内容分发网络与机器学习融合关键技术综述
2022-07-07许力澜王瑞琨
吕 慧,许力澜,王瑞琨,禹 忠
(1.中国铁塔股份有限公司 陕西省分公司,陕西 西安 710065;2.西安邮电大学 通信与信息工程学院,陕西 西安 710121)
流媒体应用已经成为数字化社会的常态,内容分发在流媒体应用,即高清媒体流媒体、大型音频、图像、视频文件和数据集共享所提供的服务中起着至关重要的作用。为了提高流媒体的网络性能和服务质量,研究者们一直致力于对内容分发网络(Content Delivery Networks,CDN)的研究。CDN可以将流媒体的选择性内容复制到离客户端较近或者服务质量比较好的副本服务器上,并允许用户从副本服务器上获取内容,此概念类似于边缘计算[1]。在边缘计算中,数据或资源被放置在边缘,更接近用户,并减轻了云计算的负担。为全方位优化CDN网络,研究者们开展了大量的研究工作,如全局服务器负载均衡、基于域名系统(Domain Nane System,DNS)的请求路由系统、IP层重定向请求路由系统、应用层协议重定向请求路由系统等。系统提供当前网络访问CDN日志数据,并提供网络设计或资源调度策略,从而提高CDN的内容分发质量。
利用机器学习技术提高内容分发网络的服务质量成为内容分发中的关键技术,并得到国内外研究者的广泛关注。通过对这些方法和成果进行深入研究,特别是对相关技术的当前应用情况和发展趋势进行探讨,从而进一步提高内容分发网络的资源管理、实时分配和质量规划。
1 内容分发网络
目前,CDN常见的解决方案是通过在现有的网络中增加一层新的网络架构,将网站的内容发布到最接近用户的网络“边缘”,使用户可以就近取得所需的内容,解决网络拥塞状况,提高用户访问网站的响应速度。从技术上全面解决由于网络带宽小、用户访问量大、网点分布不均等原因,改善用户访问网站的响应速度慢的根本原因。具体的内容分发网络架构如图1所示。
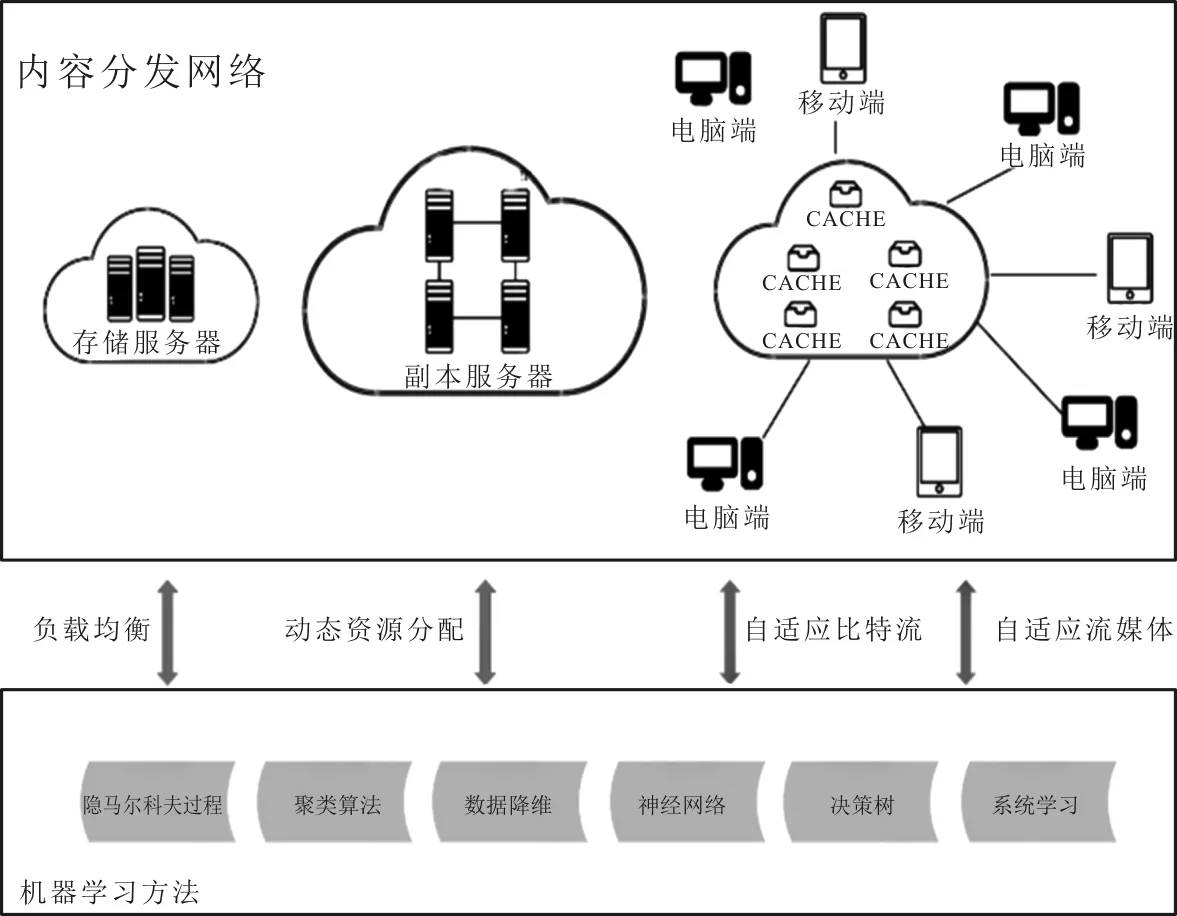
图1 内容分发网络架构
CDN是一种新型的网络构建方式,是为传统的IP网发布宽带流媒体而特别优化的网络覆盖层。从广义的角度看,CDN代表了一种基于质量与秩序的网络服务模式。同时,CDN又是一个经策略性部署的整体系统,包括分布式存储、负载均衡、网络请求的重定向和内容管理等4个要件,而内容管理和全局的网络流量管理(Traffic Management,TM)是CDN的核心所在。通过针对用户就近性和服务器负载进行判断,CDN确保内容以一种极为高效的方式为用户的请求提供服务。总的来说,内容服务基于缓存服务器,也称作代理缓存(Surrogate),其位于网络的边缘,距用户仅有“一跳”之遥。同时,代理缓存是内容提供商源服务器,即通常位于CDN服务提供商的数据中心的一个透明镜像。这样的架构不仅可以使CDN服务提供商能帮助客户如内容供应商向最终用户提供尽可能好的体验,还可以使最终用户不必容忍请求响应的延迟时间。据统计,采用CDN技术能处理整个网站页面的70%~95%的内容访问量,减轻了服务器压力,能够提升网站的性能和可扩展性。
