基于高斯噪声与ST-GCN的人体骨架动作识别
2022-07-01张芷蒙彭璟江小平石鸿凌
张芷蒙,彭璟,江小平*,石鸿凌
(1 中南民族大学 电子信息工程学院 & 智能无线通信湖北省重点实验室,武汉 430074;2 湖北省科技信息研究院,武汉 430074)
21 世纪以来,人体动作识别(Human action recognition,HAR)已经成为计算机视觉中一个高度活跃的研究领域.基于不同的输入模态,动作识别的方法主要可分为基于RGB 的动作识别[1-3]和基于骨架的动作识别[4-7].基于RGB 的动作识别是一个较为复杂的问题,因为彩色视频的背景变化多样,光照强度和视角变化也会影响最终的动作识别精度.与传统的基于RGB 视频数据的识别方法相比,基于骨架的动作识别方法既能在动态变化的环境或背景下提供更为紧凑和准确的信息,又能减少存储成本和计算代价,因此越来越多的研究人员开始尝试利用骨架模型来进行动作识别.
骨架蕴含着丰富的身体结构和姿态信息,所以利用人体骨架序列可以编码出较为准确的人体关节运动轨迹.基于骨架的动作识别有多种实现方法,这些方法主要分为传统的基于人工设计特征的方法和目前流行的基于深度学习的方法.早期的骨架动作识别模型往往通过一些人工设计的特征来模拟人体动作[8-9],但这些方法泛化性不佳,不能充分体现人体运动模式的复杂程度,因此逐渐被基于深度学习的动作识别方法所取代.
目前基于深度学习的特征提取主要有三种方法:基于卷积神经网络(Convolutional Neural Network,CNN)的方法[10-13]、基 于 循 环 神 经 网 络(Recurrent Neural Network,RNN)的方法[5-7,14-15]和近期广泛应用的基于图卷积神经网络(Graph Convolutional Neural Network,GCNs)的方法[4,16-19].基于 CNN 模型的方法的思想是利用人工设定的规则将骨架数据转换为伪图像,然后输入网络进行动作识别.基于RNN模型的方法的思想是利用人工设计的遍历规则将骨架数据转换为关节序列后输入网络进行动作识别.基于GCN 的方法是将骨架表示为以关节为点,以骨骼为边的图数据,然后将图数据输入网络进行动作识别.骨架是一种天然的图结构:骨架的关节点和骨骼可被定义为图的顶点和边,然而CNN 模型和RNN模型都不能很良好的利用这种空间结构信息,因此近年来许多研究人员尝试将GCN 引入基于骨架的动作识别,这种将人体骨架建模为时空图的图卷积神经网络的做法取得了显著的性能.这些方法中,YAN 等人提出的ST-GCN[4](SpatialTemporal GraphConvolutionalNetworks,ST-GCN)首次将图卷积操作引入时空图,通过时空图卷积同时捕捉时间和空间维度的信息并进行人体动作识别.ST-GCN 充分利用人体骨架的空间信息,提出将人体拓扑结构构造成邻接矩阵Ak,并以此来描述人体骨架的空间结构.这种人工预定义的邻接矩阵代表了一定的先验知识,但对于样本特征多样化的动作识别任务来说,固定的邻接矩阵难以捕捉到非相邻关节点之间的相关性,所以并不是最优的选择,例如,“梳头”这个动作中“手”和“头”的相关性很大,但ST-GCN 却很难关注到这些信息,因为邻接矩阵所描述的骨架空间图中“手”并没有与“头”直接相连的边.
针对以上问题,SHI等人在ST-GCN 的基础上提出了一个双流自适应图卷积网络[17](Two-Stream Adaptive Graph Convolutional Networks,2s-AGCN),2s-AGCN 的邻接矩阵由3 部分组成,分别是原ST-GCN 中的邻接矩阵Ak、全训练的邻接矩阵Bk和由输入数据驱动的邻接矩阵Ck.由这3个矩阵相加组成的自适应邻接矩阵针对不同骨架数据端到端自适应的学习人体骨架图的拓扑结构,进而能更准确的进行动作识别,但2s-AGCN 这种数据驱动的方法增加了大量1×1 卷积操作,这将导致计算量的翻倍增长,因此不利于大规模数据集下的动作识别任务.此外,文献[18]提出一种新型的语义引导图卷积网络(Semantics-Guided Graph Convolutional Network,Sem-GCN),该网络堆叠了语义图卷积和时间卷积以学习语义特征和时间特征并进行动作识别.文献[19]提出了一种基于姿态的图卷积神经网络(pose-based graph convolutional networks,PGCN),该网络利用原视频数据叠加骨架数据共同对人体姿态特征的时空相关性进行建模,为人体动作识别提供了一种有效的方法,但在有限的算力下,大量的视频数据会增大内存压力且增加训练时长,计算效率略低于仅基于骨架的动作识别.
