基于LSTM模型的北威克试验站小流域实时径流预报
2022-07-05降亚楠姜田亮
李 博,降亚楠,2,张 特,姜田亮
(1.西北农林科技大学 水利与建筑工程学院, 陕西 杨凌 712100;2.西北农林科技大学 旱区农业水土工程教育部重点实验室,陕西 杨凌 712100)
实时径流预报在防洪抗旱及水资源精细化管理中发挥着重要作用,但由于受到流域内天气条件、地形地貌、植物覆盖、降雨特征、地理位置等各种因素的共同影响,径流呈现高度的非线性,实时径流预报在水文过程模拟中始终是一个难题[1-3]。实时径流预报方法包含过程驱动方法(具有物理机制)和数据驱动方法[4]。过程驱动方法的基础是含有物理过程信息的偏微分方程和线性方程组[5-6]。但实时径流预报对模型构建速度和求解运行效率要求高,所需的数据量大且建模计算复杂,因此,通过过程驱动模型进行实时径流预报面临诸多难题[7]。以数据驱动为主导的方法可以进行大量实时数据分析处理,在高时空分辨率水文要素量测数据增加的背景下,具有不可忽视的优点,其本质是一种统计方法,更着重于实测水文资料中前期影响因素与径流间的输入输出关系,而忽略了因素间明确的因果关系[8]。大量研究表明,可以通过选取机器学习中的人工神经网络(ANN)和支持向量机(SVM)等模型,挖掘径流序列中隐藏的非线性特征,进而达到改进预测结果的目的[9-10]。
深度学习作为机器学习中的前沿技术,其显著特点是在神经网络架构中设置多层神经元,在处理复杂映射方面拥有更优性能[11]。近年来,研究人员已经采用LSTM进行径流时间序列分析和预报,表明LSTM在径流预报方面具有更出色的性能。叶陈雷等利用LSTM模型对社区尺度的降雨径流关系进行模拟,基于不同的降雨情景和SWMM模拟值生成的数据集,评估了LSTM模型的模拟效果,结果表明LSTM模型对降雨径流的模拟性能与SWMM模型基本相当[12]。Yin等[13]运用基于LSTM和S2S的多状态向量序列到序列(LSTM-MSV-S2S)降雨径流模型,选取CAMELS数据集上673个流域的日气象数据和日径流观测值进行测试,在预报期为7 d的径流预报方面取得了不错的性能表现。上述研究成果表明深度学习模型在不同时间尺度预测中具备优势。在目前自动化水文监测设备不断完善的情况下,在小流域上获得观测尺度更精细的径流气象数据已日渐成熟,之前较多研究关注小时及更大尺度的径流预报,目前尚无针对小流域在更精细的时间尺度上,深入探讨LSTM实时径流预报性能方面的研究[14]。
鉴于此,本文运用LSTM原理建立了英格兰北威克试验站小流域分钟尺度的实时径流预报模型,将逐时段径流、前期降雨及气温三个要素作为输入进行实时径流预报,并通过模拟值和实测值的对比分析,评估模型的预报性能,以期为流域实时径流预报提供技术支撑。
1 研究区概况与数据获取
1.1 研究区概况
