Channel attention based wavelet cascaded network for image super-resolution①
2022-07-06CHENJianHUANGDetianHUANGWeiqin
CHEN Jian(陈 健), HUANG Detian②, HUANG Weiqin
(∗College of Engineering, Huaqiao University, Quanzhou 362021, P.R.China)
(∗∗School of Information Science and Technology, Xiamen University Tan Kah Kee College, Zhangzhou 363105, P.R.China)
Abstract Convolutional neural networks (CNNs) have shown great potential for image super-resolution(SR). However, most existing CNNs only reconstruct images in the spatial domain, resulting in insufficient high-frequency details of reconstructed images. To address this issue, a channel attention based wavelet cascaded network for image super-resolution (CWSR) is proposed. Specifically, a second-order channel attention (SOCA) mechanism is incorporated into the network, and the covariance matrix normalization is utilized to explore interdependencies between channel-wise features.Then, to boost the quality of residual features, the non-local module is adopted to further improve the global information integration ability of the network. Finally, taking the image loss in the spatial and wavelet domains into account, a dual-constrained loss function is proposed to optimize the network. Experimental results illustrate that CWSR outperforms several state-of-the-art methods in terms of both visual quality and quantitative metrics.
Key words: image super-resolution (SR), wavelet transform, convolutional neural network(CNN), second-order channel attention (SOCA), non-local self-similarity
0 Introduction
High-resolution (HR) images are able to significantly improve the accuracy of image analysis in medical diagnosis[1], remote sensing detection[2], intelligent transportation[3], facial recognition[4]and other fields. However, because of the existence of imaging equipment, atmospheric environment, noise and other factors, the captured images are usually difficult to satisfy the requirements of engineering applications. For decades, to restore a latent HR image with rich detailed information from its available low-resolution(LR) image, varieties of image super-resolution (SR)methods with excellent performance have been proposed.
With the development of deep learning, recent deep convolutional neural networks (CNNs) have been extensively exploited in image SR tasks and achieved considerable performance. To improve the feature representation ability of CNN, the methods of modifying the network structure, including increasing the network depth or/and width, have attracted extensive attention in recent years. For instance, both memory network(MemNet)[5]and residual dense network (RDN)[6]use dense blocks[7]to develop deep network models and take full advantage of hierarchical features extracted from the convolutional layers. Besides designing a deeper or wider network, some networks, such as nonlocal recurrent network (NLRN)[8]and squeeze-andexcitation network (SENet)[9], strengthen their performance by exploring feature interdependencies of space or channels. For image SR, most of the recent CNN-based models treat intermediate features of the each channel equally, which limits flexibility in highlighting significant features to reveal high-frequency details[5-6]. To break through this limitation,Zhang et al.[10]exploited a residual channel attention network(RCAN) for image SR by designing the residual structure and channel attention mechanism. However,RCAN only exploits the first-order feature statistics and ignores higher-order ones, which limits the representational ability of CNN. To solve this problem, Dai et al.[11]built a second-order attention network (SAN) for image SR by developing a second-order channel attention(SOCA) block to learning feature relationships between intermediate layers of the network.
In recent years, some models in Refs[12-14]combining wavelet transform with CNN have also been proposed. Kang et al.[12]proved that training CNN on wavelet sub-bands is beneficial to feature learning, and then proposed a wavelet residual network (WavRes-Net) to restore abundant texture details. By converting the SR problem to a problem of wavelet coefficient prediction, Guo et al.[13]presented a deep wavelet prediction for image super-resolution (DWSR) to recover lost details of wavelet coefficients of original images to be reconstructed. Unfortunately, both WavResNet and DWSR just explore one-level wavelet decomposition and process each wavelet sub-band independently,which ignores the dependencies between these sub-bands.Inspired by the U-Net architecture, Liu et al.[14]developed a multi-level wavelet convolutional neural network(MWCNN), in which wavelet transform is adopted to substitute the conventional pooling layer to avoid information loss.
In addition, numerous studies on image restoration in Refs[8,15] show that capturing the interdependence of long-distance information from an image can help restore more edge and texture details. For an image, the convolution operation can handle local region information solely, and as for long-distance information, it is necessary to continuously superimpose the convolutional layer to expand the receptive field. However, such methods are inefficient and their network structure are complex and difficult to optimize. To address the issues, Wang et al.[16]proposed non-local neural networks, which calculate the weighted sum of features at each location and treat it as the response of the corresponding location to effectively extract longdistance feature dependencies. Besides, Liu et al.[8]improved the non-local neural network and combined it with recurrent neural networks (RNNs), which boosts the utilization of parameters and the robustness of the model.
Inspired by the above literatures, a channel attention based wavelet cascaded network for image superresolution (CWSR) is proposed by fully exploiting the superiorities of the wavelet transform, CNN, SOCA and non-local self-similarity prior. The primary contributions of this paper are as follows. (1) A novel CWSR model is proposed to reconstruct as many highfrequency details as possible. Extensive experiments demonstrate that CWSR outperforms state-of-the-art methods for comparison in both visual quality and quantitative metrics. (2) SOCA is incorporated into the network to adaptively rearrange channel-wise features through exploring the inherent interdependencies between different channels. (3) The non-local module is integrated into the network to learn interdependencies between each feature and its neighborhood to enhance the quality of residual features. (4) In the spatial and wavelet domains, a dual-constrained loss function is proposed to optimize the proposed network to minimize the differences between the reconstructed image and its original HR image.
