基于迁移学习与数据增强的蜘蛛识别平台研建
2022-07-07史晨阳杨自忠陈响育张宇航钱正坤王永良王建明
史晨阳,杨自忠,陈响育,张宇航,钱正坤,王永良,王建明*
(1.大理大学数学与计算机学院,云南大理 671003;2.云南省昆虫生物医药研发重点实验室,云南大理 671000)
蜘蛛在生态系统中具有重要地位,在生物防治、药物研究等领域中起重要作用,在维持农林生态系统稳定中的作用更是不容忽视。而要加速对蛛形类资源的研究、开发与利用,首先需要解决物种的鉴定与识别问题。目前已经有诸多植物、大型动物的智能识别技术或系统,一定程度上解决了科研、生产上缺乏专家指导的问题,但目前有关蜘蛛物种的智能识别研究鲜有报道〔1〕。因此,研究蜘蛛物种的智能识别技术,对于生态领域蜘蛛病虫害防治、物种保护、药物研发等方面具有极大的促进作用,具有较大的理论及实践价值。
当前深度学习是物种图像识别分类的重要方法,相比于人工筛选的方法,它能对图像高效识别和分类,减小识别错误率和缩短识别分类时间。深度学习的效果严重依赖于数据的数量与质量,数据量不足会导致模型识别精度低下。而对于物种图像数据的采集,难以有效保证数据的数量与质量,对于蜘蛛物种来说更是如此。大多数蜘蛛物种如颜氏大疣蛛(Macrothele yani)、白额巨蟹蛛(Heteropoda venatoria)等一般于夜间出没捕食且容易受到惊吓而逃跑,只能于夜间进行物种图像数据的采集,在一定程度上加剧了数据的采集难度,数据质量也难以保证。同时,对大量无标签样本进行标注工作也将会耗费极大的人力。因此,如何通过技术手段,有效提高蜘蛛物种图像数据的数量与质量,更好地支撑图像识别分类相关研究,是值得重点研究并解决的问题。目前,国内外对于蜘蛛识别研究有一定进展,Ticay-rivas 等〔2〕使用具有径向基函数的最小二乘向量支持机作为分类器,对蜘蛛进行识别和验证。Dolev 等〔3〕对跳跃蜘蛛的先天图案的识别和分类进行了研究。Clark 等〔4〕研究了跳跃蜘蛛的视频图像识别。然而,以上研究多是针对单一的一种蜘蛛进行理论上的研究,且没有形成可实际应用的系统软件。针对上述问题,本文设计了一种基于迁移学习的蜘蛛物种细粒度识别方法,以在ImageNet〔5〕上预训练的VGG-16〔6〕模型参数作为初始参数,从而利用预训练模型强大的特征提取能力,缓解训练数据不足带来的训练过拟合以及模型精度不足问题。并以此为基础,结合数据增强技术,研建了蜘蛛物种智能识别系统平台。
1 数据来源与处理
1.1 数据来源通过野外采集、网络爬虫的方式获取原始数据集,经专家人工分类鉴定并标注,之后采用下述方法进行数据增强。基于前景突出的蜘蛛数据增强示例见图1,数据集的划分和设置见表1。