随着技术的进步,CDN的复杂性、多样性增加,用户的期望以及需求也在不断提升。当CDN的使用场景规模变得更大、更具有动态性和异构性时,快速增长的用户群需要更高的网络吞吐量。同时,不断变化的用户期望和需求也意味着需要更短的传输延迟才不会影响内容分发的质量。此外,还需要更切实际地考虑满足不同的市场细分,尤其在部署云和雾边缘应用程序时,将会面临更复杂的问题。
近年来,已经有许多研究者正在探索解决方案,如数据驱动和基于机器学习(Machine Learning,ML)的方法,这些方法在许多研究领域取得了巨大的成功[2]。基于实时的网络状态,如负载变化模式和吞吐量特征,ML的分类、预测能力可以潜在地改善CDN中的网络调度和参数自适应能力。但是,基于ML的方法需要对数据集进行培训,包括CDN中的操作日志、网络和服务监控。
2 基于机器学习的内容分发网络架构
在使用机器学习技术实现内容分发的性能提升方面已经取得了很大的进展,但在现有基于ML的技术中,很少有系统的文献改进CDN中的内容分发性能。因此,对此背景下跟ML相关的未解决问题、关键技术以及未来潜在的发展趋势等问题进行了讨论。
一般来说,现有的机器学习算法可以分为监督学习(Supervised Learning,SL)、无监督学习(Unsupervised Learning,UL )和强化学习(Reinforcement Learning,RL)等3类算法:SL算法通常用于标记数据的分类、回归任务;UL算法可以将样本集分为不同的未标记数据簇;RL算法通常通过与环境的交互确定最优动作序列。在ML和互联网的集成方面,机器学习已经使用在网络设计、调度、部署和管理中。因此,ML在提升内容分发的性能方面的问题成为重点的研究内容。
图2展示了基于数据驱动的机器学习方法的一般框架,该框架可以增强内容分发服务的性能。在CDN中提高内容交付质量的研究可以分为在客户端优化内容分发服务的选择即内容交付阶段和在服务器端优化内容分发网络的资源调度即缓存放置阶段两类。具体而言,在客户端,每个客户端在访问日志数据时:应用机器学习技术选择服务并优化体验质量(Quality of Experience,QoE),如自适应比特率选择和自适应流;在服务器端,主要关注CDN资源调度的优化,如负载均衡、动态资源分配等。在此基础之上,使用基于ML的解决方案可以达到更好的资源调度效果。
