基于机器学习技术的窃电自动识别研究
2022-07-09赵海霞张光建张海波
赵海霞 张光建 张海波
(1、西南交通大学希望学院,四川 成都 610400 2、四川建筑职业技术学院,智能计算研究所,四川 德阳 618000)
1 概述
托马斯·B·史密斯认为,窃电可以定义为:在没有合同或有效义务的情况下使用公用事业公司的电力来改变电力计量。传统的反窃电方法包括人工定期检查、仪器仪表定期检测、用户信息查询等手段,以发现窃取用电用户的信息。这种方法耗时,依赖人力,没有明确的目标同时存在很大投机机会。目前智能电网的关键技术是广泛部署在电网方面的先进计量基础设施(AMI),通过采集电压、电流、功率、电力负荷数据,结合电力终端提取从窃电用户身上提取的异常数据,通过偷电识别模型,确定用户是否自动偷电。
2 研究现状
国内外已经提出并开发了几种检测窃电的技术。目前,对于现有窃电用户行为的识别,研究人员采用不同的方法提取用户特征,建立识别模型,得到不同的识别率。Joker P 等人提出并建立了一个应用程序,该应用程序在智能电网采样数据模型中使用用户行为,检测疑似窃电的用户。Zanetti M 等人描述了一个使用概率神经网络(PNN)模型的应用程序,根据模型选择怀疑客户,以及其耗电量。概率神经网络算法对一类给定的各向同性高斯似然函数也是如此。Mandala S 等人利用12 个月的用户用电量提取的细节作为神经网络的输入,通过机器学习训练得到期望的输出精度为70%-80%。他使用的模型是支持向量机在多次迭代之间的分类,准确率在76%到92%之间。张良军在书中介绍了一个基于LM 神经网络模型的应用,该模型的准确率为94%,CART 决策树模型的准确率为95.3%。刘涛等提出了一个应用,该应用利用电能计量自动化系统采集电力、负荷数据、报警和线损,分析窃电现象现有样本的电气检查增益,基于模糊神经网络方法的评估方法,建立自适应防盗泄漏诊断模型。样本数据的模拟和分类准确率为96.16%。
3 样本采集
根据中国的实际情况,电力用户主要集中在企业,尤其是私营企业。银行、学校、营业税等机构,其不可能实施窃电行为。因此采样数据将直接从此类用户中删除。电力负荷中的电能计量系统不能直接反映用户的窃电行为,因为终端报警可能有误报和漏报。
对于正常的电力用户来说,用电量不是不稳定的,而是稳定的。对于用电用户来说,在用电临界时间点前后,负荷和终端负荷数据都会发生一些变化,用电量会显著降低。本次样本采样原始数据采集包括三个部分:基本信息和默认值,电力营销系统提取处理用户记录,来自测量系统的实时负载数据(包括时间点和测量点、总有功功率、A/B/C、A/B/C 相电压、相电流、A/B/C 相功率因数;来自智能电网的报警数据采集终端)。
3.1 数据收集
用户当日用电量计算公式(1)。
参数fi计算如下:

其中,fi对于总有功功率的前1 天,每15 分钟的前l天,为当天的用电量总和。
对于企业用户,根据工作日和节假日较低的用电量,过滤节假日用电量。对于缺失值,使用拉格朗日插值法(2)。
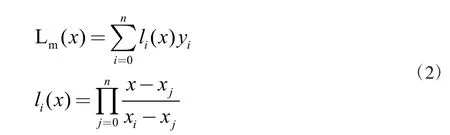
3.2 数据转换
通过电能计量系统对电能、负荷的数据特征进行转换,并采集数据样本。窃电规律表征评价指标体系构建了3 个特征:电力趋势下降指标特征、电力线损耗特性、线损耗率特性以及与盗窃相关的终端报警指示灯报警号码。
3.2.1 电力趋势指标下降
统计前一天和后一天的5 天时间段作为统计窗口,其中计算11 天用电量的斜率,计算公式(3)