图1 蜘蛛数据集

表1 数据集设置
1.2 数据增强
1.2.1 传统数据增强 传统数据增强是解决小样本学习问题的常用方法。流行的有几何变换类:翻转、旋转、裁剪、缩放变形、仿射,颜色变换类:噪声、随机擦除、模糊、超像素法、颜色变换〔7〕等。
1.2.2 基于突出前景的数据增强技术 基于显著性目标检测〔8〕(salient object detection,SOD)能够快速且较为准确地区分出一张图片中人们可能感兴趣的目标或区域,这样当面对日益增长的大量图像时,可以通过该方法分割图像中重要的部分,对于蜘蛛数据集使用显著性目标检测可以快速地提取蜘蛛前景。
本文针对小样本数据集模型训练样本量过少导致的过拟合问题,设计了一种可突出前景的数据增强方法,使用预训练的U-Net〔9〕图像分割模型对蜘蛛前景进行提取并结合PS(Photo Shop)技术实现自动替换纯色背景来实现数据增强,最后结合传统数据增强方法构造新数据集。数据增强示例见图1。
1.3 数据集设置经过基于突出前景的数据增强方法和传统数据增强的方法扩充数据后,将其与原图进行混合,构建了4 科1 种共5 类蜘蛛的数据集。如表1 所示,分为初始数据集,其每个种类图片数量为100 张左右,经过数据增强后将原始数据集扩充了大约10 倍左右。由于只能使用原图作为测试集,因此无法对测试集数量进行扩充,每类测试集图片数量在60 张左右。
2 研究方法
2.1 迁移学习迁移学习〔10〕的出现极大地提高了小样本学习的精度,缓解了数据量不足带来的过拟合问题,同时加速了神经网络的收敛。本文以大型数 据 集ImageNet 作 为 源 域〔11〕(Domain source,Ds),以目标任务的小型数据集作为目标域(Domain target,Dt)。ImageNet 中含有大量动物昆虫类数据以及蜘蛛数据,比较适合作为本研究的蜘蛛物种细粒度分类的源域。VGG-16 网络由Simonyan 等〔6〕于2015 年提出,表现优异,且VGG 适用于大多数物种分类任务。综上所述,本文针对小样本学习问题,将收集的络新妇(Nephilaclavata)、蟹蛛(Thomisidae)、鼠蛛(M.tussulena)、园蛛(Araneidae)和捕鸟蛛(Theraphosidae)等5 类蜘蛛样本数据集作为训练样本,使用VGG-16 作为目标模型进行迁移学习,具体流程见图2。

图2 基于共享参数的迁移学习
在迁移学习的范畴中有一种基于共享参数的迁移,其主要方法是预训练(pre-training)加微调(fine-tuning)〔11-12〕。神经网络提取特征的规律是浅层的神经网络提取图像的初级特征,如边缘、纹理、角点等;中层的网络提取颜色、形状等中级特征,如在人脸识别任务中提取人脸的眼睛、鼻子、嘴巴等特征;而深层的神经网络则提取高级特征,如空间位置、相对方向等,并将前面提取到的局部特征进行组合。对于蜘蛛数据集来说,模型在训练过程中提取特征的规律是先提取蜘蛛的边缘轮廓,然后提取蜘蛛身上的细节信息,随着网络层次的加深,所提取的特征越抽象,对应的特征矩阵也就越模糊,因此可利用大型数据集预训练模型底层参数迁移的方法来弥补小样本蜘蛛数据集训练过程中底层特征提取不充分问题。模型训练过程中提取蜘蛛图像特征的特征矩阵见图3。

图3 特征矩阵
本文以VGG-16 作为识别模型,将在ImageNet上预训练的VGG-16 模型去除3 个全连接层,只保留卷积层的参数作为初始参数。在使用蜘蛛数据集进行训练的过程中,冻结模型所有卷积层参数不参与训练,只训练后面全连接层参数。因为模型底层提取的是边缘轮廓等公共特征,使用在源域与目标域特征空间相似的大型数据集上预训练过的参数,可以解决因数据量不足造成的模型底层特征提取能力不足的问题,能将源模型的知识(参数)迁移到新模型上进行新的分类任务,从而增强模型的泛化能力。本文实验迁移学习预训练加微调的VGG-16结构见图4,模型的参数设置见表2。

表2 模型参数设置
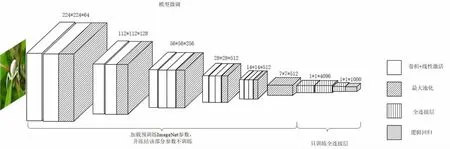
图4 微调VGG-16
2.2 评价指标采用以下指标衡量模型性能:
准确率:分类正确样本数与样本总数之比,如式(1)所示:

