(2021 年江苏省通信学会“华苏杯”论文征集一等奖)基于用户资费套餐服务满意度预测方法的研究
2022-07-08陈大龙郭柏龙唐大鹏魏东迎
陈大龙 郭柏龙 孟 维 唐大鹏 魏东迎
南京华苏科技有限公司
0 引言
近几年来,随着我国通信市场个人用户趋于饱和,传统运营商均面临着用户难以增长的问题,竞争便从增量市场转到了存量市场,如4G 用户向5G 转化,语音用户向宽带用户转化等。
在如此激烈的市场竞争背景下,如何提高用户满意度,减少用户流失,成为运营商保持用户和收入增长的重要手段之一。要提升用户满意度,就需要运营商加强用户重点投诉原因的分析,解决满意度各类短板问题,不断提升服务品质,以期留住用户。
这是一则有关香港南丫岛撞船事故的报道,整个语篇不足130字,篇幅短小,字字有用,句句有着落。没有废话,不拖沓,不冗长。修辞语义清楚明白,不费解,不含糊,读者一看即明。再看新华网的:
当前运营商服务质量管理工作的主要问题在于,手工收集来源广泛的数据容易出错,且对比分析工作量繁重。因此,使用大数据挖掘技术辅助运营商改善用户满意度的需求亟待解决,而电信运营商在用户数据方面有着天然的优势。
通信用户的海量数据均存储在运营商的OSS、BSS 和MSS 三个域中:
目前,临床上主要应用化学药如胰岛素增敏剂、降血脂药等治疗NAFLD,但这类药物效果并不十分理想,且容易导致患者出现并发症[7]。近些年来,中医药治疗NAFLD开始引起人们的广泛关注。许多中药不仅具有良好的抗脂肪肝效果,而且毒副作用小、价格低廉、宜长期使用,在治疗NAFLD方面显示出良好的发展前景[8]。
以上是歌曲《我和2035有个约》的歌词片断,你读了有怎样的感触和思考?请根据歌词内容确定立意,以“我和2035有个约”为标题写一篇文章,要求选好角度,明确文体,自拟标题;不要套作,不得抄袭;不少于800字。
基于4.1 的样本分析,由于样本比例失衡,因此在训练分类模型时,尝试了不同的正负样本组合方法,通过预留的验证集测试模型效果(定义验证集中5 分及以下为资费不满意用户),采用XGBoost 分类算法作为建模方法并保持默认参数不变,实验结果如表1 所示。
(2)BSS 域(business support system)即业务支持系统。主要包含运营商的计费系统、客服系统、帐务系统、结算系统以及经营分析系统等。
(3)MSS 域(management support system)即管理支撑系统。主要包含ERP 企业管理、门户、项目管理系统等。
1 实验方案设计
针对资费套餐服务满意度主观性较强的问题,提出一种基于机器学习的建模方法,从海量数据中分析用户个体行为特征,通过用户的多维度特征,高效且低成本地挖掘出对资费套餐服务满意度较低的用户,从而针对性地改善用户感知,提升运营商整体满意度。
实验组问卷调查结果显示97.0%及以上学生认为以多维度案例图库为基础并微信辅助的新型示教模式可以激发学习兴趣和热情,增强自主学习能力,提高分析问题、解决问题能力,锻炼语言表达能力,训练临床思维,提高阅片能力,加强师生交流,融洽师生关系(见表2)。
该方法具体包括以下步骤:
逻辑回归模型本质上是线性回归,只是在特征到结果的映射中加入了一层函数映射,即先把特征线性求和,然后使用函数g(z)将作为假设函数来预测。
步骤二:使用机器学习算法通过样本数据训练出一个分类模型,并用该模型预测全量用户的资费不满意概率;
步骤三:使用机器学习算法,对资费不满意概率较高的用户的不满意权重进行计算。
2 实验数据准备
2.1 数据来源
本方法中使用的数据均来自于某地市运营商,该运营商主要经营移动语音、数据、宽带、IP 电话和多媒体业务。
2.2 数据采集
本方法采集了样本数据与用户信息数据。