神经网络在无噪声或白噪声环境下能进行有效的学习,使神经网络能较好地跟踪系统输出[20],且在神经网络模型的训练过程中加入噪声具有正则化效果,这种做法已被证明对损失函数具有与添加惩罚项类似的效果[21].受之启发,本文将噪声引入原ST-GCN,提出一种基于高斯噪声的扰动机制,具体来说是在人工预定义的骨架图邻接矩阵上添加高斯噪声(其系数被设置为可学习的参数),利用该高斯噪声来扰动ST-GCN 中固定的邻接矩阵,同时优化人体骨架的空间结构,从而使得ST-GCN 同时从各个身体部位中挖掘丰富的特征而不是仅仅关注一些关节相邻的区域,这种基于高斯噪声的扰动机制可以捕捉到非相邻关节点之间的相关性,在节约计算量的前提下优化了ST-GCN的邻接矩阵.
本文主要工作可以概括如下:首先,将骨架数据集输入图卷积神经网络,然后在ST-GCN 的图卷积层中的原始邻接矩阵Ak上加入高斯噪声,该噪声可表示为λ·φ 的形式,其中λ为可学习的参数,在训练过程中将会与其他参数一起被优化.这种噪声能在训练过程中动态地优化ST-GCN 中的人体骨架空间结构,从而使得ST-GCN 不仅能够在相邻关节点间挖掘特征,也能在不相邻的关节点间提取到丰富的特征,从而能够更好地进行动作识别.最后,实验结果证明了本文方法的可行性:在NTU RGB+D 和Kinetics-Skeleton 两个大规模数据集上达到了基于骨架的动作识别领域的先进水平.
1 基于高斯噪声的ST-GCN
1.1 ST-GCN流程框图
基于ST-GCN的骨架动作识别方法模型简单,能自动提取关节运动特征,其性能优于传统的基于人工设计特征的方法.基于ST-GCN的骨架动作识别流程图如图1所示,首先将数据集中的骨架数据构建成时空图并输入ST-GCN,通过时空图卷积操作同时聚集时间和空间维度的信息,从而进行动作识别.
1.2 ST-GCN中的图卷积
本节将介绍ST-GCN 中的骨架图构建,并简单介绍其在空间及时间维度上所进行的图卷积操作.在ST-GCN 中,根据输入的关节点序列来构建时空图,构建规则如下:1)在单帧内部,遵循人体的自然骨架连接关系来构建空间图;2)将相邻两帧内的同一个关节点连接起来,构成时序边;3)所有帧中的关节点构成节点集,上述两个步骤中所有的边构成边集,节点集和边集的总和就是ST-GCN 所定义的时空图.时空图的构建示例如图2所示,“○”表示人体的关节点,虚线代表着所有时序边的集合.每个关节点的坐标以及置信度组成了该关节点的属性,这些属性将作为数据被输入到图卷积神经网络中.
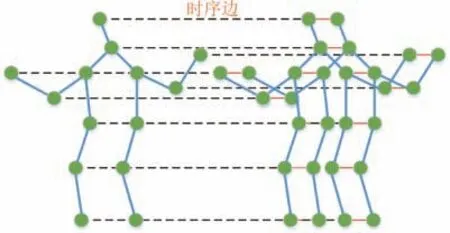
图2 时空图Fig.2 Spatial-temporal graph
在时空图构建规则已知的条件下,就可以在预先定义好的图上进行多层时空图卷积操作以便生成高层次的特征.最后,卷积后得到的特征将经过全局平均池化层和Softmax 分类器以预测出最终的动作类别.
