Non-identical residual learning for image enhancement via dynamic multi-level perceptual loss①
2022-07-06HURuiguang胡瑞光HUANGLi
HU Ruiguang(胡瑞光), HUANG Li
(Beijing Aerospace Automatic Control Institute, Beijing 100854, P.R.China)
Abstract Residual learning based deep generative networks have achieved promising performance in image enhancement. However, due to the large color gap between a low-quality image and its highquality version, the identical mapping in conventional residual learning cannot explore the elaborate detail differences, resulting in color deviations and texture losses in enhanced images. To address this issue, an innovative non-identical residual learning architecture is proposed, which views image enhancement as two complementary branches, namely a holistic color adjustment branch and a finegrained residual generation branch. In the holistic color adjustment, an adjusting map is calculated for each input low-quality image,in order to regulate the low-quality image to the high-quality representation in an overall way. In the fine-grained residual generation branch, a novel attention-aware recursive network is designed to generate residual images. This design can alleviate the overfitting problem by reusing parameters and promoting the network’s adaptability for different input conditions. In addition, a novel dynamic multi-level perceptual loss based on the error feedback ideology is proposed. Consequently, the proposed network can be dynamically optimized by the hybrid perceptual loss provided by a well-trained VGG, so as to improve the perceptual quality of enhanced images in a guided way. Extensive experiments conducted on publicly available datasets demonstrate the state-of-the-art performance of the proposed method.
Key words: image enhancement, deep residual network, adversarial learning
0 Introduction
Image enhancement, as a classical computer vision task, aims at recovering high-quality image from its low-quality version. High-quality images should have abundant color, clear texture, and satisfactory perception, etc.. It is an important task that can facilitate various industrial communities, e. g. satellite[1],medical, and 4K television[2]. Many traditional enhancement methods including Gaussian smoothing, and bilateral filtering have been proposed without supervised information. With the flourish of deep neural networks, convolutional neural networks (CNNs) have shown the powerful capability in image enhancement by learning pairwise training patches. Some existing methods mainly focus on solving image enhancement problem from specific aspects, such as enhancing illumination, adjusting contrast, and denoising.
It can be noticed that low-quality images and their high-quality targets have great similarity in contents,thus their detail differences, i. e. texture, edge and color recovery are important for image enhancement.Consequently, residual learning has become a successful method to excavate those details by building an identical mapping from low-quality to high-quality images. Later, generative adversarial networks (GANs)based image enhancement frameworks are proposed.They adopt deep residual network as generative model for enhancing low-quality images, and take multiple loss function,e.g. a perceptual loss and an adversarial loss, to optimize network for promoting visual quality.However, those methods still remains three deficiencies. (1) A low-quality image and its high-quality version exist large gaps in holistic color. The identical mapping in the residual learning cannot force generative models to accurately capture the detailed information. (2) Generative models usually have large number of parameters, causing great storage cost and rising the risk of overfitting. (3) Although one or multi-level perceptual losses are widely applied for network optimization, the loss weight allocated to each level are fixed, resulting in unpleasant artifacts or unfavorable color representations in enhanced images.
To address the above-mentioned issues, non-identical residual learning is first considered to adjust lowquality images to high-quality style. Hence, a novel image enhancement framework is proposed, which consists of two complementary branches: holistic color adjustment and fine-grained residual generation. In the fine-grained residual generation branch, recursive structures are employed to construct the proposed network with less parameters meanwhile alleviate overfitting. However, the feature representations are still limited due to model capacity, and it lacks flexibility to adapt to different image scenes. Consequently, a lightweight attention-aware recursive network is proposed.It is composed of fully multi-scale feature extraction to extract more representative primary features, and a recursive convolutional function, which collocates multilevel channel-wise attention to promote the flexibility of the network by dynamically excavating color information. The holistic color adjustment can adjust global information and facilitate the generative network to learn local details. It is tried to compute the overall residuals between low-quality images and high-quality images.Then, an adjusting map is estimated for input lowquality images adaptively. Accordingly, low-level feature maps extracted from a well-trained network have abundant color information, while the extracted highlevel feature maps contain more spatial and texture information. Optimizing single one-level perceptual loss cannot comprehensively promote enhanced quality.Therefore, a multi-level perceptual loss is considered to comprehensively optimize the proposed network.However, the loss weight of each level cannot be easily determined, and it lacks of flexibility during the training process. Consequently, a dynamic multi-level perceptual loss is introduced for optimization based on the error feedback. Detailedly, feature contents of highquality and enhanced images are extracted from maxpooling layers of VGG16, and content errors between high-quality and enhanced features are computed. According to the value of the errors, a weight is decided for perceptual loss of each level. Thus, enhanced images will have rational color representations and textures.
