User Role Discovery and Optimization Method Based on K-means++and Reinforcement Learning in Mobile Applications
2022-07-02YuanbangLiWengangZhouChiXuandYuchunShi
Yuanbang Li,Wengang Zhou,Chi Xu and Yuchun Shi
School of Computer Science and Technology,Zhoukou Normal University,Zhoukou,466001,China
ABSTRACT With the widespread use of mobile phones,users can share their location and activity anytime,anywhere,as a form of check-in data.These data reflect user features.Long-term stability and a set of user-shared features can be abstracted as user roles.This role is closely related to the users’social background,occupation,and living habits.This study makes four main contributions to the literature.First,user feature models from different views for each user are constructed from the analysis of the check-in data.Second,the K-means algorithm is used to discover user roles from user features.Third,a reinforcement learning algorithm is proposed to strengthen the clustering effect of user roles and improve the stability of the clustering result.Finally,experiments are used to verify the validity of the method.The results show that the method can improve the effect of clustering by 1.5~2 times,and improve the stability of the cluster results about 2~3 times of the original.This method is the first time to apply reinforcement learning to the optimization of user roles in mobile applications,which enhances the clustering effect and improves the stability of the automatic method when discovering user roles.
KEYWORDS User role discovery;user role optimization;K-means++;reinforcement learning
1 Introduction
According to the 47th Statistical Report on the Development of China’s Internet by the China Internet Network Information Center [1],as of December 2020,the number of Chinese netizen reached 989 million,of which 986 million were mobile netizen,accounting for 99.7%.With the widespread use of mobile phones,mobile applications have achieved rapid development because users can share their interests and freely send various types of information [2].
Massive amounts of check-in data are generated in the usage of mobile applications by users.These data include a wealth of user knowledge.Analyzing these large amounts of data and vector them as user features are interesting research directions [3].
In mobile applications,users’behaviors may be diverse and change significantly over time.However,eventually,these behaviors will have certain rules,and these are often shared by a group of users.This stable,common behavioral rule can be abstracted into the user roles.Although the definitions of roles are different in different disciplines,the core concept is the same,that is,a role is a set of user groups that share similar behavior patterns.User roles are closely related to the user’s social background,occupation,and living habits [4].
The following are the contributions of this paper.
(1) An algorithm was designed to realize the vectorization of user features from user behavior data.
(2) A method based on the K-means++ algorithm is proposed to discover user roles through the analysis of user features.
(3) A method based on reinforcement learning is proposed to improve the stability of the user-role discovery method.
(4) Experiments were conducted to verify the validity of the method.
The subsequent chapters are arranged as follows: Chapter 2 introduces the related work.Chapter 3 introduces the preliminaries of the method.Chapter 4 introduces the process of the method.Chapter 5 experimentally verifies the effectiveness of the method.Finally,Chapter 6 summarizes the paper.
2 Related Works
Role analysis has become an important analysis method and has been widely used in many applications,such as mobile applications.Yu [5] defined roles from an abstract level: a role is an abstract representation of the behaviors of social actors in a specific professional background or field of work.Zhang et al.[6] defined roles specifically in virtual communities: a role is a behavior model and behavior norm that meets the requirements of the virtual community generated by users under psychological motivation factors,which is different from social roles.They further noted that,a role is not the expectation of people’s behaviors in the real society but the expansion and extension of social roles.
The role discovery methods can be divided into the following categories: expert experiencebased,survey-based,and mathematical analysis-based methods.
· Expert experience-based method
This is a method in which domain experts define user roles in a specific field based on personal experience.For example,Liu-Thompkins et al.[7] divided users in computational advertising into three roles: creator,metavoicer,and propagator,and analyzed the opportunities,challenges,and future research directions of each role.
· Survey-based method
This method obtains user roles through a survey.According to the different objects of the survey,this method can be divided into literature-based survey methods and user-based survey methods.Literature-based methods such as systematic literature review was used by Hacker et al.[8] to investigate user roles in enterprise social networks,and 10 user roles,including initiator,debater,sharer,coordinator,seeker,helper,expert,net-worker,linker,and observer were finally obtained.The user-based survey method,such as the GLAM digital participation survey activity launched at the University of Oxford in the United Kingdom,through user surveys on users of gardens,libraries,and museums,is divided into five roles: content producers,compliant learners,and cultural consumers,topic lovers,and education practitioners [9].
· Mathematical analysis-based method
This method uses various mathematical methods or analysis techniques,such as clustering algorithms,statistical analysis,and log analysis,to discover user roles through data analysis and summary.For example,Hacker et al.[10] used the K-means clustering algorithm to analyze corporate social network data.Through the analysis of the clustering results,users are divided into nine roles: power users,conversation starters,well-connected helpers,focused information sharers,sporadic users,task coordinators,offline experts,chat users,and team members.Guo et al.[11] used social network analysis and clustering analysis techniques to analyze user data in professional virtual communities and divided users into six roles: planning instructors,active designers,multifaceted persons,communicators,passive designers,and observers.
Expert’s personal domain knowledge and social background affect the results of expert experience-based methods,and the results summarized by different experts may be quite different.Additionally,when the field is complex and involves many users and frequent user activities,experts find it difficult to sum up user roles.
The survey-based method does not require complicated equipment and experiments and is relatively easy to implement.It is a feasible method for collecting first-hand data to summarize user roles.However,this method is labor-intensive and difficult to reuse;if the research field or the user changes,the survey process should be repeated.The researcher’s skills and experience also affect the results.In mobile applications,the openness and diversity of users also increase the difficulty of using survey methods.
In mobile applications,users are transparent to managers,and user behavior data are rich.These characteristics are suitable for mathematical analysis-based methods.Therefore,many studies have been conducted using this method to discover user roles [10–13].However,current research focuses only on the discovery of roles without considering the stability of roles and corresponding user groups.Experiments show that for the same data,running the K-means algorithm multiple times has greater randomness in the division of the user’s role.Therefore,based on using the K-means algorithm to discover the user’s role,this study uses the reinforcement learning method to learn the user role division,which improves the stability of the division.
3 Preliminaries
3.1 Definitions
The definitions used in the method are as follows:
Definition 1:User context set(UCS)
The USC is a set of attributes that can be used to describe the user and context for user activities.