查准率:被模型正确识别的样本数与被检索到样本总数之比,如式(2)所示:

召回率:被正确识别的样本数与应当被检索到的样本数之比,如式(3)所示:
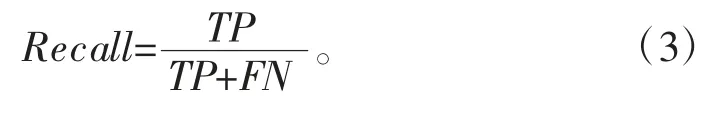
其中,TP 表示被模型识别为正样本的正样本数;FP 表示被模型识别为正样本的负样本数;FN 表示被模型识别为负样本的正样本数;TN 表示被模型识别为负样本的负样本数;ALL 为样本总数。
3 实验结果
3.1 实验环境本文蜘蛛智能识别平台,物种识别模块是其最核心的部分,通过迁移学习中预训练加微调的方法,训练VGG-16 模型,实现对不同种类蜘蛛的细粒度分类。实验硬件配置为:RTX2080Ti GPU×1、内存32 G×2、处理器Intel E5-2603×2。在Windows10 操作系统下使用Python 3.7 和Tensorflow 2.1 深度学习框架进行模型实现。
3.2 VGG-16 模型训练过程在模型训练之前首先要对数据进行重设尺寸(resize)、乱序(shuffle)及归一化处理〔13〕。resize 是重新定义图片尺寸以适应不同模型,此处将图片尺寸大小重设为VGG-16 模型的标准输入尺寸224×224;shuffle 是打乱训练图片数据防止模型抖动,增加模型泛化能力;传统的归一化是将图片像素[0,255]值控制到0~1 从而防止梯度爆炸或梯度消失。在使用预训练模型参数时要按照预训练模型的数据预处理方式对数据进行处理。此处因使用ImageNet 作预训练数据集,故对于目标域数据集也要按照源域的数据预处理方式,减去ImageNet 数据集的图像RGB 均值。
在进行数据预处理之后,将其输入模型中进行训练。设置Learning_rate(学习率)、Bach_size(1 次迭代使用的样本量)、Epoch(迭代次数)等超参数〔14〕。之后开始模型训练,VGG-16 模型由13 个卷积层以及3 个全连接层组成,在第一个模块由2 个堆叠的64 个卷积核对输入图像进行卷积操作,此时特征图的维度由3 维变为64 维,接着使用ReLU 函数对特征矩阵的权重x 进行激活,在x<0 时硬饱和,将权重置为0,x>0 时,导数为1,此时保持梯度不衰减,对应的特征矩阵权值不变,从而缓解梯度消失的问题,ReLU 激活函数如式(4)所示:

之后进行最大池化操作,此时图像尺寸被缩小为112×112。在第二个模块由2 个堆叠的112 个卷积核进行卷积、ReLU、池化,此时图像缩小为56×56,维度为128。重复上述过程,每次缩小图像尺寸大小并扩张特征矩阵的维度,最后经过全连接层,将局部特征组合为全局特征,通过Softmax 函数进行多分类并得到每个类的预测概率〔15〕,所有类别的概率相加起来约等于1。模型训练过程需要经过前向传播和反向传播。以nl表示第l 层网络节点(卷积核)数目,Kp,q作为第l 层p 通道与第l 层q 通道对应卷积核,bp表示第l 层p 节点(通道)的偏置,Wl表示第l 层全连接网络的权重,zl表示第l 层未经过激活函数的前向输入,al表示第l 层经过激活函数后的前向输出。u 和v 表示卷积操作的坐标位置。式(5)为第l 层卷积操作公式,第l 层最大池化公式见式(6):

