高效可扩展的网络流量分析系统优化方法
2022-07-08卢子晋姜海洋张广兴
景 阳 卢子晋 姜海洋 张广兴 曾 彬
1.江苏省未来网络创新研究院;2.吉林大学通信工程学院;
3.中国科学院计算技术研究所;4.湖南友道信息技术有限公司
0 引言
为了监测和防御网络入侵行为,网络中部署了大量的安全设备,如网络流量分析(Network Traffic Analysis,NTA)系统、入侵防御检测系统、防火墙等。随着网络带宽的快速增长,安全设备面临严峻的性能挑战。目前针对网络安全设备性能提升及扩展性问题的研究,大多集中在算法优化层面,如针对硬件资源的调度算法优化、针对具体业务层面的算法优化等,但是在生产环境中,所有资源都接近满负荷运行的情况下,各种调度算法就不能很好地发挥效果了。本研究以江苏省未来网络创新研究院建设的未来网络实验设施(China Environment for Network Innovations,CENI)中的NTA 系统为例,分析如何在多核、众核处理器上获得可扩展的流量处理能力。NTA 的系统架构是典型的安全设备系统架构,本研究通过分析NTA 的业务特性和使用场景,得出影响NTA 系统处理能力扩展性的两个主要方面:硬件层面的资源竞争问题和软件层面的资源竞争。然后从硬件和软件两个层面对NTA 系统的性能扩展性提出相应的优化方法。通过该方法,CENI 网管的NTA 探针子系统获得了200 Gbps 的处理能力。本研究提出的方法同样也可以应用到防火墙、入侵防御、入侵检测等安全设备中。
1 相关工作
在硬件层面,影响NTA 系统处理能力及扩展性的主要是处理器、三级缓存、内存、PCIe 网卡的工作方式。这些硬件之间的协作关系如图1 所示。对系统处理能力的影响主要有两个方面:一是报文在PCIe 网卡和内存之间传递时,跨NUMA 节点处理报文造成的性能消耗;二是内存和处理器之间的三级缓存占用不均匀,产生大量缓存不命中现象造成的性能消耗。
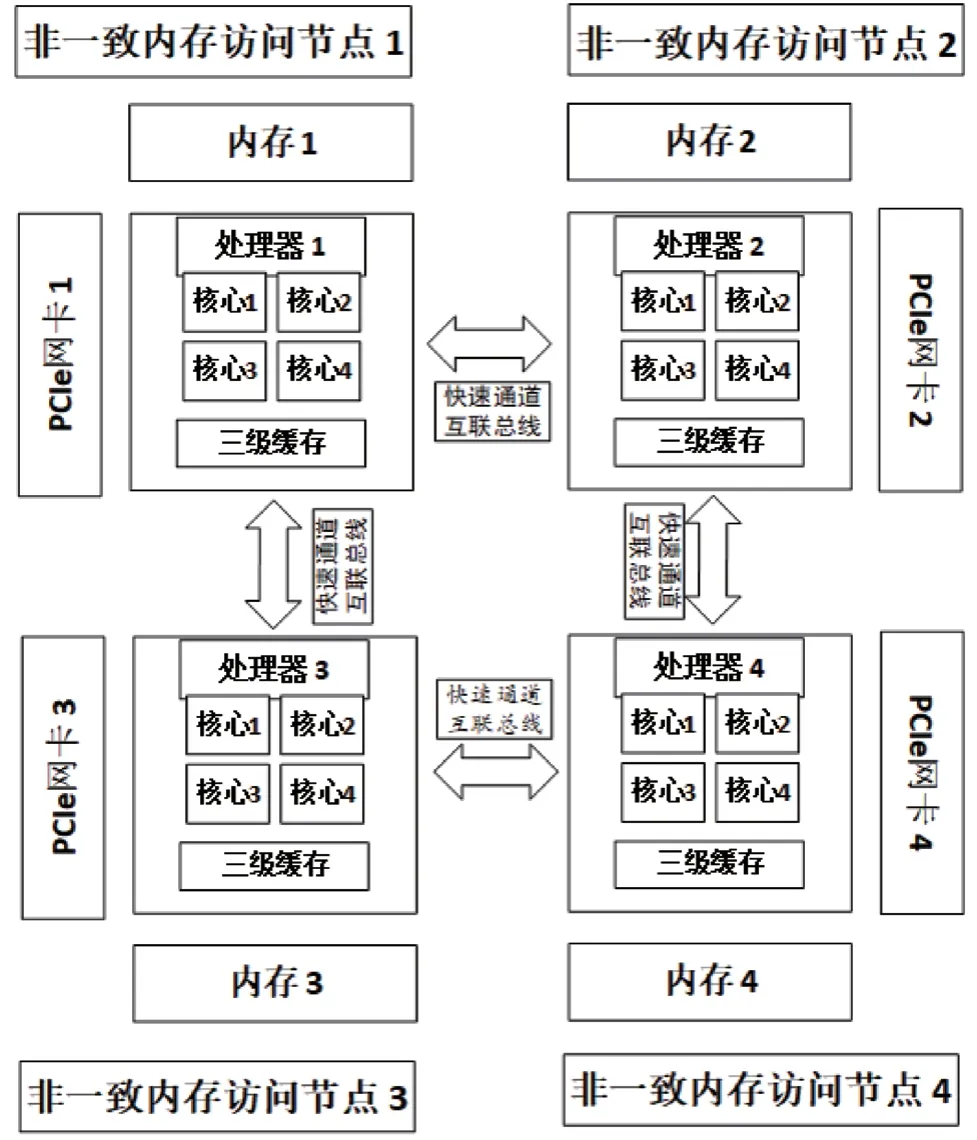
图1 处理器系统架构图
如何使用这些硬件设备才能使系统整体性能达到最优?学者们给出了一些解决方法,如,(1)Peter Zijlstra 等人提出的使用任务本地节点化来减少非本地内存访问频率的方法;(2)Mohammad Dashti 提出的使用优化算法“Carrefour”解决内存控制器和NUMA 节点互联中拥塞问题的方法;(3)intel DPDK 中对三级缓存的使用做的各种优化。但是这些方法都不能很好地解决NTA 系统中硬件最优化使用的问题。因为在NTA 业务场景中,通常需要接收、处理大量网络报文,这几乎可以消耗掉系统上所有的硬件资源,所以无论算法怎样合理,都会出现任务分配不均、数据拥塞等问题。因此,基于算法和系统自由调度的方式做的优化效果就会失效,从而使系统整体处理能力下降。所以还是希望能够根据设备的硬件特征自由配置特定的NTA 系统。
