Multi-Feature Fusion-Guided Multiscale Bidirectional Attention Networks for Logistics Pallet Segmentation
2022-07-02WeiweiCaiYapingSongHuanDuanZhenweiXiaandZhanguoWei
Weiwei Cai,Yaping Song,Huan Duan,Zhenwei Xia and Zhanguo Wei,★
1School of Logistics and Transportation,Central South University of Forestry and Technology,Changsha,410004,China
2Graduate School,Northern Arizona University,Flagstaff,AZ 86011,USA
ABSTRACT In the smart logistics industry,unmanned forklifts that intelligently identify logistics pallets can improve work efficiency in warehousing and transportation and are better than traditional manual forklifts driven by humans.Therefore,they play a critical role in smart warehousing,and semantics segmentation is an effective method to realize the intelligent identification of logistics pallets.However,most current recognition algorithms are ineffective due to the diverse types of pallets,their complex shapes,frequent blockades in production environments,and changing lighting conditions.This paper proposes a novel multi-feature fusion-guided multiscale bidirectional attention (MFMBA)neural network for logistics pallet segmentation.To better predict the foreground category(the pallet)and the background category(the cargo)of a pallet image,our approach extracts three types of features(grayscale,texture,and Hue,Saturation,Value features)and fuses them.The multiscale architecture deals with the problem that the size and shape of the pallet may appear different in the image in the actual,complex environment,which usually makes feature extraction difficult.Our study proposes a multiscale architecture that can extract additional semantic features.Also,since a traditional attention mechanism only assigns attention rights from a single direction,we designed a bidirectional attention mechanism that assigns cross-attention weights to each feature from two directions,horizontally and vertically,significantly improving segmentation.Finally,comparative experimental results show that the precision of the proposed algorithm is 0.53%–8.77%better than that of other methods we compared.
KEYWORDS Logistics pallet segmentation;image segmentation;multi-feature fusion;multiscale network;bidirectional attention mechanism;HSV;neural networks;deep learning
1 Introduction
The recent rapid development of e-commerce has promoted the prosperity of the logistics industry,accompanied by a demand for logistics that has steadily increased [1,2].The logistics industry is one of the industries with the fastest growths in personnel.Traditional logistics methods [3,4] can no longer meet the fast-paced needs of current society.Smart logistics has emerged to adapt to these changing needs [5–7],and with the rapid development of artificial intelligence[8–10],smart logistics research has expanded toward automation.The traditional logistics model requires considerable human and material resources,which can solve employment problems to a certain extent.However,current smart logistics needs to reduce high labour costs through automation while solving the shortage of labour [11] as it shifts to other industries.Automated equipment can improve warehousing,material handling,packaging,and distribution efficiency while reducing the error rate.Automated forklifts play a key role in smart logistics,and the accuracy of automated forklifts needed to identify logistics pallets determines their work efficiency and error rates.
Traditional forklift use in storage-oriented activities requires that goods be handled manually,requiring workers to ensure the accuracy of handling at all times.However,the enormous daily flow of goods and long-term repetitive operations exhaust workers,leading to workers forking the goods and even causing safety hazards.Goods are managed in storage stacked on pallets.Accurate identification of logistics pallets can enable automated forklifts to transport materials quickly and efficiently,saving time and significantly reducing logistics costs [12].Traditional image processing technology cannot provide the performance required for high-precision segmentation [13] and recognition of logistics pallets;so,semantic segmentation is being applied to the image segmentation of logistics pallets to meet these performance requirements.
Liu et al.[14] applied the YOLACT deep learning approach used in artificial intelligence to investigate the detection and segmentation of pallets in the carriage and achieved competitive segmentation performance.Jia et al.[15] combined the Otsu algorithm and the marker watershed algorithm to achieve image segmentation of pallet contours,which provided reference values for designing a warehouse robot for wooden pallet visual inspection by reducing the influences of the surrounding environment and the pallet pattern.Zhao et al.[16] designed a novel GPU-based mean shift algorithm that quickly achieved unsupervised segmentation and tracking of instances.Cui et al.[17] proposed a colour feature-based visual segmentation method that obtains pallet colour feature samples from images in the work environment and then applies morphological filtering,Sobel edge detection,and Hough transform algorithms to recognize the pallets.For pallet detection,Chen et al.[18] proposed converting the colour image from RGB space to Hue,Saturation,Value (HSV) and YUV spaces and then using the camera space model to determine the location of the pallet relative to the forklift,thus establishing the relationship between the image space and the real-world space.However,these colour-based approaches are vulnerable to interference from non-simple backdrops.The Haar-based Adaboost approach,according to Syu et al.[19],uses the AS-for-pallets algorithm to detect pallets.In addition,Seelinger et al.[20]presented mobile camera space manipulation (MCSM),a visual guiding control system to help forklift drivers.
In summary,vision-based detection methods [21–23] can effectively detect pallets against an image background.However,there is still a lack of relevant research on the precise segmentation of pallets,and accurate pallet segmentation [24] depends on whether automatic forklifts can fully automate loading and unloading.Therefore,we developed a multi-feature fusion-guided multiscale bidirectional attention (MFMBA) neural network for logistics pallet segmentation.First,multifeature extraction and fusion make up for the shortcomings of vision-based methods that are easily misled by the background.Second,in an actual complex environment,the sizes and shapes of pallets in the same image may be different,which makes feature acquisition difficult,but the multiscale architecture can extract more semantic features,thereby enhancing the feature mining capabilities of the segmentation model.In addition,the bidirectional attention mechanism [25]assigns bidirectional attention weights to each feature,which further improves the segmentation performance of the model.
These are the study’s principal innovations:
(1) This paper proposes an MFMBA network for logistics pallet segmentation.Our study has achieved competitive segmentation performance on datasets in real-world production environments.
(2) To better predict the foreground category (the pallet) and the background category (the goods) in an image,we extract the grayscale,texture,and HSV features from the pallet image and then fuse them using a feature concatenation strategy.
(3) Our novel bidirectional attention mechanism assigns weights to each feature from two directions (horizontally and vertically),which is better than traditional attention mechanisms that only assign attention weights from a single direction.
The remainder of the paper is laid out as follows: Sections 2 and 3 describe related work and explain the theoretical basis for the proposed algorithm.The comparison and ablation experiments are described in Section 4,and we present our conclusions in Section 5.
2 Related Work
2.1 Image Segmentation
The process of assigning a label to each pixel in an image so that pixels with the same label have similar characteristics is known as image segmentation [26,27].Image segmentation can be defined using the concept of set: assuming that the entire digital image is represented by setR,image segmentation can be understood as dividingRinto regionsR1,R2,...,Rnand all subregions meeting the following conditions:

whereQ(Ri)is an attribute of the pixels of the setR,∅indicates the empty set,∩is the intersection of sets,and ∪indicates the union of sets.If the union ofRiandRjforms a connected set,the two areas are defined as adjacent.It can be seen from Eq.(1) that after segmentation,each pixel in the image has a category attribute,and the pixels in any sub-region obtained after segmentation are all connected to four or eight other pixels.In addition,the pixels have one and only one category attribute,that is,sub-regions do not intersect,and two adjacent regions have different attributes.
During image processing and analysis,only a small portion of the image is usually examined.As a result,to study image data,you must first identify and extract the portion of interest from the entire image.The target is then analysed on this basis.Image segmentation is an essential step in the intelligent identification of logistics pallets.
2.2 Attention Mechanism
The attention mechanism [28,29] originated from the study of human attention.Due to the limitations on our information-processing capabilities,humans selectively focus on part of the information they receive.This is also the ability that we need the model to have when receiving and learning a large amount of information.In mathematical terms,attention is learning a set of weight coefficients through the model independently and dynamically assigning this series of weights to each area of the information received by the model.The attention mechanism is widely used in neural networks,especially in image segmentation tasks.The principle of the attention mechanism is shown in Fig.1.If the input variable is set toX=[x1,x2,···,xn],the equation for calculating the attention distribution is as follows:

whereαiis the weight of attention distribution corresponding to thei-th input variablexi,which is also a probability distribution and satisfies Eq.(2).h(xi,p)is called the attention score of thei-th input variable,which is determined byxiand a pre-set vectorp.Common attention scoring methods include bilinear scoring and dot product scoring;their calculation equations are as follows:

After obtaining the attention distribution,multiply the input variablexiand the corresponding attention distributionai,and then sum them as follows:

3 Methodology
The overall architecture of the proposed MFMBA algorithm is depicted schematically in Fig.1.This paper extracts the HSV feature,grayscale feature (GF),and texture feature (TF)from logistics pallet images,applies a feature-stitching strategy for feature fusion,and inputs the fusion features to the proposed multiscale bidirectional attention network to extract deep features.The sigmoid function is then used to achieve semantic segmentation of the logistics pallets.The MFMBA algorithm is discussed in detail in the following sections.
3.1 Multi-Feature Extraction
To improve segmentation accuracy,we first extract the TF,GF,and HSV feature from the pallet image to better distinguish the foreground category (the pallet) from the background category (the cargo).
Texture features:Texture is an important distinguishing feature on the surface of an object.When the image is transformed into different brightnesses and colours,the pixels follow a specified rule and undergo near-periodical changes.Texture characteristics can effectively deal with logistics pallet images in various light environments.The calculation equation for TF extraction is as follows:

where(xc,yc)is the central pixel,icrepresents the brightness of the point,ipis the brightness of the adjacent pixels,andsrepresents the Sigmoid function.