模型的卷积和池化操作在提取图像特征的同时能不断对输入图像进行降维,在经过前13 层卷积和5 层池化操作以后,可将图像维度改变为(7×7×512),即图像的尺寸缩小为7×7,特征图的厚度增加到512 层,之后将其转化为一个25 088 维的向量作为全连接层的输入,在经过全连接层后的输出为式(7),前向传播的公式为式(8)、(9),输出层通过Softmax 函数激活为式(10)。在计算反向传播时引入中间变量δl作为第l 层的误差,第l 层前向传播zl的梯度可以表示为,采用式(11)、(12)计算梯度:

在添加了平均梯度信息后添加L2 正则化项〔16〕,设系数为γ,正则化是为了减少参数的数量,缩减参数的规模,以避免参数冗余导致模型复杂化从而造成对样本特征学习过好而对模型分类器造成负面影响带来的过拟合问题。如若使用n 阶多项式模型,则可能使得需要计算的参数过多且运算过于复杂,容易造成过拟合现象。过拟合〔17〕指模型在学习不同种类的细节特征时过于严格,以至于神经网络将部分样本中极具特点的局部特征作为所有样本数据都具有的一般性质,从而导致模型的识别和泛化能力下降。因此,为了防止过拟合,将其高阶部分的权重w 限制为0,相当于从高阶形式转换为低阶形式。L2 正则化主要是运用奥卡姆剃刀法则〔18〕,在损失函数后增加一个正则化项,以达到对不重要特征权值的衰减作用〔19〕,如式(13)所示:

在使用迁移学习中预训练加微调的方式进行训练时,首先从Tensorflow 官网下载VGG-16 对应的在ImageNet 上的预训练权重,之后对该权重全连接层参数进行去除,再加载到模型中,训练时冻结除全连接层之外的所有层,只训练全连接层。整个模型训练和识别流程见图5。

