基于IDA microcode的控制流反混淆框架设计与实现
2022-07-08符笑彬钟晓雄郑彦斌
符笑彬, 丁 勇, 钟晓雄, 郑彦斌,2
(1.桂林电子科技大学 广西密码学与信息安全重点实验室, 广西 桂林 541004;2.曲阜师范大学 数学科学学院, 山东 曲阜 273165)
代码混淆是一种常见的软件保护方案,可将目标程序转换为更复杂但在语义上等效的混淆程序,主要目的是让逆向分析人员难以解读出软件的内部逻辑[1]。Obfuscator-LLVM(O-LLVM)是最著名的代码混淆器之一,它可以有效抵御攻击者对混淆程序的逆向分析。O-LLVM官方提供3种混淆方法:指令替换、虚假控制流和控制流平坦化。随后有多位开发者在O-LLVM官方版本基础上进行修改并开源,增加了更多的混淆方案,例如:字符串加密[2]、寄存器间接跳转[3]、函数间接调用[3]、指令虚拟化[4]等。
O-LLVM可以有效保护软件知识产权,同时也被广泛应用在病毒、木马等恶意软件。因此,实现 O-LLVM反混淆对于维护健康的软件安全生态环境具有重要的现实意义。
2015年,Yadegari等[5]提出了一种基于模拟执行的反混淆方法。但是,此类方案主要存在以下缺陷:1)反混淆完整度较低:由于条件分支的存在,很多情况下该方案无法执行到所有可能的路径。例如,在许多恶意软件程序中,只有在满足特定触发条件时,才会执行实现恶意行为的特定代码路径[6]。2)存在多种反模拟执行方案:代码虚拟化[7]、加壳与代码自修改[8-9]。3)补丁二进制困难:补丁二进制文件只能修改原指令,而不能随意添加新指令。
2019年,Kan等[10]提出了基于符号执行的安卓应用程序反混淆方案。虽然符号执行弥补了模拟执行的前2个缺陷,但仍然主要存在以下问题:1)存在多种反符号执行方案:Anand等[11]将符号执行的弱点分为复杂约束、路径发散和路径爆炸,由此设计和实现了对应的反符号执行方案。例如,攻击SMT约束求解器使得符号执行探测不到目标路径等[12-13]。2)符号执行路径爆炸:当被混淆的函数本身逻辑过于复杂时,符号执行会产生路径爆炸问题,导致严重耗时以至于无法执行完毕[11]。3)补丁二进制困难。4)真实块识别困难:当遇到定制化的O-LLVM混淆时,原本的真实块识别算法会失效,而且仅依靠分析汇编指令很难开发新的真实块识别算法。
2019年,Garba等[14]提出了基于中间语言LLVM-IR的O-LLVM反混淆方法,该方案在多个方面优于模拟执行和符号执行方案。但是,其只能针对虚假控制流进行反混淆,却不能处理控制流平坦化。由于该方案重度依赖开源项目Remill[15],导致其不支持ARM32架构。在移动平台上ARM32架构占有率极高,因此该方案不适用于绝大多数移动平台。
为了解决上述难点,提出了一种基于IDA microcode的反混淆框架BinDeob。引入中间语言(intermediate representation,简称IR)IDA microcode的主要目的是解决文献[14]不支持ARM32架构的问题,采用IR带来了架构无关的优势,因此BinDeob支持ARM32、ARM64、x86、x64等多种指令集架构。但IDA microcode本身不具备控制流反混淆能力,需要在此基础上开发相关反混淆算法。具体来说,BinDeob的反混淆操作是O-LLVM混淆的逆过程,将二进制代码提升到IR IDA microcode,即等价于O-LLVM混淆器使用的LLVM-IR,更有利于反混淆算法的实现。另外,在定制化混淆中,不仅真实块的识别会变得更加困难,而且某个真实块可能被多次复用。BinDeob在IR层通过兼容定制化混淆的真实块识别算法和复用块分割算法可以很好地解决这些问题。