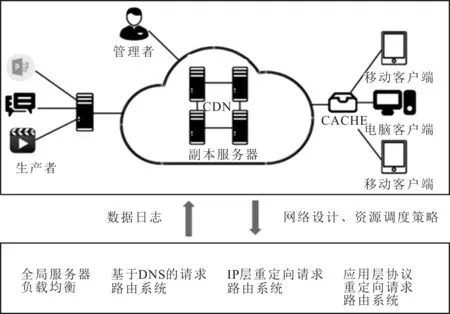
图2 基于机器学习的内容分发网络架构
3 面向客户端QoE的CDN优化
为了提高QoE,可以尝试采用基于预测的方法,如以用户最近活动中观察到的用户QoE特性为依据。换句话说,有效的QoE预测模型通常与可观察到的行为有关。文献[3]提出了一种数据驱动的方法,通过决策树模型建立视频流媒体用户参与度的预测模型,指导关键性能指标的优化策略,最终有效地改善了视频流媒体用户的QoE。
基于预测的CDN优化方法存在两种基础性的难题:一是由于复杂的关系,预测模型可能无法识别视频质量和观察到的会话特征之间的相关联系;另一个是当内容被传递给移动用户时的实时服务需求。为了改善这两个问题,文献[4]中提出了一种客户端预测方法,即交叉验证模型(Confirmatory Factor Analysis,CFA),CFA采用关键特征学习算法,基于学习到的关键特征进行质量估计,但CFA无法应对突然的变化或全局控制。
基于预测的方法也存在许多已知的偏差,为了解决该问题,研究者们已经提出了许多方法。例如,文献[5]中提出了一种在RL中进行探索和开发(Exploration and Exploitation,E2)的方法。这种方法称为Pytheas,旨在使每个客户机能够同时确定和检查服务器,将视频质量的实时优化问题转化为实时多臂老虎机(Multi-Armed Bandits,MAB)问题,即一种基础的强化学习方法,并使用了上限置信区间算法(Upper Confidence Bound,UCB)。具体来说,Pytheas将具有相同关键特性的视频会话分成组,E2算法在组粒度上执行,以确定会话特征并提高QoE,Pytheas平均提高了31%的视频质量(Video Quality of Experience,VQoE)。
同时,类似于Pytheas,提出了三层结构CDN(C3)[6],即另一种控制平面设计,C3包括建模层、决策层和传感驱动层3层。建模层使用数据驱动的方法预测新进入会话的质量,同时考虑当前会话的相似性。决策层应用全局模型做出实时决策,即亚秒级时间尺度。传感驱动层负责质量测量和控制决策执行。C3的设计解决了确保可伸缩性和处理数据平面异构性方面的关键问题。为了确保可伸缩性和响应性,C3引入了一种新的分离控制平面体系结构,容忍模型陈旧程度的小幅增加可使网络的伸缩性显著增加。C3通过最小的客户端传感/驱动层支持多种客户端平台,并将复杂的监控和控制逻辑卸载到控制平面。这种方法提供了可扩展性,减少了带宽开销并提高了客户的视频质量,但其不支持实时决策。
