基于改进MobileNetV3-Large算法的智能垃圾分类系统
2022-07-08赵一黄汉城丘文彬刘鑫陆漫洁
赵一 黄汉城 丘文彬 刘鑫 陆漫洁
(广东海洋大学 广东省湛江市 524000)
1 引言
我国每年产生近10亿吨垃圾,且每年以5%-8%的倍速递增,全国约2/3的城市,道路正在被垃圾“大军”包围。生活垃圾中有30%-40%都可以变废为宝,通过垃圾分类,不仅能减少占地,还能减少环境污染。传统上填埋和焚烧处理垃圾并不是优化的处理方式,如果经过垃圾分类,我们能大大提高对于垃圾资源的利用。现实生活中,大部分人对垃圾分类的知识了解并不全面,对于垃圾分类的意识较为薄弱,而传统的垃圾分类箱需要用户对垃圾分类的知识有一定的了解,它并不能高效地进行垃圾的分类,也难以提高用户的分类意识,导致实际垃圾分类的效果并不如预期。
针对以上垃圾分类存在的问题。本文提出了一款智能垃圾分类系统,该系统实现了软硬件的结合。软件模块是基于微信小程序实现,分成小程序端与服务器端。小程序端主要实现前端界面的展示,服务器端主要负责与小程序端进行交互,实现了网络在线的图像识别、文本识别、语音识别与积分答题等功能,让用户能够网络中了解垃圾分类的知识,提高用户分类意识。硬件模块是基于树莓派实现,分成树莓派与垃圾箱,树莓派作为垃圾箱的“大脑”,负责对垃圾箱中投入的垃圾进行识别并控制垃圾箱进行智能分类,实现了图像拍摄、图像识别、自动分类与自动喊话等功能,让用户能够在不了解垃圾分类知识的情况下也能够做到垃圾的精准分类,并通过喊话功能让用户了解其投放垃圾的具体分类,有效提高用户的垃圾分类知识。
本系统所采用的深度学习技术主要分成两大模型:图像识别模型与文本识别模型。图像识别模型与文本识别模型都是通过图像、文本提取出垃圾分类特征的关联属性,并于其领域规则进行匹配。图像识别模型以MobileNetV3-Large模型为基础进行模型搭建,其采用深度可分离卷积、倒残差结构、轻量级注意力结构以及hard_swish激活函数进行结合,实现了用户输入一张待识别的垃圾图片,通过图像识别模型的预测,能够有效反馈出该图像的具体分类结果。文本识别模型以LSTM模型为基础进行模型搭建,并采用了word_embedding技术(一种函数映射的关系,能够将文本的整数索引映射到密集向量中,有效提取到词与词之间的关系,增强文本特征信息的提取),实现了用户输入一段待识别的垃圾文本,通过文本识别模型的预测,能够有效反馈出该文本的具体分类结果。
