基于改进分布式算法的FIR滤波器设计
2022-07-07李俊俊
王 健 冉 全 李俊俊
(武汉工程大学计算机科学与工程学院 湖北 武汉 430205)
0 引 言
FIR滤波器由于具有线性相位和设计灵活的特点,被广泛应用于移动通信、语音识别和医疗仪器等领域。随着集成电路的不断发展,越来越多的FIR滤波器选用现场可编程逻辑阵列(FPGA)作为核心器件。
传统算法实现高阶FIR滤波器要进行大量的乘累加操作,会综合出较多的乘法器与加法器,这些运算单元会消耗较多的逻辑资源[1]。为了降低FPGA的资源消耗,Croisier等[2]首先引入了分布式算法(DA),它是一种将部分乘累加结果预先存储在查找表(LUT)来代替乘法器结构的算法。Peled等[3]DA获得了进一步的发展,Yiu[4]通过对符号数的研究使DA的适用范围更广,Kammeyer[5]和Taylor[6]研究了在系统中DA的量化能力。Partrick等[7]在DA的结构上进行了分析,串行结构DA占用较少资源,但处理速度较慢,很难达到滤波器高速实时性的要求,并行结构DA具有高速处理信息的能力,但会消耗更多的资源[8-9]。FPGA中查找表规模大小会随着滤波器阶数大小呈指数增长,查找表规模增大也会增大滤波延时,这是不可避免的,在高阶滤波器中怎样减小LUT规模成为分布式算法的主要难题。为此提出一种新的改进型分布式算法,能实现任意阶数的滤波器,并能有效减小查找表的规模,使系统占用更少的硬件资源。
1 分布式算法
1.1 分布式算法原理与结构
分布式算法的主要目的是简化乘法运算[10]。它与传统滤波器卷积相乘的不同在于将乘法运算进行了分解转化,该算法将乘法运算分解为若干加法运算和移位操作。具体来说,分布式算法将各输入数据的二进制格式的每一位与滤波系数相乘,会产生两种已知部分积,然后根据每位二进制数的权重对部分积进行移位操作,累加移位后的部分积就可得到最终结果。与直接相乘相比,FPGA通过分布式算法综合出来的电路中没有使用任何的乘法器,大大降低了资源占用,运算速度也得到了提高。
一个N抽头的FIR滤波器线性卷积方程如下:

(1)
式中:h(n)表示滤波系数为已知常量;x(n)为输入数据。x(n)的二进制补码形式为:
(2)
式中:xb(n)为x(n)的第b位。将式(2)代入式(1)可得:
(3)
由于x(n)为有限位数据,且每位二进制数的取值只有0、1两种,故x(n)有2N种不同的取值,又因为滤波系数h(n)已知,所以可以通过查找表来实现∑h(n)xb(n),该查找表的规模大小取决于N值。再通过不同的移位操作后进行累加,最终得到卷积相乘的结果y。分布式算法结构如图1所示,该结构由移位寄存器、查找表和移位累加模块组成,当地址向量的最高符号位为B时,发生了溢出,此时ctrl信号为高电平,累加器的值经过移位操作后与查找表输出的值做相减运算。
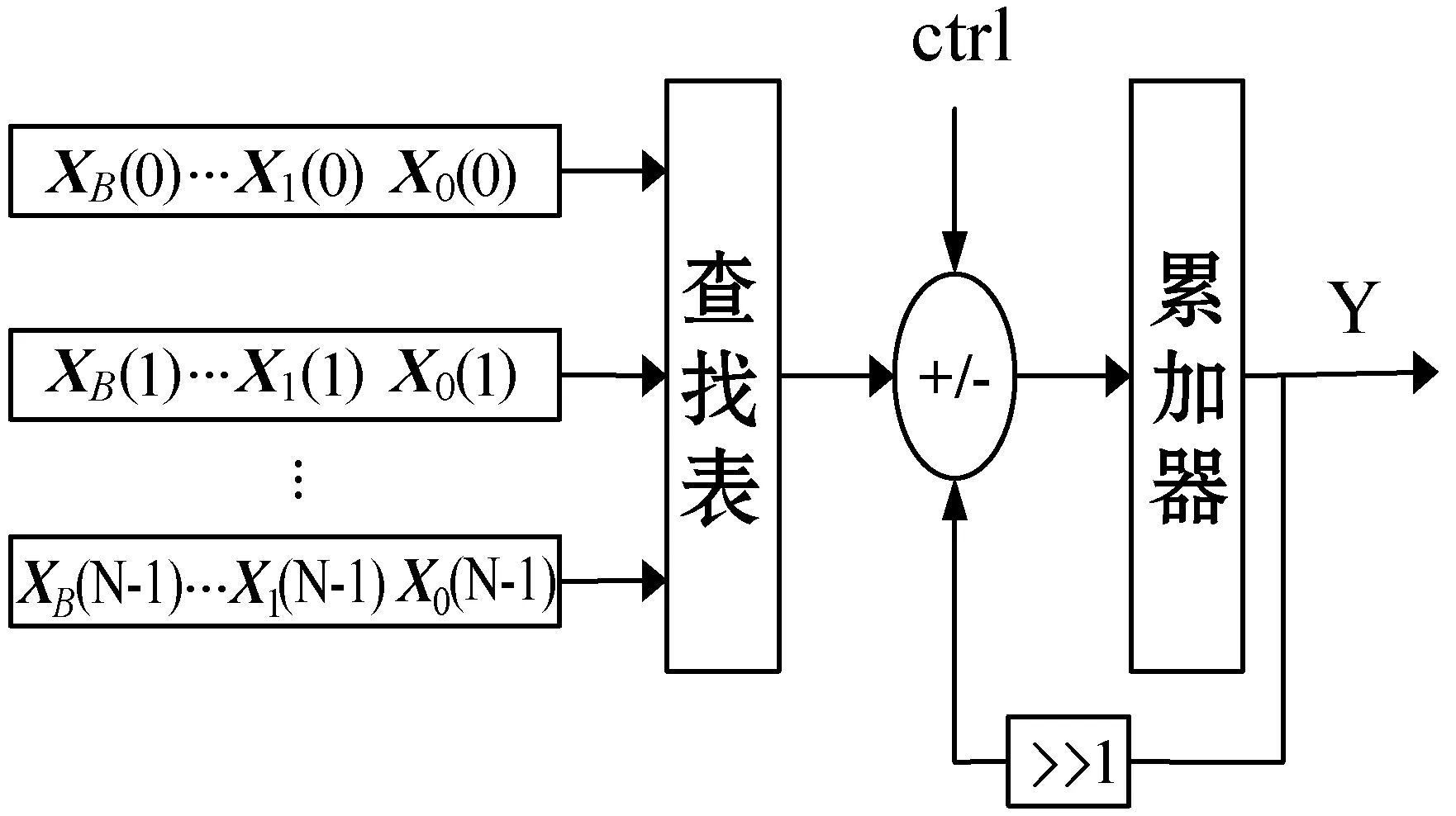
图1 分布式算法结构
分布式算法可简单概括为将每个输入数据进行分解,得到多个一位二进制数,然后将所有数据的相同位进行重组后得到查找表的地址,通过查询查找表得到该位数据与滤波系数的乘累加结果,最后将每位数据的乘累加结果通过移位寄存器进行二次幂加权后累加便可得到最后结果。
1.2 传统优化算法
查找表的规模会随着N的增大而呈现指数级的增长,通过对查找表进行分割,可以有效地减小查找表的规模。
假定一个N×L阶滤波器,该查找表的规模大小为2NL,将查找表分割为L组,每组对应一个大小为2N的查找表,查找表的规模就由原来的2NL减小为L×2N。由此可得:

(4)
取L=4,对应的四分割查找表结构如图2所示。
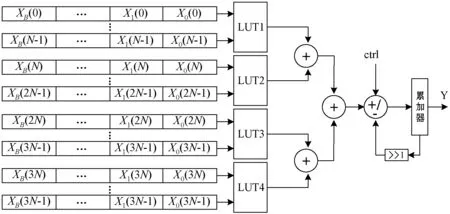
图2 分割查找表结构
对一个N×L阶的滤波器来说,分割查找表的基本思路就是将滤波器系数h(n)和输入数据xb(n)分为L份,每份滤波系数和输入数据乘累加后形成新的N阶查找表,再将所有N阶查找表进行相加后便可得到最终结果。
2 改进分布式算法
分割查找表虽然能大大降低查找表的规模,但当FIR滤波器的阶数为质数时,查找表就不能直接分割了,通过递归的思路将一个N阶的查找表进行小幅度的降阶,当阶数合适时再对查找表进行分割。
以一个4抽头FIR滤波器为例,根据图1可得到如表1所示的四输入串行结构查找表,其中b3b2b1b0是查找表的地址向量,其值是4个二进制数的某一相同位。

表1 四输入串行结构查找表

续表1
可以看出,由于查找表地址的每一位只有0和1两种取值,查找表下半部分的值由查找表上半部分的值与滤波系数h(3)的和组成。用数学公式表示如下:
LUT(1,b2,b1,b0)=LUT(0,b2,b1,b0)+h(3)
因此该四阶查找表可由一个二选一选择器和一个三阶的查找表构成,查找表的规模缩小了一半,结构如图3所示。

图3 查找表减半结构
以此类推可以不断地减小查找表的规模,甚至最终可以全部用全加器来代替,实现无查找表结构,但这样一来信号通过全加器逐级传播会产生较大的延时,对滤波器的性能会产生影响,加法器的过多使用也会消耗较多的硬件资源。先对查找表进行若干级的降级处理,然后再对查找表进行分割能达到最好的效果,在消耗资源少的同时也有良好的滤波效果。
3 FIR滤波器设计
3.1 设置滤波器参数
通过调用MATLAB中的FDATool工具可以方便快捷地得到滤波器系数,FDATool中可以设置滤波器阶数、采样频率和截止频率等。这里选择滤波器的响应类型为低通滤波器,采用窗函数中的海明窗来设计滤波器,滤波器的阶数为31阶,此时抽头系数为32个,采样频率设置为10 MHz,截止频率设置为200 kHz。低通滤波器的参数设置如图4所示。
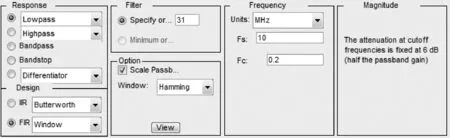
图4 FIR滤波器参数设置
设置好滤波系数后,FDA会直接生成相应的滤波系数,但此时导出的滤波系数精度比较高,会以浮点数的形式来表示,FPGA只能对定点数进行运算,所以在导出滤波系数之前需要对滤波系数进行依次量化,在满足设计的前提下,选择16位的量化位宽,通过对滤波系数放大取整最终得到量化后的滤波系数。
3.2 滤波器仿真
仿真平台采用Quantus和ModelSim,用Verilog语言进行自顶向下的设计。用DDS产生两路正旋波100 kHz和1 MHz的相加波形作为源波形,通过FIR滤波器将高于截止频率的1 MHz波形过滤掉。将输出结果设置为波形输出,仿真结果如图5所示。FIR_IN为滤波前的100 kHz和1 MHz的源波形,FIR_OUT为滤波后的信号。从仿真结果可以看出滤波效果还是非常理想的,滤波的速度也比较快。

图5 FIR滤波器仿真结果
4 实验结果分析
为了比较改进后的分布式算法与传统分布式算法在硬件逻辑资源上差别,分别设计了不同阶数的滤波器并在Quartus中实现,编译成功后显示出的资源消耗如表2所示。