Figure 1:The architecture of the proposed MFMBA algorithm
The basic principle of the local binary pattern (LBP) is that a particular pixel is centred;then,its value is compared with other pixel values in its 3×3 window.Every compared pixel value greater than that of the center point equals 1;otherwise,it is 0.Thus,a 3×3 window provides eight binary numbers and converts the binary to decimal to obtain the LBP code,which represents the texture.The LBP is shown schematically in Fig.2.
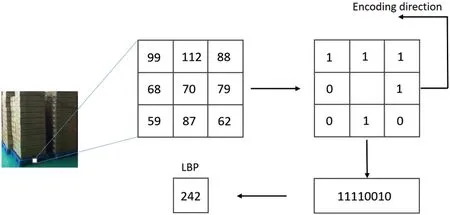
Figure 2:Schematic diagram of an LBP
Grayscale features:Grayscale uses black tones to represent objects;black is used as the reference colour,and blacks of different saturations are used to display the image.Each grayscale image has a brightness value from 0% (white) to 100% (black).Because it has less redundant information,grayscale improves image segmentation.The calculation equation is as follows:

whereR,G,andBrepresent the three-channel colours of the logistics pallet image.
HSV features:The HSV colour space,also known as the hexcone model,was created by A.R.Smith in 1978 based on the intuitive characteristics of colours.Hue (H),saturation (S),and lightness (L) are the colour parameters in this model (V).We must first convert the red,green,and blue coordinates of a colour to real numbers between 0 and 1 before using RGB to represent them.The following are the calculation formulas:

Next,we calculate the values of H,S,and V as follows:

RGB features are output as HSV features using the equation above.The new output vector block will be used as a feature sequence in our MFMBA model.Furthermore,the calculation result may containH<0.Hrequires additional calculation processing at this time.The following shows:

whereH∈[0,360],S∈[0,1],andV∈[0,1].
3.2 Multiscale Hybrid Convolution
Using a multiscale convolution kernel in the proposed algorithm has two distinct advantages.The most significant benefit of multiscale convolution kernels is that differently sized kernels can extract features from logistics pallet images of various scales,allowing the filter to extract and learn richer characterisation information.Also,the convolutional neural network trains the model by learning the filter’s parameters (weight and offset),that is,it continuously learns the filter’s parameters to find the optimal value closest to the label.This article employs a multiscale convolution kernel to allow a given convolution layer to have multiple filters,thereby diversifying the weight and deviation learning,thus extracting and learning the semantic features of the logistics pallet image fully and effectively.
Multiscale inference methods [30–32] are commonly used in computer vision models for the best results.Fine details are better predicted at larger sizes,larger objects are better predicted at smaller sizes,and the network’s receiving field understands the scene better at smaller sizes.This paper proposes a multiscale hybrid convolution model [33] that is different from the traditional multiscale structure shown in Fig.3.To extract features in the three sizes of 11×11,7×7,and 3×3,we use traditional convolution and hole convolution.The following is the calculation formula:

wherehjis the pixel feature vector’s hidden state information,kis the feature point,j*kis the size of the feature map,andl*mis the size of the hollow convolution’s local receptive field.

Figure 3:Schematic diagram of multiscale hybrid dilated convolution
3.3 Bidirectional Attention Mechanism
The model is divided into three parts and has a novel bidirectional attention mechanism,which is the first section of the model.To effectively detect the local semantic information of each pixel in the pallet image,we map all the characteristics onto a two-dimensional space and apply a bidirectional weight to each feature using bidirectional attention.The second section of the model includes the two types of weight features to broaden the weight coefficient.The third section combines the two types of weight features to produce the greatest value,which is then utilized to complement the weight coefficient result obtained in the second step.The bidirectional attention mechanism is shown schematically in Fig.4.