In summary, the main contributions of this paper are as follows.
(1) A novel non-identical residual learning frame-work is tailored for image enhancement, in which an adjusting map is carefully computed to adjust global color to high-quality target.
(2) A novel attention-aware recursive network is proposed to adaptively enhance residual details according to input low-quality images.
(3) An innovative dynamic multi-level perceptual loss (DPL) is presented to approximate color representation of high-quality images, hence promoting perceptual effect in a more comprehensive way.
(4) Extensive experiments on publicly available dataset show the state-of-the-art performance of the proposed method,both quantitatively and qualitatively.
The rest of paper is organized as follows. Section 1 overviews related work. Section 2 describes the enhancement architecture. Experimental results and their analysis are presented in Section 3. Section 4 concludes this paper.
1 Related work
1.1 Image enhancement
The pioneer image enhancement work often concentrate on improving image contrast,such as histogram equalization (HE) and its variants bi-HE. Ref.[3]proposed a low-light image enhancement method by estimating illumination maps. However, those methods do not use external information and the performance of them is usually inadequate and limited. An external example-based approach was proposed for low-light image enhancement in Ref.[4], which adopts an autoencoder to learn a mapping function. Ref.[5] proposed a unified image enhancement framework, which combines learning based methods with reconstruction based methods. Some work enhance images in specific conditions,e. g. hyper-spectral image and underwater image.
Recent years, CNNs show promising performance in many image enhancement sub-tasks, e.g. image super-resolution, image denosing[6]and image colorization. In Ref.[7], a reconstruction-based pairwise depth dataset for depth image enhancement was proposed. CNNs for weakly illuminated image enhancement was proposed in Ref.[3]. Deep residual learning was proposed in Ref.[8], and it showed effectiveness for deep network construction. However, those deep networks significantly increase the number of parameters and the overfitting problem is highly likely. Recursive structures have become an effective way to relieve overfitting for the less parameters. Ref.[9] proposed DRRN that combines residual learning for easy training by a 52-layers network, showing the promising performance in image super-resolution. Employing the recursive structure is tried to construct a lightweight model for image enhancement. However, those methods are limited by optimizing single MSE loss and it will cause some blurry and unrealistic enhancement results.
1.2 Deep residual learning
Deep learning firstly attracts great attention in Ref.[10], and it showed significant promotions in image classification tasks. Then, VGG networks were presented in Ref.[11], and they become universal feature extraction models. Ref.[12] proposed Inception network to introduce multi-scale feature representation in CNN. Ref.[12] demonstrated that deeper network can accordingly achieve better performance.Afterwards, many work focus on increasing depth of CNN to promote performance. However, when deeper networks are able to start converging, a degradation problem is exposed, that is, with the network depth increasing the performance gets saturated and then degrades rapidly. Besides, vanishing gradient problem still limits the performance of CNN.
Residual learning tries to solve those problems by constructing identical mapping, and the depth of CNN is substantially increased. It can be written asy=x+F(x),wherexandyare the input and output vectors of the layers, andFrepresents the residual mapping to be learned. The ideology of residual learning can be integrated into many previous networks[8],and many image-to-image translation tasks also adopt residual learning method to abridge the gap of generated images and input images. Ref.[8] proposed a residual learning based CNN for image denoising. In Ref.[6],a residual dense network was proposed for image super-resolution. However, residual learning has some bottlenecks in image enhancement. The identical mappingxcannot forceF(x) to learn detailed difference between low-quality and high-quality images. Therefore, nonidentical mapping is considered to adjusts inputxto an appropriate value.