Definition 2:View set(VS)
VS is a set of different perspectives that system analysts and managers use to observe user activity patterns according to their interests.

Definition 3:User context view preference set(UFS)
The UCVFS is the set of user preferences from a contextual perspective determined from different perspectives under different scenarios.

where:

3.2 Basis of Reinforcement Learning
Reinforcement learning theory is derived from the psychology and neuroscience of animal behavior and provides an explanation of how agents optimize their control of the environment [14].In an unknown and complex environment,the agent behavior and resulting consequences are usually unpredictable.The process of reinforcement learning does not directly tell the agent which behavior to perform but constantly tries to make the agent perform various behaviors in the environment.Further,it calculates the instant reward resulting from a single behavior on the environment by defining a reward function.The instant reward is used to identify the agent whose behavior is the best in the current environment.The larger the instant reward,the better is the behavior.However,in a complex environment,the optimal solution for each behavior may not reach the overall optimal solution.Therefore,the value function must be defined.The value function is used to measure the long-term value of an agent’s behavior.
The components of reinforcement learning used in this study include the following:
State set S: The state set refers to the set of all possible states of the agent from the beginning of learning to completion.It is marked as S and contains several states s,that is,s ∈S.
Behavior set A: The behavior set refers to the set of all behaviors in the learning process of the agent,marked as A,and contains several behaviors a,that is,a ∈A.
State behaviors set As: State behavior set refers to the set of possible behaviors of the agent in a specific states,marked as Asand contains several possible behaviors as,as∈As.Instant reward Rewardas: Instant reward refers to the reward generated when the agent adopts behavior a in a specific state s,which is marked as Rewardas.
Long-term value V: Long-term value refers to the sum of the value generated by the agent after adopting a series of behaviors,marked as V.
4 Method Proposed to Realize User Role Discovery and Optimization
4.1 UFS Construction
Quantifying user characteristics by analyzing user activity data is the basis of using automatic methods to analyze user features and discover user roles.In this study,we first implemented vectorization from user activity data to user features.According to Definition 3,the UFS is a set of cardinalities |VS| * |UCS|,where each set element is a matrix of |UCi| times |Vj| dimensions.The UFS algorithm is presented in Algorithm 1.
The input of the algorithm includes DS,UCS,and VS,and the output is the UFS.First,the check-in data of user u are initialized from DS (Line 1).For each context UCiin the UCS;each perspective Vjin VS is iterated.For this process,UFijis first initialized to a zero matrix;the row and column are the cardinality of UCiand Vj(Row 4).Iteration occurs over the data record d of user U,initializing the row and column subscripts of the matrix corresponding to each record to 0 (Rows 5–7).The corresponding user context value uc is obtained,and the value v is viewed.The subscript uc,that is,uc_serial_num,and the subscript v,that is,v_serial_num (Lines 8–17),are calculated.The value of the matrix corresponding to the position of the row and column subscripts was added (Line 18).Finally,UFijwas added to the UFS (Line 20).

