基于中心差分卷积的自监督学习方法研究
2022-07-06仝卫国李芝翔翟永杰
仝卫国,李芝翔,翟永杰,侯 哲
(华北电力大学 控制与计算机工程学院,河北 保定 071003)
卷积神经网络[1](convolutional neural network,简称CNN)以其强大的特征学习能力被广泛应用于计算机视觉的多个分支,例如目标检测[2]、语义分割[3]、图像描述[4]等.
CNN在计算机视觉任务中的表现取决于两个因素:一个是模型本身的表达能力或容量,另一个是训练数据集的规模,然而无论是数据的收集还是标注都是一项费时费力的工作.以ImageNet为例,目前ImageNet中总共有14 197 122幅图像,分为27大类,21 841个小类,每一张都需要手工去标注.对于检测和分割任务,不仅需要类别标签,还需要更为精细的位置信息.这样的数据集的收集和标注所花费的时间和精力是难以想象的.更重要的是,在许多现实场景中,收集如此大量的数据本身就是不现实的.与人类学习的过程不同,有监督学习需要大量有标签的数据来提升性能.而人之所以能在只有少量样本的情况下学习到有用的知识,是因为人拥有大量的先验知识.近期提出的自监督学习方法可以从无标签数据中学到更为本质的特征,从而在下游的分类和检测任务中仅使用少量有标签样本即可达到与有监督接近的水平,能有效缓解有监督学习对手工标注数据的依赖.自监督学习的本质是对于交互信息的提取,同样依赖于卷积神经网络进行特征提取.虽然有很多新的自监督学习的方法被提出,但还没有哪项工作针对不同卷积操作对自监督学习性能的影响做出探究.
论文将中心差分卷积神经网络[5](central difference convolutional network,简称CDCN)引入自监督学习.普通的卷积神经网络虽拥有强大的表达能力但更多地关注于深层的语义特征,在细节纹理的表达上有所不足,CDCN在保留强度信息的同时将梯度信息融入普通卷积操作中,能更好地捕捉细节纹理特征.因为不需要任何人工标注的数据,即使是非常大规模的数据集也可以用于自监督学习的训练.相比于其他方法,自监督学习思路简单却非常有效,在很多下游任务中,在只使用少量有标签数据的情况下达到与有监督学习接近的性能.这充分说明自监督学习学到的特征是有效的,并且还有很大的潜力可以发掘.
1 相关原理
1.1 自监督学习
自监督学习属于无监督学习的一个分支,早期的自监督学习方法通常需要通过一些预先设计好的前置任务[6]自动生成伪标签,然后通过CNN进行特征的学习.典型的前置任务有图像旋转预测[7]、图像修复[8]、拼图[9]等.自监督学习在不使用任何标注信息的情况下学习到有用的特征,并在ImageNet上取得了不错的成绩,但与有监督学习还有一定的差距.
图1为旋转预测原理框图.以旋转角度预测[7]为例,将原图分别旋转90,180,270°及包括原图在内总共4类作为输入,以对应的0,1,2,3作为伪标签进行训练,该方法在下游的检测任务中得到了54.4% mAP的成绩,仅比有监督情况下低2.4%.
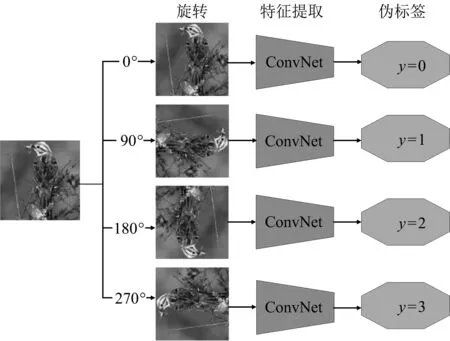
图1 旋转预测原理框图
近期,基于度量学习[10]和孪生神经网络的对比学习[6]成为自监督学习中的主流,并且取得了越来越接近有监督学习的性能指标,在性能上大大超过了之前的工作.文献[11]中使用ResNet-50在ImageNet上得到了74.3%的top-1准确率,在使用更大的ResNet时得到了79.6%的top-1准确率.
