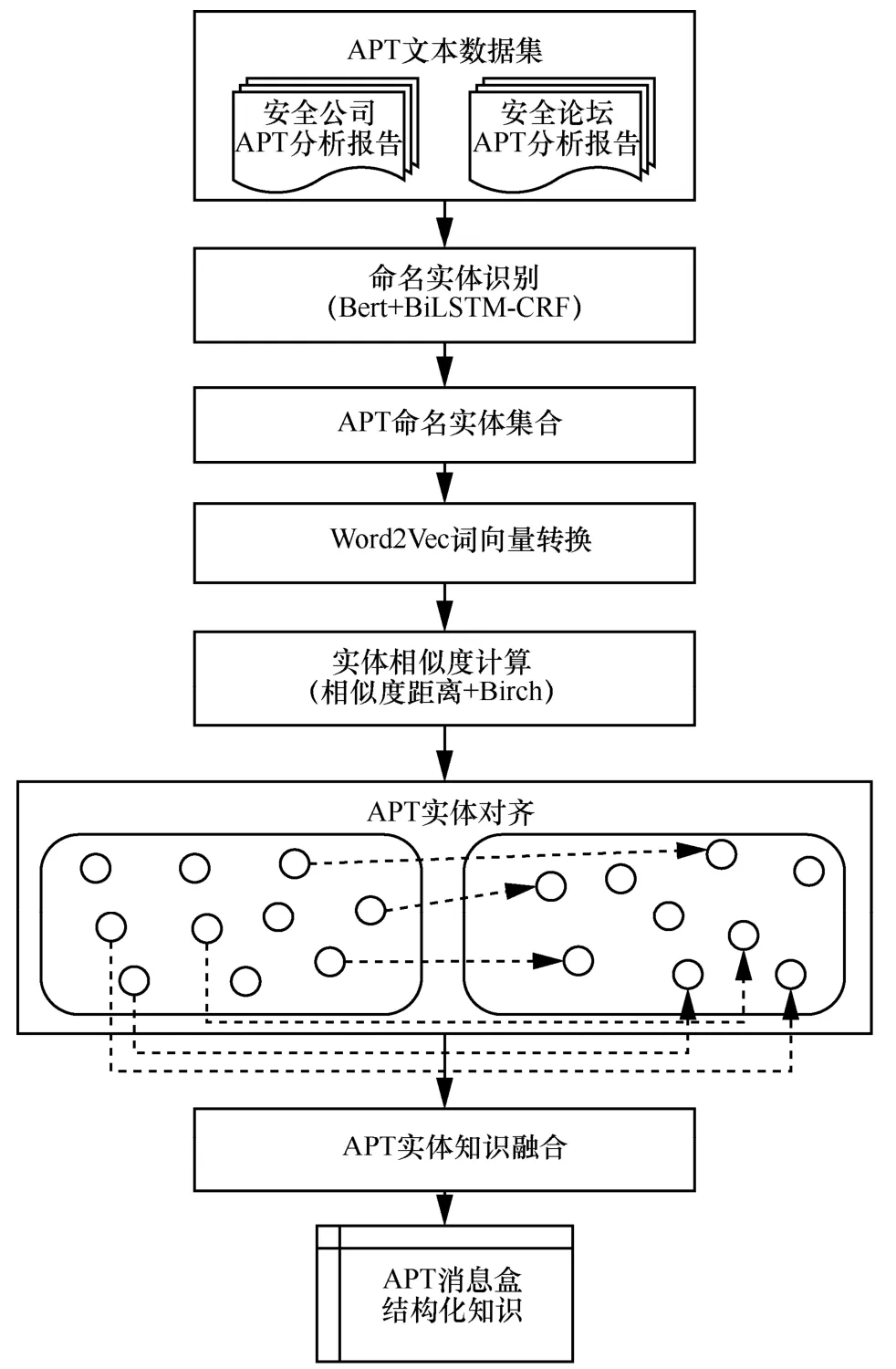
图3 实体对齐算法流程
4 实验结果与分析
4.1 实验数据集及预处理
本文采集来自 Mitre ATT&CK、FireEye、McAfee、Kaspersky 等安全公司的APT 分析报告,经过数据清洗及文本拆分后共形成包含466 篇文本的数据集,覆盖了全球各地区的APT 组织,典型的APT 组织包括APT28、APT29、APT32、APT33、APT37、Lazarus、Turla 等,其12 种APT 领域实体类别数量分布如表2 所示。整个实验数据集按照一定比例随机划分为训练集、测试集和验证集,并且测试集中存在未知的APT 命名实体。
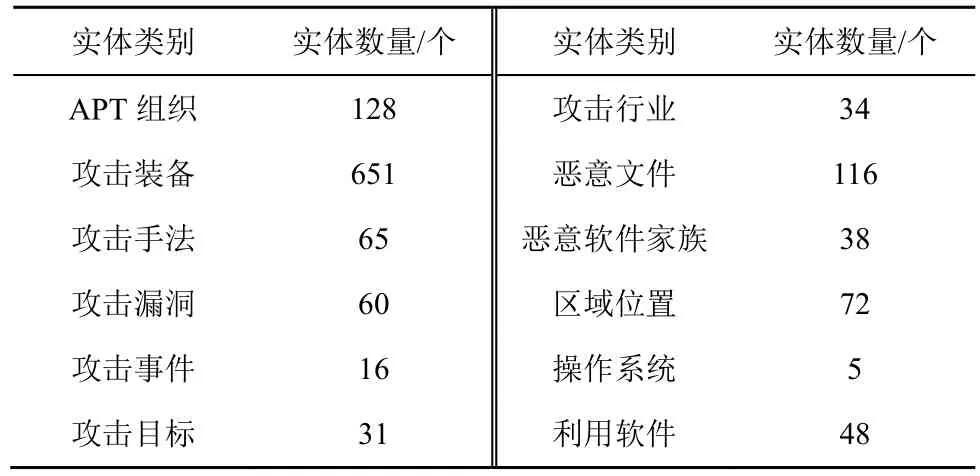
表2 APT 领域实体类别数量分布
接着,利用BIO 标记法分别对不同类别的实体进行数据标注。单词起始位置使用“B-”字符加表1定义的标志符号,如“B-AM”表示攻击手法的起始位置;单词中间位置使用“I-”字符加表1 定义的标志符号;其他不属于任何实体的单词使用O 表示,通过该方法能有效给出实体对应的类型及位置。图4 是第2 节介绍示例对应的实体标注结果。从图4 可以看到,APT 组织、地理位置、攻击事件、攻击装备、攻击漏洞等均被标注。

图4 APT 文本经过BIO 序列标注示例
