基于机器学习算法匹配的互联网企业内容日志检测工具的设计与实现
2022-07-08熊逸文
熊逸文 项 菲 苗 杰
1.国家计算机网络应急技术处理协调中心江苏分中心;2.国家计算机网络应急技术处理协调中心
0 引言
《中华人民共和国网络安全法》规定:“国家网信部门和有关部门依法履行网络信息安全监督管理职责,发现法律、行政法规禁止发布或者传输的信息的,应当要求网络运营者停止传输,采取消除等处置措施,保存有关记录。网络运营者对网信部门和有关部门依法实施的监督检查,应当予以配合。”为加强网络生态治理、清朗网络空间,网信、公安和通信部门作为国家互联网管理的三驾马车,每年都会常态化对互联网企业进行网络信息安全检查,并通报问题,指导企业整改网络信息安全隐患。在信息大爆炸时代,互联网平台一般都会发布大量平台生成内容(PGC)和用户生成内容(UGC);然而由于安全意识淡薄、安全投入不足、技术审核不严、管理措施不到位等原因,互联网平台往往会出现一些色情、赌博、诈骗等违法违规信息。根据法律法规要求,互联网平台的网络日志必须存储六个月以上。理论上,互联网平台产生的违法违规信息均要在企业内容日志存储至少六个月,因此,对互联网企业内容日志的检查可有效发现和识别这些违法违规信息,及时排查内容安全隐患。
监管部门一般采取台账查阅、人员访谈、远程检测等手段,尝试发现互联网企业违法违规信息。但这些手段受多种因素制约,存在以下局限性:一是远程检测中,受企业反爬虫策略或流量加密的限制,难以大批量地采集数据,多以内容抽查为主,抽查方式使得待检样本覆盖面不广、代表性不足,且考虑到对计算资源的消耗,整体成本较高。二是在现场检查中,多以人工检查为主,检查人员由于经验差异导致检查标准很难统一,受现场检查时间和检查人员数量限制实际检查量不大。从技术路线角度来看,开发一款现场检查工具,对互联网企业内容日志进行检测过滤,快速溯源定位违法有害内容,能够灵活、有效满足涉网监管部门现场技术检查的需求。鉴于该工具可长期复用,整体成本不高,且检查人员经简单培训后即可上手操作,适配性较强。
基于该技术路线,我单位已开发一款针对互联网企业内容日志进行自动化检测的工具,可兼容目前互联网企业主流内容日志格式(txt、csv、xls、xlsx 四种文件格式),可自定义敏感词词库,支持定位敏感词所在位置及上下文,并基于机器学习算法匹配过滤内容日志,进而提升结果的准确性和精确性。本文提炼总结了该工具设计和实现的技术方法,从工具方案设计出发,推导工具功能模块的实现,并介绍了工具内嵌的算法技术。文章结构如图1 所示。