在CDN中两个关键技术指标对ML的质量非常重要,即自适应比特率(Adaptive Bit Rate,ABR)选择和通过超文本传输协议(Hypertext Transfer Prtcl,HTTP)的自适应流。
比特率的选择和自适应是提高视频流质量进而提高CDN业务质量的重要方案。ABR是确保网络视频良好体验质量的关键,例如,跨会话状态预测(Cross-Session Stateful Prediction,CS2P)系统[7],一个吞吐量预测系统,其使用数据驱动的方法学习相似会话的集群、初始吞吐量预测器和隐马可夫过程基于中游预测器的吞吐量状态演化模型,并在客户端选择和调整视频比特率。CS2P系统可识别类似的视频会话并对吞吐量进行初始预测。同时,对吞吐量状态演化进行建模,以隐马尔可夫过程跟踪吞吐量的动态变化。CS2P系统的初始吞吐量和中游演化模型可以被插入到比特率选择和自适应算法中,这些算法可以运行在视频播放器或内容分发服务器上。设计有效的ABR算法所面临的困难包括波动的网络条件和冲突的质量目标,如比特率、重缓冲时间和视频质量平滑等。文献[8]提出了Pensieve系统在客户端使用深度RL创建ABR,可以不依赖预先编程的模型,而是根据对过去决策的观察学习,从而做出适应性决策。文献[9]提出了一个基于网络环境特征的质量满意度模型,设计了一种神经网络学习算法预测QoE的接入链路、位置、CDN和网络运营商的特征。
HTTP自适应流(HTTP Adaptive Streaming,HAS)是顶级视频流的标准。一般来说,一个HAS视频由不同质量等级和不同比特率编码的多个片段组成,其允许客户端为每个视频片段选择不同的编码速率。传统的HAS比特率选择大多采用固定参数模型,这可能导致次优解。许多商业HAS应用程序使用较大缓冲区避免回放卡顿,然而,由于直播需要更小的缓冲区,这种类型的解决方案不能充分满足直播要求。在文献[10-11]中,使用Q-Learning技术的优化能力解决了这个限制。例如,在文献[10]中提出的Q-Learning技术使一个HAS客户端可以动态地学习网络环境中的最佳行为,这种方法在性能和收敛速度方面满足了客户端的要求。文献[11]中提出的算法是利用RL实现客户端视频速率的自适应变化,并调整自适应参数主动减少缓冲区的平均填充。与以前的解决方案相比,使用该方案的客户端达到了更低的缓冲区平均填充和更高的QoE水平。
4 面向服务器端QoS的CDN优化
为了优化服务器端的QoS,可采用数据驱动的方法。文献[12]通过CDN运营大数据分析,提出了一种支持多云架构的资源分配与调度优化策略。首先,在Spark上分析CDN运行日志数据的数量,评估终端用户与多云CDN运营商之间的QoS。然后,执行一个长期资源部署算法,预定最小的资源,以满足用户的要求,最终实现更高的QoS和更低的成本。在Spark上进行QoS计算的过程如图3所示。