Algorithm 1: UFS construction algorithm Input: DS (Data Set),UCS,VS Output: UFS 1: Initialize data of user u DS_u from DS 2: for UCi in UCS 3: for Vj in VS 4: Initialize UFij=O(|UCi|*|Vj|)5: for d in DS_u 6: uc_serial_num=0 7: vs_serial_num=0 8: for uc in UCi 9: for v in Vj 10: if (d.UCi_value==uc &&d.Vj_value==v)11: uc_serial_num=GetSerial_Number(uc)12: vs._serial_num=GetSerial_Number(v)13: break 14: endif 15: endfor 16: break 17: endfor 18: UCVFij[uc_serial_num][vs._serial_num] ++19: endfor 20: UFS.add(UFij)21: end for 22: end for 23: return UCVFS
4.2 Overview of the Method
The concept behind this method is that the UFS established in the previous section is the learning object.First,the K-means++ algorithm is used to cluster the user features and discover user roles.On this basis,the idea of reinforcement learning is used to define the appropriate immediate reward function and long-term value function through the learning of the subordination between users and roles.Through continuous iterative optimization,an ideal solution set was obtained.An overview of this method is shown in Fig.1.

Figure 1:Overview of the method
4.3 K-Means++-Based User Role Discovery
A variety of clustering methods were investigated to discover user role effectively,including: 1)DBSCAN (Density-Based Spatial Clustering Application with Noise) method;2) AHC (Agglomerative Hierarchical Clustering) method;3) K-Means++ method.And user’s time-root category feature in data_1,which is detail described in Section 5.2 is used to validate the effectiveness of these method.
· DBSCAN method
DBSCAN method is a density-based non-parametric clustering algorithm [15]: given a set of points in a space,the closely arranged points,that is,the neighboring points,are clustered together.
Two parameters are needed in the method,one is the radius of the search named “eps”,and the other is the minimum number of points in the range named “min_samples”.Outliers may appear during the clustering process because they are too far away from their neighbor points and do not belong to any category.Therefore,it is necessary to analyze the parameter combination(eps,min_samples) to ensure the rationality of the number of categories and the effective data ratio.The specific analysis of the case data is shown in Figs.2 and 3.

Figure 2:Number of categories of DBSCAN method
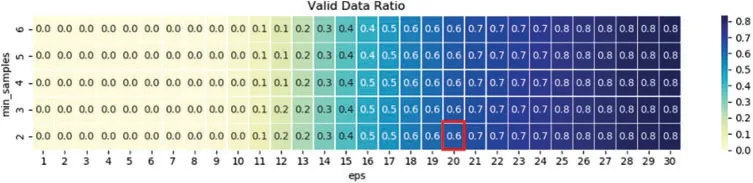
Figure 3:Effective data ratio of DBSCAN method
As shown in Fig.2,when the radius is between 9 and 26,the classification number is greater than 2.When the value of parameter combination (eps,min_samples) is (12,2),the number of clusters reaches the maximum,which is 11 categories,however,as shown in Fig.3,under this parameter,the effective data ratio is only 0.2.Through a comprehensive analysis of the combination of the two parameters,we take (20,2) as the final combination parameter,under this parameter,the number of clusters is 4,and the effective data ratio is 0.6,as shown in the small red box in the figures.
· AHC method
Hierarchical clustering obtains a cluster tree by condensing the data at different levels,which consist of agglomerative hierarchical clustering and split hierarchical clustering.In the agglomerative hierarchical clustering method [16],each record is a cluster at the beginning.Then the proximity between the clusters is calculated and the initial clusters are merged until it finally reaches the set number of categories.In this study,the AHC method was used to construct a hierarchical clustering tree of the user’s time-root category features in data_1,as shown in Fig.4.It can be found from the figure that the data is reasonably divided when the number of clusters is 6,as shown by the yellow horizontal line in the figure.
· K-means++ method
K-means algorithm divides the data into K clusters and minimize the distance between each sample and the center of its class.It has been widely used in practice because of its easy implementation and fast convergence speed [17].K-means algorithm is sensitive to the selection of the initial clustering center.Improper selection of the initial clustering center affects the clustering effect.The k-means++ algorithm optimized the k-means algorithm,its basic idea is to make the distance between the initial center points as far as possible,that is,the center points are in the“mutually exclusive” state [18].The value of K can be determined by calculating the root mean square error (RMSE) within the cluster.If the error decreases before K reaches a certain value,and then slows down,forming an obvious “elbow,” then the K value is reasonable.Taking user’s time-root category features in data_1 as an example,the specific changes of mean validation score according to K are shown in Fig.5.The figure shows that when the number of clusters is 9,there is an obvious elbow,as marked in red in the picture.

Figure 4:Agglomerative hierarchical clustering tree

Figure 5:Change trend of mean validation score according to K
Applicability of the three clustering methods was analyzed from five aspects: data coverage,number of categories,number of users for each category,standard deviation of number of users,and minimum number of users for each category.The result is shown in Table 1.