图5 VGG-16 模型训练流程
3.3 结果与讨论为研究迁移学习对识别精度的影响,本文设计了(A)迁移学习+数据增强、(B)仅数据增强两组实验进行对比分析。分别以上述两种方式进行训练,训练过程中准确率和损失函数的变化见图6~7,其中图6(a)为(A)组模型训练准确率折线图,图6(b)为(B)组模型训练准确率折线图,图7(a)为(A)组损失函数折线图,图7(b)为(B)组损失函数折线图。由图6~7 可知:迁移学习训练过程中,训练集和测试集的准确率曲线间相对夹角及损失函数曲线相对夹角几乎为零,表明迁移学习中预训练加微调的方法缓解了小样本学习通常存在的过拟合问题。同时模型中加入的L2 正则化Dropout(随机丢弃),以及对原始数据集进行的数据增强,都对防止过拟合起到了一定的作用。而(B)组实验,训练集和测试集的准确率曲线间相对夹角及损失函数曲线间相对夹角较大,属于明显的过拟合现象。在收敛速度方面,在数据集相同的情况下,(A)组实验仅需训练30 个Epoch 便可收敛,而(B)组至少需要70 个Epoch 才能达到收敛状态,且预训练加微调的方法能较大程度提高模型的训练速度。在模型精度方面,(B)组测试集准确率只有79.69%,相比之下,(A)组能在测试集上达到95.31%的准确率,比前者高出15.62%。
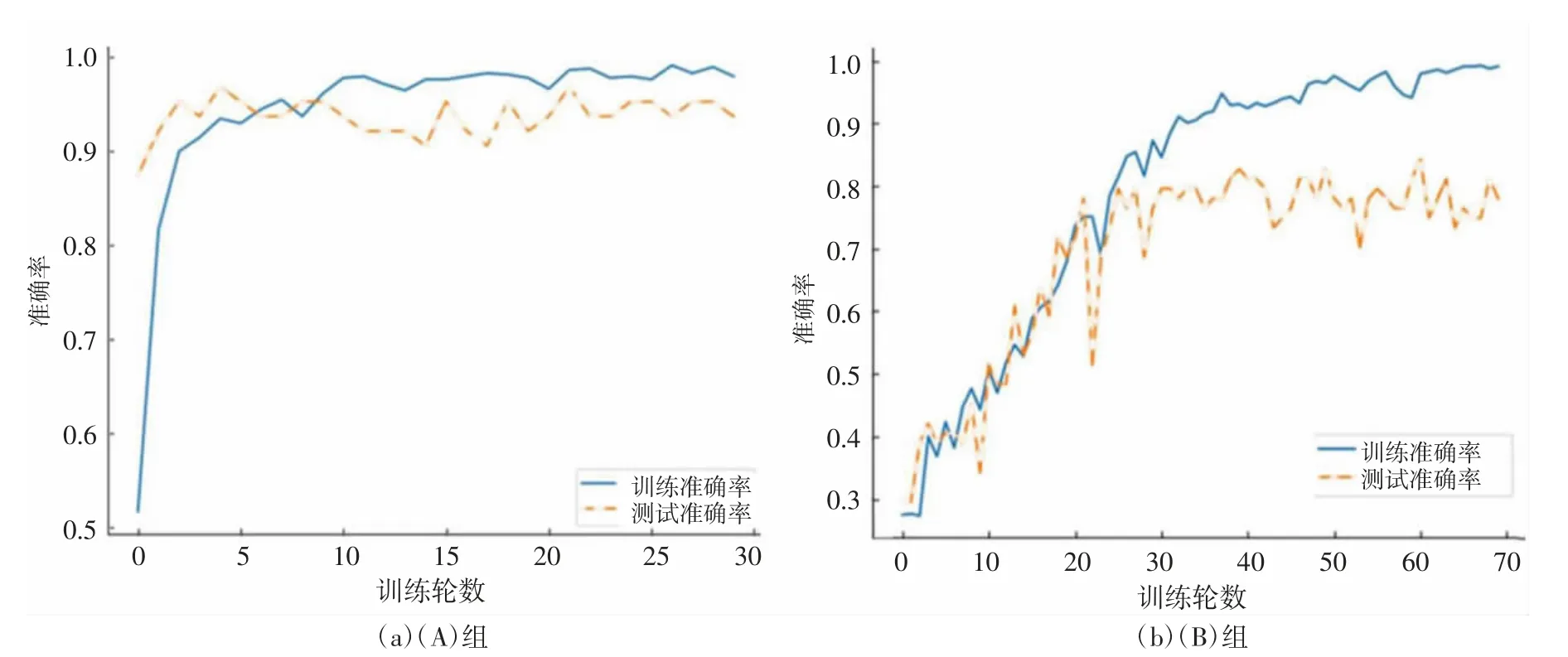
图6 准确率折线图

图7 损失函数折线图
为测试该识别平台的泛化性能和识别准确率,设置园蛛、蟹蛛、鼠蛛、捕鸟蛛、络新妇等5 个经模型训练过的类别作为测试数据集,分别使用模型进行测试,得到测试结果见表3,其中A 表示基于迁移学习和数据增强的测试结果,B 表示只有数据增强的测试结果。

表3 模型测试结果
测试结果表明使用迁移学习与基于突出前景的数据增强方法进行训练时,平均识别准确率可达到95%以上,模型具有良好的鲁棒性,且较只使用数据增强方法有明显提升。可以看出,源域ImageNet 很好地适配了目标域的蜘蛛数据集,微调预训练模型参数对蜘蛛物种识别任务提供了很大的帮助。且使用迁移学习的方法训练,模型站在了更高的起点,在测试集上的初始准确率就能达到80%以上。
在小样本情况下,传统数据增强方法虽可大幅度提高训练数据量,但生成的图像与原图像之间差距过小,对模型性能的提升具有一定局限。本文提出基于突出前景的数据增强技术,通过提取蜘蛛前景并替换纯色背景,在增大生成图像与原图像差距的同时,保留最重要的蜘蛛主体图像特征信息,使特征提取更有层次性和判别性,模型更容易学习到图片前景的特征。将突出前景的数据增强技术与迁移学习方法结合使用,可以互相弥补各自的不足,达到相互促进的效果,从而更好地解决小样本蜘蛛细粒度识别问题。
4 系统平台设计
4.1 系统框架结构设计蜘蛛智能识别平台由3个子系统构成:安卓手机端识别系统(简称“蜘识”)、微信手机端识别系统、后台管理系统。其中,安卓和微信端统称为移动端子系统。蜘蛛智能识别平台总体流程见图8。