4.2 评价指标
实验采用4 个常用于评价实体识别的指标来衡量算法的有效性,分别是精确率(Precision)、召回率(Recall)、F1值(F1-score)和准确率(Accuracy),计算式分别为

其中,精确率表示正确识别的实体数量占识别出的所有实体数量的百分比,从查准的角度评估模型;召回率表示正确识别的实体数量占所有该类标注实体数量的百分比,从查全的角度评估模型;F1值表示精确率和召回率的调和平均数,从查准和查全2 个角度综合反映模型的效果,本文用来对实体识别实验进行整体评估,F1值越大,表明模型正确识别的实体数量越多且越全;准确率表示分类预测正确实体数量占该类别实体总数量的比值。为验证本文模型的有效性和真实性,最终结果为10 次实验结果的平均值,从而避免噪声影响。
4.3 实体识别实验
实验数据集按照6:3:1 的比例随机划分为训练集、验证集和测试集,实验环境为Windows10 64 位操作系统,GPU 为GTX 1080Ti,内存为16 GB,CPU 处理器为Inter(R) Core i7-8700K,编程语言为Python3.7。模型参数设计方面,文本序列长度设为500,BiLSTM 模型2 个方向的神经元数设置为256,采用Adam 优化器,Epoch 设置为15,初始学习率设置为0.001,Transformer 层数设置为12,并且增加Dropout 防止过拟合,其参数设置为0.4。