2 相关工作
近年来,智能垃圾分类系统的相关研究主要包括以下方面:
基于云开发和微信小程序的垃圾分类系统实现。文献采用了微信小程序的云开发技术,调用百度AI接口实现通用物体和场景的辨认,调用腾讯地图API接口实现回收站的位置信息与路线规划。
基于深度学习的智能垃圾箱识别分类系统。文献的设计主要以搭载Tensorflow训练的CNN垃圾识别分类算法的树莓派与语音识别模块作为垃圾箱的主要部件,并增加了STM32单片机作为微控制器、红外和触摸模块辅助感应等技术。
基于树莓派和Arduino的智能垃圾桶。文献提出了一款基于树莓派与Arduino的智能垃圾桶,以树莓派作为主控制器,Arduino作为副控制器,通过操控舵机与电机实现垃圾的精准分类。
ResNet 网络下垃圾分类图像识别的实现,文献采用了ResNet152为网络结构搭建垃圾图像识别的神经网络,结合Androdi系统开发了一款垃圾分类APP。
目前,智能垃圾分类系统研究主要聚集于垃圾箱或小程序的单个结构进行设计,缺少两者搭配使用的组合结构设计。以小程序为结构设计的垃圾分类技术,它面向的对象是网络上的用户,有效增强网民的垃圾分类意识。以垃圾箱为结构设计的垃圾分类技术,它面向的对象是生活中的用户,有效增强用户在日常生活中的垃圾分类意识。本文将小程序与垃圾箱进行软硬件结合设计,面向的对象不仅仅是网络上的用户,也包含生活中的用户,这可以增大用户规模,更加有效提升全民的垃圾分类意识。
采用STM32单片机作为垃圾箱的控制器,这能够有效减低垃圾箱的开发成本。但是若要实现更上层应用的开发,STM32是无法实现的。而本文采用树莓派作为垃圾箱的控制器,其不仅拥有与STM32类似的IO引脚,可以直接控制其他底层硬件的功能之外,还可以完成更复杂的任务管理与调度,搭配操作系统,能够使用树莓派搭建小型的服务器,部署深度神经网络的代码。
