自主导航地图的昨天、今天和明天
2022-07-05孟立秋
孟立秋
慕尼黑工业大学制图和可视分析系,德国 慕尼黑 80333
1 无人驾驶技术的演化背景
人类关于无人驾驶的梦想已有近百年的历史。20世纪20年代美国的街头出现过无人驾驶的“幽灵汽车”[1],其方向盘、刹车和鸣笛功能由紧随其后的车里的人通过敲击电报键遥控激活。无人驾驶的实质性研究始于20世纪80年代,主要依靠计算机视觉和全球定位技术实现环境感知和安全导航。美国卡内基梅隆大学率先研制概念车系列Navlab,其中的Navlab 5在1995年从匹兹堡开往圣地亚哥4587 km的路程中,以大约97 km的平均时速自主导航,98%以上的距离无须人类接管。同一时期,德国慕尼黑联邦军大学和奔驰集团启动了“普罗米修斯”(PROMETHEUS)项目,其概念车VaMP于1995年从慕尼黑开往丹麦的欧登塞,1758 km的行程中95%的时间里自主导航,在德国高速公路上达到175 km以上的时速。在既无物联网也缺乏自动驾驶交通法规的情况下,Navlab 5和VaMP这两款无人驾驶先驱车由于计算成本过于昂贵而无法量产,但它们向世人展示了梦想成真的可行性途径。
近10余年,传感器技术和机器学习算法的不断进步以及训练数据的激增将无人驾驶的研究推向了一个新的高潮。从人类驾驶到无人驾驶的转变过程中,围绕汽车内燃机技术的竞争变成了围绕数据和人工智能技术的竞争。起主导作用的不再是传统车商,而是以谷歌、特斯拉和优步等为代表的硅谷车商。无人驾驶车更像是一台带轮子的超级计算机,每分钟可以产生超过一千兆字节的数据流,数据处理软件决定着无人驾驶车的核心价值。在数据驱动软件,软件驱动轮子的过程中,自主导航地图扮演着不可或缺的指挥员角色。
2 自主导航地图
2.1 概 念
无人驾驶车的自主导航地图称为HD map(high definition map)。正如高清电视HDTV(high definition television)比标准电视SDTV(standard definition television)呈现更清晰流畅的图像一样,HD map比普通导航地图具有更高的时空分辨率。根据目前的发展现状,HD map译为高精地图较妥。
事实上,高精地图是普通导航地图的颠覆性升级。高精地图的制作和使用同步并且实时进行;高精地图的内容以“此时此地”的动态驾驶环境为重点,但同时与“彼时彼地”的数据保持着互联;高精地图的详细程度接近1∶1的地面真实模型,是驾驶环境的一个不折不扣的数字孪生体;高精地图的制作者和使用者都是机器而不是人类;最后也是最重要的是,高精地图为无人驾驶车提供的服务不仅仅是导航支持,而是导航决策本身。
2.2 高精地图的内容构成和数据来源
高精地图在逻辑上由“此时此地”驾驶环境的动态导航地图层和“彼时彼地”的先验导航地图层集成而来。动态图层如同一个约为2×2 km2的移动窗口,而支撑这个移动窗口的先验图层则如同一个突破时空限制的超级传感器,代表着车联网的共同记忆和知识,其内容包括相对静态的三维机动车辆路网信息,路面或路侧交通标记和地标的位置和语义属性,交通统计信息和路段交通规则。图1比较了机动车路网和通过融合交通信息和规则生成的导航地图。欧洲开放地理空间联盟的三维城市模型标准CityGML对路网有车道级的详细定义,如图2所示。
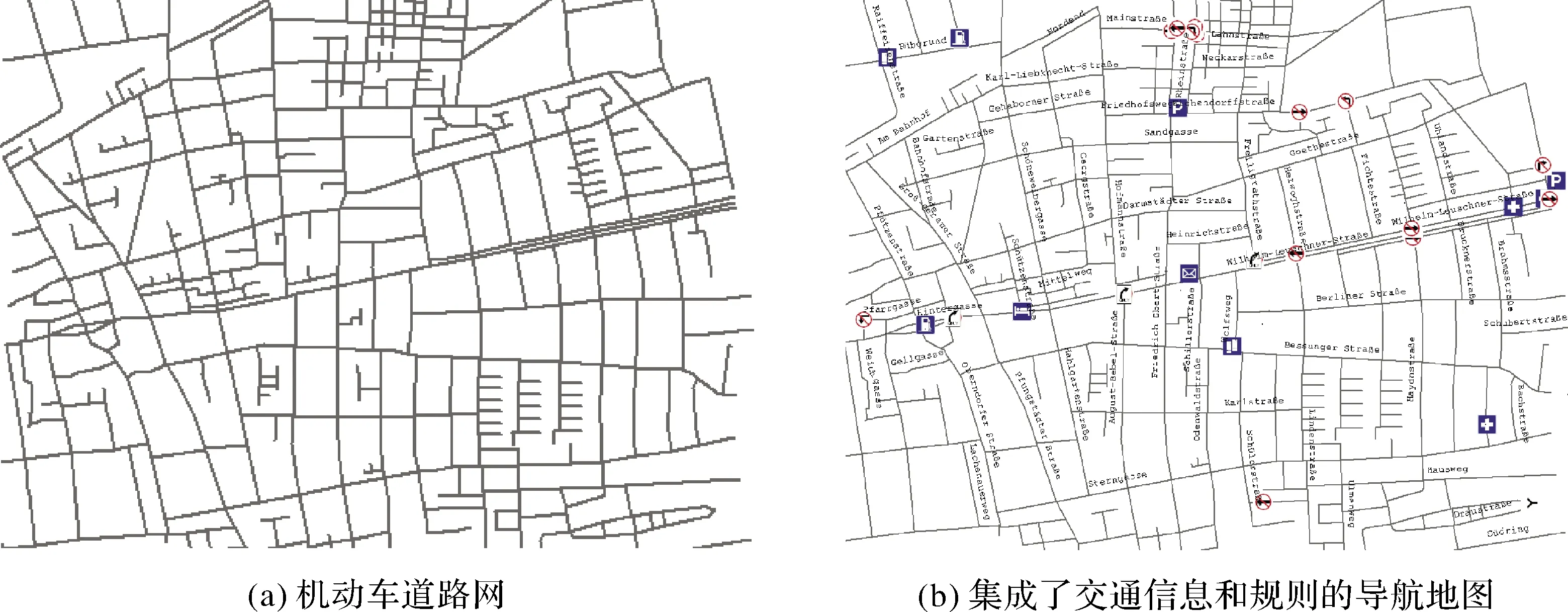
图1 机动车路网和导航地图[2]

图2 CityGML对车道级路网的标准定义(来源: Rheinmetall Defence Electronics)[3]