Table 1:Applicability analysis table for clustering method
In data coverage aspect,the effective data used by the DBSCAN method accounting for 64.7%,corresponding to 100% of AHC and K-means++ method.In the number of categories aspect,the number of the K-means++ is 9,corresponding to 4 and 6 of AHC and K-means++method,and a further analysis of the classification results found that the categories obtained by DBSCAN and HCA method can be found in the K-means++ algorithm with similar feature categories.The number of users for each category is listed in Column 4,and the standard deviation of number of users is calculated in Column 5,in which K-means++ algorithm is the smallest.In the minimum number of users for each category aspect,the K-means++ algorithm is the largest,as shown in Column 6 of the table.Based on the analysis above,K-means++algorithm was finally selected as the clustering algorithm in this research.
4.4 Reinforcement Learning Based User Role Optimization
The K-means++ algorithm can discover user roles and divide the roles to which the user belongs,but because the initial K centers of the algorithm are random,and the order of input will also impact the clustering results,the clustering results have randomness.Therefore,in this method,the idea of reinforcement learning is used to define a reasonable real-time reward and long-term value calculation function to optimize the clustering results through many rounds of continuous attempts and learning;finally,a satisfactory solution is obtained.
To describe the user role optimization method based on reinforcement learning,the concept of silhouette coefficient is introduced,which is a classic index used to measure the quality of clustering [19].
· Silhouette Coefficient
The centroid of clustering is the core concept used to calculate the silhouette coefficient.Let R be a cluster;then,its centroid is the mean vector of all vectors of the cluster,and the calculation is shown in Eq.(5).

For each user feature UFi,the calculation process for the silhouette coefficient is as follows:
(1) Calculate the maximum distance between the user feature UFiand other user features in the role,marked as TRMax (UFi).
(2) Calculate the minimum distance from the user feature UFito the centroid of other characters,marked as ORMin (UFi).
(3) Calculate the silhouette coefficient according to TRMax (UFi) and ORMin (UFi),as shown in Eq.(6).
The value range of the silhouette coefficient Se(UFi) was between -1 and 1.Se(UFi) can be used to measure the clustering effect of UFifor a single user feature.The larger the value,the better the clustering quality.To measure the overall clustering effect of all user features,the average contour coefficient of the user features is used.The larger the average contour coefficient,the better the overall clustering quality.Suppose that the user set u={U1,U2,Ui,...,Um},where m=|u| and the user feature corresponding to user Uiis UFi.The calculation of the average silhouette coefficient is shown in formula (7).

After introducing the concept of the silhouette coefficient,a user role optimization method based on reinforcement learning is proposed,which consist of the following 9 steps.
1) Data preparation
The input data used in state initialization include user set U,feature set UF,role set ROLE,and role user list set ROLE_USERLIST.The specific definitions of the data are as follows:
User set U={U1,...,Ui,...,Um},indicating all users,where m=|U|.
Feature set UF={UF1,...,UFi,...,UFm},where the user feature corresponding to user Uiis UFi.
The role set role={R1,...,Ri,...,Rn},which represents the role abstracted from the feature,where n=| role |.The construction process of the role set is shown in Section 4.3.
The role user list set ROLE_USERLIST={ROLE_USERLIST1,...,ROLE_USERLISTi,...,ROLE_ USERLISTn},represents the user list corresponding to each role,and U=ROLE_USERLISTiis established.
2) State initialization
The purpose of reinforcement learning is to obtain a satisfactory solution for the user’s role.Therefore,the system state is described as the subordinate matrix of the user and its role.If the initial state is S0,then the row number of S0is |U|,and the column number is |ROLE|.The S0initialization algorithm is presented in Algorithm 2.

Algorithm 2: State initialization algorithm Input: U,ROLE_USERLIST Output: S0 1: Initialize S0=O(|U|*|ROLE|)2: for Ui in U 3: for ROLE_USERLISTj in ROLE_USERLIST 4: if (Ui ∈ROLE_USERLISTj)5: S0[i-1][j-1]=α 6: endif 7: endfor 8: endfor 9: return S0
3) Action attempts
Take user Uifrom user set U and try to assign him to each role Rjin the ROLE.
4) Instant reward calculation
Using formula (6) to calculate the instant reward when Uiis assigned to each role Rj,the candidate instant reward set REWARD={Se (UFi)1,Se (UFi)2,Se(UFi)j,...,Se (UFi)n},where n=|ROLE|.
5) Greedy optimal reward action execution
Using the idea of the greedy algorithm,we take the current local optimal solution,that is,the role corresponding to the maximum value in the REWARD set,marked as Rj.The implementation process includes the following steps:
a.Assign Uito role Rj,and update centroid Rjusing formula (5);
b.Update the user set U,execute U=U-Ui;
c.Update the state Snto Sn+1,using formula (8)
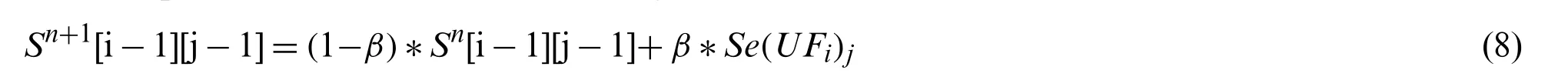
In formula (8),βis a constant,and its value is between [0,1],which is used to adjust the influence of the immediate reward obtained from this greedy strategy on the overall state.The greater the value ofβ,the greater is the influence of the immediate reward on the state.
6) Repeat Steps(3)–(5)until the end of one round of execution,that is,all users are assigned
7) Long-term value calculation
In this study,we believe that after the process of class reinforcement learning,the long-term value needs to achieve two goals.One is good role partition,and the specific indicators are measured by the average silhouette coefficient,which is calculated using formula (7).The other is reduced randomness of role partition,so that the partition results tend to be stable;that is,after a new round of allocation,users should still belong to the same role.It is assumed that the user list set of the role before allocation is ROLE_USERLIST={ROLE_USER1,...,ROLE_USERi,...,ROLE_USERn},after a new round of partition,the role user list set is ROLE_USERLIST’={ROLE_USER’1,...,ROLE_USER’i,...,ROLE_USER’n}.The calculation of randomness is shown in formulas (9) and (10).