1 背景知识
1.1 Obfuscator-LLVM
Obfuscator-LLVM(O-LLVM)是x86和ARM平台上使用最广泛的代码混淆器之一[16]。O-LLVM旨在为软件提供代码混淆和防篡改的功能,充分提高了软件的安全性。它具有良好的混淆效果、定制化的混淆方案、不依赖于编程语言和平台体系等特点,因此被广泛应用于软件安全领域。但是,恶意软件开发者也逐步在恶意软件中使用该混淆技术,以提高安全人员的分析难度,增加安全人员分析恶意软件所需的时间成本。官方版的O-LLVM提供了以下3种混淆技术。
1) 指令替换。指令替换是O-LLVM中最简单的混淆技术,使用功能等价但更复杂的指令序列代替标准的二进制运算指令。通常一条标准运算指令能匹配多种等价的指令序列,O-LLVM将随机选取并组合,进而增加代码的多样性。
2) 虚假控制流。在随机选择的基本块之前添加条件跳转,该跳转指向原始基本块或永远不会被执行的虚假基本块[16]。为了避免被编译器优化,新添加的基本块通常包含不透明谓词,同时确保在运行期间仅执行原始基本块[10]。
3) 控制流平坦化。控制流平坦化的思想最早由美国维吉尼亚大学的 Wang[17]提出,之后Chow等[18]详细证明了其正确性。2009年,Lszl等[19]将控制流平坦化技术运用于C/C++代码的保护。控制流平坦化会将正常的程序流程转换为switch结构,使得基本块之间的联系碎片化,导致逆向分析人员无法直观地判定出基本块之间的先后关系,进而提高逆向成本。
一般来说,指令替换和虚假控制流都是指令级别的语义混淆,而控制流平坦化是函数级别控制流的整体重构[10]。因此,控制流平坦化是最有效且最难还原的混淆方式。
1.2 IDA Microcode
IDA Pro作为业界安全人员的必备工具之一,其强大的反编译功能深受广大安全爱好者喜爱。从IDA 7.2版本开始,IDA开发团队开放了microcode API[21],使得用户可以改善反编译器的输出结果。与低级汇编语言相比,反编译器生成的高级语言(也称为伪代码)具有简洁、结构化、易于理解等优点,甚至可与程序源代码相媲美[22]。
IDA可将不同架构的汇编指令转换为同一种形式的microcode,然后反编译器对其进行优化和转换[21]。因此,对于反混淆研究来说,操作microcode API可忽略指令集架构的差异,只需关心反混淆算法的实现,最后直接生成反混淆后的高级语言。特别地,IDA在内部优化和转换microcode时,会存在不同的9个成熟度阶段(MMAT_ZERO,MMAT_GENERATED,MMAT_PREOPTIMIZED,MMAT_LOCOPT,MMAT_CALLS,MMAT_GLBOPT1,MMAT_GLBOPT2,MMAT_GLBOPT3,MMAT_LVARS)。在不同的成熟度阶段,编译器所做的优化操作也不同,根据需要选取适当的成熟度阶段会使得反混淆操作事半功倍。同时,在反混淆处理中需要注意不同成熟度真实块之间的对应关系。
2 反混淆框架的算法设计与实现
