关注全局真实度的文本到图像生成①
2022-06-29胡莹晖刘兴云
胡 成, 胡莹晖, 刘兴云
(湖北师范大学 物理与电子科学学院, 黄石 435002)
从文本生成图像是计算机视觉领域十分重要的一大方向, 即通过给定输入文本语句, 生成相对应内容的图像, 具有广泛的应用. 例如小说配插图、图像编辑、图像的检索等等. 生成对抗网络(GAN)[1]被应用在文本生成图像上取得了一定的可观效果. Reed 等[2]最先将GAN 应用到文本生成图像中, 生成了肉眼可接受的64×64分辨率的图像, 验证GAN 在文本生成图像的可行性. Zhang 等[3]提出堆叠式的结构(StackGAN), 将任务阶段化, 逐步细化生成的图片, 生成图像达到256×256分辨率. 后来, Zhang 等人改进了StackGAN,提出端到端树状结构的StackGAN++[4], 通过多尺度的判别器和生成器, 提高了生成图像的质量和清晰度, 但是图像整体亮度偏暗淡, 与数据集样本存在偏差, 同时缺少生成图像真实度的判定.
注意力机制在图像和自然语言处理方面有着广泛的应用. Zhang 等[5]提出的SAGAN 首次将自我注意力机制与GAN 结合, 减少参数计算量的同时, 也聚焦了更多的全局信息. Fu 等[6]提出双重注意力机制, 在空间和通道两个维度进行特征融合, 用于语义分割. Tang 等[7]结合双重注意力机制, 应用于语义图像合成.
受到以上实验的启发, 针对出现的问题, 我们提出结合双重注意力机制的端到端模型, 该模型基于Stack-GAN++基本结构, 以双重注意力机制去最大化融合文本和图像的特征, 树状结构生成低到高分辨率(128×128)的图像; 添加VGG19[8]预训练模型, 提取生成图像和真实图像特征, 计算相似度损失.
该模型旨在提高生成图像的全局真实度. 全局真实度指图像内容的完整度, 颜色的鲜明度, 场景的对比度和亮度符合人眼视觉感知的程度.
我们在CUB[9]鸟类数据集上验证了该方法, 并使用IS 和SSIM 指标判定生成图像的多样性、质量和全局真实度. 实验结果分析证明, 与原有技术相比, 我们模型生成的图像一定程度上呈现了更多的鸟类特征,并提升了整体的亮度和颜色鲜明度, 使生成图像感知上更加接近于真实图像.
1 模型及方法
1.1 模型结构
本文网络结构整体框图如图1 所示. 结构主要由文本编码器、2 个生成器、3 个判别器和VGG19 网络构成. 文本编码器使用文献[10]中提供的字符级编码器(char-CNN-RNN), 生成器采用前后级联的方式, 第一个生成器包含1 个全连接层和4 个上采样层, 第二个生成器包含连接层, 空间和通道注意力模块, 2 个残差网络[11]和1 个上采样层. VGG19 网络作为额外约束, 判别生成图像和真实图像的相似度.
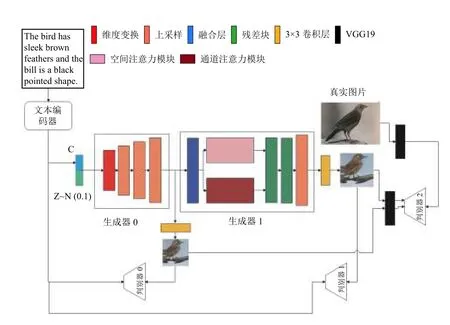
图1 模型结构
网络大致分为两个阶段, 每个阶段都包含多个输入, 如式(1)所示:
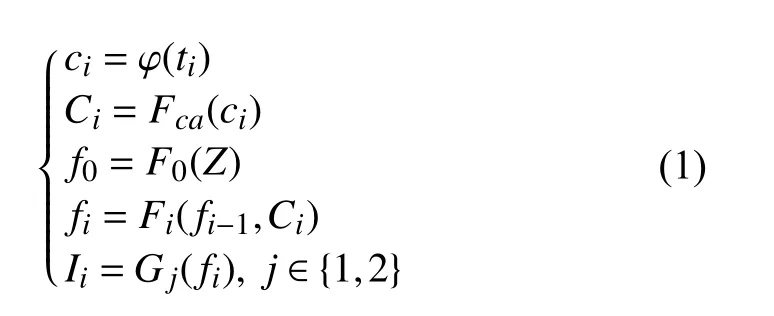
其中, φ表示文本编码器,ci表示全局句子向量,Fca表示条件增强模块,Fi表示全连接层,Gj表示生成器,Ii表示生成器输出.