在软件层面,影响NTA 系统处理能力及扩展性的主要是NTA 系统的业务处理模型。NTA 的基础业务数据处理流程如图2 所示。其业务模型主要包括业务处理模块和数据维护两个方面。业务处理模块,指的是NTA 系统中负责特定业务功能的函数的集合组成的一个系统调用。NTA 业务主要的业务处理模块包括:报文采集、报文解析、流信息处理、流信息扫描、流信息导出等等。数据维护,主要指流数据维护。流数据不仅是各个业务模块处理的核心数据,还是其他重要数据间的桥梁,因此流数据的维护和管理是NTA 系统数据维护的核心。正是因为各个业务处理模块对数据操作的竞争关系,以及流数据的全局桥梁作用,影响了多线程架构的NTA 系统的性能扩展能力。

图2 NTA 基础业务数据处理流程图
要解决软件层面的资源竞争问题,主要是解决流表操作的冲突问题。人们给出了一些解决方法,如,(1)开源项目Suricata 中使用的扩大流表存储量,减少冲突概率的方法:(2)张建宇等人提出的使用多张流表按照某种方法做倒换使用的方法。这两种方法虽然可以缓解或者避免流表使用冲突,但是耗费了大量缓存,增加了I/O 开销。在流节点数量庞大的NTA 环境中,成本增长的流表缓存和I/O 开销,会使NTA 设备难以支撑。
综上所述,在NTA 这种特定类型的系统应用上,目前硬件层面已有的优化方法达不到想要的效果,而在软件层面已有的一些优化方法,在生产实践中的资源使用性价比又比较低。因此,本研究针对NTA 业务的特殊性以及在生产实践中的资源使用性价比和可行性,提出了对软件和硬件分别做优化的方法来解决上述问题。
2 基于DPDK 可扩展的收包框架
2.1 概述
本研究设计了一套基于DPDK 的收包可扩展框架,来解决硬件层面上各种资源使用策略及竞争问题。收包可扩展框架图如图3 所示。所谓框架是指一种基于模块化设计软件应用的场景,按照特定策略,设置、编排软件模块的全局层面的部署方式。此收包框架包括:信息提取器、模块编排器、模块部署装置。信息提取器的主要功能是:收集运行设备的硬件信息。模块编排器的主要功能是:按照收集到的硬件信息,根据预制的模块设置、编排模型,得出部署要使用的模块类型、模块个数、以及相互之前的协作关系。模块部署装置:根据模块编排器给出的模块设置参数,启动、运行、监控各个功能模块。

图3 收包可扩展框架系统图
这套收包框架的重点是“模块编排器”,其工作重点就是为了解决硬件层面的资源竞争问题,其输入是硬件设备信息,输出是业务模块部署时使用的各种参数。编排器的输入参数为:(1)PCIe 网卡所在NUMA、吞吐量、硬件特性;(2)处理器所在NUMA、总核数、单个NUMA 中核数、单核性能参数;(3)三级缓存分布情况、共享核数;(4)内存所在NUMA、大小。经过编排器得到的参数为:(1)使用到的系统模块类型,各个模块占用的核号及数量;(2)申请内存的节点位置及大小。对于给定的硬件资源,综合了生产实践中经常使用到的NTA 业务模块的排布使用方式,预设了一些模块编排方法,后续也会根据生产实践需要,不断完善和丰富模块编排器的编排策略,且模块编排器的修改并不会影响框架的其他部分。
本系统以动态库的形式实现了收包框架,提供对外接口给NTA 系统使用。配置NTA 系统时,根据系统的硬件信息配置参数,系统启动时会按照配置的参数,根据策略运行指定的收包及分发模式。
2.2 系统准备工作
模块编排器从硬件信息需要得到系统启动的准备工作指的是信息提取器获取到设备信息,将设备信息输入编排器得到系统启动参数,并启动系统的过程。