Figure 4:Schematic diagram of the bidirectional attention mechanism model
Let the feature map extracted from the previous convolutional layer be∈RH×W,whereHandWare the feature map’s height and width,respectively;then,inputinto the horizontal attention module to obtain the attention weight.The steps in the calculation are as follows:

whereWhandbhare the weight parameters of the dense layer,andAtthrepresents the attention coefficient in the horizontal direction.
For the vertical attention mechanism,we transpose the matrix of the feature map to obtain the feature map in the vertical direction.The calculation equation is as follows:

whererepresents the feature map flipped vertically.Similarly,input it to the vertical attention module to obtain the vertical attention weight.The calculation equation of the weight coefficient is as follows:

Therefore,the calculation equation of the output of the bidirectional attention mechanism model is as follows:

whereBArepresents the output of the bidirectional attention mechanism model.
3.4 Feature Fusion
In this section,feature fusion is performed on the output of the multiscale semantic feature and the bidirectional attention mechanism and is then segmented by the sigmoid function.The calculation equation is as follows:
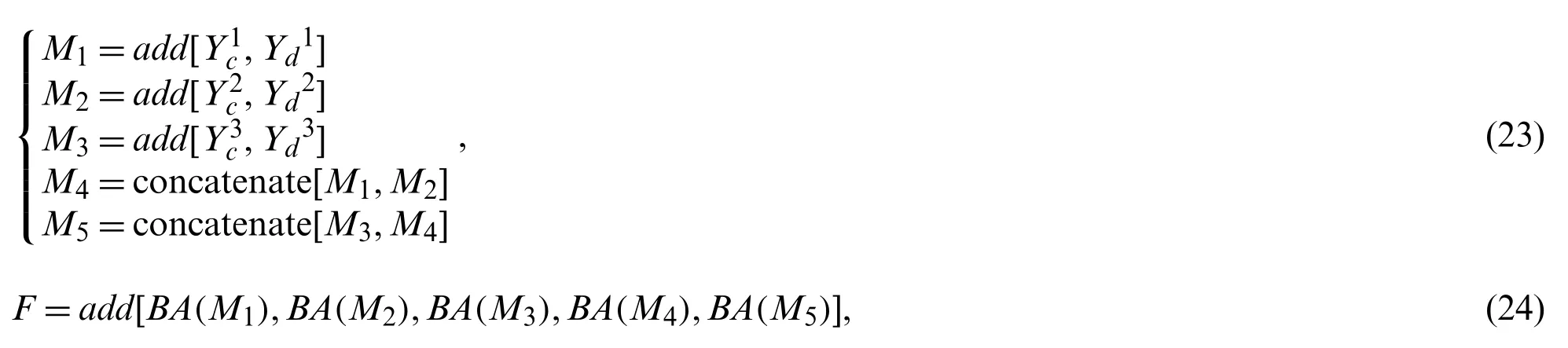
whereM1,M2,...,M5represents the fusion output of the hybrid dilated convolution of each scale,addrepresents the summation operation on the feature tensor,andconcatenaterepresents the concatenation operation on the feature tensor.
The final output of segmentation using the sigmoid function is:

4 Experiments and Results
4.1 Dataset
A pallet is a medium that transforms static goods into dynamic goods—it is a loading platform.Since the focus of this article is the intelligent identification and segmentation of logistics pallets in industrial production environments,we collected images of pallets in complex environments from the Internet.The collected images are of different sizes and pixel sizes.We uniformly cropped the size of the pallet image to 256×256.To obtain the pallet image segmentation dataset,we used ENVI software to annotate each image manually.An example of the pallet image after cropping and annotation is shown in Fig.5.
4.2 Experiment Environments
All of the experiments in this article were conducted on a computer with a single NVIDIA GTX1080 GPU to fairly verify and compare the performance of the proposed algorithms (8 GB).The keras2.1.5 deep learning library was used to construct the model.We used Python 3.6.5 as our programming language,and we processed 1280 samples each time in batches.The setting of each of the above hyperparameters was tested extensively in this study.These parameters are the best in this experiment.Table 1 summarizes the final hyperparameters.Furthermore,we used Adam [34] as the optimizer for the proposed algorithm,which converges quickly.Table 1 lists the most important parameters: The learning rate is 0.01;αindicates that the first-order moment estimation’s exponential decay rate is 0.99;βindicates that the second-order moment estimation’s exponential decay rate is 0.999;Epsilon is set to 1e-8;and Decay indicates that the learning rate decay is 3e-8.

