网络视听节目监管系统数据采集关键技术研究
2022-06-30王小珍
王小珍

[摘要]文章根据目前网络视听节目监管系统中视听节目数据采集技术的现状,通过分析归纳出目标Web页面编码元素的共有特征,提出一种基于视听节目识别技术的通用型模板主题爬虫程序,并分析研究网站遍历策略及多进程协同并行执行策略等关键技术,以大幅降低网络视听节目监管系统的维护成本,提高其监管工作的智能化水平,为研究建立高效的网络视听节目监管系统提供参考。
[关键词]网络视听节目;主题爬虫;广度优先搜索;多进程调度
近十年,网络视听媒体发展迅速,视听节目传播数量呈爆发式增长,并呈现数据更新频繁、内容丰富多样等特点。网络视听媒体平台在提供丰富多样的节目的同时,也为一些“丑、色、怪、假、俗、赌”等各类违法违规信息提供了传播渠道,损害了网络视听媒体的影响力和公信力,助长了社会不良风气。因此,建立智能化的网络视听节目监管系统,推动监管系统创新发展,在海量数据信息中快速、準确地提取出视听节目,及时发现和解决各类违法违规问题,对构建风清气正的网络视听环境具有积极意义。
目前,大多数网络视听节目监管系统主要通过定制模板爬虫程序的方式来采集目标网站数据信息,此类模式的爬虫程序需要人工归纳和提取目标网站Web页面中视听节目的所属板块、上传者、下载地址等信息来作为该网站爬虫程序的模板。其优点是采集数据准确率高,但若网站发生改版,模板程序匹配不到对应的属性信息,则会导致无法抓取到网站数据,这就需要技术员重新修改爬虫程序模板,才能采集到所需数据。此类定制模板爬虫程序根据特定网站属性而制作,因此不适用于其他网站数据信息的采集,其扩展性和通用性较差。文章研究通用型模板主题爬虫程序,使其普遍适用于网络视听节目服务网站的视听节目数据采集,并为构建智能化网络视听监管系统提供具有参考意义的案例。
一、通用型模板主题爬虫程序的实现
主题爬虫程序是一个自动提取与主题信息相关网页的搜索程序。其具有三个方面的核心技术问题,一是设定采集数据目标的描述或定义;二是网页数据信息的过滤与分析;三是网站URL的遍历策略。文章讨论的通用型模板主题爬虫程序预设置主题相关信息为视听节目特征元素,采用文字密度页面分析技术,提取出与主题相关的视听节目链接,而网站遍历策略则以广度优先搜索策略与“海捞”算法相结合的方式来采集目标数据信息。
(一)视听节日特征元素
在网络视听节目服务网站中,不同的开发者虽然在采用技术及代码方面存在一定的差异,但是也会遵循统一的技术规范。文章在对大量Web页面传播视听节目的代码进行分析研究的基础上,经由高层次抽象提取、归纳,提取出视听节目在Web页面代码中的共同特征信息,作为通用型模板主题爬虫程序的主题目标信息,此种主题爬虫程序能普遍适应大多数互联网视听节目服务网站的数据采集。在通常情况下,Web页面中的视听节目编码的后缀名信息、引用播放信息、播放器加载信息、特殊播放格式信息等,均遵循一定的规律特征,主要表现为以下几种情况。
一是Web页面中视听节目的后缀名编码规则。在通常情况下,视听节目常用格式有MPEG、AVI、ASF、MOV、WMV、3GP等,这些文件格式在Web页面中的代码也以相应的视听文件后缀名格式出现,如MPEG文件格式视听节目在Web页面中编码的后缀名为“.mp4”,AVI文件格式视听节目在Web页面中编码的后缀名为“.avi”等。
二是Web页面中引用视听节目也具有一定的编码规则。为了提高网站数据资源的丰富性,有部分视听节目服务网站传播的视听节目除了本网站所属服务器的资源,还调用其他媒体平台的视频资源,如引用央视网、优酷、腾讯、爱奇艺等媒体平台所提供的视听节目源。这些引用站外平台节目源的网站在Web页面中会出现引用媒体平台的URL地址相关标识。比如,某网站引用央视网网站平台的视听节目资源,则在该视听节目展示区域的Web页面编码中就会含有“cctv.com”等元素。