动态图层的数据主要来自车载传感器的实时观测信号。车身外围配备的测绘传感器包括摄像头、激光雷达、超声波、全球导航卫星系统接收器和惯性测量单元等,它们以互补和部分冗余的方式记录三维移动场景的360°视图及相对和绝对位置。传感器的输出以点云和影像为主,它们经过融合、同步定位与制图等处理生成驾驶场景的三维模型,包括车辆的行驶轨迹、路面及路上边长精确到大约5 cm的二维和三维矢量对象。这些矢量对象通过计算机视觉、统计分级分类、启发式算法等机器学习方法进一步转化成为驾驶环境中各类有意义的地物要素,如车道边界线、路标、行人和其他车辆等。此外,路端或车联网中其他固定的和移动的传感器(如图3所示)通过云服务平台实时发送当前和未来一段时间内的交通场景和安全移动信息,比如:拥堵情况、施工区域、滑坡风险以及天气变化造成的路面能见度和摩擦系数的变化等,这些语义信息有助于机器更有效地学习和提取与安全驾驶有关的地标和障碍物信息。先验图层对动态图层的构建也起着交叉验证、缩小传感器盲区的作用,为机器学习提供标记信息和路径规划等服务,图4所示为TomTom的云端和先验图层的信息。

图3 固定和移动的传感器(来源:亮道智能公司)

图4 TomTom的云端和先验图层信息(来源:www.tomtom.com/products/virtual-horizon)
动态图层的内容可以根据时空精度、对安全驾驶的重要性、是否需要与其他车辆共享等要求进一步细分成多个逻辑层。场景驱动的交通规则位于顶层,用于生成导航指令,如加速、车道切换、超车、刹车等。
3 高精制图流程的主要模块
采集和更新覆盖大区域乃至全球路网的高精地图数据是个代价昂贵且无法一劳永逸的任务。为此互联网平台企业、车企、导航地图生产商、人工智能研究机构和IT公司根据各自的优势和特点围绕4个主要模块展开了形式多样的竞争和合作——先验图层的数据采集和更新,动态图层的实时构建,边缘计算,数据压缩和标准化服务。
3.1 先验图层的数据采集和更新
电子导航地图商,比如,TomTom、HERE、四维图新、高德、百度等,拥有丰富的普通导航地图数据和跨境合作的先发优势,有实力组织专业测绘车队,构建和更新覆盖大区域,特别是高速公路和城市快速路的先验图层。大型车企则具有量产车的优势,每一辆新车都可装配高端或普通传感器,用作为数据采集车,以专业测绘和众包相结合的方式在全球范围内采集和共享路网的变化数据。因此,导航地图商和大型车企的强强合作很常见。比如,2015年被奔驰、宝马、奥迪联合收购的HERE把来自资源卫星、飞机和无人机等的对地观测数据和来自量产车辆和手机等的众包数据相结合,建立全球覆盖的先验图层。HERE倡议创建了OneMap联盟和全球开放平台,旨在为无人驾驶车提供跨区域的、标准化的并不断“自我修复”的高精地图产品和服务[4]。TomTom则与沃尔沃和大众集团等合作,利用车载的多个激光扫描仪、摄像头、雷达和定位天线等获取路况信息,也利用已有的导航地图数据进行交叉验证,从而更新和丰富高精地图先验图层与安全导航相关的语义信息[5]。
互补合作的方式更常见,比如丰田集团通过安装有摄像头的测绘车辆收集诸如东京市和纽约市的复杂城市道路图像和视频,其并购的高精地图公司CARMERA则负责实时处理原始数据,和已有的导航地图数据及卫星图像进行对比,提取几何误差50 cm以下的路况变化数据[6]。人工智能计算公司Nvidia利用车载传感器众包收集驾驶数据,其收购的高精制图公司DeepMap则根据这些数据开发适合高速公路和城市道路上大多数驾驶场景的图层。宝马集团的测绘车队和客户车队在慕尼黑和上海的测试区采集了数亿千米的驾驶数据,其合作伙伴DXC技术公司则利用深度学习方法快速分析和识别有意义的驾驶场景,从中提取安全导航规则。同理,大众集团与微软合作,利用量产车队获取的驾驶数据加强对机器算法的训练[7]。四维图新除了用专业测绘车采集数据外,也实时收集和融合众包和车商的多源传感器数据,使高速公路及城市快速路的绝对和相对几何误差分别达到了50 cm和10 cm以内。百度地图收购长地万方,利用图像识别和文字识别等方法处理路况数据,其先验图层包括相对误差10 cm内的车道位置,路口表达和停车位等语义信息[8]。