(1)样本数据
资费满意度模型的训练需要使用满意与不满意用户作为正负样本,因此本文采集了近一年的资费满意度用户调研详单。
通过CATI(Computer Assisted Telephone Interview,计算机辅助电话访问)方式开展客户满意度调研。评分0-10 分,10 分表示非常满意,0 分表示非常不满。9-10 分为推荐者,7-8分为中立者,0-6 分为贬损者。
(2)用户信息数据
特征分箱是为了防止模型出现过拟合而将连续型特征进行离散化的处理方法,在分箱后,将分箱结果与原始特征均保留,同时放入模型进行特征筛选。
基础信息:包括年龄、性别、入网时长、用户星级等指标;
终端信息:包括是否合约机、是否4/5G 终端等指标;
投诉信息:包括是否历史投诉用户、当月投诉次数等指标;
五网属性:包括是否集团网/家庭网用户等指标;
宽带信息:包括是否宽带用户、宽带带宽等指标;
消费行为:包括当月通话分钟数、当月流量使用数、当月短信条数等指标;
套餐信息:包括流量主体套餐名称、套餐费用等指标;
电视信息:包括是否互联网电视用户、电视观看时长等指标;
1978年,我国实行改革开放政策。党的十一届三中全会决定“把党的工作重心转移到社会主义现代化建设上来”,自此我国体育开始了强国之路。在发展竞技体育的同时,群众体育也发生翻天覆地的变化,无论是群众体育发展的模式、思路、观念都发生了很大的变化。得益于社会大环境的改变和政府的协助,我国群众体育无论是在横向或纵向都有了突破性的进展,而国内学者对于群众体育的横向研究较多,对于群众体育的纵向研究相对较少,在此借改革开放40周年之际,对我国群众体育发展进行纵向研究并展望。
自我国实现改革开放后,社会经济体制得到了迅速发展,而当代企业的发展在这样的环境下也得到了大力推进,以此同时,其在发展过程中也面临着诸多挑战。由此,当代企业必须加强对危急意识的培养,在不断完善自身管理体系的同时,结合社会的发展需求成立一套具备针对性的企业管理系统。所谓管理会计是指将企业管理以及会计工作相互结合,不仅突破了传统财务管理的局限性,同时能够分析企业生产环节以及财务数据等方面来实现对企业管理重点的有效预测,以此为企业的生产经营等提供可靠保障。
营销案信息:包括营销案个数、营销案到期月份等指标;
掌厅使用信息:包括掌厅登录天数、掌厅套餐业务接触次数等指标。
人参为五加科植物人参Panax ginseng C.A.Mey.的干燥根和根茎[1]。具有大补元气、复脉固脱、补脾益肺、生津养血、安神益智等作用。多于秋季采挖,洗净经晒干或烘干。栽培的俗称“园参”;播种在山林中并在野生状态下自然生长的称“林下山参”,习称“籽海”。其炮制品为人参、红参。西洋参为五加科植物西洋参Panax quinquefolium L.的干燥根[1]。均系栽培品。秋季采挖,洗净,晒干或低温干燥。西洋参与人参为同科植物,且所含有效成分与人参基本一致,因此经炮制后的西洋参亦可入药,但在中药质量控制过程中需对人参、红参、西洋参的不同药材及炮制品进行区分。
3 算法概述
3.1 XGBoost
XGBoost 模型是一种决策树集成算法。XGBoost 的拟合过程是基于加法训练模型的启发式算法,其目标不再是直接优化整个目标函数,而是通过不断添加决策树并进行特征分裂来生长一棵决策树,来拟合之前的预测残差。整个过程如下所示:
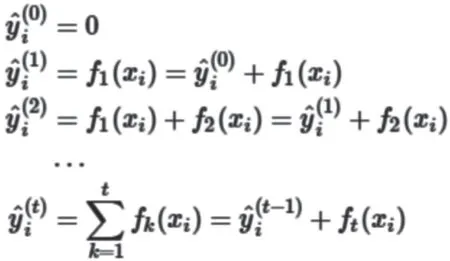
由于低分用户样本过少,需要通过负样本的过采样以及正样本的欠采样来保证分类模型的样本均衡,同时尽量使用更低分的用户作为负样本。从表1 可看出,使用5 分及以下用户作为负样本效果较好,在此基础上,使用不同正负样本比例调优模型,实验结果如表2 所示。