首先,信息提取器需要获取的硬件信息包括:网卡端口的流量采集能力、网卡收包队列的最大个数、处理器框架结构、内存分布情况及容量大小、共享三级缓存与对应的处理器核心信息。其中,网卡端口的流量采集能力代表可以接入系统的总流量大小;网卡收包队列的最大个数决定了每个端口的流量最多可以分成多少份;处理器框架结构及共享三级缓存与对应的处理器核心,决定了系统接入的流量如何分布在各个处理器核心上做处理;处理器的处理能力决定了单个处理器核心可以处理的报文量;内存分布情况及容量大小决定了可以申请的内存节点及大小。
其次,模块编排器从硬件信息需要得到的配置参数包括:(1)网卡初始化相关的参数:需要使用的端口、端口个数、端口启用的硬件队列个数、端口队列可容纳的报文个数等;(2)收包线程设置相关的参数:是否需要单独开设收包线程、线程个数及使用的逻辑核号等;(3)业务线程设置相关的参数:启用哪些业务线程、各种业务线程个数、是否绑核等;(4)报文转发方式相关的参数:丢弃、转发到指定端口、投递到共享内存给其他进程使用。
最后,模块部署装置按照启动信息,设置网卡、内存,启动收包线程、监控线程、扫描线程、信息导出线程,设置业务处理线程个数,等待收包。各个启动线程定义如下:
(1)收包线程定义:是本系统动态库创建的,直接调用DPDK 收包接口,并将DPDK 的报文结构转换成本系统动态库自有的报文结构的线程,此线程主要的工作是从DPDK 驱动层接受报文,然后根据配置需要做些简单的统计、解析工作。
(2)监控线程定义:是本系统动态库创建的,负责监控系统状态、连接状态、端口状态并定期输出状态信息的一类线程。
(3)扫描线程定义:非本系统动态库创建的,负责定期扫描、老化流表信息,并将流信息组织成固定输出格式的线程。
(4)信息导出线程定义:非本系统动态库创建的,负责导出动态库统计、收集的报文层次的基础信息的线程。
(5)业务处理线程定义:非本系统动态库创建的,专门做NTA 复杂业务解析的线程。但此线程的个数由本系统动态库设置并传递给创建此线程的进程,此线程的主要工作包括创建流表、做深层次的报文解析、做流量测量等工作。
2.3 收包分配策略
收包分配策略是按照配置文件具体参数部署收包模型的策略。策略设置是根据DPDK 的特性,以及实践中的使用习惯设置的,需要不断积累和调整。这里只介绍三种NTA 系统中常用的收包分配策略。
(1)针对小流量场景,一般情况是收包线程数量小于收包端口数量。可以按照端口数量,为系统分配1-2 个收包线程,然后再由收包线程将流量均衡地分配到多个业务线程。
(2)针对大流量、业务负载重的场景,一般情况是合并收报线程和业务线程。可以按照端口流量大小,为每个端口分配多个处理线程,每个处理线程均使用运行到完成(Run To Completion,RTC)的处理方式。
(3)针对单核处理能力差但是总核数多的场景,一般需要充分利用设备的硬件特性,尽量将业务模块分散到多个CPU 线程中去,尽可能达到负载均衡的效果。
3 基于硬件资源分区的竞争消除方法
3.1 概述