一些企业利用专长满足市场的特殊需求,比如,Atlatec公司使用立体相机、全球定位接收器和惯性测量单元在复杂路网的每条车道上反复行驶,从多个轨迹中自动提取车道位置。该公司在全球数千千米的车道轨迹中,95%实现了误差小于3 cm的整体精度[9]。宽凳科技也利用摄像头相对于激光雷达的成本优势,通过人工智能技术提高数据处理速度和数据的更新频率,从而带动空间精度,将几何误差控制在20 cm以内[10]。亮道智能公司则以车载激光雷达为核心传感器,发挥硬件和软件的组合优势,开发全栈式路侧感知、数据融合和驾驶场景自动识别系统(www.liangdao.ai)。
3.2 动态图层的实时构建
动态图层的数据采集和融合需要强大的计算功能和数据传输效率。比如,特斯拉利用多个摄像头和车身雷达获取驾驶场景内的图像和距离数据,上传给本公司的Dojo超级计算机,在数据流的持续训练下使人工智能算法得到升级,实现对三维场景实时建模和地物识别,降低对先验图层的依赖作用[11]。Mobileye将其摄像头系统安装在多种车型上,遍布不同国家和地区的大多数主干道,主要采集路面和路标数据,以每千米不到1万字节的小数据打包上传给云端,利用软件将大量次精数据融合成高精数据,用于持续更新和扩展先验图层,使任何路段不仅实现10 cm级的相对几何精度,还含有司机的动态驾驶行为及当地交通规则等信息(www.mobileye.com/our-technology/rem),这种低成本硬件和高性能软件相结合的方式已成为构建动态图层的最佳实践。
3.3 边缘计算
无人驾驶车置身于动态图层的中心,同时也是车联网中的一个边缘节点,如同戍边的战士直面各种风险,车内具备一定的边缘计算能力,以便在网络信号不畅的情况下仍具备基本的导航功能。比如,Civil Maps公司在一个基于传感器实时融合、6个自由度实时定位等边缘计算的平台上,开发了轻量化手迹底图(fingerprint base map),绝对和相对精度误差分别达到15~20 cm和1~5 cm以内[12]。手迹底图利用前后两辆车生成,第一辆作为参考车生成基于体素的手迹基准图(图5(a)所示的绿色网格及菱形点),每一个体素对应于驾驶场景中有意义的地物或地标特征点,相比传感器生成的点云(图5(b)),手迹底图上的体素稀疏得多,每千米的数据量只有10~30万字节,既便于存入云端,也便于通过普通的3G和4G网络迅速下载。第二辆作为查询车在行驶中用同样的方法生成驾驶场景的体素(图5(c)所示的蓝色菱形点),利用边缘计算和基准图中的体素进行实时匹配(图5(d)),当有足够多的体素匹配成功时(图5(c)所示的橙色菱形点),绿色和蓝色网格之间实现配准,从而实现查询车的定位,手迹底图内容也可得到相应的更新。

图5 手迹底图(来源:https:∥youtu.be/JOLzVoYq7cE)
3.4 数据标准化和压缩服务
高精制图流程始终面临两个压力:一是如何提高数据的共享效率;二是如何提高数据的存储、计算和传输效率。除了对计算设备和网络基础设施进行系统升级外,提供数据的标准化和压缩服务也是缓解压力的有效途径。企业为了保持竞争优势,对于共享数据有所保留,但统一高精地图的存储格式和数据模型已成为共识,这有助于降低专业测绘和众包测绘的成本,为实现未来跨品牌车辆的大规模数据共享和维护奠定基础。