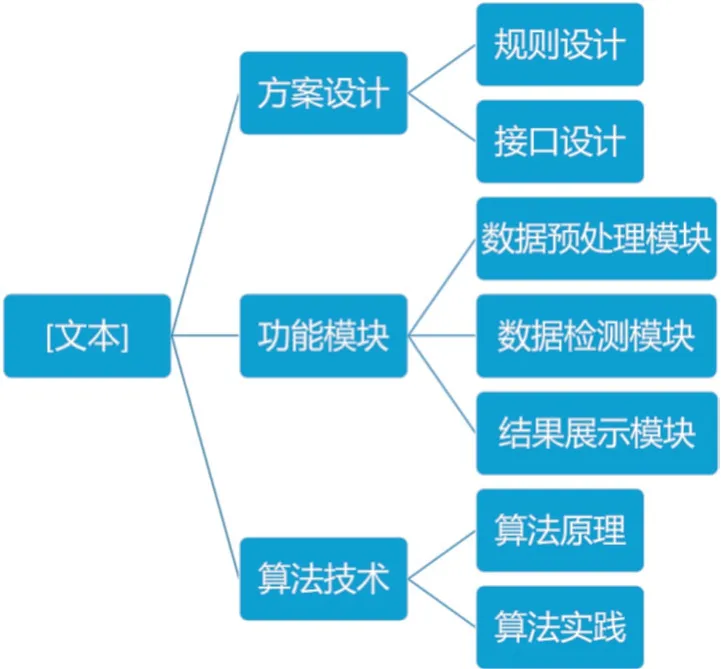
图1 文章结构示意图
1 方案设计
检测工具方案设计主要包括账号、词库、文件等检测规则的设计和API 接口的设计。
1.1 规则设计
(1)用户账号规则
系统内随机生成若干个账号和密码,账号和密码的数量可根据需要动态调整;输入相应账号和密码,点击登录按钮即可登录系统。对外服务时可通过远程授权省内涉网监管部门账号和密码的形式,配置用户使用人数的权限,工具未授权则不可使用。
(2)敏感词库规则
敏感词管理应遵循分级分类原则,色情、赌博、诈骗、宗教、暴恐等敏感词不适合在公共互联网环境下暴露显示,但检测工具须在互联网企业公共互联网环境下使用,因此有必要对敏感词库进行加密处理,使得工具使用人员不能看到敏感词文件。可在内网环境下由高权限内容审核人员编辑敏感词,对敏感词进行分类,并根据检查任务或目标提取相关分类的敏感词,自定义生成敏感词库,并对其进行混淆加密;在外网环境下,高权限内容审核人员将经过封装后的敏感词库移交给工具使用人员,使用时将已加密的敏感词库导入工具,工具自动解压缩敏感词库并导入程序,整个流程敏感词库对工具使用人员不可见。
(3)待检文件规则
互联网企业内容日志存储在不同类型的操作系统、数据库中,采用不同的安全策略限制数据访问;鉴于成本和技术上的考虑,检测工具开发不同接口去适配企业内容日志数据库较为复杂,为此本设计将内容日志导出为主流文件格式,工具支持对这些文件格式的检测;鉴于内容日志存储量一般较大,设计支持将内容日志导出为多个文件,工具支持对多文件的检测。
(4)日志检测规则
现场技术检查应与其它检查进程同步,有时需要中止检查,并显示实时检查结果;设计检测工具运行时可显示进度、可暂停检测、可导出结果。设计可通过字符数判断待检文件的类型,如用户昵称通常字符数较少,发布的文章每行字符数则较多,灵活选择待测字符区间,可显著提高检测效率。在config 文件配置中可以选择参数,设置字符最大展示个数;待测文件每行少于字符最大展示个数,直接忽略,检测工具只检测每行不小于字符最大展示个数的样本。
1.2 接口设计