本研究提出了一种基于硬件的资源分区的竞争消除方法,来解决软件层面上的资源竞争问题。系统结构图如图4 所示。主要包括以下三个方面:(1)对流节点管理方式做了改造。对流表划分了两级区域,第一级以收包端口为单位划分区域,第二级以端口对应的收报线程为单位划分区域,因此每个业务处理线程只从对应的流表区域获取、归还流节点,从而消除各个业务处理线程之间的冲突。(2)对流表的扫描方式做了相应的改造。以端口为单位创建扫描线程,做分区扫描,按照预估的端口流量情况,通过配置为每个端口创建1 个或多个扫描线程,减轻了整体扫描的负担。(3)对数据的导出方式做了改造。按照不同的分区,通过配置预设的方式,增加导出线程数量、压缩导出数据,以此增加导出能力。
3.2 流表管理
为了实现流表添加、删除的无锁操作,本系统对流表做了区域划分管理,见图4 绿色的流表存储结构。以下将从流节点内存管理和流节点使用两个方面来描述对流表管理方式的优化。
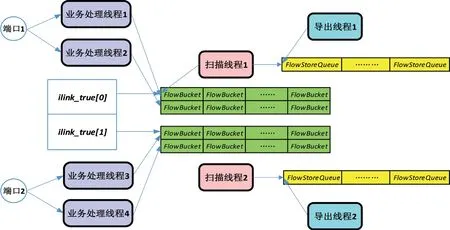
图4 系统结构图
(1)流节点内存管理。设计了一种无锁的流节点内存池管理结构。流节点存储使用的是一个二维数组全局变量,行数是链路个数,列数是业务处理线程个数,其中每一个节点维护一条Flow 类型的链表,链表存储的是预先申请的流节点内存。按照配置设置流节点数量的分配规则,整个内存是初始化的时候一次性申请好的。这种内存管理方式可以使每个业务处理线程、每条链路都有自己获取流节点的区域,所以获取流节点时不需要加锁。
(2)流节点使用。基于上述流节点内存管理方式,设计了一种将冲突最小化的流节点使用方式。先按照链路创建管理流表的哈希表,再结合业务线程数量、业务特征等为此哈希表划分区域。产生分区的哈希键值需要对原始的经过计算得到的哈希键值再做一次转化,原始哈希键值可以转化为“每个线程可使用的哈希桶个数乘以线程号,再加上原始哈希键值对每个线程可使用的哈希桶个数取余得到的数值”的形式。。这样做的原因是为了将流表维护及使用过程中的冲突限定在某一个扫描线程和某一个业务处理线程中。
3.3 流表扫描
针对上节实现的流表管理方式,设计了一种基于端口的流表扫描、信息存储机制,将流表操作的冲突限制在最小的范围,见图4 粉色的扫描线程和黄色流信息存储结构。流节点管理的最终目的是为了从有效的流节点中获取各种统计信息,所以需要创建与业务处理线程并行处理的扫描线程搜集要导出的各种信息。随着业务量越来越重,要搜集的信息也越来越多,扫描线程个数也需要相应的增加,而制定扫描线程个数设置策略的时候,也需要考虑流表使用冲突的问题。这里流表增删与流表扫描的冲突问题无法完全解决,只能尽量将其冲突最小化。综合上面的流表管理方式,本研究的处理方式是:为每条链路设置1 个或多个扫描线程,每隔一段时间扫描、老化一次哈希表中的流节点,并且拼装要导出的信息。每条链路的扫描线程个数,要依据流节点数量和处理器处理能力的经验值来设置。比如,如果这条链路产生的流节点较少且处理器处理能力强,则只需要设置一个扫描线程,如果这条链路产生的流节点数量很大且处理器处理能力又弱,则设置多个扫描线程。这种线程部署方式,将流表使用冲突限制在了每个基于端口的流表的一个业务处理线程和一个扫描线程之间,并且流表锁的范围是一个冲突链。
3.4 数据导出