三是Web页面中加载播放器信息的编码规则。互联网视听节目服务网站为用户提供视听节目服务,需要在Web页面代码中加载播放器相关信息。目前被广泛使用的播放器的类型主要分为专用播放器、流媒体、flash、现代播放器等。流媒体是目前网络平台较为流行的视听媒体传播格式,其常见的格式有M3U8、RA、RM、SWF等。其传播方式是把视听节目压缩后,按规则将视听节目拆分成多个小片段,以视频流(视频片段)的方式发送至用户端,当特定播放器接收到视频流(视频片段)后,用户即可边播边看。此外,有部分网站也通过调用专用播放器的形式为用户提供视听节目在线观看服务,例如调用爱奇艺、优酷、腾讯、哔哩哔哩等平台研发的专用播放器。另外,也有部分网站采取调用player等通用播放器的方式为访问用户提供视听节目在线观看服务。在Web页面中加载这些流媒体播放器、专用播放器等播放器信息,页面编码均呈现特定的编码规则,如含有“showPlayer”“player.video.qiyi.com”“flvplayer.swf”等播放器信息编码元素。
四是特殊播放器在Web页面中的元素特征。除了上述情况,还有部分互联网视听节目服务网站以加载特殊播放器的方式提供视听节目,其页面编码也有相应的规律,如含有“aliyunlayer”“playerframe”等特征元素。
通过分析上述几种视听节目特征元素发现,网络视听节目服务网站在为用户提供视听节目在线观看服务时,其Web页面中的编码元素均具有一定规则,根据这些编码元素的特征和规律,配置为主题爬虫程序的目标信息,制作成基于视听节目识别的通用型模板主题爬虫程序。此类爬虫程序作为网络视听节目监管系统中数据信息采集的重要手段,解决了原有定制模板爬虫程序通用性较差等问题。主题爬虫程序根据Web页面中含有符合视听节目的元素特征的某一种或多种元素来判断页面含有视听节目的概率,网站页面的链接中含有符合视听特征的元素越多,则该链接为视听节目链接的概率就越大。在通常情况下,在程序调试及实际使用过程中,使用者根据网站采集数据的正确率,对主题爬虫程序主题相关度的阈值进行调整,以提升程序采集的准确率。E8EDFC82-0FA6-4531-BD7D-1A739FED0DD3
(二)爬虫主题信息相关度计算
文章讨论的通用型模板主题爬虫程序中的主题信息为视听节目特征元素,其在Python程序中用正则表达式来标识。在主题相关度的计算过程中,利用视听节目特征元素对某一个URL进行评分时,需要下载URL指向的目标页面,再对其进行评分,并在配置文件中设置好主题相关度的阈值,如果主题相关度得分大于这个阈值,就进行下一步处理,否则就把这个URL对应的页面丢弃。
笔者将从Web页面提取的视听节目特征元素个数n作为空间向量的维数,设置特征元素的权重ωi作为每一维度分量的大小,则该主题空间向量表示为:
=(ω1,ω2,...,ωn),i=1,2,...,n
对网页代码的空间向量建立进行统计,计算出视听节目特征元素出现的个次数,并求出对应的频率之比,将出现频度最高的特征元素作为基准,其频率用x1=1表示,通過频率比求出其他特征元素的频率xi,则这个页面所对应的向量的每一维度分量为xnωn,
那么网页代码对应的空间向量表示为:
q=(x1ω1,x2ω2,...,xnωn),=1,2,...,n
用两个向量的余弦表示页面的主题相关度为:
同时,技术员设定一个阈值m,当cos<·q>大于等于m时,目标页面与主题相关度高,如果小于m,则目标页面与主题相关度不高,可直接把该页面做丢弃处理。在实际应用过程中,技术员可以根据采集数据的正确率对m阈值进行微调。但是此种通用型模板主题爬虫程序在应用中的准确率无法达到100%,需要进一步结合人工智能模型进行训练,不断调整主题相关度的阈值,以提升主题爬虫程序的准确性。
(三)网站遍历策略