德国的导航数据标准协会(Navigation Data Standard Association)为高精地图制定了包括导航数据模型、存储格式、接口和协议的标准规范NDS,并与3个主要操作系统Windows、macOS、Linux兼容。NDS确保了高精地图在全球范围内以统一的数据格式存储访问、互操作和更新。导航数据标准协会的成员包括车企、地图商和导航设备生产商。不同的国家和地区也可对NDS进行调整,以符合当地的规定。
德国的自动化和测量系统标准化协会ASAM(The Association for Standardization of Automation and Measuring Systems),则发布了一系列开放标准,包括静态道路网描述OpenDRIVE,静态路面描述OpenCRG和动态场景描述OpenSCENARIO。这些ASAM标准是基于其他公共标准,如UML、XML和CORBA建立的,因此独立于特定的信息技术和平台,不仅方便车商、供应商和工程服务商之间相互验证无人驾驶功能,还允许用户根据地区特点和政策特点作必要的调整和优化。
德国卡尔斯鲁厄理工学院主导启动了“KIsSME”研究项目,采用人工智能方法从无人驾驶测试场地的数据以及模拟数据中自动剔除无关的数据,提取有重要意义的驾驶场景,用ASAM标准格式存储,并提供场景选择工具(kissme-projekt.de)。Bertrandt集团也致力于将纷杂的大数据转化为智能小数据,采用数据挖掘方法,从传感数据中自动识别和标记对安全驾驶相关程度最高的移动对象,用ASAM标准格式存储相应的驾驶场景,并提供自动标签工具“Bertrandt Data Labeler”(www.bertrandt.com/#gref)。
4 高精制图技术面临的疑难问题
将所有交通规则集成在高精地图中还远远不能满足自主导航的安全性要求。数量有限的交通规则在不断变化的驾驶场景中可以产生出不计其数的组合方式。每一个具体场景都是无人驾驶车和其他交通对象之间互动的社会技术系统。交通对象的种类越多,互动关系就越复杂。在没有交通标志的路口,人类除了交通规则以外,往往依靠司机之间,司机和行人之间的各种眼神和手势沟通各自的意图,达成默契,自组织地安全通行。相比之下,高精地图只能依赖已有的交通规则生成导航指令,使无人驾驶车的行为有点像新手,缺乏随机应变能力,比如刹车过于突然,从而造成被其他车辆追尾的事故。高精地图的安全导航决策面临4个方面的疑难问题:①复杂驾驶环境的自动建模;②边角案例的数据获取;③伦理困境中的导航决策;④无人驾驶技术的安全性能评估。下面依次介绍和总结研究现状。
4.1 复杂驾驶环境的自动建模
复杂驾驶环境可以视为无人驾驶车、人类驾驶车和车外行人这三大类交通对象的共享空间,目前流行的方法是把它分解成3个相对简单的子空间分别建模:①无人驾驶车的专用空间;②无人驾驶车和人类驾驶车的共享空间;③无人驾驶车和行人的共享空间。
4.1.1 无人驾驶车之间的交互
无人驾驶车在准入公共道路之前需要经过特殊场地的测试,但小规模或使用时间有限的测试场地往往只能展示少量的场景,难以遍历自动驾驶功能。为此,美国密歇根州正在筹建世界上第一条大规模无人驾驶车专用廊道,长约65 km。该道路的物理基础设施将配置便于机器迅速识别的导航标记,并且对应一个互联的数字走廊[13]。建设这样的廊道尽管代价昂贵,但研究者可以深入了解无人驾驶车在各种场景里的交互行为和学习能力,为未来扩建无人驾驶友好型道路基础设施提供宝贵的经验。
4.1.2 无人驾驶车和人类驾驶车的交互
无人驾驶车和人类驾驶车共享的子空间主要是高速公路和各种封闭式快速道。无人驾驶车在这个子空间的操作,如车道切换、变速、高速路进出、切入等,都可描述为一个受交通规则约束的事件模型,每一个事件由一个或多个原因引发,造成车辆间相对位置和拓扑关系的变化,事件结束后,车辆间达到新的动态平衡。深度学习方法和知识图谱已广泛应用于识别和描述车辆轨迹数据中的交通事件及其前因后果,经过大数据训练的事件模型可进一步用来预测驾驶场景中每一辆车下一个时刻的移动行为。比如,Woven Planet Level 5建立了一个基于代理的行为预测平台并提供一系列开放轨迹数据,便于用户分析不同场景下车辆的运动规律(https:∥level-5.global/data/prediction)。