研究区域位于英格兰西南部(50°46′10″N,3°54′05″W)的北威克试验站(the North Wyke Farm Platform,NWAFP),是为可持续草地畜牧业系统研究建立的标准农场试验站,如图1所示。北威克试验站海拔为120 m~180 m,1985年—2015期间年平均气温为6.8℃~13.4℃,年平均降水量为1 033 mm,土壤质地构成主要包括石质壤土(约36%壤土)以及石质黏土(约60%黏土)且底层土壤透水性较弱,流域降雨期间大部分雨水通过试验站地表排水系统排出[15]。该试验站由三个独立的小试验站组成,每个小试验站的面积为21 hm2,且每个小试验站包含五个子集水区。该平台定期对15个子集水区内的径流、降雨、气温和相对湿度等气象要素按15 min时间精度进行定期监测,可为实时径流预报提供充足的数据。

图1 北威克试验站地理位置及子集水区分布图
1.2 数据收集
图1所示15个子集水区域在水文联系上相互独立,经由沟渠引导径流至组合流量仪表水槽,北威克试验站自2012年10月起以15 min时间频率监测子流域降雨、土壤湿度、气温、径流及其化学成分等指标。由于第10至第15子流域缺失前期降雨径流资料,故研究区选定为其余资料完善的9个子流域(图1标签分别为1、2、4、6、7、8、9、11、12)。英格兰西南部秋冬季为雨季,降雨径流关联程度高,为降低模型计算成本且确保训练数据间的水文联系,选择4至5个月作为训练周期。故本文选取该站2017年10月—2018年3月的流域前期降雨、流域气温、流域径流和流域相对湿度的15 min数据集作为模型训练资料[16-17]。样本总数为15 552,其中训练周期样本数占比为80%,共计12 442,测试周期样本数占比为20%,共计3 110。
2 基于LSTM的实时径流预报
2.1 LSTM模型基本原理
LSTM属于循环神经网络,通过模型结构具备的输入门、遗忘门和输出门能有效解决梯度问题,在解决时间序列相关的回归问题中表现出更优的性能。LSTM最早由Hochreiter等[16]提出,之后被Graves等[17]进一步改善。
LSTM记忆单元的内部结构如图2所示。t记忆单元的输入信息包含输入变量Xt、隐藏层变量ht-1和记忆单元变量Ct-1。模型经由三种门结构,通过梯度下降算法和对误差的反向传播算法调整网络结构的权重与偏置参数。输出包括:输出变量ht和记忆单元变量Ct。各部分结构如下[18]:
遗忘门ft:决定记忆单元变量Ct-1的 舍弃状态。

图2 长短记忆模型记忆单元结构示意图
ft=σ(Wf·[ht-1,xt]+bf)
(1)
输入门it:决定Xt以何种比例输入到Ct中。
it=σ(Wi·[ht-1,xt]+bi)
(2)
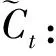
(3)
至此,t记忆单元的组成包括遗忘门留存下的信息和输入门新输入的信息。
(4)
输出门Ot:计算当前时刻信息输出程度。
Ot=σ(Wo·[ht-1,xt]+bo)
(5)
ht=Ot×tanh(Ct)
(6)
ht传递到模型的输出层以后经过计算得到在t时刻的最后输出信息为yt。
yt=wd·ht+bd
(7)

2.2 模型构建
2.2.1 网络结构