The subsequent structure of this paper is as follows. Section 1 introduces related work. Section 2 describes the detail of the proposed network. Section 3 presents the experimental results. And finally, the conclusions of the paper are drawn in Section 4.
1 Related work
Recently, the deep CNNs have achieved unprecedented success in various machine vision tasks including image SR[17-23]. However, most CNN-based models for image SR treat intermediate features of different channels equally, which limits the super-resolution performance. To deal with this problem, various attention mechanisms in Refs[7,10,11,15-16,23-25] have been explored in CNN-based approaches.
1.1 CNN-based SR approaches
In the image SR community, Dong et al.[17]developed a three-layer lightweight CNN for image SR(SRCNN), which implements end-to-end mapping between LR and HR images. To reduce the computational burden of SRCNN, Dong et al.[18]further proposed a fast super-resolution CNN (FSRCNN) by employing the deconvolution layer to enlarge the image and utilizing smaller filter sizes and more mapping layers. Similarly, Shi et al.[19]built an efficient sub-pixel CNN(ESPCN) by developing a sub-pixel convolution layer to enlarge feature maps extracted from LR images.Compared with SRCNN, FSRCNN and ESPCN achieved significant improvement in both super-resolution performance and computational efficiency. To further promote the super-resolution performance, Kim et al.[20].utilized residual learning[21]to exploit a very deep convolutional network (VDSR). Subsequently, by designing deeper and wider residual modules, Lim et al.[23]built an enhanced deep SR network (EDSR), which achieves great success in both reconstruction accuracy and computational efficiency.
1.2 Attention mechanism
Although the residual module facilitates to improve the super-resolution performance by increasing the network depth, the network becomes difficult to converge after it reaches a certain depth. To tackle this issue, the methods of embedding attention mechanisms, such as spatial attention and channel attention,into CNN-based models in Refs[10,11,15-16,24-25]have received more and more attention. Wang et al.[16]built a non-local neural network by developing non-local operation to capture long-range dependency. It is worth noting that non-local operations can be easily incorporated into various computer vision networks and boost their performance. Liu et al.[8]also designed non-local operations and incorporated them into the RNN for end-to-end training to capture feature correlation between each location and its neighborhood. The difference between Ref.[16] and Ref.[8] is that the former measures feature correlation of each location throughout the whole image, while the later measures feature correlation of each location only in its neighborhood. Zhang et al.[15]built residual non-local attention networks (RNAN), in which local and non-local attention blocks were designed to capture the long-range dependency between pixels to promote the representation ability of the network. Except for local and non-local attention, channel attention is developed to explore the dependency between network channels. RCAN[10]and SAN[11]respectively employed the first- and second-order feature statistics to develop different channel attention mechanisms to enhance the representational ability of CNNs.
2 Proposed network
Considering that most existing CNN-based models do not make full use of the information of the original LR images and treat each channel-wise feature equally, a channel attention based wavelet cascaded network for image super-resolution is proposed to further improve the super-resolution performance.
2.1 Network framework
Wavelet transform possesses multi-resolution decomposition characteristics, it is able to effectively decompose the ‘contour’ and ‘detail’ features of the image. With this advantage of the wavelet transform,the image SR is performed in the wavelet domain,rather than in the spatial domain, to overcome the shortcoming that local features are hard to be well represented in the spatial domain[12-13].
CWSR, as shown in Fig.1, is essentially a U-Net architecture network, and each level of the network includes a contracting sub-network and an expanding sub-network. Considering that the discrete wavelet transform (DWT) is a reversible operation and can simultaneously capture the frequency and position information of features, it is incorporated into the contracting sub-network to replace the conventional pooling operation to preserve the edge and texture features of the input image and avoid the loss of information. In the expanding sub-network, the inverse discrete wavelet transform (IDWT) is used to implement the upsampling operation to achieve the mapping from LR to HR features. At the same time, to explore and utilize the feature interdependencies between the four wavelet sub-bands, a convolutional layer is introduced in the proposed model to strengthen the image details after each level of DWT operation.Such methods,which have been exploited in the exiting models in Refs[12-14],can effectively improve the super-resolution performance.
As shown in Fig.1, CWSR consists of 3 parts.Each group of DWT and IDWT of the same size constitute a part of the network. That is, DWT1 and IDWT1, DWT2 and IDWT2, DWT3 and IDWT3 constitute the first, second and third part of the network, respectively. In a certain part, three CNN units and a CSOCA module are connected after each level of DWT, where each CNN unit contains a 4-layer fully convolutional network (FCN) and all sub-bands are provided as inputs; the CSOCA module consists of a convolutional (Conv) layer and a SOCA block, and the Conv layer of CSOCA is used for feature selection.Specifically, each layer of the CNN unit contains three Conv filters, batch normalization (BN), and rectified linear unit (ReLU). It is noteworthy that the last CNN unit (CNN18) in the network utilizes only one Conv layer (without BN and ReLU) to compress the channel number. CSOCA module consists of Conv, global covariance block, Conv, ReLU and Sigmoid. After features are input into the Sigmoid, it will output weightsf(as shown in SOCA module in Fig.1) ranging from 0 to 1, which are used to measure the importance of the features among channels. To realize the mapping from shallow features to deep features and network training,the features obtained by the CSOCA1 and CSOCA2 modules and the features obtained by the CNN25 and CNN15 modules are added with the element-wise summation, respectively. In addition, in the final stage of obtaining the reconstructed image, a non-local module was added before the CNN18 block to enhance residual features.