表2 不同抽头数FIR滤波器资源消耗情况和最坏路径延时
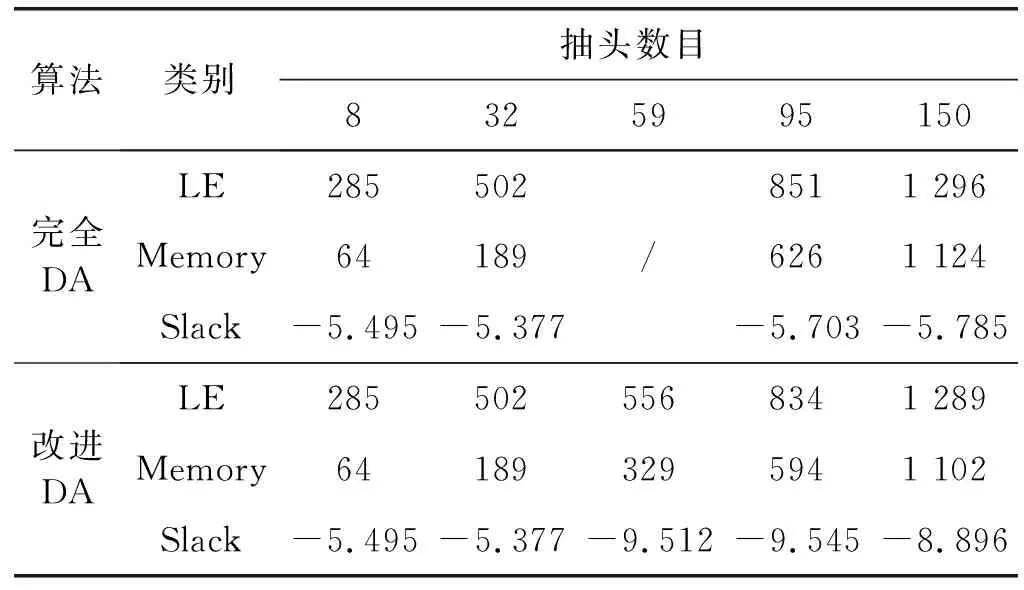
续表2
实验结果表明对于不同抽头数的FIR滤波器,分割DA相较于传统DA在逻辑单元(LE)和内存资源(Memory)上的占用显著减小,并且抽头数越大,减小得越明显。对于8抽头的内存资源占用情况,主要是查找表规模较小,分割查找表产生了额外的内存资源开销。对于59抽头滤波器,查找表无法进行直接分割,所以完全分割DA在该项数据缺失。完全分割DA和改进DA在资源的使用情况上大致相同,但改进DA可以适用于任意抽头数的滤波器。因此,对于抽头数目小的滤波器,实现电路简单,分割查找表对资源占用的影响不大,可以直接使用传统的查找表;对于抽头数目大的滤波器,电路结构十分复杂,传统的DA就会占用较多的硬件资源,这时就可以采用改进分割查找表算法。
另外从表2显示的最坏路径延时(Slack)可以看出,传统分布式算法与完全分割查找表算法的最坏路径延时基本上相差不大,但在改进分布式算法中的59、95和150抽头的最坏路径延时明显增大,这主要由于在改进分布式算法中使用了更多的选择器和加法器,产生了更多的组合逻辑,最坏路径延时与系统的最大运行时钟频率有很大关系,这直接影响到系统的性能。
5 结 语
提出一种改进的分布式算法,能适用于任意阶数的滤波器,基于该算法进行了不同阶数的滤波器仿真设计,仿真实验结果表明滤波效果达到了预期,与传统的分布式算法相比,显著减少了逻辑单元和内存资源的占用,但产生的最坏路径延时较大,未来可通过时序约束或插入寄存器减少组合逻辑等来减小最坏路径延时。