1.3 Perceptual loss
A high-quality image should have clear textures,abundant colors, and conform to human perception.Thus, Ref.[13] introduced a pre-trained VGG network to compute perceptual loss for improving the quality of generated images. Ref.[9] proposed an enhancement method based on perceptual loss, which enriches more high-frequency information of enhanced images. Ref.[14] proposed generative adversarial nets(GANs), which has become an effective way for image generation. A conditional GAN was proposed in Ref.[15]for image-to-image translation task. Ref.[16] proposed a cycle-consistent adversarial networks for style transfer.Super-resolution based GAN adopts a generator, a feature extractor, and a discriminator to optimize hybrid loss, and they also achieve state-of-the-art performance in human perceptions. However, real-world image enhancement is a universal task for various image transformations (texture, luminance and resolutions). In Ref.[17], universal image enhancement frameworks were proposed. They publish a new large-scale image enhancement dataset based on DSLR camera. And a multi-term loss function is composed of color, texture and content terms, allowing an efficient image quality estimation. For image enhancement, optimizing highlevel perceptual loss tends to extrude the shape of objects, while optimizing low-level perceptual loss can generate color-bright images. However, conventional multi-level perceptual loss lacks of flexibility in balancing those two aspects, because they allocate a fix loss weight for each level. Those weights are dynamically controlled to promote the flexibility.
2 The proposed method
2.1 General framework
The architecture of non-identical residual learning for image enhancement via dynamic multi-level perceptual loss is shown in Fig.1. The holistic color adjustment globally adjusts the low-quality image to highquality target. The fine-grained residual generation can recover texture and color details. Conventional residual learning[17]for image enhancement can be represented as
whereY∈R3×H×Wis a trainable matrix rather than a single value. In the fine-grained residual generation,an attention-aware recursive network is proposed to generate fine residuals, and it is composed of three components. In the first component, the fully multiscale block (FMSB) aims to extract multi-scale primary features. ByN-step recursions in the recursive block, deep feature representations can be exploited.Finally, the reconstruction component converts the deep features to residual image. The generated residual image will be added with the adjusted image for getting the final enhanced image. In network training, three losses, i. e. MSE loss, dynamic multilevel perceptual loss (DPL) and adversarial loss are utilized.
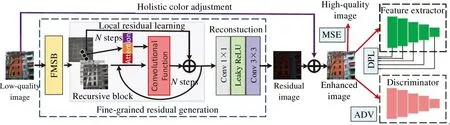
Fig.1 Framework of the proposed method (the holistic color adjustment globally adjusts low-quality image,so the fine-grained residual generation tends to generate elaborate details. FMSB denotes fully multi-scale block, and ⊕denotes element-wise addition.DPL denotes dynamic multi-level perceptual loss, and ADV is adversarial loss)
2.2 Holistic color adjustment


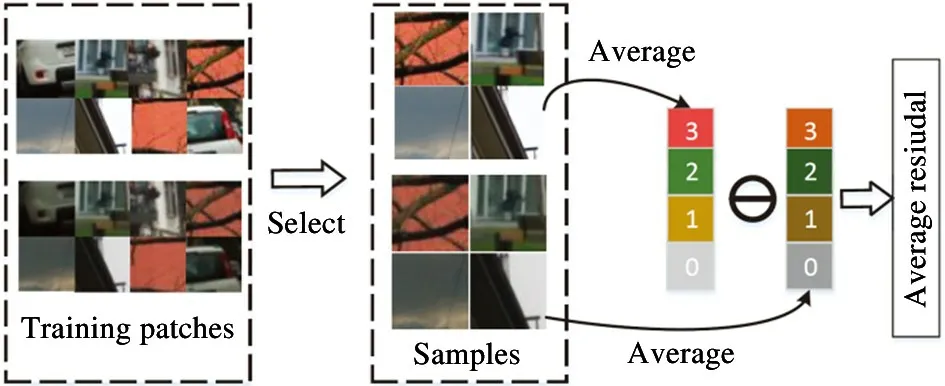
Fig.2 Flow diagram of average residual computation


2.3 Fine-grained residual generation
Fully multi-scale block. The success of inception network[4]has shown that the multi-scale information can provide multiple views to detect one image.So, the extracted features can benefit final image reconstruction. Motivated by Ref.[4], a fully multiscale block is designed to extract primary features. It is composed of two multi-scale convolutional layers and a compressive layer, as shown in Fig.3. In the first layer, convolutional kernels are adopted with three sizesW(1)i×i(i∈{1,3,5}) to extract multi-scale features, in which PReLU is selected as activation functions[19].Each convolutional kernel introduces all multi-scale features from the first layer, which utilizes features extracted by three kinds of receptive field. While the conventional multi-scale block only utilizes one kind of receptive field. Thus,FMSB can obtain more abundant information from the first layer to bring diversity representation. Finally, 1 ×1 convolutional kernel is used to compress feature maps and perform non-linear mapping.
