开放科学数据集的统一发现平台研究进展
2022-07-02罗鹏程王继民
罗鹏程,王继民,聂 磊
(1. 北京大学信息管理系,北京 100871;2. 北京大学图书馆,北京 100871;3. 北京外国语大学区域与全球治理高等研究院,北京 100089)
1 引 言
大数据时代,科学数据的开放共享受到各方高度重视,“数据爆炸”问题正在显现。2018 年,国务院发布《科学数据管理办法》,明确了“开放为常态、不开放为例外”的科学数据共享原则[1]。随后,陕西[2]、湖北[3]、江苏[4]等十余省份陆续发布科学数据管理实施细则。国际上,美国国家科学基金会(National Science Foundation)要求项目申请时必须提交数据管理计划[5],澳大利亚推出国家数据服务[6],欧盟建设开放科学云[7]。各类研究机构也积极建设数据仓储,共享科学数据,如哈佛大学Dat‐averse、中国科学院科学数据云。在这一背景下,科学数据正不断积累。据DataCite 统计,截至2021年10 月,科学数据集的数量达到1000 多万;据Google 统计,互联网上数据集的数量已从2016 年的50 万快速增长到2020 年的2800 万[8]。随着科学研究转向数据密集型范式,许多学科对数据的需求十分强烈,基于共享的科学数据可支撑高质量研究成果产出[9],并且研究者越来越愿意共享和复用科学数据[10-11]。目前,科学数据集分散在众多异构的数据仓储之中,各数据仓储的元数据标准、数据内容存在较大差异。面对海量、多源、异构的开放科学数据集,如何高效地从中发现符合需求的有效数据正成为研究者面临的重要问题。
目前,科学数据集检索相关研究问题已受到许多学科领域的广泛关注。在图书馆学、情报学领域,研究者关注数据检索行为[12-14],DataCite、加拿大研究图书馆协会分别推出了科学数据集的统一发现平台DataCite Search、Federated Research Data Re‐pository(FRDR)。在计算机领域,2018 年信息检索 顶 级 会 议SIGIR (Special Interest Group on Infor‐mation Retrieval)和交叉综合领域顶级会议WWW(The Web Conference) 专门组织了数据搜索研讨会[15-16],Google Dataset Search 负 责 人Noy 受 邀 在2020 年数据库顶级会议之一SIGMOD 中作主旨报告[17]。在医学领域,美国国立卫生研究院资助成立了生物医学和医疗保健数据发现索引生态系统联盟(biomedical and healthcare data discovery index ecosys‐tem,bioCADDIE),由该联盟开发推出了数据集的统一发现平台DataMed[18]。在社会科学领域,德国GESIS - Leibniz-Institut für Sozialwissenschaften (莱布尼兹社会科学研究所)面向社会和经济科学推出了gesisDataSearch[19]。从2019 年开始,卡耐基梅隆大学还组织“面向数据发现与复用的人工智能研讨会”,推动人工智能技术在数据发现与复用中的应用[20]。近年来商业性数据集的统一发现平台也陆续推出,如Data Citation Index(DCI)、Elsevier DataS‐earch 等。
科学数据是国家重要的战略资源,目前国内对科学数据集的统一发现平台的研究和应用不足,阻碍了科学数据价值的释放。本文以对互联网上多源、异构、海量的开放科学数据集进行统一检索的发现平台为研究对象,对相关研究和应用进展进行梳理和总结,以期为进一步的研究和应用实践提供参考。
2 研究方法
2.1 概念界定
本文将科学数据与研究数据视为同义词,即面向研究分析目的而收集、观察或创建的数据,用于支持研究结论[21]。因此,本文所指科学数据不仅涵盖自然科学和工程技术,也包括社会科学、人文与艺术等学科。数据集是为特定目的而组织在一起的相关数据的集合[22],科学数据集则是指为研究分析目的而收集、观察或创建的相关数据的集合。本文中“开放科学数据集的统一发现”是指针对互联网上多源、异构、海量的开放科学数据集进行采集和组织,为用户提供统一的检索入口,帮助用户高效地发现所需要的数据。图1 给出了科学数据集的统一发现平台的功能示意。通过发现系统自动从众多数据仓储中采集数据,为用户提供统一的检索入口,避免了用户到每个仓储中检索所耗费的时间。
2.2 文献筛选
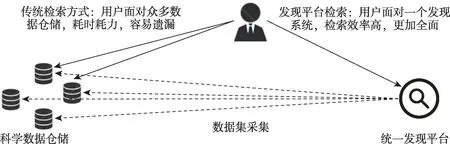
图1 科学数据集的统一发现平台功能示意