本文采用五层LSTM循环神经网络建模,分别为输入层、双隐含层、丢弃层以及全连接输出层,输入层神经元个数为200,隐含层神经元个数为32,输出层神经元个数为1。第一层输入流域相关气象数据,第二及第三隐含层决定输入信息的遗忘与更新,通过反向传播算法寻求最优模型参数进行模拟。第四层为一层丢弃层,设定丢弃率为50%[19],即随机性地屏蔽半数神经元。第五层为全连接输出层,用于独立输出模拟的流域径流序列。
2.2.2 参数率定
LSTM网络参数主要有两种,一种为网络内部隐藏神经元和输入输出层间的权重与偏置,通过反向传播算法自动调整和更新参数;另一种为超参数,神经网络模型中包含有多种超参数,例如学习率、正则化参数、神经网络层数、隐藏层神经元数目、学习循环次数、激活函数等,在机器学习中超参数不能直接从标准模型培训过程的数据中学习,需要在开始训练模型之前预先设置超参数值。通过模型参数率定,达成优化超参数目的,进一步提升模型模拟的精度。为衡量优化算法在独立数据集上的性能,在选择最优超参数过程中面临模型选择和超参数优化等问题,本文采用均方根误差RMSE作为损失函数对模型超参数进行优化。
将初始学习率设置为0.01, 每循环10 000次学习率衰减为前一刻的90%, 达到迭代更新学习率目的。训练次数是指神经网络使用训练集中全部样本的学习次数, 若训练时间过长则易出现过拟合现象, 即模型仅对训练数据进行特征提取而泛化性能较差。反之训练次数不足则会出现欠拟合问题, 无法充分挖掘数据的共有特征。本文设置初始训练次数为500次, 其后依次减少训练次数, 观察到理想的拟合结果稳定在200次后, 因此将后续训练次数都设置为200次。其余超参数则通过经验试错法进行优化, 采取的设置场景和超参数选取情况如表1所示。

表1 LSTM网络超参数选择情况
2.2.3 数据预处理
考虑到降雨量、气温、相对湿度等气象数据具有不同量纲和量纲单位,为消除指标之间量纲影响以解决数据指标之间的可比性,将数据归一化到0和1之间:
(8)
式中:x为原始输入数据;minx和maxx为原始输入数据中对应的最小值和最大值。
使用下列公式将模型模拟的径流量归一化值转换为径流量实际值:
x=x*(maxx-minx)+minx
(9)
2.2.4 输入因子选取
从研究资料中选取2013年10月1日—2014年2月1日为模型训练期,2014年2月1日—2014年3月11日为模型验证期。以往的研究主要以前期径流作为模型输入变量,为进一步提高模型预测精度,本次研究从诸如降雨、气温、相对湿度等气象要素中选取4类相关因素来训练径流预报模型,即流域前期径流量、流域前期降雨、流域气温和相对湿度。
可选择这4类因素中的一种或数种作为输入因子预报流域径流。根据有可能的输入因子组合,设置了7组输入方案,方案1仅采用一种输入因子,属于第Ⅰ类方案;方案2—方案4有2种输入因子,属于第Ⅱ类方案;方案5—方案7有3种输入因子,属于第Ⅲ类方案。每种输入方案的预见期相同且采用统一长度预测窗口,不同输入因子情况依此类推具体情况见表2。