文章讨论的主题爬虫程序采用广度优先搜索策略与“海捞”算法相结合的方式来采集目标数据信息。网络爬虫的原理基本大同小异,主要包括广度优先搜索策略、深度优先搜索策略和最佳优先搜索策略等,其中广度优先搜索策略遍历网站,遍历方式类似于树的按层次进行搜索。假设网站所有顶点集合为图G,其初始状态是“所有定点均未访问过”,在图G中任选一个顶点Vi作为爬虫程序最初的出发点。则广度优先搜索遍历网站的基本思路为:先访问出发顶点Vi,紧接着依次访问其邻接点W1,W2,...,Wi,然后再依次访问与W1,W2,...,Wi相邻接的所有未曾访问过的顶点。依次循环,直至网站中所有与初始出发点Vi有相同路径的顶点均已访问为止,则完成整个网站的搜索遍历。广度优先搜索策略能较好结合主题爬虫程序对目标网站充分、快速、准确地进行数据信息采集。
通用型模板主题爬虫程序的分析算法用“海捞”算法,其也叫Fish-Search方法,工作原理为:把主题爬虫程序比喻成海里的鱼群,把爬虫抓取主题相关的有效网页比喻成食物,把整个网站比喻成大海。当鱼群发现食物后,会繁殖后代,即为增加有效网页里的链接,对Web页面内容进行分析,将主题相关度高的页面链接加入待爬取队列,直到达到预先设定的网页层数才终止程序退出。因此,主题爬虫程序将“海捞”算法结合页面内容进行分析,以视听节目特征元素作为爬虫抓取主题相关的目标,完成目标页面中视听节目链接的采集。
二、爬虫工作流程
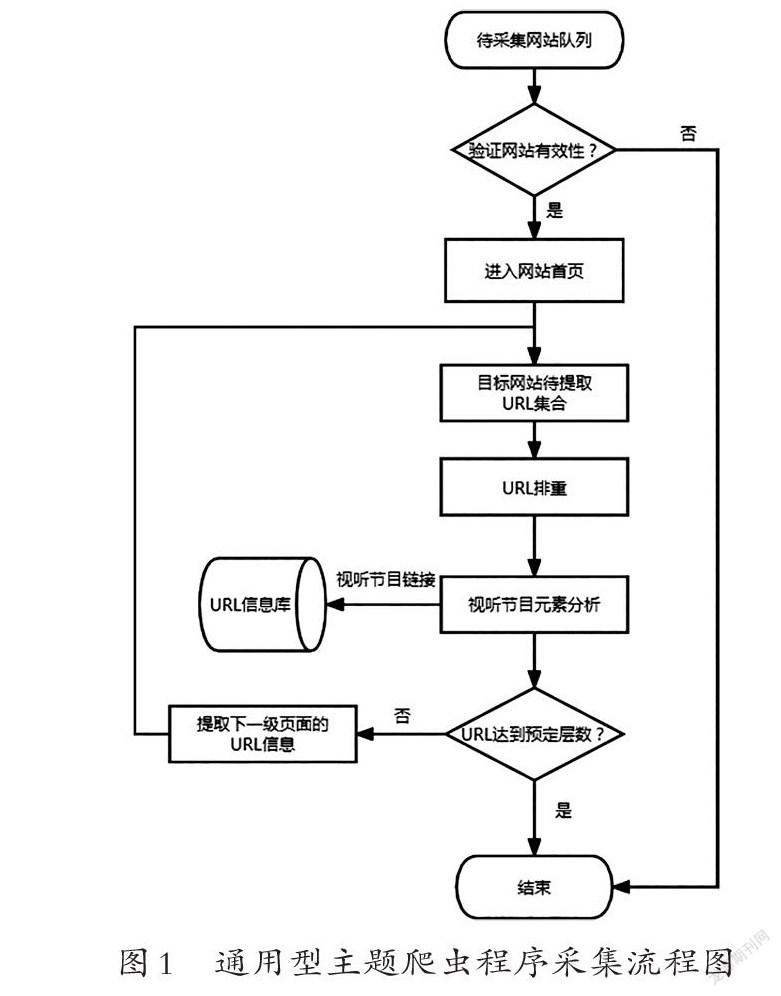
程序将需要采集的网站集合至待爬取网站队列,基于通用型主题爬虫程序根据设定数据采集规则对目标网站的Web页面数据信息进行搜索遍历,并下载相关网页信息。程序搜索目标网站信息的同时,提取页面中所有的URL,排重后存放至待爬取的URL集合队列。页面分析程序则对已下载于存储中的目标网页数据信息进行分析研判,识别出各个网站中含有视听节目的URL,并将相关页面中的视听节目标题、发布者、发布时间等信息一并存入数据库中。其采集流程分为五步,如图1所示。
三、多进程任务调度
基于网络视听节目分析的通用型模板主题爬虫程序在采集网站数据信息过程中,需要访问待爬取的目标网站,并分析Web页面的数据信息,下载与主题相关的目标页面。为了提高程序执行效率,本系统建立了多进程爬虫程序调度模块,该模块对主题爬虫的数据采集程序、数据下载程序、页面分析程序等进行整体统筹调度,根据各个资源池待分配的任务情况,及时、有效地调度各个程序协同分工合作,以达到各类进程同时并行执行的目标。
多进程协同并行执行的模式,主要根据待抓取网站数量来分配同时执行进程的数量,进程的最大数量受服务器CPU内核限制,单核CPU的服务器只能同时执行1个进程,本系统采用的服务器为多核CPU服务器,最多可同时并行执行8个进程。其工作原理为:调度程序根据待采集的目标网站数量,分配对应的主题爬虫程序对不同的目标网站分别进行数据采集,主题爬虫程序把采集到的Web页面信息下载存入至存储器中,调度程序分别在等待队列中的页面分析程序对缓存中的页面数据进行分析研判,并返回识别到含有视听节目的URL信息。
四、结语
近年来,国家网信办持续在网络媒体平台开展系列“清朗”专项整治行动,推动网络空间健康有序发展。在此形势下,监管部门及网络媒体平台应不断创新理念、方式与模式,依托先进科学技术方法,通过人工智能等技术破解网络视听媒体平台监管过程中的各种难点和痛点,进一步加强监督管理,切实维护好网络用户的合法权益。面对日趋复杂的网络媒体环境,文章研究的通用型模板主题爬虫程序仍处于初级阶段,其在解决智能化网络视听节目监管过程中仍面临诸多问题,当下人工智能等技术快速发展,主题爬虫程序如何更好地结合机器学习、深度学习等先进技术进行更智能的训练、学习,建立更加智能化的采集模型,还需要进一步探究。
[参考文献]
[1]杨本栋.基于网页信息自动提取的分布式爬虫系统设计与实现[D].北京:北京邮电大学,2021.
[2]程光,吴桦,王会羽,等.僵尸网络检测技术[M].南京:东南大学出版社,2014.
[3]库波,曹静.数据结构(Java语言描述)[M].2版.
北京:北京理工大学出版社,2016.E8EDFC82-0FA6-4531-BD7D-1A739FED0DD3