正常情况下神经网络越深模型就能拟合更复杂的结果。但是在实际训练中,模型一旦加深效果不一定会更好,并且很有可能会产生拟合效果差,梯度消失等现象。ResNet残差网络能够很好解决这类问题,有效提高模型的准确率。但是ResNet的网络结构庞大,运算量多,需要较高的硬件支持。本文采用了MobieNetV3作为图像是被模型的基础,该模型引用了深度可分离卷积和1×1升降维层,具有在很低参数量和运算量的情况下获得较高的准确率,能够轻松部署在树莓派等硬件条件不足的环境当中,同时引入注意力机制,对不同层的输出比重具有较高的适应,一定程度上提高了模型的准确率。
3 算法模型
3.1 垃圾分类识别的知识构建
垃圾分类领域知识的构建,包括垃圾分类的概念、垃圾分类规则以及垃圾分类特征。通过图像特征提取算法与文本特征提取算法,提取出的图像、文本的特征对应于垃圾分类特征的关联属性。垃圾分类领域的知识来自于。该文献提供了垃圾分类的概念和垃圾分类领域规则。我国主要将垃圾分成可回收垃圾、厨余垃圾、有害垃圾以及其他垃圾的四大类垃圾类型。本文垃圾图像分类数据集一部分来自百度开放数据集,另一部分来自对百度搜狗等各大搜索引擎采用爬虫技术所爬取的数据集。图像分类除了分成可回收垃圾、厨余垃圾、有害垃圾以及其他垃圾的四大类垃圾类型外,还对每大类垃圾进行二级分类,共分成158小类,包括饼干、草莓、盘子、电池等具体类型。尽管百度开放数据集已经经过一定的筛选,但是仍然存在着跟爬虫一样的不可用图片,最常见的就是图片被截断,所以还是需要数据清洗,包括对爬虫所获得的图片进行人工筛选。
垃圾分类规则的例子如表1。

表1:垃圾分类规则表
3.2 图像识别模型
3.2.1 图像模型的数据集
本文垃圾图像分类数据集一部分来自百度开放数据集,另一部分来自对百度搜狗等各大搜索引擎采用爬虫技术所爬取的数据集。图像分类除了分成可回收垃圾、厨余垃圾、有害垃圾以及其他垃圾的四大类垃圾类型外,还对每大类垃圾进行二级分类,共分成158小类,包括饼干、草莓、盘子、电池等具体类型。尽管百度开放数据集已经经过一定的筛选,但是仍然存在着跟爬虫一样的不可用图片,最常见的就是图片被截断,所以还是需要数据清洗,包括对爬虫所获得的图片进行人工筛选。
3.2.2 图像模型的实现
本文图像识别模型采用以MobileNetV3-Large为基础模型。该作者结合NAS和NetAdapt技术对网络结构进行搜索,前者用于在计算量和参数量一定的情况搜索网络中的各个模块,后者用于对各模块确定的情况下对网络层进行微调。MobileNetV3引入了MobileNetV1的深度可分离卷积,MobileNetV2的具有线性瓶颈的倒残差结构,MnasNe引入的基于squuze and excitation结构的轻量级注意力模型,同时还加入hard_sigmoid和hard_swish激活函数。