4.1.3 无人驾驶车和行人的交互
无人驾驶车和行人的共享子空间可进一步分为车道上的共享空间(比如马路上的人行横道)和非车道上的共享空间(比如允许送货车辆进入的步行区)。无人驾驶车和行人安全互动的研究尚处探索阶段,面临两个挑战:一是这类互动模型必须在感知、识别和轨迹跟踪的初级模型基础上增加心理和社会理解模型;二是有实用意义的车辆和行人的互动模型往往针对相对拥挤的城市驾驶环境。目前,从这种环境采集的原始数据,特别是带有标记的训练数据既不充足,也不均衡。
欧盟地平线2020框架计划下的interACT项目综合介绍和分析了行人行为预测模型的基础研究现状和发展趋势[14]。目前已有的理论模型包括:行人的行为特征模型(比如注意力集中程度,过马路的步态和速度);行人的类别特征模型(比如上班族,残疾人,性别,年龄等);目的地已知或未知情况下的单个行人的轨迹预测模型(比如过马路的意图);基于速度、加速度、步态等变量的行人之间的时空相关性和互动决策模型(比如疏散行为);基于交通信号灯的变化次序、车辆状态、人群的密度、速度和方向等变量的群体行为预测模型(比如过马路的行人数量,人群在不同的时间空隙里过马路的概率等);无人驾驶车和行人之间基于博弈论(game theory)、空间行为理论(proxemics)及信号交互理论(signalling interaction)的互动行为和预测模型。
不少人际交流方法可以移植到无人驾驶车和行人之间的交流。例如,行人头部朝向并注视车辆是预测行人意图的一个关键线索,行人也可通过外部人机交互界面eHMI(external human-machine interface)向车辆发出明确的行动信号。同理,无人驾驶车在确认行人状态的情况下也可利用显示屏或灯条以文字、动画或图标等方式向行人传达行动意图。随着技术的深化,人车之间将形成标准化交流“手势”并纳入高精地图。
理论模型的实践检验离不开行人数据和模拟平台。目前公开的最大和最多样化的带有标记的驾驶视频数据集是伯克利深度驾驶视频BDD100K(http:∥bdd-data.berkeley.edu),包括了1万多小时的世界各地的驾驶视频。与此同时,用于观察行人之间以及行人和车辆之间互动关系的开源模拟器也日益增多。
4.2 边角案例的数据获取
边角案例,即高风险和伤亡事故案例,很少出现在普通的驾驶环境中,因此无法在公共路网的大规模试驾中获取。目前可以通过三种互补的途径——实测场地,虚拟仿真和众包平台来收集边角案例,用于训练机器学习的极限应变能力。
4.2.1 实测场地
建设足够规模的物理试验环境来制造边角案例是研究机构和企业的首选手段。比如,美国密歇根大学主导建设的试验场MCity可供多家企业测试高风险驾驶场景。如图6所示,该试验场不仅呈现城市和郊区环境中常见的路面、交通标记、交叉口类型、建筑立面、车库、地上地下进出口坡道等静态基础设施,也模拟城市和郊区的日常生活,比如叫车服务、搬家、垃圾运输等。另一个供多家车企共享使用的大型测试场地是美国加州Contra Costa交通管理局负责运营的GoMentum Station,该场地拥有31.5 km的公路网及智能基础设施,其中一条11 km长的道路用于生成高速驾驶场景,一对430 m长的隧道则用于生成传感器信号发生变化的驾驶场景。为了鼓励更多的研究机构参与测试,积累和共享边角案例,美国交通运输部于2017年公布了10个实测场地(www.transportation.gov/briefing-room/dot1717)。