控制流混淆一般包括虚假控制流和控制流平坦化。通过配置IDA pro的Segment权限即可自动对抗虚假控制流。在反混淆中,BinDeob操作microcode API将被混淆函数的汇编指令转换为中间语言,再通过设计的兼容定制化混淆的真实块识别算法和复用块分割算法对中间语言进行优化和控制流重建,最后得到反混淆后的伪代码。在BinDeob的设计过程中主要考虑如下3个问题。
1) 真实块识别。在被定制化混淆器保护的代码中,可能存在多个主分发器与预分发器或者只存在主分发器,文献[10,20]中提出的真实块识别算法均会失效。本文提出一种兼容定制化混淆的真实块识别算法,可同时适用于标准和定制化混淆器。
2) 复用块分割。在定制化混淆中,经常出现某个真实块被多次引用,但该真实块的后继块却不唯一,这里称之为复用块。因此,在反混淆时必须多次拷贝复用块。文献[5,10,20]的反混淆操作目标为汇编指令,均难以完成分割操作。本文使用中间语言IDA microcode可以很好地解决该问题。
3) 控制流重建。在确定了真实块及真实块之间的先后关系后,通常还需考虑真实块有分支与无分支2种情况,最后通过修改相应的跳转指令重建控制流程。
围绕以上3个问题,提出了基于IDA microcode的控制流反混淆框架BinDeob,其架构如图1所示。具体工作流程为:1)给定一个O-LLVM混淆保护的二进制文件,BinDeob框架首先通过真实块识别算法得到难以识别的真实块、映射表等信息,该算法能同时适用于标准和定制化混淆器;2)利用复用块分割算法复制并重组被复用的真实块,使得BinDeob在降低控制流重建难度的同时提升反混淆的准确率;3)根据真实块更新的平坦化变量值重建控制流程;4)得到反混淆后的伪代码。
2.1 真实块识别
为了更加准确地反混淆,首先需要识别出全部真实块,即包含原始操作的块。在实际工程应用中,大多数为定制化的O-LLVM混淆器,此前文献[10,20]的反混淆研究均不能适用。此时被混淆函数的控制流程图已不再具备相关规律,可能出现多个主分发器或者缺失预分发器,导致原真实块识别算法无法正常工作。为了兼容定制化O-LLVM混淆器,结合多指令集架构在IDA microcode的特性,将混淆后的控制流结构分为以下5类基本块,如图2所示。

图2 被混淆函数的控制流程
1) 序言:包含函数中大部分常量以及控制流混淆中的平坦化变量的初始化操作。平坦化变量是O-LLVM添加的决定控制流走向的变量,相当于switch语句中的变量表达式。
2) 主分发器:序言的后继块且入度最大,通常将入度最大作为识别特征。
3) 子分发器:尾指令为某个平坦化常量与平坦化变量的条件跳转。平坦化常量是指O-LLVM分配的多个随机常量,相当于switch语句中case的常量表达式。
4) 返回块:唯一一个出度为0的基本块。
5) 真实块:除以上外,其余为真实块。通常先更新平坦化变量,再无条件跳转到分发器,之后进入下一轮的switch选择结构中。
在5类基本块识别过程中,最难识别且最关键的是真实块。当全部的真实块未被完全识别时,会导致反混淆的结果语义不一致;当分发器被错误识别为真实块时,则不能达到预期的反混淆效果。另外,在一些定制化的混淆器中,真实块之间会出现复用的情况,也需要精准地判断其是否为真实块,以供后续进行分割处理。因此,提出了一种针对定制化混淆的真实块识别算法。
算法1真实块识别算法
输入:dispatch主分发器,block_to_key真实块与平坦化常量映射表
输出:真实块列表
/*递归识别后继的真实块*/
function RecRealBlock(blk_no,dispatch,result)