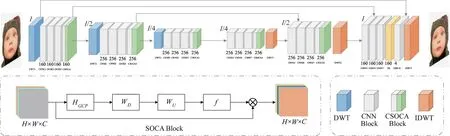
Fig.1 The architecture of CWSR
The workflow of CWSR is as follows. Firstly, to achieve both odd and even magnification, an image of the same size as the HR image are fed, which is obtained by up-sampling the image to be reconstructed with bicubic interpolation, into CWSR, instead of directly feeding the original LR image. Then,the LR image is first decomposed into four sub-bands by performing DWT1 operation, and then four sub-bands are separately fed into CNN11 as four channels to investigate the relationship of the sub-bands. Subsequently, after performing each level of DWT operation or before each level of IDWT operation, SOCA is employed to explore interdependencies between channel-wise features of four wavelet sub-bands. Next, the non-local module is used to enhance the quality of the residual features before performing the last level IDWT (IDWT1) operation. Finally, four wavelet sub-bands obtained by DWT1 are individually added to the corresponding residual images obtained by CNN18, and then IDWT1 is performed to obtain the final reconstructed image. It is worth noting that each time a DWT operation is performed, the size of the feature map will be reduced to 1/4 of the original size, and the number of the corresponding channel will be increased to four times that of the original one; on the other hand, all feature maps obtained by DWT are input into the CNN module for training, instead of training each sub-band separately.
As with DWSR[13], the Haar kernels are selected as the wavelet basis function. In CWSR, assuming that the size of the input LR image is 4Iand the initial number of channels isn, the feature map size obtained by performing a one-level DWT on the input isI,and the corresponding number of channels is increased to 4n.Among them,the feature corresponding to[1:n] channels is the low-frequency approximation sub-bandLL,the features corresponding to[n+1:2n],[2n+1:3n]and[3n+ 1:4n] channels are the high-frequency detail sub-bandLH,HLandHHin the horizontal,vertical and diagonal direction, respectively.
2.2 Second-order channel attention
Compared with traditional CNN, the advantage of DWT is that its frequency and location characteristics facilitate the preservation of edges and textures because of its biorthogonal property[14]. Moreover, since DWT is reversible, down-sampling the image with DWT ensures that all image information will be preserved.Considering that there is a meaningful relationship among the four wavelet sub-bands obtained by DWT decomposition, the CNN module is utilized to exploit their relationship.
For CNN-based SR models, if the low-frequency and high-frequency information of the input image are treated indiscriminately in each channel, the powerful representation ability of CNN will be suppressed[10-11].To effectively explore dependencies between channelwise features, SOCA is incorporated into the proposed CWSR, which enables the network to learn more highfrequency features to boost its representational ability.As shown in Fig.1, SOCA block is fused with the last Conv layer after each level of DWT operation, and the fused module is named as CSOCA. Where, SOCA is employed to learn feature dependencies adaptively by utilizing second-order feature statistics for a more discriminative representation. Assuming aW×H×Cfeature mapF= [F1,F2,…,FC] withCfeature maps with the size ofW×H, then the feature mapFis reshaped to a feature matrixXwithS×C,(where,S=W×H),subsequently, the covariance matrixΣis obtained:
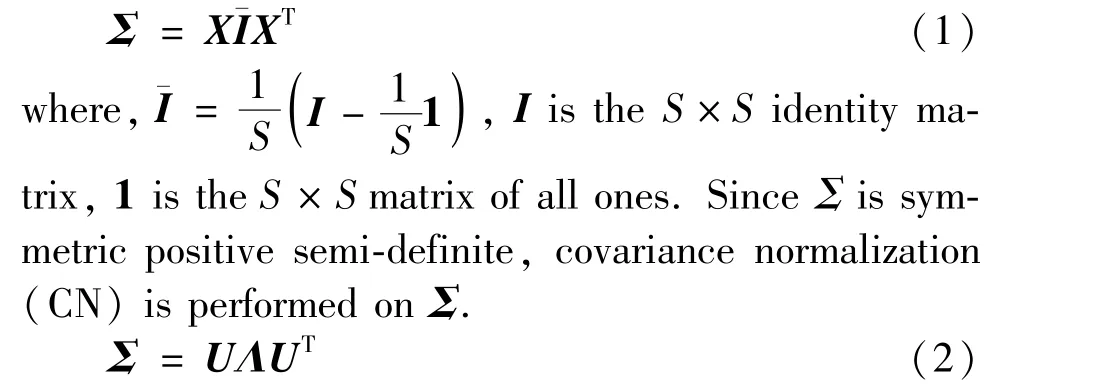
where,UandΛare an orthogonal matrix and diagonal matrix, respectively, andΛ= diag(λ1,…,λC).Subsequently, CN can be converted to the power of eigenvalues.