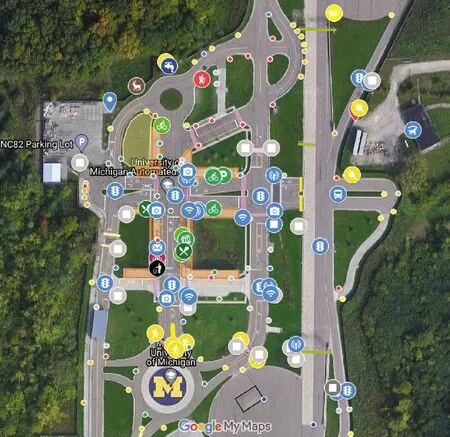
图6 MCity测试场地平面图(来源:https:∥mcity.umich.edu/our-work/mcity-test-facility)
一些车企为了保持某些方面的竞争优势,单独建设试验场地,比如Waymo在美国加州的试验场地Castle,重点构建车辆与行人的互动场景,目前已经积累了4万多个场景。优步在美国匹兹堡附近的测试场地Almono则利用各种模仿建筑物、移动车辆和行人的道具,在复杂路口制造无人驾驶车难以应对的边角案例,比如用道具建筑物挡住视线,道具车辆突然加速,道具人群突然横穿马路等。
4.2.2 虚拟仿真
虚拟仿真环境比实测场地更便于构建罕见的边角案例,特别是伤亡事故案例。微软推出了一个用于模拟复杂驾驶场景的开放平台CausalCity,使用者通过交互操作,可以详细了解交通事故中的各种因果关系,也可以利用平台提供的工具生成新的边角案例[15]。模拟的边角案例也可用于获取用户的认知信息,比如在边角场景里的关注点和行动意图。模拟环境还可用作为培训工具,向用户透明地展示边角场景驱动下的导航决策过程。图7所示为人类驾驶员在一个路口场景的眼动轨迹,持续时间为1.2 s,眼动轨迹显示出在四个时间点t0-t3依次被关注的内容:一位过街的人(t0),右侧的交通标志(t1),再次关注过街的人(t2)和另一位过街的人(t3)。人类驾驶员的眼动轨迹除了可用于识别疲劳驾驶的风险外,也可用于识别边角场景中人类的导航决策特点。

图7 眼动轨迹所示的4个时间点t0-t3被人类驾驶员关注的交通对象[16]
4.2.3 众包收集
众包收集是对实测场地的另一个有效补充。英国城市创新公司DG Cities和伦敦帝国学院等联合启动的项目D-Risk,利用来自交通摄像头、事故报告和志愿者目睹或亲历的事件构建了全球最大的边角案例库(www.drisk-project.org/edge-cases)。这些边角案例都是机器难以应对的小概率事件及奇特组合,比如,车道上突然出现动物的同时,有物体从高速公路桥上掉下来;万圣节打扮成交通灯的孩子站在街上;地下水管工从路面的井盖里露出身体。目前这个案例库已从世界各地收集到数百万起交通事故或险情的描述,其中六万多起是由天气骤变造成的,一万多起涉及动物或其他非机动车,数千起和无人驾驶技术有关。绝大部分涉及行人的险情描述不曾记录在交通事故报告中。研究者将这些从现实生活中收集的边角案例组织成知识图谱,一方面帮助人们更好地了解驾驶风险空间,另一方面还将案例进一步合成数十万亿种事故和险情场景,用于训练机器学习算法,丰富高精地图场景驱动下的导航规则。
4.3 伦理困境中的导航决策
在大多数驾驶场景里,交通规则和伦理规范有很高的一致性,然而,危及人身安全的边角场景里却会出现两相矛盾的道德困境。人类驾驶员善于根据安全第一的指导原则和伦理规范作出判断并采取行动,以违反交通规则的代价从困境里突围。目前的高精地图尚无能力应对交通规则和伦理规范发生冲突的情况。为了填补这个空白,德国马克斯·普朗克协会和美国麻省理工学院等联合创建了一个叫“道德机器”的开放平台,将无人驾驶车在边角场景中面临的各种伦理困境公布于众,来自不同地区和不同社会文化环境的用户可以对每一种伦理困境进行个人评判,提出具体建议,并讨论那些建议会造成哪些道德后果(www.moralmachine.net)。通过“道德机器”收集的众包决策意向有助于训练机器算法,提取伦理困境中的导航决策。