图8 系统总体流程
4.2 系统业务流程设计在通过神经网络进行蜘蛛物种智能识别同时,系统集成了对上传识别的图片进行分类管理的功能。不同权限的用户有着不同的功能。管理员主要功能有用户权限分配、识别任务管理、照片管理、酬劳发放。管理员可对所有用户采集上传的图像,按批次分配给专家进行人工鉴定,从而不断迭代完善样本数据集、增加物种识别种类、增强系统功能,这是系统的核心功能之一。若采集的图片模糊或达不到标准,管理员可以剔除这些照片;管理员同时负责对专家和普通用户鉴定所得酬劳的发放:在数据库中根据不同用户的鉴定级别设计标准薪酬、浮动比例等字段。专家用户主要功能有物种人工识别:通过管理员用户的任务分配,鉴别蜘蛛物种(目科属种),鉴定完成后打上标签,且专家也可对所有照片进行管理;普通用户主要有拍照上传识别、个人采集图片管理、辅助鉴定的功能。系统角色任务流程见图9。
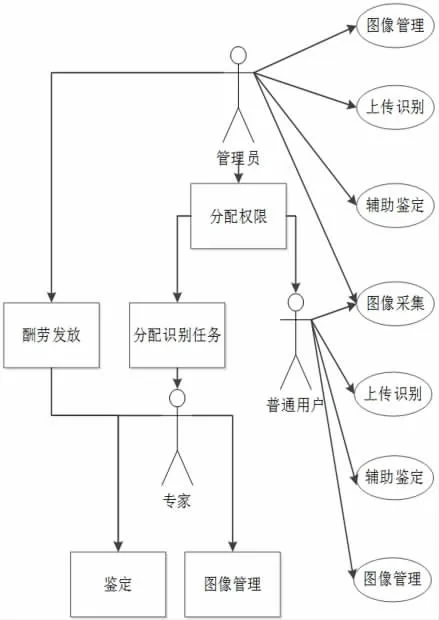
图9 系统角色任务流程图
4.3 数据库设计使用Mysql作为后台数据库,本系统设计了用户信息、图像信息等数据表,分别应用于用户安全信息的管理、上传图片的生态环境信息管理以及社交的点赞信息管理。用户信息表记录了用户的用户名、密码、角色、绑定微信号、手机号、邮箱、头像信息、标准薪酬、浮动比例、用户薪酬等信息。图像信息表记录了图片临时编码、用户名、物种编码、图片状态、图片路径、图片ID、经度、纬度、海拔、采集日期等信息。用户信息和图像信息示例见表4~5。

表4 用户信息示例

表5 图像信息示例
系统设计了蜘蛛物种目录树,采用层次编码法,将编码分为目、亚目、下目、总科、科、亚科、属、种、亚种,每一层的蜘蛛编码由两位阿拉伯数字组成,对于缺失的层,用数字00 表示,如鼠蛛的编码结果为:010300000003010100。编码结构图见图10,数据库蜘蛛编码规则示例见表6。