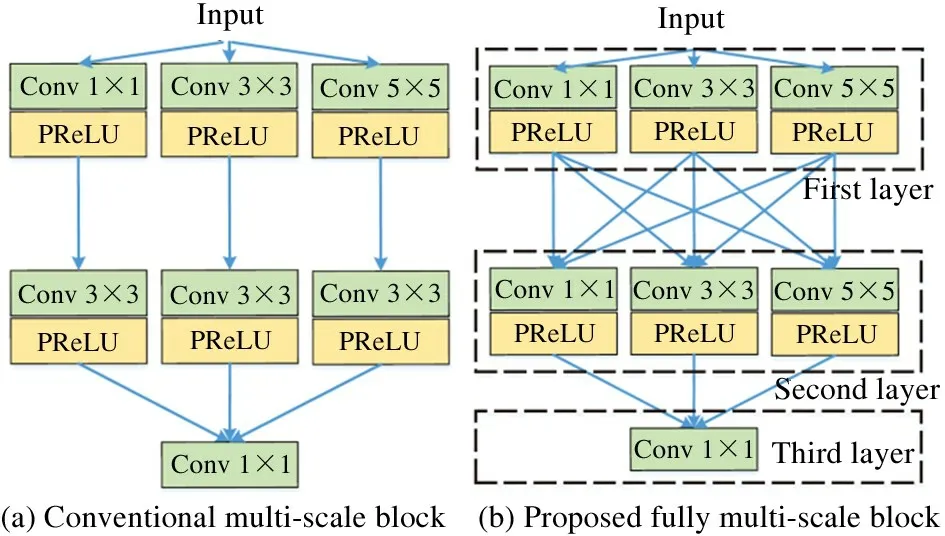
Fig.3 Comparison of the proposed fully multi-scaleblock against the conventional multi-scale block
Recursive block. Recently, residual recursive structures are proposed and show promising performance in super-resolution tasks[9].It can construct large receptive fields by reusing convolutional layers. However, a well-behaved image enhancement model should flexibly consider different input conditions (light and color etc.), and feature representations in conventional recursive structures are limited due to parameters sharing. So some dynamic factors are introduced in this structure by adaptively selecting appropriate channels according to input images. Based on this motivation,attention mechanisms are employed[20]and three kinds of attention-aware recursive units are built.
Design of recursive units. A recursive block consists of multiple recursive units. Fig.4(a) shows a typical recursive structure proposed in Ref.[8], which has no attention mechanism. In this work, three kinds of attention based recursive units are designed to explore the effectiveness of dynamic factors in different weighting scope. Their architectures are listed in Fig.4(b), (c), and (d). Fig.4(b) is residual recursive attentive unit (RRAU), which aims to effectively extract local discriminative features via directly weighting the convolutional features of the input imageX.Fig.4(c) is attentive residual recursive unit (ARRU), which aims to adaptively select global recursive features via weighting the residual recursive representations. Fig.4(d) is residual attentive recursive unit(RARU), which aims to enhance the mutual information between convolutional features and inputs via second-order residual attentive weighting. According to the experiments, RARU is more appropriate for image enhancement task. Hence, RARU is used in block construction. Double 3 ×3 convolution and ReLU are stacked to construct a convolutional function for convolving.
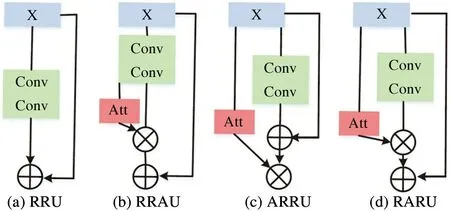
Fig.4 Four types of recursive units


The local residual learning is designated to always start fromX(0)for efficient and stable training[19]. Notably, due to the global non-identical residual learning can adjust the above-mentioned residual gap, local identical residual learning is normally adopted in the recursive block.
2.4 Dynamic multi-level perceptual loss
An individual MSE loss based optimization approaches usually lead to generating blurry and unrealistic results in image-to-image translation[16]. Inspired by Ref.[17], the generative adversarial nets (GANs)are considered. They are accomplished by utilizing an adversarial loss, which minimizes KL-divergence between the distribution of images produced by the generator and the distribution of images in the training dataset. An adversarial learning framework based on dynamic multi-level perceptual loss is proposed, which mainly contains a attention-aware recursive generator,a pre-trained VGG-19-based feature extractor, and a CNN-based discriminator. Specially, the feature extractor and the discriminator are used as two constraints to optimize the enhanced images generated by the generator from low-quality images. Among them, the feature extractor provides dynamic multi-level perceptual loss of hierarchical content, and the discriminator provides the measure of similarity between the generated images and corresponding ground-truths.