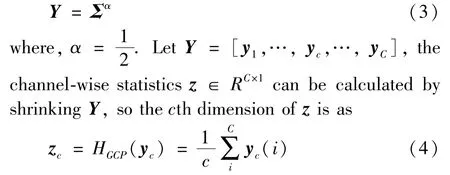
where,HGCP(·) stands for the global covariance pooling (GCP) function. Then, the channel attention mapwcan be calculated by

2.3 Non-local module
The non-local operation can be used to capture long-range dependency,i.e.,capturing the dependency between a location and its neighborhood, which breaks through the limitation of the local operation of traditional CNNs[15-16]. Then, the obtained dependency can be used as a weight to represent the similarity between other locations and the current location to be calculated.
Inspired by Ref.[26], the non-local operation is wrapped as a non-local module by adding a skip connection, as shown in Fig.2, and then the non-local module is incorporated into the network to produce reliable feature dependencies to enhance the quality of residual features.Furthermore, to decrease the amount of calculation, a bottleneck structure is also introduced.Assuming the channel number of input feature is 4C,its channel number is reduced to 1/4 of the original channel number after it is operated byθ,φandg,where,θ,φandgall represent 1×1×Cconvolution operation,νdenotes a 1× 1× 4Cconvolution operation, ⊗and ⊕stand for dot multiplication and addition.
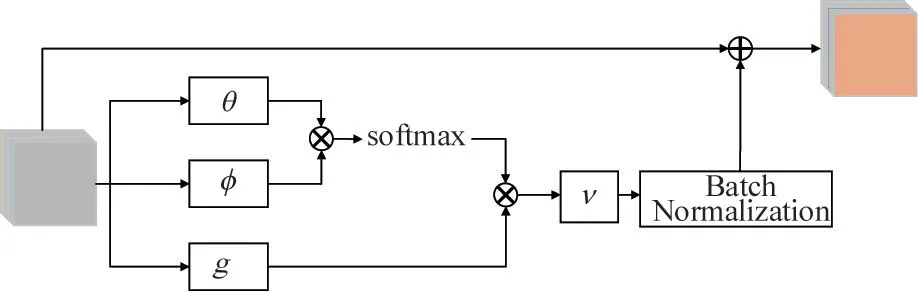
Fig.2 Non-local module
Concretely, the non-local module takes a multichannel inputMas the image feature and generates an output featureO. Its expression is

2.4 Loss function
IDWT operation is performed to generate a reconstructed image as a final result from a series of wavelet sub-bands. On the one hand, the wavelet domain loss is used to constrain the proposed model to recover more high-frequency details. On the other hand, the spatial domain loss is utilized to constrain the proposed model to achieve a balance between edge texture features and smooth features. Eventually, a dual-constrained loss function is proposed to optimize the proposed CWSR.Thus, the total loss is composed of the wavelet domain losslosswavand the spatial domain onelossimg.
Since theL2norm can not only be used to measure the difference between two vectors, but also prevent overfitting in model training, which greatly improves the generalization ability of the model. Therefore, a novel loss function is proposed based on theL2norm,and its expression is as where,Nrepresents the number of training samples,ISRrepresents the reconstructed image, andIHRrepresents the original HR image.
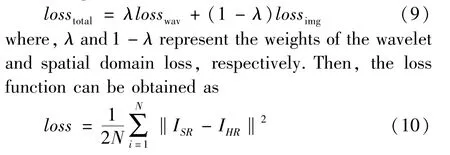
Wavelet domain loss. Due to taking full use of the relationships between four sub-bands, the proposed network can avoid information loss, which is conducive to recovering more detailed information. SupposeyLRrepresents the test LR image, andxHRrepresents the corresponding original HR image. The input of the proposed network is a middle resolution (MR) imageyMRobtained by up-samplingyLR.It is necessary to learn the relationship between the wavelet coefficients obtained by feedingyMRandxHRto a one-level DWT, so that the network output will be as close as possible to the wavelet coefficients obtained by performing a onelevel DWT on the corresponding HR image.
Calculating the wavelet domain losslosswaveinvolves solvingloss1in Fig.3 andloss3in Fig.4, wherelosswav=loss1+loss3.The residuals obtained by the CSOCA1 module are respectively added to the four sub-bands to formDCS1(LL1,LH1,HL1,HH1).Suppose that the four sub-bands, represented asDWTHR(LL,LH,HL,HH),are obtained by feeding the original HR imagexHRto a one-level DWT, thenloss1betweenDCS1 andDWTHRcan be solved according toL2norm. Concretely, each sub-band ofDCS1 first solves the loss with its corresponding sub-band ofDWTHR,and then the losses of four sub-bands are summed to obtain the final lossloss1, that is,loss1=lossLL1+lossLH1+lossHL1+lossHH1.The purpose of calculatingloss1is to constrain the extracted features in the shallow network so that the edge and texture features of the reconstructed image are as close as possible to that of the original HR image.