Figure 5:Examples of original and segmented logistics pallet images

Table 1:Setting the hyperparameters
4.3 Evaluation Methods
This paper uses three evaluation indicators—precision (P),recall (R),and F1 score (F1)—to evaluate the segmentation performance of the proposed MFMBA algorithm comprehensively.The following are the calculation formulas for Precision,Recall,and F1 score:


where TP represents a true positive (the number of pixels of the logistics pallet that were correctly detected),FP represents a false positive (the number of pixels of the logistics pallet that were incorrectly detected),and FN represents a false negative (the number of pixels of the logistics pallet that were incorrectly detected).
4.4 Experimental Results of Different Methods
In this section,a comparative experiment is conducted to demonstrate the superiority of the proposed algorithm.Furthermore,all experiments were carried out in the same environment and with the same hyperparameters.We compared AlexNet [18],Res-Net [19],DenseNet [20],Unet [21],and DeepLab-v3 [2] with the proposed MFMBA model.The comparative experimental results of various methods are shown in Tables 2 and 3 and Fig.6.Only 1% and 20% of the training samples were chosen in separate experiments.

Table 2:The result of comparison with five different models under 1% of the training samples

Table 3:The result of comparison with five different models under 20% of the training samples
Due to the wide variety of pallets,shape complexity,strong regularity,and complex environments (e.g.,pallets being occluded in the industrial production environment and changing lighting conditions),the semantic segmentation of the pallet segmentation image can be an arduous task.The training set was made up of either 1% or 20% of the total number of samples.Table 2 shows that the overall residual network outperforms the dense network and AlexNet,as evidenced by the experimental results.Because the residual network preserves many shallow features,and the residual calculation and deep features are better merged to gain additional features,the residual calculation and deep features are better integrated to obtain more features.Fig.6 shows that ResNet has a high level of accuracy on positive samples.

Figure 6:Segmentation results under 1% training sample.(a) Input image;(b) AlexNet;(c)ResNet;(d) DenseNet;(e) Unet;(f) DeepLab-v3;and (g) MFMBA (Ours)
Furthermore,the residual network has better performance for mining features,as evidenced by the precision index.On the same training sample,our proposed MFMBA algorithm outperforms other methods in P (0.5%–8.1% higher than the others),R (0.4%–9.1% higher than the others),and F1 score (compared to the other five groups of models,3.9%–7.5% higher),demonstrating its feasibility.Fig.6 depicts the outcomes of the experiment (using 1% of the samples for training).Table 3 shows that,with the increase in the number of training samples,the performance of our algorithm is significantly improved and outperforms the other five methods.This fully demonstrates the effectiveness of our model.
4.5 Ablation Experiment on the MFMBA Sub-Module
The sub-modules of the proposed algorithm were subjected to ablation experiments and are described in this section.The multi-feature fusion (MFF) module,multiscale network (MSN),and bidirectional attention (BA) mechanism are acronyms for multi-feature fusion module,multiscale network,and bidirectional attention mechanism,respectively.We combined them and ran separate experiments to see which sub-modules have the greatest impact on segmentation performance.Table 4 summarizes the findings of the ablation experiment.
Table 4 and Fig.7 clearly show that any two sub-modules perform better segmentation than a single module.MFF outperforms a single MS and BA,demonstrating the utility of multi-feature extraction.Moreover,the MFF MS combination is superior to the MS and BA combination because the multi-feature extraction and fusion module can extract richer semantic information.Furthermore,the combined model outperforms a single module,demonstrating that the proposed algorithm’s MFF extraction,MSN,and BA mechanism are effective.As a result,MFMBA’s effectiveness is also demonstrated.

Table 4:Ablation experiment results of the sub-module of MFMBA under 1% and 20% training samples