本工具共设计3 个API 接口,分别为CreateTask 接口、GetTaskInfo 接口、CancelTask 接口。接口原理设计为上传待测文件之后,调用CreateTask 接口去创建文件检测任务,通过后端处理模块进行数据处理,并将处理的结果放入到队列中;然后通过GetTaskInfo 接口去实时队列中对结果进行判断,并将判断结果实时反馈给UI 界面;最后通过调用CancelTask 接口可以中止文件检测。如表1 所示。

表1 检测工具API 接口处理逻辑
2 功能模块
企业内容日志检查工具共有三个功能模块,分别为数据预处理模块、数据检测模块和结果展示模块,如图2 所示。数据预处理模块实现对敏感词的预处理和待测文本的预处理,将敏感词和待测文件从原始格式转化为检测工具可识别的格式;数据检测模块支持多种类型的检测模式,可根据检查需要动态调整检测模式;结果展示模块可根据检测进度,灵活选择展示或保存检测结果,明示违法内容所在位置和上下文关系。
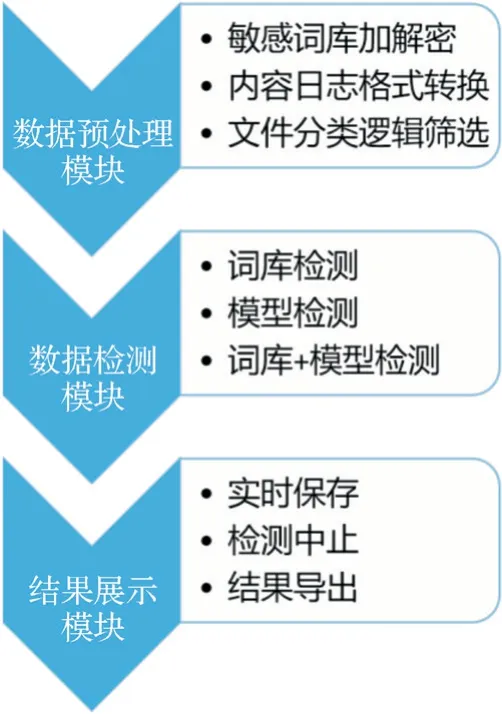
图2 检测工具模块架构图
2.1 数据预处理模块
2.1.1 检测流程
关键词仅支持txt 格式,使用ICSharpCode.SharpZipLib第三方的DLL 库实现对敏感词库的加密压缩和解压缩功能,将加密词库导入到检测工具后,检测工具再逆向对加密词库进行解密,用于下一步的文本过滤。待测文件支持txt、csv、xls、xlsx 四种主流的文件格式,内容日志从互联网企业数据库导出后须先转换为这些文件格式。对待测文件的检测支持目录检测,待测文件以文件夹形式导入检测工具。关键词和待测文件均以UTF-8 格式编码;UTF-8 包含简体和繁体中文字符,能正确显示多种语言文字,鉴于部分有害内容可能以繁体中文字符显示,使用UTF-8 覆盖更为全面。
2.1.2 逻辑筛选
上传文件,系统会根据文件类型进行筛选,过滤掉非txt、csv、xls、xlsx 文件格式的待测文件,对筛选后的结果计算文件大小。以大小1M 为基准对文件进行划分,规定大于1M 的文件为大文件,小于1M 的文件为小文件。对于大文件,以文件中文本行数一万行为基准进行切割,以此类推,直至划分成单个或多个文本行数为一万行的文件和一个小文件,分别进行检测;对于小文件,直接进行检测即可。如图3 所示。

图3 文件分类逻辑筛选图
2.2 数据检测模块