本文以“科学数据集发现”“scientific dataset discovery”作为查询语句,并使用“研究”替换查询中的“科学”,使用“检索”“搜索”替换“发现”,使用“research”替换“scientific”,使用“re‐trieval”“search”替换“discovery”。根据以上各种同义词替换策略的组合在中国知网、万方数据库和Web of Science 核心集中进行题名、关键词等字段的检索。通过以上查询获得的文献数量不多,为此本文还对检索条件进行放宽,去掉查询中的“科学”“研究”“scientific”“research”,或者使用“数据”“data”分别替换“数据集”“dataset”。从检索到的1000 多篇文献中筛选出与科学数据集的统一发现平台、科学数据集检索相关性较高的论文41 篇。同时,本课题组对科学数据集的统一发现平台进行了长时间的广泛调研,在谷歌及谷歌学术中检索与具体发现平台相关的论文、报告、博客、网页等。最终,本文共汇集77 篇核心论文进行综述。此外,还纳入了对相关内容进行补充的扩展性论文、报告、博客、网页等。
2.3 综述框架
国际上,已有许多科学数据集的统一发现平台陆续推出[23]。根据现有科学数据集的统一发现平台的构建模块[18-19,24],将相关主要研究问题分为四类:数据集采集、数据集组织、数据集检索、检索结果综合排序,如图2 所示。本文将以该框架为基础来组织全文内容。

图2 科学数据集的统一发现平台相关的研究问题
①数据集采集。互联网中资源数量庞大,种类繁杂,科学数据集在其中占比极小。如何从海量、分散的互联网资源中采集所需数据集,是对科学数据集进行统一发现的前提。②数据集组织。通过采集得到海量科学数据集的元数据,然而元数据标准众多,质量参差不齐,需要对不同来源的元数据进行融合统一,对元数据质量进行评估,并在此基础上补充和丰富元数据内容。③数据集检索。数据集作为一种新的信息对象,其检索特征有别于传统文献和网页搜索,相应检索方法正处于研究探索阶段。④检索结果综合排序。依据检索模型获得的数据集,通常按照主题相关性排序呈现给用户,然而研究表明用户对检索结果做出相关性判断时会考虑数据质量等诸多因素[12]。本文第3~6 节将分别对数据集采集、组织、检索和综合排序相关研究进行梳理和述评。
3 数据集采集
数据集主要由元数据和数据内容组成,由于数据内容较大,且可能存在访问限制,通常采集的数据均为元数据。
3.1 数据采集方法
依据采集策略的不同,本文将现有科学数据集的统一发现平台的采集方法分为三类:数据仓储向发现平台主动推送元数据,发现平台全网扫描并筛选数据集类型网页,发现平台定向采集数据仓储元数据。
(1)数据仓储向发现平台主动推送元数据:由发现系统提供统一的API(application programming interface)接口,各科学数据仓储在新增或更新数据集时,通过API 接口将元数据推送给发现系统。目前,这种数据采集方式仅在DataCite Search 中实现。DataCite 是科学数据领域最大的DOI (digital object identifier)注册代理机构,各个数据仓储在注册DOI 时,需要按照DataCite Metadata Schema[25]的要求提交元数据。因此,DataCite Search 通过数据仓储主动推送的方式采集了大量科学数据集元数据。
(2) 发现平台全网扫描并筛选数据集类型网页:由网页制作者依据特定标准对页面内容进行描述,并将描述元数据嵌入页面;发现系统采集网络中的页面,从网页中解析元数据,并筛选出数据集类型的网页。目前,这种数据采集方式仅在Google Dataset Search 中实现,主要依靠网页制作者在页面中嵌入的schema.org 或DCAT (data catalog vocabu‐lary)标记数据识别数据集页面。schema.org 由谷歌等搜索引擎公司建立,用于描述网页资源,帮助搜索引擎更好地理解页面内容。2013 年,schema.org增加了Dataset 类型用于描述数据集页面[26]。DCAT是W3C(World Wide Web Consortium)于2014 年发布的推荐标准,它是一个RDF(resource description framework)词汇表,其目的在于促进Web 上发布的数据目录之间的互操作性[27]。Google Dataset Search 依托谷歌强大的通用网页爬虫平台采集网页,解析页面中嵌入的元数据,从中筛选出使用schema.org 的Dataset 和DataCatalog,以 及DCAT 描述的元数据,构成谷歌数据集搜索的基础[24]。