空间维度上,某关节点vi上的图卷积被定义为:
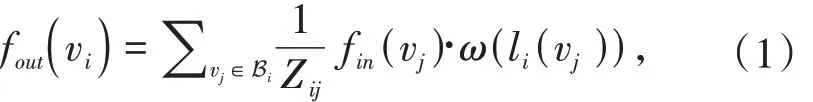
其中,fin和fout代表输入和输出特征图;vi 代表该空间维度中的某个关节点;Bi 代表该关节点卷积时的采样区域(此处为vi 的一阶邻居节点vtj的集合);Z 代表顶点v 所在x 子集的基数;w 代表提供权重向量的权重函数.但由于权重向量的个数是固定的,而邻域中的顶点数量确实不断变化的,所以为了能够正确使用权重函数,ST-GCN设计了一个映射函数li.具体来说,可将邻域B 划分x 个子集,对每个子集分配不同的标签,该映射函数可将每一个邻域中的节点按相应的映射规则映射到B的某个子集xi中.图3详细描述了这种映射规则:红星代表人体重心位置,xi1代表根节点本身,xi2代表离重心更近的向心节点,xi3代表离重心更远的离心节点.
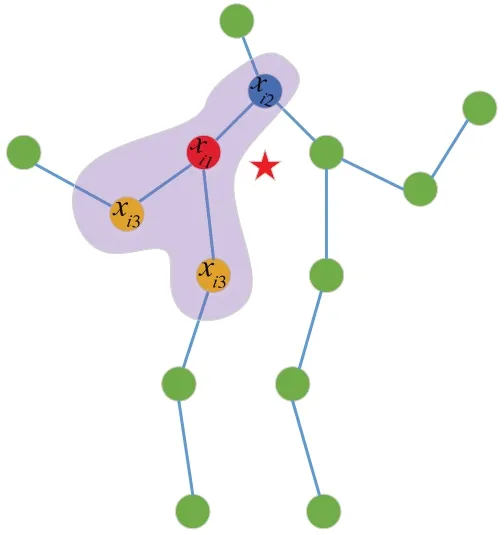
图3 映射策略图示Fig.3 Illustration of the mapping strategy
将式(1)进行转换即可得到ST-GCN 的图卷积公式:
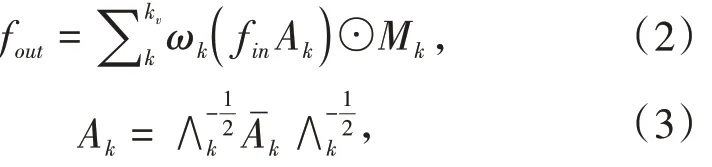
式(2)中kv代表卷积核大小,根据上述的映射规则卷积核大小为3;Aˉk是一个N×N 的邻接矩阵,它表示单M 代表一个可学习的权重矩阵,类似于一个N×N 掩码,它可以代表每个关节点的重要性;ω 是 1 × 1 卷积运算,表示式1 中的权重函数;⊙代表点积运算.ST-GCN 在时间维度上遵循经典的2D 卷积,即执行kt×1的卷积(kt代表时间卷积核大小).综上所述,STGCN 在经过空间维度和时间维度上的卷积操作后,提取出了更高层次的时空特征.
1.3 ST-GCN的网络结构
如图1 所示,在将时空图输入ST-GCN 之前,需要先经过一个批标准化层来归一化输入数据,整个网络由9 个基本单元构成,在图4 中表现为B1~B9.每个基本单元的输出通道数分别是64,64,64,128,128,128,256,256,256,整个网络的后端添加了一个全局平均池化层以将不同样本的特征图转换为相同的大小,最后的输入将被送到Softmax分类器以实现分类,并得到最终的预测结果.
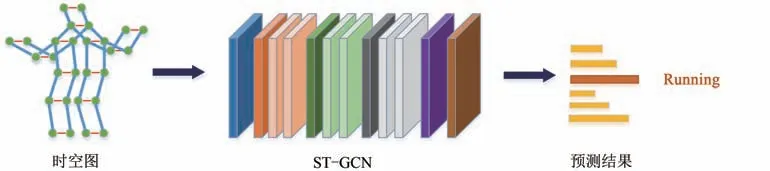
图1 基于ST-GCN的骨架动作识别流程图Fig.1 Flow chart of skeleton action recognition based on ST-GCN
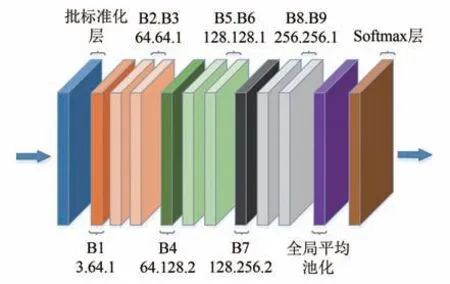
图4 ST-GCN的网络结构Fig.4 The network architecture of ST-GCN
1.4 ST-GCN的基本单元
ST-GCN 的每一个基本单元(B1~B9)都由一个空间图卷积子模块、一个丢失率为0.5 的dropout 随机丢弃层和一个时间图卷积子模块构成,如图5 所示.时间卷积子模块中的时间卷积操作和ST-GCN中的设定一样,均是在大小为C×T×N 的特征图上,利用一个大小为kt×1的卷积核进行2D 卷积.空间图卷积子模块和时间图卷积子模块后都添加了一个批标准化层和一个激活函数ReLU 层.为了使训练阶段更稳定,在每个基本单元中添加了残差连接.针对ST-GCN 在构建骨架空间结构上的不足,本文在ST-GCN 基本单元的空间图卷积层上引入高斯噪声,具体细节见1.5节.