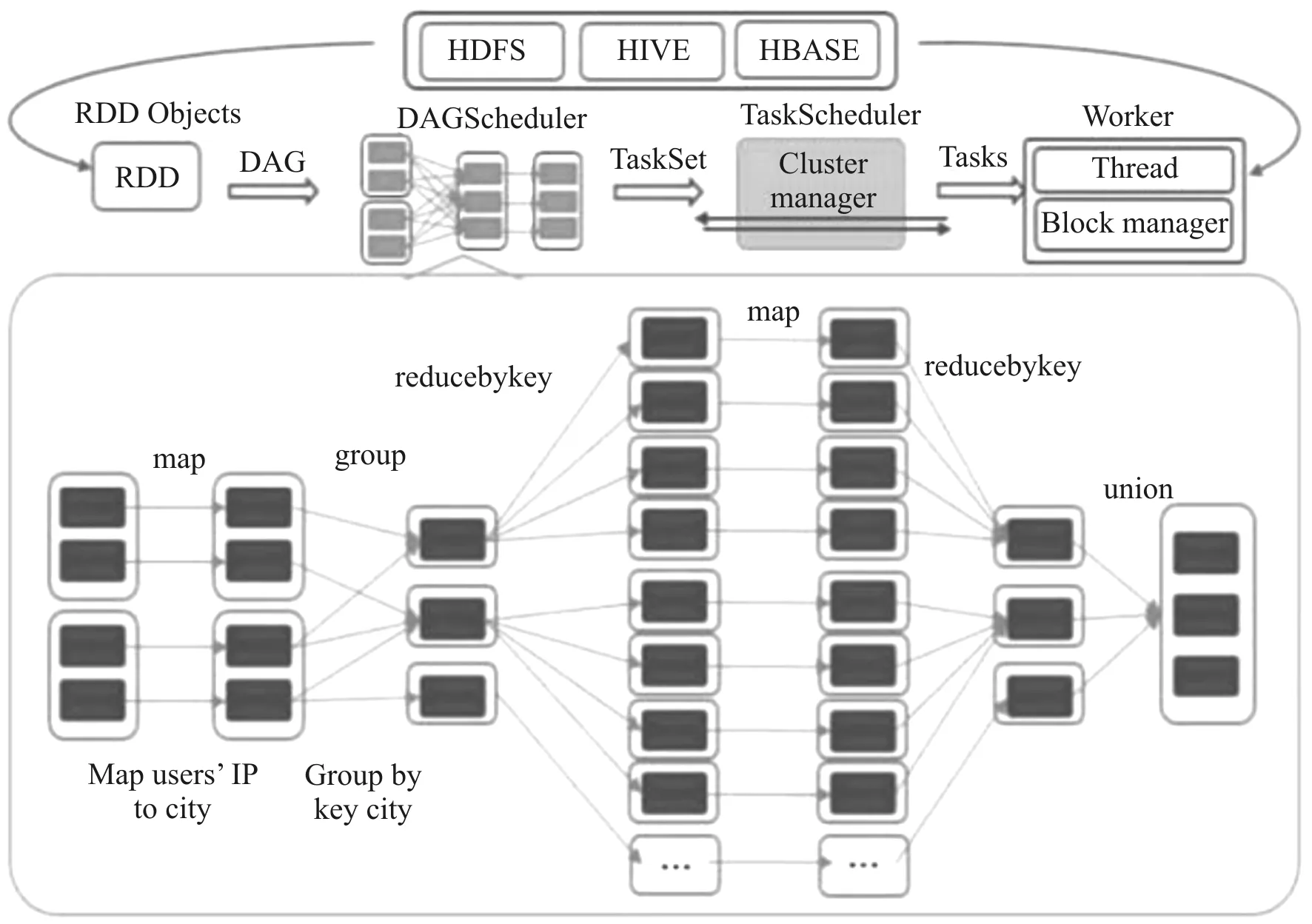
图3 在Spark上进行QoS计算的过程
在文献[13]中,提出了一种数据驱动的方法建立一个实用CDN缓存服务器组,即CDN的服务器节点性能评估模型,还在深度学习中使用LSTM自动编码器捕获时间结构。
缓存是增强内容传递性能的另一种重要机制。缓存模式可以大致分为响应式模式和静态缓存模式。在响应式缓存模式中,单个缓存完全根据最近本地观察到的对象访问模式决定缓存哪些对象。在静态缓存模式中,集中控制器根据用户需求的全局视图和对象访问模式决定要缓存哪些对象。例如,文献[13]从内容提供者的角度提出了一个智能内容缓存框架DeepCache。DeepCache在决定缓存哪些内容对象之前,利用LSTM编码器-解码器模型对内容流行度进行准确预测。因此,DeepCache框架可以显著增加CDN中缓存命中的次数,提高内容传递的QoS。
为提升QoS,云内容交付网络(Cloud Content Delivery Networks,CCDNs)也是一个极好的办法,其允许资源租赁如存储和带宽在云中构建CDN,能够增强可伸缩性、灵活性和弹性,并降低内容存储和交付的成本。传统的CCDNs网络架构由用户、源服务器和云代理服务器组成,如图4所示。文献[14]提出了一种基于Q-Learning的动态CCDNs内容布局模型,称为Q-内容布局模型(Q-Content Placement Model,Q-CPM)。首先,通过最新和更可靠的拥塞值进行判断,Q-Learning方法可以做出更好的路由决策。然后,在Q-CPM模型的基础上,提出了一种构建Q-自适应交付树(Q-Adaptive Delivery Tree,Q-ADT)的算法,通过网络学习包传播本地和非本地拥塞信息,可以选择拥塞代价低且能适应动态云传输的路径。

图4 传统CCDNs架构
采用基于ML优化CDN调度方法可分为面向客户端QoE和面向服务器端QoS两种方法。通过观察可以发现,基于预测的ML方法大多应用于客户端。因此,在服务器端,需要一个全局视图实现负载平衡和动态资源分配。
5 面临的主要问题
在基于ML的CDN中,面临着以下4个主要的问题。
1)客户端的实时服务器选择。流媒体的特殊性多、数据量大,对抖动和时延极其敏感,在广域网上传输要有一定的QoS保证。而且服务器的负载轻重与否,并不代表从客户端到服务器端的网络状态的好坏。如果服务器处于轻负载状况,还可以支持更多的用户,但客户端到服务器端的网络状态却很差。因此,在分布式流媒体的服务器选择策略中,必须考虑客户端到服务器端的真实网络环境。