本文提出一种融合Bert 和BiLSTM-CRF 模型的APT 攻击实体识别方法,与现有常见的实体识别方法(CRF、LSTM-CRF、GRU-CRF、BiLSTM-CRF、CNN-CRF 和Bert-CRF)的对比结果如表3 所示。
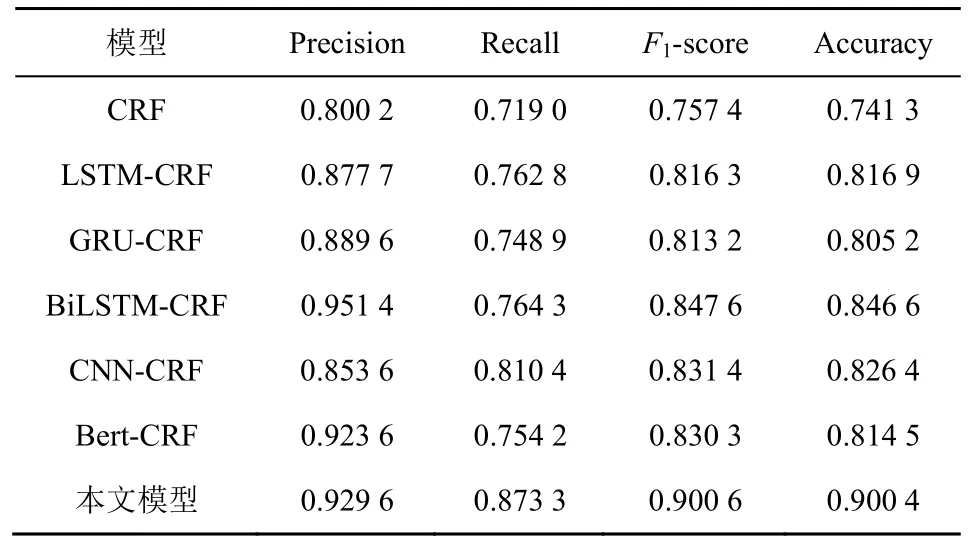
表3 各模型实体识别结果对比
由表3 可知,本文模型在APT 攻击领域的实体识别任务中能够取得较好效果,其精确率、召回率和F1值分别为0.929 6、0.873 3 和0.900 6,比现有6 种模型均有一定程度的提升。相比于CRF,本文模型的F1值提升了0.143 2;相比于融合卷积神经网络的CNN-CRF,本文模型的F1值提升了0.069 2;相比于LSTM-CRF 和BiLSTM-CRF,本文模型的F1值分别提升了0.084 3 和0.053 0;相比于GRU-CRF,本文模型的F1值提升了0.087 4;相比于Bert-CRF,本文模型的F1值提升了0.070 3。同时,本文模型的准确率为0.900 4,比其他6 种模型的平均值高0.098 5。通过实验发现,融合Bert和BiLSTM-CRF 及注意力机制的实体识别模型具有最佳的效果,其主要原因是Bert 预训练能更好地表示APT 攻击领域知识,并且BiLSTM 网络能学习上下文语义信息,注意力机制能有效突出关键特征。