图5 ST-GCN的基本单元Fig.5 The basic block of ST-GCN
1.5 基于高斯噪声的ST-GCN
ST-GCN 中骨架的空间结构由一个人工预定义的邻接矩阵所表示,即式(2)中的Ak,它代表了人体骨架自然连接的先验知识,掩码M 代表着关节之间连接的强度,但在训练过程中使用式(2)这样的点乘操作将无法在不相邻的关节点之间产生新的连接,这意味着,图卷积神经网络的学习能力受到了限制,这样的邻接矩阵不是最优的选择.例如,当网络识别“梳头”的动作时,手和头之间的相关性本应该是显著的,但由于在ST-GCN 中代表头和手的关节点相距甚远,因此限制了“梳头”这个动作样本的特征表达,所以本节对ST-GCN 的邻接矩阵进行一些改进.
针对以上问题,本文将噪声引入原ST-GCN,提出一种基于高斯噪声的扰动机制,即在原始的ST-GCN 的图卷积层中的空间图卷积层中引入高斯噪声Noise,该噪声与原邻接矩阵相加构建成一个新的邻接矩阵,高斯噪声的扰动使得不相邻的关节点之间也能够产生连接关系,既优化了邻接矩阵,又获取到了更适合描述动作样本的骨架空间结构,从而能够更好地进行动作预测.Noise 与Ak结构相似,都是一个N×N 的邻接矩阵,此处的N 表示骨架图包含的关节点数量.具体来说,高斯噪声Noise可用式(4)表示:

其中λ 是一个可训练的参数,它被点乘到高斯噪声φ 的每一个元素上.高斯噪声的参数由2.2节中的消融实验确定.添加Noise 后,空间维度的图卷积公式可由式(2)转变为:
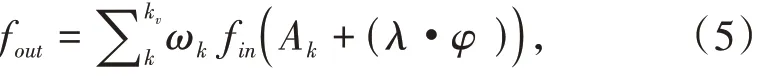
整个优化过程中保留先验知识Ak,并将高斯矩阵Noise 添加至Ak上,噪声添加示意如图6 所示.其中每层的邻接矩阵由Ak和动态变化的高斯噪声Noise共同组成,(1 × 1)表示卷积的核大小,kv表示子集的数量,虚线表示仅当Cin与Cout不同时,才需要残差卷积操作.
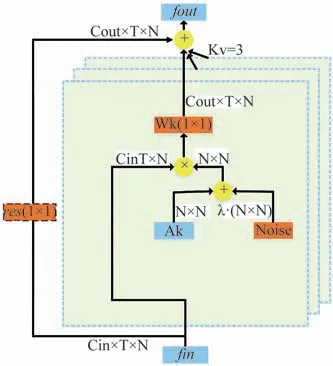
图6 图卷积层加噪图示Fig.6 Illustration of the graph convolutional layer with noise
2 消融实验
2.1 数据集
为了有效地和ST-GCN 进行对比试验,本文遵循该网络选用两种大型骨架动作识别数据集:NTU RGB+D[14]和 Kinetics-Skeleton[4].实验环境为:Ubuntu16.04 系 统 ,CPU 为 Intel Xeon Silver 4110 CPU @2.10GHz,深度学习框架Pytorch,显卡为NVIDIA RTX 2080Ti,内存 64G.
NTU RGB+D:NTU RGB+D 是目前规模最大、应用最广泛的室内动作识别数据集,包含由40名来自不同国籍、不同年龄段、不同性别和外貌特征的志愿者演示的60 个动作类别,共含56000 个动作样本.本文遵循该数据集的两个评估标准:跨对象(cross-subject),即训练集和测试集中的样本分别来自不同的实验对象;跨视角(cross-view),即训练集和测试集中的样本分别来自不同角度的摄像机.
