基于多尺度语义信息融合的SSD小目标检测方法
2022-07-04武德彬刘笑楠
武德彬,刘笑楠
(沈阳工业大学信息科学与工程学院,沈阳 110870)
1 引言
在目标检测中,小目标具有信息占比低、特征不明显的特点,因此如何提高小目标检测精度已成为目标检测领域的研究热点。深度学习目标检测方法可分为两大类,即单阶段目标检测方法和两阶段目标检测方法。其中,两阶段目标检测方法检测精度较高,但是速度较慢,包括Fast-RCNN[1],Faster-RCNN[2]等。单阶段目标检测方法采用一种端到端的方式,包括SSD[3]、YOLOv3[4]以及YOLOv4[5]等,这类方法具有较高的检测速度,但检测精度较低。针对SSD算法对小目标检测精度不高的问题,研究者们做了一些改进工作。Lim等人[6]提出一种SSD改进方法,通过特征融合获取上下文信息,使用注意力模块使网络信息集中在重要部分,来提高小目标检测精度。吴天舒等人[7]利用深度可分离卷积、逐点分组卷积与通道重排提出轻量化提取最小单元,在保证精度的条件下,提高了算法运行速度。上述方法虽然提高了小目标检测精度,但是图像浅层网络特征信息尚未得到有效利用,仍有大量信息丢失。为有效利用浅层网络中的特征信息,进一步提高SSD方法的小目标识别精度,在此提出一种借鉴FPN[8]的思想来提高小目标检测精度的改进SSD算法。该方法使用转置卷积[9]进行上采样,借助空洞卷积[10]降采样来增大浅层网络的感受野,将浅层网络的特征图与深层网络的特征图进行特征融合,使浅层网络的位置信息与深层网络的细节语义信息融合得更好。最终,将特征图通过注意力机制,提升对关键信息的学习能力,实现对小目标的更准确的检测。
2 改进的SSD算法
提出的改进SSD算法是一种结合多尺度语义信息的浅层网络与深层网络融合的特征金字塔结构,使用了注意力机制来增强关键特征提取。这一策略能够丰富浅层网络与深层网络提取到的特征。
2.1 网络结构