The feature extractor can provide perceptual loss based on content error between enhanced images and their high-quality versions. However, conventional GAN based methods for image enhancement usually optimize high-level perceptual loss, losing accuracy in color representations. Based on the motivation that optimizing high-level perceptual loss is beneficial for recovering spatial and texture information, and optimizing low-level perceptual loss is helpful for color reconstruction[9], hierarchical features are utilized, which are widely applied to classification[21]and detection[22]tasks. Instead of solely optimizing high-level content loss, five content losses are optimized from the output of each max-pooling layer cooperatively. In this way,the generated patches tend to be more consistent with human perception. The overall formulation of the multi-level perceptual loss is

However, the weightaiis usually hard to design due to uncertainty of the importance of each level perceptual loss. Although equally allocating weights is an intuitive way, but the importance of each level perceptual loss is also dynamic with training process. Hence,a weightaican be computed via a dynamic way based on error feedback ideology. Firstly, theith average content errorzibetween generated patchesPGand highquality patchesPHis computed. Then the weightaiis gotten via a softmax function for normalizing those errorszi:

3 Experiments
3.1 Dataset and metrics
Following Ref.[17], the classic DSLR enhancement dataset (DPED) is adopted to train and test the method. The DSLR is specially collected for image enhancement tasks. The image quadruples in DSLR are captured by cameras with different qualities. Detailedly, DPED contains 4549 photos from Sony smartphone,5727 photos from iPhone, and 6015 photos from Canon. The peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) index are two prevailing criteria selected for evaluations. In the experiments, PSNR and SSIM are all calculated on RGB space. In ablation studies, the most challenging iPhone dataset[25]is selected to conduct validation and 400 pairs of patches for testing are randomly selected. Without loss of generality, NRL is optimized by MSE loss. The detailed settings are introduced in next section.
3.2 Ablation study for network architectures
Fully multi-scale block (FMSB) can better extract features compared with conventional multi-scale block (MSB).Other three methods are compared:(1)double convolutional layer with 3 ×3 kernel size (Conv-3); (2) a large convolutional layer with 9 ×9 kernel size (Conv9); (3) multi-scale block (MSB) as shown in Fig.4; (4) fully multi-scale block, in which the second convolutional layers are all 3 ×3 (FMSB-3). In line with the settings in Ref.[12], ResNet is used as backbone network. As shown in Table 1,FMSB achieves the highest scores both in PSNR and SSIM and it is 0.04 dB PSNR and 0.0025 SSIM higher than MSB.

Table 1 Results of different blocks on the iPhone dataset
It demonstrates the superiority of FMSB. Conv3 and Conv9, large kernel size tends to achieve higher SSIM but low PSNR. FMSB-3 gains a very close PSNR to FMSB, but FMSB has different sizes of kernel in the second layer, which can better exploit holistic color information. In summary, the proposed FMSB is an effective block for primary feature extraction.
To verify the effectiveness of the attention along with recursive architectures, a comparison for different designs is shown in Fig.4. Besides, RRU+A is introduced which adds single attention mechanism in the last recursive step. Without loss of generality, PSNR is compared for verifying modeling capability in 1,3,6,12,24 recursive steps (Nsteps). Experimental results are listed in Table 2.
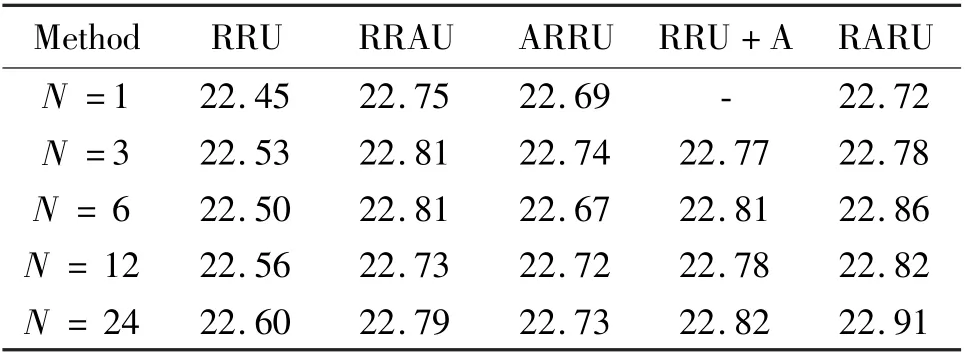
Table 2 PSNR results of different recursive steps
It can be seen that except forN=1 andN=3,RARU achieves the best performance compared with the others. FromN=6 toN=12, it can be seen that simply increasing recursive steps sometimes can decrease performance. Especially, RRAU degrades performance withNincreasing. It can be seen that the setting of 6-step recursions is cost-effective. The 6-step RARU achieves promising performance meanwhile has less recursive steps. It outperforms RRU, RRAU and ARRU by 0. 36, 0. 05, and 0. 05 dB PSNR, respectively.Training curves are exhibited in the condition of 6-step recursions in Fig.5. The pink curve is conventional ResNet structure as illustrated in Ref.[17]. It can get similar results before 20 epochs. While RARU can stably increase PSNR, resulting in the best performance. Therefore, RARU is considered as the final structure.