8) Long-term value judgment
To determine the long-term value,if the two targets average silhouette coefficients Se(UF)>γand Rand (ROLE)<δcannot be satisfied,both initialize the user set to all users and repeat Steps (3)–(8);if the two targets are satisfied,turn to Step (9).The constantγrepresents the lowest value of the acceptable average silhouette coefficient,andδrepresents the maximum value of the randomness of the acceptable role partition.
9) Ends the algorithm and return the results
5 Experiments
5.1 Research Questions
According to the research motivation,the research questions (RQ) are as follows:
RQ1: What is the effect of automatically discovering user roles from user features using the K-means++ algorithm?
RQ2: What is the effect of using reinforcement learning to optimize user role discovery?
RQ3: Compared with existing user role discovery methods,what are the advantages of the method in this study?
5.2 Date Sets of Experiment
The data set is constructed based on the Foursquare user check-in data in existing research [20,21].The data set includes three independent sets,which are labeled as data_1,data_2,and data_3.data_1 uses the check-in data of New York City in the study [20].To verify that the method is not data sensitive,data_2 and data_3 are randomly generated from [21].The statistical information of the data set is shown in Table 2,and an example of the data in the data set is shown in Table 3.The dataset can be downloaded directly at the following URL:https://pan.baidu.com/s/1zibTOM9dKaSkLoap3bh97Q,and the password is 1234.

Table 2:Data statistics table of the datasets

Table 3:Data sample table of the datasets
To obtain an intuitive understanding of user characteristics from an abstract level,the root category data item is added to the data set.The corresponding relation between the POI category and POI root category is established based on the hierarchical category relationship tree on the Foursquare official website.On the website,nine types of root categories exist,which are arts and entertainment,college and university,food,outdoors and recreation,professional and other places,residence,shop and service,travel and transport,and event.
5.3 Results and Analysis
Through data analysis,the user context set UCS={UCt,UCd},where t represents time and d represents distance.In this study,the time was segmented in hours,so |UCt|=24.The distance from the user’s home to the POI is divided into 4 levels [22]: within 1 km,between 1 and 10 km,between 10 and 30 km,and more than 30 km.Therefore,|UCd|=4.
The view set VS={Vr},where r represents the root category of POI.Nine root categories of POI exist in the dataset,so |Vr|=9.
Based on the analysis above,UFS={UFtime-rootcategory,UFdistance-rootcategory}.UF time-root category is a 24 * 9 matrix and UF distance-root category is a 4 * 9 matrix.The construction of these matrices is shown in Algorithm 1.
According to the research questions,the results and analysis are as follows:
RQ1: What is the effect of automatically discovering user roles from user features using the K-means++ algorithm?
The K-means++ algorithm is used to cluster user features.The results are presented in Table 4.