因为使用的损失函数是MSE,因此上式可变为:

对于一般的损失函数,需要将其作泰勒二阶展开,如下所示:
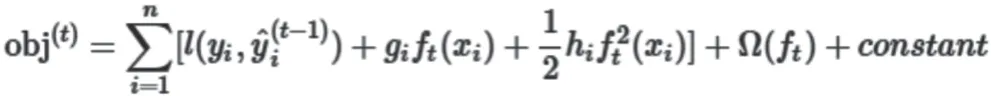
其中:

对于本项目的分类模型,损失函数为:

模型优化的目的是使目标函数最小化:

为了防止过拟合,在本项目中,添加了正则化项:

由此,目标函数可转变为:

可求解为:

至此就可以先求最佳的树结构,这个定出来后,最佳的叶子结点的值实际上在上面已经求出来了。
3.2 逻辑回归模型
步骤一:从不同维度的用户数据中,提取出与用户个体行为特征相关的指标;
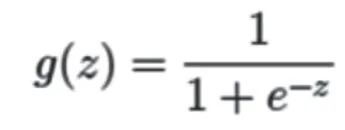
将原始的线性回归表达式带入g(z),就可得到逻辑回归的表达式:
一般情况下,葡萄酒的苹-乳发酵发生在酒精发酵之后,此时葡萄糖基本转化成乙醇,此时乙醇浓度约为12%vol,因此能够进行苹乳发酵的乳酸菌应该具备较强的耐酒精能力。我们按照方法1.2.2对45株乳酸菌进行了耐酒精能力测试,同时以商业乳酸菌株CH35(O.oeni)作为对照菌,进行酒精耐受性试验,结果见表1,对照组为不加乙醇组。
大量研究证明配戴角膜塑形镜可以显著控制近视增长,并获得良好的日间裸眼视力[2,3],但Chang和Liao[5]对201名小学生的调查发现只有53.2%的儿童日间摘镜后可以获得0.8以上裸眼视力。随着近视患病率的逐年升高,配戴角膜塑形镜的儿童人数也快速增加[1]。因此,探讨去片视力低下的原因以及对近视的控制作用对于提升验配效果意义重大。本研究通过回顾分析北京同仁医院验光配镜中心验配角膜塑形镜的50名近视青少年儿童,发现验配前球镜度越高,去片后的裸眼视力越差,而裸眼视力差儿童的近视增长同样得到了有效控制。