1.1.1 双重注意力机制
由于图像像素区域和文本存在对应关系, 不同通道存在依赖关系, 我们引入空间和通道注意力机制, 输入为文本向量和低分辨率特征的融合矩阵, 引导生成器更多关注整体特征的关联性和匹配度. 由于高分辨率图像是在低分辨率图像的基础上进行细化, 所以低分辨率图像的好坏决定着最终输出的好坏. 虽然低分辨率图像更加的模糊, 缺少细节, 但是却保留着更多的全局特征. 所以我们将机制放置在G1 的连接层后, 即残差模块前, 引导生成器在低分辨率维度上关注更多的全局特征. 注意力机制模块如图2, 图3 所示.
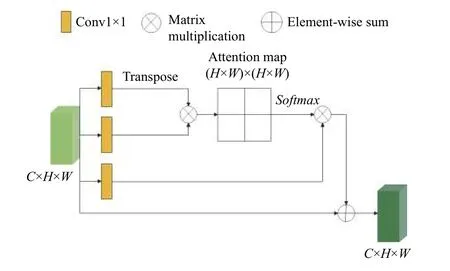
图2 空间注意力模块(SAM)结构
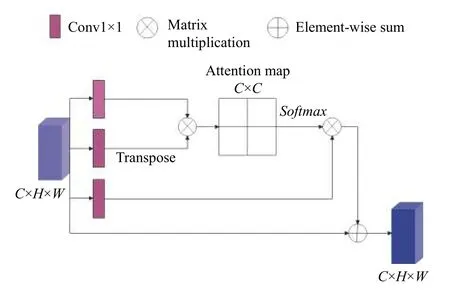
图3 通道注意力模块(CAM)结构
对于通道注意力模块而言, 输入是文本向量和上阶段图像矩阵连接后卷积得到的特征图(h∈RC×H×W).其流程对应公式如式(2):
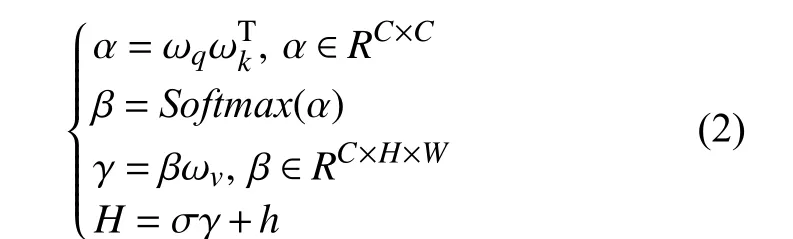
其中, ωq∈RC×H×W、ωk∈RC×H×W、ωv∈RC×H×W分别代表特征图经过三个通道的1×1 卷积后得到的特征矩阵. 对 ωq和 ωk转置应用一次矩阵乘法, 随后经过Softmax层得到位置注意力映射图, 再与特征矩阵 ωv进行一次矩阵乘法运算, 最后乘上权重因子 σ和输入特征图(h)逐元素相加得到输出, 以此来增强通道特征图之间的语义依赖性. 权重因子初始化为0, 并逐步学习变化.
空间注意力机制忽略了通道间的语义关联性, 关注像素间的特征信息, 运算与通道注意力机制类似. 两个模块输出最后从通道维度进行拼接, 得到最终的结果.
1.1.2 VGG19
增强型超分辨率生成对抗网络(ESRGAN)[12]中指出, 使用VGG19 的第5 个maxpool 层前的最后一层卷积层去提取图像特征, 使得生成图像特征在亮度和颜色感知上更接近于真实图像. 受其启发, 我们引入VGG19的前35 层网络层进行预训练处理, 用来提取生成图像和真实图像的特征, 求取两者的L1 损失, 作为生成图像真实度的判别约束.