Fig.3 Loss of the shallow network
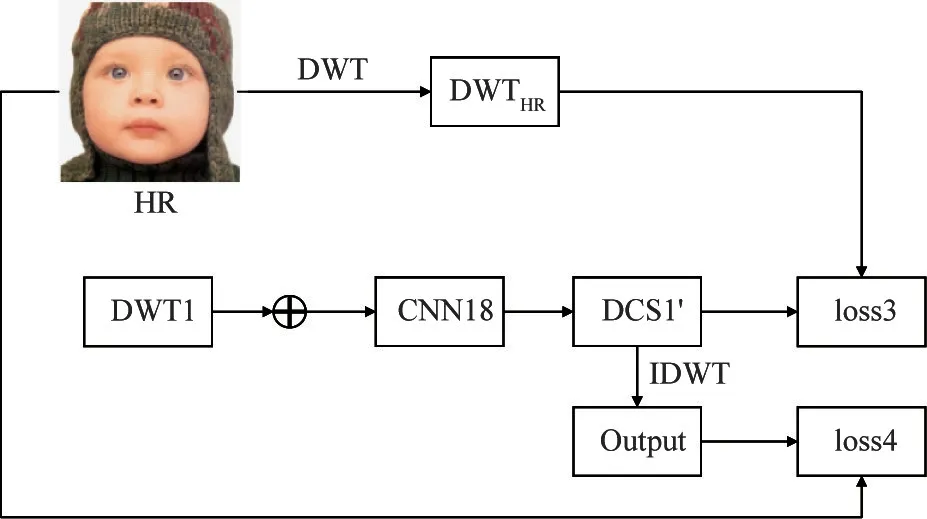
Fig.4 Loss of the deep network
Similarly,loss3in Fig.4 can be solved byDCS1′andDWTHRaccording toL2norm, where,DCS1′represents the residual images obtained by adding the four wavelet sub-bands obtained by DWT1 to the corresponding residuals obtained by CNN18, as shown in Fig.1, which can be used as a supplement to the detailed information of the MR imageyMRduring the reconstruction process to boost the super-resolution performance. Similarly, each sub-band ofDCS1′first calculates the loss with its corresponding sub-band of the HR image, and then the losses of four sub-bands are summed to obtain the final lossloss3, that is,loss3=lossLL3+lossLH3+lossHL3+lossHH3.
Spatial domain loss. To achieve a balance between detail and smooth features, in addition to the wavelet domain loss, the spatial domain loss of the image is also concerned. Calculating the spatial domain losslossimginvolves solvingloss2in Fig.3 andloss4in Fig.4, wherelossimg=loss2+loss4.In Fig.3,IDCS1 represents the result obtained after the IDWT is performed onDCS1(LL1,LH1,HL1,HH1). SinceIDCS1 is essentially a rough reconstructed image to be further optimized,loss2betweenIDCS1 and the original HR imagexHRcan be solved according toL2norm. In Fig.4, since the reconstructed imagexSRobtained by performing a one-level IDWT onDCS1′is equivalent to the output of the proposed CWSR,loss4betweenxSRandxHRcan be calculated according toL2norm.
3 Experiment
3.1 Parameters, datasets and metrics
To train CWSR, a large training consists of the images from the following dataset, including BSD[27],DIV2K[28]and WED[29]. Specifically,200 HR images were selected from BSD, 800 ones were selected from DIV2K, and 4744 ones were selected from WED. During training,24 ×6000 patches with the size of 240 ×240 were cropped from the training images. For the network parameters, their initialization is the same as Ref.[21]. ADAM optimizer[30]was employed to train the proposed CWSR. A min-batch size was 32, and other hyper parameters of ADAM are set to default values. During the iteration,the learning rate decays from 0.01 to 0.0001. Moreover, the neighborhood size is 45 ×45 in the non-local module. The proposed CWSR has been implemented on two Nvidia Titan RTX 24GB GPUs.
To ensure the objectivity of the experiments, four benchmark sets including Set5[31], Set14[32], BSD100(100 images derived from BSDS 300[27]) and Urban100[33]were selected as test datasets. Moreover,the reconstructed images are gauged with subjective visual perception and objective evaluation metrics including peak signal-to-noise ratio (PSNR) and structural similarity (SSIM)[34].
Mrs. Thompson paid particular attention to Teddy. As she worked with him, his mind seemed to come alive. The more she encouraged him, the faster he responded. By the end of the year, Teddy had become one of the smartest children in the class.
3.2 Experimental results
To quantitatively evaluate the reconstructed image, the MR images obtained by up-sampling LR ones are regarded as the input images to be reconstructed,and the original HR images are regarded as the reference ones.
3.2.1 Analysis of different modules
To explore the feasibility and effectiveness of different modules, the proposed CWSR model is compared with two intermediate models, i.e., WCN is the model using only wavelet transform and CNN modules,and WCN +SOCA are the model using wavelet transform, CNN and SOCA modules. Essentially, CWSR is the model using wavelet transform, CNN, SOCA and non-local modules. Table 1 lists the average PSNR and SSIM of reconstructed images obtained by three models mentioned above. As can be seen from Table 1, although WCN+SOCA performs much better than WCN,CWSR achieves the optimal super-resolution performance with the highest average PSNR and SSIM. These results indicate that almost all different modules of CWSR have positive significance.