(1)深度可分离卷积(Depthwise Convolution),DW的卷积核与输入通道数相等,即一个卷积核单独对上一层的一个feature map进行卷积操作,得到与输入通道数相等的输出通道数,与常规卷积相比DW参数数量可节约1/3,在同等参数数量的前提下可以使神经网络层数做的更深。如图1所示。
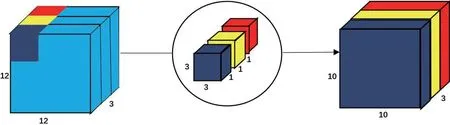
图1:DW卷积网络示意图
(2)倒残差结构,当网络做的足够深时,往往会遇到梯度消失和梯度爆炸的问题,尽管可以通过batch normilization正则化解决梯度的问题,但是网络性能却下降了,模型已经不能学习到新的信息。实验证明,单单一层y=Wx+x并不起作用,而残差网络在考虑计算优化的情况下,对两个3×3卷积层替换为1×1+3×3+1×1,这样可以对参数量减少了16.94倍,第一个1×1对卷积层进行升维,第二个则是对卷积层进行降维,降维后的通道应与输入通道数相等,并与输入x相加得到输出y。如图2所示。
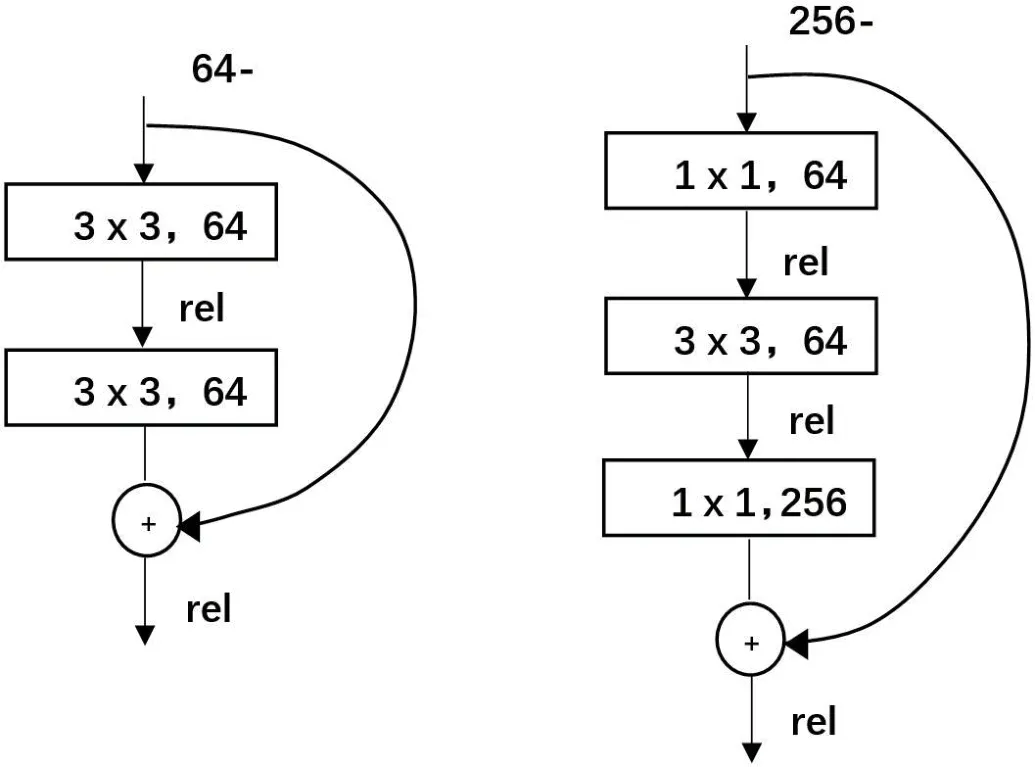
图2:倒残差结构
(3)轻量级注意力结构,SE block的思想是从空间信息的权重出发,利用feature map经过一系列conv操作获取BP优化后的各层权重。首先对H×W×C的feature map经过averatepool变成1×1×C的向量,再经过两次1×1的卷积,获得1×1×C的权重,最后将输入的各个通道的feature map与该向量相乘,获得最终的输出。如图3所示。
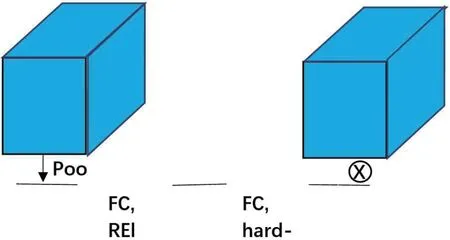
图3:注意力机制
(4)hard_swish激活函数通过hard_sigmoid来获得,hard_sigmoid是logistic_sigmoid激活函数的分段线性近似。它更容易计算,能使学习进行的更快。
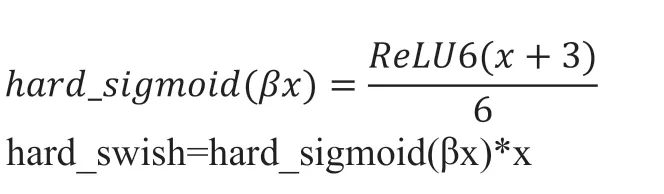
3.2.3 图像模型的效果