Table 4:User roles generated from UFS
It can be found from the table that clustering different user features can describe the life habits of a user set from different perspectives,thereby providing a basis for analyzing users’social attributes.Taking the UFtime-rootcategoryas an example,a schematic of the user roles is shown in Figs.6–14.
As shown in Fig.6,users in this role sign in very frequently around noon,and sign in a lot in outdoor activities,shops and services,travel,and transportation.This shows that users like to be active around noon and like to use transportation and engage in daily activities such as outdoor activities or shopping.
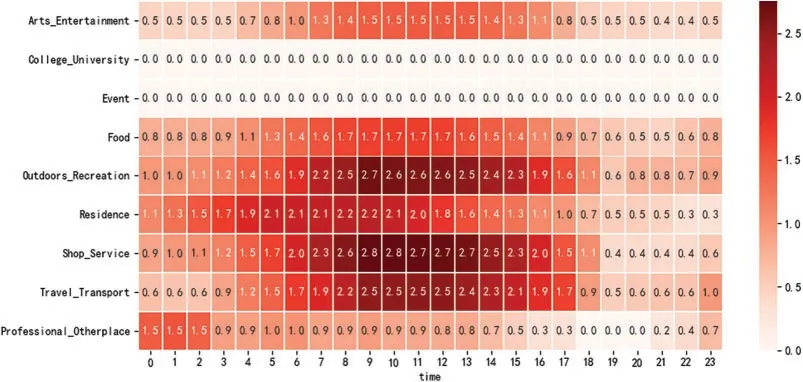
Figure 6:Noon outdoor activists
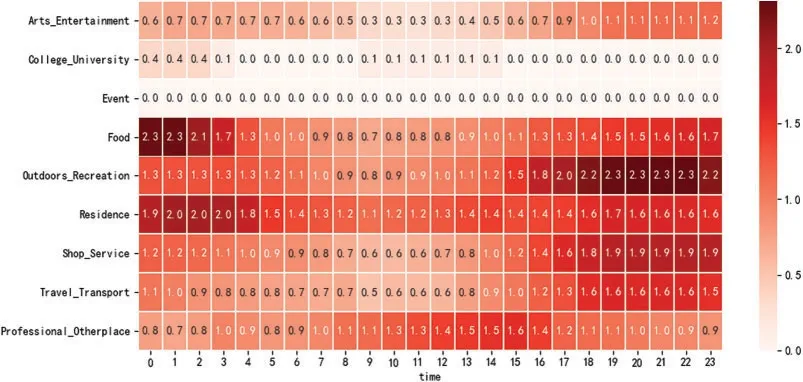
Figure 7:Urban practitioners
As shown in Fig.7 from approximately 08:00 a.m.to approximately 16:00 p.m.,users in this role check in more occupations in the root category of professional and other places,indicating that the user should be at work;from the end of work at around 17:00 p.m.to 23:00 p.m.,users are more active,and activities are mainly concentrated in outdoor and recreation,shops and services,and travel and transport root categories.From 00:00 a.m.to 02:00 a.m.,users’outdoor and shopping activities are significantly reduced,whereas there is more food and housing,indicating that users have been busy for a day and ate some supper before rest.

Figure 8:Night food lover

Figure 9:Early morning food lover
Fig.8 shows that night food lovers are particularly fond of fine food,and check in activities are mainly concentrated between 17:00 p.m.and 23:00 p.m.Starting from 00:00 a.m.,checking in drops sharply,indicating that users in this role do not like to stay up late.
As shown in Fig.9,early morning food lovers have the most activity in the food root category,and their check in activity began to increase significantly after 00:00 a.m.,indicating that users are interested in urban nightlife.
As shown in Fig.10,lunch-time food lovers have the highest activity in the food root category,and the time is concentrated around noon.It was also found that the users’activity frequency in the morning was significantly higher than that in the afternoon in the professional and other root categories,suggesting that users would often be busy working in the morning and then enjoy a meal break at noon.
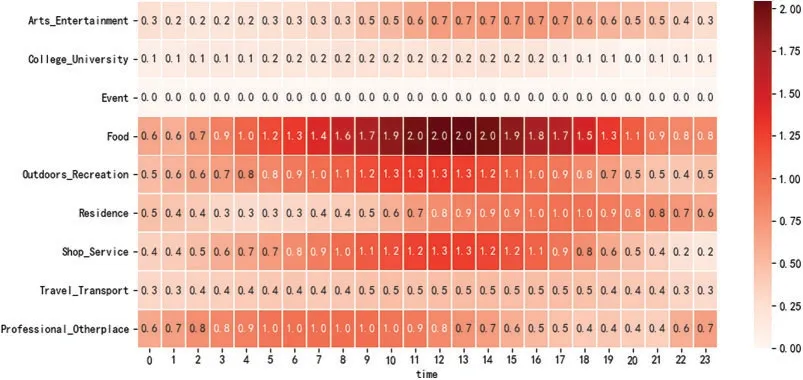
Figure 10:Lunch-time food lover
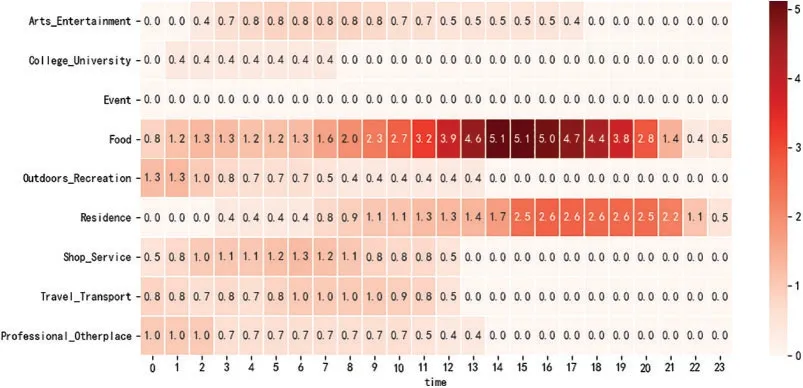
Figure 11:Afternoon at home food lover
As shown in Fig.11,the users in this role had the highest activity in the food root category,with the time being concentrated in the afternoon,and they had significantly more activity in the residential category in the afternoon,indicating that users in this role like stay at home and enjoy fine food in the afternoon.
As shown in Fig.12,check-in activities of users in this role are mainly concentrated between 17:00 and 22:00 p.m.,and the frequency of activity drops significantly from 23:00 p.m.The main categories of activities are concentrated in shops and services,outdoor and recreation,and travel and transportation,indicating that users would always use public transportation and enjoy shopping and outdoor activities.
As shown in Fig.13 check in activities of users in this role are concentrated after 00:00 a.m.The root categories of these check in activities include shops and services,outdoor and recreation,and travel and transportation,indicating that users are avid nightlife enthusiasts and like many kinds of outdoor activities such as shopping,outdoor activities,and recreation.