针对上节实现的流扫描、信息搜集机制,设计了一种与之相匹配的日志导出机制,见图4 蓝色的导出线程和黄色流信息存储结构。NTA 系统要导出的数据量非常大,通常是要每隔一段时间导出几百万乃至上千万条流数据,并且每条流的数据长度可多达上千字节长度。所以为了提升扩展性,一般也会增设多个导出线程。本系统设计的日志导出机制从两个方面考虑:一是设置合理的导出线程数量及导出方式;二是将导出的数据做压缩来减轻单线程导出负担。导出线程的设置策略方面,与扫描线程一一对应,扫描线程将拼装的数据存储到输出队列中,导出线程定时检测队列中是否有数据,有数据则导出。另一方面,根据策略来设置是否要将数据做压缩,经过对各种压缩算法比较,综合考虑压缩率和压缩时间,我们最终选择使用Lz4 压缩算法来对单条流数据做压缩,通过压缩的方式可提升30%数据导出量。
综上三节的实现方式,可以做到流表的管理使用、扫描、信息导出,按照端口划分是完全独立的,并且在每个端口内部流量处理时冲突缩减到最小化。再加上硬件资源也可以按照端口独立,理论上我们的系统在对流量的处理、信息搜集导出能力上,是可以达到以增加不同端口接入流量的方式来使得系统处理能力线性扩展的。为了验证本研究设计的NTA 系统的处理能力以及性能扩展能力,找到了一款硬件资源相对独立的海光设备来做验证。
4 在海光设备上的应用
为了验证本系统处理能力及性能扩展性,选择了一款PCIe 网口数量较多、处理器核数较多、NUMA 节点较多、共享三级缓存对应的核较少、资源比较独立的海光设备作验证。
4.1 设备信息及使用策略
海光服务器硬件信息如下:(1)面板口信息:2 个100Gbps 的面板口。(2)处理器信息:型号为Hygon C86 7185 32-core Processor,2 座处理器,处理器为NUMA 架构,1 座处理器会分成4 个NUMA,每个NUMA 是8 个物理核心。(3)FPGA 芯片信息:共2 个FPGA 芯片,做报文分发。(4)PCIe号虚拟出来的口:每个虚拟口2 个收包队列。(5)面板口、FPGA 芯片、PCIe 号虚拟出来的口、内存、处理器之间的关系:1 个面板口对应1 个FPGA 芯片,1 个FPGA 芯片通过8 个PCIe 号虚拟出来的口,与一个处理器连接,此处理器有4 个NUMA 节点,2 个PCIe 号虚拟出来的口对应一个NUMA 节点。
针对上述硬件信息,首先用模块编排器进行编排。得到下面的结果:(1)在每个NUMA 上申请2G 巨页;(2)在每个NUMA 上,按照共享三级缓存的逻辑核,将1 个NUAM上的所有逻辑核分为2 组,则每组8 个逻辑核,将这8 个逻辑核分给1 个PCIe 口使用;(3)1 个PCIe 口对应的8 个逻辑核的使用方式是:设置2 个收包核、4 个业务处理核、1 个流表扫描核、1 个数据导出核;(4)设置16 个扫描线程、16 个导出线程、1 个监控线程。
之后用模块部署装置,根据收包分发策略及流节点扫描导出策略,设置系统运行模型。
4.2 测试结果及分析
使用测试仪构造各种不同长度TCP 和UDP 流量,测试优化后的NTA系统的处理能力及扩展能力,测试结果如表1所示。关于性能对比实验,不仅对优化前后的NTA 系统做了对比,而且还选用了一款具有代表性的、使用比较普遍的、开源的NTA 系统suricata,与优化后的NTA 系统做了对比。在使用suricata 做对比实验的时候,对suricata 的整体负载能力做了调整,使其与优化后的NTA 系统在单核处理能力上接近一致,这样做是为了使两者的对比实验更有可比性。对比结果如图5所示。