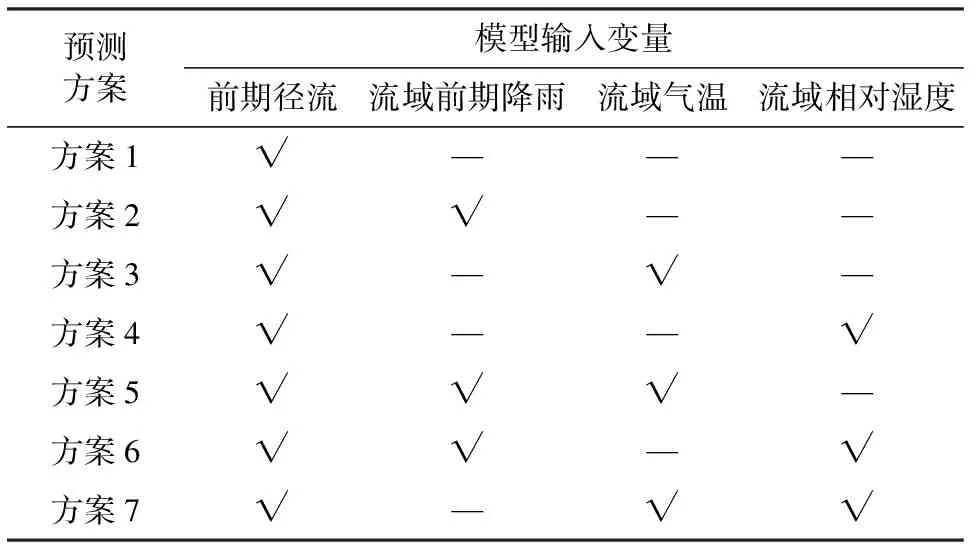
表2 径流预报模型不同输入方案
2.2.5 预测窗口设定
LSTM长短记忆模型的窗口长度对模型预测效果有重要影响,在本文中分析了不同窗口长短对预测效果的影响试图寻找出最优参数。以运算精度和数据集容量作为参考,设置了9组预测窗口,长度分别为1、2、3、4、5、10、15、20、30个单位步长,即15 min(I)、30 min(Ⅱ)、45 min(Ⅲ)、1.25 h(Ⅳ)、2.50 h(Ⅴ)、3.75 h(Ⅵ)、5.00 h(Ⅶ)、7.50 h(Ⅷ)、9.00 h(Ⅸ),从中筛选出预测效果最优的窗口作为最终预测窗口长度。
2.3 模型评价指标
LSTM通过训练样本得到优化模型,再用该模型将输入映射为输出进行预测,模型的预测效果采用统计指标进行量化,本文选用纳什效率系数和均方根误差对模型精度进行评估,其计算公式分别为:
(10)
(11)
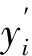
3 研究结果
3.1 模型参数优选
3.1.1 输入因子对模型预测效果的影响
图3为七种输入方案下依次模拟50次后该流域径流预报精度指标。由观察可知,七种输入方案的NSE均处于0.80~0.98范围,RMSE处于0.000~0.035 m3/s范围,预测精度较好。方案1使用径流数据作为单一类型输入变量,模拟期和验证期NSE稳定在0.97附近,验证期相较于模拟期RMSE有较小幅度削减,但箱体分布相对离散,上下限差距较大。方案2—方案4皆为双因子类型输入变量,三类输入方案处于验证期的NSE较模拟期有显著程度削减,且验证期的RMSE均有不同程度上升,验证期预测精度指标总体弱于模拟期。方案5—方案7为三因子类型输入变量,径流预报精度较双因子方案均有所提高且RMSE略有降低。以上三类方案中验证期的NSE、RMSE与模拟期相比维持稳定,无明显幅度波动,体现出三输入因子训练模型具备良好的稳定性能与泛化性能。其中方案5对应的输入因子为流域径流、流域前期降雨和流域气温,验证期和模拟期的NSE均为三类方案中最高精度指标,验证期和模拟期RMSE均为数值最低,且分布相对集中离散化程度低,上下限差距更小,综合考虑模型的模拟性能和计算效率,选择方案五作为最优的径流预报输入变量。
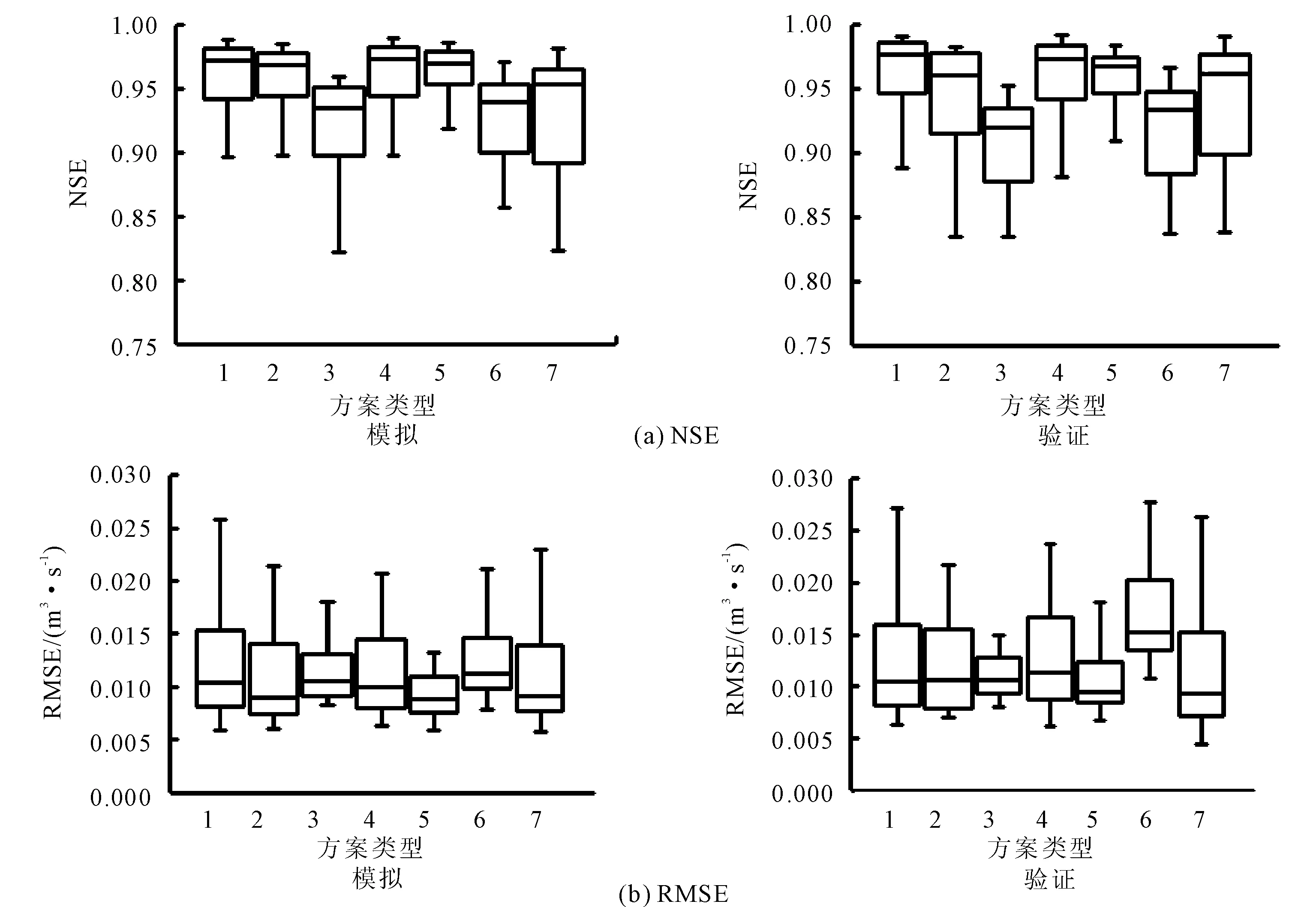
图3 不同输入方案下模拟指标
3.1.2 输入窗口对模型预测效果的影响
选用9种不同长度的窗口构建模型,预测结果如图4所示。在预测窗口长度增加初期,模拟期和验证期RMSE下降较迅速,模拟期RMSE在预测窗口为4个单位步长时达到最小值,验证期RMSE在预测窗口长度为3个单位步长时达到最小值。当预测窗口继续增大至方案7所对应的15个单位步长时,模拟期和验证期RMSE均有不同程度增大,存在过拟合特征。当预测窗口超过15个单位步长后,模拟期与验证期的RMSE在小幅度波动的情况下趋近于稳定,继续增加预测窗口长度对于模型模拟效果并无显著增益。