1.2 时间复杂度
空间注意力模块输入C×H×W矩阵, 计算相似特征图的时间复杂度为O(CN2)(N=H×W),Softmax的时间复杂度为O(N2), 加权求和的时间复杂度为O(CN2),所以空间注意力模块的时间复杂度为O(CN2). 以此类推, 通道注意力模块的时间复杂度为O(C2N). 而该模型生成器的最后一层卷积层的时间复杂度为O(N4kC2)(k=3,表示卷积核大小)由于N=64×64,C=64, 所以O(CN2)>O(N4kC2), 即双重注意力模块在本实验中,虽然取得良好的效果, 但增加了算法的时间复杂度, 在训练时间上并不占优势.
1.3 损失函数
1.3.1 生成器损失
生成器损失包含非条件损失和条件损失两部分.非条件损失用来判别图像是真实的或是虚假的; 条件损失用来判别图像和文本是否匹配.
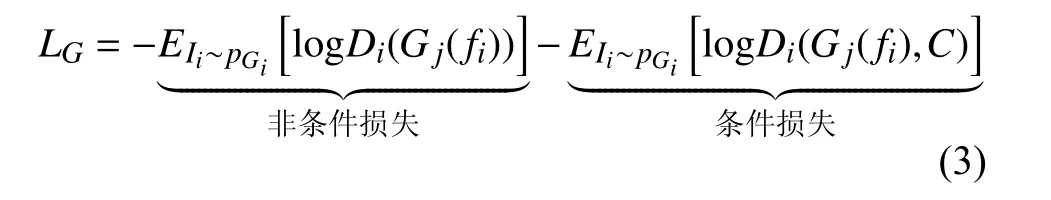
其中,Gj(fi)表示生成器的输出.j=0,1, 代表两个生成器.Ii表示生成的第i个图像, 来自于生成图像分布pGi
两个生成器对应两个尺度的图像分布生成, 各自后面接一个判别器. 不同尺度生成图像送入判别器中,计算交叉熵损失, 返回真假概率和图像文本匹配概率.生成器Gj和判别器Di两者交替优化, 以致收敛.LG值越小, 代表优化效果越好.
1.3.2 判别器损失
判别器损失包含非条件损失、条件损失和真实度损失3 部分.

其中,L1 表示真实度损失. 由VGG19 提取真实图像和不同尺度图像的特征空间, 送入判别器计算L1 范数距离损失, 通过最小化损失, 达到优化效果.
Ri: 第i个真实图像, 来自于真实图像分布pdatai.
Ii: 生成的第i个图像, 来自于生成图像分布pGi.
µ: 损失系数, 设其值为0.001.
非条件损失分别计算真实图像、各个尺度生成图像的交叉熵损失, 优化判别器判别真假的能力. 条件损失采用正负对比计算, 正计算包括真实图像和对应标签, 生成图像和对应标签两个组合, 负计算指真实图像和不对应标签. 通过正负对比学习, 优化判别器判别图像文本匹配能力.
2 实验结果和分析
2.1 实验环境
本文实验基于搭载GTX1070i 显卡的CentOS 7 操作系统, 使用Python 2.7 编程语言, PyTorch 框架.
实验设置训练过程中生成器和判别器学习率为0.0001, batch_size 为8, 迭代次数为160 次.
2.2 实验数据集及评估指标
2.2.1 数据集
本文实验方法在CUB200-2011 数据集上进行验证. CUB200-2011 数据集由加州理工学院提出, 共包含11788 张鸟类图像, 200 种鸟类, 每张图像对应10 个文本描述语句. 除类别标签外, 每个图像都会用1 个边界框、15 个零件关键点和312 个属性进行进一步注释.其中, 训练集8855 张图像, 测试集2933 张图像, 如表1.

表1 实验数据集
2.2.2 评估指标
本文采用Inception Score (IS)和SSIM作为评估标准.IS基于预先在ImageNet 数据集[13]上训练好的Inception V3 网络. 其计算公式如下:
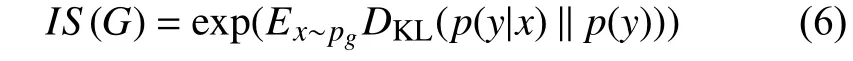
其中,x~pG表示生成的图片,y表示Inception V3 预测的标签,DKL表示KL 散度
公式表明,IS评估生成图像的多样性和质量, 好的模型应该生成清晰且多样的图像, 所以边际分布p(y|x)和条件分布p(y)的KL 散度越大越好, 即IS值越大越好. 但是IS存在不足之处, 它不能判定生成图像的真实度, 所以我们引入SSIM指标.