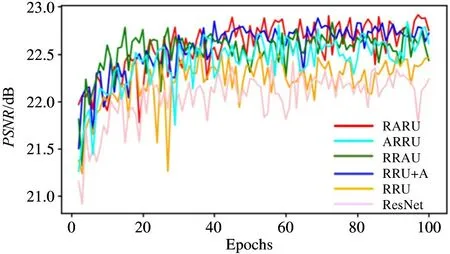
Fig.5 PSNR testing results with different recursive structures
3.3 Evaluation for non-identical residual learning
For evaluating the non-identical residual learning(denoted as RL), three control group are set, i.e. residual learning is not utilized in the holistic color adjustment (denote as no-RL), conventional residual learning, incomplete non-identical residual learning as illustrated in Eq.(6) (denoted as NRL-). Experimental results are shown in Table 3. Compared with no-RL and RL, RL outperforms no-RL by 0.47 dB PSNR and 0. 0097 SSIM on the iPhone dataset. The advantage of residual learning is clearly demonstrated.The performance of NRL- is slightly lower than RL,because some pixels cannot be accurately adjusted.While the NRL achieves the best performance, it outperforms RL by 0.09 dB PSNR and 0.013 SSIM on the Sony dataset,respectively. Although both RL and NRL achieve identical PSNR value (22. 54 dB) on the BlackBerry dataset,NRL precedes RL by 0.0027 SSIM,showing the effectiveness of NRL. The training curve of RL and NRL are visualized in Fig.6. It can be seen that the NRL lines are higher than the RL lines in the most conditions. Though both RL and NRL cause unstable PSNR curves on the Sony dataset, the NRL is still higher than RL in some peak values. Conclusively, the non-identical residual learning is an effective method, which is superior to conventional residual learning in the image enhancement task.
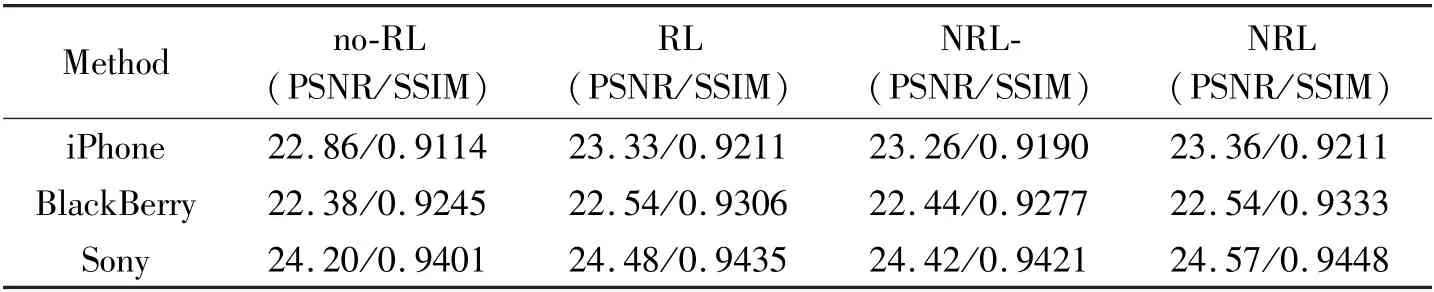
Table 3 Experimental results of residual learning
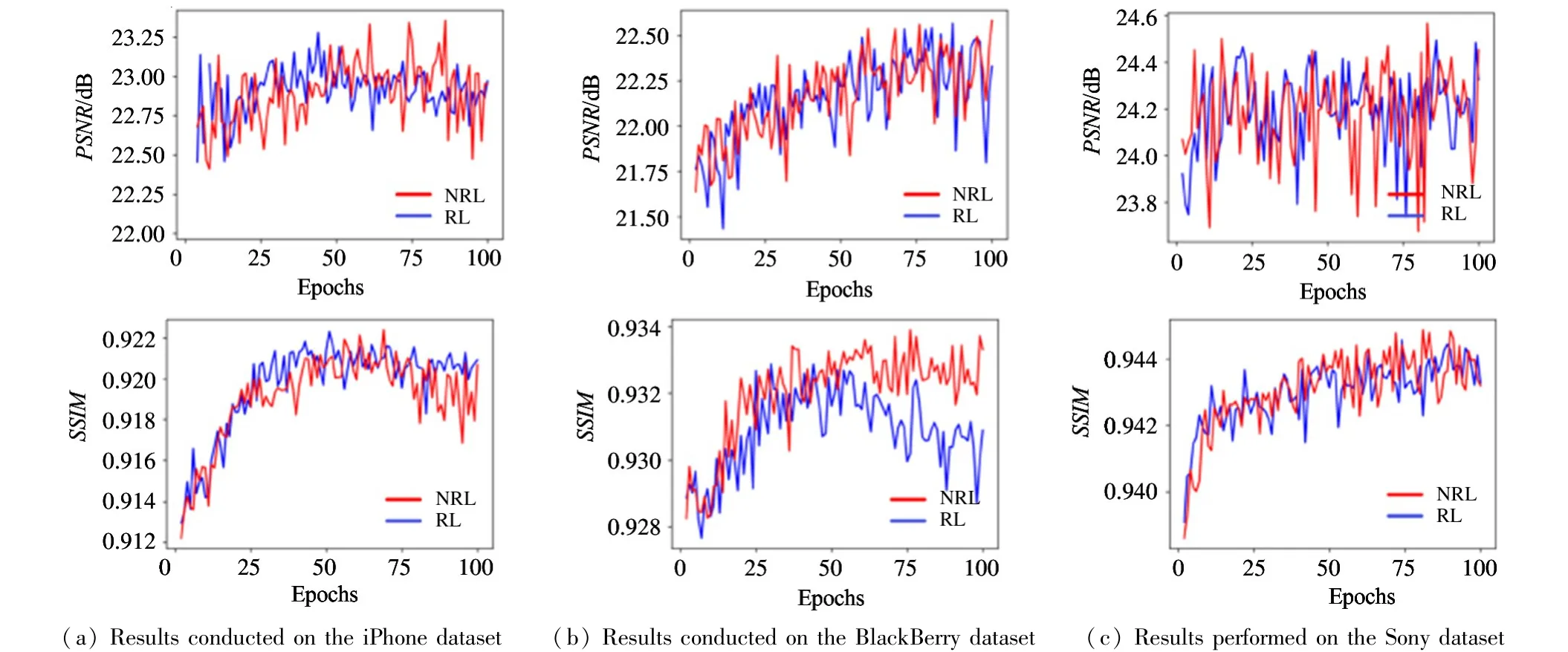