为更形象地表现本文模型的良好性能,使用训练和验证数据进一步评估模型的学习过程,得出如图5 所示的准确率变化曲线和如图6 所示的误差变化曲线。由图5 可知,与其他模型相比,本文模型训练过程更加稳定,整个曲线收敛速度更快,能在较少训练周期下取得较高的准确率。图6 展现了各模型的误差随训练周期变化的曲线,本文模型的误差随训练周期收敛速度更快,曲线更平缓,这进一步体现了本文模型应用到APT 实体识别是可行的。
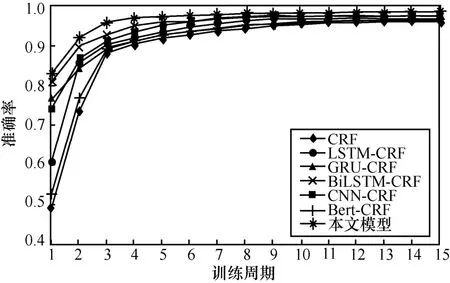
图5 各模型准确率变化曲线
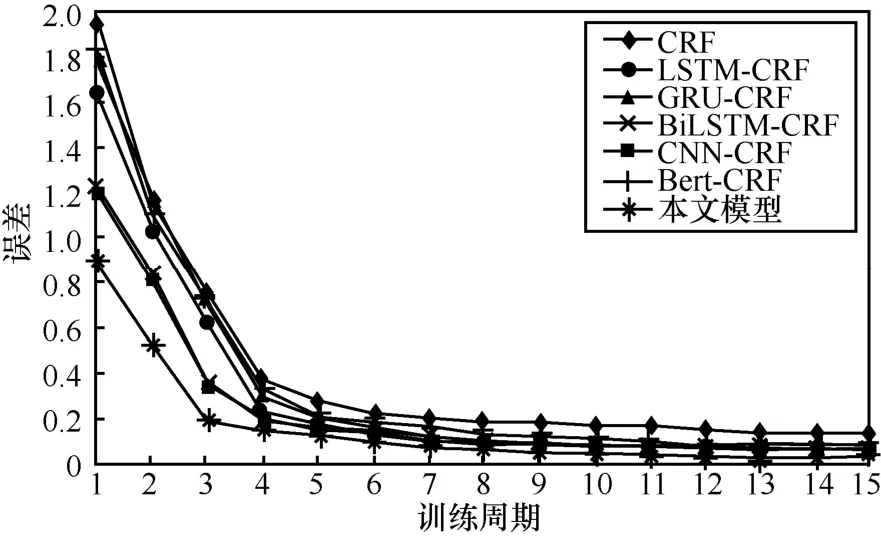
图6 各模型误差变化曲线
为进一步衡量本文模型对APT 攻击领域不同类别实体的识别效果,本节进行了详细的对比实验,得出如表4 所示的12 种APT 攻击实体类别的识别结果。
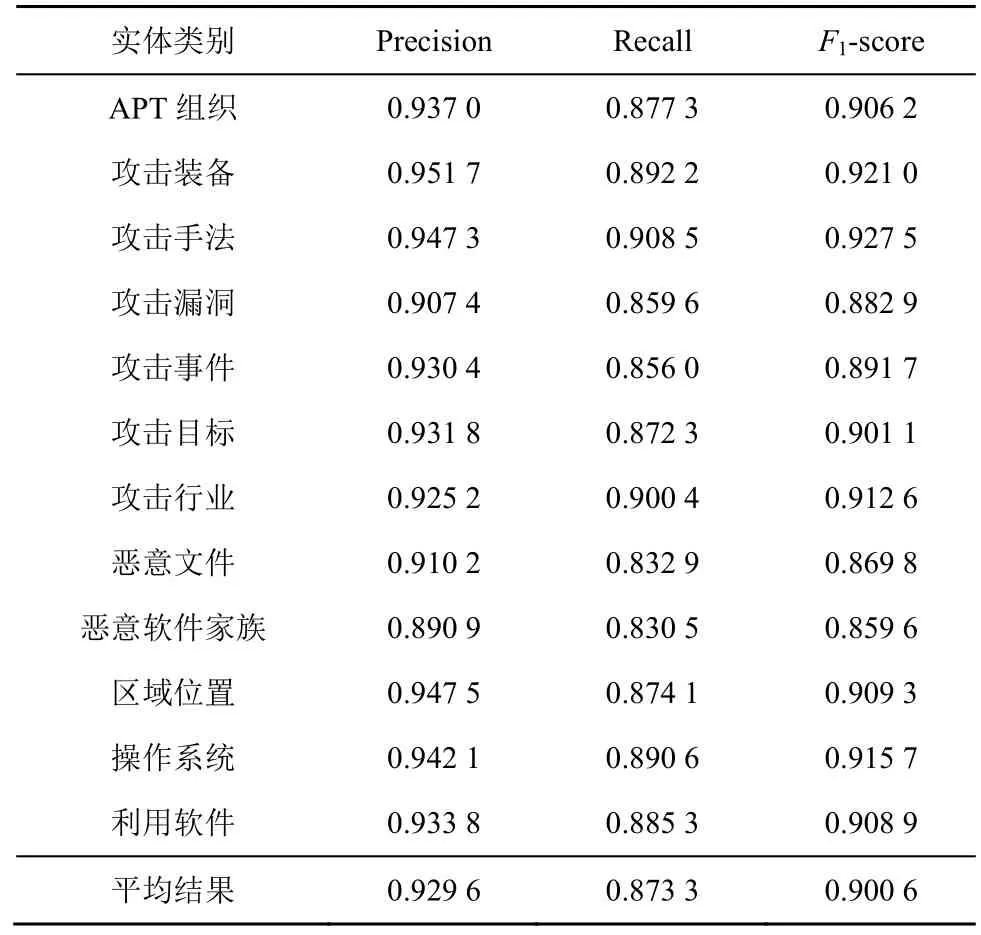
表4 APT 攻击领域不同类别的实体识别结果
由表4 可知,本文模型在“攻击手法”实体类别上的预测效果最佳,其F1值为0.927 5,这一方面是由于该类别的实体数量较多,另一方面是该类实体广泛存在于富含语义的APT 攻击事件中,并且带有攻击行为的动作特征,从而导致其识别效果更好。