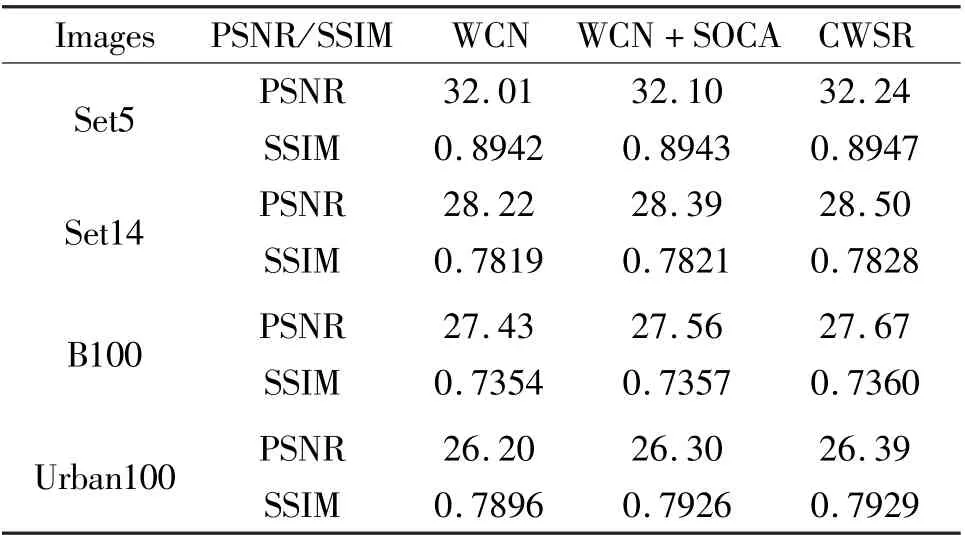
Table 1 Comparison of the average PSNR (dB) and SSIM obtained by different modules with scale factor×4
3.2.2 Analysis of network structure
CWSR can essentially be extended to different levels of DWT. However, higher level of DWT directly means deeper network and higher computational complexity. Accordingly, an appropriate level of DWT is required to balance super-resolution performance and computational efficiency. This experiment compared the performance of the models (i. e., CWSR-1,CWSR-2, CWSR-3 and CWSR-4) with 1-,2-,3- and 4-level DWT with scale factor 4.
Table 2 presents the average PSNR, SSIM and computational time of different models with the level of 1 to 4. As can be seen from Table 2, in terms of both PSNR and SSIM metrics, CWSR-3 is significantly superior to CWSR-1 and CWSR-2, while CWSR-4 has only a negligible improvement over CWSR-3; then,combined with the computational time, it can be seen that the CWSR-3 model, which is the default CWSR model, has a better tradeoff between super-resolution performance and computational efficiency than the other three models. The main reason is thatLLncontains scarcely effective low-frequency information for image SR after an appropriate level of DWT.
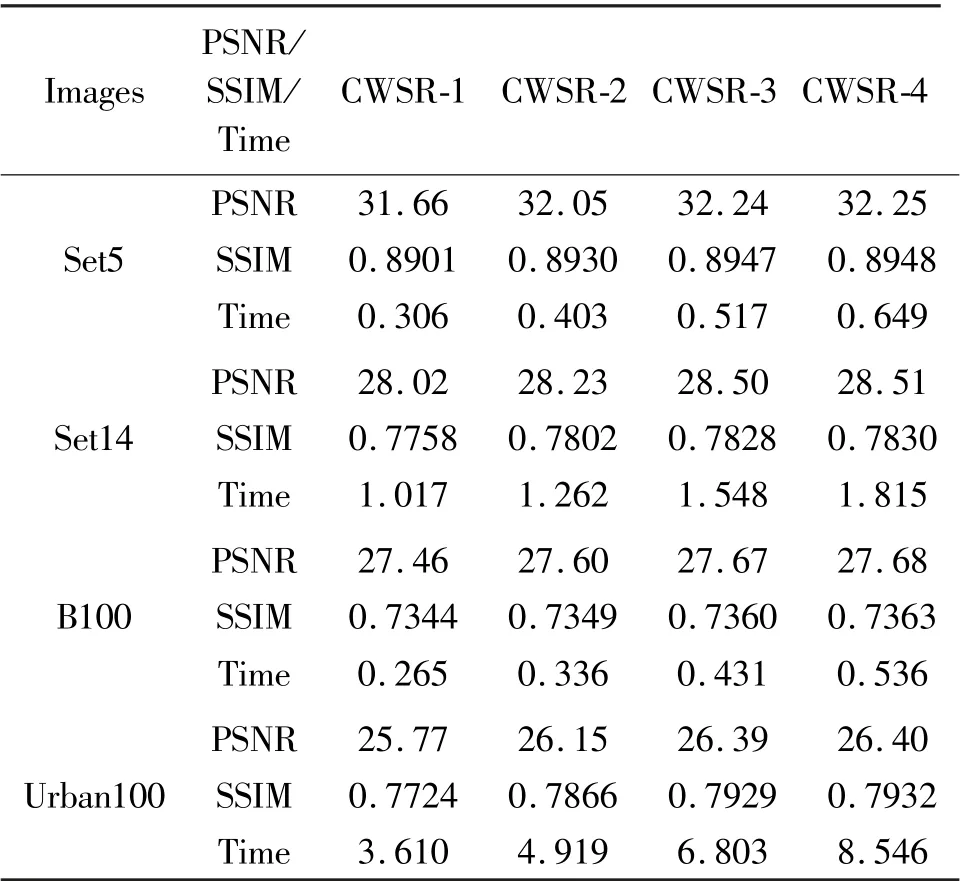
Table 2 Comparison of the average PSNR (dB), SSIM and computational time (seconds) of CWSRs with different levels of DWT with scale factor ×4
To further validate the effectiveness of CWSR, it is compared with state-of-the-art methods, i.e., SRCNN[17], VDSR[21], LapSRN[35], DRRN[36], IDN[37],DPSR[38], IMDN[39]and MWCNN[14]. Table 3 lists the average PSNR and SSIM of reconstructed images obtained by various