企业选择在实践中逐步完善边角场景驱动下的安全导航规则。比如,NVIDIA发布了一个叫“安全力场”的开放平台(www.nvidia.com/sff),以确保车辆和行人不发生碰撞为底线,利用传感器数据以及对高速公路和城市驾驶场景的模拟,重点研究无人驾驶车的刹车和转向等动作的安全驾驶规则。Aptiv公司则从大量高风险场景的驾驶行为数据中提取了数百条规则,并根据它们对安全性的重要程度进行排序,形成无人驾驶车辆共享的“规则手册”。排在顶层的是关于保证人类安全的规则,底层的是关于舒适性的规则。其余的规则和优先级可以根据具体的任务适当调整[17]。
Mobileye提出了一个叫“责任-敏感性安全”的数学模型(RSS)(www.mobileye.com/responsibility-sensitive-safety)。通常,高精地图的导航决策依赖启发式算法提供“预测”,需要消耗大量的计算资源,RSS结合人类的常识,用“意图”取代预测,从而只需要一小部分的计算能力。RSS的规则中不仅明确定义在各种高风险场景,特别是其他道路使用者违反交通规则时无人驾驶车应有的正确反应。更重要的是,当突发危险情况时允许无人驾驶车违反一条或多条交通规则,以避免事故发生。例如,如果一个物体突然出现在车道上,高精地图就指挥无人驾驶车立即换车道来避免直接碰撞或连锁碰撞,尽管这个决策有可能违反有关车道线或路肩等的交通规则。
4.4 无人驾驶的安全性能评估
高精度地图的导航决策能力体现在无人驾驶技术的成熟度上。其中,安全性能的公众关注度最高,并直接影响着无人驾驶车的准入门槛。每一起致命事故的发生,即使原因很快被查明,都会对公众产生持久的消极效应。因此,如何建立一个令公众信服的安全性能评估体系已成为一个研究热点。
4.4.1 基于定量属性的评估方法
无人驾驶技术的安全性被视为可定量的属性。目前普遍采用的指标包括免提行驶的里程数,单位里程中人类驾驶员的接管次数和时长。这种方法的优点是直观易懂,车企定期公布业绩数据有利于提高透明度,使公众及时了解无人驾驶技术的进步。定量属性也可以用作为研发目标,鼓励竞争。一个叫“零事故愿景网络”(https:∥visionzeronetwork.org)的公益合作项目致力于推进安全和健康行驶,避免一切可以避免的重大交通事故,同时增加所有人的安全、健康、公平的流动性。零伤亡愿景于20世纪90年代在瑞典首次实施,在欧洲和美国得到了广泛的支持和认同。2016年,美国推出了“零事故”重点城市计划,2022年初,美国交通部将“零事故”扩展到零排放愿景。
然而,基于定量属性的评估方法并不现实。为了在统计显著性上说明比人类驾驶安全两倍,无人驾驶车需要在实际的公路上达到62亿千米以上的免提行驶距离,并以每百万千米的伤亡人数来和人类驾驶的业绩相比较[18]。这样的指标不仅难以监管,还会延缓甚至阻碍创新开发。即使在很多年后满足了指标要求,只要依然存在伤亡事故,公众仍未必完全信任无人驾驶技术。
4.4.2 基于系统设计的评估方法
无人驾驶技术的安全性被视为一个系统的安全设计原则,涉及比车辆本身更多的相关组件,包括社会因素、道路基础设施和通信网络在内。欧盟公布的和公共道德价值观有关的伦理原则,涵盖了安全设计、新的交通规则、算法决策的透明度、道路使用者的信息隐私和知情权、数据集的公共和开放的基础设施资源、审计算法、问责等多项规定[19]。系统安全性实际上是约束条件下的求解问题,可能有多种解法。比如对车辆进行“地理围栏”,以防它们在实际交通中误入不可预测的空间,或者改变系统设置,限制其他道路参与者的行动或对道路基础设施进行升级改造[20]。