接下来,识别效果较好的实体类别包括“攻击装备”“攻击行业”“APT 组织”等,这些实体也都具有上下文语义突出和广泛存在于APT 分析报告中的特点,比如“APT-C-36”“Lazarus Group”“APT28”属于 APT 组织实体,“CobaltStrike”“PowerShell”“Mimikatz”属于攻击装备实体。然而,本文实验识别效果最差的类别是“恶意软件家族”,其F1值为0.859 6,这是由于该类实体数量较少,其构造规则缺乏规律,常混合出现于上下文段落中,较难与普通特征词区别,从而识别困难。
此外,本文结合ATT&CK 框架,选取了4 种类别数量较多且常出现于APT 攻击事件中的实体类别进行F1值比较,包括攻击装备、APT 组织、攻击手法和利用软件,其详细的对比实验结果(F1值)如图7 所示。由图7 可知,本文模型在4 种类别的实体识别中F1值均最高。其中,本文模型攻击装备的F1值为0.921 0,比6 种对比模型的平均F1值提升了0.059 6;本文模型APT 组织的F1值为0.906 2,比6 种对比模型的平均F1值提升了0.046 0;本文模型攻击手法和利用软件的F1值分别为0.927 5 和0.908 9,比6 种对比模型的平均F1值分别提升了0.043 0 和0.124 9。综上所述,本文模型能有效对APT 攻击领域的命名实体进行识别,其效果优于传统的实体识别模型,且能在各实体类别上取得良好性能。