methods with different scale factors(i.e., ×2, ×3 and ×4) on Set5, Set14, B100 and Urban 100. From Table 3, it can be seen that the average PSNR and SSIM of reconstructed images obtained by CWSR are higher than that of most methods for comparison, which indicates that the proposed method produces the leading result in overall super-resolution performance. Specifically, as can be seen from Table 3,for the case of scale factor with 2, the average PSNR of CWSR is only slightly lower than that of IMDN on the Set5 dataset, but the average SSIM is still higher than IMDN; at the same time, both the average PSNR and SSIM of the proposed CWSR are the highest on other three datasets. And for the case of scale factor with 3,although the average PSNR of the proposed method is rarely insufficient on the Set5 and Set14 datasets, the average SSIM is also the highest on all datasets. For the case of scale factor with 4, the proposed method almost achieves optimal or suboptimal performance in terms of PSNR and SSIM metrics.
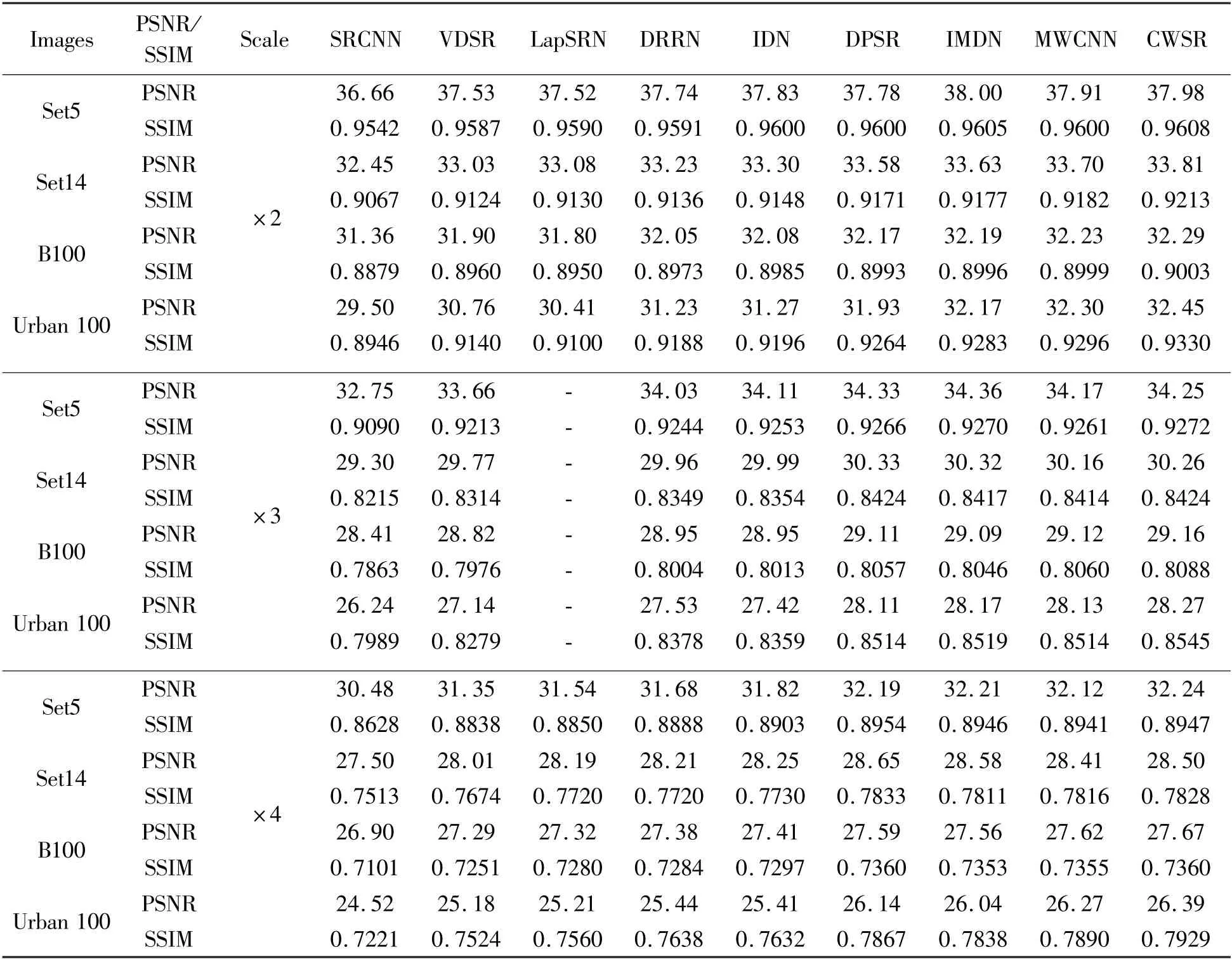
Table 3 Comparison of the average PSNR (dB) and SSIM obtained by different methods with different scale factors
To intuitively compare reconstructed images of different SR methods from subjective visual perception,Fig.5 -Fig.8 illustrate the enlarged results of reconstructed images at the same area with scale factor 4,and the corresponding original HR image is given as a reference image. From Fig.5 -Fig.8, it can be seen that most compared methods are unable to accurately reconstruct the edge and texture details, and even suffer from serious artifacts. However, CWSR reconstructs a sharper image and restores more high-frequency details.