4 建模过程
4.1 样本分析
本文使用的样本数据来自于某地市运营商在2020 年4 月至2021 年2 月期间进行的用户满意度调研,如图1 所示。

图1 资费满意度分布图
从资费满意度分布图中可以看出,在一共7689个用户中,资费满意度10 分用户数量占比极高(48.11%),资费满意度7 至9 分用户占比较高(38.07%),而资费满意度0 至6 分用户占比最少(13.82%)。
4.2 数据清洗
将该地市的全量用户的基本信息数据进行清洗,包括缺失值填充、错误数据修改、字符串型特征转换、多类别型特征嵌入、套餐价格提取等步骤。其中套餐价格提取,是基于“流量套餐名称”、“语音套餐名称”、“其他套餐名称”的文本信息中匹配出价格信息。
4.3 特征工程
在模型训练之前,需要基于原始数据进行特征扩维、特征分箱、数据归一化、特征筛选等特征工程。
特征扩维是基于采集到的用户信息,对原始特征进行扩维,包括计算“流量套餐饱和度”、“超流量套餐流量数”、“超流量套餐费用”、“语音套餐饱和度”、“超语音套餐分钟数”、“超语音套餐费用”等指标。
从一般满意用户(5-8 分)与愉悦用户(9-10 分)的差距,和对满意度的影响权重来看,需要重点改善的感知要素包括:手机上网、价格水平、宣传、新业务;其次改善的有:促销、资费套餐、终端。因此,本方法采集了以下几类用户信息数据进行建模(本方法使用的数据集中,涉及到用户个人隐私的敏感信息均进行了脱敏处理):
精干设置党政部门及其内设机构。严格执行中央规定的机构限额,严格限定省市县党政机关最小规模。省市原则上不设20名行政编制以下机构,县级原则上不设10名行政编制以下机构。省级原则上不设5人以下处室,市县原则上不设3人以下内设机构。综合性内设机构不超过内设机构总数的三分之一。
在使用逻辑回归模型时,对连续型特征进行了标准化处理,将训练集的均值和方差当做是总体的均值和方差。样本x的标准分数计算如下:

其中u 是训练样本的均值,s 是训练样本的标准偏差。
本文采用了Boosting 中的特征重要性排序进行特征筛选,某个特征的重要性就是它在所有树中出现的次数之和。在特征重要性排序后,保留了前100 个特征进入模型。
银行业的发展离不开创新技术的支持,当前银行业要想提升自身的竞争力,同样需要借助新技术的支持与应用。但是,在应用新技术的时候需要能够适应银行的高风险、高收益、运转周期长的特点,并形成一个新型的金融服务方式,以此来促使更多的资金支持技术创新。同时,银行业还需要不断的提升互联网技术的更新,运用人工智能、云技术等现代化的科技来提升银行业的服务效率,降低成本,以此来提升银行业的服务实体经济能力,促使银行业更好的发展。
4.4 分类模型训练
(1)OSS 域(operation support system)即运营支撑系统。指的是电信运营商的后台支撑系统,包括各设备厂商自有的操作维护系统、统一调度的综合网管系统、以及综合资管系统等。

表1 负样本采样表
在第t 步时,添加了一棵最优的CART 树f_t,就是在现有的t-1 棵树的基础上,使得目标函数最小的那棵CART 树,如下所示:

表2 样本比例调优表

?
最终确实使用1:1 的正负样本比例进行模型训练。通过反复实验,确定超参数如表3 所示。

表3 样本超参数
使用以上最优参数训练模型时,可以得到预留的验证集结果,如表4 所示。

表4 实验结果表
其中0_precision 是预测出不满意用户的实际不满意率,是随机用户差评率(8.86%)的2.58 倍,说明模型效果显著。
4.5 归因分析
在训练分类模型后,将全量用户数据放入模型,即可输出全量用户的资费不满意概率,取出排名靠前的若干用户作为潜在资费不满意用户。
为了便于运营商有针对性地解决资费不满意问题,在输出潜在资费不满意用户后,使用了归因分析的方法对用户的资费不满意问题进行分析。
通过构建逻辑回归模型得到变量系数,从而计算出各个特征对资费不满意的贡献度。
盐胁迫会抑制植物的生长发育。当土壤含盐量过高时,会严重影响冰叶日中花的生理生化反应,造成其减产,甚至导致植株死亡。
在逻辑回归中变量 x 与概率是非线性关系:

如果x1增加一个单位,则胜率:
例5:萧炎和父亲之间的对话,父亲一直唤他为炎儿,“呵呵炎儿这么晚了怎么还待在这上面呢?”“炎儿还在想下午测验的事呢?”“炎儿你十五岁了吧?”