图10 鼠蛛编码示意图
4.4 子系统设计
4.4.1 安卓端识别子系统 安卓端的蜘蛛识别程序开发工具为Android Studio。主要由登录注册模块、拍照识别模块、选取相册照片识别模块、设置传输压缩率模块、更新说明模块、官方网站模块、点赞和分享等模块组成。
进入主页面后显示各种蜘蛛的图片和介绍,可以点赞分享到朋友圈、QQ 等社交平台。在识别界面可以选择拍照识别或者选取相册中的图片进行识别,拍照后会获取经纬度等生态环境信息,并将这些信息一起传回到服务器端,系统使用Socket 模块来进行客户端与服务器端的交互,拍摄的照片以字节流的方式传入到服务器端时,会调用后台的核心识别模块进行识别并反馈识别结果,然后将结果传回到客户端,客户端根据返回的字符串结果来判断并展示相对应的蜘蛛种类及相关介绍以及置信度,目前可识别蟹蛛、园蛛、捕鸟蛛、络新妇4 类蜘蛛科及鼠蛛1 类蜘蛛种。如果选择从相册中选取图片上传识别,则无法获取经纬度信息并会给出提示,但同样可以成功识别。为了降低用户野外采集图像时的流量消耗、节约成本,系统设置了传输压缩率设置功能。该模块可以设置图片压缩率,其范围在0~100,数值越低则图片压缩的程度越高,而上传速度越快,但不可避免地会损失一些清晰度,用户可根据实际情况进行取舍。更新说明模块记录APP 每次更新迭代的内容,在官方网站模块可进入到蜘识的官方页面〔20〕进行版本更新或者下载。系统实现流程见图11,系统识别界面见图12。

图11 安卓端系统实现流程

图12 安卓端识别界面
4.4.2 微信端识别子系统 微信端开发语言为WXSS(Weixin Style Sheets),使用微信开发者工具开发。微信端识别子系统包含拍照识别、选取相册照片识别、获取用户当前位置、获取天气、蜘蛛百科等模块。在拍照识别和选择相册模块,可以拍摄照片或直接从相册选择照片,然后通过微信端的uploadfile()方法将图片上传到JAVA 后台端,JAVA后台调用upload()方法获取图片并将图片传到识别端,由核心识别模块进行识别,再将识别后反馈的结果传入到JAVA 后台,JAVA 后台再通过post.addHeader()方法将识别结果传回到微信端,然后微信端再调用数据库中的蜘蛛百科选择渲染结果并展示。系统实现流程见图13,系统识别界面见图14。

图13 微信端系统实现流程

图14 微信端识别界面
4.4.3 后台管理系统 后台管理系统采用Spring Boot 框架,包括用户信息管理和图片信息管理两大模块,分管理员、普通用户、专家3 种角色。该模块主要是对移动端拍照上传的蜘蛛图像信息进行一个分类管理,从而不断收集新的蜘蛛图像来扩充蜘蛛数据集。系统实现流程见图15。

图15 后台管理系统实现流程
4.5 系统测试系统的测试方法有单元测试、集成测试、黑盒测试、白盒测试等。使用移动端APP 进行拍照上传服务器对5 类蜘蛛进行识别测试,验证该APP 在实际应用中的表现以及结果反馈的反应时间,测试结果见表7。由测试结果可知在对每类蜘蛛进行的250 次测试中,识别的平均准确率能达到95%以上,且反应时间均在1.6 s 左右。

表7 系统测试结果
5 结语
针对蜘蛛物种细粒度分类问题,本文基于迁移学习方法,以VGG-16 作为实验模型在蜘蛛数据集上进行训练,研建了蜘蛛识别平台。结果表明,该识别平台对4 科1 种共5 类蜘蛛的平均识别准确率达到95%以上。用户可通过移动设备拍照上传蜘蛛图像进行识别并得到结果反馈,同时获取该蜘蛛的百科信息。
本研究所达到的识别准确率及识别种类还有较大的提升空间。在接下来的研究中,我们将采用其他数据增强技术,如生成对抗网络等增强样本数据集,尝试应用EfficientNet、Vision Transformer 等其他更先进的模型进行训练,并通过系统用户采集、野外拍摄等方式不断收集数据,扩增识别种类,不断迭代完善识别系统。