(3)发现平台定向采集数据仓储元数据:由数据仓储提供元数据收割协议,发现系统评估、选择符合需求的数据仓储,并通过收割协议采集元数据。目前,这种数据采集方式应用最多,如DCI、DataMed、gesisDataSearch、Mercury 等。在 定 向 数据采集中,发现系统需要依据一定的标准遴选数据仓储。DCI 考虑了多种定性、定量因素来对仓储进行综合评价,包括仓储持久性和稳定性、资助情况、作者身份的多样性等,并且要求提供英文元数据[28]。DataMed 则以标准、互操作性、可持续性、整体质量、用户需求等作为数据仓储的选择标准[29]。此外,FAIRsharing 和DataCite 面向期刊论文支撑数据存储制定仓储评价标准[30-31],这些标准对发现系统选择数据仓储具有参考价值。在数据仓储选定后,需要依据收割协议采集数据。最常用的收割协议为OAI-PMH(Open Archives Initiative Protocol for Meta‐data Harvesting),例如,DCI[32]、FRDR(Federated Re‐search Data Repository)[33]、gesisDataSearch[19]、Mer‐cury[34]均采用该协议采集元数据。除了OAI-PMH外,一些发现系统会提供多种数据收割方式,例如,Research Data Australia提供直接收割、OAI-PMH收割、OGC CSW(Open Geospatial Consortium Catalogue Ser‐vice for the Web) 收 割、 CKAN (Comprehensive Knowledge Archive Network)收割四种方式[35]。
3.2 采集方法述评
不同数据采集方法各有特点,适用于不同场景和应用需求。表1 从采集效率、及时性、数据覆盖率、自动化程度、实现难度和应用数量六个角度给出了三种采集方法的对比情况。

表1 三种数据集采集方法对比
对于数据仓储主动推送的方法,通常会在数据集新增或更新时,由数据仓储按照统一的元数据标准,向发现系统推送元数据。因此,它具有采集效率高、数据更新及时、自动化程度高的优势。然而,通常情况下发现系统提供方对数据仓储提供方没有约束力,无法要求所有数据仓储都为发现系统推送元数据。因此,这种数据采集方式很难实现,实践中的应用数量很少。对于数据覆盖率,以Data‐Cite Search 为例,其中注册仓储数量达到2000 多个,覆盖了许多有影响力的科学数据仓储,但并非所有仓储都会注册DOI,数据覆盖率适中。
对于发现系统全网扫描的方法,由于需要采集海量互联网页面,而科学数据集页面仅占其中很小比例,并且网页抓取有一定的时间周期。因此,它具有实现难度大、采集效率低、更新有时延的特点,在实践中的应用数量很少,通常仅适合拥有海量Web 资源库的大型搜索引擎公司。这种数据采集方法基于爬虫获取数据,面对的元数据格式相对单一,自动化程度高。过去,采用schema.org 和DCAT描述页面的数据仓储较少,例如,Khalsa 等[36]在2017 年的调查显示,仅有13%的科学数据仓储使用了schema.org。不过现在已有越来越多的仓储提供schema.org 和DCAT 元数据,以Google Dataset Search为例,2020 年其收录数据仓储3700 多个[8],高于其他类型的发现平台,具有相对较高的数据覆盖率。
对于发现系统定向采集的方法,通常按照一定时间间隔采集指定数据仓储,其采集效率适中,有一定时延。由于数据采集过程中涉及数据仓储的评价与选择,新增仓储会因为数据收割协议和元数据标准的不同,需要人工参与采集程序的修改,如DataMed 新增数据摄入插件(ingest consumer)需要半天到数天的开发时间[18],因而其自动化程度不够高。定向采集的数据仓储通常限定在一定范围内(如特定的国家、学科),仓储数量偏向于中小规模,通常从数十个到上千个不等。相比于前两种采集方法,定向采集实现相对容易,采集效率适中,在实践中应用得最为广泛。
4 数据集组织
数据集的组织主要通过元数据实现,现有研究和应用主要关注多源元数据的融合,以及科学数据集的元数据质量分析与元数据信息丰富等研究问题。
4.1 多源元数据的融合
科学数据的元数据标准众多,包括通用元数据标准、学科领域元数据标准等数十种[37]。面对繁杂的元数据格式,发现系统需要设计一个统一的元数据模型,将不同来源的元数据进行融合。目前,主要有两种实现方法:仅考虑通用信息的多源元数据融合,以及同时考虑通用和学科特有信息的多源元数据融合。
1)仅考虑通用信息的多源元数据融合