Figure 12:Evening outdoor activists

Figure 13:Early morning revelers
Fig.14 shows that users in this role are frequently active from 12:00 p.m.to 18:00 p.m.,and the activities are mainly in shop and services,outdoor and recreation,and travel and transportation,indicates that users often take public transportation and like shopping and outdoor activities.
RQ2: What is the effect of using reinforcement learning to optimize user role discovery?
· Parameter setting
The values ofγandδare first set according to a set of experiments,whereγis the threshold value of the silhouette coefficient,andδis the threshold of randomness.Further,the two parameters are defined in the process of long-term value judgment.The experimental result of theγ’value is shown in Table 5,and that ofδ’value is shown in Table 6.The data in the table are the running time of the experiment,and the unit is minutes.“/” indicates that the algorithm runs for more than 24 h without convergence.

Table 5:Threshold value table of γ

Table 6:Threshold value table of δ

Figure 14:Afternoon outdoor enthusiasts
The experimental results in Table 5 show that when the value ofγis 0.9,or 0.8,the algorithm cannot converge in the specified time.When the value ofγis 0.7,the algorithm converges in the effective time.Therefore,the final value of parameterγin the experiment is 0.7.
U in Table 6 represents the number of users in the data set.The experimental results show that when the value ofδis |U|/100,that is,the randomness of the cluster cannot be greater than 1%,or the value ofδis |U|/50,the algorithm cannot converge within the specified time.When the value ofδis |U|/20,the algorithm converges;therefore,the parameterδis |U|/20.
· Experiment result
To verify the effectiveness of the method,the K-means++ algorithm is run N times for each user feature,and the average silhouette coefficient of each cluster result,as well as the randomness between each two cluster results are calculated using formulas (7),(9),and (10).The reinforcement process for each cluster result was then conducted.After the reinforcement process,the average silhouette coefficient of each cluster result and the randomness between each two cluster results were calculated and compared with those before reinforcement.In this experiment,the value of N was set to three,and the specific experimental results are shown in Tables 7 and 8.