图7 常见4 种实体类别的F1 值对比结果
4.4 小样本标注的实体识别实验
为有效评估各模型对小样本标注的实体识别效果,本文按照2:7:1 的比例随机划分训练集、测试集和验证集,从而降低训练集标注知识,并进行详细的对比实验,实验结果如表5 所示。由表5 可知,本文模型在小样本标注情况下,实体识别的精确率、召回率和F1值分别为0.780 0、0.589 4 和0.671 4。其F1值比CRF 模型提升了0.274 2,比LSTM-CRF模型提升了0.187 8,比GRU-CRF 模型提升了0.236 2,比BiLSTM-CRF 模型提升了0.132 5,比CNN-CRF模型提升了0.148 8,比Bert-CRF 模型提升了0.144 6。该实验充分说明了本文方法能通过Bert 模型对小样本语料开展预训练,从而提升实体识别的效果。
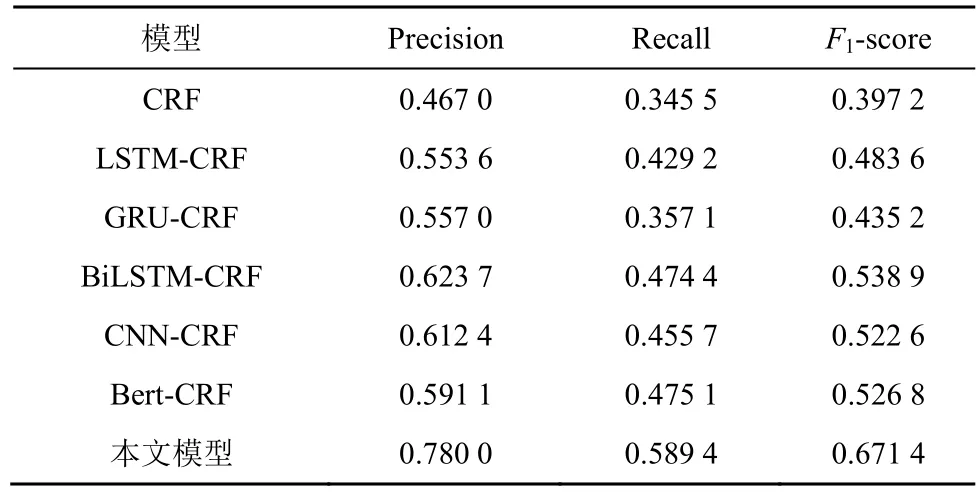
表5 各模型小样本标注的实体识别结果对比
接着,本文结合APT 攻击流程和实体类别分布数量,在小样本标注情况下,详细对比了现有模型与本文模型在六大常见实体类别(APT 组织、攻击事件、攻击装备、攻击手法、恶意文件、利用软件)的F1值,其实验结果如图8 所示。通过雷达图能有效反映本文模型在不同类别的实体识别中取得的最佳效果。总之,本文模型能在少量样本标注的情况下实现实体识别,并取得更好的效果。