Kinetics-Skeleton:Kinetics 是来自 DeepMind 实验室所建立的极具挑战性的人体骨架动作识别数据集,涵盖了单人、人人交互以及人物交互为主题的动作类别.该数据集总共有306,245 个采集于YouTube 视频的样本,涵盖400 个动作类别,每个动作至少有400 个视频片段.Kinetics-Skeleton 是文献[4]利用OpenPose 姿态估计工具提取的骨架数据集.本文采用Top-1和Top-5的分类精度进行评估.
2.2 高斯噪声的参数
本节分析这种特定高斯噪声Noise 的参数设定,Noise 一共有3 个参数,分别是均值 μ、方差 σ2和可训练系数λ,其中μ 和σ2被设定为超参数.该高斯噪声Noise可用式(6)表示:
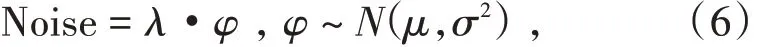
以上3 个参数中,λ 为一个可学习的参数,其在训练过程中将会与其他参数一起被优化.因此只需讨论Noise的两个超参数的设定.
本节采用控制变量法确定高斯噪声分别在Kinetics-Skeleton 数据集和NTU RGB+D 数据集上的两个超参数的最佳取值.本文中,考虑到训练数据的预处理阶段中输入数据的值被归一化至以0 为中心的[-1,1]的范围内,故本文算法首先将高斯噪声的均值拟定在同样以0 为中心的一定范围内以避免噪声与原始数据的不对称性影响整体网络的性能.具体来说,以经验主义考虑,针对K 数据集我们选定均值的范围为[-0.05,0.05],步长设置为0.01;针对N 数据集我们选定均值的范围为[-0.09,0.09],步长设置为0.02.其次,本文中高斯噪声作为一种扰动机制来增加整体网络的泛化能力,故其值不应该过于波动从而影响原始数据的先验性(因为原始的骨架人体连接已经具有一定的信息),故本文算法将高斯噪声的方差拟定在从0 开始递增的小范围内.具体来说,针对两个数据集我们均选定方差的范围为[0,0.45].为方便作图和节省算力,图7 利用Kinetics-Skeleton 数据集的Top-1 准确率作为纵轴,图8 利用NTU RGB+D 数据集的cross-subject子数据集的Top-1 准确率作为纵轴,横轴均为方差σ2的取值.根据折线图7 和折线图8 的结果,高斯噪声在Kinetics-Skeleton 数据集上的最佳参数为μ=0.03,σ2=0.20(即“■”折线);高斯噪声在 NTU RGB+D 数据集上的最佳参数为μ=0.05,σ2=0.23(即“□”折线).
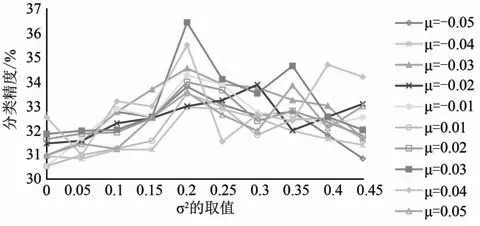
图7 Kinetics-Skeleton上高斯噪声的超参数消融实验Fig.7 Ablation experiments of hyper-parameter on Kinetics-Skeleton
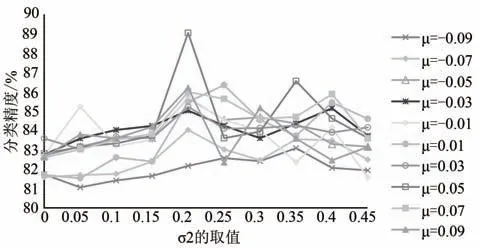
图8 NTU RGB+D上高斯噪声的超参数消融实验Fig.8 Ablation experiments of hyper-parameter on NTU RGB+D
2.3 邻接矩阵与关节点相关性的可视化实验
本节首先展示了邻接矩阵的可视化情况,如图 9 所示 .图 9(a)是 ST-GCN 原始邻接矩阵 Ak的初始状态,图9(b)是添加了高斯噪声并经过训练之后的邻接矩阵状态.图中的灰度代表关节点之间一一对应的连接强度,黑色代表连接强度为0,白色代表连接强度为1,不同强度的灰色代表0 ~1间的不同强度值.原ST-GCN 按人体骨架自然连接来构建邻接矩阵,因此图9(a)中绝大部分关节点之间没有建立起连接,即处于黑色状态,但在添加高斯噪声并进行训练之后,邻接矩阵Ak的连接状态和连接强度发生了不同程度的变化,在原Ak中无法建立连接的两个关节点可以在高斯噪声的扰动下建立不同强度的连接,这也更符合多样化动作识别任务的要求.