Table 7:Comparison table of reinforcement effect of average silhouette coefficient
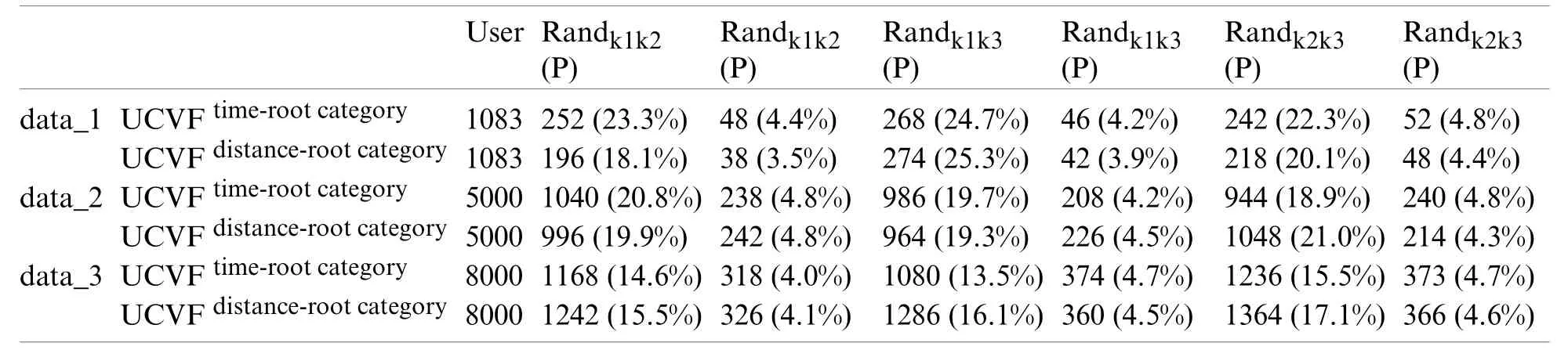
Table 8:Comparison table of reinforcement effect of stability
In Table 7,SC_ K1,SC_ K2,and SC_ K3are the average silhouette coefficients for each run of the K-means++ algorithm.SC_ KE1,SC_ KE2,and SC_ KE3are the average silhouette coefficients after the enhancement of each clustering result.The results of the experiment show that the average silhouette coefficient has been improved after using the reinforcement process of the clustering results,which means that the reinforcement process is effective.
In Table 8,Randk1k2,Randk1k3,and Randk2k3refer to the randomness between the two cluster results.SC_ KE1,SC_ KE2,and SC_ KE3are the randomness between the two cluster results after the reinforcement process.The stability used in this paper refers to the stability of the user list belongs to each role,that is,changes of the user list for each role when running automatic algorithm multiple times,the smaller the change value,the stronger the stability is.We adopt the criterion proposed by Cohen [23] to validate the stability of the user list.Cohen using statistical method to analyze user behavior,and drew a conclusion that “when the difference value is less than one-tenth of the average value,the experimental result is stable”.The experimental results in Table 8 show that after the reinforcement learning process,the change value between each of the two cluster results was reduced to less than 10 percent.
In summary,the experimental results show that after the reinforcement learning process,not only was the average silhouette coefficient of clustering improved but the stability between each two clustering results was also improved.Therefore,the reinforcement learning process is effective for the optimization of the user role discovery.
RQ3: Compared with existing user role discovery methods,what are the advantages of the method in this study?
· Baselines
Role discovery methods mainly include the following categories: expert experience-based,survey-based,and mathematical analysis-based methods.The studies shown in Table 8 were chosen as baselines after a review of the most recent research in each method category.
· Comparison dimension
Automation [24] and re-usability [25] of methods play an important role in improving the efficiency of software development.Whether the result is stable or influenced by personal experience have an important impact on the re-usability of the method.Therefore,four comparison dimension is defined in this study to validate the effective of the method,which are automation,personal experience influence,re-usability,and result stability.
· Result analysis
The method proposed in this study is compared with the baseline methods.The comparison results are presented in Table 9.

Table 9:Comparison results table of the methods
As shown in the table,the expert experience-based method is a no automated process of manual judgment,which is strongly influenced by the personal experience of experts.With the complexity of the scene,the difficulty of manual judgment will be greatly increased,the method is difficult to reuse,and the result is unstable [7].Therefore,this method has not been widely used in role discovery.
Survey-based methods can discover the role of users through a survey of the literature [8] or users [9].Although the results obtained by this method are stable,the method is not automatic.It requires a large amount of human resources to investigate the literature and users.Moreover,when the application scenarios or user groups change,the method is difficult to reuse directly,and the research activities need to be repeated.
Mathematical analysis is a general term that refers to methods for discovering user roles using clustering analysis,statistical analysis,social network analysis,and other mathematical algorithms.Because it is difficult to communicate with users directly in mobile applications,and user activity data are rich,this type of method has been widely used [10–13].This type of method can realize automation and easy re-usability,and the running results are not affected by personal experience.However,the current research does not consider the stability of the classification results.From the experiments in this study,which run the K-means++ algorithm numerous times,the user set in the same role is quite different,which can reach even more than 20% of the total number of users,as shown in Table 8.
The method proposed in this paper is easily automated and reusable,and the running results are not affected by personal experience.The method uses reinforcement learning to improve the stability of the cluster results.
6 Conclusions
The discovery of user roles from user behavior data in mobile applications is necessary for an in-depth and comprehensive understanding of users.A user role discovery and optimization method based on K-means++ and reinforcement learning were proposed in this paper.First,an algorithm was proposed to vector user features from user behavior data.Second,a method based on the K-means++ algorithm was used to discover user roles through the clustering of user features.On this basis,a method based on reinforcement learning was proposed to optimize the clustering results to improve the stability of the results.A set of experiments were conducted.The results show that the method can improve the effect of clustering by 1.5~2 times,and the stability of the cluster results are improved about 3 times of the original,which indicates the effectiveness of the method.
Funding Statement: This work is supported by the National Natural Science Foundation of China under Grant No.U1504602.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
杂志排行

Computer Modeling In Engineering&Sciences的其它文章
- Analysis of Multi-AGVs Management System and Key Issues:A Review
- Assessment of the Solid Waste Disposal Method during COVID-19 Period Using the ELECTRE III Method in an Interval-Valued q-Rung Orthopair Fuzzy Approach
- Sentiment Analysis of Roman Urdu on E-Commerce Reviews Using Machine Learning
- Nonlinear Response of Tunnel Portal under Earthquake Waves with Different Vibration Directions
- A Method Based on Knowledge Distillation for Fish School Stress State Recognition in Intensive Aquaculture
- Detecting and Repairing Data-Flow Errors in WFD-net Systems