图像分类模型的数据集分成训练集与测试集,其中训练集有23,690训练样本,测试集有5,872测试样本。把数据放入模型训练前,需要对训练集进行数据增强,通过对图片进行水平翻转和垂直翻转,以及(0,30)度的随机抖动,并把图片随机裁剪成长宽为224大小的图像,还有饱和度、亮度、对比度和色调的随机抖动,最后对图像数据进行归一化。对上述的图像分类模型模型导入imagenet权重后进行50次迭代训练,并以Accuracy准确率作为评判该模型的评价指标,将每次迭代结果输出到tensorboard中,得到训练集与测试集准确率和损失值的关系图。将文本数据集按比例7:1分成训练集与测试集,可分成3500余条训练样本和500余条测试样本。训练样本用于不断输入数据训练垃圾文本分类模型,测试样本则用于该模型的测试。对上述的垃圾文本分类模型进行50次迭代训练,在每一次迭代后对模型进行测试,并以Accuracy准确率作为评判该模型的评价指标,模型准确率与迭代次数的关系如图4所示。
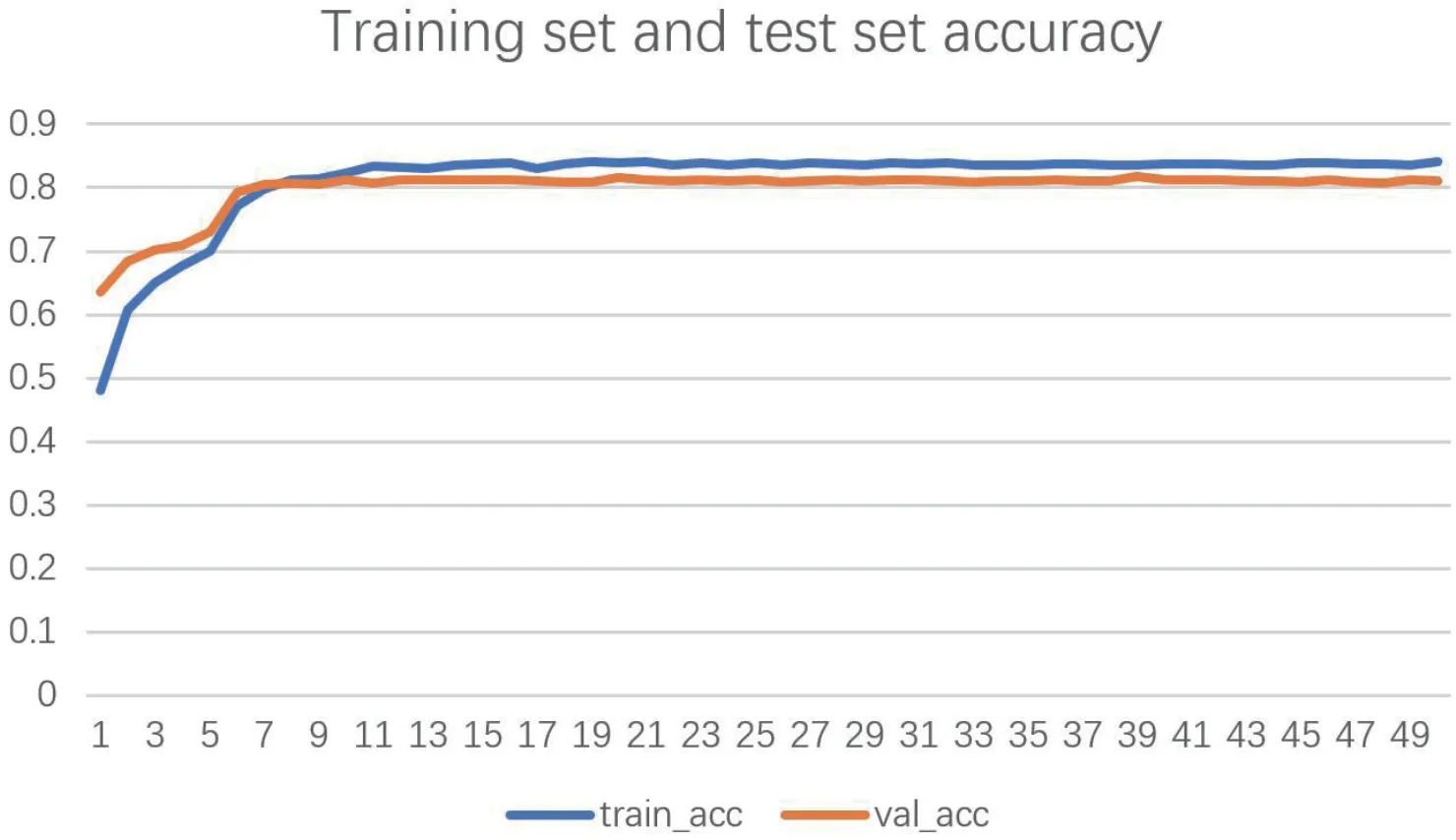
图4:图像模型准确率
可见,当模型训练的迭代次数达到10次后,其准确率达到80%以上,损失值降低到0.5~0.6的区间中。随着迭代次数的增加,模型的准确率逐渐趋于平缓增长,并最后稳定在81%。
4 结语
本文针对垃圾分类领域,提出了一个基于深度学习的智能垃圾分类系统。通过软硬件结合的模式,制作以微信小程序为基础的软件平台和以树莓派为基础的硬件垃圾箱。并采用深度学习技术,图像识别技术采用MobileNetV3-Large模型,通过对图像信息进行分析,得出“可回收垃圾、厨余垃圾、有害垃圾、其它垃圾”的四种一级垃圾分类以及“饼干、草莓、盘子、电池”等158种二级垃圾分类结果;文本识别技术采用LSTM模型,结合word embedding词嵌入,通过对文本信息进行分析,得出四种一级垃圾分类结果。未来工作包括尝试将图像识别模型的MobileNet模型所使用的注意力机制改为更为强大的移动网络注意力机制Coordinate Attention,在增加一定参数量的情况下增加网络的层数,提高图像模型的准确率,丰富垃圾类别。并采用多层LSTM结构替换文本识别模型中的单层LSTM模型,并添加attention注意力机制,提高文本模型的准确率。