SSIM(structural similarity), 结构相似性度量指标,已被证明更符合人眼的视觉感知特性. 我们用其评估生成图像的真实度.SSIM包含亮度、对比度、结构3 个度量模块. 其计算公式如下:
亮度对比函数:
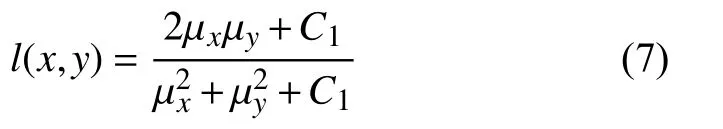
对比度对比函数:
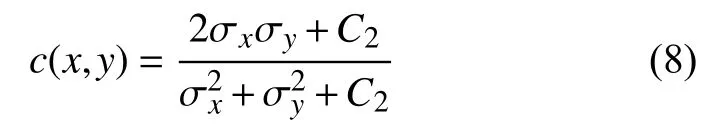
结构对比函数:
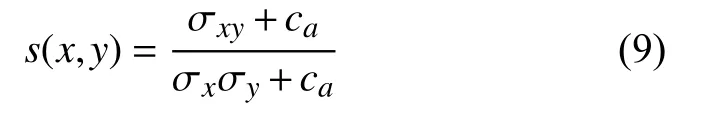
最后把3 个函数组合起来得到SSIM指数函数:
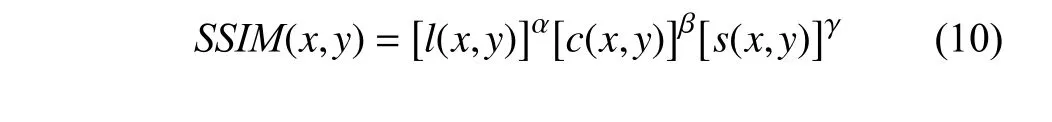
2.3 实验结果及比较
我们将模型在CUB 数据集的训练集上进行训练,并在测试集上进行了验证实验. 下图展示训练过程中收敛的判别器损失和生成器损失, 以及IS值.
结合图4、图5 我们看出, 判别器损失逐步收敛到(2, 3)区间, 保持平稳震荡; 生成器损失逐步上升到(25, 30)区间, 基本保持缓慢上升的趋势. 模型判别器和生成器形成对抗趋势, 逐步保持平衡状态.
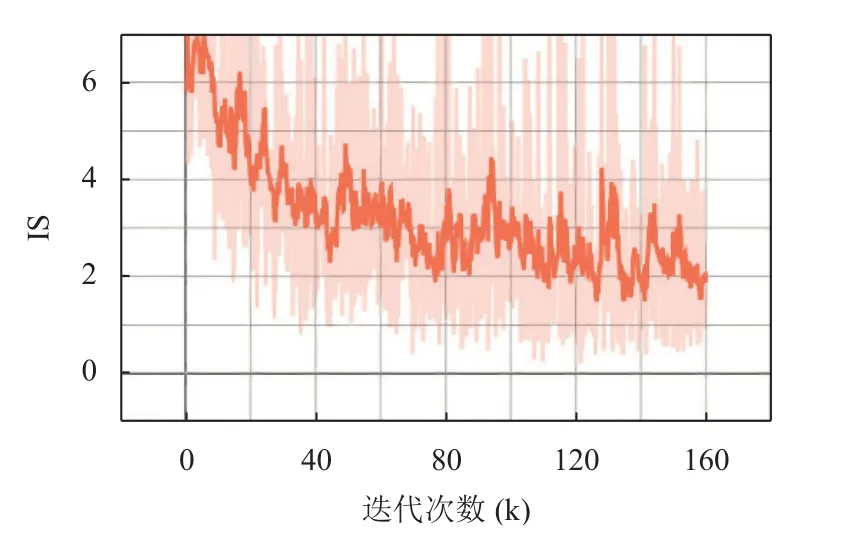
图4 判别器损失
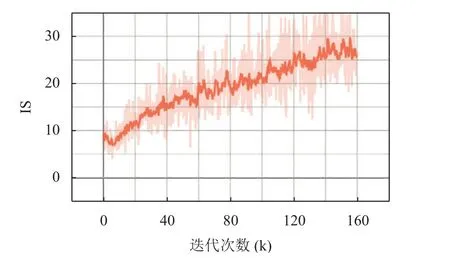
图5 生成器损失
由图6 看出, 我们的模型IS值最高可达到5.6 左右.