不同元数据标准虽然各有特色,但都具有标题、创建者等通用信息。因此,最简单的多源元数据融合方法,便是将不同来源的元数据映射到一个通用的元数据模型。目前,绝大多数通用科学数据集的统一发现平台均采用该方法。例如,DataCite Search 的元数据模型为DataCite Metadata Schema[25],Google Dataset Search 的元数据模型与schema.org 的Dataset 元数据类似[24],英国Research Data Discovery Service 的元数据模型与DataCite Metadata Schema 相似[38-39],Research Data Australia 的元数据模型为RIFCS(registry interchange format - collections and servic‐es)[40],它们均为通用元数据模型。此外,一些面向特定学科的发现系统也会采用通用元数据模型。例如,gesisDataSearch 使用Dublin Core(DC)作为它的元数据模型[19]。
基于通用元数据模型的融合方法的优点在于其复杂度低,映射规则简单,易于实现,但是存在学科特有信息丢失的问题。Löffler 等[41]对生物多样性领域研究者的数据需求进行分析发现,通用元数据标准对用户需求的覆盖度较低,而学科领域元数据标准能更全面地覆盖用户需求。因此,仅考虑通用信息的多源元数据融合方法在满足学科个性化数据需求上存在一定的困难。
2)同时考虑通用和学科特有信息的多源元数据融合
为了保留更多信息,一些发现系统在设计元数据模型时会纳入学科特有信息。加拿大FRDR 以DC 为基础进行多源元数据的融合,制定了不同元数据标准到DC 的映射方案[42]。任何无法映射到DC的字段,将保留原始的元数据信息,这些特有的元数据也会被索引,并可做出定制化的搜索[33]。DataMed构建了DATS(data tag suite)元数据模型,该模型包括核心元素和扩展元素两个部分。核心元素较为通用,适用于任何类型数据集的描述;扩展元素用于特定学科数据集的描述,目前DATS 包括一个初始的面向生命、环境、生物医学领域的扩展元数据集合[43]。
引入学科特有信息的多源元数据融合方法的优点在于其可保留更多信息,有助于满足学科用户个性化的数据检索需求,提升检索效果。由于考虑了学科因素,会导致映射规则增多,模型复杂度上升,系统实现和维护难度加大。因此,该多源元数据融和方法通常在面向特定领域的科学数据集的统一发现平台中应用。
4.2 元数据质量与丰富
元数据是当前科学数据集检索最主要的依据,其质量的高低直接影响到数据集的发现效果。已有大量研究对科学数据集的元数据质量进行了分析,并在此基础上探索如何利用各种技术手段和外部资源来丰富数据集的元数据信息。
1)科学数据集的元数据质量
与传统文献信息的组织主要通过专业人员来对资源进行描述不同,科学数据仓库中的元数据主要由用户提供。由于缺乏控制,元数据普遍存在质量问 题。对Dryad[44-45]、BioSample[46]、BioSamples[46]、Gene Expression Omnibus[47]等科学数据仓储的分析发现,元数据存在错误、不一致、不规范等问题;一些平台还允许用户自定义元数据信息,使得元数据字段字存在重复、不一致等问题[46]。发现系统采集的元数据来自科学数据仓储,由于来源仓储的元数据存在缺失等质量问题,导致发现系统获取的元数据质量不高。对DataONE (data observation net‐work for earth) 分析发现,其元数据字段在标识、发现、评价、获取、集成五个方面的完整度均在70%左右或以下[48]。一些发现系统采集的元数据格式并非科学数据仓储底层使用的元数据模型,由于元数据格式转换等问题,采集的元数据质量降低。例如,Google Dataset Search 采集的元数据存在“可能出错的地方都会出错”的问题[24],DataCite 大量推荐和可选的元数据字段缺失严重[49]。
在构建科学数据集的统一发现平台时,由于元数据存在错误、不规范等问题,需要对其进行大量清洗和规范化,发现元数据中频繁出现的模式,制定相应规则来消减错误。例如,Google Dataset Search从schema.org 元数据的多个字段中提取文件格式、下载地址、DOI 标识符,对不同格式的日期进行规范化[24]。由于元数据存在信息缺失的问题,需要利用各种手段和外部资源来对其进行补充,丰富数据集的描述信息。
2)科学数据集的元数据丰富
目前研究和应用中对元数据丰富的探索主要包括:提取元数据中的重要实体、获取数据集的关联文献、利用外部资源来补充数据集信息等。