图5 三种NTA 系统处理能力对比

表1 优化后的NTA 系统处理能力
首先,对比在1 个NUMA 中增加处理器线程数是否可以使系统处理能力线性增加。根据表1 前两列测试结果可得:
(1)处理64 字节的TCP、UDP 流量。使用1 个NUMA中8 个线程,处理125 万流节点的能力是1.5Gbps;使用1 个NUMA 中16 个线程,处理250 万流节点的能力是3Gbps。所以在1个NUMA中对64字节流量处理能力是可以达到线性增长的。
(2)处理512 字节的TCP、UDP 流量。使用1 个NUMA中8 个线程,处理125 万流节点的能力是9Gbps;使用1 个NUMA 中16 个线程,处理250 万流节点的能力是18Gbps。所以在1 个NUMA 中对512 字节流量处理能力是可以达到线性增长的。
(3)处理混合字节的TCP、UDP 流量。使用1 个NUMA中8 个线程,处理125 万流节点的能力是13Gbps;使用1 个NUMA 中16 个线程,处理250 万流节点的能力是25Gbps。所以在1 个NUMA 中对混合字节流量处理能力是可以达到近似线性增长的。
(4)处 理1518 字 节 的TCP、UDP 流 量。使 用1 个NUMA 中8 个线程,处理125 万流节点的能力是26Gbps;使用1 个NUMA 中16 个线程,处理250 万流节点的能力是50Gbps。所以在1 个NUMA 中对1518 字节流量处理能力是可以达到近似线性增长的。
由上述实验结果可以证明,优化后的系统在1 个NUMA中增加处理器线程数可以使系统处理能力达到近似线性增加的效果。
其次,对比增加不同NUMA 节点中的处理器线程数是否可以使系统处理能力线性增加。此型号设备共有8 个NUMA,每个NUMA 中有16 个处理器线程。表1 中16 个处理器线程使用的是1 个NUMA 中的所有线程、32 个处理器线程使用的是2 个不同NUMA 中的所有线程、64 个处理器线程使用的是4 个不同NUMA 中的所有线程、128 个处理器线程使用的是8 个不同NUMA 中的所有线程。根据表1 后四列测试结果可得:
(1)处理64 字节的TCP、UDP 流量。使用1 个NUMA节点处理250 万流节点的能力是3Gbps;使用2 个NUMA 节点处理500 万流节点的能力是5Gbps;使用4 个NUMA 节点处理1000 万流节点的能力是10Gbps;使用8 个NUMA 节点处理2000 万流节点的能力是20Gbps。所以在多NUMA 中处理64 字节流量可以达到近似线性增长。
(2)处理512 字节的TCP、UDP 流量。使用1 个NUMA节点处理250 万流节点的能力是18Gbps;使用2 个NUMA 节点处理500 万流节点的能力是34Gbps;使用4 个NUMA 节点处理1000 万流节点的能力是68Gbps;使用8 个NUMA 节点处理2000 万流节点的能力是134Gbps。所以在多NUMA 中处理512 字节流量可以达到近似线性增长。
