基于多智能体近端策略优化的分布式动态火力分配方法
2022-07-04吴建设
唐 骁,吴建设
(1.江南机电设计研究所,贵州 贵阳 550009;2.西安电子科技大学,陕西 西安 710071)
火力分配问题[1]研究如何分配武器单元打击敌方目标,以取得最佳的打击效果。其本质是非线性组合优化问题,随着武器单元及目标数量的增长,解空间的大小也呈指数增长,是一个NP 完全问题。常用的火力分配方法,有枚举法、匈牙利算法以及动态规划算法等传统方法,也有遗传算法、蚁群算法以及粒子群算法之类的启发式算法。传统方法原理简单,但是流程较为繁琐,难以处理大规模的火力分配问题;启发式算法利用一些启发式规则在解空间中进行寻优,可以高效地处理较大规模的火力分配问题。但是上述这些方法都仅适用于静态火力分配问题中,无法处理动态火力分配问题。而动态火力分配问题是更加贴近真实作战情况的。并且随着近些年科学技术的发展,各类高超音速武器的出现,需要更快速地、更准确地打击目标,这对于火力分配提出了更高的要求。同时在作战理念上也发生了巨大的变化,主要特点就是从集中式指挥转向了分布式指挥。即对于联合作战来说,要做到去中心化,每个作战单元可以根据自己的信息进行自主决策。而现有的火力分配方法,无论是传统方法抑或是启发式算法,都只能在集中式指挥的场景下处理火力分配问题。
本文借用多智能体深度强化学习的方法,提出了多智能体近端策略优化方法以解决分布式指挥场景下的动态火力分配问题。
1 火力分配概述
火力分配(WTA)是现代防御系统中的核心问题,指根据战场态势和武器性能等因素,将一定类型和数量的火力单元以某种准则进行分配,一般以最大化对目标的毁伤概率为目的。火力分配又分为静态火力分配(SWTA)以及动态火力(DWTA)分配,静态火力分配只考虑单次的火力分配,而动态火力分配考虑多次分配,且各次分配之间互有影响。
以静态火力分配为例,假设有m个火力单元,分别用Mi(i=1,2,...,m)表示;共有n个来袭目标,用Tj(j=1,2,...,n)表示;ωj表示第j个目标的威胁度,Pij表示第i个武器对第j个目标的毁伤概率,xkj(k=1,2,...,m)为决策变量,表示是否分配第k个武器打击第j个目标,xkj=1 表示分配,xkj=0 表示不分配。每个火力单元只能分配给单个目标。通过攻击最大化对目标的毁伤,可描述为:

传统的火力分配方法原理简单,但是在规模较大的情况下难以高效地找到问题的解,现在多用的是启发式的算法。文献[2]针对鲸鱼优化算法搜索精度低、易早熟的问题,提出了一种改进的鲸鱼优化算法,提高了火力分配的收益和速度;文献[3]通过将混沌优化算子应用到遗传算法的选择过程中,增强了遗传算法的局部搜索及全局寻优能力。这些算法在静态火力分配的问题中都能够达到很不错的效果,规模较大时寻优时间也能令人满意。但是实际战场中面临的实质是动态火力分配的问题,每一次分配都会影响下一次分配。无论是传统方法还是启发式方法都难以解决这样的序贯问题。