数据集元数据中包含一些重要实体,通过提取这些实体,可为后续数据集检索功能优化奠定基础。Lafia 等[50]从标题、描述和关键词中识别主题词和地理位置,并将识别的实体链接到美国国会图书馆规范主题词和DBpedia 地理位置中。gesisDataSe‐arch 从元数据中识别出命名实体,并使用Open‐StreetMap 来确定地名实体的坐标位置[19]。DataMed拥有生物医学命名实体识别模块,用于为每个数据集提取一些语义概念集合[18]。将元数据中的重要实体提取出来,并关联到外部的语义概念资源库,可为后续基于概念、地理位置进行检索提供必要信息。
数据集的关联文献可用于描述数据集的使用环境,关联文献的文本信息可提供更多检索点,同时关联文献也可用于评估数据集的价值。目前,数据集关联文献的获取主要包括两种方法:通过DOI 来识别文献对数据集的引用,以及通过文献全文挖掘识别数据集标题和链接地址。基于DOI 的方法较为准确可靠,在实际应用中使用较多。例如,Google Dataset Search 通过DOI 实现了数据集与谷歌学术中的文献的关联[51],DataCite 通过在文献全文中搜索匹配DOI 来实现与数据集的关联[52]。由于数据引用不规范,文献中大量的数据引用并没有DOI,而主要通过数据集标题、URL(uniform resource locator)地址等实现引用。通过对文献全文进行分析挖掘,可提取该引用信息。Ghavimi 等[53]通过人工参与数据集标题与文献全文中句子的匹配与判断,半自动地提取对数据集的引用。Lu 等[54]利用机器学习分类方法,以及数据集标题与URL 链接在不同文献中的共现情况,来识别数据集标题及其对应的链接。由于通过文献全文挖掘识别数据集关联文献的方法不能实现完全准确,其在实践中应用较少。
此外,一些研究者还探索了利用外部资源来补充数据集信息。由于数据集的描述信息中可能会缺失研究领域等重要信息,而这些信息可能在来源数据仓储的“关于”页面中存在,因此Karisani 等[55]利用该信息补充对数据集的描述。Wei 等[56-57]从生物医学领域数据集中识别出连接到基因表达数据库(Gene Expression Omnibus)的序列记录,收集序列记录的摘要、标题、总体设计三个字段的信息用于丰富数据集的描述。Singhal 等[58-59]使用数据集标题在学术搜索引擎中进行检索,将检索出的文献标题、主题词作为数据集的扩展上下文信息。
4.3 数据集组织方法述评
在多源元数据融合方面,由于采集的元数据都主要映射到一个数据通用元数据模型,导致很多数据集的发现平台无法提供更加精细的检索功能。例如,除了查询词检索外,DataCite Search 仅有注册年、资源类型、隶属机构三个字段的筛选功能。同时,映射过程中学科特有信息的丢失,会影响查询匹配的效果。虽然DATS 构建了包含通用和学科领域信息的元数据模型,但目前只有特定学科的扩展信息,本质上仍是领域元数据模型。因此,有必要对现有各个学科领域的元数据模型进行分析,建立一个通用的、能涵盖各学科领域的统一元数据模型。在模型构建中,除了考虑国际上主流的元数据标准,也应将国内相关元数据标准(如中国科学院制定的生态科学数据元数据、土壤科学数据元数据等标准[60])作为重点进行考虑。
在元数据质量与丰富方面,现有研究主要通过人工统计分析来发现元数据中存在的质量问题,有必要建立一个面向科学数据集发现平台的元数据质量评价体系及自动化评价方法,对采集到的元数据质量进行评估,并用于检索排序中(优质数据集可能会有更丰富的描述信息)。在数据集和文献关联识别中,现有应用主要通过DOI 来识别关联关系,但绝大多数论文对数据集的引用缺乏DOI 信息。目前通过文献全文来挖掘识别数据集引用的研究还很少,相关研究也仅在特定学科的小批量数据集上进行方法探索,识别精准度不够高。此外,当前发现系统都只采集数据集的元数据,缺乏对数据集内容的挖掘利用。据本课题组调研,目前仅Chen 等[61-62]利用机器学习方法从数据集中表格数据内容生成模式标签,用来补充元数据信息。事实上,数据集本身也包含丰富的信息,如数据文件名称、说明文档、数据内容等,这些信息能够被部分采集到(如文件名称、说明文档),把这些信息补充到元数据中,将有利于数据集的检索匹配。
5 数据集检索
目前,数据集检索相关研究主要在传统信息检索模型的基础上,通过查询扩展来提高召回率,通过相应排序优化算法来提高检索精度。
5.1 查询扩展方法
自然语言中普遍存在同义词、近义词、概念包含等关系,而数据集检索中的用户查询很短[63-65],通常不会包含其信息需求的所有词汇表达。为了提高科学数据集检索的召回率,已有大量研究对查询扩展方法进行了探索,包括基于本体的查询扩展、基于搜索结果的查询扩展、基于词向量的查询扩展,如表2 所示。