Fig.6 Comparisons of non-identical residual learning and conventional residual learning with N=6
3.4 Comparisons with state-of-the-art methods
The proposed method is compared with the stateof-the-art methods (Apple photo enhancer (APE) is taken as a baseline). Ref.[23] was a 3-layer CNN and was optimized by MSE. Ref.[9] was classical image-to-image translation method based on perceptual losses. Refs[17,24] were all state-of-the-art enhancement methods. Ref.[25] was an adversarial learning framework and its generator is replaced by the attention-aware recursive network for fair comparison. NRL denotes the non-identical residual learning framework optimized by individual MSE loss. Besides, NRL is introduced with the proposed dynamic multi-level perceptual loss (denotes as NRL-DPL). Experimental results are shown in Table 4, where NRL-DPL achieves the highest SSIM among all others. Concretely, NRL-DPL outperforms by 0.0072[17]and 0.0046[24]SSIM on the iPhone dataset, respectively. It also outperforms by 3.82 dB[23]and 1.14 dB[25]PSNR on the Sony dataset, respectively. It demonstrates the state-of-the-art performance of the method for image enhancement.NRL also achieves favourable PSNR results compared with others. It reveals the strong generalization ability of the network architecture. NRL-DPL outperforms NRL except for PNSR on the BlackBerry dataset, showing superiority of the proposed DPL and adversarial learning strategy. According to Fig.7, the method achieves better visual effect and less unpleasant artifacts. In the first group comparison, the bag can be enhanced more distinctly by the method.