2 多智能体近端策略优化
2.1 多智能体深度强化学习
在2016年AlphaGo[4]在打败世界顶尖棋手后,深度强化学习也引起了极大的关注,被视为迈向通用人工智能的重要技术。深度强化学习通过让智能体与环境进行互动进行自学习。非常适合解决序贯问题。多智能体深度强化学习在此基础上引入了多个智能体,让智能体通过合作来解决问题。一般将多智能体所处的环境描述为部分可观的马尔科夫博弈。每个智能体只能获得自己的观测并据此进行决策,以使整个团队获得最大的奖励。在火力分配问题中,战场中具有诸多的火力单元,可以将每个火力单元看作一个智能体。这样的做法不仅能够适应当下去中心化的作战理念,同时由于各个火力单元可以进行分散计算,对于算力的要求也更低。
2.2 算法设计
本文采取集中式训练分布式执行的范式[5],即在训练阶段对所有火力单元进行联合训练,在执行阶段每个火力单元单独执行自己的决策。对于每一个火力单元,采取Actor-Critic 结构[6],即每个火力单元都有一个Actor 以及一个Critic。每个火力单元的Actor 根据自己的观测进行决策,目标是要使在一场战斗中毁伤的目标威胁度之和最大,而Critic 仅仅在训练阶段使用,起到帮助Actor 训练的作用。算法的网络结构如图1 所示。

图1 多智能体近端策略优化算法网络结构
火力单元i由Critici与Actori构成,其中Actori接收局部观测oi输出决策向量,但是由于实际情况中有些操作无法进行,因此要对该输出的决策向量进行Mask 操作[7],最后得到最终的决策ai。而Critici仅在训练阶段使用,根据集中式训练分布式执行的框架,为了提升训练效率需要充分利用各智能体获取的信息。具体操作为,将所有火力单元的局部观测进行拼接得到全局状态的近似向量,将该向量输入到火力单元i的Critici得到状态价值Vi以指导Actori做出合理的决策。在训练过程中,参数为θi的Actori的优化目标为:


该式由TD-error 的方式[9]得到,其中是第k步的目标奖励,B 为批量大小,sk为第k步的近似全局状态信息,由所有智能体在第k步的观测向量拼接得到。
3 实验
3.1 实验场景
实验场景考虑空袭场景,假设敌方对我方某要地进行打击。我方防空武器系统有10个火力单元,分别为3种类型的防空武器,其中,5个火力单元为一型武器,3个火力单元为二型武器,2个火力单元为三型武器。各型武器的装填时间分别为0、1、2,单位为防空系统的时间步(发现目标到发射的时间),装填时间为0 表示其装填时间小于1 时间步。敌方具有无人机、巡航导弹、战斗机、轰炸机、战术导弹5 种类型的空袭兵器。其数量比约为10∶6∶4∶3∶1。设探测到的来袭目标均为符合拦截条件,对于符合拦截条件的目标,各型拦截武器对其毁伤概率仅与来袭目标类型有关。由于来袭目标类型、突防能力、杀伤力各不相同,同类型的来袭目标威胁度在一定范围内。表1 为环境具体数据,包含威胁度及毁伤概率。