1)基于本体的查询扩展
本体资源库中的同一概念的不同表达、上下位概念等关系可以对用户查询进行有效扩充。目前,基于本体的查询扩展主要应用在面向特定学科的数据集检索研究中。例如,仪表领域[66]、林业领域[67]、生物医学领域[18,55-57,68-70]、社会科学领域[71]、生态学领域[72]。一些科学领域在长期的数据管理实践中,会更倾向于使用领域叙词表中的词汇描述数据集,这使得通过领域本体可以更好地检索数据集。例如,Porter[73]对生态学领域的科学数据进行分析,发现相比于一般的关键词,在LTER(long-term eco‐logical research)叙词表中的词能够更好地检索数据集。此外,多语言版本的本体资源还能实现跨语言检索,例如,Vanderbilt 等[72]使用EnvThes 检索多语种的生态学数据集。目前,基于本体的查询扩展方法在一些学科领域数据集的发现平台中已有应用,如DataMed[18]。由于本体的研制成本高,缺乏足够精细和覆盖面的通用本体资源,限制了该方法在通用数据集搜索中的应用。
2)基于搜索结果的查询扩展
搜索结果中会包含一些与查询相关的词汇,这些相关词汇可用于查询扩展。目前该类方法主要利用两类搜索结果:一类是来自外部检索系统的搜索结果,例如,Karisani 等[55]使用商业垂直搜索引擎获取的维基百科和NCBI (National Center for Bio‐technology Information)网站检索结果中的词来扩展查询,Wei 等[56-57]基于谷歌检索的结果来扩展查询;另一类是来自内部数据集检索系统的搜索结果,这类方法也被称为伪相关反馈,主要使用检索结果中的文本内容来扩展查询[55,69,74]。由于数据集检索中包含时间、地理位置的查询的占比高[64-65,75],一些学科领域数据集的时空信息对于相关性判断十分重要。为此,Takeuchi 等[76-77]提出了基于时间和空间的伪相关反馈方法,来获取与初始数据集检索结果具有相似时空分布的数据集。与本体查询扩展方法相比,基于搜索结果的查询扩展不依赖于人工构造的资源库,能够适应不同的应用领域。但检索结果具有一定数量的噪声词,会降低其查询扩展的质量。
3)基于词向量的查询扩展
词向量能够表达词汇之间的语义关系,已有研究者将其应用于科学数据集检索的查询扩展之中。例 如, Teodoro 等[78]、 Wang 等[79]基 于word2vec,Scerri 等[70]、Cieslewicz 等[74]基于fastText 训练 获 得词向量对查询进行扩展。词向量可以基于不同语料文本训练得到,如数据集的元数据、科学文献数据,不同语料训练得到的词向量会影响查询扩展的效果。Teodoro 等[78]在bioCADDIE、 PMC (PubMed Cen‐tral)、Medline 三个语料上训练word2vec,结果显示在Medline 上训练的词向量效果最优。此外,通过不同模型获得的词向量,质量也有所不同,Scerri等[70]和 Cieslewicz 等[74]研 究 发 现 fastText 较word2vec、GloVe 具有更优的效果。与本体方法相比,基于词向量的查询扩展方法能够适应不同的应用领域,只要提供足够的领域文本,便可以自动获取高质量的词向量。

表2 查询扩展方法
5.2 排序优化方法
为了提高科学数据集检索的精度,一些研究将检索过程分为两个阶段。在第一阶段,使用BM25等高效的检索方法获取候选的相关数据集,这一阶段通常会进行查询扩展,以提高召回率。在第二阶段,取第一阶段排名靠前的数据集,使用更加精细的方法对数据集的相关性重新评分。目前,第二阶段检索结果排序优化主要包括两类方法。一类是基于启发式规则计算数据集的相关性,例如,Teodoro等[78]对查询和数据集自动分类,将与查询类别相同的数据集的得分进行提升;Wang 等[79]统计数据集元数据中与查询具有相同实体的数量,将实体数量多的数据集得分进行提升;Wei 等[56-57]考虑查询中不同词的重要性,使用伪顺序依赖模型(pseudo se‐quential dependence,PSD)对数据集的相关性重新评分。另一类是使用机器学习方法从训练数据中学习排序规则,例如,Karisani等[55]基于手工制定的特征,使用MART(multiple additive regression trees) 学习排序算法对检索结果重新排序。目前,由于科学数据集检索领域缺乏大规模的标注数据,学习排序方法效果不佳,而基于启发式规则的检索结果优化方法不需要训练数据,因而研究中应用得相对较多。此外,一些研究还利用代数的方法来提升检索效果,例如,刘春蔚等[80]利用潜在语义索引来检索数据集。