(3)处理混合字节的TCP、UDP 流量。使用1 个NUMA节点处理250 万流节点的能力是25Gbps;使用2 个NUMA 节点处理500 万流节点的能力是50Gbps;使用4 个NUMA 节点处理1000 万流节点的能力是100Gbps;使用8 个NUMA 节点处理2000 万流节点的能力是200Gbps。所以在多NUMA 中处理混合字节流量可以达到近似线性增长。
(4)处 理1518 字 节 的TCP、UDP 流 量。使 用1 个NUMA 节点处理250 万流节点的能力是50Gbps;使用2 个NUMA 节点处理500 万流节点的能力是100Gbps;使用4 个NUMA 节点处理1000 万流节点的能力是200Gbps。所以在多NUMA 中处理1518 字节流量可以达到近似线性增长,并且远远没有达到系统的最大处理能力。
由上述实验结果可以证明,在多NUMA 系统中优化后的系统处理能力也是近似线性增加的。
对比图说明:(1)图5(a)、(b)、(c),使用的16个处理器线程是NUMA 0 中的;使用的32 个处理器线程是NUMA 0-1 中的;使用的64 个处理器线程是NUMA 0-4 中的;使用的128 个处理器线程是NUMA 0-7 中的。(2)图5(d),由于报文长度较长,优化后的系统可以只使用NUMA 0-1 中的处理器,就可以处理所有来自面板口1 的流量,又由于硬件架构原因,优化后的系统需要使用NUMA 6-7 中的处理器,来处理所有来自面板口2 的流量。所以优化后的系统只需要NUMA 0-1、6-7 的64 个处理器线程,就可以处理最大可接入的200G流量了,而优化前的系统和suricata 还需要继续使用其他线程。(1)64 字节流量。优化后的最大处理能力比suricata 系统高出1 倍,比优化前的系统高出1.85 倍。(2)512 字节流量。优化后的最大处理能力比suricata 系统高出1.68 倍,比优化前的系统高出7.9 倍。(3)混合字节流量。优化后的最大处理能力比suricata 系统高出1.67 倍、比优化前的系统高出11.5 倍。
由4 组不同长度报文的对比图可以看出,优化后的系统无论是在单核处理能力方面,还是在性能扩展性方面,都比优化前的系统和suricata 系统要好很多,并且系统最大处理能力要远远高于后两种NTA 系统。由此可以证明,优化后的系统整体处理性能有了很大提升。
5 结束语
本研究提出的优化方法从硬件和软件两个方面对NTA 系统做优化,设计了一套基于DPDK 的可扩展收包框架,可以在硬件资源上按照NTA 系统的业务特性,将资源做合理划分,解决硬件层面的资源竞争问题。提出了一种基于硬件的资源分区竞争消除方法,虽然不能完全解决冲突问题,但是已将冲突范围大大减少,且不会消耗大量缓存资源、不影响系统扩展性。通过硬件、软件两方面的优化,可以使NTA 系统随着资源的增加,处理能力达到近似线性增长的效果。基于该方法,在一款海光国产化平台上,对NTA 进行性能优化,实验结果表明,本研究设计的NTA 系统的实际性能扩展性与理论上的效果相符,可达到线性增长的效果。目前优化后的NTA 已经应用于CENI 网管的NTA 探针子系统上,后续会逐步将该方法推广到网络安全领域的其他设备上。