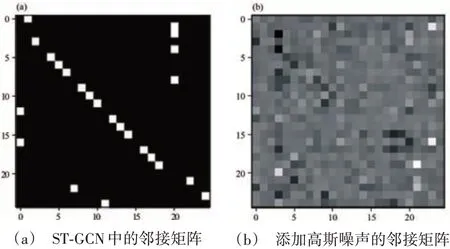
图9 骨架图拓扑结构的邻接矩阵图Fig.9 Adjacency matrix graph of skeleton topology
此外,本节以动作样本“梳头”与“鼓掌”为例,还展示了添加高斯噪声前后关节点相关性在骨架图中的可视化,如图10 所示.这些骨架图是根据人体的物理连接方式连接而成的,每一个“○”代表一个关节点,其大小表示经过模型学习后每个关节点与第25 个关节点“右手拇指”的连接强度(即图10中的★),图10(a)和(c)分别表示“梳头”与“鼓掌”动作样本在ST-GCN 中的关节点相关性在骨架图中的可视化,图10(b)和(d)代表添加高斯噪声后的关节点相关性在骨架图中的可视化.该可视化实验表明,ST-GCN 仅能关注到与“右手拇指”相邻的关节点之间的连接特征,且在ST-GCN 作用下其他节点((a)中表现为头部节点,(c)中表现为左手节点)和“右手拇指”之间的连接强度远小于高斯噪声作用下其他节点((b)中表现为头部节点,(d)中表现为左手节点)和“右手拇指”之间的连接强度.这意味着利用人体物理连接作为骨架图的拓扑结构很难捕捉到非相邻关节点之间的相关性,但添加高斯噪声的方法使得神经网络开始关注到非相邻关节点之间丰富的特征,并且能在训练过程中根据不同的样本动态的修改骨架图的拓扑结构,使得骨架图的拓扑结构表达更具多样性.
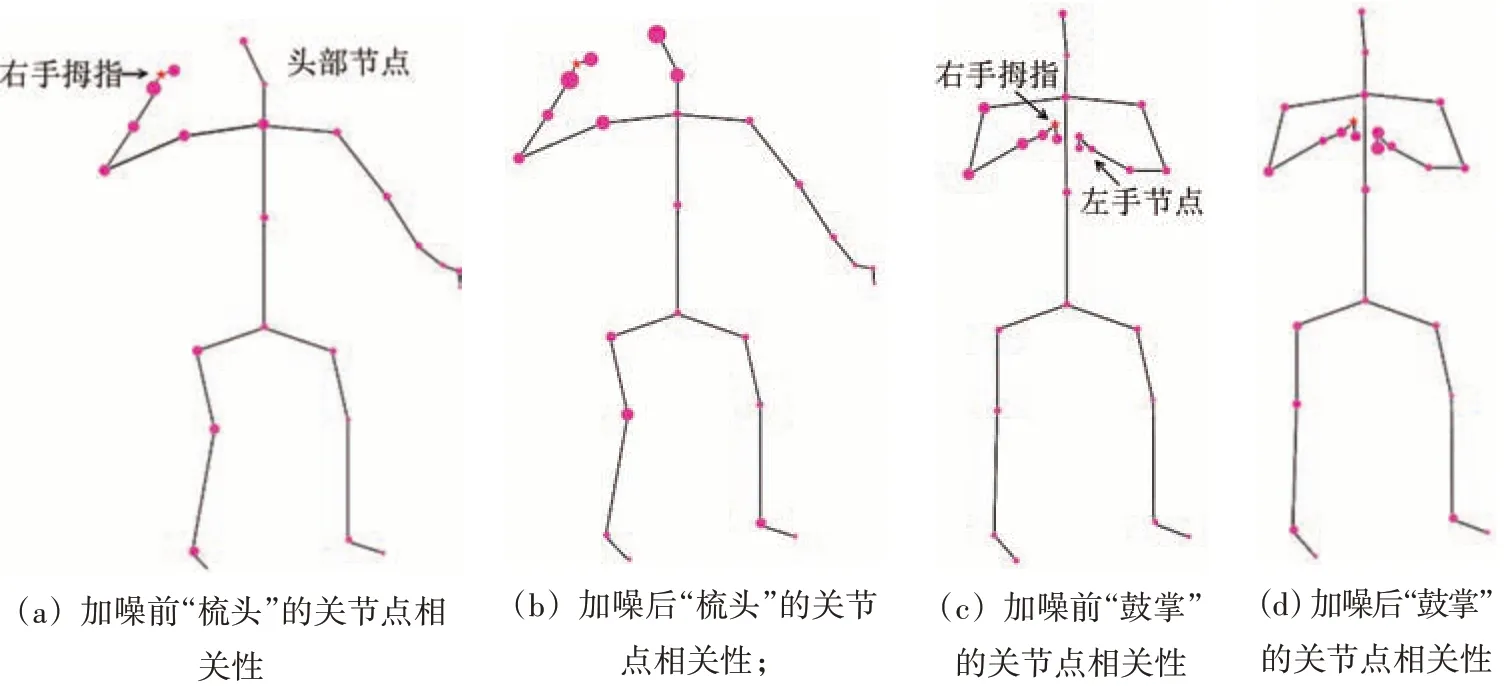
图10 关节点相关性在骨架图中的可视化Fig.10 Visualization of joint correlation in skeleton
2.4 实验结果
本文设计了一种添加高斯噪声的扰动机制,将这种特定的噪声添加至ST-GCN 的原始邻接矩阵Ak上,使得骨架图的拓扑结构表达更具多样性.为了测试了掩码M 在原始的ST-GCN 中的效果,本节实验利用NTU RGB+D 数据集作为基准,将添加高斯噪声之后的效果与之对比(wo/M 代表不添加掩码M),由表1 可显示出高斯噪声对动作识别任务的性能提升.