Figure 7:Visualized results of ablation experiments.(a) Precision;and (b) F1 score
4.6 Ablation Experiment of Multi-Feature Fusion
In the previous section’s ablation experiment,we discovered that the MFF module performs exceptionally well in the proposed algorithm.As a result,this section sets up an ablation experiment to investigate the impact of various features on the experimental outcomes.The three extracted features were abbreviated as HSV,T,and G,and ablation experiments were performed on combinations of these three features.Table 5 presents the results of the experiment.
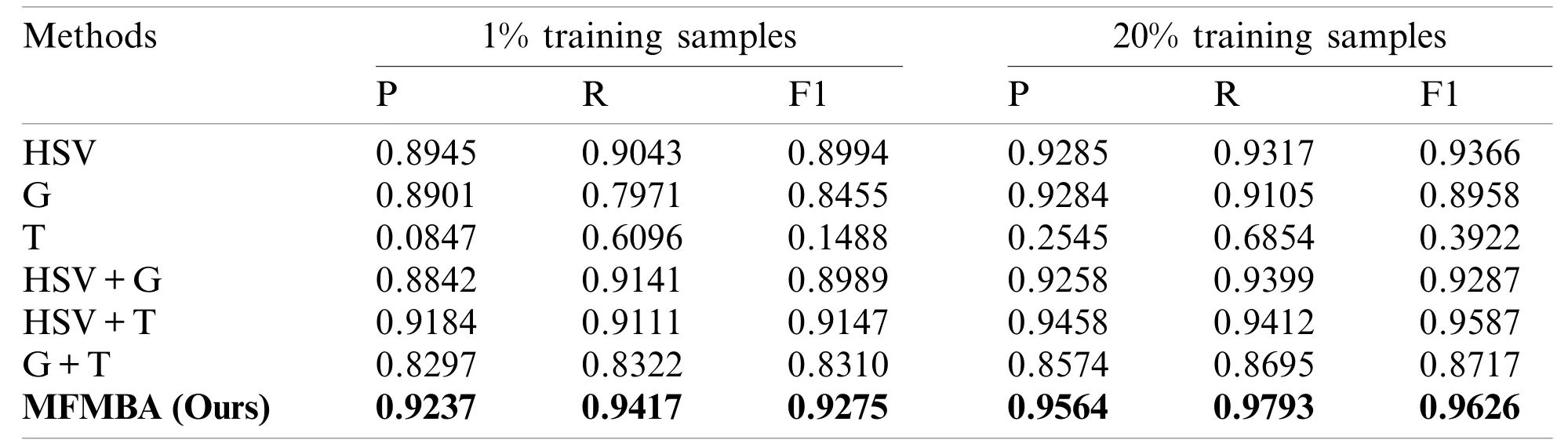
Table 5:Experimental results of ablation studies on multi-feature fusion under 1% and 20%training samples
From Fig.8 and Table 5,we see that the segmentation performance using texture features is the worst,while the performance using HSV features is the best.HSV features contain more semantic information,while logistics pallets’grayscale features do not.Local features can also be described in greater detail with greater accuracy.Furthermore,the fusion of any two groups of features exceeds the utility of a single feature,meaning that integrating several characteristics provides more semantic information than using a single feature.The results suggest that the MFF of the algorithm is effective.

Figure 8:(Continued)
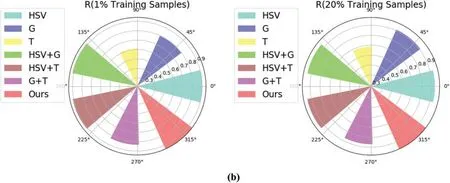
Figure 8:Visualized results of multi-feature fusion ablation experiment.(a) Precision.(b) Recall
5 Conclusions
This paper proposes a novel MFMBA neural network for logistics pallet segmentation.To better predict the foreground category (the pallet) and background category (the cargo) of the pallet image,three types of features (grayscale,texture,and HSV) are extracted and fused.Experimental results demonstrate that all three features improve the segmentation performance of the model,especially the HSV feature.Also,we demonstrated the superiority of the multiscale architecture,which extracts more semantic features than other architectures used to date.In addition,since the traditional attention mechanism only allocates attention from a single direction,we also designed a two-way attention mechanism that can assign cross-attention weights to each feature from two directions (horizontally and vertically).This mechanism improves the segmentation performance of the proposed algorithm,which is also demonstrated by comparison and ablation experiments.
Funding Statement: This work was supported by the Postgraduate Scientific Research Innovation Project of Hunan Province under Grant QL20210212 and the Scientific Innovation Fund for Postgraduates of Central South University of Forestry and Technology under Grant CX202102043.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
杂志排行

Computer Modeling In Engineering&Sciences的其它文章
- Analysis of Multi-AGVs Management System and Key Issues:A Review
- Assessment of the Solid Waste Disposal Method during COVID-19 Period Using the ELECTRE III Method in an Interval-Valued q-Rung Orthopair Fuzzy Approach
- Sentiment Analysis of Roman Urdu on E-Commerce Reviews Using Machine Learning
- Nonlinear Response of Tunnel Portal under Earthquake Waves with Different Vibration Directions
- A Method Based on Knowledge Distillation for Fish School Stress State Recognition in Intensive Aquaculture
- Detecting and Repairing Data-Flow Errors in WFD-net Systems