提出的改进SSD算法网络结构如图1所示。该网络在原有SSD网络的特征层基础上,增加了一层VGG16网络中的75×75大小的池化特征层,称为Pool2,以弥补38×38大小特征图损失的一些浅层网络语义信息,从而包含更多的小目标的位置信息以及细节信息。将Pool2、Conv4_3层称为浅层网络,将Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2层称为深层网络。为了提高浅层网络对小目标的检测能力,将两个浅层特征层使用空洞卷积进行降采样。空洞卷积可以在不增大计算量的情况下增大卷积核的感受野,且保证该层特征信息不丢失。同时将Conv7、Conv8_2、Conv9_2进行转置卷积上采样,令高层语义信息特征图与低层语义信息特征图分辨率相同,以此增大感受野。分别在Conv4_3、Conv7、Conv8_2的特征层通过特征融合模块进行特征融合,进行多尺度融合。
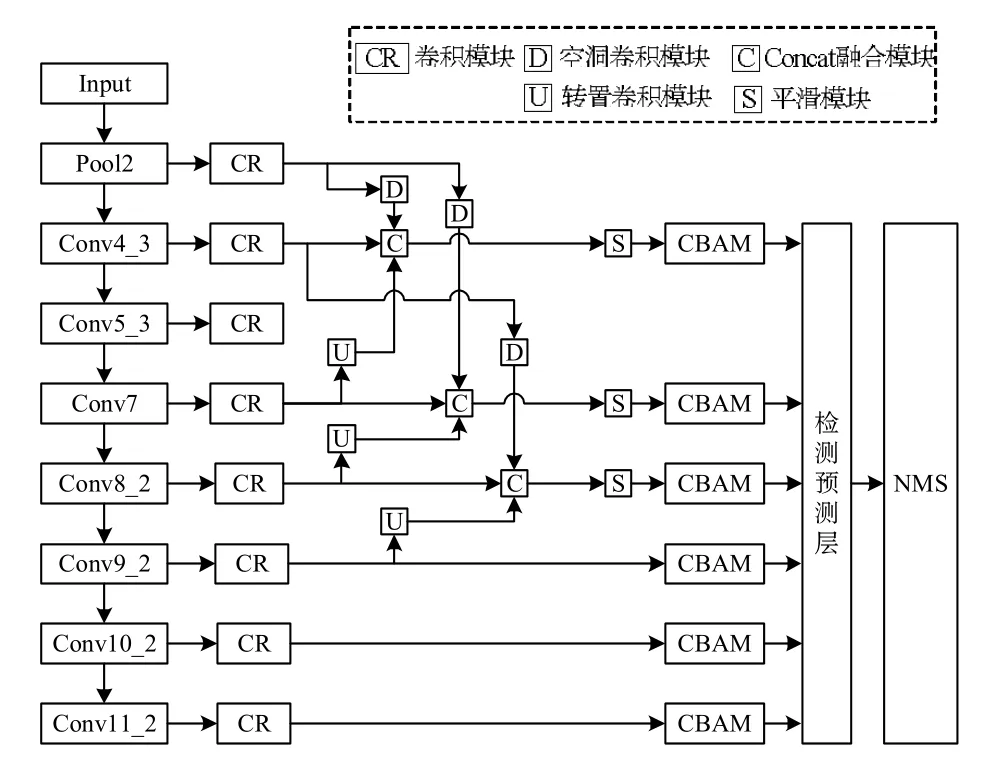
图1 改进算法网络结构
从Pool2到Conv9_2便是FPN中的自下而上的特征提取过程。从Conv9_2进行转置卷积是自顶向下的特征融合部分,将二者进行横向连接,就构成特征金字塔结构。通过这种融合方式可以将浅层网络中的位置信息与深层网络中的语义信息进行融合,使小目标有更好的特征表达能力。
由于深层网络的特征图语义信息已经很丰富,故将Conv9_2、Conv10_2、Conv11_2直接输出结果,获取细节信息。将得到的6个融合后的特征图通过6个3×3卷积层进行平滑,再将平滑后的特征图分别输入到CBAM[11]注意力模块中,接着进行回归预测,生成初步结果,最后通过NMS非极大值抑制算法滤除不符合条件的预测框,得到最终检测结果。
2.2 注意力模块
改进算法所使用的注意力机制CBAM(Convolutional Block Attention Module)如图2所示。它是一种结合通道注意力模块和空间注意力模块的注意力机制,将平滑后的特征图先后通过上述两个模块。
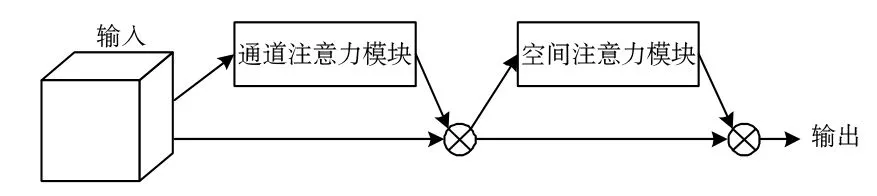