for disp_succ in get_mblock(blk_no).succset do
if disp_succ == dispatch then
continue
else
if disp_succ not in result then
result.append(disp_succ)
RecRealBlock(disp_succ,dispatch,result)
end if
end for
end function
/*获取所有真实块*/
function Get_RealBlocks(dispatch,block_to_key)
RealBlocks = []
for block in block_to_key do
tmp_realblock = []
RecRealBlock(block,dispatch,tmp_realblock)
for rb in tmp_realblock do
if rb not in RealBlocks then
RealBlocks.append(rb)
end if
end for
end for
return RealBlocks
end function
上述真实块识别算法的主要思想是借助规律性强、易识别的分发器逆推得到难以识别的真实块。因此先准确地识别全部分发器,进而确定真实块、真实块与平坦化常量的映射关系,供后续控制流恢复使用。在真实块识别前,需要先从序言中提取平坦化变量,再确定主分发器的位置。具体操作流程如下:
1) 确定平坦化变量。若序言中存在mov指令的源操作数为常量类型,目的操作数为堆栈变量类型,则记录目的操作数。被混淆函数的控制流程图具有图2的一般规律,平坦化变量会多次出现在子分发器的条件跳转指令中,且满足的条件跳转指令只有jz与jnz。因此,扫描整个函数的jz与jnz指令,当满足右操作数为常量类型,左操作数为堆栈变量类型时,记录左操作数。之后筛选出现最多的堆栈变量,即为平坦化变量,且该变量应存在于序言中。最后根据平坦化变量可快速准确地定位子分发器。特别地,在一些定制化的混淆器中,平坦化变量会赋值到中间变量,导致其未出现在序言中,此时可引入污点分析技术解决该问题。
2) 建立平坦化常量与真实块的映射。扫描子分发器的条件跳转指令,当操作码是jz时,平坦化常量为右操作数,与之对应的真实块为目的操作数;当操作码是jnz时,平坦化常量为右操作数,与之对应的真实块为该子分发器的另一个后继块。
3) 递归识别真实块。通常第2步得到的真实块并不完整。如图2所示,Block7可由Block2计算得到,但Block8与Block9未被识别。因此在算法1中,遍历已知的真实块的全部后继块,使用递归算法完整且准确地识别其余真实块。
2.2 复用块分割
在一些定制化的混淆器或者编译优化后的程序中,还会遇到更加复杂的情况,如真实块被复用等。被复用的真实块可能出现在任意位置,这对反混淆操作目标为汇编指令的方案是致命的。因为在一个二进制文件中不能随意添加新指令,同时在汇编指令级别准确识别真实块是一件困难的事情。
如图3所示,真实块被复用的情况通常可以分为2大类:无分支的单个真实块和有分支的一组真实块。实际上,以上2大类还会组合出更多样、更复杂的复用情况。在第一种情况中,A、B两组真实块共用一个真实块。该被复用的真实块一般主要负责更新平坦化变量,而此时将存在3种不同的平坦化常量影响平坦化变量的取值,最终决定控制流程所到达的下一组真实块。同理,在第二种情况中,平坦化变量将存在最多4种不同的取值。