以系数β1为例,如果x1是连续变量,当x1变化一个单位且其他变量保持不变时,胜率变成了原来的eβ1倍。
因此,可以近似认为在特征统一量纲的前提下,逻辑回归的系数可以看成胜率的权重(eβ),注意是胜率而不是概率p。系数可以表示,它的存在使得概率如何变化。
基于4.2 中划分后的样本,使用逻辑回归算法训练一个分类模型,并提取出逻辑回归模型的系数,如图2 所示。
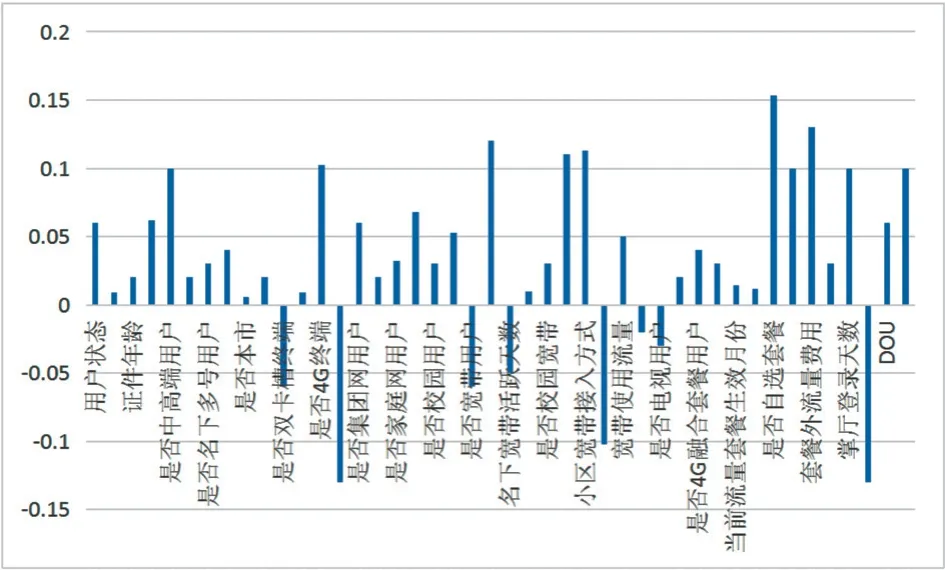
图2 回归系数分布
使用4.2中训练好的模型预测全量用户的资费不满意概率,输出不满意概率最高的50 万用户,根据逻辑回归模型的系数与用户特征,分别计算出该50 万用户的特征贡献度,如图3所示。
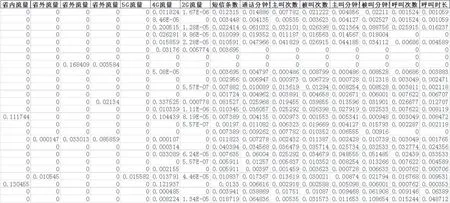
图3 特征贡献度
最后将每个用户特征贡献度排名前三的特征输出,作为潜在的资费不满意原因,如图4 所示。

图4 潜在资费不满意显著指标输出列表
5 结果对比
以某地市电信运营商地市数据为例,未使用模型前,使用规则筛选资费不满意用户,准确率仅15%。使用模型预测后,模型输出不满意概率最高的50 万用户,在全量用户随机抽潜在取资费不满意用户,用户出现在概率最高的50 万用户范围内的准确率高达50%。为在全量用户下使用规则筛选的3.3 倍。
6 结束语
本文以某地市电信运营商数据为例,对其用户数据清洗、下钻等特征工程,通过人工智能的机器学习算法,训练了资费不满意预测模型以及不满意归因分析模型,从海量用户数据中,快速聚焦潜在资费不满意用户,从预测出的潜在资费不满意用户中随机抽取验证,差评率是全量随机用户差评率的2.58 倍,效果显著;同时针对性地锁定可能造成该潜在资费不满意用户体验较差的原因,为电信运营商改进服务质量、提升用户满意度等工作提供了参考依据,助推电信运营商工作的降本增效。