5.3 检索方法述评
现有科学数据集检索系统主要依赖传统信息检索模型,对科学数据本身特性的挖掘不够。在科学数据集的统一发现平台中,DataMed[18]、gesisDataS‐earch[19]、DataCite Search[81]基 于ElasticSearch,Else‐vier DataSearch[82]、Mercury[83]基于Solr 实现数据集搜索,相应的检索模型基本都为经典的向量空间模型、概率模型等。在科学数据集检索方法研究中,也都主要在传统信息检索模型的基础上,通过查询扩展等方法来优化检索结果。相关用户研究表明,科学数据集检索与文献和网页检索存在差异[84-86]。例如,查询词非常短[63-65,75],包含更高比例的数字、时间、地理位置等信息[64-65,75],元数据和数据内容在查询匹配中都具有重要的作用[87]。目前,科学数据集的检索主要基于元数据文本匹配,对查询中时间、空间等特性关注度不高。
查询词不一定能有效地表达用户数据需求,目前仅少量研究对非关键词检索模型进行了探索。对于一些科学领域,使用数据范围(如水温、时间、空间范围)能更好地表达用户需求。Megler 等[88-90]构建了Data Near Hear 系统,使用基于距离的指标来衡量查询范围和数据集范围的相似度,据此来检索排序海岸带观察数据集。现有数据集检索系统主要基于倒排索引来检索匹配元数据文本,对其他数据结构检索的探索较少。Zhang 等[91]研究探索了适合不同类型查询(字符串、数字)的最优数据结构(如哈希表、Trie、自平衡搜索树等)。对于特定学科领域,科学数据的同质性更高,用户学科个性化数据需求更多,因而有必要寻找更适合学科用户需求的信息检索模式,提高数据集检索的效果。
测评数据对于检索模型的比较和发展具有重要的作用,现有科学数据集检索研究领域缺乏高质量、大规模的测评数据。据本课题组调研,目前仅bioCADDIE 组织了生物医学领域数据集检索挑战赛[92],并公开其数据集[93],但是该数据集的标注数量非常有限。当前,深度学习方法在文档检索领域有较多的研究和应用,如BERT (bidirectional en‐coder representation from transformers)排序模型取得了比传统检索方法更优的效果。由于深度学习模型需要大规模标注数据,现有测评数据集无法满足深度学习模型的训练要求。因此,需要进一步加强科学数据集检索领域高质量、大规模测评数据的建设,丰富通用领域、各个学科领域可用的测评数据集。
6 检索结果综合排序
在第5 节中,检索结果排序主要依据数据集与用户查询的主题相关性,已有研究表明,用户会基于许多因素对科学数据集的相关性进行判断。本节将对科学数据集检索综合排序中的相关性判据(relevance criteria)及排序方法研究进行梳理和总结。
6.1 相关性判据
对于科学数据集检索系统返回的结果,用户会根据一定的评价标准来判断其是否满足需求。目前,国内外已有学者对科学数据集检索中的用户相关性判据进行了探索,表3 给出了现有研究中提及较多的相关性判据。
在这些判据中,主题相关性最为重要[94-95]。用户主要通过数据集元数据中的标题、摘要、关键词等信息来判断数据集是否主题相关,部分用户会在查看数据内容后做出最终判断。除主题相关性外,数据集的可获得性、质量、权威性也被国内相关研究提及较多[12,94-102]。科学数据集的开放程度不一,如果数据无法或者难以获取,即使主题相关性很高对用户来说也不具有价值。Gregory 等[101]通过用户调查发现,73%的用户认为易于获取重要或者非常重要,赵华等[94]通过用户访谈发现可获取性的重要性仅次于主题相关性。科学数据本身的准确度和有效性直接影响到研究结论,因而数据集的质量对于相关性判断非常重要。张贵兰等[97]通过访谈发现,数据集质量出现的频次位于第二位,仅次于主题性;而通过问卷调查发现质量的重要性排名第一。权威性在数据集相关性判断中也具有重要的地位,它本质上反映的也是数据集的质量,来自高权威性作者和机构的数据集,能使用户相信其具有较高的质量[102]。Gregory 等[101]通过用户调查发现,71%的用户认为数据来源的声誉重要或非常重要。张贵兰等[97]通过问卷调查发现,权威性的重要程度排名第三,仅次于质量和主题性。除以上相关性指标外,时效性、可理解性、新颖性、便利性、规范性、可用性、全面性等指标在研究中也有较多的提及。此外,用户相关判断依据会随着学科特点而变化,Gregory 等[12]研究发现天文学、地球和环境科学、生物医学、田野考古、社会科学的相关性判据都有所不同。
6.2 综合排序方法