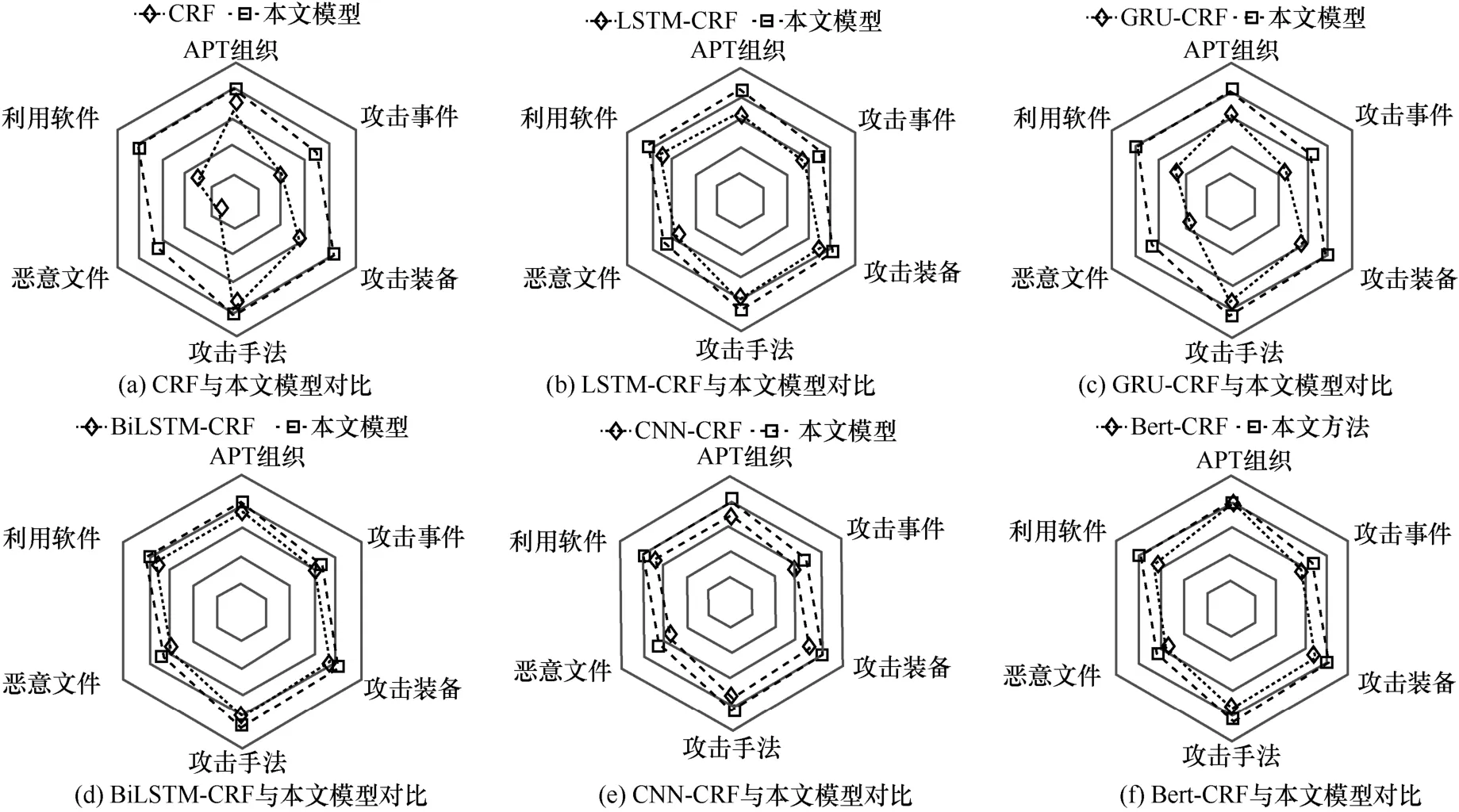
图8 各模型小样本标注的F1 值对比
4.5 实体对齐与知识融合实验
APT 攻击领域通过实体识别任务能有效提取攻击实体,再通过本文提出的实体对齐算法能进一步形成各APT 组织的结构化知识。表6 显示了本文实验自动化抽取各类实体类别出现频率较高的命名实体,这些实体常常存在于APT 攻击事件中。比如常见APT 组织包括“APT29”“APT32”“APT28”和“Turla”等,常见攻击装备包括“PowerShell”“Cobalt Strike”和“Mimikatz”等,常见攻击手法包括“Spearphishing”“C2”“Watering Hole Attack”和“Backdoor”等,常见漏洞包括“CVE-2017-11882”“CVE-2017-0199”和“CVE-2012-0158”等。

表6 本文模型所提取APT 攻击领域的常见命名实体
经过实体识别处理后,为更好地抽取APT 攻击领域知识,并为后续APT 知识图谱或特征指纹库构建提供支撑,本文对APT 组织名称进行了实体对齐与知识融合实验。本文通过基于语义相似度和Birch聚类的实体对齐算法将不同来源的组织命名实体进行匹配,判断其是否指向同一个目标实体,比如“APT28”又称为“Sofacy”“Fancy Bear”“Strontium”“Sednit”,这些APT 组织对应的目标实体均相同。