2)CDN服务器资源管理。CDN的性能策略在最小化延迟和最大化缓存命中率之间的权衡,具有多个存在点(Point of Presence,PoP)的CDN可以提供更低的延迟,但由于流量被分配到更多缓存,可能会遇到更低的缓存命中率。最小化延迟和最大化缓存命中率之间的权衡是一个范围。因此,在这个范围之内寻求一个平衡点合理配置CDN服务器资源,就成为一个技术难点。
3)CDN服务器端规划。由于每个服务器上都有相同的动态资源,这就需要配置相应的数据库。因此,易导致核心节点间数据同步等问题,即便做到集群式服务器规划,依旧解决不了成本高的难点。
4)CDN服务器端QoS评估。用ML优化CDN能够降低网络中的网络延时、丢包率和回源率数值,缓存命中率也得到相应提高。但是,由于业务场景和业务类型不同,即使选择了相同配置的CDN与ML融合技术服务,评估分配和规划后的CDN的QoS优化效果也不相同。因此,利用规划的响应指导未来的优化、改进是一大难点。
6 关键技术
6.1 从高维到低维特征提取
通常情况下,数据降维是提高预测准确性和可识别性的一种选择。利用现有的性能评价数据进行业务质量分析,并建立整个网络系统的评价模型,是实现CDN的QoS动态评价的基础[15]。
在性能评估中包括基于机器的数据和基于网络的数据两种典型的数据类型,都是高维数据。原始数据中的每个特征都代表一定的含义,每个特征值范围都是不同的。那么,将所有原始数据输入到模型中可能会导致计算成本提高、收敛速度降低和由于冗余参数使模型复杂性增加。事实上,很多特性对CDN的QoS影响很小,这意味着使用冗余特性可能会对服务质量的表示产生负面影响。因此,从原始数据中选择真正相关的特性是提高CDN业务质量的关键。
6.2 基于缓存的多服务器特性收敛
CDN服务提供商通常以缓存组为单位提供客户端服务和资源管理,这意味着CDN的QoS的动态评估需要在缓存组中进行评估[16]。相同缓存组中的服务器是同构的,由一台或多台服务器组成,用负载平衡设备连接这些服务器。在实践中,整个网络的性能一般都属于单个服务器,数据仅代表单个服务器的QoS。因此,需要通过汇聚缓存组的特性并收集多个服务器的数据确定缓存组的特性和服务质量之间的关系。
7 发展趋势
CDN可以通过实施数据驱动的ML方法改进,以实现优化的资源管理、实时分配和质量规划。一个功能完备的CDN能够在资源使用效率和成本节约方面对QoE和QoS的性能进行提升。其中一个研究热点是设计基于深度学习的CDN网络QoS评估模型和算法,重点研究基于有限样本的数据驱动的CDN业务分配和基于ML的CDN大数据驱动的网络规划。
7.1 基于深度学习的CDN的QoS评估