图3 真实块复用示例
如图4所示,在真实块被复用时,最终理想的还原效果是将复用块拷贝多次,并修复指向主分发器的无条件跳转指令目的操作数为真实目标真实块。但在实际操作中,真实块的复用情况还会更加复杂,不仅需要制定新的控制流重建规则,还要创建大量真实块、维护真实块之间的流程关系。由于复用块出现的位置不确定性,基于上述规则的匹配拆分处理是困难的。针对该难题,提出了一种被复用的真实块分割算法。

图4 复用块分割效果
算法2复用块分割算法
输入:dispatch主分发器, RealBlocks真实块列表
输出:分割后的真实块
for rb in RealBlocks.GetRepeatBlocks() do
blk ← get_mblock(rb)
for pred_num in blk.predset do
if pred_num != blk.serial - 1 then
p_blk←get_mblock(pred_num)
if is_mcode_jcond(blk.tail.opcode) then
/*处理有条件分支块*/
Split_JCCBlk(blk,p_blk,dispatch)
else
while blk.succ(0) != dispatch do
/*拷贝并追加指令*/
Copy_AppendMinsns(blk,p_blk)
blk←get_mblock(blk.succ(0))
end while
Copy_AppendMinsns(blk,p_blk)
/*修复Goto指令*/
ChangeGoto(p_blk, p_blk.succ(0))
p_blk.mark_lists_dirty()
end if
end if
end for
end for
在算法2中,核心思想是复制并重组被复用的真实块,这得益于准确的真实块识别,否则分发器会干扰分割效果。当分割操作完成后,程序流程回归常规情况,兼容了常规反混淆流程,在降低控制流重建难度的同时,提升了反混淆的准确率。
2.3 控制流重建
根据真实块更新的平坦化变量值和映射表重建控制流程。在常规的控制流重建阶段,需要考虑以下2种情况:
1) 真实块无分支:如图2中Block4所示,真实块Block4不存在条件分支。由Block4的尾指令开始向上扫描mov指令,当源操作数为常量类型且目的操作数为平坦化变量时,该源操作数即为当前真实块的平坦化常量。最后修改Block4的尾部goto指令,将无条件跳转目标更新为映射表中对应的编号。
2) 真实块有分支:如图2中Block7、8、9所示,真实块Block7存在条件分支会影响到Block9中平坦化变量的赋值情况,因此Block8与Block9的跳转目标不同。于是将Block9的指令复制到Block8的尾部,接着与无分支的操作类似。如图5所示,由映射表计算出真实目标基本块块号,并修复goto指令目的操作数为该块号,即可完成重建。

图5 有条件分支重建
3 实验评估与对比分析
选取 C/C++经典混淆基准[23]和公开的高危安全漏洞作为数据集,采用控制流程图相似度、语义等价、伪代码相似度作为评估指标,对提出的BinDeob进行实验评估。最后从反混淆操作语言、指令集架构支持、对抗反符号执行、对抗反模拟执行、对抗定制化混淆、恢复函数伪代码、平均CFG相似度7个方面,将BinDeob与Yadegari[5]、BARF[20]、DiANa[10]、SATURN[14]反混淆框架进行对比分析。