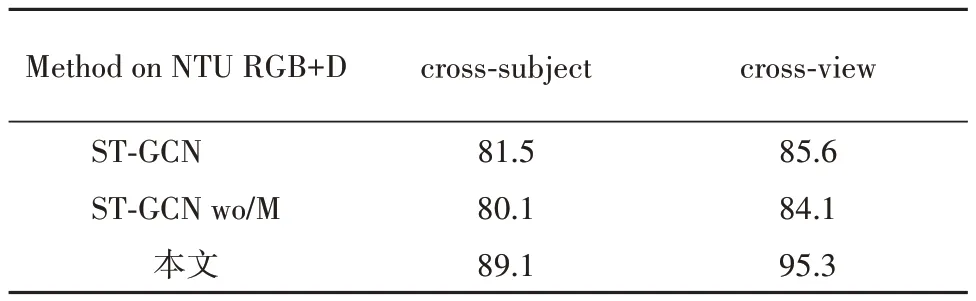
表1 NTU RGB+D数据集上的消融分析Tab.1 Ablation analysis on NTU RGB+D /%
利用2.2 节实验中得出的最佳参数,在NTU RGB+D 和Kinetics-Skeleton 数据集上,将本文的最终的模型与最新的基于骨架的动作识别方法进行比较,比较结果分别显示在表2 和表3 中.其中,用于比较的方法包括基于人工设计特征的方法[8-9]、基 于 RNN 的 方 法[5-7,14-15]、基 于 CNN 的 方法[10-13]和 基 于 GCN 的 方 法[4,16-19]. 另 外 ,针 对 2s-AGCN 中由数据驱动邻接矩阵所导致的计算量翻倍增长问题,进行了计算量对比实验,测试了迭代过程中2s-AGCN、PGCN 与本文方法的平均耗时.

表2 Kinetics-Skeleton数据集上与最新方法的验证精度比较Tab.2 Comparisons of the validation accuracy(%)with state-of-the art methods on the Kinetics-Skeleton dataset
表2 和表3 的实验结果表明:本文模型在2 个数据集上都达到了更高的准确率,这有效地证明了本文模型的优越性(本文模型与PGCN 的精度有一定的差距,原因是PGCN 在输入数据中增加了原视频信息,多样化的模态数据提高了骨架动作识别的性能,但十分占据内存且增加了训练时长).虽然本文提出的基于高斯噪声的扰动机制对于NTU RGB+D 数据集的cross-subject 评估标准的提升仍不够明显,这有可能是因为这种跨对象的评估标准增加了扰动机制动态优化骨架空间结构的难度.另外,两表中的耗时实验也表明:与2s-AGCN 中提出的数据驱动的方法以及PGCN 中提出的基于姿态的动作识别方法相比,本文提出的基于高斯噪声的扰动机制能有效的降低计算量,并在此基础上进一步提升了骨架动作识别的性能.