数据检测支持词库检测、模型检测和模型+词库检测三种检测模式,可根据任务类型、时间要求和检测精度选择检测模式。词库检测原理为关键词比对,命中关键词即显示目标结果;模型检测原理为利用机器学习算法进行模糊比对,模糊比对命中即显示目标结果。一般情况下,在敏感词较少(如专项检测)、待测文件不大(如用户昵称、简介)时,使用词库检测效率较高;在敏感词较多(如覆盖全部敏感词样本)、待测文件较大(如系统发布文章)时,建议采用模型检测;在检测时间允许时,可采用模型+词库检测。
2.3 结果展示模块
在进行大文件检测时为防止数据丢失,可设置实时保存结果选项,并在检测开始前选择结果文件保存路径,即可实时将已检测结果保存并显示在UI 界面。UI 界面实时显示检测进度,若文件过大过多、等待时间较长,可中止检测,并保存已完成检测的结果。检测结束后,UI 界面展示检测结果,包括文件路径、危险等级、敏感词分类、命中敏感词、行号和上下文六个数据字段。检测工具支持结果文件的导出,结果文件可保存为csv 或xlsx 格式。
3 算法技术
3.1 算法原理
检测工具使用的机器学习匹配算法共两种,分别为随机森林算法和DFA 算法,检测工具会将两种算法匹配到的数据进行合并,并分析判断是否存在敏感词。两种算法均判断为违规则认为是“危险”数据,一种算法判断为违规另一种算法判断为正常则认为是“未知”数据,两种算法均判断为正常则认为是“安全”数据。机器学习算法匹配逻辑如图4所示,机器学习算法重要参数设置如表2 所示。从算法特点来看,随机森林算法对数据的适应性较好,但在噪音较大的过滤分类上会出现过拟合问题;DFA 算法针对变种词等特殊字符检测较为灵敏,但在关键词数量较多时消耗内存较大。综合使用两种算法,能够平衡变体词、形近词、拟声词等特殊字符的检测速度和精度。
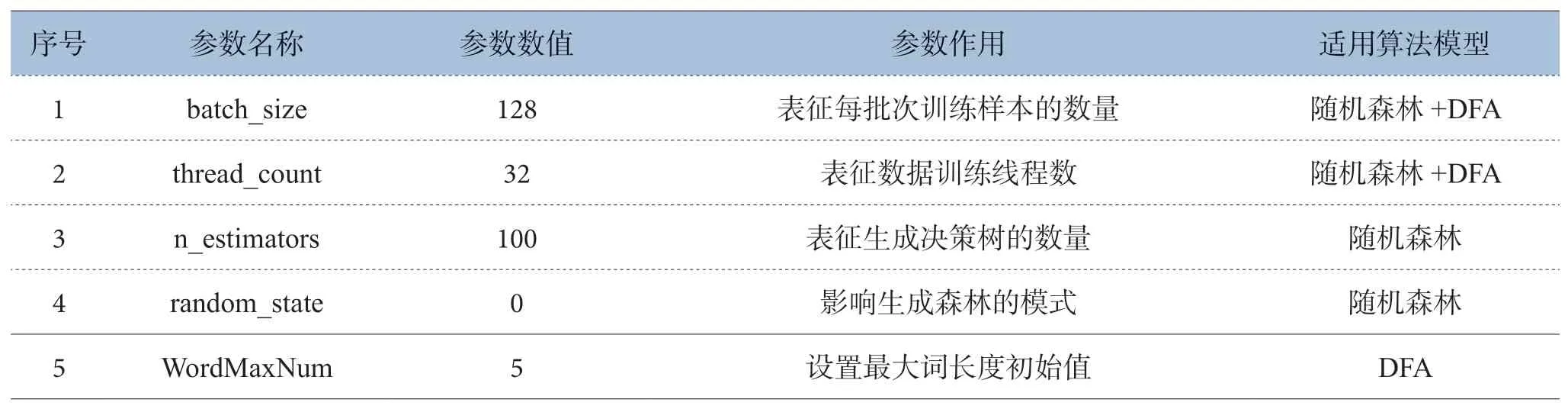
表2 机器学习算法重要参数设置

图4 机器学习算法匹配逻辑图
随机森林算法匹配过程直接调用Python Sklearn 库中的随机森林分类器Random Forest Classifier,使用Jieba 库对待测文件中文字符进行分词操作,用LabelEncoder、OneHotEncoder 函数对已分词字符进行编码;以Hashing Vectorizer 词袋模型对文本进行特征向量化(该模型可通过哈希技巧标记文本的索引位置,而不创建词典,占用内存较低,适用大型数据集);使用fit_transform 函数训练数据、transform 函数测试数据,使用predict 函数预测数据,使用optimize_model 函数优化模型。如图5 所示。