Fig.5 presents the visual comparisons of various methods on the image ‘butterfly’ from Set5. It can be seen from Fig.5 that the images reconstructed by SRCNN, VDSR and LapSRN are not clear enough; the image reconstructed by DRRN even has aliasing; IDN and DPSR can only recover the main contour of the image, but not more detailed information; in contrast,IMDN, MWCNN and the proposed method can recover more details and achieve better super-resolution results. However, compared with IMDN and MWCNN,the reconstructed image of CWSR has sharper contours and better preserves the edge and texture information of the butterfly wings.
Fig. 6 shows the visual comparisons of various methods on the image ‘Baboon’ from Set14. As can be seen from Fig.6, the reconstructed image of CWSR retains the details of the beard well,and the images reconstructed by DPSR, IMDN and MWCNN are slightly blurry. This is mainly because CWSR makes full use of wavelet transform, channel attention and non-local prior to jointly recover more high-frequency details.
Fig.7 illustrates the visual comparisons of various methods on the image ‘Zebra’ from B100. As can be seen from Fig.7, although the reconstructed image of LapSRN algorithm is better than that of SRCNN, VDSR and IDN in edge sharpening, many artificial details appear in its reconstructed images; compared with LapSRN, the images reconstructed by DRRN, DPSR and IMDN have only a few artificial details and contain sharper edge; compared with the previous SR algorithms, MWCNN can obviously restore more edge details, and there are almost no artificial details in its reconstructed images;however,thanks to the attention mechanism that can explore dependencies between channel-wise features and the non-local module that can further enhance the residuals, CWSR is slightly better than MWCNN in restoring the edge details.

Fig.5 Visual comparison of super-resolution results of ‘Butterfly’ (Set5) obtained by different algorithms with scale factor ×4

Fig.6 Visual comparison of super-resolution results of ‘Baboon’ (Set14) obtained by different algorithms with scale factor ×4

Fig.7 Visual comparison of super-resolution results of ‘Zebra’ (B100) obtained by different algorithms with scale factor ×4

Fig.8 Visual comparison of super-resolution results of ‘Img 006’ (Urban100) obtained by different algorithms with scale factor ×4
Fig.8 presents the visual comparisons of various methods on the image ‘Img 006’ from Urban100. It can be seen from Fig.8 that the reconstructed image of SRCNN has some distortion,while the edge and texture of reconstructed images of VDSR, IDN, LapSRN,DPSR and DRRN are blurred; obviously, IMDN and MWCNN outperform the previous methods,but also are still inferior to CWSR. The image reconstructed by the proposed CWSR has better visual effects than that by MWCNN, with sharper edges and textures.
4 Conclusion
To obtain more high-frequency information, a channel attention based wavelet cascaded network for image super-resolution is proposed. A SOCA module is incorporated into the proposed network to adaptively learn the inherent correlations of channel-wise features, and then the non-local module is utilized to capture interdependencies between each feature location and its neighborhoods to boost residual features, finally a novel dual-constrain loss function based on the spatial and wavelet domains is proposed to strengthen the constraints on network training. Experimental results demonstrate the superiority of CWSR in comparison with several state-of-the-art super-resolution methods.
杂志排行

High Technology Letters的其它文章
- Directional nearest neighbor query method for specified geographical direction space based on Voronoi diagram①
- A multispectral image compression and encryption algorithm based on tensor decomposition and chaos①
- Analysis of fluid vibration transfer path and parameter sensitivity of swash plate axial piston pump①
- Non-identical residual learning for image enhancement via dynamic multi-level perceptual loss①
- SAR image despeckling via Lp norm regularization①
- A correlation OPTS algorithm for reducing peak to average power ratio of FBMC-OQAM systems①