对比学习的目的是在尽可能地保留语义相关信息的同时丢弃低层噪声[12].随机采样N张图像,经过两种不同的数据增强方法产生N对图像,这里不特意挑选负样本,将由同一张源图像产生的图像对(xi,xj)作为正样本,其余2(N-1)张图像相对于xi或xj均为负样本.以sim(u,v)=uTv/(‖u‖*‖v‖)(余弦相似)衡量样本对之间的相似度,则正样本对(xi,xj)的损失函数定义为
(1)
其中:τ为待优化参数,在一个数量为N的批次中,li,j与lj,i都要被计算在内,因此总的损失函数定义为
(2)
1.2 中心差分卷积神经网络
图2为卷积操作示意图.一般的卷积神经网络的计算主要分为两步:在输入特征图x中采样一个局部感受野R,将权重与对应的特征值相乘然后求和,如图2上半部分所示.

图2 卷积操作示意图
输出特征图y可由下式得到
(3)
其中:p0为输入特征图x和输出特征图y当前的位置,pn为局部感受野R上的位置,w为对应权重参数.以3×3的卷积为例,R={(-1,-1),(-1,0),…,(0,1),(1,1)}.
受到局部二值化特征LBP(local binary pattern)[13]的启发,为了增强CNN对细节纹理的捕捉能力和模型的表达能力,文献[5]提出了一种新的卷积操作CDCN.与一般的卷积神经网络类似,如图2下半部分所示,CDCN同样有两步组成,计算过程可由式(4)表示
(4)
为了在考虑梯度信息的同时保留强度信息,将两种操作进行融合后如式(5)所示,θ的取值范围是0到1.同时为了方便实现,将式(5)进行变形得到式(6),在Pytorch上仅需要几行代码即可实现.
(5)
(6)
2 基于CDCN的自监督学习
基于CDCN的自监督学习算法包括网络模型训练与性能评估两个阶段.这里使用图像分类作为下游性能评估任务,整个过程包含以下几个步骤:①构建多种数据增强算法,随机使用其中两种构建正样本对;②使用无标签数据训练特征提取模型;③下游任务性能评估.
2.1 网络框架
网络框架的选择对算法性能有着重要的影响,根据文献[14]的研究,残差结构有助于模型保留更多有用信息防止学到的特征随着网络的加深而退化.因此论文选取Resnet18[15]作为主干网络,Resnet50[15]作为对比网络,并且根据式(6)将中心差分卷积融入主干网络以探究参数θ对网络性能的影响.图3为网络框架.
图3中f(·)即为特征提取网络,但与一般Resnet18不同,这里去掉了最后的全连接层并在后面加了一个非线性变换网络g(·).在最终的输出zi与zj上实现式(1)的对比损失,以yi和yj作为下游性能评估的输出特征.
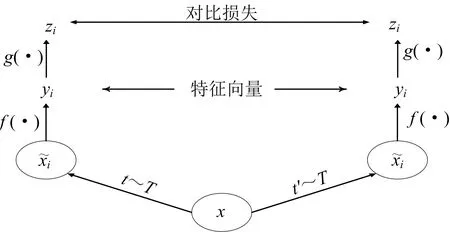
图3 网络框架
2.2 数据集STL-10
STL-10是一个专门为无监督学习而发展的图像分类数据集,包含10个类别、100 000张无标签图像、5 000张包含标签的训练集图像、8 000张测试集图像.图像均为96×96的RGB图像,整个数据集属于ImageNet的一个子集.图4为从数据集中抽取的一些示例.

图4 数据集示例
2.3 性能评估方法
与一般计算机视觉任务的性能评估不同,自监督学习需要将训练好的模型应用到一些下游任务中来检验学习到的特征的有效性[16].在图像分类性能评估任务中,自监督学习算法使用无标签数据训练,得到一个特征提取器.将有标签的训练集和测试集图像输入网络,得到对应的特征向量.然后利用训练集的特征向量和对应的标签训练一个逻辑回归模型,并在测试集上进行验证,以最后的分类准确率作为评价自监督学习的性能指标.
3 实验结果与分析
基于CDCN的自监督学习方法在单片的GTX1080Ti上进行训练,显存11 GB,操作系统为Ubuntu 16.04.12,使用Pytorch深度学习框架.
实验过程中使用100 000张无标签图像训练特征提取器,下游任务测试阶段包含5 000张训练集和8 000张测试集.以下游任务中的分类准确率作为衡量自监督学习方法效果的指标.实验首先探究了式 (6)中变量θ对最终分类效果的影响,并同未加入中心差分卷积的模型进行对比.在得到最佳的θ值之后与更大的残差网络Resnet50的分类效果进行了比较.