3.1 实验环境
测试环境为LLVM-8.0.1、NDK 21.1.6352462、Visual Studio 2019、IDA pro 7.5 Service Pack 3及O-LLVM反混淆框架BinDeob。计算机配置为Windows 10 20H2、Intel®CoreTMi7-9750H CPU @ 2.60 GHz、RAM 32 GiB。
3.2 数据集
为了全面评估BinDeob的有效性,选取2个构建覆盖率高的可靠开源数据集。
1)C/C++经典混淆基准:C/C++混淆基准被广泛应用于混淆器及反混淆系统的评估,包括常见的基础算法、哈希函数和小型程序(包含IF,WHILE和FOR语句的组合)。使用其中的98个基准程序,同时又将每个程序编译为arm32、arm64、x86、x64四种架构的可执行文件,最后从多个指标评估BinDeob的有效性。
2) 公开的高危安全漏洞:选取较有代表性的Microsoft Windows本地提权漏洞 (CVE-2021-1732)[24],可以更严格评估BinDeob对抗真实威胁的有效性。该漏洞由微软公司披露于2021年2月,影响多种不同版本的Windows系统。普通权限的应用程序可利用该漏洞提升至System权限,被官方评为高危漏洞。
3.3 评估指标
评估指标采用控制流程图相似度、语义等价、伪代码相似度。
1) 控制流程图(control flow graph,简称CFG)相似度。CFG相似度被广泛用作混淆与反混淆评估的标准[5,10,14,25-26]。采用Hu等[28]提出的算法计算2个CFG之间的相似度,文献[29]证明该算法是最好的CFG比较算法之一。给定2个控制流程图G1和G2,此算法使用最大二分匹配来计算G1与G2的顶点之间的对应关系。设σ(G1,G2)为2个控制流图G1与G2之间的编辑距离,|Ni|是Gi的节点数,|Ei|是Gi的边数,则相似度计算式为
(1)
相似度为介于0和1之间的实数,数值1说明这2个图形是完全相同的,而数值0说明它们是完全不同的。
2) 语义等价(semantic equivalence,简称SE)。语义等价评估指标与文献[10]相同,只计算CFG相似度不足以证明反混淆后的函数,在语义上与原始函数等效[10]。给定反混淆后的伪代码以不同的输入并获取输出结果,最后与源代码同等操作下的结果进行比较。
3) 伪代码相似度(pseudocode similarity,简称PCS)。引入伪代码相似度作为重要的评估指标之一。在逆向工程中,静态分析二进制文件最快最好的办法是用IDA强大的反编译功能将汇编指令转换为伪代码。因此,不论使用哪种反混淆方案,在真实的逆向场景中都会将反混淆结果转换成伪代码。通过引入反混淆后的伪代码与原始源代码得到相似度,可以直观反映反混淆效果。但是该指标过于苛刻,因为即使不经过混淆,由汇编指令反编译得到的伪代码也会与原始源代码存在差距。在对比了多个代码相似度比对工具后发现,即使变量名称发生更改,源代码克隆检测工具CCFindeX[27]仍可准确提取并计算代码相似度,因此选用CCFinderX计算伪代码相似度。该工具最初是由Toshiro Kamiya开发,并在论文中介绍和证明了其有效性[30],它是对先前工具CCFinder的优化版本。
3.4 评估C、C++经典混淆基准
如表1、2所示,“Sim1”列表示混淆后函数CFG与原始函数CFG之间的相似度,“Sim2”列表示反混淆后函数CFG与原始函数CFG之间的相似度。实验结果表明,反混淆后平均CFG相似度约为0.989,语义等价平均为100%。