图2 CBAM注意力机制
通道注意力模块如图3所示。首先将平滑后的特征图做全局平均池化和全局最大池化,得到两个一维矢量;再将得到的结果送入一个共享网络,把得到的两个特征图逐个像素求和合并,经过一个激活函数以产生一个权重结果;最后将这个权重结果和平滑后的特征图相乘,得到缩放后的新特征图。
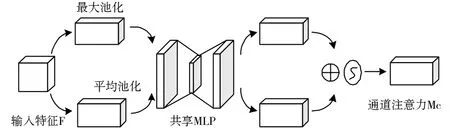
图3 通道注意力模块
空间注意力模块如图4所示。输入新特征图,先通过平均池化和最大池化得到两个特征图,并将两个特征图拼接在一起,经过激活函数得到一个新的权重系数,再将新的权重系数与新特征图相乘,得到最终缩放的特征图。
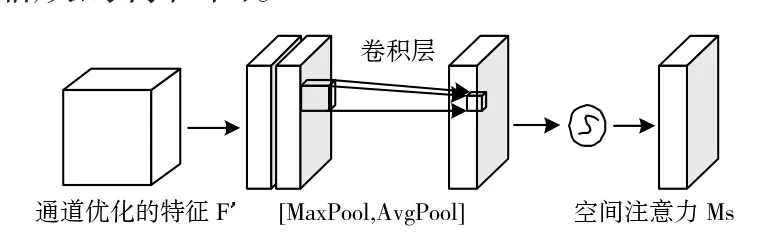
图4 空间注意力模块
2.3 特征融合模块
为了丰富上下文语义信息,使用的特征融合机制是有空洞卷积参与的浅层网络融合机制,如图5所示。这种融合机制包含正向卷积、转置卷积和空洞卷积三部分。正向卷积首先将特征图输入到大小为3×3的卷积层中,减少通道数,再经过ReLU激活函数;转置卷积将特征图先变成需要的分辨率大小,再通过ReLU激活函数;空洞卷积则是先利用空洞卷积进行降采样,再通过BN层和ReLU激活函数,最后将这三部分得到的特征图进行Concat通道拼接,然后通过3×3卷积和ReLU激活函数进行平滑,以产生最后的特征图。
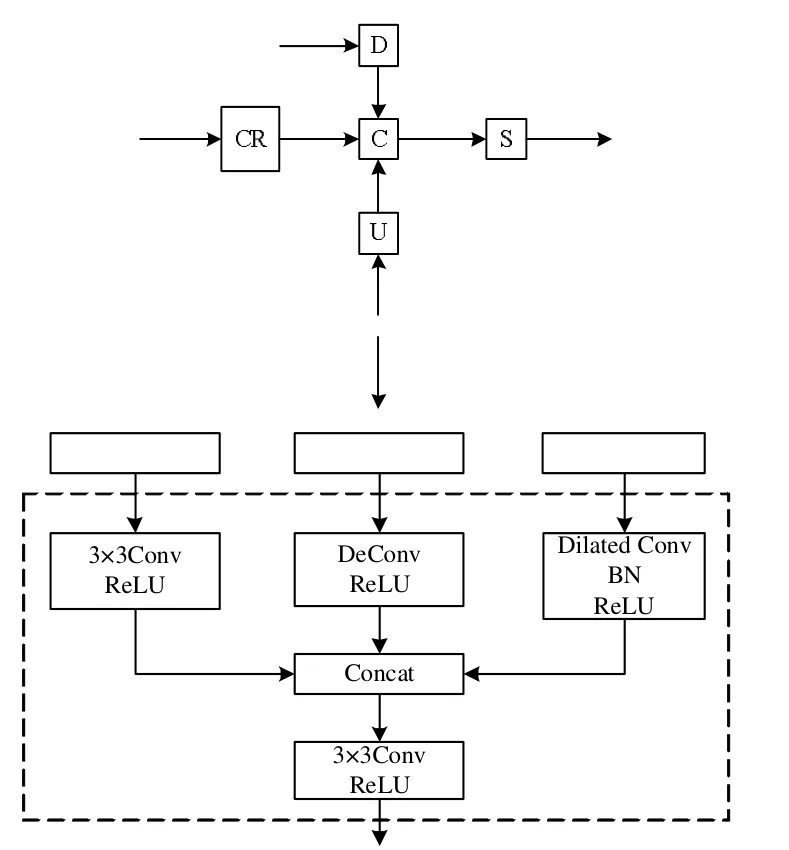
图5 特征融合模块
2.4 损失函数
改进算法的损失函数沿用SSD算法的损失函数,由分类损失函数和位置损失函数相加构成,整体损失函数公式如下:
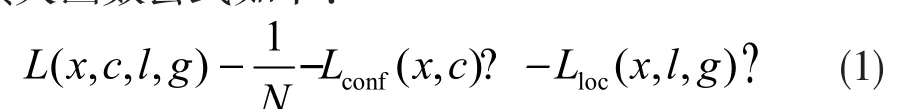
其中,N表示正样本匹配候选框数量,Lconf表示分类损失函数,Lloc表示位置损失函数,α通常设置为1,当N=0时,L为0,表示没有匹配的候选框。
位置损失函数由如下公式表示:
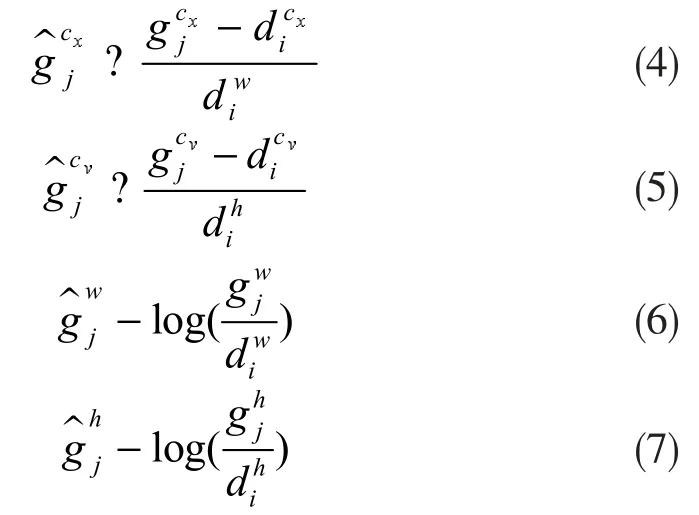
其中,xijk表示第i个预测框与第j个实际框关于类别k是否相匹配,匹配则值为1,不匹配则为0。ljm表示第i个预测框的位置,g^jm表示第j个预测框相对实际框的位置。k代表类别,cx、cy、w、h分别代表候选框偏移量的中心x/y坐标、宽和高。
3 实验与分析
为测试改进算法的性能,在下述条件下进行实验:Windows 10操作系统;Intel Core i5-9300HF处理器(主频2.40 GHz);NVIDIA GeForce GTX 1660 Ti显卡。编译环境为Torch 1.7.1、Torchvision 0.8.2、CUDA 10.1、cuDNN10.1、Python 3.8。
3.1 实验过程
实验用来进行模型评估的数据集选用PASCAL VOC 2007和PASCAL VOC 2012,再选用PASCAL VOC 2007 trainval和PASCAL VOC 2012 trainval数据集进行训练,二者均包含20个类别,共16651张图片。选用PASCAL VOC2007 test进行测试,共20个类别,4952张图片。数据的具体类别如表1所示。

表1 数据集类别
为了对改进的SSD算法进行模型评估,选用查准率(Precision,P)、召回率(Recall,R)、单类别平均精确率(Average Precision,PA)、所有类别的平均精确率PmA作为评价指标,其定义式如下:
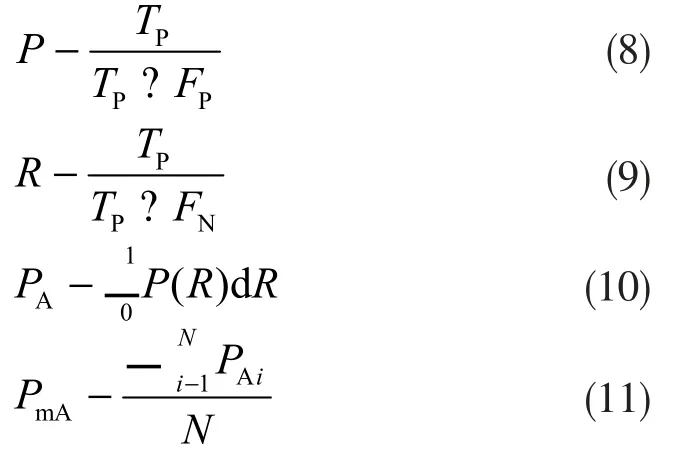
其中,TP为真正的正样本数,FP为假的正样本数,FN为假的负样本数,N为检测的类别数,P(R)为查准率和召回率构成曲线。
3.2 实验结果分析