目前,科学数据集的统一发现平台中的检索结果主要基于主题相关性排序,对科学数据集的综合排序方法的研究还比较少,仅在少量相关性判据上进行了研究和应用探索。在数据集质量方面,Google Dataset Search 在检索结果排序中引入了元数据质量因素[24]。在数据集权威性方面,藤常延等[103]引入HITS(hyperlink-induced topic search)算法,黎建辉等[104]和腾常延[105]引入PageRank 算法来衡量数据集的重要性。Google Dataset Search 引入数据集所在网页的重要性对检索结果进行排序[24]。在数据集的可获取性方面,Research Data Australia 和Google Datas‐et Search 分别提供了获取(开放、有条件开放、受限)、使用授权(允许商业用途、不允许商业用途)的分面筛选功能。
此外,一些研究利用计量方法对数据集质量进行评价,这对于科学数据集的综合排序也有参考价值。传统图书情报学领域对文献等学术成果质量的评价主要采用基于引用的指标,DCI 中可提供科学数据集的引用量。然而,当前科学数据引用不规范,数据集引用量极低。因此,一些研究探索利用替代计量指标来对数据集的质量进行测度。李龙飞等[106]通过获取地球系统科学数据共享平台中的使用数据来测度科学数据集的价值。在国外,加州数字图书馆、公共科学图书馆(Public Library of Sci‐ence,PLoS)、地球数据观测网构建了Making Data Count 服务,通过基于PLoS 的文章级计量工具,为科学数据集提供来自CiteULike、Twitter 等13 个数据源的替代计量指标[107]。

表3 相关性判据
6.3 综合排序述评
现有研究对科学数据集检索结果综合排序中的相关性判据进行了较多探索,但是缺乏对相关性判据量化方法的研究。目前,Google Dataset Search 在数据集排序中引入网页重要性排序指标,但是数据集所在页面常位于“长尾”部分且缺乏相互链接,排序差异通常不具有意义[24]。DCI 虽然包含数据集的被引情况,但当前科学数据引用不规范,绝大多数数据集都不具有引用量。替代计量指标数据的收集难度大,现有研究还处于初步探索阶段。前述相关研究主要是在数据集的质量和权威性方面进行探索,其他如时效性、可用性等大量非主题相关性判据还缺乏关注。因此,需要进一步加强相关性判据的量化方法研究。
现有研究对用户相关性判据的探索都主要采用用户问卷调查、访谈等方式获取数据,这些研究方法有助于得到可能影响排序的相关性指标,但是不能准确、可靠地分析出相应指标如何影响检索结果排序的质量。对检索结果综合排序的研究,需要以实际应用系统真实的用户需求和用户交互的详细日志为基础,通过控制变量,能更准确有效地分析出各相关性判据对检索效果的影响。由于研究者很难接触到发现平台的后台数据,因此还需要加强公开可用的科学数据集搜索日志数据集的建设,以促进研究者对真实用户行为和相关性判据的深入分析。
7 总 结
随着开放科学和开放获取运动的发展,科学数据的共享与复用受到重视,互联网上科学数据集的数量迅速增长。为了帮助研究者从多源、异构、海量的科学数据中快速地发现所需数据,科学数据集的统一发现平台应运而生。本文对国内外科学数据集的统一发现平台相关研究与应用实践进行了广泛调研,依据现有发现平台的构建模块,分别从数据集采集、数据集组织、数据集检索、检索结果综合排序四个方面总结现有研究进展。总体来看,现有研究已经对科学数据集采集、组织、检索和排序方法进行了广泛的研究,有效地推动了科学数据集的统一发现平台的建设。
欧美发达国家非常注重科学数据集的统一发现平台的构建,已经建立了一批研究原型和应用系统,包括:涵盖多个国家、多个学科领域的通用发现平台,如DataCite Search、Data Citation Index、Else‐vier DataSearch、Google Dataset Search;面向特定国家的发现平台,如澳大利亚Research Data Australia、加拿大Federated Research Data Repository、英国Re‐search Data Discovery Service;面向特定学科的发现平台,如生物医学DataMed、社会科学gesisDataSeach、地球与环境科学DataONE。国内对科学数据集的统一发现平台的研究相对匮乏,实践应用中也缺少收录范围足够广的发现平台,仅有中国科技资源共享网、中国科学院科学数据云提供数据集的统一发现服务。前者仅收录受国家资助的20 个理工科数据仓储,后者为机构级的发现平台。因此,我国还应继续加强科学数据集的统一发现平台的建设力度。