如果认为秋季的电力趋势涉嫌窃电,则在该日前后5 天内,总共有11 天的电力下降趋势指标T,方程式(4)。

3.2.2 线损指数
线损率是衡量电力线损耗的指标,结合电路拓扑,计算线损,公式(5)。

计算当日5 天前后的线损率统计平均值Vi1和Vi2,如果Vi1和Vi2,比增长率大于1%,则认为用户涉嫌窃电,线损指数E(i),公式(6)。

3.2.3 报警指示灯
报警统计端子电压相位、电压相位总数、电流反极性报警作为报警指示。
根据上述三类指标,收集的样本如表1 所示。
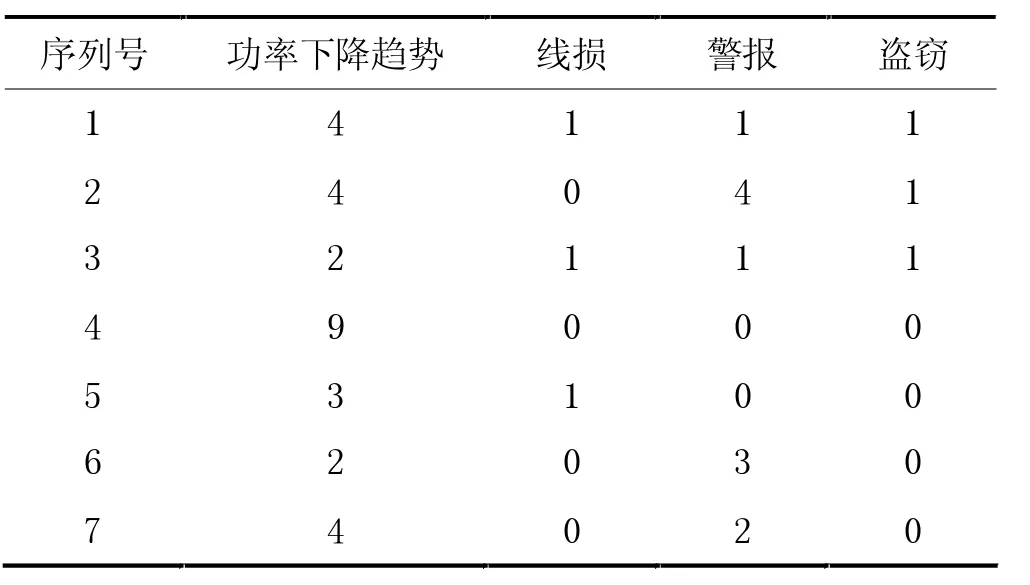
表1 样本数据
序列号功率下降趋势指示灯线损指示灯报警指示灯被盗。
3.3 解决阶级失衡问题
在实际应用中,不同错误的代价往往是不相等的。根据收集到的样本,普通客户的成本可能比窃电客户的成本高得多。
考虑到解决阶级不平衡问题最常用的方法,其基本思想是改变训练数据的分布有助于消除或减少不平衡数据。
3.3.1 过采样
过采样方法通过添加几个样本来提高少数类的性能,最简单的方法是简单地复制几个样本,缺点是可能会导致过拟合,没有向少数类添加任何新信息。在少数随机高斯噪声中改进的采样方法创造了新的样本合成方法。
3.3.2 抽样不足
在抽样方法下通过减少大多数样本来提高少数类的性能,最简单的方法是去掉一些最随机的样本来减少大多数类的大小,但一些重要信息在大多数类中丢失了,不能充分利用现有信息。
3.3.3 成本敏感的方法
3.3.3.1 重建训练集
不改变现有算法,而是根据样本不同的误分类代价给每个样本分配一个权重训练集,然后对原始样本的权重进行重构。
3.3.3.2 引入成本敏感因素,设计了成本敏感分类算法
一般来说,它对小样本施加了更高的成本,大样本给出了更小的价格和期望,以平衡样本之间的差异数量。
3.3.4 特征选择
当样本分布非常不均匀时,分布将不平衡。特别是在文本分类问题中,经常出现在特征的类别中,它很可能没有出现在罕见的类别中。因此,根据非平衡分类的特点,选择最具差异性的特征有助于提高贵族阶层的识别率。
根据一个经验样本,选择一个样本的正负两组,分别从中选择最能体现样本集特征的方法,然后将特征集作为最终选择的一个方面。
在参考文献[12]中,使用抽样方法处理不平衡数据的类不平衡问题。
3.3.5 模型与仿真
参考文献1,样本数291,使用270 个样本作为训练集,剩余样本作为测试集,构建支持向量机模型,其中支持向量机类型设置为0(c-SVC),内核类型设置为1(多项式核函数)。如图1 所示绘制ROC。绘制混乱矩阵,如图2 所示。
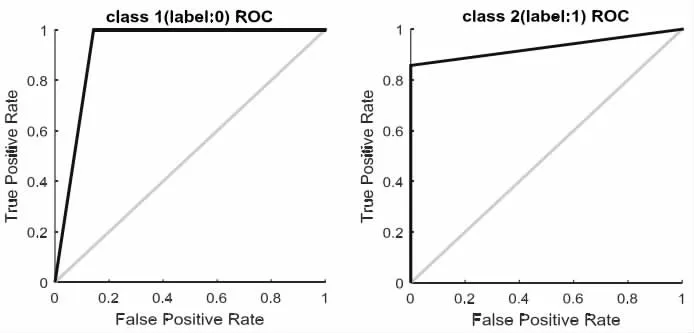
图1 ROC
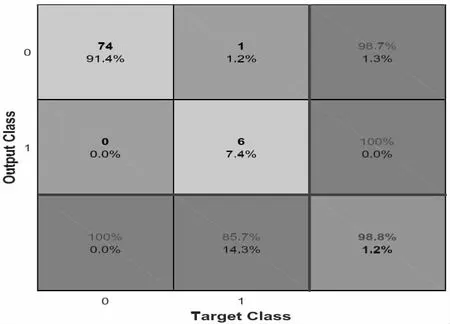
图2 混淆矩阵
4 结论
在智能电网先进测量的基础上,自动采集原始数据,利用支持向量机分类装置对窃电用户的行为特征进行分析和计算,实现窃电识别,提高识别精度。模型将进一步分析窃电用户的行为,并提供更多重复特征。与多个模型相比,选择的最优模型能够提高识别精度。