Table 4 Comparisons with the state-of-the-art methods in PSNR/SSIM

Fig.7 Examples of visual enhancement comparisons on DPED
In the second group, the edges of the window has less artifacts compared with Ref.[17]. In the last group, the method achieves a very high-quality result both in overall and local details. Notably, the model has only 190 ×103parameters compared with 400 ×103in Ref.[17]; it also demonstrates the advantage of the proposed recursive architecture.
The proposed framework is trained with 6 recursive steps without batch normalization (BN). All channel numbers are set to 64 in the recursive block.1/6 patches are randomly selected in training dataset as one epoch. The Adam is adopted for optimizing the network, and the initial learning rate is set to 0.0005.Training batch is set to 32. For each 5 epochs, the learning rate will decrease by the scale of 0.95. Training is stopped at 100 epoch. Experiments are performed on double NVIDIA Titan XP GPUs for training and testing. The training process costs about 14 h for 100 epochs,and the average testing speed of a 256 ×256 patch is 0.04 s.
3.5 User study
Previous classical work are followed to perform mean opinion score (MOS) tests, which quantify the ability of different approaches to re-construct perceptually convincing images. 100 low-quality images are selected from VOC2012 (VOC2012-LQ100) for testing.Specifically, 29 raters are asked for assigning an integral score from 1 (bad quality) to 5 (excellent quality). The score criterion is four-fold:Color(Col),Texture (Tex), Luminance (Lumin), Overall (Over).Four methods are evaluated,i.e.,Ref.[17], Ref.[23],Ref.[25] and the method NRL-DPL. They are all trained on the iPhone dataset for evaluating their adaptability. According to results in Table 5, the proposed method achieves the highest average MOS scores. Although Ref.[17] achieved the highest luminance score, it causes many harsh textures. Overall, the method performs the best scores in color, texture and overall feeling.
Fig.8 shows some visual examples. Apparently,the enhanced images obtained by the method have more perceptual comfortableness and textural softness.
4 Conclusions
In this paper, a non-identical residual learning for image enhancement via dynamic multi-level perceptualloss is proposed, which views image enhancement as two branches. In the first branch, a holistic color adjustment method is designed to adjust global color representation to the high-qualities. It forces the second branch to accurately capture color and texture details by learning elaborate difference. In the second branch,an attention-aware recursive network is proposed to adaptively transform features according to image color conditions, as well as mitigate overfitting problem. Last but not least, a dynamic multi-level content loss is designed to improve color effect as high-quality images.Extensive experiments conducted on publicly available datasets demonstrate the state-of-the-art performance of the proposed method.
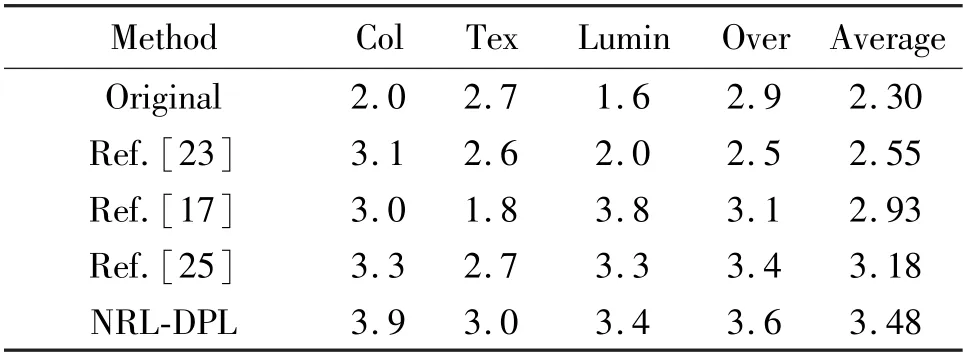
Table 5 MOS testing results on VOC2012-LQ100

Fig.8 The selected visual demonstration on VOC2012-LQ100
杂志排行

High Technology Letters的其它文章
- Directional nearest neighbor query method for specified geographical direction space based on Voronoi diagram①
- A multispectral image compression and encryption algorithm based on tensor decomposition and chaos①
- Analysis of fluid vibration transfer path and parameter sensitivity of swash plate axial piston pump①
- SAR image despeckling via Lp norm regularization①
- Channel attention based wavelet cascaded network for image super-resolution①
- A correlation OPTS algorithm for reducing peak to average power ratio of FBMC-OQAM systems①