CDN的QoS评价模型的目标是找出机器性能测量或网络性能数据与用户体验之间的关系。使用CDN的一个目的是防止性能受限,以促进更有效和更稳定的数据传输[17]。然而,如何将整个网络的性能数据用于QoS分析以支持策略制定仍然是一个难题。从本质上讲,模型的建立需要整个网络的性能数据,包括机器和网络相关的集合,与机器相关的数据包括CPU、内存和IOWAIT数据。网络数据包含测试的下载数据(来自整个HTTP网络)、测试频率(如每小时)、测试包大小(如2 M)和数据量(如每天203行,404 MB)。响应测试数据包括测试频率(如每10 min一次)、测试包大小(如8 B)、数据量(如每天1 033行,2.1 GB)。
目前的建模方法大致可以分为基于规则的方法和数据驱动的方法。典型的基于规则的方法使用数学表达式表示已知变量和未知变量之间的关系,该方法的优点是可解释性强。然而,该方法的缺点是很难解释复杂的关系,当采用基于规则的建模方法时,通常无法获得在线更新。
在数据驱动方法中,模型可以被视为一个“黑盒子”,其中历史数据用来揭示变量之间的关系,并预测新的输入变量。大多数数据驱动的方法都适用于实时更新,尽管这些方法大多缺乏可感知性。在数据驱动框架中,已经实现了深度学习机制构建CDN服务质量评估模型,例如,运行基于多层神经网络的监督训练[18]。由于CDN上的业务可以看作是一致的时间序列,因此可以实现对业务质量的预测。在某种程度上,从整个网络收集的实时数据是一个高质量的训练集,其输出有望具有足够指导资源分配的能力。
7.2 基于ML的CDN长期资源规划
在CDN业务平台建设和扩展过程中,一个可采用的规划策略能够满足用户需求和成本效益是研究的一个关键性问题。在这种情况下,通常不需要实时交付,那么离线大数据分析解决方案是一个选择。其中,可选择建立一个工作负荷利用模型解释终端用户的质量和CDN的成本之间的关系。而另一个解决方案是挖掘大量收集的样本,以识别访问特征、资源需求和使用属性。从现实部署的角度出发,该方案需要考虑接入模型、应用条件和QoS保障等实际特性,以达到全局优化和多数据中心CDN的长期规划。
8 结 语
以内容分发网络在流媒体中真实需求为切入点,深入分析ML在CDN的设计、调度、部署和管理部分发挥的性能。以客户端体验质量和服务端服务质量为评估准则,分别剖析了不同的ML工具在CDN优化过程中的技术手段,总结多种基于预测的方法提高QoE、多种数据驱动的方法优化QoS,展示了CDN在提供流媒体服务中使用ML的发展潜力。
在基于ML的CDN已经取得的进展和成果之后,进一步挖掘该领域所面临的关键技术问题和主要难点。将难点划分为高维到低维特征提取、基于缓存的多服务器特性收敛两个技术层面,分别刻画出CDN与ML融合技术应具备关键技术。以此为基础,对在QoS评估下的ML改进的CDN的发展趋势从评估到资源规划方面进行展望。