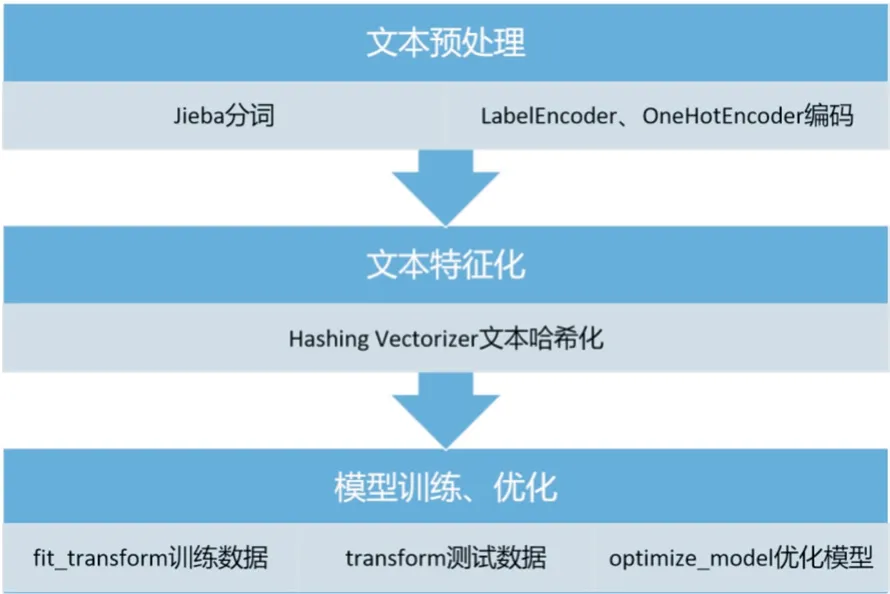
图5 随机森林算法匹配流程图
DFA 算法原理是一个状态通过一系列事件可转换为另一个状态,鉴于通过树结构而非哈希表方法能够更容易实现对文本的状态标,因此本文采用的是基于Trie 树字典机制的DFA 算法。在Trie 树上进行检索类似于查阅英语词典,首先将敏感词分为多个片段,每个片段作为状态,构成树结构;然后通过树结构进行敏感词匹配。流程上,通过create_node函数新建节点,使用dfa 函数扫描待测文本,以add_word函数添加关键词,以add_words 函数添加关键词组,最后用query 函数查询是否包含敏感词。如表3 所示。
3.2 算法实践
(1)数据抽取:本文实验数据的原始样本共2000 条,其中正常样本1600 条,违法违规内容样本400 条。以9:1的比例通过train_test_split 函数划分训练集和测试集,即训练集占90%,测试集占10%。
(2)特征抽取:计算训练集和测试集的特征向量。
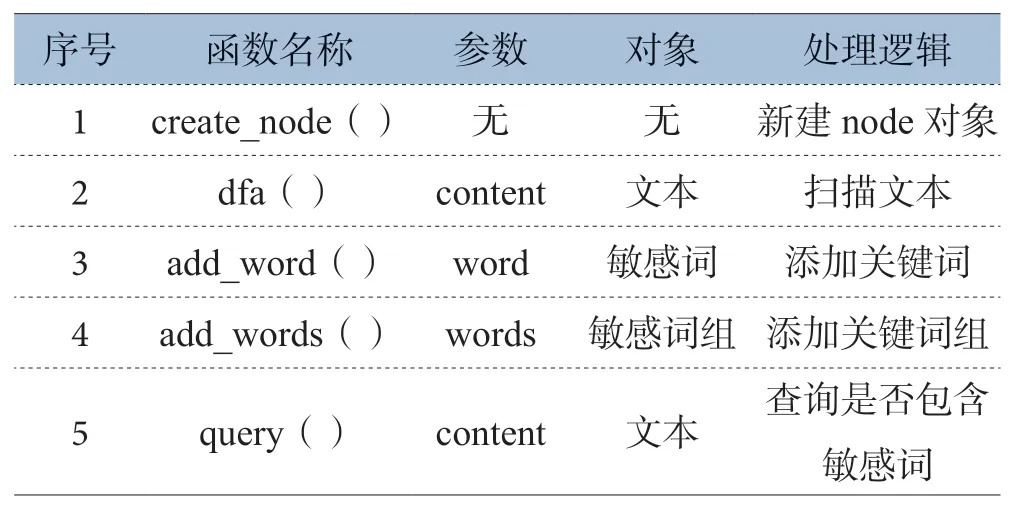
表3 DFA 算法函数介绍
(3)建立模型:使用Sklearn 机器学习库中的Count Vectorizer、TFIDF Vectorizer、Hashing Vectorizer 三种词袋模型,配置模型重要参数,得到预测结果。如表4 所示。

表4 随机森林模型重要参数设置
(4)性能计算:计算三种模型评价指标,包括准确率(Precision)和召回率(Recall)。
(5)重复1-4 步,共进行10 轮实验,计算平均结果。
从平均性能来看,Hashing Vectorizer 模型表现最好,TFIDF Vectorizer 模型其次,Count Vectorizer 模型表现最差。如表5 所示。

表5 随机森林模型实验性能结果
4 结束语
本文基于对互联网企业内容日志的现场技术检查需求,提出了一种内容日志的自动化检测工具设计方案,并完成了检测工具的实现开发。该工具内嵌机器学习算法模型,并支持基于关键词的词库检测、基于算法的模型检测和基于前两者混合的检测三种检测模式,可根据现场检查需要灵活调整检测模式,快速、高效发现涉诈、涉黄、涉赌等违法有害信息。