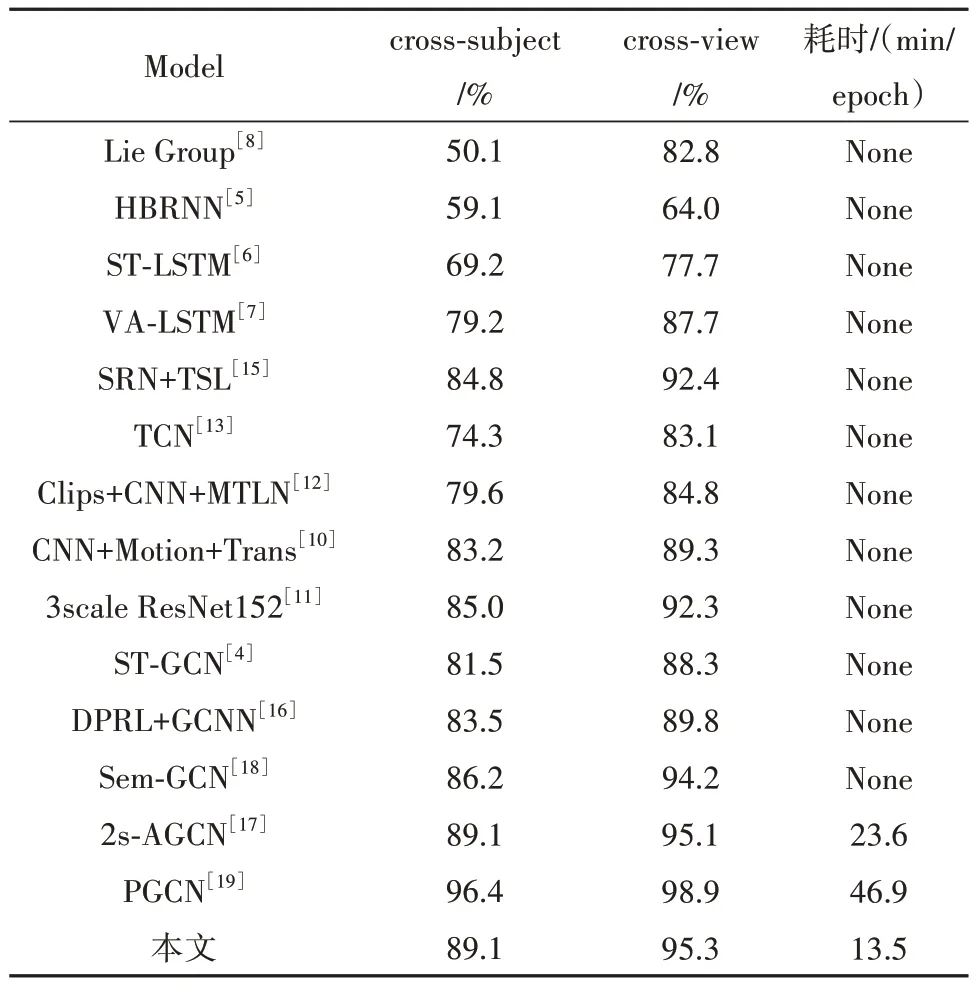
表3 NTU RGB+D数据集上与最新方法的验证精度比较Tab.3 Comparisons of the validation accuracy(%)with state-of-the art methods on the NTU RGB+D dataset
3 结语
本文提出一种基于高斯噪声扰动机制,用以优化基于ST-GCN 的骨架动作识别中结构单一的邻接矩阵.具体来说是在原始的ST-GCN 的空间图卷积层中引入高斯噪声,该噪声与原邻接矩阵联合构建成一个新的邻接矩阵,高斯噪声的扰动动态优化了原ST-GCN 的中的骨架空间结构,使得不相邻的关节点之间也能够产生不同强度的连接关系,从而能够促进ST-GCN 更好地进行动作识别.最后,在2 个极具挑战性的大规模数据集NTU RGB+D 和Kinetics-Skeleton 上对模型进行了评估,实验证明本文方法在2 个数据集上都能获得更高的识别精度,但本文方法对于NTU RGB+D 数据集中的crosssubject 评估标准存在一定的局限性,未来的工作可以聚焦于如何更好地优化噪声,提升噪声扰动机制在不同评估标准下的泛化性,进一步改善和提高模型的性能.