为验证改进算法性能,在300×300分辨率下进行对比实验,为了使评估更加的全面,实验将沿用MS COCO数据集对物体大小的分类,将小于32×32的物体归为小目标,大于96×96的归为大目标,介于二者之间的归为中等目标,并采取IOU=0.5检测整体平均精度,采用IOU=0.5:0.05:0.95检测小目标的平均精度。为验证网络性能,将改进算法+VGG16网络与SSD+VGG16网络、SSD+ResNet50网络、Pool2+Conv4_3+Conv7融合+VGG16网络进行对比,实验结果如表2所示。
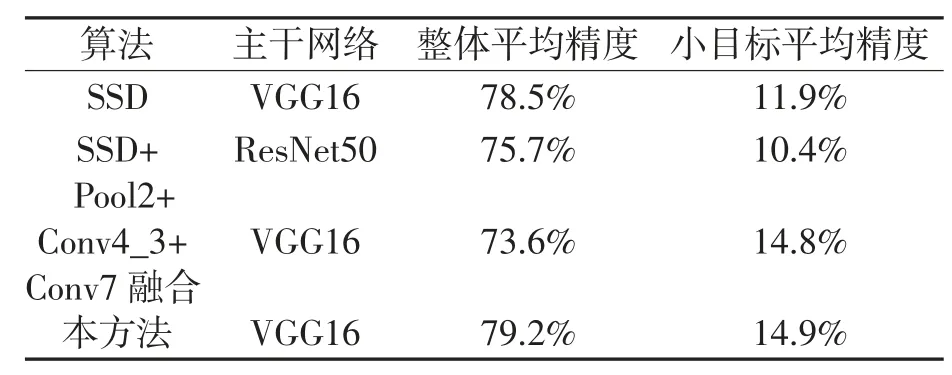
表2 算法性能比较
实验结果表明,Pool2+Conv4_3+Conv7融合相比原始SSD算法和在ResNet50网络基础上的SSD算法对小目标的检测精度分别提高了2.9%和4.4%。但对于整体的精度却下降了4.9%。经过本方法,可以在将小目标检测精度较原SSD算法提高3%的同时将整体的检测精度提高到79.2%,解决了Pool2+Conv4_3+Conv7融合只提高检测小目标精度而导致整体精度下降的问题。使用Conv7层网络进行融合,这一层相较于Pool2,Conv4_3已经损失了很多小目标位置信息以及其它细节信息,这是整体精度会出现下降的原因。
除了对算法的整体精度以及小目标的精度进行对比外,实验还对PASCAL VOC2007 test数据集当中的20个类别的单个类别精度进行了对比,结果数据如表3所示。
实验结果表明,本算法对11个类别的检测精度都是超过原SSD算法以及Pool2+Conv4_3+Conv7融合算法的,而其它9个类别的精度与原SSD算法的检测精度相差甚微,改进效果明显。
相应的部分检测结果如图6所示。其中,图6(a)与图6(c)未能将图中的相应对象都检测出来,说明对小目标的识别都不及改进算法效果好。

图6 小目标检测效果对比
4 结束语
针对原SSD算法对小目标检测精度低的问题,本算法在原始SSD算法的基础上将浅层网络与深层网络进行特征融合构成特征金字塔,并引入CBAM注意力模块,较原SSD算法在对小目标的检测能力上得到了一定提升。在后续工作中,将进一步完善浅层网络特征提取,研究如何在多尺度特征融合的情况下,解决模型的轻量化问题。