表1 环境参数
每一场防空作战,设定空袭方对我方进行30 轮空袭,我方武器储备充足,对方最大空袭能力为10,即每一时间步空袭方最多会有由各类型空袭兵器组合成的10个目标。对于每个来袭目标,我方只能在当前时间步内将其摧毁。对于判定目标是否被摧毁,由环境生成随机数,若小于当前拦截武器对目标的毁伤概率则判定为摧毁。同时,在分布式指挥场景下,令每个火力单元仅能观测到来袭目标的信息,但是无法获取其他火力单元对于拦截目标选择的信息。我方最终目的是在一场防空作战内,使被摧毁来袭目标的威胁度之和尽可能高。
3.2 对比算法
由于当前并没有能够适用于分布式指挥下动态火力分配问题的算法。因此本文选取文献中的算法,并对其进行适当调整,使其能够适应动态火力分配问题。然而该算法仅适用于集中式指挥场景,因此在用该算法模拟时,作战场景调整为集中式指挥的方式,即算法可以根据所有现有信息为所有火力单元统一分配目标。
具体做法是,由于动态火力分配可以看作一次次的静态火力分配,因此对于每一时间步的情况当作静态火力分配处理。每一时间步不同的量为来袭目标的类型和数量,此外由于装填时间的存在,另一个每一时间步会不同的量为可开火的火力单元数量。综上,在每一时间步中,改变粒子的编码长度,令其长度为当前可开火的火力单元数量,并调整其合法区间在来袭目标的数量之内。每一时间步均设种群规模为30,迭代次数为200。
3.3 算法设置及实验结果
对于多智能体近端策略方法来说,令每个火力单元的局部观测向量(即火力单元的Actor 的输入向量)为来袭目标的威胁度信息,当前火力单元对于当前来袭目标的毁伤概率以及当前火力单元的装填信息。同时为了训练的稳定性,对来袭目标按威胁度由大到小进行了排序。另外,当当前火力单元处于装填状态无法进行拦截时,对于向量中毁伤概率的部分进行置零操作。输出动作设为11 维,分别代表不发射、拦截1 号目标、……、拦截10 号目标。应注意的是,神经网络的输出需要设置为定长,根据实际情况是可以改变其维度的。
在实验中,使用多智能体近端策略优化方法进行50 000 代训练并记录的平均奖励,这里的平均奖励为一场防空作战中所摧毁的来袭目标威胁度之和。作为对比,使用粒子群优化算法在防空作战场景中进行20 次仿真,记录仿真中取得的最优奖励、最差奖励并计算20次仿真的平均奖励。实验结果如图2 所示,可以看到经过50 000 代训练,多智能体近端策略优化方法的平均奖励超过了40。图中的三条虚线分别为粒子群优化算法进行20 次仿真的最优奖励、最差奖励以及平均奖励。

图2 多智能体近端策略优化的训练结果