表1 BinDeob在C、C++数据集的反混淆结果(ARM32 ARM64)

表2 BinDeob在C、C++数据集的反混淆结果(x86 x64)
图6为测试程序中的SelectSort函数在反混淆前后的CFG变化。原始函数仅有12个基本块,但经过混淆后基本块数量暴涨至243个,同时,调用关系也变得十分混乱。对于被混淆的函数,无论进行静态分析还是动态调试,逆向所花费时间成本都将数十倍提升。如图6(c)所示,经过BinDeob处理后,基本块数量又降至13个,且CFG与原始CFG几乎一致。实际上,图6(c)中5、13块等价于图6(a)中12块,最终CFG相似度由0.085提升至0.966。另外如表3所示,Sim1列数据越小说明被混淆的函数越复杂,Sim2列数据越大则说明反混淆效果越显著,对比结果表明,BinDeob在更加复杂的混淆情况下仍比DiANa的反混淆效果出众。综上所述,在ARM32、ARM64、x86、x64架构中,BinDeob均能表现出色的反混淆效果。

图6 SelectSort函数CFG

表3 DiANa与BinDeob在ARM32的对比结果
3.5 评估公开的高危漏洞
评估公开的高危系统漏洞样本能最大程度反映BinDeob框架对抗实际威胁的能力。用开源的漏洞代码[31]对该代码中最重要的6个函数进行实验评估。
如表4所示,混淆后的平均CFG相似度为0.125,反混淆后的平均CFG相似度显著提升为0.983,同时,原始源代码与反混淆得到的伪代码的相似度平均值为0.976。这说明BinDeob可以有效对抗实际威胁,尤其是对于要求非常高的伪代码相似度指标,BinDeob仍能达到很好的效果。
3.6 对比分析
由表5可知,在指令集架构支持、对抗定制化混淆、恢复函数伪代码的对比中,BinDeob拥有绝对优势,而且平均CFG相似度优于表5中的其余框架。另外,根据表4的实验数据,反混淆后得到的平均伪代码相似度高达97.6%,直观反映了反混淆后伪代码的可读性和准确性。这些都说明该反混淆框架比表5中其他几个框架拥有更优秀的反混淆性能。
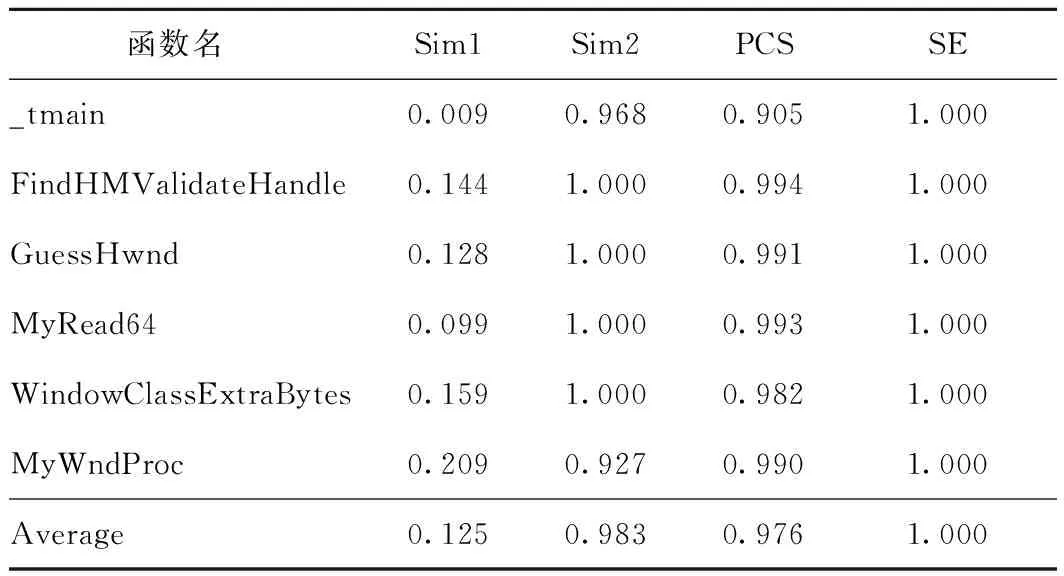
表4 CVE-2021-1732实验结果
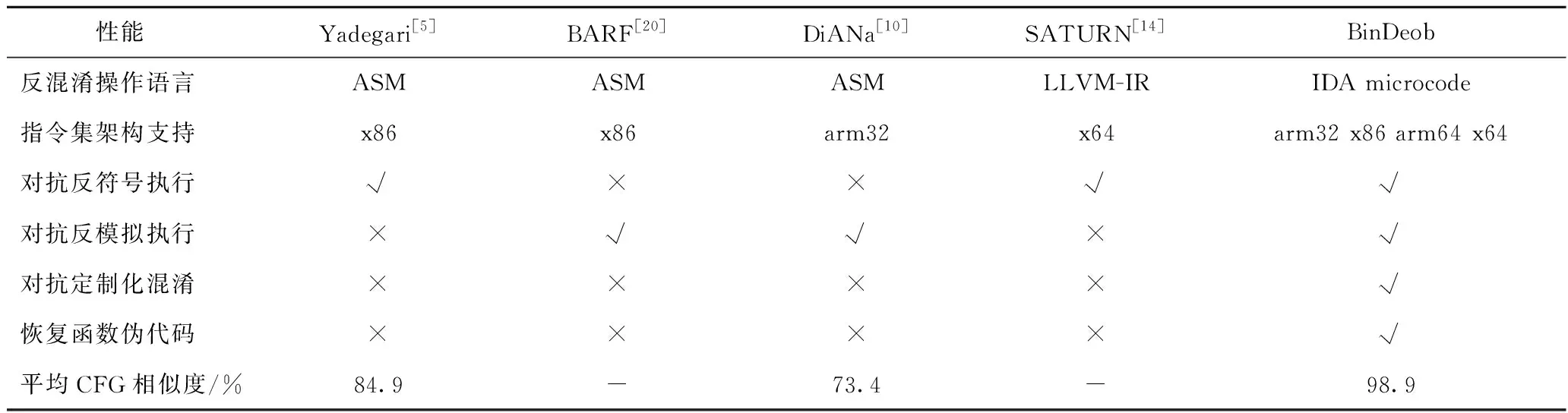
表5 反混淆性能对比结果
4 结束语
提出了一种基于IDA microcode的O-LLVM控制流反混淆框架BinDeob,通过针对定制化混淆的真实块识别算法及复用块分割算法重建严重混淆的控制流。目前,BinDeob可以很好地处理ARM32、ARM64、x86、x64架构可执行文件的O-LLVM控制流混淆。相对于参考文献中提出的其他框架,BinDeob拥有多架构支持、高扩展性、高CFG还原度、灵活对抗定制化混淆等诸多优势。另外,由BinDeob反混淆得到的伪代码与原始函数源代码相似度高达97.6%,反混淆后与原始未混淆的程序流程图相似度高达98.9%。这些都表明BinDeob相比其他框架具有更出色的性能。
虽然在O-LLVM控制流反混淆中,BinDeob表现出色,但由于缺乏动态运算功能,BinDeob仅适用于静态分析的方案。在字符串加密、间接跳转、指令虚拟化等混淆中,基于模拟执行或符号执行的动态分析方案占据主导地位。赋予BinDeob框架动态对抗能力是下一步的研究重点。