本文结合语料标题和关键词对APT 组织名称开展实体融合,最终构建了该数据集常见APT 组织的知识消息盒,形成各APT 组织的结构化知识。
表7 和表8 分别呈现APT28 和APT32 经过实体识别和实体对齐实验后的攻击领域知识。它们既包括本文模型所识别的实体知识,如攻击装备、攻击手法、攻击漏洞、攻击目标、恶意文件等,又包括经过实体对齐后的APT 组织名称,有效融合APT攻击领域知识,为后续知识图谱构建提供支撑。

表7 APT28 常见的实体知识展示
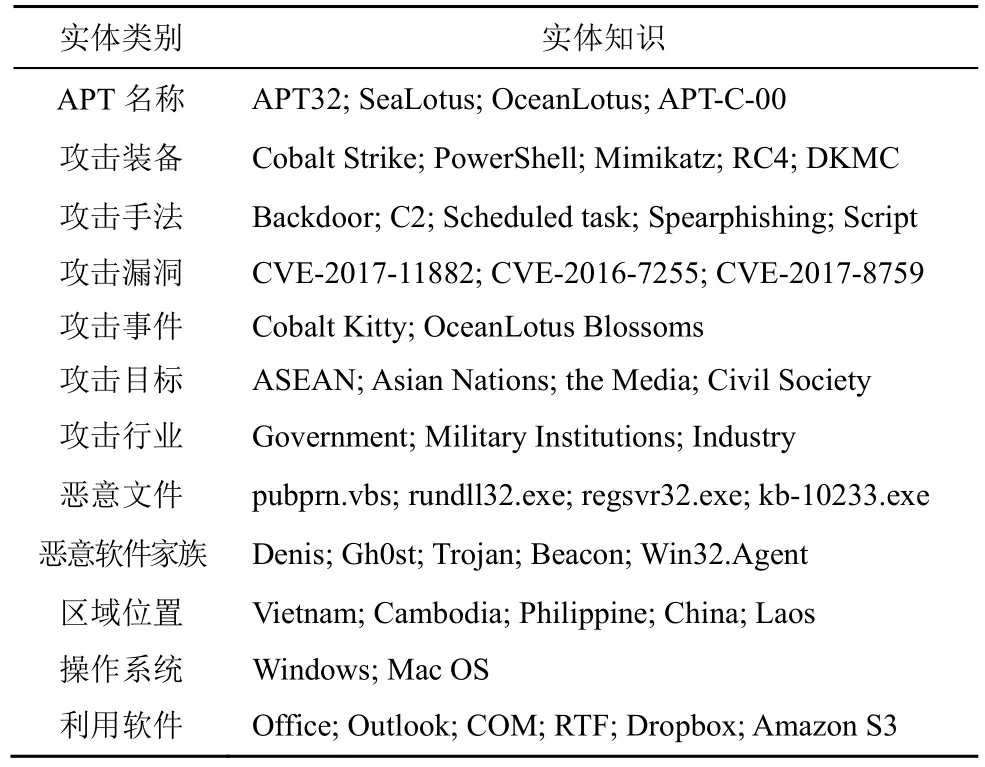
表8 APT32 常见的实体知识展示
5 结束语
本文设计并实现了一种融合实体识别和实体对齐的APT 攻击知识自动抽取方法。该方法结合APT 攻击特点设计了12 种实体类别,构建了融合Bert 和BiLSTM-CRF+Attention 的APT 实体识别模型,再结合实体对齐生成了不同APT 组织的结构化知识。实验结果表明,本文模型能有效识别APT攻击实体,在少样本标注的情况下自动抽取高级可持续威胁知识,并生成常见APT 组织的结构化特征画像。这将为后续APT 攻击知识图谱构建和攻击溯源分析提供帮助。在下一步工作中,笔者将针对中文APT 分析报告开展知识自动抽取研究,并结合图神经网络开展攻击关系抽取及攻击事件推理。