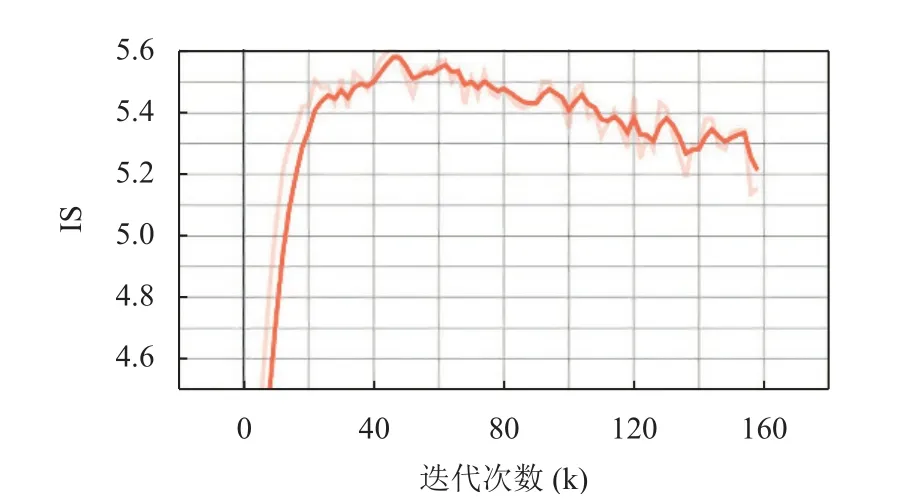
图6 Inception Score
为了节省内存占用率, 我们将StackGAN++缩减为两个阶段, 生成128×128分辨率的图像, 在CUB 数据集上进行训练和测试. 并和我们的方法的测试结果进行了对比, 实验结果如图7 所示.
由图7 可以很明显观察到, StackGAN++模型生成的128×128分辨率的图像亮度偏暗, 与真实图像存在差异. 我们的方法生成的图像颜色更加的鲜艳, 图像整体更加的明亮, 在背景颜色、鸟类形状和整体感知上, 更加地接近真实图像. 同时, 鸟类的羽毛纹理更加的丰富,例如图7(b)–图7(d).

图7 测试结果示例
我们列举以往不同模型在CUB 数据集上的IS值,进行一个对比, 见表2. 我们所提方法评估的IS值能够达到5.4, 高于所比较的以往模型.

表2 各模型在CUB 上的IS 值
为了定量地评估我们模型对真实度提升的贡献,我们用SSIM指标在生成图像和真实图像做相似性评估, 在StackGAN++模型和我们模型做了对比实验, 见表3.

表3 模型在CUB 上的SSIM 值
由表3 看出, 相同模型下, 更高分辨率的生成图像具有更高的SSIM值, 符合图像质量提升导致真实度提升的逻辑. 以此为前提, 对比不同模型在相同分辨率的SSIM值, 我们的模型值更高, 则图像真实度相比更高.结合实验结果图来看, 我们模型生成的图像人眼感知与真实图像样本也更加相似.
3 结论
本文提出一种以堆叠式结构为基础, 着重关注图像全局特征真实度的生成对抗网络, 应用于文本生成图像任务. 实验结果证明, 同以往的模型对比, 结果图像更加专注于全局特征, 颜色的鲜明度和整体视觉效果更加具有真实感, 更接近于真实图片. 这是因为我们引入双重注意力机制引导图像学习对应文本的更多特征; 使用真实感损失约束, 提高生成图像的真实感. 在文本单词向量级别, 增添图像子区域的细节, 提升文本和图像的语义一致性, 应用于更加复杂的数据集, 会是接下来研究的一个方向.