3.1 θ值对性能的影响
为了研究θ值对模型性能的影响,论文以0.1为单位间隔分别训练了θ值从0到1变化的总计11个模型,相关结果如表1所示.训练时,初始学习率为0.000 3,经过10轮迭代后学习率开始按余弦曲线变化,训练的批数量始终为512.
表1中统计了准确率、召回率和F1-score 3种评价指标,这里以准确率为主要评价指标.从表1可以看出,加入了CDCN的模型性能明显优于普通卷积网络模型,其中0.8为θ最优值,相对于θ值为0时的准确率提升了4.14%.另外,通过对比参数值为0(完全为普通卷积)和1(完全为中心差分卷积)的结果可以看出,中心差分卷积比普通卷积更加适用于自监督学习.
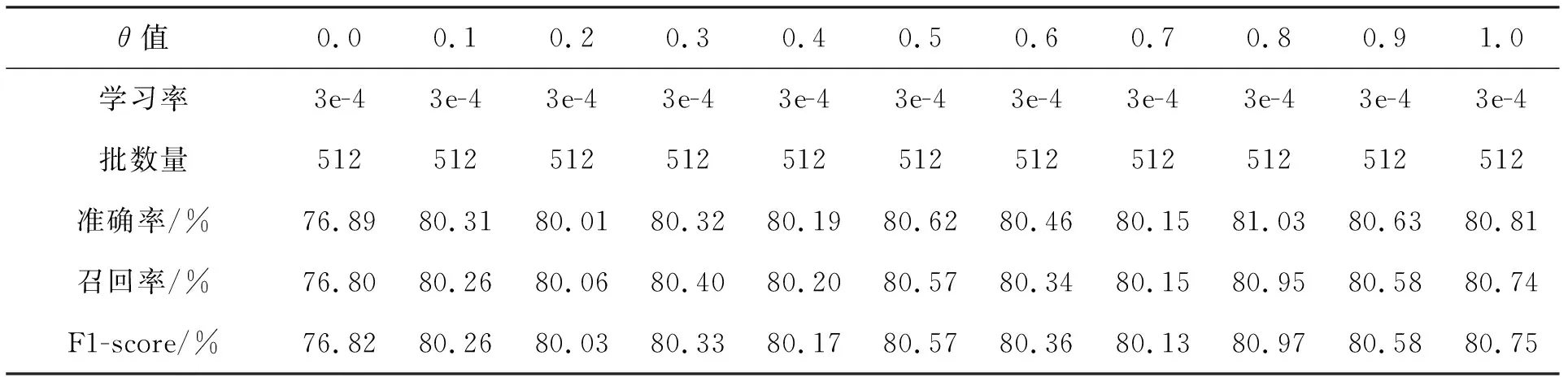
表1 不同θ值对模型性能的影响
3.2 不同模型的对比
论文使用Resnet50作为对照模型,表2为不同模型性能对比.从表2可以看出,在几乎不增加推理时间的情况下,加入了CDCN的模型训练时长更短,收敛更快,在准确率上比参数量更大的Resnet50提升了1.7%,这充分证明加入了CDCN的自监督学习所提取到的特征比普通自监督学习提取到的特征更加有效.图5为CDCN相对于普通卷积的性能提升.

表2 不同模型性能对比
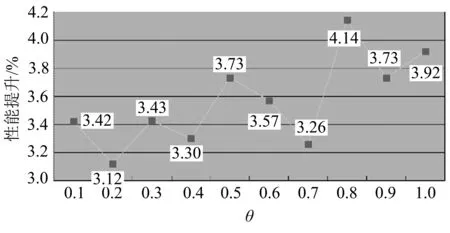
图5 CDCN相对于普通卷积的性能提升
4 结束语
论文将CDCN引入自监督学习,探究卷积操作对自监督学习性能的影响.相较于普通卷积操作CDCN,论文在保留强度信息的同时加入梯度纹理信息,对两种操作进行了融合,并对融合参数θ对算法性能的影响进行了研究.实验结果表明,中心差分卷积操作相较于普通的卷积操作更加适用于自监督学习.