类似的特征也在NSE的变化过程中有所体现,在模拟期内当预测窗口长度小于4个单位步长时,随着预测窗口增加NSE也相应增加。在大于4个单位步长时,窗口长度增大会导致NSE继续降低。当窗口超过15个单位步长后,NSE短暂上升,之后转为小幅度下降并逐渐趋于稳定。在验证期内当预测窗口小于3个单位步长时,模型模拟效果随窗口长度增加而持续提升。窗口长度处于4个单位步长及以上范围,其后续对应变化特征与模拟期类似。在综合考虑计算效率和预测效果的前提下,方案3与方案4相比处于验证期的NSE更高,RMSE更低,箱体数据分布集中且上下限差距更小,模型预测效果更优,在该预测模型中使用3个单位步长的预测窗口较为合理。

图4 不同输入窗口长度下模拟指标
3.2 模型性能评估
在对模型各项参数进行调整和完善后,对模型预测性能指标进行评估。图5为径流预报模型在完整时间序列中不同子流域上预测结果与实测值的比较。由图观察得知:各子流域完整时间序列的NSE均在0.970左右,仅C1流域相对较低为0.916,表明模型在径流预报方面的良好性能。C1子流域在训练期与验证期散点分布与45°直线偏离略大,其他子流域散点分布均趋近于45°直线且于两侧均匀分布,表明模型在训练期和验证期均能有效捕捉各子流域的输入要素与径流的相关关系。将C7子流域预测结果作为代表进行分析(见图6),可以看出整体预测结果与实测值吻合较好,模型在非汛期及峰前峰后时刻均能较好地预测实测序列,但对峰值的预测效果略差,模型对于峰值预测偏低。

图5 各子流域完整时间序列径流预报结果
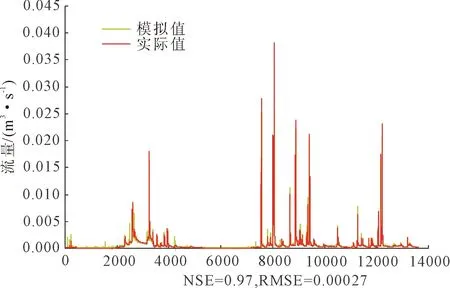
图6 C7子流域径流预报模型结果
4 结论与讨论
本文运用LSTM原理构建了英格兰南部北威克试验站小流域分钟尺度的实时径流预报模型,并采用NSE和RMSE两个评价标准定量评价预报模型在各子流域的性能。主要结论如下:
(1) 长短时记忆神经网络(LSTM)模型可以用于小流域的实时径流预报,且具备良好的模拟性能和预报能力,多个小区流域模型的NSE均可达到0.95左右。
(2) 模型输入及预测窗口长度的选择对模型精度和稳定性有较大影响,多气象数据输入的LSTM模型比单一气象数据输入的预报精度更高,且在多个输入情况下选取适当窗口长度的模型计算量较低。在北威克试验站流域的径流预报模型中选择以前期流域径流、流域降雨及流域气温作为输入因子,以三个单位时间步长(即45 min)作为预测窗口时模型预报效果最佳。
LSTM模型在北威克试验站流域径流预报中表现良好,主要有以下两方面原因:(1) 该模型相比于其他机器学习模型,性能更加优越,对于长期序列更加敏感;(2) 此外,本文研究区面积小、环境湿润,流域水文条件总体保持平稳。目前模型的缺陷在于对径流极值的预报效果较差,有待进一步采取实时校正等方法修复预报结果达到提高精度的目的。本文研究结果可为小流域实时径流预报模型的构建提供参考依据,今后可考虑持续完善影响因素和参数选择并采用多种模型耦合方式,以达到模型间优势互补进而提高预测效果和泛化能力。