无人驾驶系统的安全设计也包括网络安全测试,主要体现在定位通信和远程控制两个方面。高精地图的导航决策对卫星定位信息有很高的依赖性,使黑客攻击有了可乘之机。软件技术公司Regulus Cyber的研究人员模仿潜在黑客,用无线电设备干扰定位卫星的组合,伪造定位信号并导出欺诈坐标。面临来自“定位接收器”和其他传感器互相矛盾的信号,导航规则中如果对“定位接收器”的信号设置了过高的权重,往往会导致测试车把错误的位置当作高速路出口,执行错误的限速指令,甚至驶入逆行道[21]。远程控制技术也面临同样的网络安全隐患。相比远程操纵的工业自动车,比如挖土机、采矿车、货物装卸车等,无人驾驶车行驶在开放的公共场合,遇到故障的时候,需要借助通信网络获得可靠的远程指导。芬兰阿尔托大学研发了A!ex概念,重点研究无人驾驶车在5G网络里与其他车辆和交通基础设施进行通信的意外情况,比如远程控制器使无人驾驶车在地球的另一端踩下油门的时刻网络中断,远程控制器和无人驾驶车的边缘计算能力之间的责任划分等[22]。
德国经济能源部支持的PEGASUS项目组提出了一个对无人驾驶车进行安全性能系统测试和验收的方案,先以高速公路基础设施作为试验区[23]。研究人员首先利用机器学习方法,从大量传感数据以及德国的动态交通事故数据库等多种数据源中识别高速公路上出现的高风险场景的各种特征及取值,并用ASAM的标准格式加以描述。当场景数量足够大的时候,它们可以形成一个连续分布的场景空间。因此,机器学习的结果不再是具体的高风险场景列表,而是一个可供测试的逻辑场景空间,空间内任意一个点都对应一个有若干特征参数值组合而成的高风险场景。在此基础上,研究者们进一步开发模拟器,系统地分析整个逻辑场景空间里无人驾驶车的安全性责任以及必须达到的指标,并在实测场地或虚拟仿真环境里反复验证。如果一辆无人驾驶车能够通过随机抽取的高风险场景的安全性能检验,就被认为是合格的,换句话说,其高精地图的导航智能达到了安全性要求。
5 展 望
无人驾驶是对高精地图导航智能的极限挑战,需要立法机构、研究机构、企业和公众在全球范围内协同合作,共享数据和知识,才能在任何驾驶场景达到法律和道德框架内都无须人类接管的要求。以安全为导向的无人驾驶是现阶段的研究重点,随着对安全驾驶有意义的数据和知识的日益增多,人工智能算法将得到更加完备的训练,为高精地图补充越来越多场景驱动并且符合伦理准则的安全导航规则。
现阶段的高精地图主要服务于无人驾驶车。在机器的“眼”里,高精地图是关于路网和驾驶场景中和安全导航相关的几何对象、语义属性、互动关系、交通规则、伦理规范等的结构化数码,地图的视觉设计元素可有可无。随着无人驾驶技术的不断完善,安全第一将逐渐扩展成兼顾安全、环保节能和身心愉悦度的移动体验。
不断追求技术进步的人类将驾驶控制权全部交给机器,欣喜之余也有失落感。手握方向盘安全且快速地在道路上穿梭的过程不全是迫不得已的赶路或周而复始的上下班交通程序,而是生活乐趣的一部分。失去这部分乐趣,就意味着需要通过其他方式找到另一种乐趣。无人驾驶环境里的人类不再是监护者,而是机器的平等对话者、用户体验数据的贡献者、驾驶场景的目击者和车载信息娱乐系统的欣赏者。移动车辆中的乘客仍将继续本能地关注高风险场景,无人驾驶车也会及时感知到车内乘客和车外行人的手势、表情和意图。人和车辆之间的自然交流不仅能够提升移动体验的愉悦度,也是对边缘计算以及安全导航的有效补充。但人类在移动世界的新角色离不开清晰易懂的驾驶场景地图。高精地图的结构化数码除了服务于无人驾驶车以外,也将作为数字社会的知识载体服务于更广泛的科技、教育和文化传媒领域,衍生出多样化的适合人眼阅读的高清地图。如何充分发挥自主导航地图数据的价值,实时生成高精地图和高清地图,同时为机器和人类提供最优服务,将成为新的研究热点。
高清地图不像一幅世界全图那样静美和超脱,它是一个个平常或者千钧一发的移动窗口。未来的HD Map既是高精地图,也是高清地图,并且还由于承载着安全驾驶的伦理规范而成为名副其实的高德地图。无人驾驶的发展趋势是用数据之真,地图之美,为人类创造移动服务之善。