从图2 可以看到多智能体近端策略优化方法的拦截效果要远远超过粒子群优化算法,为了说明这样的差距是如何产生,接下来的实验中选取相同的连续3 轮空袭的防空场景,分别令粒子群算法以及多智能体近端策略优化方法进行分配。并且,在该实验中,所有武器单元在一开始都处于可开火的状态。表2 为3 轮空袭中来袭目标的情况。其中类型一栏1-5 分别代表无人机、巡航导弹、战斗机、轰炸机以及战术导弹。
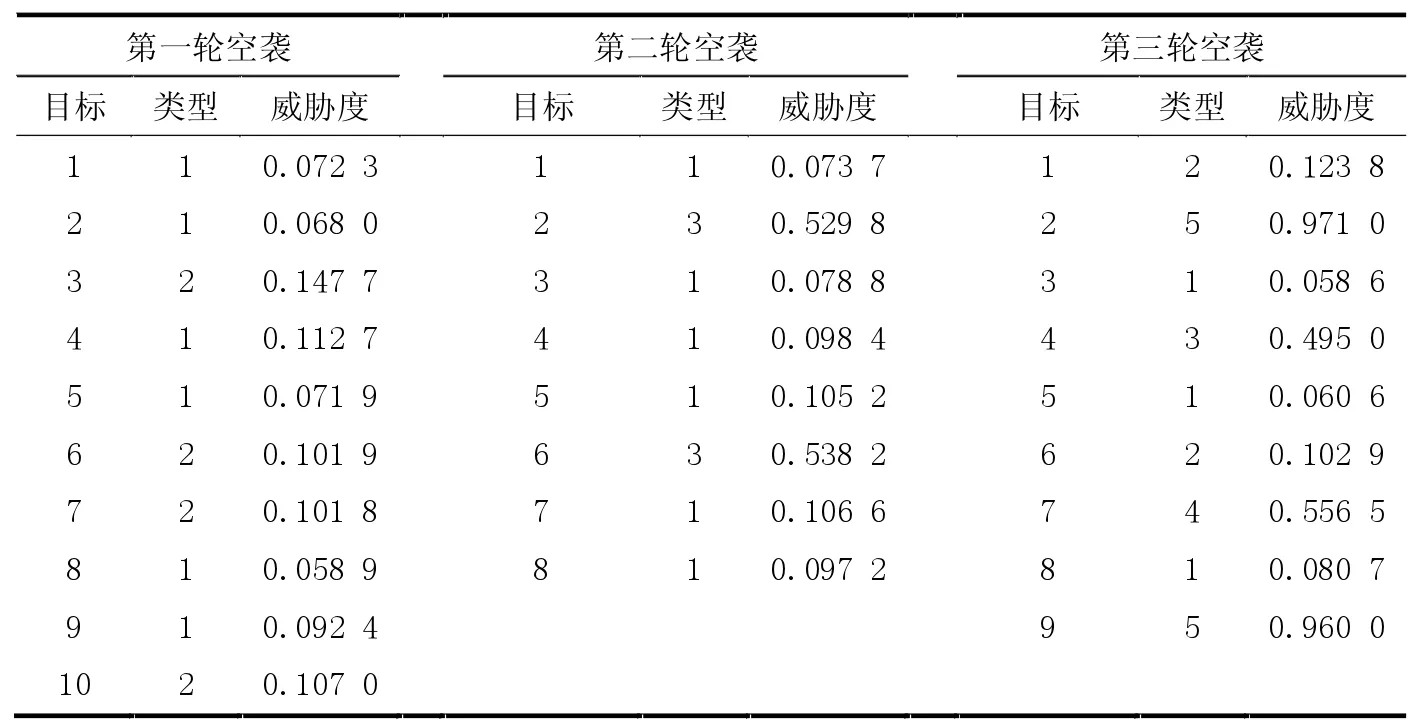
表2 来袭目标情况
从表中可以发现,敌方在第一轮空袭中采取了饱和式攻击,但是同时又以威胁度较低的无人机及巡航导弹为主;随后第二轮空袭中敌方投入了战斗机搭配无人机的攻击方式;第三轮敌方则使用了各种类型空袭兵器的搭配,并且还包含威胁度极高的战术导弹。
表3为粒子群优化算法所做分配,需要说明的是在火力单元一栏中,火力单元1-5 为一型武器,火力单元6-8 为二型武器,火力单元9 和10 为三型武器。可以看到在进行第一轮拦截时,所有的火力单元都选择了目标进行拦截。这就导致在第二轮拦截中,有一半的火力单元处于无法开火的状态,能够开火的火力单元均为一型武器,也无法高效地对战斗机进行拦截。在第三轮中,尽管二型武器完成装填,但是对于战术导弹有较高拦截效率的三型武器都处于无法开火的状态。
表4为多智能体近端策略优化算法所做的分配,火力单元一栏的表示与表3 相同。可以看到在面对第一轮饱和攻击时,防空系统放过了近一半的目标,在第二轮和第三轮拦截时,都只有一个火力单元处在装填的状态。并且在最为复杂严峻的第三轮空袭中对所有的来袭目标都进行了分配,并且威胁最大的弹道导弹都分配了三型武器进行拦截。
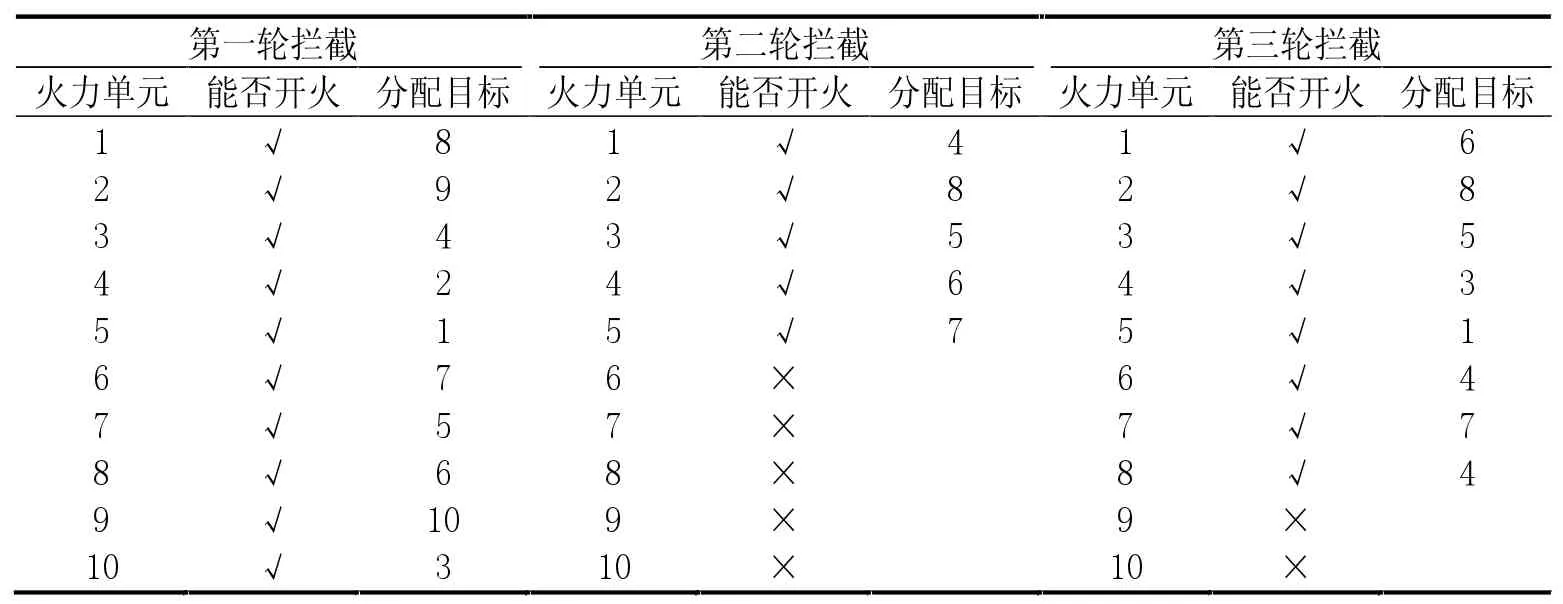
表3 粒子群优化算法的分配情况

表4 多智能体近端策略优化算法的分配情况
根据上面的实验,可以发现,在动态火力分配问题中,由于有了时间维度的考量,每一次分配就需要考虑对于之后分配可能会产生的影响。粒子群优化算法亦或是其他的启发式算法以及传统的方法都无法考量时间维度上一次分配可能会对后续分配产生的影响。而在多智能体近端策略优化算法中,尽管是分布式指挥方式,但是火力单元之间依然存在非常好的合作,并且其能够未雨绸缪,为未来的风险预留武器。
4 结束语
本文针对当前无论是启发式算法或是传统方法都难以处理分布式指挥下的动态火力分配问题,引入了多智能体深度强化学习,提出了使用多智能体近端策略优化方法,采取集中式训练分布式执行框架以及Actor-Critic 框架。通过实验证明了该方法能够有效地处理分布式指挥下的动态火力分配问题。为研究处理分布式场景下的动态火力分配提供了参考。对于该研究未来的方向,可以考虑如何在智能体数量大规模增加时,处理智能体中Critic 的输入向量以降低计算量。
